分页查询及其拓展应用案例
分页查询
分页查询是处理大量数据时常用的技术,通过分页可以将数据分成多个小部分,方便用户逐页查看。SQLAlchemy 提供了简单易用的方法来实现分页查询。
本篇我们也会在最终实现这样的分页效果:
1. 什么是分页查询
分页查询是将查询结果按照一定数量分成多页展示,每页显示固定数量的记录。分页查询通常使用两个参数:
-
limit:每页显示的记录数量。 -
offset:跳过的记录数量。
例如,要查询第二页,每页显示 10 条记录:
-
limit:10 -
offset:10
2. 使用 SQLAlchemy 实现分页查询
基本查询
首先,我们需要一个基本的查询来获取数据:
import db
from model import Studentdef basic_query():students = db.session.query(Student).all()for stu in students:print(stu.to_dict())使用 limit 和 offset
前文中,我们已经了解到 SQLAlchemy 提供了 limit 和 offset 方法来实现分页查询。limit 限制返回的记录数量,offset 跳过指定数量的记录。
import db
from model import Studentdef paginated_query(page, per_page):q = db.select(Student).limit(per_page).offset((page - 1) * per_page)students = db.session.execute(q).scalars()for stu in students:print(stu.to_dict())例如,要获取第 2 页,每页显示 10 条记录:
paginated_query(2, 10)对应的 SQL 语句:
SELECT * FROM tb_student LIMIT 10 OFFSET 10;3. 前后端实现分页功能
后端分页
在后端实现分页功能时,可以创建一个函数来处理分页逻辑。这个函数接受 page 和 per_page 参数,并返回当前页的数据和总页数。
import db
from model import Studentdef get_paginated_students(page, per_page):total = db.session.query(Student).count()q = db.select(Student).limit(per_page).offset((page - 1) * per_page)students = db.session.execute(q).scalars()return {'total': total,'page': page,'per_page': per_page,'pages': (total + per_page - 1) // per_page,'data': [stu.to_dict() for stu in students]}前端分页
在前端实现分页时,可以使用后端提供的分页数据来渲染页面:
{"total": 100,"page": 2,"per_page": 10,"pages": 10,"data": [{"id": 11, "name": "Student 11", ...},{"id": 12, "name": "Student 12", ...},...]
}前端可以根据这些数据渲染分页控件和当前页的数据。
[拓展] Flask 分页演示
下面是一个前后端不分离的 Flask 项目,代码文件比较多,你需要自行理一下。同时也要保证 Flask 、 Flask-SQLAlchemy 与 Flask-MysqlDB 的安装。
pip install flask
pip install flask-sqlalchemy # 兼容 Flask 的 SQLAlchemy 框架,提供 ORM 功能
pip install flask-mysqldb # 为 Flask-SQLAlchemy 提供 MySQL 驱动Flask 项目目录如下:
flask_app/ # 项目目录
├── templates/ # 模板目录
│ └── list.html # 模板文件
├── config.py # Flask 配置文件
├── db.py # 数据库核心文件,包含重要操作
├── manage.py # Flask 路由和业务视图文件
