Redis的使用(四)常见使用场景-缓存使用技巧
1.绪论
redis本质上就是一个缓存框架,所以我们需要研究如何使用redis来缓存数据,并且如何解决缓存中的常见问题,缓存穿透,缓存击穿,缓存雪崩,以及如何来解决缓存一致性问题。
2.缓存的优缺点
2.1 缓存的优点
缓存可以降低数据库的负载,提高读写效率和响应时间。
2.2 缓存的缺点
1.需要额外的资源消耗
2.如何保证缓存和数据库的一致性是一个问题,所以要求强一致性的业务尽量不要用缓存
3.缓存一致性
为了保证缓存和数据库的一致性,我们一般有三种方式来操作缓存,分别是读写穿透,旁路缓存和异步写回。
3.1 Cache Aside Pattern (旁路缓存)
其实就是人工编码方式,也是我们操作redis的常见的使用方式,就是先更新完数据库再去更新缓存。
3.1.1 步骤
1.读缓存
如果命中缓存直接返回,如果未命中便从数据中读取数据并且更新缓存。
2.写缓存
如果未命中缓存直接更新数据库,如果命中缓存,便更新数据库,同时更新(删除)缓存。
3.1.2 更新缓存和数据库的方式
读缓存这里没有一致性问题,但是在写入缓存的时候是先写入到数据库,还是先写入到缓存这里就会有一致性问题。对于写缓存的操作方式主要有如下4种:写数据库写缓存,写缓存写数据库,写数据库删缓存,写缓存删数据。
1.写缓存写数据库

先写缓存,再写数据库的话,如果缓存写入成功,数据库写入失败,数据库回滚,此时缓存便会与数据库内容不一致。
2.写数据写缓存

可以看出在线程1更新数据库为1成功,线程2获得时间片,更新数据库和缓存为x,线程1再次获得时间片,更新缓存为1。这个时候缓存和数据库数据不一致。
3.删缓存更新数据库

可以看出线程1在删除缓存后,线程2获得时间片,读取到缓存为空,会查询数据库并将该旧值写入到缓存中,但是线程1会更新数据库为新值,导致缓存不一致。
4.更新数据库删除缓存
假设此时因为缓存淘汰策略,缓存已经失效。所以初始时缓存为null

可以看出,假设缓存初始时因为淘汰策略,缓存为null,然后线程1查询数据库得到A=1,线程2获得时间片,更新数据库为A=x并且删除缓存,线程1得到时间片,更新缓存为A=1,此时发生了缓存不一致。
但是上面主要有两个条件导致:
1.线程1查询缓存刚好失效,需要从数据库中重新读取;
2.线程1查完库后线程2立刻更新数据库并且删除缓存。
这两个条件在事件开发过程中是很难遇到的,所以该方式可以作为缓存更新数据库的方式。
5.延迟双删
延迟双删其实是在第3种方式删除缓存更新数据库上面再加了一次删除。如下:

前面说过,在删除缓存和更新数据之间,可能会有其他线程因为未命中缓存,所以读取到旧数据并且更新到缓存中。所以我们就延迟一定时间,尽量将这部分线程更新的缓存数据删除掉。
a) 为什么需要第一次删除
因为删除和写入数据库不是一个原子操作,如果是先更新数据库,然后延迟一段时间,在删除缓存,这样操作的话,如果第二次删除失败,会有不一致的问题。所以在更新数据库前引入一次删除操作,这样可以尽可能的保证删除成功。
b) 为什么需要删除第二次
前面已经讲过,第二次删除是为了删除掉因为第一次删除和更新期间其他线程查询数据库旧值 并写入到缓存的问题。
3.1.3 如何保证删除成功
根据前文的分析,我们在实际开发中可以通过如下两种方式来更新缓存:
1.更新数据库删除缓存
2.延迟双删
当时上面两种方式都需要保证删除成功才能保证缓存和数据库的一致性,我们应该怎样才能保证删除缓存成功呢?
1.设置超时时间
这种方式其实就是利用缓存自带的过期策略保证缓存一定会过期,尽量的减少脏读。
2.重试
当删除失败的时候,可以进行重试,但是可能影响接口性能。
3.监听binlog
比如延迟双删可以变成如下:
1.删除缓存
2.更新数据库。
3.监听binlog删除缓存。
监听binlog的中间件一般都有重试机制,能够保证删除尽量成功。
3.1.4 如何保证redis和数据库的强一致性
前面说的更新缓存的方案里面推荐的更新数据库+删除缓存和延迟双删都不能完全保证数据库和缓存的一致性。如果对一致性要求很高,可以做成同步的方式,先更新数据库再更新redis,并且给这两个操作加分布式锁,保证原子性。
3.2 Read/Write Through Pattern(读写穿透)
缓存和数据库为一个整体,用户只需要操作缓存,至于如何实现缓存与数据的一致性,交给缓存去实现。其实我觉得这种模式叫通过缓存读,通过缓存写更好理解。因为客户端基本上只更缓存打交道,如果缓存没有数据需要同步数据库内容,是通过缓存去更新的。更新缓存数据后,同步到数据库也是通过缓存更新的。

3.2.1 读缓存
读缓存的时候,如果数据存在,便直接返回,如果数据不存在,缓存便会从数据库中拉取数据,并用户返回。
3.2.2 写缓存
写缓存的时候,如果未命中缓存,便更新数据库。如果命中缓存,便更新缓存,缓存在更新数据到数据库。注意,缓存需要保证这两个动作的原子性。
这里,为什么,客户端更新缓存的时候,是直接更新数据库,而不更新缓存呢?其实是因为这样可以将更新操作分摊到读写缓存中来。读缓存时同步未命中缓存的那一部分数据,写缓存时同步命中缓存的那一部分数据。
3.2.3 优势
其实就是为了减少旁路缓存,用户的开发工作,缓存自己实现了和数据库同步的这部分工作。
3.3 Write Behind Caching Pattern(异步写回)
异步写回,其实就是用户只用更新缓存中的数据,然后启动一个线程,异步的将缓存中的数据刷到数据库中。这个其实在很多框架中都是采用这种方式,比如前面介绍的RocketMq中对MappedFile的持久化,还有linux中的页缓存等都是采用这种方式。
它的优点就是,只用和缓存打交道,所以速度极快。并且它和读穿/写穿模式的最主要的区别是。读穿/写穿模式是更新缓存过后,会同步刷新到数据库中。但是异步写回是异步的写入到库中。所以可能会有丢数据的风险。
4.缓存穿透
4.1 什么是缓存穿透
缓存穿透就是,当客户端访问缓存时,发现缓存中没有数据,然后去访问数据库,但是数据库中也没有数据。所以在读取数据的时候,因为数据库中没有数据给redis缓存,所以请求会一直到数据库中,导致数据库压力过大。
4.2 怎么解决缓存穿透
4.2.1 缓存空对象
1.操作
当数据库中没有数据的时候,可以缓存一个空对象到redis中。
2.优缺点
操作简单,但是如果数据库有对象的时候,并且采用的是过期淘汰的策略的话,会有一段时间和数据库不一致。
3.代码
public <R,ID> R queryWithPassThrough(String keyPrefix, ID id, Class<R> type, Function<ID, R> dbFallback, Long time, TimeUnit unit){String key = keyPrefix + id;// 1.从redis查询商铺缓存String json = stringRedisTemplate.opsForValue().get(key);// 2.判断是否存在if (StrUtil.isNotBlank(json)) {// 3.存在,直接返回return JSONUtil.toBean(json, type);}// 判断命中的是否是空值if (json != null) {// 返回一个错误信息return null;}// 4.不存在,根据id查询数据库R r = dbFallback.apply(id);// 5.不存在,返回错误if (r == null) {// 将空值写入redisstringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);// 返回错误信息return null;}// 6.存在,写入redisthis.set(key, r, time, unit);return r;}4.2.3 布隆过滤器
可以在请求前根据id到布隆过滤器中查询一下,判断该数据是否存在,如果不存在便直接返回。布隆过滤器时基于概率统计的判断某个元素是否存在某个位数组中的工具。
我们来看看其实现原理:
布隆过滤器由一组hash函数和一个数组组成。现在假设有k个hash函数,当有一个对象传入的时候,这k个hash喊出会将这个字符串进行hash运算,然后映射到数组的k个bit位上。在判断对象是否存在的时候,根据对象上面的bit位是否都位1,如果都为1的话,表示对象可能存在。但为什么是可能,而不是一定呢?因为有hash冲突,有极低的可能存在某两个元素,经过k个hash函数的映射到数组中的位置是一样的。

