神经网络 | Transformer 基本原理
目录
- 1 为什么使用 Transformer?
- 2 Attention 注意力机制
- 2.1 什么是 Q、K、V 矩阵?
- 2.2 Attention Value 计算流程
- 2.3 Self-Attention 自注意力机制
- 2.3 Multi-Head Attention 多头注意力机制
- 3 Transformer 模型架构
- 3.1 Positional Encoding 位置编码
- 3.2 模型训练过程
- 3.3 Masked 因果遮罩
- 4 Transformer 的细节
- Add & Norm
前言:
- 本博客仅为初学者提供一个学习思路,如有错误请大佬指出!
- 进实验室后的第一次学习汇报就是 Transformer,后来研究方向变了,就渐渐忘了。不巧最近夏令营面试又被面到了,看来得好好复习一下。
参考博客:
- 史上最小白之 Transformer 详解
- Attention 注意力机制 | 鲁老师
1 为什么使用 Transformer?
Transformer 可以克服 RNN 存在的问题:
- 并行化差: h t h_t ht 依赖 h t − 1 h_{t-1} ht−1
- 长距离依赖问题:梯度消失、梯度爆炸,如: d L d W = d L d y ∗ d y d W \frac{\mathrm{d} L}{\mathrm{d} W} = \frac{\mathrm{d} L}{\mathrm{d} y} * \frac{\mathrm{d} y}{\mathrm{d} W} dWdL=dydL∗dWdy
- 无法处理变长的输入序列

面试官:既然有了 RNN,为什么还需要 LSTM?既然有了 RNN,为什么还需要 Transformer?
2 Attention 注意力机制
在介绍 Transformer 的整体架构(如下图所示)之前,我们先来介绍它所采用的 Attention 注意力机制,后文简称 Attention 机制。要知道原论文的标题就是《Attention Is All You Need》,可见 Attention 机制的地位之高。

Transformer 对 Attention 机制的描述如下图所示:

你可能会好奇上图中的 Q , K , V Q, K, V Q,K,V 矩阵都是什么?为什么要用 Q , K , V Q, K, V Q,K,V 去命名?接下来,我们将进行介绍。
对 Attention 机制的介绍会比较长,但个人感觉其中的原理还蛮有意思的。
2.1 什么是 Q、K、V 矩阵?
Q , K , V Q, K, V Q,K,V 矩阵的全称:
- Q —— Query 查询
- K —— Key 键
- V —— Value 值
是不是一股子查字典的味道扑鼻而来!我们可以通过一个搜索引擎的例子来加深理解:

假设我们想要在 Google 学术中搜索所有 Attention 相关的论文,那么我们的 q u e r y \mathrm{query} query 就应该是 “attention”。搜索引擎会立即根据标题和查询的相似度来给出搜索结果,这里的标题可以理解为关键字 k e y 1 , k e y 2 , k e y 3 \mathrm{key_1, key_2, key_3} key1,key2,key3。也就是说,搜索引擎根据 q u e r y \mathrm{query} query 与各个 k e y \mathrm{key} key 的相似度的高低,按序给出若干搜索结果 v a l u e 1 , v a l u e 2 , v a l u e 3 \mathrm{value_1, value_2, value_3} value1,value2,value3。最终的搜索结果可以看作 v a l u e 1 , v a l u e 2 , v a l u e 3 \mathrm{value_1, value_2, value_3} value1,value2,value3 的按权求和,其中的权重就是 q u e r y \mathrm{query} query 与各个 k e y \mathrm{key} key 的相似程度,即按不同的比例从各个论文中都吸取了一些内容。
2.2 Attention Value 计算流程
在上一节中,我们已经用搜索引擎的例子讲解了 Q , K , V Q, K, V Q,K,V 矩阵的含义。在本节中,我们将继续介绍 Attention 机制中的 Q , K , V Q, K, V Q,K,V 矩阵是如何被使用的。详细的计算流程如下图所示:

