Count数据转换为TPM数据方法整理-常规方法、DGEobj.utils和IOBR包
在正式分析之前,对于数据的处理是至关重要的,这种重要性是体现在很多方面,其中有一点是要求分析者采用正确的数据类型。
对于芯片数据,原始数据进行log2处理之后可以进行很多常见的分析,比如差异分析、热图、箱线图、PCA分析、生存分析、模型构建,聚类分析和相关性分析等。
对于转录组数据,在上述的常见分析中只有差异分析时需要采用count值,其他的分析是需要采用log2后的cpm,tpm,fpkm,rpkm数据。
除了上述的常规分析,在使用不同R包进行分析之前务必浏览一下输入数据的要求。
那么芯片数据还好说,毕竟后续进行log2处理后就可以做很多分析。但是转录组数据的可选项就比较多了。
但目前常用的只有tpm和cpm

count数据转换为cpm数据非常简单
# exprSet是count表达矩阵
# 一句代码搞定
exprSet = log2(edgeR::cpm(exprSet)+1)
比较难的就是count数据转换为tpm数据,因此搬运了常规的流程和R包的方法,做个对比
首先要去获取基因长度文件,因为后续需要用这个数据去矫正基因长度。
网址:https://gdc.cancer.gov/about-data/gdc-data-processing/gdc-reference-files
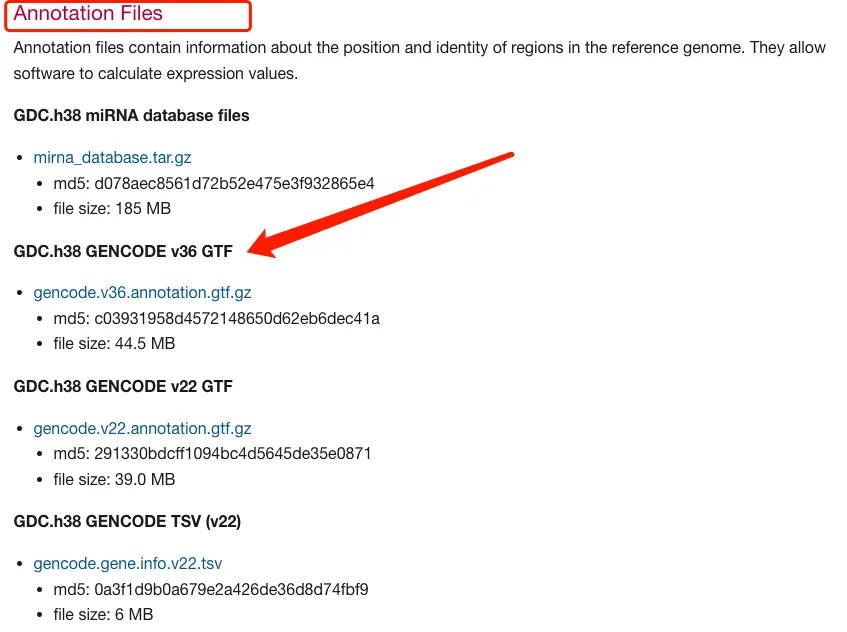
方法一:常规方法-来自生信技能树
1、获取gencode.v36.annotation并处理
if(!require(GenomicFeatures))BiocManager::install("GenomicFeatures")
library(GenomicFeatures)
txdb <- makeTxDbFromGFF("gencode.v36.annotation.gtf.gz",format="gtf")
# 获取每个基因id的外显子数据
exons.list.per.gene <- exonsBy(txdb,by="gene")
# 对于每个基因,将所有外显子减少成一组非重叠外显子,计算它们的长度(宽度)并求和
exonic.gene.sizes <- sum(width(GenomicRanges::reduce(exons.list.per.gene)))
# 得到geneid和长度数据
gfe <- data.frame(gene_id=names(exonic.gene.sizes),length=exonic.gene.sizes)
head(gfe)[1:5,1:2]
