基于京东电商蓝牙耳机产品评论数据的情感分析与文本分析
摘要
随着电子商务的迅速发展,了解用户对产品的意见和情感倾向对企业至关重要。本研究旨在利用Python大数据技术对电商产品评论进行情感分析和主题建模,为企业提供有价值的市场洞察。
通过爬虫获取电商评论数据,使用pandas清洗和预处理数据,结合jieba库进行中文分词,应用LDA模型进行主题建模,并结合snownlp库实现情感分析。分析结果可通过可视化展示直观了解产品的用户评价情况。
本研究为电商平台提供了产品评论的情感分析和主题建模工具,帮助企业了解用户意见和情感倾向,指导产品改进和市场决策。此外,该研究丰富了大数据技术在情感分析领域的应用,并为相关研究提供了理论和实践参考。通过本研究,企业可以更好地理解用户需求和市场趋势,提高产品质量和竞争力。
1 绪论
1.1 研究背景与目的意义
1.1.1 研究背景
随着互联网和电商市场的发展,人们越来越倾向于在网上购买商品。然而,在无法实际接触产品的情况下,消费者很难准确评估其质量和性能。因此,他们常常依赖其他消费者的产品评论和评价来做出购买决策[1]。
电商平台上的大量产品评论数据包含了丰富的用户意见和反馈。对企业来说,准确了解用户对产品的评价和情感倾向至关重要。然而,手动分析大规模的评论数据是繁琐且耗时的工作。因此,利用大数据技术进行电商产品评论的情感分析成为有效的解决方案[2]。
Python作为一种强大的编程语言,具备丰富的库和工具,可应用于大数据处理、文本挖掘和机器学习等领域。本研究将使用Python进行电商产品评论的情感分析,并结合多种技术和工具:使用requests库进行网络爬虫,从电商平台获取产品评论数据。使用pandas库处理和分析评论数据,清洗数据、去除噪音和处理缺失值等。使用matplotlib库进行数据可视化,通过图表展示不同情感类别的评论数量或比例,帮助理解用户对产品的评价情况。使用jieba库进行中文分词,结合LDA模型识别评论中的关键词和主题,了解用户对产品的关注点和意见。使用snownlp库进行情感分析,根据词语的情感倾向性判断评论是正面、负面还是中性情感。
通过以上技术的结合应用,我们能够深入挖掘电商产品评论数据中蕴含的信息,准确评估用户对产品的评价和情感倾向,为企业提供有价值的市场洞察和决策支持。这对于改善产品质量、提升用户满意度具有重要意义,也为研究者在大数据和情感分析领域提供了新的研究方向和实践应用[3]。
1.1.2 研究目的和意义
本研究的目的是基于Python大数据技术,利用电商产品评论数据进行情感分析。通过使用request爬虫获取评论数据,利用pandas进行数据分析和清洗,结合matplotlip实现数据可视化,以及jieba进行中文分词、LDA模型进行主题建模和snownlp进行情感分析,旨在深入挖掘用户对电商产品的评价和情感倾向。具体目标包括[4]:1)通过情感分析准确判断评论的情感倾向(正面、负面、中性),帮助企业了解用户满意度;2)利用LDA模型识别评论中的关键词和主题,揭示用户对产品的关注点和意见;3)通过数据可视化展示不同情感类别的评论数量或比例,直观呈现产品评价情况;4)为企业提供有价值的市场洞察和决策支持,促进产品改进和提升用户体验。通过这些目标,我们希望为电商平台的运营和产品优化提供科学依据,并推动大数据技术在情感分析领域的应用和研究。
1.2 国内外研究现状分析
1.2.1 国外研究现状
目前,在国外也有许多关于基于Python大数据的电商产品评论情感分析的研究。这些研究主要集中在以下几个方面:
数据获取和处理:类似于本研究使用的request爬虫技术,国外研究也采用网络爬虫从不同的电商平台获取评论数据。对于数据的处理和清洗,pandas库是常用的工具[5]。
分词和情感分析:jieba库在国内广泛应用于中文分词,而在国外,常见的分词工具包括NLTK和spaCy。此外,snownlp库在情感分析方面有很好的表现,但国外的研究更倾向于使用其他自然语言处理(NLP)技术,如词嵌入(word embeddings)和深度学习模型[6]。
主题建模:国外研究也使用LDA模型进行主题建模,以揭示电商产品评论中的关键词和主题。然而,一些研究还引入了其他主题模型,如隐含狄利克雷分布(Latent Dirichlet Allocation, LDA)的变体,以提高建模效果[7]。
数据可视化:与matplotlip库类似,国外的研究使用各种数据可视化工具和库,如D3.js、Plotly和Tableau等,以展示情感分析结果和评论数据的可视化效果[8]。
1.2.2 国内研究现状
随着电商行业的快速发展,对于电商产品评论的情感分析在学术界和实际应用中受到了广泛关注。国内许多研究者在此领域进行了深入研究,并应用了多种技术和模型来进行情感分析。
在技术方面,大多数研究采用了Python作为主要编程语言,并利用request爬虫技术获取大量的电商产品评论数据。数据分析阶段,研究者普遍使用pandas库来处理和清洗数据,使其适合进一步的分析。数据可视化方面,matplotlip被广泛用于绘制图表,以便更直观地展示情感分析结果[9]。
在情感分析方法中,分词技术是一个重要的环节,研究者常常使用jieba库对评论文本进行分词处理,以便后续的情感判断。此外,LDA模型(Latent Dirichlet Allocation)也被广泛应用于评论主题建模,从而揭示出不同主题下的情感倾向。
另外,snownlp情感分析是一种常见的基于机器学习的方法,它可以通过训练模型对文本进行情感分类。这种方法可以有效地分析大规模的评论数据,并得出情感倾向[10]。
然而,国内研究在电商产品评论情感分析方面还存在一些不足之处。首先,由于数据获取和处理的复杂性,许多研究仅限于小规模的数据集,缺乏对大规模数据的深入分析。其次,目前的情感分析方法主要依赖于人工标注的情感词典或监督学习算法,对于特定领域的电商评论可能存在一定的局限性。因此,如何提高情感分析的准确性和适用性仍然是一个值得探索的问题。
1.3 主要研究方法
该研究基于Python大数据技术,旨在进行电商产品评论的情感分析。以下是该研究的主要研究方法:
数据获取:使用request爬虫技术从电商平台上抓取大量的产品评论数据。通过发送HTTP请求,并解析网页内容,将评论数据保存为文本文件或数据库。
数据清洗和处理:使用pandas库对获取的评论数据进行清洗和预处理。这包括去除重复评论、处理缺失值、去除特殊字符等操作,以确保数据的准确性和一致性。
分词处理:使用jieba库对评论文本进行中文分词。将长句子切分成独立的词语,以便后续的情感分析。分词可以帮助提取评论中的关键词和表达,进而揭示情感倾向。
情感分析模型:采用LDA模型(Latent Dirichlet Allocation)来进行评论主题建模和情感分析。LDA模型能够自动发现文本中的主题,并通过计算每个主题的情感倾向得出整体情感分析结果。
情感分类:使用snownlp情感分析工具进行情感分类。该工具基于机器学习算法,通过训练模型对文本进行情感判断,将评论分类为正面、负面或中性。
数据可视化:使用matplotlip库对情感分析结果进行可视化展示。通过绘制图表和图形,直观地呈现不同情感类别的分布情况和趋势变化。
2 相关技术
2.1 数据采集技术
2.2 可视化技术
2.3 情感分析技术
2.4 LDA主题分析技术
3 数据采集与数据处理
3.1 数据采集流程及实现
表3.1 数据集字段信息
| 序号 | 字段 |
| 1 | 用户名 |
| 2 | 颜色 |
| 3 | 评论内容 |
| 4 | 评论时间 |
| 5 | 会员等级 |
| 6 | 评分 |
| 7 | 点赞数 |
| 8 | 配置 |
| 9 | 地区 |
3.2 数据清洗与预处理实现
3.2.1 数据集信息展示并去重
3.2.2 数据替换和拆分列
3.2.3 筛选和清洗评论内容
4 数据的初步分析
4.1 数据分析和可视化思路
4.2 词频分析
通过对清洗后的评论数据进行处理,使用df['配置']获取列中的数据。然后,根据需要进行数据清洗和预处理操作,例如替换特殊字符、去除空格等,以确保数据符合词云图生成的要求。接着,使用结巴分词库(jieba)对配置数据进行分词,将配置内容拆分成单个词语,并保存在tokenized_comments列表中。进一步,使用Counter类进行词频统计,生成词频字典count_dict,其中键为词语,值为词频。最后,创建词云对象,并基于词频字典count_dict生成词云图。设置词云图的参数,例如字体、大小、背景颜色等,以便更好地展示词云效果。
生成列的词云图有助于直观地了解评论中的高频配置信息。词云图通过词语的大小和颜色来展示词频的差异,越大和鲜艳的词语表示其在评论中出现的频率越高。这样做的目的是为了从大量的评论数据中提取和展示与产品配置相关的关键词汇,帮助分析人员更快速地捕捉到用户对配置的关注点和评价。通过词云图,可以直观地了解用户对不同配置的反馈情况,为产品改进、市场定位等方面提供有价值的参考和洞察。配置列词云图如图4.1所示,评论信息词云图如图4.2所示。