阶段 1:通过 F ( Q , K ) F(Q,K) F(Q,K) 公式来计算 Q Q Q 和各个 K e y Key Key 的相似度,得到分数 s 1 , s 2 , s 3 , s 4 s_1,s_2,s_3,s_4 s1,s2,s3,s4。针对 F ( Q , K ) F(Q,K) F(Q,K) 的具体形式,一般采用的是向量点乘的方式。这是源于向量点乘的几何意义,即向量点乘的结果越大表明两个向量越相似。
阶段 2:使用类 S o f t M a x ( ) \mathrm{SoftMax()} SoftMax() 函数对分数 s 1 , s 2 , s 3 , s 4 s_1,s_2,s_3,s_4 s1,s2,s3,s4 进行归一化:
a i = S o f t M a x ( s i ) = e a i ∑ j = 1 n e a j a_i=SoftMax(s_i)=\frac{e^{a_i}}{\textstyle \sum_{j=1}^{n}e^{a_j}} ai=SoftMax(si)=∑j=1neajeai
得到注意力分数 a 1 , a 2 , a 3 , a 4 a_1,a_2,a_3,a_4 a1,a2,a3,a4。个人理解,就是把分数 s s s 的值缩放到 [ 0 , 1 ] [0, 1] [0,1] 区间内,并使得 ∑ i a i = 1 \textstyle \sum_{i}^{} a_i=1 ∑iai=1。
阶段 3:令注意力分数 a 1 , a 2 , a 3 , a 4 a_1,a_2,a_3,a_4 a1,a2,a3,a4 为权重,对各个 V a l u e Value Value 进行加权求和,得到最终的 Attention Value。
图中的 s 代表 score,a 代表 attention score;类 S o f t M a x ( ) \mathrm{SoftMax()} SoftMax() 是因为 Transformer 并不是直接使用的原始 S o f t M a x ( ) \mathrm{SoftMax()} SoftMax() 函数,后文会介绍;这图的配色是真丑啊,我无能为力 😇
2.3 Self-Attention 自注意力机制
实际上在 Transformer 的编码器中,采用的是 Self-Attention 自注意力机制,后文简称 Self-Attention 机制。
区别于上一节介绍的 Attention 机制,Self-Attention 机制进一步要求 Q = K = V Q=K=V Q=K=V。也就是说,针对一个矩阵,让它计算自己与自己的相似度,并且对自己的值进行加权求和。这就是 “自注意力” 一词的由来。
假设我们需要处理 “never give up” 这个短语,那么先要通过词嵌入将字符串转换为词向量矩阵 X X X(否则计算机无法处理),然后再令 Q = K = V = X Q=K=V=X Q=K=V=X 即可。之后,按照上一节介绍的计算流程进行处理,如下图所示:

由于 Transformer 最开始做的是机器翻译,属于 NLP 领域,所以本文举的例子都是字符串。
现在,让我们回过头来看 Transformer 原文中的图:
其中 Q , K , V Q,K,V Q,K,V 矩阵的含义已知, M a t M u l \mathrm{MatMul} MatMul 无非就是矩阵乘法, S o f t M a x \mathrm{SoftMax} SoftMax 的含义已知。
注意一
实际操作中 Q , K , V Q,K,V Q,K,V 并不直接等于 X X X,而是:
Q = X W Q , K = X W K , V = X W V Q=XW^Q, K=XW^K, V=XW^V Q=XWQ,K=XWK,V=XWV
其中 W Q , W K , W V W^Q, W^K, W^V WQ,WK,WV 是可以训练的参数矩阵。Transformer 之所以不直接使用 X X X,而是使用通过矩阵乘法生成的三个矩阵,是因为使用三个可训练的参数矩阵,可以增强模型的拟合能力。
上图中没有画出也没有使用该操作,后文的 Multi-Head Attention 多头注意力机制才画了并使用了该操作。
注意二
上图中的 S c a l e \mathrm{Scale} Scale 缩放操作是指:
S o f t M a x ( Q K T d k ) V SoftMax(\frac{QK^T}{\sqrt{d_k}})V SoftMax(dkQKT)V
其中 d k d_k dk 是指 K K K 矩阵的维度。由于 d k d_k dk 越大, Q K T QK^T QKT 运算结果的方差越大,因此通过 S c a l e \mathrm{Scale} Scale 缩放操作让方差变小,从而使训练时的梯度更新更稳定。
上图中的 M a s k ( o p t . ) \mathrm{Mask(opt.)} Mask(opt.) 操作是指因果遮罩,我们后面再讲。标明 ( o p t . ) \mathrm{(opt.)} (opt.) 是因为在编码器中不使用该操作,在解码器中要使用该操作,所以这个操作是可选的而非必须的。
2.3 Multi-Head Attention 多头注意力机制
根据前文的介绍,我们已经一步步地从 Attention 机制走到了 Self-Attention 机制,但这还不是 Transformer 实际采用的注意力机制。Transformer 在 Self-Attention 机制的基础上,进一步得到了 Multi-Head Attention 多头注意力机制,后文简称 Multi-Head Attention 机制。如下图所示:

