【常见开源库的二次开发】基于openssl的加密与解密——Base58比特币钱包地址——算法分析(三)

目录:
目录:
一、base58(58进制)
1.1 什么是base58?
1.2 辗转相除法
1.3 base58输出字节数:
二、源码分析:
2.1源代码:
2.2 算法思路介绍:
2.2.1 Base58编码过程:
2.1.2 Base58解码过程:
2.1.3 Base58Check编码过程:
2.1.4 Base58Check解码过程:
三、Base58编解码:
3.1 Base58 编码函数 encodeBase58
3.2 Base58 解码函数 decodeBase58
3.3 主函数 main
一、base58(58进制)
1.1 什么是base58?
Base58编码是在Base64字符集基础上,为了避免混淆而进行的优化。它去除了在Base64中可能引起混淆的字符,包括数字0、大写字母O、小写字母l、大写字母I,以及“+”和“/”两个符号。这样的设计使得Base58在视觉上更为清晰,减少错误。

Base58采用了一种相当别致的处理方法,它并未像Base16或Base64那样规律性的按位处理。相反,我们采用了一种称为"辗转相除法"的处理方式。这种方法虽然与传统方式不同,但却同样有效,进一步增强了编码的清晰度和可读性。
1.2 辗转相除法
欧几里得算法,也称为辗转相除法,是一种高效求解两个数最大公约数的方法。这种算法的核心思想在于:两个数的最大公约数等于其中较小的数与它们的差的最大公约数。这个算法不仅简洁,而且在数学和计算机科学中应用广泛。
Base58编码中,字符从'1'开始映射,其中'1'代表数字0,'2'代表数字1,一直到'z'代表数字57。这种映射策略有助于在编码时减少混淆,并保持数据的清晰易读。
对于将一个数字转换为Base58编码,我们用辗转相除法,这可以通过以下步骤来说明:
以数字1234为例,转换为58进制的过程如下:
- 将1234除以58,得到商21和余数16。根据Base58的编码表,余数16对应字符'H'。
- 接着将商21除以58,得到商0和余数21。根据Base58的编码表,余数21对应字符'N'。
因此,1234在Base58编码中表示为“NH”。
对于数字前有一个或多个0的情况,按Base58的编码规则,每一个0都直接转换为字符'1'。例如,如果数字是001234,那么在Base58编码中,它将表示为“11NH”。这里,前面的两个0分别转换为两个'1',紧接着是由1234转换来的“NH”。
1.3 base58输出字节数:
在Base58编码中,每个字符来自58个可选字符,因此每个字符需要表示的位数是log2(58),也即每个字符携带的信息量为log2(58)位。
对于输入的字节数据,其长度为(length * 8)位。所以,需要预留的字符数量就是(length * 8) / log2(58)。
换句话说,为了表示一个字节(8位)的信息,Base58编码需要的字符长度为1 / log2(58),即大约1.38个字符。这意味着每个Base58字符能够表示的信息比二进制编码要多,从而提高了编码效率。
二、源码分析:
2.1源代码:
实现了Base58编码与解码的相关功能,包括对输入的字节序列进行Base58编码、对Base58编码的字符串进行解码,并且包含了对Base58Check编码的支持(这是一种在Base58编码的基础上添加了校验和的编码方式,用于提高数据的传输可靠性)。
//版权信息 (c) 2014-2022 比特币核心开发者
//在MIT软件许可下分发,参见附带的
//复制文件或http://www.opensource.org/licenses/mit-license.php.#include <base58.h>
#include <hash.h>
#include <uint256.h>
#include <util/strencodings.h>
#include <util/string.h>
#include <assert.h>
#include <string.h>
#include <limits>// 使用无NUL包含的工具
using util::ContainsNoNUL;/** 所有的字母数字除了 "0", "I", "O", 和 "l" */
//定义一个Base58编码表
static const char* pszBase58 = "123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz"; //定义一个映射表,将输入字符映射为对应的整数值
static const int8_t mapBase58[256] = { -1,-1,-1,-1,-1,-1,-1,-1, -1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1, -1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1, -1,-1,-1,-1,-1,-1,-1,-1,-1, 0, 1, 2, 3, 4, 5, 6, 7, 8,-1,-1,-1,-1,-1,-1,-1, 9,10,11,12,13,14,15, 16,-1,17,18,19,20,21,-1,22,23,24,25,26,27,28,29, 30,31,32,-1,-1,-1,-1,-1,-1,33,34,35,36,37,38,39, 40,41,42,43,-1,44,45,46,47,48,49,50,51,52,53,54, 55,56,57,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1, -1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1, -1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1, -1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1, -1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1, -1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1, -1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1, -1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1, -1,-1,-1,-1,-1,-1,-1,-1,