图4.1 配置列词云图
通过配置列的词云图结果,我们可以了解用户对不同配置方面的关注点和评价。这有助于产品团队了解用户需求、改进产品配置。以下是词云图解读:
配置词汇多样性:词云图展示了评论中出现频率较高的配置词汇。从结果中可以看出,涵盖了多种配置选项,如经典、升级、冰川、黑色、降噪等。这表明用户对不同配置方面有着丰富的需求和评价。
热门配置特征:词云图中出现频率较高的词语可能代表热门或受关注的配置特征。例如,升级、降噪、全功能、旗舰、版等词语出现频率较高,说明用户对这些配置特征有较高的关注度和期望。
品牌特征:品牌名如小米也在词云图中出现,表示用户对该品牌的产品配置进行了评价和讨论。

图4.2 评论信息词云图
通过对评论信息词云图结果的解读,可以得出用户对产品的质量、功能、性价比和购买体验等方面持有较高的评价。这对于产品改进、市场推广和用户满意度提升具有重要参考价值。同时,也反映了用户关注点的分布情况,为产品设计和营销策略提供了指导。以下是词云图的结果解读:
用户评价方面:评论中出现频率较高的词汇包括做工、质感、不错、舒适度、佩戴、续航、音质、音效等。这表明用户对产品的外观质量、舒适性、音质效果以及续航能力等方面给予了较高的评价。
功能特点:词云图中出现频率较高的词汇有降噪、耳机、无线、蓝牙、耳塞等。这显示用户对产品的降噪功能、无线连接和蓝牙技术等功能特点持有较高的评价和兴趣。
性价比:词云图中出现频率较高的词汇有性价比、值得、推荐、物美价廉、实惠等。这说明用户认为产品具有较高的性价比,价格合理且物有所值。
质量与服务:用户评论中出现了质量、服务、物流、快递等词汇。这表明用户对产品质量和购买体验的评价较高,对店家的服务态度和快递速度也给予了正面评价。
4.3 评论时间分布分析
为了了解评论的时间分布情况,探索用户在不同时间段发表评论的趋势和特点。通过评论时间分布分析,可以帮助企业更好地了解用户活跃的时间段、产品的受欢迎程度等信息,从而优化营销策略、调整产品发布时间以及提升用户满意度。此外,还可以发现评论数量的高峰期和低谷期,为客服资源的分配和运营活动的安排提供指导。通过提取评论数据中的时间信息,并转换为日期格式。使用
然后,通过groupby()函数按照年份和月份对评论进行分组,并使用size()函数统计每个分组中的评论数量。最后,通过绘制折线图或柱形图,展示评论数量随时间变化的趋势。评论时间分布图如图5.3所示。