5.缓存雪崩
5.1 什么是缓存雪崩
缓存雪崩就是在某一个时刻大量的key同时过期或者redis直接宕机,导致大量请求涌入到数据库,数据库压力激增。
5.2 怎么解决缓存雪崩
为了预防大量key同时过期:给key的过期时间设置一个随机值;
为了防止redis过期:我们可以通过集群的方式保证redis服务高可用。
6.缓存击穿
6.1 什么是缓存击穿
缓存击穿就是在高并发场景下,因为热点key(这里热点key可以指访问频率高或者重建缓存时间长的key)过期,导致大量线程同时重建缓存。
6.2 怎么解决缓存击穿
6.2.1 互斥锁
1.思路
其实就是保证只有一个线程在重建缓存。当某个线程发现缓存不存在是,先加互斥锁,然后查询数据库,构建缓存,更新缓存。如果此时其他线程来获取缓存,发现缓存为空,重建缓存时需要先阻塞获取锁。
2.代码
public <R, ID> R queryWithMutex(String keyPrefix, ID id, Class<R> type, Function<ID, R> dbFallback, Long time, TimeUnit unit) {String key = keyPrefix + id;// 1.从redis查询商铺缓存String shopJson = stringRedisTemplate.opsForValue().get(key);// 2.判断是否存在if (StrUtil.isNotBlank(shopJson)) {// 3.存在,直接返回return JSONUtil.toBean(shopJson, type);}// 判断命中的是否是空值if (shopJson != null) {// 返回一个错误信息return null;}// 4.实现缓存重建// 4.1.获取互斥锁String lockKey = LOCK_SHOP_KEY + id;R r = null;try {boolean isLock = tryLock(lockKey);// 4.2.判断是否获取成功if (!isLock) {// 4.3.获取锁失败,休眠并重试Thread.sleep(50);return queryWithMutex(keyPrefix, id, type, dbFallback, time, unit);}// 4.4.获取锁成功,根据id查询数据库r = dbFallback.apply(id);// 5.不存在,返回错误if (r == null) {// 将空值写入redisstringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);// 返回错误信息return null;}// 6.存在,写入redisthis.set(key, r, time, unit);} catch (InterruptedException e) {throw new RuntimeException(e);}finally {// 7.释放锁unlock(lockKey);}// 8.返回return r;}6.2.2 逻辑过期
1.思路
其主要步骤如下:
1.给数据设置一个逻辑过期时间,并且写入到缓存中比如{"name":"三',"expireTime":1720712827}
2.线程1查询缓存,发现数据已经过期,单独启动一个线程进行缓存重建,这里重建缓存也需要加互斥锁,防止多个线程进行重建。
3.其他线程访问缓存,发现缓存过期,首先会获取锁,如果发现数据已经过期,会去获取锁进行缓存重建,但是获取锁失败,返回redis中的旧数据。
2.代码
public <R, ID> R queryWithLogicalExpire(String keyPrefix, ID id, Class<R> type, Function<ID, R> dbFallback, Long time, TimeUnit unit) {String key = keyPrefix + id;// 1.从redis查询商铺缓存String json = stringRedisTemplate.opsForValue().get(key);// 2.判断是否存在,这里会进行缓存预热,提前将热点数据加载到redis中if (StrUtil.isBlank(json)) {// 3.存在,直接返回return null;}// 4.命中,需要先把json反序列化为对象RedisData redisData = JSONUtil.toBean(json, RedisData.class);R r = JSONUtil.toBean((JSONObject) redisData.getData(), type);LocalDateTime expireTime = redisData.getExpireTime();// 5.判断是否过期if(expireTime.isAfter(LocalDateTime.now())) {// 5.1.未过期,直接返回店铺信息return r;}// 5.2.已过期,需要缓存重建// 6.缓存重建// 6.1.获取互斥锁String lockKey = LOCK_SHOP_KEY + id;boolean isLock = tryLock(lockKey);// 6.2.判断是否获取锁成功if (isLock){// 6.3.成功,开启独立线程,实现缓存重建CACHE_REBUILD_EXECUTOR.submit(() -> {try {// 查询数据库R newR = dbFallback.apply(id);// 重建缓存this.setWithLogicalExpire(key, newR, time, unit);} catch (Exception e) {throw new RuntimeException(e);}finally {// 释放锁unlock(lockKey);}});}// 6.4.返回过期的商铺信息return r;}
3.优缺点
逻辑过期不用进行锁等待,但是会占用额外的空间(存储缓存过期时间)并且不能保证一致性(因为其他线程发现有线程在异步重建缓存过后,会返回旧数据)。
7.参考
1.Redis第12讲——缓存的三种设计模式_缓存的设计模式-CSDN博客
2.缓存一致性问题解决方案-CSDN博客
3.https://www.yuque.com/hollis666/un6qyk/tmcgo0
4. 黑马程序员Redis入门到实战教程,深度透析redis底层原理+redis分布式锁+企业解决方案+黑马点评实战项目_哔哩哔哩_bilibili
相关文章:
Redis的使用(四)常见使用场景-缓存使用技巧
1.绪论 redis本质上就是一个缓存框架,所以我们需要研究如何使用redis来缓存数据,并且如何解决缓存中的常见问题,缓存穿透,缓存击穿,缓存雪崩,以及如何来解决缓存一致性问题。 2.缓存的优缺点 2.1 缓存的…...