# gene_id length
# ENSG00000000003.15 ENSG00000000003.15 4536
# ENSG00000000005.6 ENSG00000000005.6 1476
# ENSG00000000419.13 ENSG00000000419.13 1207
# ENSG00000000457.14 ENSG00000000457.14 6883
# ENSG00000000460.17 ENSG00000000460.17 5970
save(gfe,file = "gfe.Rdata")
2、使用TCGA-HNSC数据
load("hnsc_exp.Rdata")
head(hnsc)[1:3,1:3]
# TCGA-UF-A7JF-01A-11R-A34R-07 TCGA-CN-4725-01A-01R-1436-07 TCGA-D6-6827-01A-11R-1915-07
# ENSG00000000003.15 2090 1680 5433
# ENSG00000000005.6 0 0 0
# ENSG00000000419.13 2098 3872 2240
identical(rownames(hnsc),rownames(gfe))
#[1] TRUE 行名是能够对上的
使用了TCGA-HNSC中的count数据,检测了一下count数据和下载的基因信息的顺序是一致的。
3、曾老师写的代码进行count/tpm转化
load("gfe.Rdata")
#提取基因长度列
effLen = gfe$length
#转化
Counts2TPM <- function(counts, effLen){rate <- log(counts) - log(effLen)denom <- log(sum(exp(rate)))exp(rate - denom + log(1e6))
}
hnsc_tpm_raw <- apply(hnsc, 2, Counts2TPM, effLen = effLen)
head(hnsc_tpm_raw)[1:3,1:3]
# TCGA-UF-A7JF-01A-11R-A34R-07 TCGA-CN-4725-01A-01R-1436-07 TCGA-D6-6827-01A-11R-1915-07
# ENSG00000000003.15 31.13713 15.74248 72.37614
# ENSG00000000005.6 0.00000 0.00000 0.00000
# ENSG00000000419.13 117.46366 136.35307 112.14231
4、加载既往处理好的数据进行对比
load("hnsc_tpm.Rdata")
head(hnsc_tpm)[1:3,1:3]