图4.3 评论时间分布
通过评论时间分布的结果,我们可以了解用户在不同时间段对产品进行评论的趋势和特点。这对于企业来说具有重要意义,可以根据不同时间段的评论活跃度,合理安排客服人员的工作时间和加强营销策略的投放时段,以更好地满足用户需求并提升用户体验。根据评论时间分布结果,可以得出以下结论:
评论数量高峰期:从数据中可以看出,评论数量在早上9时至晚上10时之间达到了较高的峰值。尤其是上午10时和晚上8时至9时之间,评论数量最多。
评论数量低谷期:评论数量在凌晨4时至5时之间达到了较低的水平,此时用户发表评论的活跃度较低。
用户活跃时间段:根据数据,可以看出用户在白天和晚上的时间段更为活跃,尤其是上午9时至下午5时和晚上8时至10时,这可能与用户在工作、学习之余进行购物和评价有关。
4.4 评论地区分布分析
为了了解用户评论的地域分布情况。通过评论地区分布分析,可以帮助企业了解用户所在地区对产品的评价和反馈,从而更好地针对地域特点调整营销策略、优化产品设计或改进服务。此外,还可以发现哪些地区的用户对产品表达了较高的兴趣和参与度,为市场扩张和品牌推广提供指导和决策支持。通过提取评论数据中的地区信息,可以使用df['地区'].value_counts()对地区进行统计,得到每个地区出现的评论数量。
接着,可以根据需要,使用head()函数获取前几个地区的评论数量或者使用plot(kind='bar')绘制柱形图来展示不同地区评论的分布情况评地区分布图如图4.4所示。

图4.4 评论地区分布
根据提评论地区统计结果,可以得出以下结论:
用户分布范围:从数据中可以看出,用户的评论地区涵盖了中国的各个省份和部分海外地区,包括上海、北京、广东、山东等。其中,广东、北京、山东、江苏和四川是评论数量较高的地区。
地域差异:不同地区的评论数量存在差异。例如,广东、北京和山东的评论数量相对较高,可能与这些地区的人口数量和经济发展水平有关。
市场潜力:通过评论地区的分布情况,可以发现一些地区的用户对产品表达了较高的兴趣和参与度,如广东、北京和山东。这为企业在市场推广和品牌扩张方面提供了一定的指导和决策支持。
4.5 评论情感分析分布
情感分析部分使用了SnowNLP库,通过对评论内容进行情感分析来判断评论的情感倾向(积极、中性或消极)。首先,将清洗后的评论数据转化为SnowNLP对象,并调用sentiments方法获取情感分析得分。根据得分的大小,将评论归类为积极、中性或消极。
情感分析在文本挖掘和社交媒体分析等领域具有重要应用。通过情感分析,可以了解用户对产品、服务或事件的情感态度,从而帮助企业和机构了解用户需求、改进产品、优化服务等。此外,情感分析还可以用于舆情监测、品牌管理、市场研究等领域,为决策提供参考依据。情感分析结果如图4.5所示。