BERT架构的深入解析
BERT(Bidirectional Encoder Representations from Transformers)是由Google在2018年提出的一种基于Transformer架构的预训练模型,迅速成为自然语言处理(NLP)领域的一个里程碑。BERT通过双向编码器表示和预训练策略&am…...

数字孪生技术如何助力低空经济飞跃式发展?
一、什么是低空经济? 低空经济,是一个以通用航空产业为主导的经济形态,它涵盖了低空飞行、航空旅游、航空物流、应急救援等多个领域。它以垂直起降型飞机和无人驾驶航空器为载体,通过载人、载货及其他作业等多场景低空飞行活动&a…...

HTTP背后的故事:理解现代网络如何工作的关键(二)
一.认识请求方法(method) 1.GET方法 请求体中的首行包括:方法,URL,版本号 方法描述的是这次请求,是具体去做什么 GET方法: 1.GET 是最常用的 HTTP 方法. 常用于获取服务器上的某个资源。 2.在浏览器中直接输入 UR…...

数据流通环节如何规避安全风险
由于参与数据流通与交易的数据要素资源通常是经过组织加工的高质量数据集,甚至可能涉及国家核心战略利益,一旦发生针对数据流通环节的恶意事件,将造成较大负面影响,对数据要素市场的价值激活造成潜在威胁。具体来说,数…...

部署k8s 1.28.9版本
继上篇通过vagrant与virtualBox实现虚拟机的安装。笔者已经将原有的vmware版本的虚拟机卸载掉了。这个场景下,需要重新安装k8s 相关组件。由于之前写的一篇文章本身也没有截图。只有命令。所以趁着现在。写一篇,完整版带截图的步骤。现在行业这么卷。离…...
实验二:图像灰度修正
目录 一、实验目的 二、实验原理 三、实验内容 四、源程序和结果 源程序(python): 结果: 五、结果分析 一、实验目的 掌握常用的图像灰度级修正方法,包括图象的线性和非线性灰度点运算和直方图均衡化法,加深对灰度直方图的理解。掌握对比度增强、直方图增强的原理,…...

bash: ip: command not found
输入: ip addr 报错: bash: ip: command not found 报错解释: 这个错误表明在Docker容器中尝试执行ip addr命令时,找不到ip命令。这通常意味着iproute2包没有在容器的Linux发行版中安装或者没有正确地设置在容器的环境变量PA…...