└── models.py # 数据库模型文件首先看一下配置文件 config.py:
class Config:SQLALCHEMY_DATABASE_URI = 'mysql://root:0908@localhost:3306/db_flask_demo_school?charset=utf8mb4' # 数据库连接。自行替换数据库用户名称和密码以及实际数据库名SQLALCHEMY_ECHO = False # 是否打印执行的 SQL 语句及其耗时DEBUG = True # 是否启用调试模式db.py
"""
Create database:> create database db_flask_demo_school charset=utf8mb4
"""
from flask_sqlalchemy import SQLAlchemy
from sqlalchemy import *db = SQLAlchemy()models.py
from db import *class Student(db.Model):__tablename__ = 'tb_student2'id = db.Column(db.Integer, primary_key=True, comment="主键")name = db.Column(db.String(15), index=True, comment="姓名")age = db.Column(db.SmallInteger, comment="年龄")sex = db.Column(db.Boolean, comment="性别")email = db.Column(db.String(128), unique=True, comment="邮箱地址")money = db.Column(db.Numeric(10, 2), default=0.0, comment="钱包")def to_dict(self):return {'id': self.id,'name': self.name,'age': self.age,'sex': self.sex,'email': self.email,'money': float(self.money)}def __repr__(self):return f'<{self.__class__.__name__}: {self.name}>'然后就是 manage.py,编写了路由与业务代码:
from pathlib import Path
from flask import Flask, jsonify, request, render_template
from config import Config
from models import db, Studentapp = Flask(__name__, template_folder='./templates')
app.config.from_object(Config)db.init_app(app)@app.route('/', methods=['GET'])
def index():"""没啥用,勿看"""title = Path(__file__).namereturn title@app.route('/students', methods=['POST'])
def create_student():"""采集访问的信息,创建学生"""sex = request.form.get('sex')sex = int(sex) if sex.isdigit() else 0student = Student(name=request.form.get('name', '未知'),age=request.form.get('age', 0),sex=bool(sex),email=request.form.get('email', ''),money=request.form.get('money', 0),)if request.form.get('id', None) is not None:student.id = request.form['id']db.session.add(student)db.session.commit()return jsonify({'success': True,'data': student.to_dict(),'msg': 'success'}), 201@app.route('/students', methods=['DELETE'])