};// 定义一个函数DecodeBase58,用于解码输入的Base58字符串,返回转换后的字节序列
[[nodiscard]] static bool DecodeBase58(const char* psz, std::vector<unsigned char>& vch, int max_ret_len)
{// 跳过前导空格while (*psz && IsSpace(*psz))psz++;// 跳过并计数前导的'1'sint zeroes = 0;int length = 0;while (*psz == '1') {zeroes++;if (zeroes > max_ret_len) return false;psz++;}// 在大端base256表示中分配足够的空间int size = strlen(psz) * 733 /1000 + 1; // log(58) / log(256), 向上取整std::vector<unsigned char> b256(size);// 处理字符static_assert(std::size(mapBase58) == 256, "mapBase58.size() should be 256"); // 保证不超出范围while (*psz && !IsSpace(*psz)) {// 解码base58字符int carry = mapBase58[(uint8_t)*psz];if (carry == -1) // 无效的b58字符return false;int i = 0;for (std::vector<unsigned char>::reverse_iterator it = b256.rbegin(); (carry != 0 || i < length) && (it != b256.rend()); ++it, ++i) {carry += 58 * (*it);*it = carry % 256;carry /= 256;}assert(carry == 0);length = i;if (length + zeroes > max_ret_len) return false;psz++;}// 跳过后导空格while (IsSpace(*psz))psz++;if (*psz != 0)return false;// 跳过b256中的前导零std::vector<unsigned char>::iterator it = b256.begin() + (size - length);// 将结果复制到输出向量vch.reserve(zeroes + (b256.end() - it));vch.assign(zeroes, 0x00);while (it != b256.end())vch.push_back(*(it++));return true;
}// 定义一个函数EncodeBase58,用于将输入的字节序列编码为Base58字符串
std::string EncodeBase58(Span<const unsigned char> input)
{// 跳过和计数前导零int zeroes = 0;int length = 0;while (input.size() > 0 && input[0] == 0) {input = input.subspan(1);zeroes++;}// 在大端base58表示中分配足够的空间int size = input.size() * 138 / 100 + 1; // log(256) / log(58), 向上取整std::vector<unsigned char> b58(size);// 处理字节while (input.size() > 0) {int carry = input[0];int i = 0;// 应用 "b58 = b58 * 256 + ch" for (std::vector<unsigned char>::reverse_iterator it = b58.rbegin(); (carry != 0 || i < length) && (it != b58.rend()); it++, i++) {carry += 256 * (*it);*it = carry % 58;carry /= 58;}assert(carry == 0);length = i;input = input.subspan(1);}// 在base58结果中跳过前导零std::vector<unsigned char>::iterator it = b58.begin() + (size - length);while (it != b58.end() && *it == 0)it++;// 将结果转化为字符串std::string str;str.reserve(zeroes + (b58.end() - it));str.assign(zeroes, '1');while (it != b58.end())str += pszBase58[*(it++)];return str;
}// 定义一个函数DecodeBase58,用于解码输入的Base58字符串,返回转换后的字节序列
bool DecodeBase58(const std::string& str, std::vector<unsigned char>& vchRet, int max_ret_len)