全开源TikTok跨境商城源码/TikTok内嵌商城/前端uniapp+后端+搭建教程
多语言跨境电商外贸商城 TikTok内嵌商城,商家入驻一键铺货一键提货 全开源完美运营 海外版抖音TikTok商城系统源码,TikToK内嵌商城,跨境商城系统源码 接在tiktok里面的商城。tiktok内嵌,也可单独分开出来当独立站运营 二十一种…...

云原生、Serverless、微服务概念
云原生(Cloud Native) 云原生是一种设计和构建应用程序的方法,旨在充分利用云计算的优势。云原生应用程序通常具有以下特征: 容器化:应用程序和其依赖项被打包在容器中,确保一致的运行环境。常用的容器技…...

Windows上LabVIEW编译生成可执行程序
LabVIEW项目浏览器(Project Explorer)中的"Build Specifications"就是用来配置项目发布方法的。在"Build Specifications"右键菜单中选取"New",可以看到程序有几种不同的发布方法:Application(EXE)、Installer、.Net Inte…...

ref 和 reactive 区别
在Vue 3中,ref和reactive都是用于创建响应式数据的API,但它们之间存在一些关键的区别。以下是ref和reactive的主要区别: 1. 数据类型处理 ref:主要用于定义基本类型的数据(如字符串、数字、布尔值等)以及…...

深度学习计算机视觉中, 多尺度特征和上下文特征的区别是?
在深度学习和计算机视觉中,多尺度特征和上下文特征都是用来捕捉和理解图像中复杂模式和关系的重要概念,但它们的侧重点有所不同。 多尺度特征 (Multi-scale Features) 多尺度特征是指在不同尺度上对图像进行特征提取,以捕捉不同尺度的物体特…...

Facebook未来展望:数字社交平台的进化之路
在信息技术日新月异的时代,社交媒体平台不仅是人们交流沟通的重要工具,更是推动社会进步和变革的重要力量。作为全球最大的社交媒体平台之一,Facebook在过去十多年里,不断创新和发展,改变了数十亿用户的社交方式。展望…...

uniapp-vue3-vite 搭建小程序、H5 项目模板
uniapp-vue3-vite 搭建小程序、H5 项目模板 特色准备拉取默认UniApp模板安装依赖启动项目测试结果 配置自动化导入安装依赖在vite.config.js中配置 引入 prerttier eslint stylelint.editorconfig.prettierrc.cjs.eslintrc.cjs.stylelintrc.cjs 引入 husky lint-staged com…...

sealos快速安装k8s
Sealos 提供一套强大的工具,使得用户可以便利地管理整个集群的生命周期。 功能介绍 使用 Sealos,您可以安装一个不包含任何组件的裸 Kubernetes 集群。此外,Sealos 还可以在 Kubernetes 之上,通过集群镜像能力组装各种上层分布式…...

智慧水利:迈向水资源管理的新时代,结合物联网、云计算等先进技术,阐述智慧水利解决方案在提升水灾害防控能力、优化水资源配置中的关键作用
本文关键词:智慧水利、智慧水利工程、智慧水利发展前景、智慧水利技术、智慧水利信息化系统、智慧水利解决方案、数字水利和智慧水利、数字水利工程、数字水利建设、数字水利概念、人水和协、智慧水库、智慧水库管理平台、智慧水库建设方案、智慧水库解决方案、智慧…...