图4.5 情感分析分布
对于蓝牙耳机的评论数据进行了情感倾向的分类。结果显示:
从情感分析结果来看,中性评论数量最多,积极评论数量次之,而消极评论数量最少。这表明大部分用户对蓝牙耳机的评价是中性的,少部分用户持有积极的态度,相对较少的用户持有消极的态度。
基于这一结论,可以进一步分析中性评论中的关键词和主题,以了解用户对蓝牙耳机的具体意见和需求。同时,也需要重点关注消极评论,分析其中的问题和不满之处,以改进产品或服务。积极评论则可以作为宣传推广的参考,强调产品的优点和用户体验。
5基于LDA模型的主题分析
5.1 LDA主题模型介绍
LDA(Latent Dirichlet Allocation)是一种生成式概率模型,用于从文本数据中发现潜在的主题。它基于以下假设:每个文档都由多个主题组成,每个主题又由词汇表中的单词组成。
LDA的目标是根据观察到的文档和单词之间的关联关系,推断出文档的主题分布和单词的主题分布。以下是LDA的基本原理:
建立基本假设:
文档-主题分布:每个文档都可以表示为一个主题分布,其中每个主题的权重表示该文档包含该主题的概率。
主题-单词分布:每个主题都可以表示为一个单词分布,其中每个单词的权重表示该主题包含该单词的概率。
模型生成过程:
对于每个文档,从主题-单词分布中采样一个主题分布。
对于文档中的每个位置(单词),从文档的主题分布中采样一个主题。
从被选中的主题的主题-单词分布中采样一个单词。
模型参数估计:
目标是通过最大化似然函数来估计模型参数,即找到最优的主题分布和主题-单词分布。
通常使用变分推断或Gibbs采样等方法进行参数估计。
LDA模型可以用以下公式表示:
P(文档∣模型)=∫P(文档∣主题分布)⋅P(主题分布∣模型)d主题分布
P(主题分布∣模型)=Dirichlet(α)
P(单词∣主题分布,模型)=∫P(单词∣主题,模型)⋅P(主题∣主题分布)d主题
P(主题∣主题分布)=Dirichlet(β)
其中,α 和 β 是超参数,Dirichlet是狄利克雷分布。这些公式描述了文档生成过程和模型参数之间的关系。
通过LDA模型,我们可以从文本数据中学习到主题的分布以及单词与主题之间的关联。这使得我们能够揭示文档集合中的潜在主题,并根据主题分布对文档进行分类、文本摘要、推荐等任务。
5.2 聚类分析寻找最优主题数
聚类分析部分使用了KMeans算法,通过对评论数据进行聚类,将相似的评论归为同一类别。首先,使用TfidfVectorizer对评论数据进行TF-IDF转换,将文本数据转化为数值表示。然后,使用KMeans算法对转换后的数据进行聚类,并选择最优聚类数。聚类分析可以帮助我们发现数据中存在的内在结构和模式。在文本数据中,聚类分析可以将相似的评论归类在一起,从而识别出不同的主题或用户群体。这有助于我们了解用户对蓝牙耳机的不同观点、需求或偏好。
通过聚类分析,可以发现具有相似特征的评论组成的簇,从而更好地理解用户的反馈和评价。聚类结果可以帮助企业了解产品的不同方面和用户群体,为产品改进、定位、推广等决策提供指导。此外,聚类分析还可以用于市场细分、用户分类和个性化推荐等应用领域。聚类分析结果如图5.1所示。
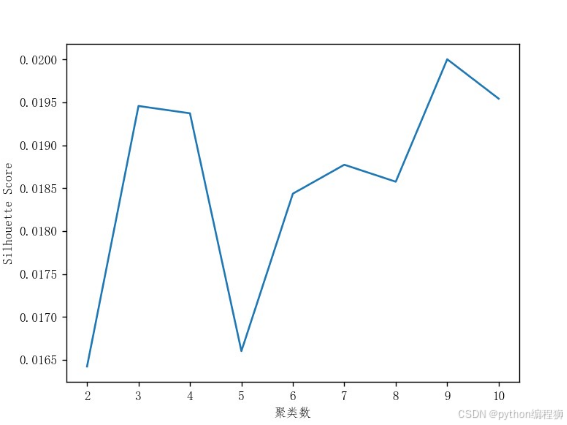
图5.1 聚类分析
横轴为聚类簇数的变化,纵轴为数据的凝聚度(SSE方差),当凝聚度的大小随着K值得增多降低数量较小时,证明,K值得增加对凝聚度的影响变小,那么选择拐点的K值是可行的,因为继续增加K值,对分类的准确度增加不高,但是会增加分类的簇数,根据需求,如果划分过细,对分类也并不利,因此不划算,所以选择拐点处K值。此处K值为5,即选择5个主题最为合适。
5.3 LDA主题分析实现
LDA主题分析部分使用了gensim库中的LdaModel模型,通过对评论数据进行主题建模和分析,识别出潜在的主题以及每个主题关键词的权重。
LDA(Latent Dirichlet Allocation)是一种用于主题建模的概率图模型,它可以帮助我们从大量文本数据中发现隐藏的主题结构。LDA将文档看作是各个主题的混合,并假设每个主题都是由一组词汇构成的。通过对文档进行建模,LDA可以推断出主题和单词之间的分布关系。
首先将清洗后的评论数据转换为词袋表示形式,并创建一个字典来映射词语和编号。然后,使用LdaModel模型对词袋进行训练,并设置主题数量为5,迭代次数为10次。最后,使用print_topics方法打印每个主题的关键词和权重,并将结果保存到DataFrame和Excel文件中。
通过LDA主题分析,我们可以更好地理解评论数据中存在的潜在主题,了解用户对蓝牙耳机的评价涵盖的方面,并发现不同主题之间的差异。LDA主题分析结果如表5.1所示。
表5.1 LDA主题分析结果
| Topic0 | Topic1 | Topic2 | Topic3 | Topic4 |
| "音效" | "耳机" | "音质" | "耳机" | "颜值" |
| "音质" | "音质" | "耳机" | "蓝牙" | "耳机" |
| "续航" | "蓝牙" | "舒服" | "音质" | "音质" |
| "舒适度" | "不错" | "京东" | "降噪" | "喜欢" |
| "质感" | "小米" | "下单" | "漫步者" | "红米" |
| "做工" | "听歌" | "续航" | "入耳式" | "入耳" |
| "不错" | "颜值" | "充电" | "戴久" | "不错" |
| "耳机" | "待机时间 | "杂音" | "颜值" | "漫步者" |
| "发货" | "充电" | "佩戴" | "高音质" | "过电" |
| "服务态度" | "漫步者" | "小巧" | "听歌" | "物美价廉 |
根据LDA主题分析的结果,可以得出以下结论:
主题0:音效、音质、续航、舒适度等是评论中经常提及的关键词。这表明用户对耳机的声音质量、音效体验、电池续航和佩戴舒适度比较关注。
主题1:耳机、音质、蓝牙、不错等是评论中的关键词。用户在评论中谈到了产品的音质、蓝牙连接、以及用户对于商品的使用感受。
主题2:京东、音质、舒适、耳机、等是评论中的关键词。用户关注购买渠道(如京东)寻找一款音质好、穿戴舒适的耳机等。
主题3:耳机、音质、蓝牙、降噪等是评论中的关键词。以推断用户对产品的需求是一款具备优质音质、支持蓝牙无线连接以及具备降噪功能的耳机。用户可能希望通过蓝牙连接便捷地使用耳机,并且希望耳机具备降噪功能,以提供更好的音频体验。