# TCGA-UF-A7JF-01A-11R-A34R-07 TCGA-CN-4725-01A-01R-1436-07 TCGA-D6-6827-01A-11R-1915-07
# ENSG00000000003.15 31.13713 15.74248 72.37614
# ENSG00000000005.6 0.00000 0.00000 0.00000
# ENSG00000000419.13 117.46366 136.35307 112.14231
结果是一致的
方法二:R包 DGEobj.utils
load("gfe.Rdata")
#提取上面处理好的基因长度列
effLen = gfe$length
library(DGEobj.utils)
CC_res <- convertCounts(exp,unit = "TPM", # CPM、FPKM、FPK 或 TPMgeneLength = effLen, #这里还是需要下在基因长度数据log = FALSE, #默认为False,设为TRUE时返回Log2值normalize = "none", #默认为none,调用edgeR的calcNormFactors()进行标准化prior.count = NULL #为避免取0的对数,对每个观测值添加平均count。仅当 log = TRUE 时使用,
)
head(CC_res)[1:3,1:3]
# TCGA-UF-A7JF-01A-11R-A34R-07 TCGA-CN-4725-01A-01R-1436-07 TCGA-D6-6827-01A-11R-1915-07
#ENSG00000000003.15 31.13713 15.74248 72.37614
#ENSG00000000005.6 0.00000 0.00000 0.00000
#ENSG00000000419.13 117.46366 136.35307 112.14231
与前面得到的分析结果是一致的。
需要下载基因长度数据,但是前期处理完之后后面可以很方便的转化为各种想要的格式(CPM、FPKM、FPK 或 TPM)。
方法三:R包 IOBR
load("hnsc_exp.Rdata")
exp <- hnsc
library(IOBR)
exp_tpm <- count2tpm(exp, #表达矩阵, 行为基因idType = "Ensembl", #"Ensembl" "ENTREZ","SYMBOL"
)
head(exp_tpm)[1:3,1:3]
