tensorflow之欠拟合与过拟合,正则化缓解

过拟合泛化性弱
欠拟合解决方法:
增加输入特征项
增加网络参数
减少正则化参数
过拟合的解决方法:
数据清洗
增大训练集
采用正则化
增大正则化参数
正则化缓解过拟合
正则化在损失函数中引入模型复杂度指标,利用给w增加权重,弱化数据集的噪声,loss = loss(y与y_) + REGULARIZER*loss(w)
模型中所有参数的损失函数,如交叉上海,均方误差
利用超参数REGULARIZER给出参数w在总loss中的比例,即正则化权重, w是需要正则化的参数

正则化的选择
L1正则化大概率会使很多参数变为0,因此该方法可通过系数参数,减少参数的数量,降低复杂度
L2正则化会使参数很接近0但不为0,因此该方法可通过减少参数值的大小降低复杂度
with tf.GradientTape() as tape:h1 = tf.matul(x_train, w1) + b1h1 = tf.nn.relu(h1)y = tf.matmul(h1, w2) + b2loss_mse = tf.reduce_mean(tf.square(y_train - y))loss_ragularization = []loss_regularization.append(tf.nn.l2_loss(w1))loss_regularization.append(tf.nn.l2_loss(w2))loss_regularization = tf.reduce_sum(loss_regularization)loss = loss_mse + 0.03 * loss_regularization
variables = [w1, b1, w2, b2】
grads = tape.gradient(loss, variables)生成网格覆盖这些点,会对每个坐标生成一个预测值,输出预测值为0.5的连成线,这个线就是红点和蓝点的分界线。