主题4:颜值、耳机、音质、喜欢、等是评论中的关键词。可以推断用户对产品的需求是一款不仅外观设计出色(颜值高),同时具备优质音质的耳机。用户可能希望购买一款耳机,不仅能够提供出色的音频体验,还能够与自己的审美偏好相符合,让自己喜欢上这款产品。所以,用户可能对于产品的外观设计、音质性能非常看重,并且希望能够找到一款能够满足自己喜好的耳机。
从LDA主题分析的结果来看,用户在评论中对蓝牙耳机主要关注音质、续航、舒适度等方面的体验。同时,用户也关注待机时间、服务态度以及耳机的性价比等因素。这些结果可以帮助企业了解用户的需求和评价,为产品改进、市场推广等方面提供参考依据。
6 总结与展望
6.1总结
本研究利用Python大数据技术对电商产品评论进行情感分析和主题建模,旨在为企业提供有价值的市场洞察。通过爬虫获取评论数据,使用pandas进行数据处理和分析,结合jieba库进行中文分词,应用LDA模型进行主题建模,并结合snownlp库实现情感分析。通过对评论数据的处理和分析,我们得出了以下结论:
通过词云图结果,我们了解了用户对不同配置方面的关注点和评价。这有助于产品团队了解用户需求、改进产品配置。同时,我们还发现用户对热门配置特征以及品牌特征有较高的关注度。
评论时间分布的结果显示,评论数量在早上9时至晚上10时之间达到峰值,尤其是上午10时和晚上8时至9时之间评论数量最多。这为企业合理安排客服人员的工作时间和加强营销策略的投放时段提供了依据。
评论地区分布的结果表明,用户的评论地区涵盖了中国各个省份和部分海外地区。其中,广东、北京、山东、江苏和四川是评论数量较高的地区。这为企业在市场推广和品牌扩张方面提供了决策支持。
情感分析的结果显示,大部分用户对产品的评价是中性的,少部分用户持有积极的态度,而消极评论数量最少。这为企业了解用户对产品的整体评价和情感倾向提供了指导。
LDA主题分析的结果表明,用户在评论中关注音质、续航、舒适度等方面的体验。同时,用户也关注待机时间、服务态度以及耳机的性价比等因素。这些结果可以帮助企业了解用户的需求和评价,并为产品改进、市场推广等方面提供参考依据。
6.2展望
尽管基于Python大数据技术的电商产品评论情感分析方法具有广泛的应用前景,但也存在一些局限性和不足之处:
1、数据采集问题:爬取电商平台的评论数据可能受到反爬虫机制的限制,因此需要寻找合适的解决方案来获取更全面和准确的评论数据。
2、情感分析精度:目前的情感分析算法仍然面临一些挑战,例如处理语义复杂性、理解上下文等方面。进一步改进和优化情感分析算法可以提高情感分析的准确性和稳定性。
3、主题建模的优化:在LDA主题建模中,选择合适的主题数目仍然是一个挑战。未来的研究可以探索更多的方法来确定最佳的主题数目,以获得更准确和有意义的主题模型。
未来的研究可以从以下几个方面进行拓展:
1、结合其他算法:探索结合深度学习和自然语言处理技术的方法,如使用神经网络模型进行情感分析和主题建模,以提高模型的性能和准确性。
2、多模态情感分析:将图像、音频等多模态数据与文本评论相结合,进行多模态情感分析,以更全面地了解用户对产品的评价和反馈。
3、用户个性化分析:考虑用户个体差异,通过用户画像和用户行为数据,实现对不同用户群体的个性化情感分析和推荐。
[1]贺海玉.大数据下的网络评论情感分析研究与实现[J].电脑知识与技术,2023,19(18):64-66.DOI:10.14004/j.cnki.ckt.2023.0852.
[2]彭梅,胡必波.基于大数据人工智能的电商用户评论情感分析[J].电脑编程技巧与维护,2022(06):123-126.DOI:10.16184/j.cnki.comprg.2022.06.014.
[3]黄岩岩. 网络评论数据的文本情感分析[D].苏州大学,2023.DOI:10.27351/d.cnki.gszhu.2021.003444.
[4]郭浩翔. 基于大数据的评论文本情感分析方法研究[D].太原理工大学,2022.DOI:10.27352/d.cnki.gylgu.2021.000649.
[5]郝志恒. 笔记本电脑产品在线评论数据的情感分析[D].中南财经政法大学,2023.DOI:10.27660/d.cnki.gzczu.2021.002241.
[6]张公让,鲍超,王晓玉等.基于评论数据的文本语义挖掘与情感分析[J].情报科学,2021,39(05):53-61.DOI:10.13833/j.issn.1007-7634.2021.05.008.
[7]张美颀.基于电商产品评论数据的情感分析[J].电子技术与软件工程,2020(11):186-187.
[8]梁艳秋. 面向电子商务评论数据的文本情感分析[D].湘潭大学,2021.DOI:10.27426/d.cnki.gxtdu.2020.001511.
[9]李怀玉. 基于大数据的用户评论情感分析[D].华北电力大学(北京),2019.
[10]崔志刚. 基于电商网站商品评论数据的用户情感分析[D].北京交通大学,2015.
相关文章:
基于京东电商蓝牙耳机产品评论数据的情感分析与文本分析
摘要 随着电子商务的迅速发展,了解用户对产品的意见和情感倾向对企业至关重要。本研究旨在利用Python大数据技术对电商产品评论进行情感分析和主题建模,为企业提供有价值的市场洞察。 通过爬虫获取电商评论数据,使用pandas清洗和预处理数据&a…...
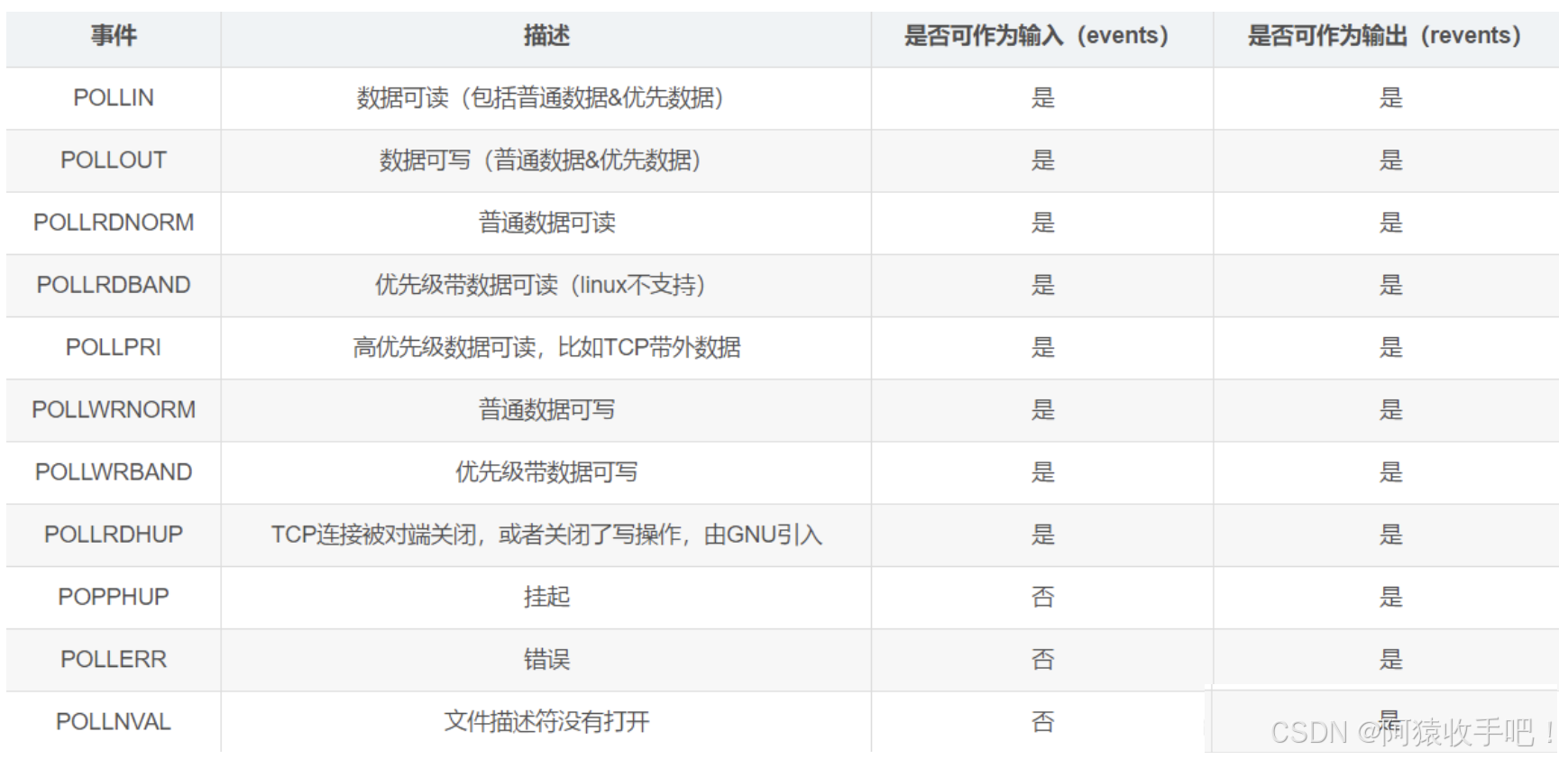
【Linux网络】poll{初识poll / poll接口 / poll vs select / poll开发多客户端echo服务器}
文章目录 1.初识pollpoll与select的主要联系与区别poll的原理poll的优点poll的缺点poll vs select 2.poll开发多客户端echo服务器封装套接字接口Makefile主函数日志服务聊天服务器 1.初识poll poll是Linux系统中的一个系统调用,它用于监控多个文件描述符(…...
数据库db文件损坏修复方法(sqlite3:database disk image is malformed)
参考博客: https://www.cnblogs.com/liuyangQAQ/p/18037546 sqlite3数据库提示database disk image is malformed 解决办法-CSDN博客 【SQL】sqlite数据库损坏报错:database disk image is malformed(已解决)-CSDN博客 一、第…...