其实这个图一点也不复杂,紫色部分的 Scaled Dot-Product Attention 就是我们上一节讲的 Self-Attention 机制,而灰色部分的 Linear 就是我们上一节讲的注意一,即为 Q , K , V Q,K,V Q,K,V 各自乘上一个参数矩阵。区别在于:在 Multi-Head Attention 机制中, Q , K , V Q,K,V Q,K,V 各自将乘上多个参数矩阵。我们接下来将介绍这样做的好处。
多头是什么?
我们假设 head 为 2 即 h = 2 h=2 h=2,也就是把原来一个参数矩阵 W W W,劈开为两个参数矩阵 W 1 , W 2 W_1, W_2 W1,W2,如下图所示:

其中词向量矩阵的维度为 3 × d m o d e l 3\times d_{model} 3×dmodel,两个参数矩阵合起来的维度为 d m o d e l × d m o d e l d_{model}\times d_{model} dmodel×dmodel,单个参数矩阵的维度为 d m o d e l × d q d_{model}\times d_{q} dmodel×dq,其中 h × d q = d m o d e l h\times d_{q} = d_{model} h×dq=dmodel,如右上角虚线框所示(注意:由于我这里拿的是 W Q W^Q WQ 举例,因此维度写的是 d q d_{q} dq)。可以看出,Multi-Head Attention 机制就是把 1 1 1 个大小为 d m o d e l × d m o d e l d_{model}\times d_{model} dmodel×dmodel 的参数矩阵,劈开为了 h h h 个大小为 d m o d e l × d q d_{model}\times d_{q} dmodel×dq 的参数矩阵。
针对 X X X 和 W 1 , W 2 W_1,W_2 W1,W2 之间的矩阵乘法:根据矩阵乘法的原理可知, X X X 分别和 W 1 , W 2 W_1,W_2 W1,W2 相乘与 X X X 和 W 1 W 2 W_1W_2 W1W2 相乘的结果是一样的。因此为了简化操作,我们可以先不将 W 1 W_1 W1 和 W 2 W_2 W2 劈开,上图也体现了这一点。
下图展示了上图中 S o f t M a x \mathrm{SoftMax} SoftMax 的具体过程:

在 S o f t M a x \mathrm{SoftMax} SoftMax 这一步,我们必须将 Q 1 Q 2 Q_1Q_2 Q1Q2、 K 1 K 2 K_1K_2 K1K2 劈开,然后让 Q 1 Q_1 Q1 去乘 K 1 T K^T_1 K1T,让 Q 2 Q_2 Q2 去乘 K 2 T K^T_2 K2T。相应地,得到 h = 2 h=2 h=2 个权值矩阵。最后,再拿 h = 2 h=2 h=2 个权值矩阵分别去乘 V 1 V_1 V1 和 V 2 V_2 V2 矩阵,得到最终的 Z 1 Z_1 Z1 和 Z 2 Z_2 Z2 矩阵。
个人思考:只让 Q 1 Q_1 Q1 去乘 K 1 T K^T_1 K1T,只让 Q 2 Q_2 Q2 去乘 K 2 T K^T_2 K2T,是否属于一种局域而非全局的自注意力?
为什么使用多头?