def delete_students():"""删除学生表的所有记录"""db.session.execute(db.delete(Student))db.session.commit()return jsonify({'success': True,'data': None,'msg': 'success'})@app.route('/students', methods=['GET'])
def get_students():# 旧版本 2.x 获取全部数据# students = Student.query.all()# 新版本 3.1.x 获取全部数据students = db.session.execute(db.select(Student).where()).scalars()return jsonify({'success': True,'data': {'count': Student.query.count(),'students': [student.to_dict() for student in students]},'msg': 'success'})@app.route('/students/<int:student_id>', methods=['GET'])
def get_student(student_id):# 根据主键查询数据,不存在则为 Nonestudent = db.session.get(Student, student_id)if not student:return jsonify({'success': False,'data': None,'msg': 'student not found'})return jsonify({'success': True,'data': student.to_dict(),'msg': 'success'})@app.route('/students/data', methods=['GET'])
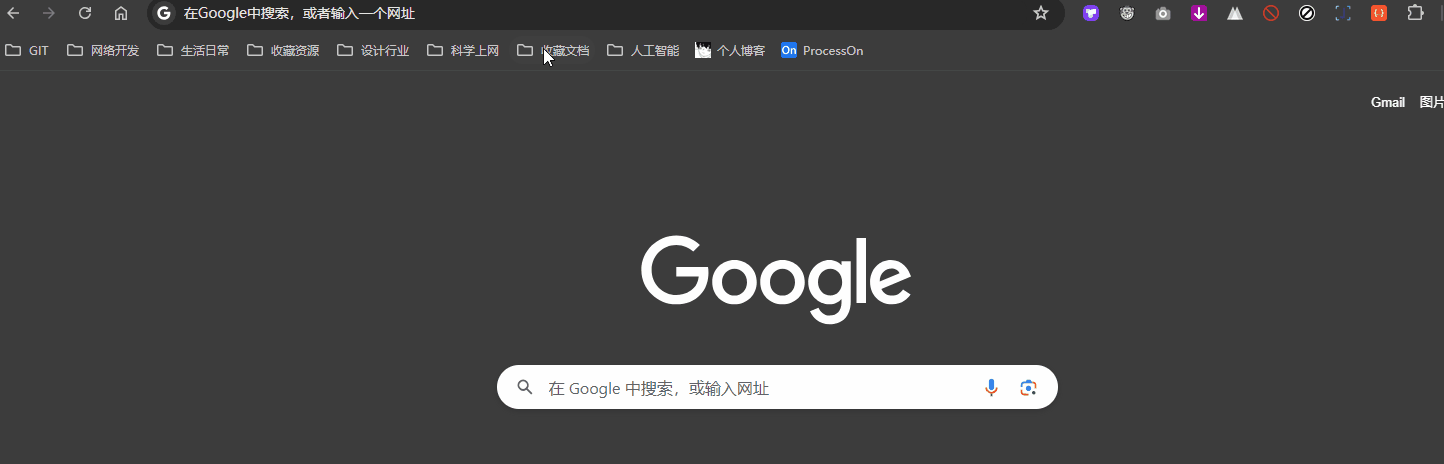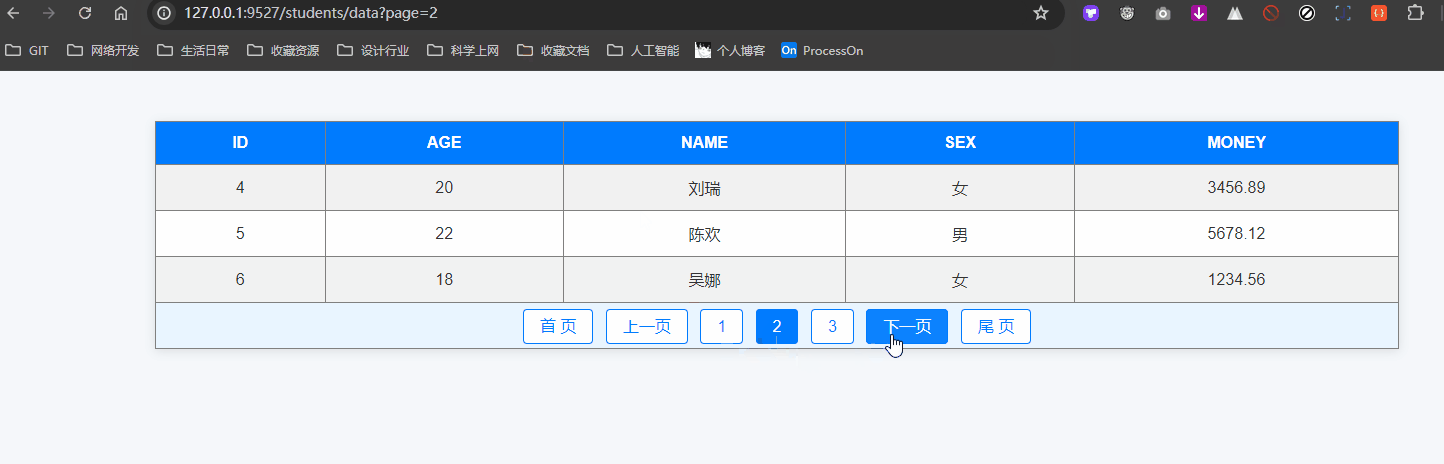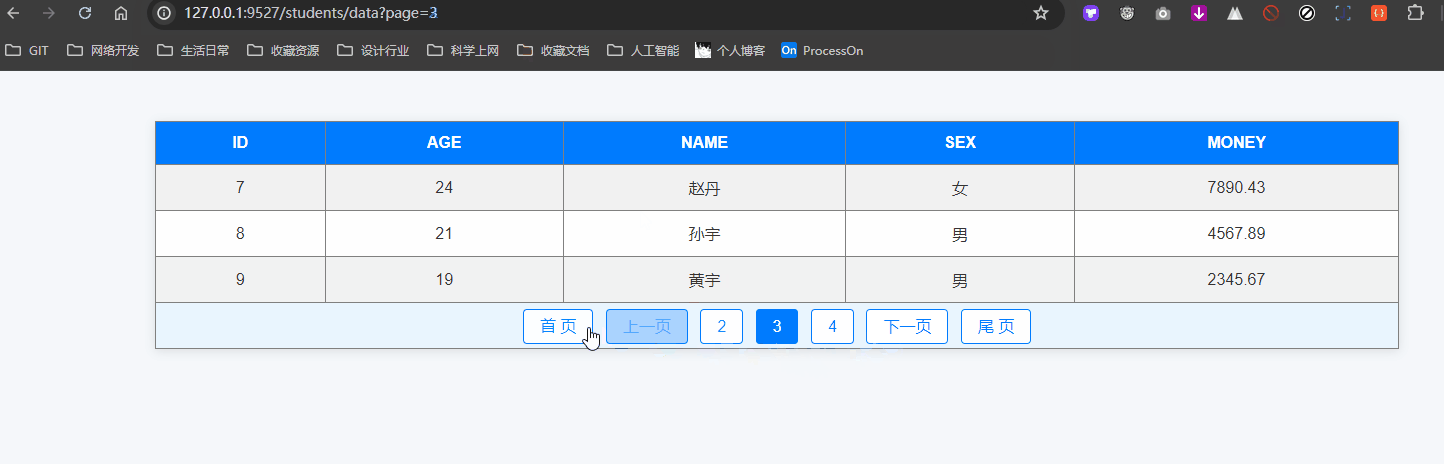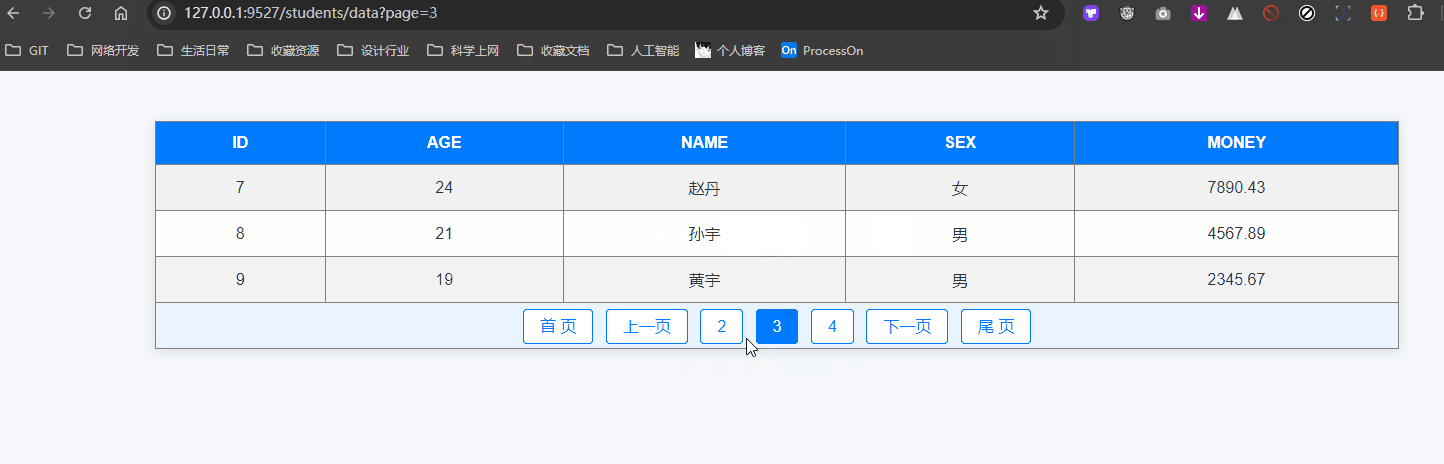
def students_data():"""这里是分页器的使用,不同于我们所使用的 limit 和 offset 需要自己编写"""# 不采取数据分页时,大量数据时会导致服务器运存膨胀,这是非常不妥的page = request.args.get('page', 1, type=int)per_page = request.args.get('size', 3, type=int)# 创建分页器对象pagination = Student.query.paginate(page=page, per_page=per_page, max_per_page=20)print('当前页对象', pagination)print('总数据量', pagination.total)print('当前页数据列表', pagination.items)print('总页码', pagination.pages)print()print('是否有上一页', pagination.has_prev)print('上一页页码', pagination.prev_num)print('上一页对象', pagination.prev())print('上一页对象的数据列表', pagination.prev().items)print()print('是否有下一页', pagination.has_next)print('下一页页码', pagination.next_num)print('下一页对象', pagination.next())print('下一页对象的数据列表', pagination.next().items)# """前后端分离推荐使用的 json 结果,这里没用到"""data = {"page": pagination.page, # 当前页码"pages": pagination.pages, # 总页码"has_prev": pagination.has_prev, # 是否有上一页"prev_num": pagination.prev_num, # 