Prometheus 云原生 - 微服务监控报警系统 (Promethus、Grafana、Node_Exporter)部署、简单使用
目录 开始 Prometheus 介绍 基本原理 组件介绍 下文部署组件的工作方式 Prometheus 生态安装(Mac) 安装 prometheus 安装 grafana 安装 node_exporter Prometheus 生态安装(Docker) 安装 prometheus 安装 Grafana 安装…...

Spring源码注解篇三:深入理解@Component注解
Component及其派生注解的源码 Spring框架作为Java开发中不可或缺的一部分,其依赖注入机制的核心是通过注解来实现的。本文将深入探讨Spring中Component及其派生注解的源码实现,分析Spring如何通过类路径扫描(Classpath Scanning)和…...
SpringBoot中常用的注解及其用法
1. 常用类注解 RestController和Controller是Spring中用于定义控制器的两个类注解. 1.1 RestController RestController是一个组合类注解,是Controller和ResponseBody两个注解的组合,在使 用 RestController 注解标记的类中,每个方法的返回值都会以 JSON 或 XML…...
【大语言模型】私有化搭建-企业知识库-知识问答系统
下面是我关于大语言模型学习的一点记录 目录 人工智能学习路线 MaxKB 系统(基于大语言模型的知识问答系统) 部署开源大语言模型LLM 1.CPU模式(没有好的GPU,算力和效果较差) 2.GPU模式(需要有NVIDIA显卡支持) Ollama网络配置 Ollama前…...