# TCGA-UF-A7JF-01A-11R-A34R-07 TCGA-CN-4725-01A-01R-1436-07 TCGA-D6-6827-01A-11R-1915-07
# TSPAN6 31.89988 16.16771 73.85059
# TNMD 0.00000 0.00000 0.00000
# DPM1 15.65888 18.22162 14.88931
# 可以看到这个函数还自动把gene_id给转换成了symbol# 为了更好的对比,我们也把hnsc_tpm_raw中的gene_id转换成symbol
# 使用小洁老师的trans_exp_new函数
library(tinyarray)
a <- trans_exp_new(hnsc_tpm_raw)
head(a)[1:3,1:3]
# TCGA-UF-A7JF-01A-11R-A34R-07 TCGA-CN-4725-01A-01R-1436-07 TCGA-D6-6827-01A-11R-1915-07
# DDX11L1 0.000000 0.0000000 0.000000
# WASH7P 1.150477 0.8180029 2.191641
# MIR6859-1 0.993794 0.0000000 4.443138# 排个序再看一下
p <- identical(rownames(a),rownames(exp_tpm));p
if(!p) {s = intersect(rownames(a),rownames(exp_tpm))a = a[s,]exp_tpm = exp_tpm[s,]
}
head(a)[1:3,1:3]
# TCGA-UF-A7JF-01A-11R-A34R-07 TCGA-CN-4725-01A-01R-1436-07 TCGA-D6-6827-01A-11R-1915-07
# DDX11L1 0.000000 0.00000000 0.000000
# WASH7P 1.150477 0.81800290 2.191641
# FAM138A 0.000000 0.03486849 0.000000head(exp_tpm)[1:3,1:3]
# TCGA-UF-A7JF-01A-11R-A34R-07 TCGA-CN-4725-01A-01R-1436-07 TCGA-D6-6827-01A-11R-1915-07
# DDX11L1 0.00000 0.00000000 0.00000
# WASH7P 22.63327 5.95811827 15.88102
# FAM138A 0.00000 0.03581036 0.00000
IOBR包中的count2tpm函数只能进行tpm转化(github上搜了这个R包内容似乎没有转化为其他数据格式的函数了)。用默认的方式进行运算得到的结果存在一定的偏差,而且我个人觉得这个偏差有点大... 但是我暂时不知道是什么原因?是内置的基因长度顺序有问题?还是我某个参数设的不对?求高手指点~