{if (!ContainsNoNUL(str)) {return false;}return DecodeBase58(str.c_str(), vchRet, max_ret_len);
}// 定义一个函数EncodeBase58Check,用于将输入的字节序列编码为添加了4字节hash校验的Base58字符串
std::string EncodeBase58Check(Span<const unsigned char> input)
{// 在结束处添加4字节的hash校验std::vector<unsigned char> vch(input.begin(), input.end());uint256 hash = Hash(vch);vch.insert(vch.end(), (unsigned char*)&hash, (unsigned char*)&hash + 4);return EncodeBase58(vch);
}[[nodiscard]] static bool DecodeBase58Check(const char* psz, std::vector<unsigned char>& vchRet, int max_ret_len)
{if (!DecodeBase58(psz, vchRet, max_ret_len > std::numeric_limits<int>::max() - 4 ? std::numeric_limits<int>::max() : max_ret_len + 4) ||(vchRet.size() < 4)) {vchRet.clear();return false;}// 重新计算校验和,确保它匹配包含的4字节校验和uint256 hash = Hash(Span{vchRet}.first(vchRet.size() - 4));if (memcmp(&hash, &vchRet[vchRet.size() - 4], 4) != 0) {vchRet.clear();return false;}vchRet.resize(vchRet.size() - 4);return true;
}bool DecodeBase58Check(const std::string& str, std::vector<unsigned char>& vchRet, int max_ret)
{if (!ContainsNoNUL(str)) {return false;}return DecodeBase58Check(str.c_str(), vchRet, max_ret);
}
2.2 算法思路介绍:
Base58编码是一种常用于加密货币地址和某些区块链应用中的编码方式,它使用了58个字符(排除了容易混淆的字符,如0(零)、O(大写的o)、I(大写的i)和l(小写的L)),以提供一种相对于Base64更容易人工阅读和手写的编码系统。
2.2.1 Base58编码过程:
- 计算输入数据的大小:输入数据(通常是一串字节)首先被评估以确定其长度和所需的编码空间大小。
- 处理前导零:Base58编码保留了输入数据中的前导零字节(0x00),每个前导零字节在编码字符串中用字符'1'表示。
- 转换为Base58:剩余的输入数据被转换为一个大整数,然后这个大整数被转换成Base58表示,即通过不断除以58并取余数的方式获得一系列的Base58字符。
- 拼接结果:最终的编码字符串由步骤2中处理的前导零(每个零用'1'表示)和步骤3的转换结果组成。
2.1.2 Base58解码过程:
- 校验并移除前导'1':解码首先会检查编码字符串中前导的'1'字符,并记录其数量,因为每个'1'代表一个前导零字节。
- Base58到大整数:然后将Base58编码字符串转换回一个大整数,即通过对每个Base58字符进行查表操作,获取对应的数值,并将这些数值以58为基数合并成一个大整数。
- 转换为字节序列:这个大整数随后被转换回原始的字节序列。
- 重建前导零:根据步骤1中记录的前导'1'的数量,在解码后的字节序列前加上相应数量的零字节。
2.1.3 Base58Check编码过程:
Base58Check是在Base58的基础上增加了错误检测的能力。它通常包括以下几个步骤:
- 计算校验和:对输入数据计算校验和(如,通过SHA-256算法计算两次,取前四个字节作为校验和)。
- 添加校验和:将这个校验和添加到原始数据的末尾。
- Base58编码:将步骤2得到的字节序列进行Base58编码。
2.1.4 Base58Check解码过程:
- Base58解码:首先对编码字符串进行Base58解码。
- 验证校验和:从解码结果中提取末尾四个字节作为校验和,与剩余数据重新计算的校验和进行比较。
- 提取数据:如果校验和匹配,说明数据未被篡改,去掉末尾四个字节的校验和,返回剩余的数据部分。
这些步骤中对前导零的特殊处理(编码中的'1'字符和解码时的零字节)是Base58和Base58Check编码的一个重要特性,确保了编码结果的唯一性和解码的准确性。
三、Base58编解码:
Base58编码和解码的实现。Base58是一种用于比特币等加密货币中的编码方案,它避开了某些视觉上容易混淆的字符,比如0(数字零)、O(大写字母O)、I(大写字母I)和l(小写字母L)。
#include <iostream>
#include <string>
#include <vector>
#include <algorithm>// 定义Base58编码的字符集
static const std::string BASE58_ALPHABET = "123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz";// Base58编码函数