CSS常用的样式
字体和文本样式 font-family: 定义文本字体。 font-size: 设置字体大小。 color: 设置文本颜色。 text-align: 水平对齐文本(左对齐、右对齐、居中、两端对齐)。 line-height: 设置行间距。 text-decoration: 控制文本装饰线(如下划线、…...
结合实体类型信息(2)——基于本体的知识图谱补全深度学习方法
1 引言 1.1 问题 目前KGC和KGE提案的两个主要缺点是:(1)它们没有利用本体信息;(二)对训练时未见的事实和新鲜事物不能预测的。 1.2 解决方案 一种新的知识图嵌入初始化方法。 1.3 结合的信息 知识库中的实体向量表示+编码后的本体信息——>增强 KGC 2基…...
如何在电脑上演示手机上APP,远程排查移动端app问题
0序: 对接客户,给领导演示移动端产品,或者远程帮用户排查移动端产品的问题。都需要让别人能够看到自己在操作手机。 会议室可以使用投屏,但需要切换电脑和手机。 排查问题经常都是截图、或者手机上录制视频,十分繁琐…...
SQL Server 创建用户并授权
创建用户前需要有一个数据库,创建数据库命令如下: CREATE DATABASE [数据库名称]; CREATE DATABASE database1; 一、创建登录用户 方式1:SQL命令 命令格式:CREATE LOGIN [用户名] WITH PASSWORD 密码; 例如,创建…...
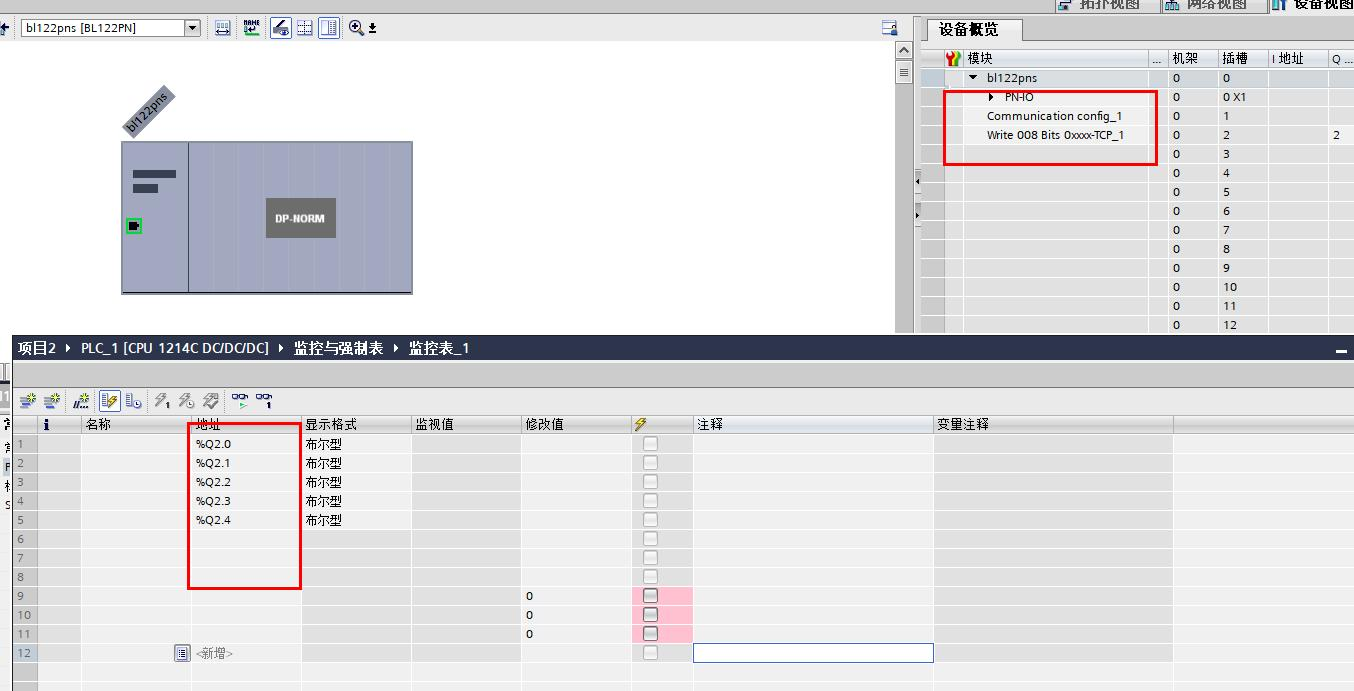
网关设备BL122实现Modbus RTU/TCP转Profinet协议
Modbus与Profinet是两种广泛应用于工业自动化领域的通信协议:Modbus因其简单性和兼容性,在许多工业设备中得到广泛应用;而Profinet提供了高速、高精度的通信能力,适合于复杂控制系统和实时应用,但两者之间的差异导致了…...

采购管理软件:改善初创企业的采购流程
说到初创企业,人们往往会联想到一个宽松的工作环境,缺乏严格的流程规范,以及公司收入的迅猛增长。这种快速增长可能会被认为会导致工作流程的无序和缺乏结构,使得员工在决策上具有较大的自由度,例如在采购方面。 在这…...

Python 是一种用途广泛的编程语言,应用于各个领域
1. 网络和互联网开发: Python 拥有丰富的框架和库,使其成为 Web 开发的理想选择。 框架: Django 和 Pyramid 用于构建复杂的 Web 应用。Flask 和 Bottle 则适合轻量级应用和 API。 库: Python 标准库支持处理 HTML、XML、JSON 和电子邮件。此外,还有强大…...