如果 h = 1 h= 1 h=1,那么最终可能得到的就是一个各个位置只集中于自身位置的注意力权 矩阵;如果 h = 2 h= 2 h=2,那么就还可能得到另外一个注意力权重稍微分配合理的权值矩阵; h = 3 h= 3 h=3 同理。因此,作者提出多头这一做法,用于克服「模型在对当前位置的信息进行编码时,过度将注意力集中于自身的位置」的问题。
至此,关于注意力机制的介绍结束 🥳
3 Transformer 模型架构
我们在前文已经介绍完了 Transformer 的重头戏部分,下面我们从左到右、从下到上来介绍 Transformer 的整体架构:
3.1 Positional Encoding 位置编码
为什么使用位置编码?
- ① 对于任何一门语言,单词在句子中的位置以及排列顺序是非常重要的,它们不仅是一个句子的语法结构的组成部分,更是表达语义的重要概念。一个单词在句子中的位置或者排列顺序不同,可能会导致整个句子的意思发生偏差。
- ② Transformer 抛弃了 RNN、CNN 作为序列学习的基本模型,而是完全采用 Attention 机制取而代之,从而导致词序信息丢失,模型没有办法知道每个单词在句子中的相对位置信息和绝对位置信息。
RNN 自带循环结构,因此天然能够捕捉词序信息。
如何进行位置编码?

其实就是让词向量 + + + 位置编码,位置编码的计算公式如下:
P E ( p o s , 2 i ) = sin ( p o s 1000 0 2 i / d m o d e l ) P E ( p o s , 2 i + 1 ) = cos ( p o s 1000 0 2 i / d m o d e l ) \begin{alignat}{2} PE(pos,2i) &= \sin (\frac{pos}{10000^{2i/d_{model}}}) \\ PE(pos,2i+1) &= \cos (\frac{pos}{10000^{2i/d_{model}}}) \end{alignat} PE(pos,2i)PE(pos,2i+1)=sin(100002i/dmodelpos)=cos(100002i/dmodelpos)
其中 p o s pos pos 表示单词在句子中的绝对位置,比如:“有” 在 “我有一只猫” 中的 p o s pos pos 为 1 1 1,假设从 0 0 0 开始计数。 d m o d e l d_{model} dmodel 表示每个词向量的维度, i i i 表示一个词向量中的第 i i i 维,而 2 i 2i 2i 表示这是一个偶数维度, 2 i + 1 2i+1 2i+1 表示这是一个奇数维度。也就是说,偶数维度根据公式 (1) 来计算位置编码,奇数维度根据公式 (2) 来计算位置编码。
Q:为什么是让位置编码和词向量相加,而不是拼接?
A:相加或拼接都是可以的。只是因为词向量本身已经有 512 512 512 维了,如果再拼接一个 512 512 512 维的位置向量变为 1024 1024 1024 维,会导致训练速度下降。
3.2 模型训练过程
Transformer 的训练过程如下图所示:

对于 “我” 字,由于上一轮没有预测结果,因此模型纯靠输出的编码矩阵去预测 “我” 字的翻译结果 “I”;对于 “有” 字,由于上一轮的预测结果是 “I”,因此模型依靠输出的编码矩阵和 “I” 去预测 “有” 字的翻译结果 “have”;以此类推。
但在实际的训练过程中,通常采用了一种名为 t e a c h e r - f o r c i n g \mathrm{teacher\text{-}forcing} teacher-forcing 的训练方式。具体是指,不使用上一次的输出作为下一次的输入,而是直接使用上一次输出对应的标准答案(ground truth)作为下一次的输入,如下图所示:

这又引出了一个新问题:当我们翻译到 “有” 的时候,我们应该只能知道上一轮的翻译结果 “I”,而不应该知道后面的翻译结果 “have a cat”。因此 Transformer 采用了因果遮罩机制,对解码器的输入矩阵进行了处理。
个人理解:你可以把这个翻译过程理解为同声传译,只要讲话人不说出下一个字,我们就不知道该如何翻译。
3.3 Masked 因果遮罩
解码器中的 Masked Multi-Head Attention 用的就是因果遮罩。
这是为了让前面位置的信息无法关注到后面位置的信息,比如:翻译 “我” 的时候,无法关注到 “有一只猫” 的翻译结果 “have a cat”,但是它能看到自己的翻译结果 “I”;翻译 “有” 的时候,无法关注到 “一只猫” 的翻译结果 “a cat”,但是它能看到前面的翻译结果以及自己的翻译结果 “I have”。具体操作如下图所示:

其中让 Q K T QK^T QKT 右上角的元素为 − ∞ -\infty −∞,经过 S o f t M a x \mathrm{SoftMax} SoftMax 后变为 0 0 0,即权重为 0 0 0,从而不会被关注到。
4 Transformer 的细节
Add & Norm
两次面试都有被问到这个问题。
什么是 Add?
下图中蓝色虚线指向的就是 A d d \mathrm{Add} Add 操作:

也就是在 Multi-Head Attention 的输出 Z Z Z 的基础上加上原始输入 X X X:
X + Z = X + M u l t i - H e a d A t t e n t i o n ( X ) X+Z=X+\mathrm{Multi\text{-} Head\ Attention}(X) X+Z=X+Multi-Head Attention(X)
简单理解,为了防止注意力机制让模型学得更烂了,所以还是把原始输入也带上吧 😇
为什么使用 Add?
深度神经网络在训练过程中可能出现退化现象。退化指的是随着网络层数的增加,损失函数的值先减小后增大,导致网络性能不再提升甚至下降。这种现象发生的原因在于,增加的层数并没有有效地增强网络的表达能力,反而可能引入了不必要的复杂性。
考虑一个神经网络,其实际最佳层数可能是 18 18 18 层。然而,我们可能基于理论假设认为更深层的网络会更好,因此可能会设计一个 32 32 32 层的网络。在这样的网络中,后 14 14 14 层实际上并不增加任何有用的表达能力,反而可能干扰到网络的性能。为了避免这种情况,我们需要确保这额外的 14 14 14 层能够实现恒等映射:
F ( X ) = X F(X)=X F(X)=X
即其输出恰好等于输入。然而,神经网络的参数是通过训练获得的,而确保这些参数能够精确地实现 F ( X ) = X F(X)=X F(X)=X 的恒等映射是极具挑战性的。为了解决这一问题,大神们提出了残差神经网络 ResNet 以克服神经网络退化的挑战。
说来 ResNet 也是一个很经典的网络了,但我居然还没有去学 😇
什么是 Norm?
神经网络训练前,通常会对输入数据进行归一化处理,这一步骤旨在实现两个目标:
- 一是提升训练速度;
- 二是增强训练过程的稳定性。
相关文章:
神经网络 | Transformer 基本原理
目录 1 为什么使用 Transformer?2 Attention 注意力机制2.1 什么是 Q、K、V 矩阵?2.2 Attention Value 计算流程2.3 Self-Attention 自注意力机制2.3 Multi-Head Attention 多头注意力机制 3 Transformer 模型架构3.1 Positional Encoding 位置编…...