std::string encodeBase58(const unsigned char* input, size_t len) {std::vector<unsigned int> digits(40, 0); // 用于存储Base58表示的向量,初始全为0size_t digits_len = 1; // 有效位数长度,初始为1// 对输入数据的每个字节进行处理for (size_t i = 0; i < len; i++) {unsigned int carry = input[i]; // 当前字节值for (size_t j = 0; j < digits_len; j++) {carry += digits[j] * 256; // 将当前值加到之前的结果digits[j] = carry % 58; // 计算Base58的当前位carry /= 58; // 更新进位}// 处理剩余的进位while (carry) {digits[digits_len++] = carry % 58;carry /= 58;}}std::string output;// 处理前导0的特殊情况,Base58用'1'表示前导0for (int i = 0; i < len && input[i] == 0; i++) {output += '1';}// 将计算得到的Base58位数转换为字符for (size_t i = 0; i < digits_len; i++) {output += BASE58_ALPHABET[digits[digits_len - 1 - i]];}return output; // 返回编码后的字符串
}// Base58解码函数
std::vector<unsigned char> decodeBase58(const std::string& input) {std::vector<unsigned char> output; // 初始化输出向量// 对输入的每个字符进行处理for (size_t i = 0; i < input.length(); i++) {int value = BASE58_ALPHABET.find(input[i]); // 查找字符在Base58字符集中的位置if (value == std::string::npos) {// 如果字符不在Base58字符集中,返回空向量表示解码失败return {};}for (size_t j = 0; j < output.size(); j++) {value += output[j] * 58; // 更新当前位output[j] = value % 256; // 计算当前位的值value /= 256; // 更新进位}// 处理剩余的进位while (value) {output.push_back(value % 256);value /= 256;}}// 处理前导'1'的特殊情况,对应前导0字节for (size_t i = 0; i < input.length() && input[i] == '1'; i++) {output.push_back(0);}// 逆转输出向量以匹配原始输入的顺序std::reverse(output.begin(), output.end());return output; // 返回解码后的字节向量
}int main() {const std::string input_data = "Hello, world!"; // 要编码的输入数据std::cout << "原始数据:" << input_data << "\n";// 调用编码函数std::string encoded = encodeBase58(reinterpret_cast<const unsigned char*>(input_data.data()), input_data.size());std::cout << "Encoded编码后: " << encoded << "\n";// 调用解码函数std::vector<unsigned char> decoded = decodeBase58(encoded);std::string decodedStr(decoded.begin(), decoded.end());std::cout << "Decoded解码后: " << decodedStr << "\n";return 0; // 返回0表示程序成功执行
}
3.1 Base58 编码函数 encodeBase58
这个函数用于将字节数组编码为Base58字符串。
- 输入:
const unsigned char* input, size_t len,表示输入的字节数组及其长度。 - 处理:
- 使用一个
vector<unsigned int>来临时存储计算的数字,这个向量的长度被初始化为40,足以处理常见的输入长度。 - 通过多重循环,将输入的字节转换为Base58编码。内部逻辑处理了进位,这对于任何基数的转换都是必需的。
- 处理前导0,因为Base58编码中前导0用'1'字符表示。
- 使用一个
3.2 Base58 解码函数 decodeBase58
这个函数用于将Base58编码的字符串解码回原始的字节数据。
- 输入:
const std::string& input,Base58编码的字符串。 - 处理:
- 初始化一个动态大小的
vector<unsigned char>用于存储解码的结果。 - 遍历输入的每一个字符,找出其在Base58字符集中的索引,这个索引值代表了其对应的数值。
- 通过计算和处理进位,将Base58编码转换回字节。
- 处理Base58编码中的前导'1',这些'1'在解码时应转换为前导0字节。
- 最后,由于解码过程中字节被逆向存储,需要将结果向量反转以恢复初始的字节顺序。
- 初始化一个动态大小的
3.3 主函数 main
- 功能: 测试
encodeBase58和decodeBase58函数,使用字符串"Hello, world!"作为输入。 - 输出:
- 显示原始数据。
- 显示编码后的Base58字符串。
- 显示解码后的字符串,应与原始输入相同。