综合上述分析,暂时还是选择常规方法和DGEobj.utils R包中的convertCounts函数吧~
参考资料:
1、https://hbctraining.github.io/Training-modules/planning_successful_rnaseq/lessons/sample_level_QC.html
2、https://rdrr.io/cran/DGEobj.utils/man/convertCounts.html
3、https://rdrr.io/github/IOBR/IOBR/man/count2tpm.html
4、生信技能树推文:https://mp.weixin.qq.com/s/IUV9dSbRBK1nvetixKOCRw
致谢:感谢曾老师,小洁老师以及生信技能树团队全体成员。
注:若对内容有疑惑或者有发现明确错误的朋友,请联系后台(欢迎交流)。更多内容可关注公众号:生信方舟
- END -
相关文章:
Count数据转换为TPM数据方法整理-常规方法、DGEobj.utils和IOBR包
在正式分析之前,对于数据的处理是至关重要的,这种重要性是体现在很多方面,其中有一点是要求分析者采用正确的数据类型。 对于芯片数据,原始数据进行log2处理之后可以进行很多常见的分析,比如差异分析、热图、箱线图、…...
简易限流实现
需求描述 写一个1秒两个的限流工具类,2r/s 使用semaphore 代码实现-类似令牌桶算法 public class LimitHelper {private int maxLimit;private Semaphore semaphore;private int timeoutSeconds;public LimitHelper(int maxLimit, int timeoutSeconds) {this.max…...
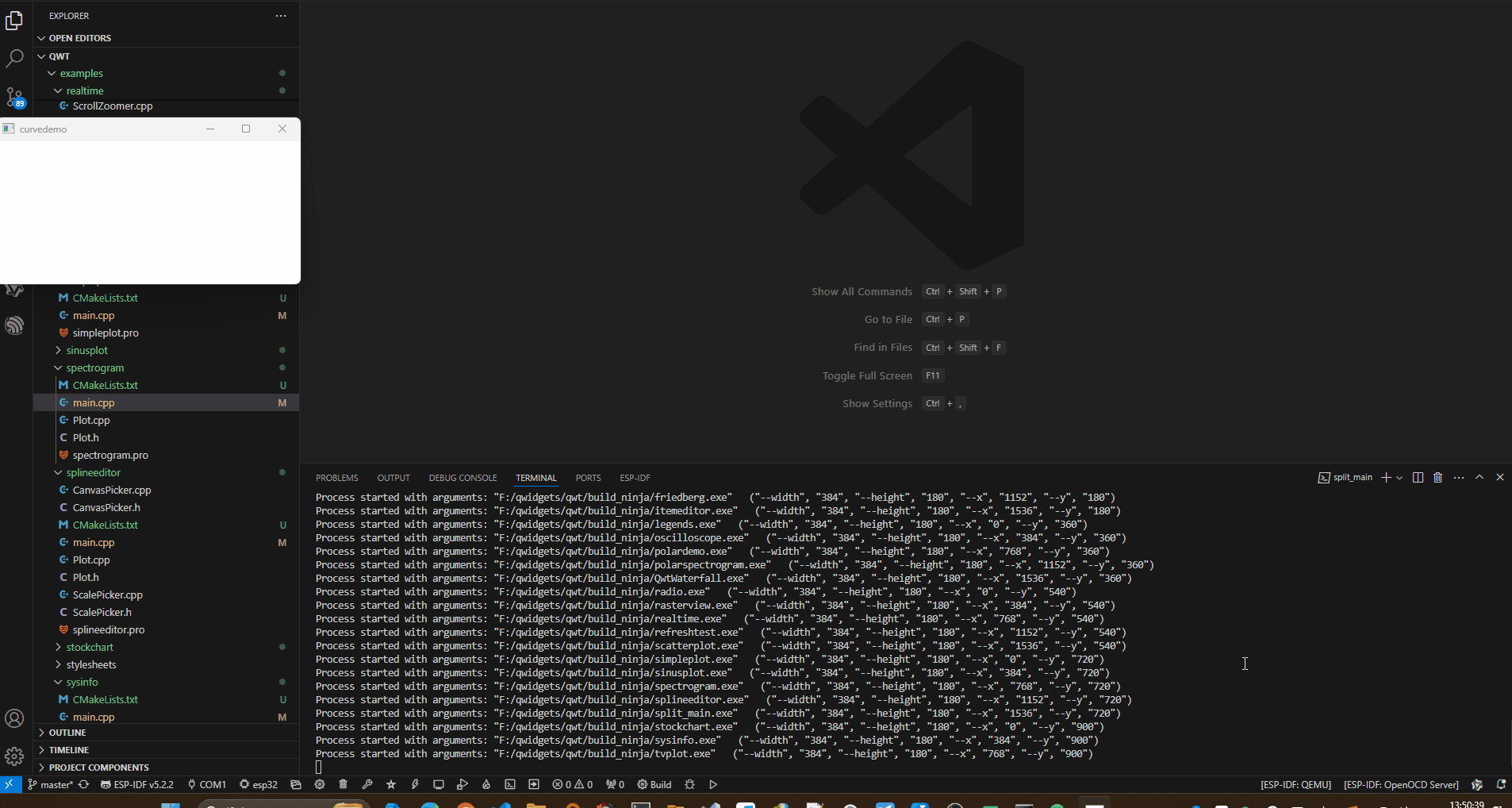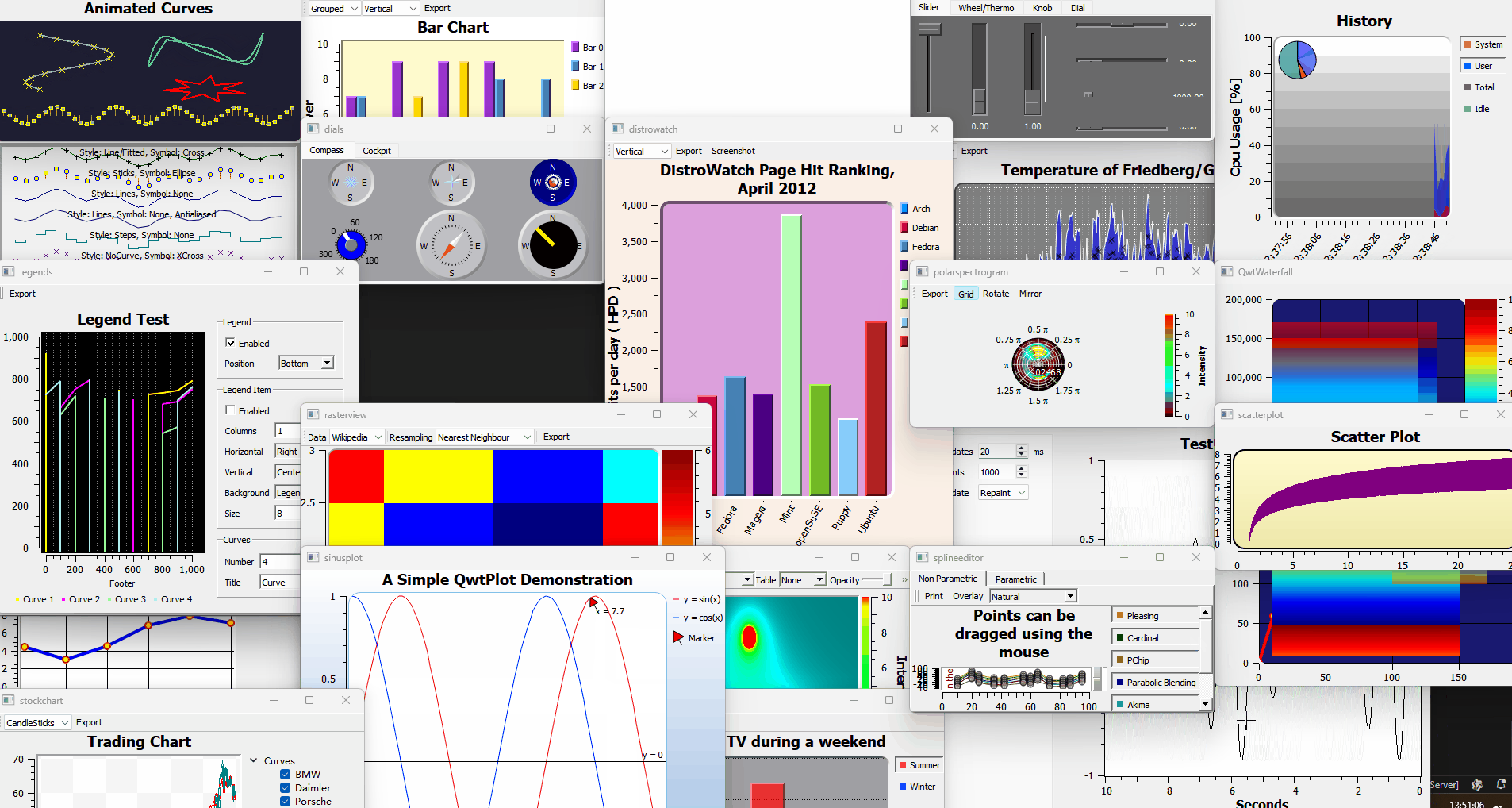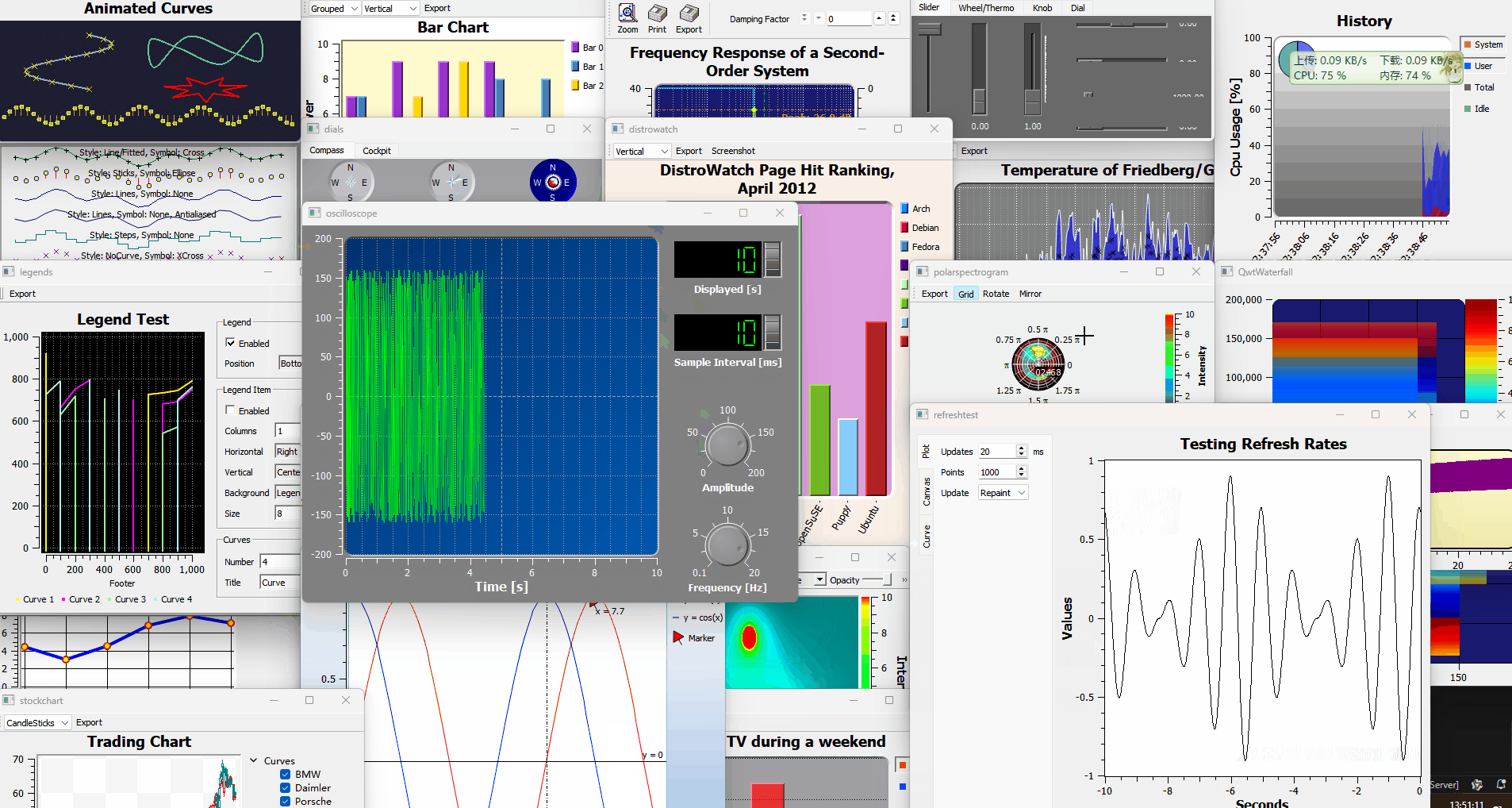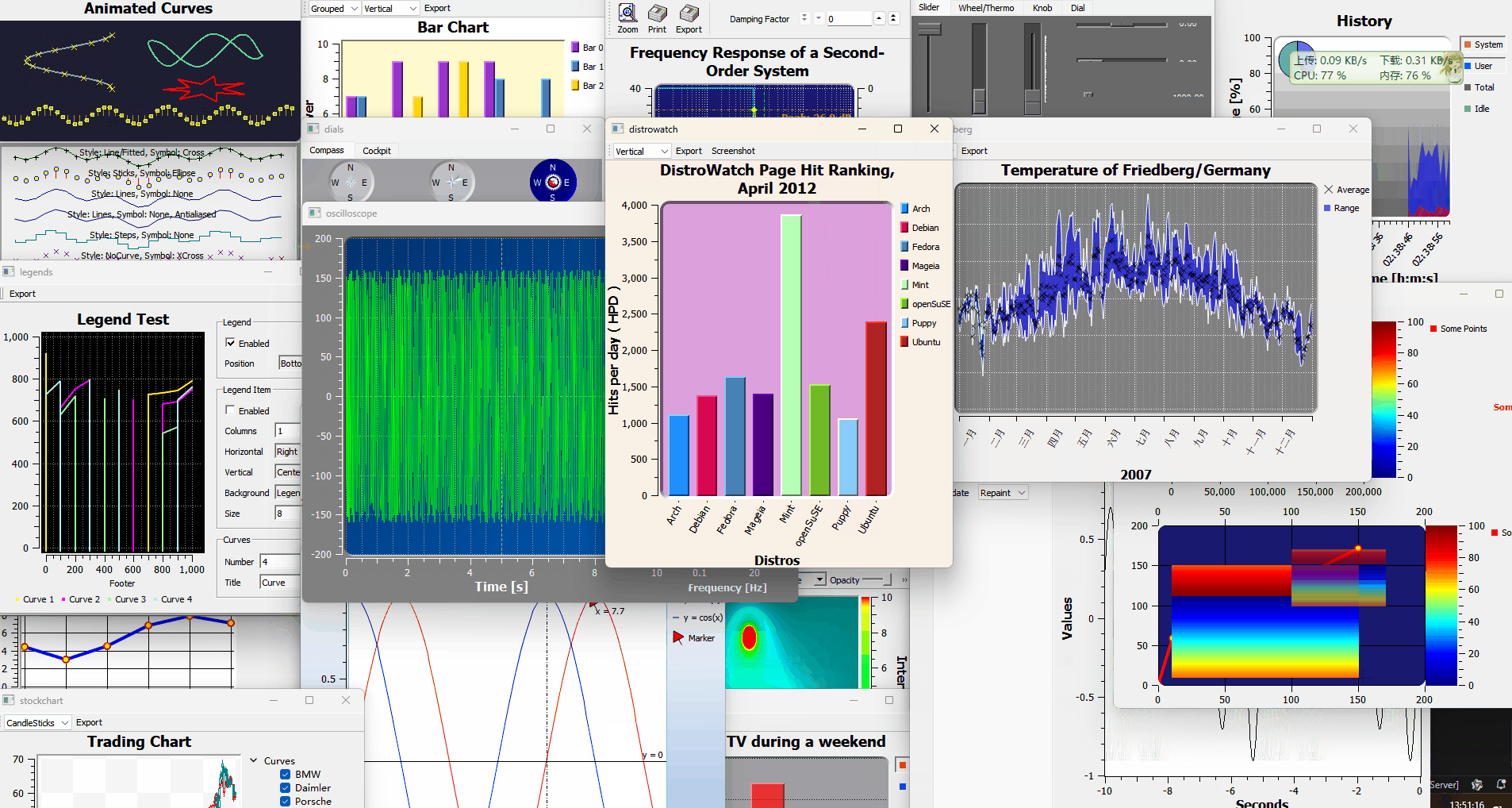
用Qwt进行图表和数据可视化开发
目录 Qwt介绍 示例应用场景 典型QWT开发流程 举一些Qwt的例子,多绘制几种类型的图像 1. 绘制折线图 (Line Plot) 2. 绘制散点图 (Scatter Plot) 3. 绘制柱状图 (Bar Plot) 4. 绘制直方图 (Histogram) Qwt介绍 QWT开发主要涉及使用QWT库进行图表和数据可视化…...