浅析 VO、DTO、DO、PO 的概念
文章目录 I 浅析 VO、DTO、DO、PO1.1 概念1.2 模型1.3 VO与DTO的区别I 浅析 VO、DTO、DO、PO 1.1 概念 VO(View Object) 视图对象,用于展示层,它的作用是把某个指定页面(或组件)的所有数据封装起来。DTO(Data Transfer Object): 数据传输对象,这个概念来源于J2EE的设…...
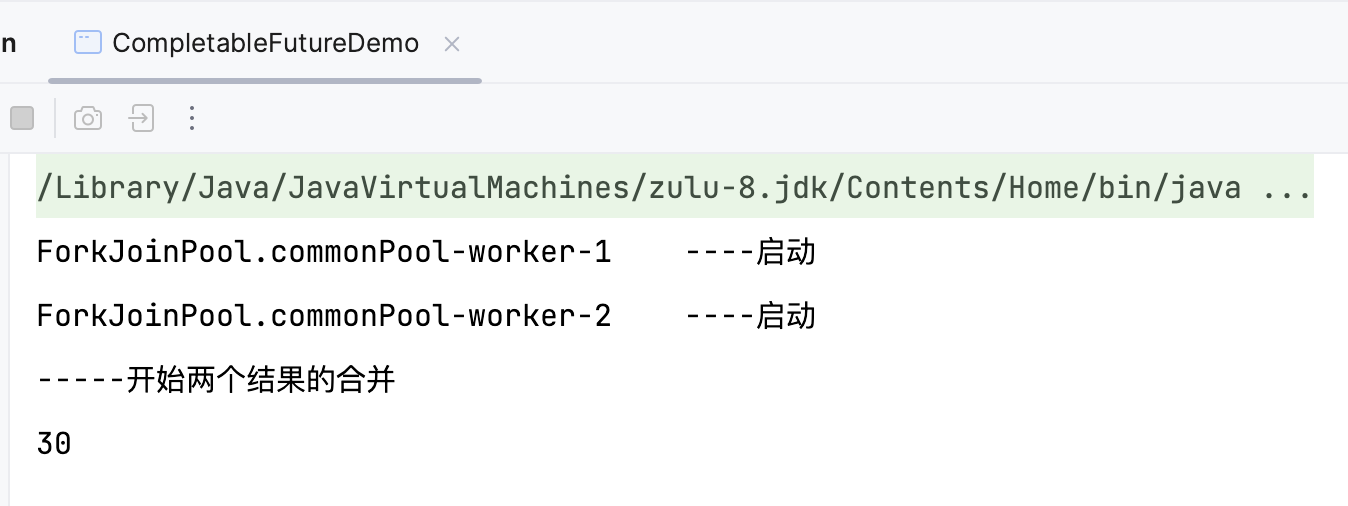
7.8 CompletableFuture
Future 接口理论知识复习 Future 接口(FutureTask 实现类)定义了操作异步任务执行的一些方法,如获取异步任务的执行结果、取消任务的执行、判断任务是否被取消、判断任务执行是否完毕等。 比如主线程让一个子线程去执行任务,子线…...
iPad锁屏密码忘记怎么办?有什么方法可以解锁?
当我们在日常使用iPad时,偶尔可能会遇到忘记锁屏密码的尴尬情况。这时,不必过于担心,因为有多种方法可以帮助您解锁iPad。接下来,小编将为您详细介绍这些解决方案。 一、使用iCloud的“查找我的iPhone”功能 如果你曾经启用了“查…...
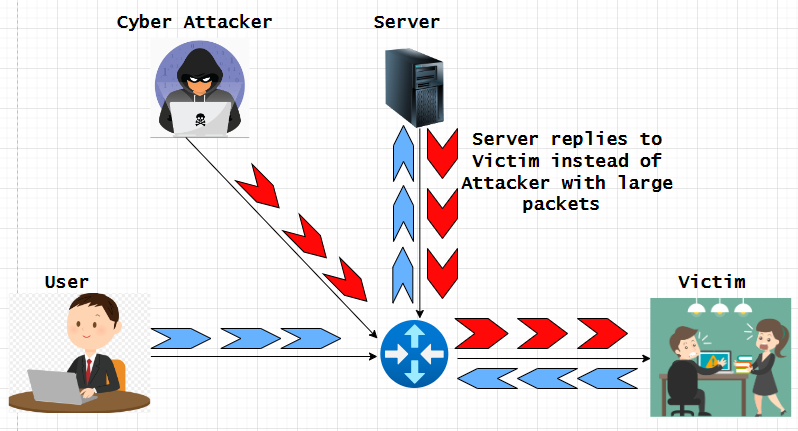
了解并缓解 IP 欺骗攻击
欺骗是黑客用来未经授权访问计算机或网络的一种网络攻击,IP 欺骗是其他欺骗方法中最常见的欺骗类型。通过 IP 欺骗,攻击者可以隐藏 IP 数据包的真实来源,使攻击来源难以知晓。一旦访问网络或设备/主机,网络犯罪分子通常会挖掘其中…...

java LogUtil输出日志打日志的class文件内具体方法和行号
最近琢磨怎么把日志打的更清晰,方便查找问题,又不需要在每个class内都创建Logger对象,还带上不同的颜色做区分,简直不要太爽。利用堆栈的方向顺序拿到日志的class问题。看效果,直接上代码。 1、demo test 2、输出效果…...

02. Hibernate 初体验之持久化对象
1. 前言 本节课程让我们一起体验 Hibernate 的魅力!编写第一个基于 Hibernate 的实例程序。 在本节课程中,你将学到 : Hibernate 的版本发展史;持久化对象的特点。 为了更好地讲解这个内容,这个初体验案例分上下 2…...
MySQL超详细学习教程,2023年硬核学习路线
文章目录 前言1. 数据库的相关概念1.1 数据1.2 数据库1.3 数据库管理系统1.4 数据库系统1.5 SQL 2. MySQL数据库2.1 MySQL安装2.2 MySQL配置2.2.1 添加环境变量2.2.2 新建配置文件2.2.3 初始化MySQL2.2.4 注册MySQL服务2.2.5 启动MySQL服务 2.3 MySQL登录和退出2.4 MySQL卸载2.…...