相关文章:
【常见开源库的二次开发】基于openssl的加密与解密——Base58比特币钱包地址——算法分析(三)
目录: 目录: 一、base58(58进制) 1.1 什么是base58? 1.2 辗转相除法 1.3 base58输出字节数: 二、源码分析: 2.1源代码: 2.2 算法思路介绍: 2.2.1 Base58编码过程: 2.1.2 Base58解码过…...

Linux操作系统——数据库
数据库 sun solaris gnu 1、分类: 大型 中型 小型 ORACLE MYSQL/MSSQL SQLITE DBII powdb 关系型数据库 2、名词: DB 数据库 select update database DBMS 数据…...

【数据结构与算法】希尔排序:基于插入排序的高效排序算法
💓 博客主页:倔强的石头的CSDN主页 📝Gitee主页:倔强的石头的gitee主页 ⏩ 文章专栏:《数据结构与算法》 期待您的关注 目录 一、引言 二、基本原理 三、实现步骤 四、C语言实现 五、性能分析 1. 时间复杂度…...

关于正点原子的alpha开发板的启动函数(汇编,自己的认识)
我傻逼了,这里的注释还是不要用; 全部换成 /* */ 这里就分为两块,一部分是复位中断部分,第二部分就是IRQ部分(中断部分最重要) 我就围绕着两部分来展开我的认识 首先声明全局 .global_start 在 ARM 架…...

Deep Layer Aggregation【方法部分解读】
摘要: 视觉识别需要跨越从低到高的层次、从小到大的尺度以及从精细到粗略的分辨率的丰富表示。即使卷积网络的特征层次很深,单独的一层信息也不足够:复合和聚合这些表示可以改进对“是什么”和“在哪里”的推断。架构上的努力正在探索网络骨干的许多维度,设计更深或更宽的架…...
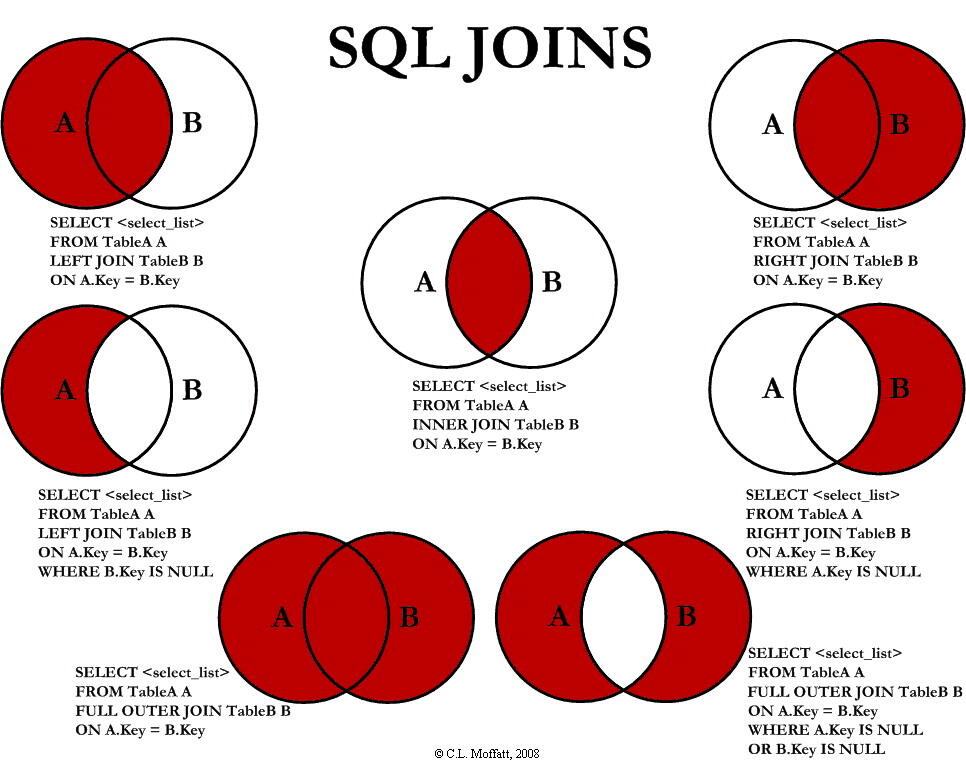
大数据面试SQL题-笔记01【运算符、条件查询、语法顺序、表连接】
大数据面试SQL题复习思路一网打尽!(文档见评论区)_哔哩哔哩_bilibiliHive SQL 大厂必考常用窗口函数及相关面试题 大数据面试SQL题-笔记01【运算符、条件查询、语法顺序、表连接】大数据面试SQL题-笔记02【...】 目录 01、力扣网-sql题 1、高频SQL50题(…...