上一页页码"has_next": pagination.has_next, # 是否有下一页"next_num": pagination.next_num, # 下一页页码"items": [{"id": item.id,"name": item.name,"age": item.age,"sex": item.sex,"money": item.money,} for item in pagination.items]}return render_template('list.html', **locals())if __name__ == '__main__':with app.app_context():db.drop_all() # 启动时先删除相关表,后创建相关表db.create_all()app.run('0.0.0.0', 9527)最后就是 list.html 这个模板文件,呈现一个分页的演示:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>Title</title><style>body {font-family: Arial, sans-serif;background-color: #f4f7fa;color: #333;}table {border-collapse: collapse;margin: 50px auto;width: 80%;box-shadow: 0 2px 10px rgba(0, 0, 0, 0.1);background-color: #fff;}th, td {padding: 12px 15px;text-align: center;}th {background-color: #007bff;color: #fff;text-transform: uppercase;}tr:nth-child(even) {background-color: #f2f2f2;}tr:hover {background-color: #e9f5ff;}.page {margin: 20px auto;text-align: center;}.page a, .page span {padding: 8px 16px;margin: 0 4px;color: #007bff;background: #fff;border: 1px solid #007bff;border-radius: 4px;text-decoration: none;transition: background-color 0.3s, color 0.3s;}.page a:hover {background-color: #007bff;color: #fff;}.page span {background-color: #007bff;color: #fff;}</style>
</head>
<body><table border="1" align="center" width="600"><tr><th>ID</th><th>Age</th><th>Name</th><th>Sex</th><th>Money</th></tr>{% for student in pagination.items %}<tr><td>{{ student.id }}</td><td>{{ student.age }}</td><td>{{ student.name }}</td><td>{{ "男" if student.sex else "女" }}</td><td>{{ student.money }}</td></tr>{% endfor %}<tr align="center"><td colspan="5" class="page">{% if pagination.has_prev %}<a href="?page=1">首 页</a><a href="?page={{ pagination.page - 1 }}">上一页</a><a href="?page={{ pagination.page - 1 }}">{{ pagination.page - 1 }}</a>{% endif %}<span>{{ pagination.page }}</span>{% if pagination.has_next %}<a href="?page={{ pagination.page + 1 }}">{{ pagination.page + 1 }}</a><a href="?page={{ pagination.page + 1 }}">下一页</a><a href="?page={{ pagination.pages }}">尾 页</a>{% endif %}</td></tr></table>