# 导入所需模块
import tensorflow as tf
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd# 读入数据/标签 生成x_train y_train
df = pd.read_csv('dot.csv')
x_data = np.array(df[['x1', 'x2']])
y_data = np.array(df['y_c'])x_train = x_data
y_train = y_data.reshape(-1, 1)Y_c = [['red' if y else 'blue'] for y in y_train]# 转换x的数据类型,否则后面矩阵相乘时会因数据类型问题报错
x_train = tf.cast(x_train, tf.float32)
y_train = tf.cast(y_train, tf.float32)# from_tensor_slices函数切分传入的张量的第一个维度,生成相应的数据集,使输入特征和标签值一一对应
train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(32)# 生成神经网络的参数,输入层为4个神经元,隐藏层为32个神经元,2层隐藏层,输出层为3个神经元
# 用tf.Variable()保证参数可训练
w1 = tf.Variable(tf.random.normal([2, 11]), dtype=tf.float32)
b1 = tf.Variable(tf.constant(0.01, shape=[11]))w2 = tf.Variable(tf.random.normal([11, 1]), dtype=tf.float32)
b2 = tf.Variable(tf.constant(0.01, shape=[1]))lr = 0.005 # 学习率为
epoch = 800 # 循环轮数# 训练部分
for epoch in range(epoch):for step, (x_train, y_train) in enumerate(train_db):with tf.GradientTape() as tape: # 记录梯度信息h1 = tf.matmul(x_train, w1) + b1 # 记录神经网络乘加运算h1 = tf.nn.relu(h1)y = tf.matmul(h1, w2) + b2# 采用均方误差损失函数mse = mean(sum(y-out)^2)loss_mse = tf.reduce_mean(tf.square(y_train - y))# 添加l2正则化loss_regularization = []# tf.nn.l2_loss(w)=sum(w ** 2) / 2loss_regularization.append(tf.nn.l2_loss(w1))loss_regularization.append(tf.nn.l2_loss(w2))# 求和# 例:x=tf.constant(([1,1,1],[1,1,1]))# tf.reduce_sum(x)# >>>6loss_regularization = tf.reduce_sum(loss_regularization)loss = loss_mse + 0.03 * loss_regularization # REGULARIZER = 0.03# 计算loss对各个参数的梯度variables = [w1, b1, w2, b2]grads = tape.gradient(loss, variables)# 实现梯度更新# w1 = w1 - lr * w1_gradw1.assign_sub(lr * grads[0])b1.assign_sub(lr * grads[1])w2.assign_sub(lr * grads[2])b2.assign_sub(lr * grads[3])# 每200个epoch,打印loss信息if epoch % 20 == 0:print('epoch:', epoch, 'loss:', float(loss))# 预测部分
print("*******predict*******")
# xx在-3到3之间以步长为0.01,yy在-3到3之间以步长0.01,生成间隔数值点
xx, yy = np.mgrid[-3:3:.1, -3:3:.1]
# 将xx, yy拉直,并合并配对为二维张量,生成二维坐标点
grid = np.c_[xx.ravel(), yy.ravel()]
grid = tf.cast(grid, tf.float32)
# 将网格坐标点喂入神经网络,进行预测,probs为输出
probs = []
for x_predict in grid:# 使用训练好的参数进行预测h1 = tf.matmul([x_predict], w1) + b1h1 = tf.nn.relu(h1)y = tf.matmul(h1, w2) + b2 # y为预测结果probs.append(y)# 取第0列给x1,取第1列给x2
x1 = x_data[:, 0]
x2 = x_data[:, 1]
# probs的shape调整成xx的样子
probs = np.array(probs).reshape(xx.shape)
plt.scatter(x1, x2, color=np.squeeze(Y_c))
# 把坐标xx yy和对应的值probs放入contour函数,给probs值为0.5的所有点上色 plt.show()后 显示的是红蓝点的分界线
plt.contour(xx, yy, probs, levels=[.5])
plt.show()# 读入红蓝点,画出分割线,包含正则化
# 不清楚的数据,建议print出来查看
 存在过拟合现象,轮廓不够平滑, 使用l2正则化缓解过拟合
存在过拟合现象,轮廓不够平滑, 使用l2正则化缓解过拟合
# 导入所需模块
import tensorflow as tf
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd# 读入数据/标签 生成x_train y_train
df = pd.read_csv('dot.csv')
x_data = np.array(df[['x1', 'x2']])
y_data = np.array(df['y_c'])x_train = x_data
y_train = y_data.reshape(-1, 1)Y_c = [['red' if y else 'blue'] for y in y_train]# 转换x的数据类型,否则后面矩阵相乘时会因数据类型问题报错
x_train = tf.cast(x_train, tf.float32)
y_train = tf.cast(y_train, tf.float32)# from_tensor_slices函数切分传入的张量的第一个维度,生成相应的数据集,使输入特征和标签值一一对应
train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(32)# 生成神经网络的参数,输入层为4个神经元,隐藏层为32个神经元,2层隐藏层,输出层为3个神经元
# 用tf.Variable()保证参数可训练
w1 = tf.Variable(tf.random.normal([2, 11]), dtype=tf.float32)
b1 = tf.Variable(tf.constant(0.01, shape=[11]))w2 = tf.Variable(tf.random.normal([11, 1]), dtype=tf.float32)
b2 = tf.Variable(tf.constant(0.01, shape=[1]))lr = 0.005 # 学习率为
epoch = 800 # 循环轮数# 训练部分
for epoch in range(epoch):for step, (x_train, y_train) in enumerate(train_db):with tf.GradientTape() as tape: # 记录梯度信息h1 = tf.matmul(x_train, w1) + b1 # 记录神经网络乘加运算h1 = tf.nn.relu(h1)y = tf.matmul(h1, w2) + b2# 采用均方误差损失函数mse = mean(sum(y-out)^2)loss_mse = tf.reduce_mean(tf.square(y_train - y))# 添加l2正则化loss_regularization = []# tf.nn.l2_loss(w)=sum(w ** 2) / 2loss_regularization.append(tf.nn.l2_loss(w1))loss_regularization.append(tf.nn.l2_loss(w2))# 求和# 例:x=tf.constant(([1,1,1],[1,1,1]))# tf.reduce_sum(x)# >>>6loss_regularization = tf.reduce_sum(loss_regularization)loss = loss_mse + 0.03 * loss_regularization # REGULARIZER = 0.03# 计算loss对各个参数的梯度variables = [w1, b1, w2, b2]grads = tape.gradient(loss, variables)# 实现梯度更新# w1 = w1 - lr * w1_gradw1.assign_sub(lr * grads[0])b1.assign_sub(lr * grads[1])w2.assign_sub(lr * grads[2])b2.assign_sub(lr * grads[3])# 每200个epoch,打印loss信息if epoch % 20 == 0:print('epoch:', epoch, 'loss:', float(loss))# 预测部分
print("*******predict*******")
# xx在-3到3之间以步长为0.01,yy在-3到3之间以步长0.01,生成间隔数值点
xx, yy = np.mgrid[-3:3:.1, -3:3:.1]
# 将xx, yy拉直,并合并配对为二维张量,生成二维坐标点
grid = np.c_[xx.ravel(), yy.ravel()]
grid = tf.cast(grid, tf.float32)
# 将网格坐标点喂入神经网络,进行预测,probs为输出
probs = []
for x_predict in grid:# 使用训练好的参数进行预测h1 = tf.matmul([x_predict], w1) + b1h1 = tf.nn.relu(h1)y = tf.matmul(h1, w2) + b2 # y为预测结果probs.append(y)# 取第0列给x1,取第1列给x2
x1 = x_data[:, 0]
x2 = x_data[:, 1]
# probs的shape调整成xx的样子
probs = np.array(probs).reshape(xx.shape)
plt.scatter(x1, x2, color=np.squeeze(Y_c))
# 把坐标xx yy和对应的值probs放入contour函数,给probs值为0.5的所有点上色 plt.show()后 显示的是红蓝点的分界线
plt.contour(xx, yy, probs, levels=[.5])
plt.show()# 读入红蓝点,画出分割线,包含正则化
# 不清楚的数据,建议print出来查看