零基础自学爬虫技术该从哪里开始入手?
零基础自学爬虫技术可以从以下几个方面入手: 一、学习基础编程语言 Python 是爬虫开发的首选语言,因此首先需要学习 Python 编程语言的基础知识。这包括: 语法基础:学习 Python 的基本语法,如变量定义、数据类型、控…...

CV11_模型部署pytorch转ONNX
如果自己的模型中的一些算子,ONNX内部没有,那么需要自己去实现。 1.1 配置环境 安装ONNX pip install onnx -i https://pypi.tuna.tsinghua.edu.cn/simple 安装推理引擎ONNX Runtime pip install onnxruntime -i https://pypi.tuna.tsinghua.edu.cn/si…...

Redis的使用(四)常见使用场景-缓存使用技巧
1.绪论 redis本质上就是一个缓存框架,所以我们需要研究如何使用redis来缓存数据,并且如何解决缓存中的常见问题,缓存穿透,缓存击穿,缓存雪崩,以及如何来解决缓存一致性问题。 2.缓存的优缺点 2.1 缓存的…...

BERT架构的深入解析
BERT(Bidirectional Encoder Representations from Transformers)是由Google在2018年提出的一种基于Transformer架构的预训练模型,迅速成为自然语言处理(NLP)领域的一个里程碑。BERT通过双向编码器表示和预训练策略&am…...

数字孪生技术如何助力低空经济飞跃式发展?
一、什么是低空经济? 低空经济,是一个以通用航空产业为主导的经济形态,它涵盖了低空飞行、航空旅游、航空物流、应急救援等多个领域。它以垂直起降型飞机和无人驾驶航空器为载体,通过载人、载货及其他作业等多场景低空飞行活动&a…...

HTTP背后的故事:理解现代网络如何工作的关键(二)
一.认识请求方法(method) 1.GET方法 请求体中的首行包括:方法,URL,版本号 方法描述的是这次请求,是具体去做什么 GET方法: 1.GET 是最常用的 HTTP 方法. 常用于获取服务器上的某个资源。 2.在浏览器中直接输入 UR…...

数据流通环节如何规避安全风险
由于参与数据流通与交易的数据要素资源通常是经过组织加工的高质量数据集,甚至可能涉及国家核心战略利益,一旦发生针对数据流通环节的恶意事件,将造成较大负面影响,对数据要素市场的价值激活造成潜在威胁。具体来说,数…...

部署k8s 1.28.9版本
继上篇通过vagrant与virtualBox实现虚拟机的安装。笔者已经将原有的vmware版本的虚拟机卸载掉了。这个场景下,需要重新安装k8s 相关组件。由于之前写的一篇文章本身也没有截图。只有命令。所以趁着现在。写一篇,完整版带截图的步骤。现在行业这么卷。离…...
实验二:图像灰度修正
目录 一、实验目的 二、实验原理 三、实验内容 四、源程序和结果 源程序(python): 结果: 五、结果分析 一、实验目的 掌握常用的图像灰度级修正方法,包括图象的线性和非线性灰度点运算和直方图均衡化法,加深对灰度直方图的理解。掌握对比度增强、直方图增强的原理,…...

bash: ip: command not found
输入: ip addr 报错: bash: ip: command not found 报错解释: 这个错误表明在Docker容器中尝试执行ip addr命令时,找不到ip命令。这通常意味着iproute2包没有在容器的Linux发行版中安装或者没有正确地设置在容器的环境变量PA…...

全开源TikTok跨境商城源码/TikTok内嵌商城/前端uniapp+后端+搭建教程
多语言跨境电商外贸商城 TikTok内嵌商城,商家入驻一键铺货一键提货 全开源完美运营 海外版抖音TikTok商城系统源码,TikToK内嵌商城,跨境商城系统源码 接在tiktok里面的商城。tiktok内嵌,也可单独分开出来当独立站运营 二十一种…...

云原生、Serverless、微服务概念
云原生(Cloud Native) 云原生是一种设计和构建应用程序的方法,旨在充分利用云计算的优势。云原生应用程序通常具有以下特征: 容器化:应用程序和其依赖项被打包在容器中,确保一致的运行环境。常用的容器技…...