sqlalchemy使用with_entities返回指定数据列
sqlalchemy使用with_entities返回指定数据列 在 SQLAlchemy 中,with_entities 方法用于指定查询语句返回的实体(Entity)或列(Column)。它允许你限制查询的返回结果,只包含你感兴趣的特定字段或实体 使用方法 假设有一个名为 User 的 SQLAlchemy 模型类,包含以下字段:…...
express
文章目录 🟢 Express⭐️ 1.初始Express✨安装✨使用Express 搭建一台服务器⭐️2.Express-基本路由✨1.使用字符串模式的路由路径示例:✨2.使用正则表达式的路由路径示例:✨3.中间件浅试(demo)⭐️3.Express-中间件✨1.应用级中间件✨2.路由级中间件✨3.错误处理中间件✨4…...
HTML网页大设计-家乡普宁德安里
代码地址: https://pan.quark.cn/s/57e48c3b3292...

深度学习:从数据采集到模型测试的全面指南
摘要 随着人工智能和大数据技术的迅猛发展,深度学习已成为解决复杂问题的有力工具。然而,从项目启动到模型部署,包含了数据处理和模型研发的多个环节,每个环节的细致和严谨性直接决定了最终模型的性能和可靠性。本论文详细探讨了…...

Excel第29享:基于sum嵌套sumifs的多条件求和
1、需求描述 如下图所示,现要统计12.17-12.23这一周各个人员的“上班工时(a1)”。 下图为系统直接导出的工时数据明细样例。 2、解决思路 首先,确定逻辑:“对多个条件(日期、人员)进行“工时”…...
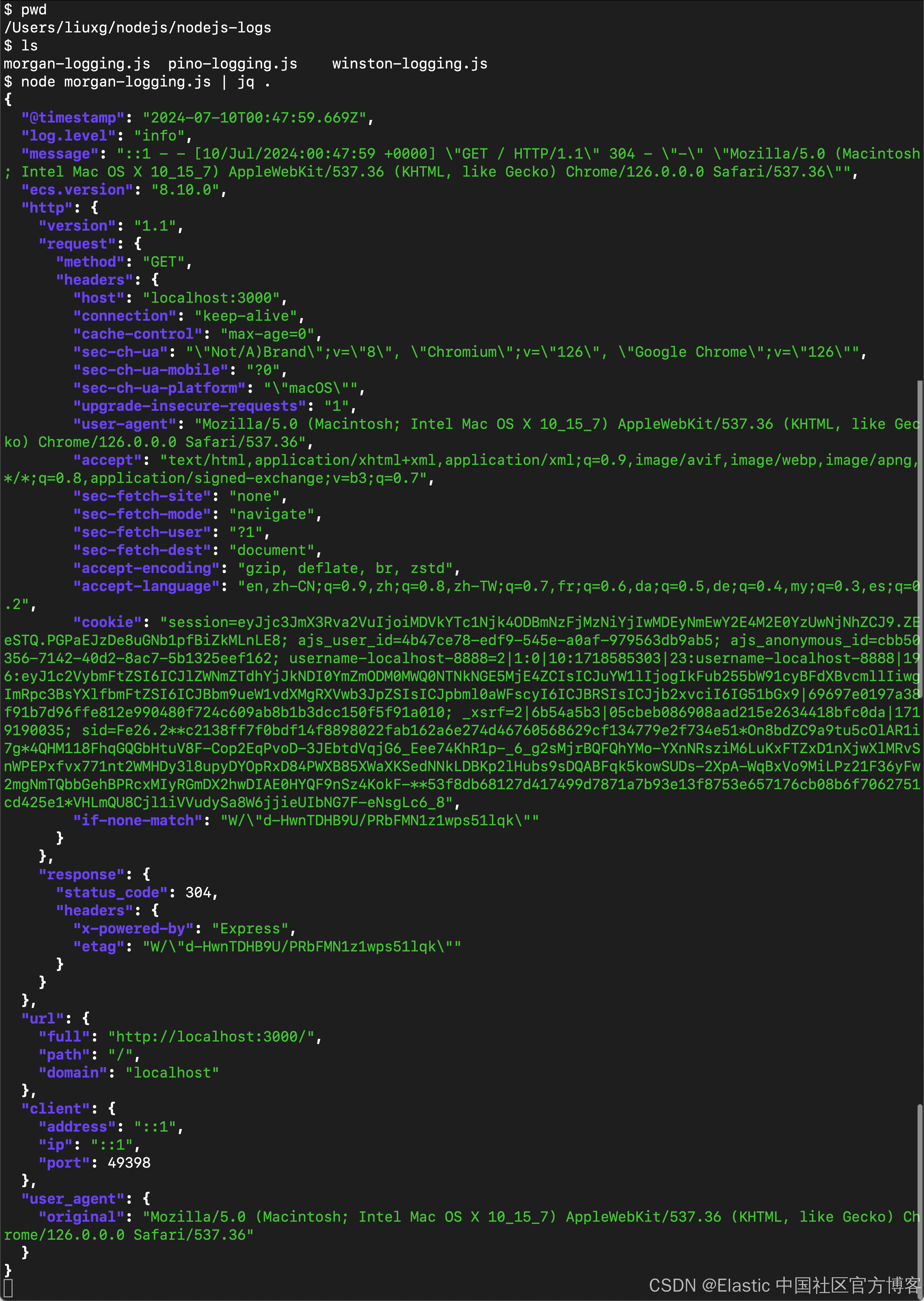
Elasticsearch:Node.js ECS 日志记录 - Morgan
这是之前系列文章: Elasticsearch:Node.js ECS 日志记录 - Pino Elasticsearch:Node.js ECS 日志记录 - Winston 中的第三篇文章。在今天的文章中,我将描述如何使用 Morgan 包针对 Node.js 应用进行日子记录。此 Morgan Node.j…...