python EmptyDataError No columns to parse from file sites:stackoverflow.com

相关文章:
tensorflow之欠拟合与过拟合,正则化缓解
过拟合泛化性弱 欠拟合解决方法: 增加输入特征项 增加网络参数 减少正则化参数 过拟合的解决方法: 数据清洗 增大训练集 采用正则化 增大正则化参数 正则化缓解过拟合 正则化在损失函数中引入模型复杂度指标,利用给w增加权重,…...

vue实现a-model弹窗拖拽移动
通过自定义拖拽指令实现 实现效果 拖动顶部,可对整个弹窗实施拖拽(如果需要拖动底部、中间内容实现拖拽,把下面的ant-modal-header对应改掉就行) 代码实现 编写自定义指令 新建一个ts / js文件,用ts举例 import V…...

速盾:如何加强网站的安全性
随着互联网的快速发展,网站的安全性变得越来越重要。CDN(内容分发网络)是一种常见的网络加速服务,它可以将网站的静态内容分发到全球各地的服务器上,以提供更快的访问速度。然而,CDN 也存在一些安全风险&am…...

【PyTorch单点知识】自动求导机制的原理与实践
文章目录 0. 前言1. 自动求导的基本原理2. PyTorch中的自动求导2.1 创建计算图2.2 反向传播2.3 反向传播详解2.4 梯度清零2.5 定制自动求导 3. 代码实例:线性回归的自动求导4. 结论 0. 前言 按照国际惯例,首先声明:本文只是我自己学习的理解&…...

【Java】搜索引擎设计:信息搜索怎么避免大海捞针?
一、内容分析 我们准备开发一个针对全网内容的搜索引擎,产品名称为“Bingoo”。 Bingoo的主要技术挑战包括: 针对爬虫获取的海量数据,如何高效地进行数据管理;当用户输入搜索词的时候,如何快速查找包含搜索词的网页…...

【Python】ModuleNotFoundError: No module named ‘distutils.util‘ bug fix
【Python】ModuleNotFoundError: No module named distutils.util bug fix 1. error like this2. how to fix why this error occured , because i remove the origin version python of ubuntu of 20.04. then the system trapped in tty1 , you must make sure the laptop li…...

痉挛性斜颈对生活有哪些影响?
痉挛性斜颈,这个名字听起来可能并不熟悉,但它实际上是一种神经系统疾病,影响着全球数百万人的生活质量。它以一种无法控制的方式,使患者的颈部肌肉发生不自主的收缩,导致头部姿势异常。对于患者来说,痉挛性…...

Javassist 修改 jar 包里的 class 文件
前言 Javassist 是一个用于处理 Java 字节码的类库,可以用以修改 class 文件或 jar 包里的 class 文件。 简单来说我们用Java编写的代码是放在 java 格式的代码文件里,在编译的时候会编译为 class 格式的字节码文件,然后一般所有 class 文件…...

交换机的二三层原理
相同VLAN的交换机交换原理(二层交换原理): 交换机收到数据帧,首先会检查数据帧的VLAN标签和目标MAC,若属于相同VLAN,且该目标MAC在本地MAC表中,则直接根据出接口进行数据转发 不同VLAN的交换机…...