</body>
</html>为了确保能够有一定数量的数据,请你另外新建一个 request.py,用于创建大量数据(如果你知道 faker 的使用,也可以自己弄一些数据),先启动 manage.py,保证后端服务的开启和路由可用,然后直接运行该文件后可添加测试数据:
# request.py
import requests # pip install requestsstudents = [ # 虚拟数据,务必当真{'name': '王毅','age': 21,'sex': 1,'email': 'wangyi@gmail.com','money': 4488.5},{'name': '张晓','age': 19,'sex': 0,'email': 'zhangxiao@example.com','money': 2389.75},{'name': '李春阳','age': 23,'sex': 1,'email': 'lichunyang@outlook.com','money': 6715.32},{'name': '刘瑞','age': 20,'sex': 0,'email': 'liurui@yahoo.com','money': 3456.89},{'name': '陈欢','age': 22,'sex': 1,'email': 'chenhuan@gmail.com','money': 5678.12},{'name': '吴娜','age': 18,'sex': 0,'email': 'wuna@example.org','money': 1234.56},{'name': '赵丹','age': 24,'sex': 0,'email': 'zhaoda@outlook.com','money': 7890.43},{'name': '孙宇','age': 21,'sex': 1,'email': 'sunyu@yahoo.co.jp','money': 4567.89},{'name': '黄宇','age': 19,'sex': 1,'email': 'huangyu@gmail.com','money': 2345.67},{'name': '杨静','age': 22,'sex': 0,'email': 'yangjing@example.com','money': 6789.01}
]
for student in students:response = requests.request('POST', 'http://127.0.0.1:9527/students', data=student)print('添加一条记录', response.json())确定 Flask 项目正常启动,并且上面的数据也完成了注入,如果你发现启动失败了,请检查路由、数据库连接是否有问题,你可能需要一定的 Flask 基础知识。接下来如何访问我们渲染的模板呢?
根据路由视图和设置的访问端口(9527):
@app.route('/students/data', methods=['GET'])
def students_data():...return render_template('list.html', **locals())我们直接在浏览器访问:http://127.0.0.1:9527/students/data 这个地址即可。
上述案例是演示所用,随意写的,小部分代码参考了某机构的教程代码示例,平台原因无法标注,路由设计也是很随便的,这种代码如果存在版权纠纷,emmm.....,请联系我删除,谢谢。无私开源,只为搞懂后端开发的学习,请勿钻牛角……
文章转载自:顾平安
原文链接:https://www.cnblogs.com/gupingan/p/18300467
体验地址:引迈 - JNPF快速开发平台_低代码开发平台_零代码开发平台_流程设计器_表单引擎_工作流引擎_软件架构
相关文章:
分页查询及其拓展应用案例
分页查询 分页查询是处理大量数据时常用的技术,通过分页可以将数据分成多个小部分,方便用户逐页查看。SQLAlchemy 提供了简单易用的方法来实现分页查询。 本篇我们也会在最终实现这样的分页效果: 1. 什么是分页查询 分页查询是将查询结果按照…...