MATLAB——字符串处理
文章目录 MATLAB——字符串处理字符串处理函数字符串或字符串数组构造 MATLAB——字符串处理 字符串处理函数 MATLAB中的字符串处理函数如下: 函数名称说明eval(string)作为一个MATLAb命令求字符串的值blanks(n)返回一个具有n个空格的字符串deblank去掉字符串末尾…...
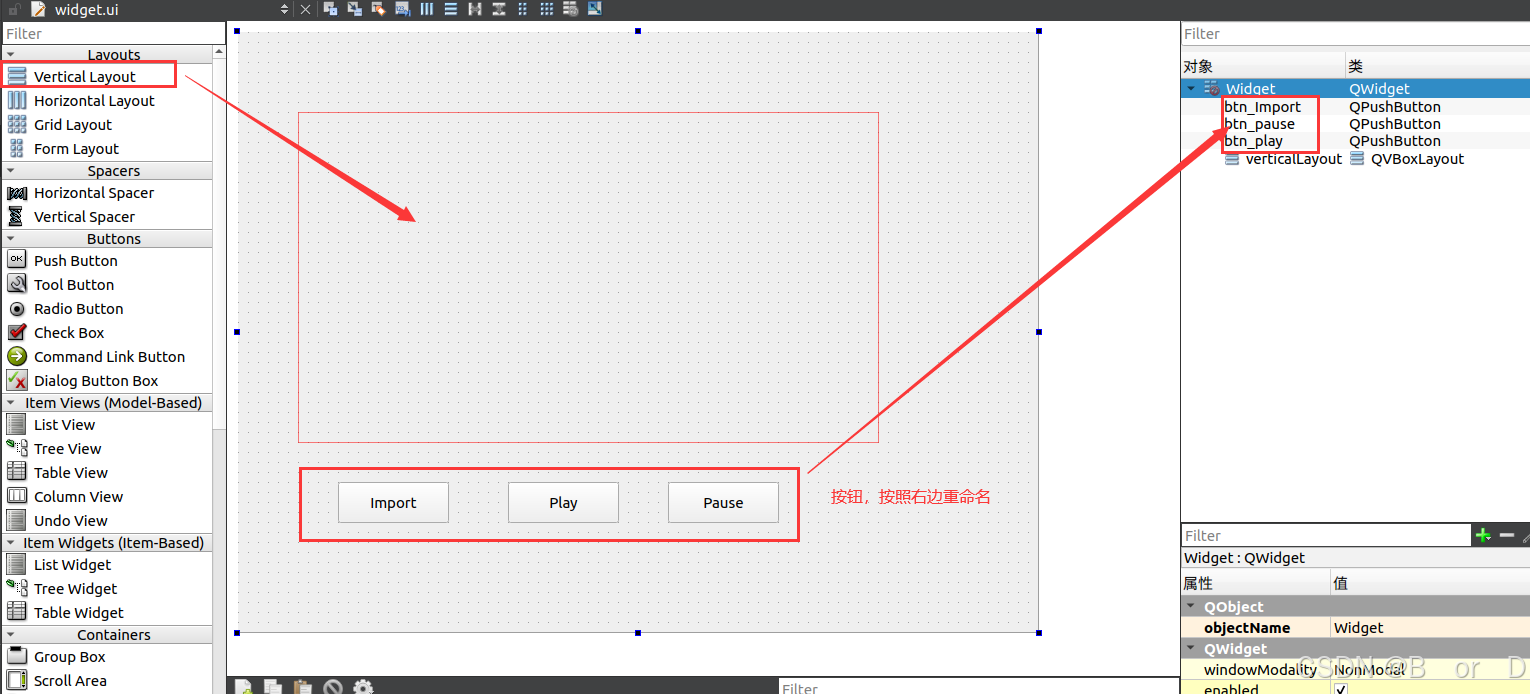
Qt实现一个简单的视频播放器
目录 1 工程配置 1.1 创建新工程 1.2 ui界面配置 1.3 .pro配置 2 代码 2.1 main.c代码 2.2 widget.c 2.3 widget.h 本文主要记述了如何使用Qt编写一个简单的视频播放器,整个示例采用Qt自带组件就可以完成。可以实现视频的播放和暂停等功能。 1 工程配置 1.…...