HarmonyOS ArkUi 字符串<展开/收起>功能
效果图: 官方API: ohos.measure (文本计算) 方式一 measure.measureTextSize 跟方式二使用一样,只是API调用不同,可仔细查看官网方式二 API 12 import { display, promptAction } from kit.ArkUI import { MeasureUtils } fr…...

Lianwei 安全周报|2024.07.09
新的一周又开始了,以下是本周「Lianwei周报」,我们总结推荐了本周的政策/标准/指南最新动态、热点资讯和安全事件,保证大家不错过本周的每一个重点! 政策/标准/指南最新动态 01 《数字中国发展报告(2023年)…...

火遍全网的15个Python的实战项目,你该不会还不知道怎么用吧!
经常听到有朋友说,学习编程是一件非常枯燥无味的事情。其实,大家有没有认真想过,可能是我们的学习方法不对? 比方说,你有没有想过,可以通过打游戏来学编程? 今天我想跟大家分享几个Python小游…...

快速使用BRTR公式出具的大模型Prompt提示语
Role:文章模仿大师 Background: 你是一位文章模仿大师,擅长分析文章风格并进行模仿创作。老板常让你学习他人文章后进行模仿创作。 Attention: 请专注在文章模仿任务上,提供高质量的输出。 Profile: Author: 一博Version: 1.0Language: 中文Descri…...

Xilinx FPGA DDR4 接口的 PCB 准则
目录 1. 简介 1.1 FPGA-MIG 与 DDR4 介绍 1.2 DDR4 信号介绍 1.2.1 Clock Signals 1.2.2 Address and Command Signals 1.2.3 Control Signals 1.2.4 Data Signals 1.2.5 Other Signals 2. 通用存储器布线准则 3. Xilinx FPGA-MIG 的 PCB 准则 3.1 引脚配置 3.1.1 …...

神经网络 | Transformer 基本原理
目录 1 为什么使用 Transformer?2 Attention 注意力机制2.1 什么是 Q、K、V 矩阵?2.2 Attention Value 计算流程2.3 Self-Attention 自注意力机制2.3 Multi-Head Attention 多头注意力机制 3 Transformer 模型架构3.1 Positional Encoding 位置编…...

浅析 VO、DTO、DO、PO 的概念
文章目录 I 浅析 VO、DTO、DO、PO1.1 概念1.2 模型1.3 VO与DTO的区别I 浅析 VO、DTO、DO、PO 1.1 概念 VO(View Object) 视图对象,用于展示层,它的作用是把某个指定页面(或组件)的所有数据封装起来。DTO(Data Transfer Object): 数据传输对象,这个概念来源于J2EE的设…...
7.8 CompletableFuture
Future 接口理论知识复习 Future 接口(FutureTask 实现类)定义了操作异步任务执行的一些方法,如获取异步任务的执行结果、取消任务的执行、判断任务是否被取消、判断任务执行是否完毕等。 比如主线程让一个子线程去执行任务,子线…...
iPad锁屏密码忘记怎么办?有什么方法可以解锁?
当我们在日常使用iPad时,偶尔可能会遇到忘记锁屏密码的尴尬情况。这时,不必过于担心,因为有多种方法可以帮助您解锁iPad。接下来,小编将为您详细介绍这些解决方案。 一、使用iCloud的“查找我的iPhone”功能 如果你曾经启用了“查…...
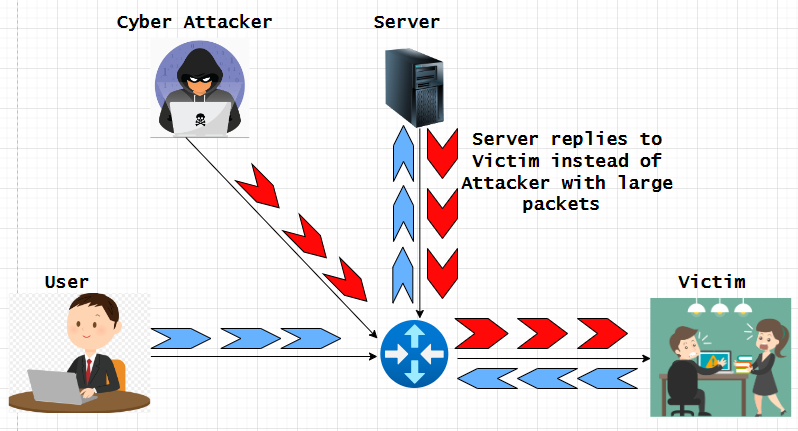
了解并缓解 IP 欺骗攻击
欺骗是黑客用来未经授权访问计算机或网络的一种网络攻击,IP 欺骗是其他欺骗方法中最常见的欺骗类型。通过 IP 欺骗,攻击者可以隐藏 IP 数据包的真实来源,使攻击来源难以知晓。一旦访问网络或设备/主机,网络犯罪分子通常会挖掘其中…...