【UE5.1】NPC人工智能——02 NPC移动到指定位置
效果 步骤 1. 新建一个蓝图,父类选择“AI控制器” 这里命名为“BP_NPC_AIController”,表示专门用于控制NPC的AI控制器 2. 找到我们之前创建的所有NPC的父类“BP_NPC” 打开“BP_NPC”,在类默认值中,将“AI控制器类”一项设置为“…...

有关电力电子技术的一些相关仿真和分析:⑤交-直-交全桥逆变+全波整流结构电路(MATLAB/Siumlink仿真)
全桥逆变+全波整流结构 参数:Vin=500V, Vo=200V, T=2:1:1, RL=10Ω, fs=100kHz, L=1mH, C=100uF (1)给定输入电压,输出电压和主电路参数,仿真研究电路工作原理,分析工作时序; (2)调节负载电阻,实现电流连续和断续,并仿真验证; (3)调节占空比,分析占空比与电…...

记录一次Android推流、录像踩坑过程
背景: 按照需求,需要支持APP在手机息屏时进行推流、录像。 技术要点: 1、手机在息屏时能够打开camera获取预览数据 2、获取预览数据时进行编码以及合成视频 一、息屏时获取camera预览数据: ①Camera.setPreviewDisplay(SurfaceH…...

VsCode 与远程服务器 ssh免密登录
首先配置信息 加入下列信息 Host qb-zn HostName 8.1xxx.2xx.3xx User root ForwardAgent yes Port 22 IdentityFile ~/.ssh/id_rsa 找到自己的公钥,不带pub是私钥,打死都不能给别人。复制公钥 拿到公钥后,来到远程服务器 vim ~/.ss…...