ChatGPT对话:Python程序自动模拟操作网页,无法弹出下拉列表框
【编者按】需要编写Python程序自动模拟操作网页。编者有编程经验,但没有前端编程经验,完全不知道如何编写这种程序。通过与ChatGPT讨论,1天完成了任务。因为没有这类程序的编程经验,需要边学习,边编程,遇到…...

Unity 之 抖音小游戏集成排行榜功能详解
Unity 之 抖音小游戏集成排行榜功能详解 一,前言1.1 为游戏设计利于传播的元素2.2 多人竞技、社交传播二,集成说明2.1 功能介绍2.2 完整代码2.3 效果展示三,发现的问题和迭代计划一,前言 对于 Unity 开发者而言,在开发抖音小游戏时集成排行榜功能是提升游戏社交性和玩…...

【学习笔记】Redis学习笔记——第13章 客户端
第13章 客户端 redisServer通过clients链表保存全部客户端的状态信息。 13.1 客户端属性 13.1.1 套接字描述符 fd:-1时伪客户端,载入AOF文件或Lua脚本。 13.1.2 名字 默认无客户端名,可以通过SETNAME命令设置。 13.1.3 标志 flags&am…...

Android中的JSON解析:从基础到实践
在Android应用开发中,JSON(JavaScript Object Notation)是最常用的数据交换格式之一,因其轻量级、易读性强以及跨平台兼容性好等特点,被广泛应用于服务器与客户端之间的数据传输。解析JSON数据对于提取和处理这些信息至…...
力扣-回溯法
何为回溯法? 在搜索到某一节点的时候,如果我们发现目前的节点(及其子节点)并不是需求目标时,我们回退到原来的节点继续搜索,并且把在目前节点修改的状态还原。 记住两个小诀窍,一是按引用传状态…...
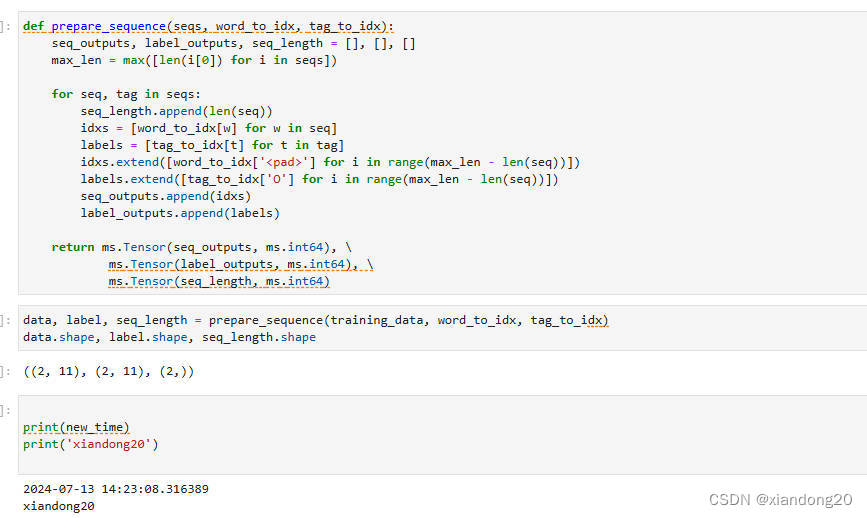
240713_昇思学习打卡-Day25-LSTM+CRF序列标注(4)
240713_昇思学习打卡-Day25-LSTMCRF序列标注(4) 最后一天咯,做第四部分。 BiLSTMCRF模型 在实现CRF后,我们设计一个双向LSTMCRF的模型来进行命名实体识别任务的训练。模型结构如下: nn.Embedding -> nn.LSTM -&…...

python requests关闭https校验
python requests关闭https校验 import requests# 关闭SSL验证 requests.get(https://***.com, verifyFalse)...

PG大会周五于杭州举办;Pika发布4.0;阿里云MySQL上线Zero-ETL集成能力
重要更新 1. PostgreSQL中国技术大会举行12日(周五)于杭州举办,是PostgreSQL社区年度的大会,举办地点:杭州君尚云郦酒店(杭州市上城区临丁路1188号),感兴趣的可以考虑现场参加 ( [1]…...
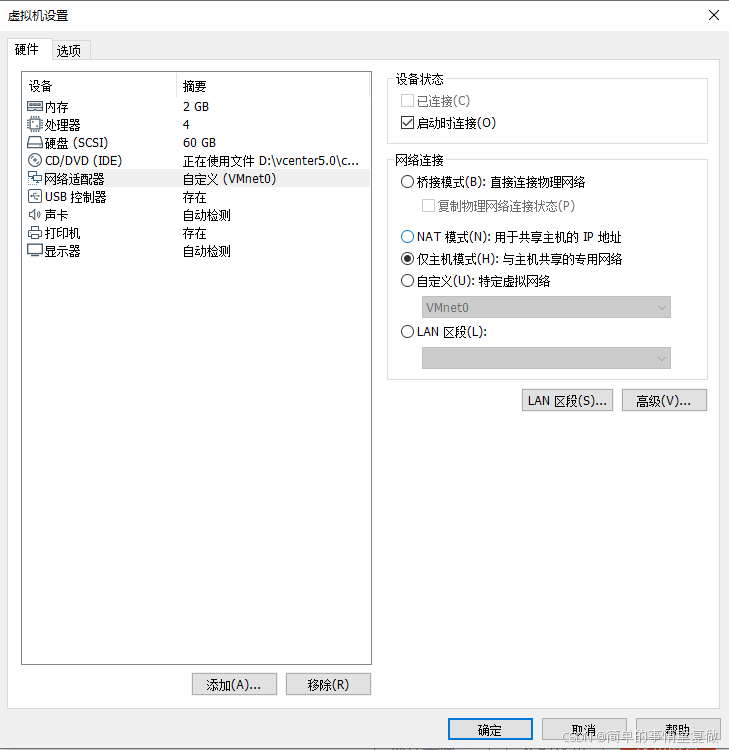
虚拟机vmware网络设置
一、网络分类 打开vmware workstation网络编辑器可以知道有三种网络类型,分别是:桥接模式、nat模式、仅主机模式。 1、桥接模式 桥接模式是将主机网卡与虚拟机虚拟的网卡利用虚拟网桥进行通信。在桥接的作用下, 类似于把物理主机虚拟为一个交换机, 所有设…...
数学建模国赛入门指南
文章目录 认识数学建模及国赛认识数学建模什么是数学建模?数学建模比赛 国赛参赛规则、评奖原则如何评省、国奖评奖规则如何才能获奖 国赛赛题分类及选题技巧国赛赛题特点赛题分类 国赛历年题型及优秀论文 数学建模分工技巧数模必备软件数模资料文献数据收集资料收集…...
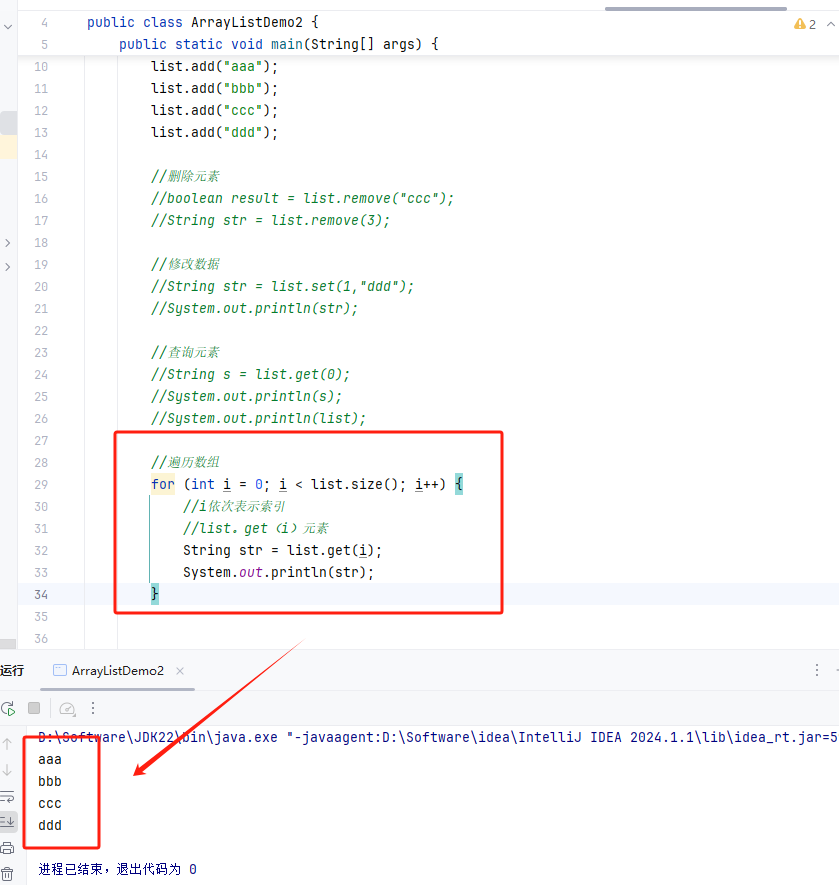
Java基础之集合
集合和数组的类比 数组: 长度固定可以存基本数据类型和引用数据类型 集合: 长度可变只能存引用数据类型存储基本数据类型要把他转化为对应的包装类 ArrayList集合 ArrayList成员方法 添加元素 删除元素 索引删除 查询 遍历数组...