java LogUtil输出日志打日志的class文件内具体方法和行号
最近琢磨怎么把日志打的更清晰,方便查找问题,又不需要在每个class内都创建Logger对象,还带上不同的颜色做区分,简直不要太爽。利用堆栈的方向顺序拿到日志的class问题。看效果,直接上代码。 1、demo test 2、输出效果…...

学术写作创新突破!2026全流程AI论文工具精选指南
2026 年 AI 论文写作工具已进入全流程闭环 学术合规时代,千笔 AI(综合评分 99 分)中文学术场景标杆;Grammarly Academic与Elicit为英文论文写作首选;按需求匹配度 - 数据可信度 - 成本承受力三维模型选型,…...

Burp Suite证书安装全解:HTTPS抓包失败的根源与跨平台命令行方案
1. 为什么必须亲手安装Burp Suite证书——不是“点一下就完事”的操作很多人第一次在手机或测试设备上配置Burp Suite代理时,会下意识认为:只要把电脑上的Burp监听地址填进Wi-Fi代理设置,再用浏览器访问http://burp,点击那个绿色的…...

【MySQL数据库 | 第一篇】 概述
数据库相关概念: 数据库(Database):数据库是指一组有组织的数据的集合,通过计算机程序进行管理和访问。数据库管理系统:操纵和管理数据库的大型软件SQL:操作关系型数据库的编程语言,定义了一套操作关系型数…...

Owl-Alpha 新手快速上手指南
在处理大规模数据或构建高性能应用时,我们常常会遇到一个棘手的问题:如何在不阻塞主线程的情况下,高效地执行耗时任务?无论是处理图像、解析大型文件,还是进行复杂的数学运算,传统的单线程模式往往会让界面…...

DragonBones与Godot集成:骨骼动画的可编程化实践
1. 为什么在Godot里用DragonBones不是“锦上添花”,而是“绕不开的刚需” 去年上线一个横版动作手游Demo时,美术团队交来一套20个角色、每个角色含8套动画(待机/跑动/跳跃/攻击/受击/死亡/闪避/必杀)的Spine资源。我兴冲冲导入God…...

WebSocket实时通信架构进阶:Room、命名空间与集群部署
WebSocket实时通信架构进阶:Room、命名空间与集群部署 作者:Crown_22 | AI Agent & Hermes Agent 桌面程序开发者 前言 WebSocket已经成为实时应用的标准技术,但大多数教程只停留在"建立连接、发送消息"的基础阶段。在生产环境中,你需要处理Room管理、命名空…...

在Node.js服务中集成Taotoken实现稳定的大模型能力调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js服务中集成Taotoken实现稳定的大模型能力调用 对于需要在后端服务中集成AI功能的Node.js开发者而言,直接对接…...

claude code用户如何迁移到taotoken解决封号与token不足问题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Claude Code 用户如何迁移到 Taotoken 解决封号与 Token 不足问题 应用场景类,针对 Claude Code 用户常遇封号与 Token…...

基于Jetson Nano与JNEEG Shield的脑电信号采集与边缘AI处理实战
1. 项目概述:低成本脑机接口的硬件基石 如果你对脑机接口、生物信号处理或者边缘AI应用感兴趣,但又苦于专业设备动辄数万甚至数十万的高昂门槛,那么JNEEG Shield的出现,可能会为你打开一扇新的大门。这是一个专为NVIDIA Jetson Na…...

DeepSeek-R1代码补全实测报告:37个真实项目、8类编程语言、48小时压测后,我删掉了Copilot
更多请点击: https://intelliparadigm.com 第一章:DeepSeek-R1代码补全实测报告总览 DeepSeek-R1 是深度求索(DeepSeek)推出的开源大语言模型,专为代码理解与生成任务优化。本章聚焦其在主流 IDE 环境中代码补全能力的…...