7/13 - 7/15
vo.setId(rs.getLong("id"))什么意思? vo.setId(rs.getLong("id")); 这行代码是在Java中使用ResultSet对象(通常用于从数据库中检索数据)获取一个名为"id"的列,并将其作为long类型设置为一个对象…...

烟雾监测与太阳能源:实验装置在其中的作用
太阳光在烟雾中的散射效应研究实验装置是一款模拟阳光透过烟雾环境的设备。此装置能帮助探究阳光在烟雾中的传播特性、散射特性及其对阳光的影响。 该装置主要包括光源单元、烟雾发生装置、光学组件、以及系统。光源单元负责产生类似于太阳光的光线,通常选用高亮度的…...

QT下,如何获取控制台输入
最近工作中为了测试某个模块,需要把原先输入模块部分,改成控制台输入来方便测试。在QT中,我们可以使用 QTextStream 类来读取用户的输入来达到目的。下面是一个简单的例子: #include <QCoreApplication> #include <QTex…...

mybatis动态传入参数 pgsql 日期 Interval ,day,minute
mybatis动态传入参数 pgsql 日期 Interval 在navicat中,标准写法 SELECT * FROM test WHERE time > (NOW() - INTERVAL 5 day)在mybatis中,错误写法 SELECT * FROM test WHERE time > (NOW() - INTERVAL#{numbers,jdbcTypeINTEGER} day)报错内…...

常见CSS属性
常见CSS属性。 1. display: 定义:display 属性控制元素如何渲染在文档流中,影响了元素是否占用空间、位置及盒子模型的行为。 使用说明:它可以设置为如block, inline, inline-block, flex, grid, none等值,用于决定元素显示模式…...
WSL-Ubuntu20.04训练环境配置
1.YOLOv8训练环境配置 训练环境配置的话就仍然以YOLOv8为例,来说明如何配置深度学习训练环境。这部分内容比较简单,主要是安装miniAnaconda以及安装torch和torchvision. 首先是miniAnaconda的安装(参考官网的教程Miniconda — Anaconda ),执行…...

运维检查:mysql表自增id是否快要用完
数据库表中最大自增ID用完会报错。判断是否接近或达到自增ID类型的最大值: 对于MySQL中的自增ID,如果使用的是int类型,其无符号(unsigned)的最大值可以达到2^32 - 1,即4294967295。如果使用的…...

深入理解FFmpeg--libavformat接口使用(一)
libavformat(lavf)是一个用于处理各种媒体容器格式的库。它的主要两个目的是去复用(即将媒体文件拆分为组件流)和复用的反向过程(以指定的容器格式写入提供的数据)。它还有一个I/O模块,支持多种…...

坚持日更的意义何在?
概述 日更,就是每天更新一次或一篇文章。 坚持日更,就是坚持每天更新一次或一篇文章。 这里用了坚持,实际上不是恰当的表述,正确的感觉应该是让日更当作习惯,然后,让自己习惯每天去更新一篇文章。 日更…...

内容长度不同的div如何自动对齐展示
平时我们经常会遇到页面内容div结构相同页,这时为了美观我们会希望div会对齐展示,但当div里的文字长度不一时又不想写固定高度,就会出现div长度长长短短,此时实现样式可以这样写: .e-commerce-Wrap {display: flex;fle…...

Qt中https的使用,报错TLS initialization failed和不能打开ssl.lib问题解决
前言 在现代应用程序中,安全地传输数据变得越来越重要。Qt提供了一套完整的网络API来支持HTTP和HTTPS通信。然而,在实际开发过程中,开发者可能会遇到SSL相关的错误,例如“TLS initialization failed”,cantt open ssl…...

P2p网络性能测度及监测系统模型
P2p网络性能测度及监测系统模型 网络IP性能参数 IP包传输时延时延变化误差率丢失率虚假率吞吐量可用性连接性测度单向延迟测度单向分组丢失测度往返延迟测度 OSI中的位置-> 网络层 用途 面相业务的网络分布式计算网络游戏IP软件电话流媒体分发多媒体通信 业务质量 通过…...

zookeeper相关总结
1. ZooKeeper 的架构 ZooKeeper 采用主从架构(Leader-Follower 模型),包括以下组件: Leader:负责处理所有写请求和协调事务一致性。Follower:处理读请求并转发写请求给 Leader。参与 Leader 选举和事务提…...

【openwrt】Openwrt系统新增普通用户指南
文章目录 1 如何新增普通用户2 如何以普通用户权限运行服务3 普通用户如何访问root账户的ubus服务4 其他权限控制5 参考 Openwrt系统在默认情况下只提供一个 root账户,所有的服务都是以 root权限运行的,包括 WebUI也是通过root账户访问的,…...