【VUE】9、VUE项目中使用VUEX完成状态管理
Vuex 是一个专为 Vue.js 应用程序设计的状态管理模式,它帮助开发者更有效地管理组件间共享的状态。在 Vue 项目中使用 Vuex,可以解决复杂应用中状态管理的困扰,确保状态变更的可追踪性和一致性。 1、Vuex 核心概念 State(状态&a…...
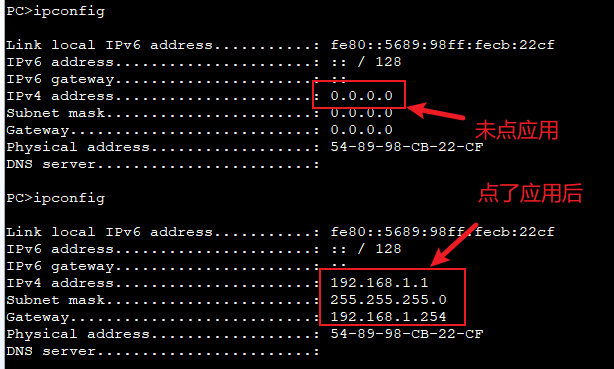
【eNSP模拟实验】单臂路由实现VLAN间通信
实验需求 如下图所示,辅导员办公室需要访问处在不同vlan的学生管理服务器的文件,那么如何实现两台终端相互通信呢?我们可以使用单臂路由的方式来实现。 单臂路由(router-on-a-stick)是指在路由器的一个接口上通过配置…...

哪些点权衡素材优秀与否
投放信息流素材的过程当中,我们究竟看哪几点来权衡这个素材是优秀的还是不优秀的?我们主要是以三个维度来看。 第一个就是 3 秒和 5 秒的完播率。很多优秀的素材它可能在前三秒和前五秒很平淡的一个过程,但是因为现在是一个非常快节奏的过程&…...

服务器数据恢复—2块硬盘离线且热备盘未完全激活的raid5数据恢复案例
服务器存储数据恢复环境: 北京某企业一台EMC FCAX-4存储上搭建一组由12块成员盘的raid5磁盘阵列,其中包括2块热备盘。 服务器存储故障: raid5阵列中两块硬盘离线,热备盘只有一块成功激活,raid瘫痪,上层LUN…...
Excel 学习手册 - 精进版(包括各类复杂函数及其嵌套使用)
作为程序员从未想过要去精进一下 Excel 办公软件的使用方法,以前用到某功能都是直接百度,最近这两天跟着哔哩哔哩上的戴戴戴师兄把 Excel 由里到外学了一遍,收获良多。程序员要想掌握这些内容可以说是手拿把掐,对后续 Excel 的运用…...

【CUDA】thrust进行前缀和的操作
接上篇文章,可以发现使用CUDA提供的API进行前缀和扫描时,第一次运行的时间不如共享内存访问,猜测是使用到了全局内存。 首先看调用逻辑: thrust::inclusive_scan(thrust::device, d_x, d_x N, d_x);第一个参数指定了设备&#x…...

团队协作AI编程工具怎么选?最新热门AI编程助手实测推荐
团队协作AI编程工具怎么选?最新热门AI编程助手实测推荐开篇“团队协作时,AI编程工具怎么选才能统一代码规范、减少沟通成本?”“新手加入团队,有没有能快速适配团队代码风格、降低上手难度的AI编程助手?”“多人协同开…...

布局先行、技术深耕:国内端侧AI企业抢滩机器人与具身智能赛道
具身智能作为AI与物理世界交互的核心方向,正成为工业智能化、人形机器人落地的关键抓手。国内一批端侧AI企业凭借原生技术优势,早早入局机器人与具身智能领域,以全栈技术、规模化落地与生态共建,抢占行业先发优势。其中࿰…...

KMS_VL_ALL_AIO:智能激活脚本的完整使用指南
KMS_VL_ALL_AIO:智能激活脚本的完整使用指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO KMS_VL_ALL_AIO是一款基于微软官方KMS协议开发的智能激活脚本,为Windows系统…...

Windows 11 LTSC版终极解决方案:三分钟恢复完整Microsoft Store体验
Windows 11 LTSC版终极解决方案:三分钟恢复完整Microsoft Store体验 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore 还在为Windows 11 LTS…...

wechatferry 高级技巧:如何实现AI驱动的智能对话机器人
wechatferry 高级技巧:如何实现AI驱动的智能对话机器人 【免费下载链接】wechatferry - 项目地址: https://gitcode.com/gh_mirrors/wec/wechatferry WechatFerry 是一款功能强大的微信机器人底层框架,通过 Node 生态下的第三方客户端实现&#x…...

CANN/Ascend C 基于语言扩展层C API编程
基于语言扩展层C API编程 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https:…...

MoE稀疏激活:大模型推理效率革命的核心原理与工程实践
1. 这不是参数堆砌,而是“动态稀疏激活”的工程革命你可能已经看到过那条刷屏的推文:“GPT-4有1.8万亿参数,但每生成一个token只用其中2%。”——这句话像一道闪电劈开了大模型圈的认知惯性。它背后根本不是在炫耀数字有多吓人,而…...

仅剩最后47个印尼语专属Voice ID配额!ElevenLabs企业版印尼语音定制通道即将关闭——附2024Q3合规接入白皮书
更多请点击: https://codechina.net 第一章:印尼语Voice ID配额告急与企业定制通道关闭预警 近期,多家使用印尼语(Bahasa Indonesia)语音身份验证(Voice ID)服务的企业客户收到平台侧自动通知&…...

Mardi 品牌创始人是谁?一文读懂法国 Mardi Ladin
法国 Mardi Ladin 品牌创始人是La Bergon(Baudino Cd L),一位出身法国时尚世家的设计师,品牌的灵感直接来自于 1975 年法国经典电影《表兄妹》中入围奥斯卡最佳女主角的角色 "玛尔蒂 MARDI"。创始人 La Bergon 解析La B…...

mPDF实战指南:PHP环境下HTML转PDF的高性能解决方案深度解析
mPDF实战指南:PHP环境下HTML转PDF的高性能解决方案深度解析 【免费下载链接】mpdf PHP library generating PDF files from UTF-8 encoded HTML 项目地址: https://gitcode.com/gh_mirrors/mp/mpdf 在当今数字化办公环境中,PDF文档生成已成为企业…...