初识SpringBoot
1.Maven Maven是⼀个项⽬管理⼯具, 通过pom.xml⽂件的配置获取jar包,⽽不⽤⼿动去添加jar包 主要功能 项⽬构建管理依赖 构建Maven项目 1.1项目构建 Maven 提供了标准的,跨平台(Linux, Windows, MacOS等)的⾃动化项⽬构建⽅式 当我们开发了⼀个项⽬之后, 代…...

Qt之元对象系统
Qt的元对象系统提供了信号和槽机制(用于对象间的通信)、运行时类型信息和动态属性系统。 元对象系统基于三个要素: 1、QObject类为那些可以利用元对象系统的对象提供了一个基类。 2、在类声明中使用Q_OBJECT宏用于启用元对象特性,…...

Provider(1)- 什么是AudioBufferProvider
什么是AudioBufferProvider? 顾名思义,Audio音频数据缓冲提供,就是提供音频数据的缓冲类,而且这个AudioBufferProvider派生出许多子类,每个子类有不同的用途,至关重要;那它在Android哪个地方使…...

加密与安全_密钥体系的三个核心目标之完整性解决方案
文章目录 Pre机密性完整性1. 哈希函数(Hash Function)定义特征常见算法应用散列函数常用场景散列函数无法解决的问题 2. 消息认证码(MAC)概述定义常见算法工作原理如何使用 MACMAC 的问题 不可否认性数字签名(Digital …...

【C++】:继承[下篇](友元静态成员菱形继承菱形虚拟继承)
目录 一,继承与友元二,继承与静态成员三,复杂的菱形继承及菱形虚拟继承四,继承的总结和反思 点击跳转上一篇文章: 【C】:继承(定义&&赋值兼容转换&&作用域&&派生类的默认成员函数…...

昇思25天学习打卡营第13天|基于MindNLP+MusicGen生成自己的个性化音乐
关于MindNLP MindNLP是一个依赖昇思MindSpore向上生长的NLP(自然语言处理)框架,旨在利用MindSpore的优势特性,如函数式融合编程、动态图功能、数据处理引擎等,致力于提供高效、易用的NLP解决方案。通过全面拥抱Huggin…...

nigix的下载使用
1、官网:https://nginx.org/en/download.html 双击打开 nginx的默认端口是80 配置文件 默认访问页面 在目录下新建pages,放入图片 在浏览器中输入地址进行访问 可以在电脑中配置本地域名 Windows设置本地DNS域名解析hosts文件配置 文件地址…...
)
nginx+lua 实现URL重定向(根据传入的参数条件)
程序版本说明 程序版本URLnginx1.27.0https://nginx.org/download/nginx-1.27.0.tar.gzngx_devel_kitv0.3.3https://github.com/simpl/ngx_devel_kit/archive/v0.3.3.tar.gzluajitv2.1https://github.com/openresty/luajit2/archive/refs/tags/v2.1-20240626.tar.gzlua-nginx-m…...

算法学习笔记(8.4)-完全背包问题
目录 Question: 图例: 动态规划思路 2 代码实现: 3 空间优化: 代码实现: 下面是0-1背包和完全背包具体的例题: 代码实现: 图例: 空间优化代码示例 Question: 给定n个物品…...
陈述)
C++catch (...)陈述
catch (...)陈述 例外处理可以有多个catch,如果catch后的小括弧里面放...,就表示不限型态种类的任何例外。 举例如下 #include <iostream>int main() {int i -1;try {if (i > 0) {throw 0;}throw 2.0;}catch (const int e) {std::cout <…...

Redis实践
Redis实践 使用复杂度高的命令 如果在使用Redis时,发现访问延迟突然增大,如何进行排查? 首先,第一步,建议你去查看一下Redis的慢日志。Redis提供了慢日志命令的统计功能,我们通过以下设置,就…...