Windows上LabVIEW编译生成可执行程序
LabVIEW项目浏览器(Project Explorer)中的"Build Specifications"就是用来配置项目发布方法的。在"Build Specifications"右键菜单中选取"New",可以看到程序有几种不同的发布方法:Application(EXE)、Installer、.Net Inte…...

ref 和 reactive 区别
在Vue 3中,ref和reactive都是用于创建响应式数据的API,但它们之间存在一些关键的区别。以下是ref和reactive的主要区别: 1. 数据类型处理 ref:主要用于定义基本类型的数据(如字符串、数字、布尔值等)以及…...

Docker 入门完全指南
Docker 入门完全指南 容器这东西,用上了就回不去了。比虚拟机轻,比装环境快,一套走天下。 先搞清楚几个概念 镜像(Image):只读模板,类似装系统的ISO容器(Container)&…...

终极Python SECS/GEM协议实现:5分钟构建半导体设备通信系统
终极Python SECS/GEM协议实现:5分钟构建半导体设备通信系统 【免费下载链接】secsgem Simple Python SECS/GEM implementation 项目地址: https://gitcode.com/gh_mirrors/se/secsgem secsgem是一个专为半导体制造行业设计的Python SECS/GEM协议实现库&#…...

基于YOLOv8的AI自瞄项目完整配置指南
基于YOLOv8的AI自瞄项目完整配置指南 【免费下载链接】RookieAI_yolov8 基于yolov8实现的AI自瞄项目 AI self-aiming project based on yolov8 项目地址: https://gitcode.com/gh_mirrors/ro/RookieAI_yolov8 RookieAI_yolov8是一个基于YOLOv8目标检测技术实现的AI自瞄项…...
)
7. 线程编程(线程概念和创建)
线程的创建 #include <pthread.h> int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*routine)(void *), void *arg); 成功返回0,失败时返回错误码 thread 线程对象 attr 线程属性,NULL代表默认属性 routine 线程执行…...

Keil MDK双J-Link并行调试实战指南
1. 双J-Link调试器并行使用场景解析在嵌入式开发过程中,我们经常会遇到需要同时调试多个目标板的情况。传统做法是频繁插拔调试器或使用调试器切换器,但这会显著降低开发效率。通过Keil MDK配合双J-Link调试器并行工作,可以完美解决这个痛点。…...

边缘视觉模型实战指南:ViT优化、多模态对齐与事件相机融合
1. 项目概述:这不是一份“论文清单”,而是一份实战派视觉工程师的周度技术雷达上周(2023年8月28日至9月3日)我像往常一样,在晨会前半小时打开arXiv、CVPR官网和几所顶尖实验室的GitHub更新页,准备快速扫一遍…...
)
从0到1搭建AI-PPT流水线,支持中英双语自动适配+品牌VI强制注入(含可运行Python脚本+Power Automate配置包)
更多请点击: https://intelliparadigm.com 第一章:从0到1搭建AI-PPT流水线,支持中英双语自动适配品牌VI强制注入(含可运行Python脚本Power Automate配置包) 本方案构建端到端自动化PPT生成流水线,输入结构…...

萌新学习第九天,python篇,内置函数
内置函数:一句话:Python 自带的、不需要A import 导入就可以直接使用的函数。比如你经常用的 print()、len()、input()、type() 都是内置函数。输出类:函数作用print()打印输出input()从键盘读取输入format()格式化字符串类型转换类:函数作用…...

使用workbuddy 30分钟搭建微信小程序
前言 今天发现一个超好用的工具WorkBuddy可以非常快速地进行搭建小程序,还有进行一些代码的修改,简直是一个开发小程序的好帮手,今天用一节很小的短篇介绍一下整个创建部署和搭建过程。 第一步下载workbuddy 创建小程序 首先需要下载work…...

tcpdump 核心选项与过滤表达式实战指南:从基础到高效网络排查
1. 从命令行到洞察力:为什么你需要精通 tcpdump如果你在运维、开发或者网络安全领域工作,网络问题排查几乎是你绕不开的日常。当服务调用超时、接口响应异常,或者流量出现诡异波动时,你需要的不是猜测,而是证据。tcpdu…...