Python 3.7 + XGBoost 多分类实战:从数据清洗到SHAP模型解释的保姆级教程
Python 3.7 XGBoost 多分类实战:从数据清洗到SHAP模型解释的保姆级教程在机器学习领域,XGBoost因其出色的性能和可解释性成为众多数据科学家的首选工具。本文将带您完整走过多分类任务的全流程,从原始数据到可解释的预测模型,每个…...

深度解析DeTikZify:科研工作者的智能图表生成神器
深度解析DeTikZify:科研工作者的智能图表生成神器 【免费下载链接】DeTikZify Synthesizing Graphics Programs for Scientific Figures and Sketches with TikZ. 项目地址: https://gitcode.com/gh_mirrors/de/DeTikZify 在科研工作中,创建高质量…...

终极指南:5步快速掌握免费的3D点云标注工具labelCloud
终极指南:5步快速掌握免费的3D点云标注工具labelCloud 【免费下载链接】labelCloud A lightweight tool for labeling 3D bounding boxes in point clouds. 项目地址: https://gitcode.com/gh_mirrors/la/labelCloud 想要为自动驾驶、机器人视觉或3D目标检测…...

WTF Auto Layout? 实战:10个常见约束冲突案例解析与解决方案
WTF Auto Layout? 实战:10个常见约束冲突案例解析与解决方案 【免费下载链接】wtfautolayout The source code for Why The Failure, Auto Layout? 项目地址: https://gitcode.com/gh_mirrors/wt/wtfautolayout 在iOS开发中,Auto Layout是构建灵…...

通过用量看板分析团队大模型API消耗发现优化调用策略的机会
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过用量看板分析团队大模型API消耗发现优化调用策略的机会 作为团队的技术负责人,确保大模型API调用在满足业务需求的…...

Armv9-A架构解析:SVE/SME与安全增强技术
1. Armv9-A架构演进与核心特性全景Armv9-A架构代表了Arm公司面向未来十年计算需求的设计哲学,其核心在于三个维度的突破:性能、安全与专用计算。作为长期从事Arm架构开发的工程师,我见证了从Armv7到Armv9的技术跃迁。与固定宽度向量指令的NEO…...

城通网盘直链解析终极指南:3分钟告别广告等待
城通网盘直链解析终极指南:3分钟告别广告等待 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 还在为城通网盘下载而烦恼吗?每次下载都要面对烦人的广告等待,还要输入…...

GraphpostgresQL高级用法:JSON、JSONB和HStore复杂数据类型的查询技巧
GraphpostgresQL高级用法:JSON、JSONB和HStore复杂数据类型的查询技巧 【免费下载链接】GraphpostgresQL GraphQL for Postgres 项目地址: https://gitcode.com/gh_mirrors/gr/GraphpostgresQL GraphpostgresQL作为PostgreSQL的GraphQL扩展,为开发…...

免费岛屿设计终极指南:5分钟快速掌握Happy Island Designer
免费岛屿设计终极指南:5分钟快速掌握Happy Island Designer 【免费下载链接】HappyIslandDesigner "Happy Island Designer (Alpha)",是一个在线工具,它允许用户设计和定制自己的岛屿。这个工具是受游戏《动物森友会》(Animal Cros…...

温差发电驱动轻型电动车:热电模块与催化燃烧器的系统集成实践
1. 项目概述:用温差发电驱动轻型电动车最近在琢磨一个挺有意思的玩意儿:能不能给那些轻型的电动车,比如高尔夫球车、园区巡逻车或者小型载货三轮,换上一套不一样的“心脏”?传统的方案,要么背着一大块死沉死…...