【Lora模型推荐】Stable Diffusion创作具有玉石翡翠质感的图标设计
站长素材AI教程是站长之家旗下AI绘图教程平台 海量AI免费教程,每日更新干货内容 想要深入学习更多AI绘图教程,请访问站长素材AI教程网: AI教程_深度学习入门指南 - 站长素材 (chinaz.com) logo版权归各公司所有!本笔记仅供AIGC…...

智慧无人机巡检-无人机可见光红外数据集 无人机多模态检测数据集 红外与可见光检测数据集
智慧无人机巡检-无人机可见光红外数据集,已完成标注,可导出各种常用数据集,yolo,voc,coco等格式。可见光33000张,红外16100张,目标一张一个 无人机可见光红外目标数据集项目详细信息数据集名称无…...
)
Windows10下V-REP教育版安装保姆级教程(附百度网盘资源与避坑点)
Windows10系统V-REP教育版完整安装指南:从下载到实战避坑在机器人仿真和自动化控制领域,V-REP(现更名为CoppeliaSim)作为一款功能强大的跨平台机器人仿真软件,已经成为众多工科学生和研究人员的首选工具。特别是其教育…...

人类防伪指南:为什么你越写错字,HR越信你是真人?
前言各位码农、算法侠、CtrlC/V十级学者请注意:你有没有过这样的经历?辛辛苦苦肝了一晚上文档,逻辑严密、语法丝滑、连Markdown都对齐得像军训方阵,结果老板幽幽来一句:“这真是你自己写的?”那一刻&#x…...
)
Postgresql基础实践教程(八)
⭐️⭐️⭐️⭐️⭐️ 完整数据详见 练习数据免费 ⭐️⭐️⭐️⭐️⭐️ 六十九、查找会员ID 27的向上推荐链 问题 查找会员ID 27的向上推荐链:即推荐该会员的人,以及推荐那个人的人,依此类推。返回会员ID、名字和姓氏。按会员ID降序排列。…...

WarcraftHelper终极指南:魔兽争霸3兼容性问题一站式解决方案
WarcraftHelper终极指南:魔兽争霸3兼容性问题一站式解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为《魔兽争霸3》在现代电…...

InVideo插件深度解析:如何在Unreal Engine中实现高效视频流播放与录制
InVideo插件深度解析:如何在Unreal Engine中实现高效视频流播放与录制 【免费下载链接】InVideo 基于UE4实现的rtsp的视频播放插件 项目地址: https://gitcode.com/gh_mirrors/in/InVideo InVideo是一个基于Unreal Engine 5开发的RTSP视频播放插件࿰…...
)
紧急预警:DeepSeek代码生成中未公开的3类逻辑漂移现象(附自动化检测脚本+修复模板)
更多请点击: https://intelliparadigm.com 第一章:紧急预警:DeepSeek代码生成中未公开的3类逻辑漂移现象(附自动化检测脚本修复模板) 近期在多轮生产级代码审计中发现,DeepSeek-R1(v2.5&#x…...

Metabase:零代码 BI 数据可视化工具,自建数据看板
Metabase:零代码 BI 数据可视化工具,自建数据看板 在数据驱动决策的时代,能快速看到业务数据的变化趋势至关重要。然而,专业 BI 工具(如 Tableau、Power BI)价格昂贵,而让每个业务同学都学 SQL …...

昇腾CANN elec-ops-simulation 实战:电力系统仿真——潮流计算与暂态稳定分析在 NPU 上的加速
电力系统仿真:500 节点电网的牛顿-拉夫逊潮流计算 → 解 10001000 稀疏雅可比矩阵(每迭代 1 次矩阵求逆)→ CPU 迭代 15 次 2.4s。实时调度要求 < 100ms → NPU 加速:雅可比矩阵求解用 Cube 单元做批量小矩阵 LU 分解 → 每迭…...

Godot 2D随机地图三大静默故障:黑屏、穿墙、寻路失败的根源与修复
1. 为什么刚上手Godot做2D随机地图就总卡在“生成出来是黑的”“角色穿墙”“房间连不通”这三件事上?如果你是刚从Unity或GameMaker转来Godot,或者第一次用GDScript写程序逻辑的新手,大概率已经在2D随机地图生成这个环节反复摔过跟头——不是…...