微服务治理新篇章:Eureka中细粒度策略管理实现
微服务治理新篇章:Eureka中细粒度策略管理实现 在微服务架构中,服务的治理和管理是确保系统稳定性和可扩展性的关键。Eureka作为Netflix开源的服务发现框架,提供了基本的服务注册与发现功能。然而,随着微服务规模的扩大和业务需求…...

AFM虚拟实验避坑指南:PID参数怎么调?相位图为何比形貌图更“敏感”?
AFM虚拟实验避坑指南:PID参数调节与相位图敏感性的深度解析 1. 从零开始理解AFM虚拟实验的核心逻辑 原子力显微镜(AFM)虚拟实验作为现代材料表征技术的重要教学工具,其核心价值在于让学习者无需接触昂贵设备就能掌握微观世界探测…...

Mac应用卸载不干净?Pearcleaner帮你彻底清理,释放存储空间
Mac应用卸载不干净?Pearcleaner帮你彻底清理,释放存储空间 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾发现,…...

量子优化新突破:虚时间演化高效求解QUBO问题
1. 量子优化新范式:模拟虚时间演化解决QUBO问题在金融投资组合优化、物流路径规划和机器学习特征选择等领域,二次无约束二进制优化(QUBO)问题无处不在。这类NP难问题随着规模扩大,求解难度呈指数级增长,传统…...

从‘微软 ORG’到流畅中文NLP:你的zh_core_web_sm模型真的装对了吗?
从‘微软 ORG’到流畅中文NLP:你的zh_core_web_sm模型真的装对了吗? 当你在Spacy中加载zh_core_web_sm模型,运行示例文本"微软准备用十亿美金买下这家英国的创业公司"后,看到"微软"被正确标记为ORG࿰…...
)
别再乱调了!用Audition参数均衡器拯救你的干音(附实战预设)
别再乱调了!用Audition参数均衡器拯救你的干音(附实战预设) 录制完一段音频后,你是否经常遇到这样的困扰:人声听起来闷闷的像隔了层棉被,或是尖锐刺耳到让人皱眉,又或者整体浑浊不清缺乏层次感&…...

第一性原理计算在半导体缺陷研究中的应用:以氢掺杂氧化镓为例
1. 项目概述:从“掺杂”与“缺陷”说起在半导体材料的研究与开发中,我们常常听到“掺杂”这个词。简单来说,就像在炒菜时撒入不同的调料来改变风味,掺杂就是在纯净的半导体材料(本征材料)中,有目…...

hoverboard-firmware-hack-FOC终极兼容性指南:STM32F103RCT6与GD32F103RCT6深度对比
hoverboard-firmware-hack-FOC终极兼容性指南:STM32F103RCT6与GD32F103RCT6深度对比 【免费下载链接】hoverboard-firmware-hack-FOC With Field Oriented Control (FOC) 项目地址: https://gitcode.com/GitHub_Trending/ho/hoverboard-firmware-hack-FOC 想…...

AI辅助科研的加速逻辑与隐性成本拆解
1. 这不是科幻片里的桥段:当AI真正坐进实验室,它在改写科研的底层规则 “AI加速科学发现”这个说法,最近两年几乎成了学术会议开场白的标配。但如果你真去翻过Nature、Science上那些标着“AI-driven discovery”的论文,会发现一个…...

AirPodsDesktop:在Windows上解锁苹果耳机的完整体验
AirPodsDesktop:在Windows上解锁苹果耳机的完整体验 【免费下载链接】AirPodsDesktop ☄️ AirPods desktop user experience enhancement program, for Windows and Linux (WIP) 项目地址: https://gitcode.com/gh_mirrors/ai/AirPodsDesktop 你是否曾经在W…...

本地视频怎么去水印?2026本地视频去水印软件推荐与方法合集
不少朋友都会碰到一个烦恼:从抖音、快手、小红书下载的视频都带着水印,自己录制的视频也会被社交平台自动添加水印。想要去掉这些水印用于素材库或后期编辑,却不知道该怎么办。别急,今天就给你盘点2026年最实用的本地视频去水印方…...