【GD32】从零开始学GD32单片机 | WDGT看门狗定时器+独立看门狗和窗口看门狗例程(GD32F470ZGT6)
1. 简介 看门狗从本质上来说也是一个定时器,它是用来监测硬件或软件的故障的;它的工作原理大概就是开启后内部定时器会按照设置的频率更新,在程序运行过程中我们需不断地重装载看门狗,以使它不溢出;如果硬件或软件发生…...

k-Mode聚类算法原理与手写实现:专治分类数据的无监督学习利器
1. 项目概述:为什么k-Mode不是k-Means的“换皮版”,而是一把专治分类数据的手术刀你有没有遇到过这样的场景:手头有一批客户数据,字段全是“性别:男/女”、“城市:北京/上海/广州”、“会员等级:…...

驱动教学模式革新:广凌智慧教学融合平台如何实现个性化教学?
随着高等教育从“知识为主”向“能力为先”深刻转型,千人千面的个性化学习已成为未来教育的核心诉求。传统的统一内容、统一路径的教学模式,已难以满足学生差异化的发展需要。如何借助技术手段实现真正的因材施教?广凌智慧教学融合平台以人工…...

ToastFish:Windows通知栏背单词神器,碎片化时间高效记忆方案
ToastFish:Windows通知栏背单词神器,碎片化时间高效记忆方案 【免费下载链接】ToastFish 一个利用摸鱼时间背单词的软件。 项目地址: https://gitcode.com/GitHub_Trending/to/ToastFish ToastFish是一款创新的Windows桌面应用程序,专…...

构建完全自由操作系统:从内核净化到硬件选择的完整指南
1. 项目概述:探寻“完全自由”操作系统的内核秘密 如果你和我一样,在技术这条路上摸爬滚打超过十年,一定会对“自由”这个词有更深的执念。这里的“自由”,不是指免费,而是指“自由软件”意义上的自由——拥有使用、研…...

LEFT JOIN 中 ON 与 WHERE 过滤的差异
在 MySQL 数据库开发中,LEFT JOIN(左外连接)是一个最常被误用的语法。许多开发者往往习惯性地将所有过滤条件一股脑地往 ON 后面塞,或者为了排版好看将条件全部扔到 WREHRE 里面。 这种模糊的逻辑在普通内连接(INNER J…...

CANN/asc-devkit同步通知API文档
asc_sync_notify 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcod…...

Q学习入门:用DQN训练乒乓AI的原理与实操
1. 项目概述:从乒乓游戏切入,理解Q学习如何让AI学会“思考下一步”你有没有试过盯着一个简单的乒乓球游戏界面发呆?球正朝右下角飞来,挡板在屏幕左侧,此时你的手指悬在键盘上方——是按上、按下,还是不动&a…...

H3CSE 高性能园区网:VRRP 技术详解
H3CSE 高性能园区网:VRRP 技术详解VRRP 技术详解一、VRRP 简介1.1 VRRP 技术背景与定义1.1.1 技术背景1.1.2 VRRP 核心定义1.2 VRRP 核心原理与关键概念1.2.1 主备切换工作流程1.2.2 关键概念解析1.2.3 免费ARP工作原理二、VRRP 核心工作原理2.1 VRRP 基础运行原理概…...

独立站 AI 智能推荐商品功能落地实操:从 0 到 1 提升转化与客单价
在独立站运营中,流量成本持续走高,很多站点陷入 “有流量、没转化、客单价低” 的困境。2026 年跨境电商数据显示,部署 AI 智能推荐的独立站,平均转化率提升 4.7%-15%,客单价上涨 20%-30%,复购率提高 18% 以…...

AI Agent与RPA的融合:智能自动化新范式
AI Agent与RPA的融合:智能自动化新范式 关键词:AI Agent、RPA、智能自动化、融合技术、自主决策、业务流程优化、人机协作 摘要:本文深入探讨了AI Agent与RPA(机器人流程自动化)的融合,揭示了这一技术组合如何开创智能自动化的新范式。我们将通过生动的类比和详细的技术解…...