大数据框架之Hadoop:HDFS(一)HDFS概述
1.1HDFS产出背景及定义
-
HDFS产生背景随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。
HDFS只是分布式文件管理系统中的一种。 -
HDFS定义HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件,其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。HDFS的使用场景: 适合一次写入,多次读出的场景,且不支持文件的修改。适合用来做数据分析,并不适合用来做网盘应用。
1.2HDFS优缺点
1.2.1优点
1)高容错性
- 数据自动保存多个副本。它通过增加副本的形式,提高容错性;

- 某一个副本丢失以后,它可以自动恢复。

2)适合处理大数据
-
数据规模:能够处理数据规模达到GB、TB、甚至PB级别的数据;
-
文件规模:能够处理百万规模以上的文件数量,数量相当之大。
3)可构建在廉价机器上,通过多副本机制,提高可靠性
1.2.2缺点
1)不适合低延时数据访问,比如毫秒级的存储数据,是做不到的。
2)无法高效的对大量小文件进行存储
-
存储大量小文件的话,它会占用NameNode大量的内存来存储文件目录和块信息。这样是不可取的,因为NameNode的内存总是有限的;
-
小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标。
3)不支持并发写入、文件随机修改
-
一个文件只能有一个写,不允许多个线程同时写;
-
仅支持数据append (追加) ,不支持文件的随机修改。
1.3HDFS组成架构
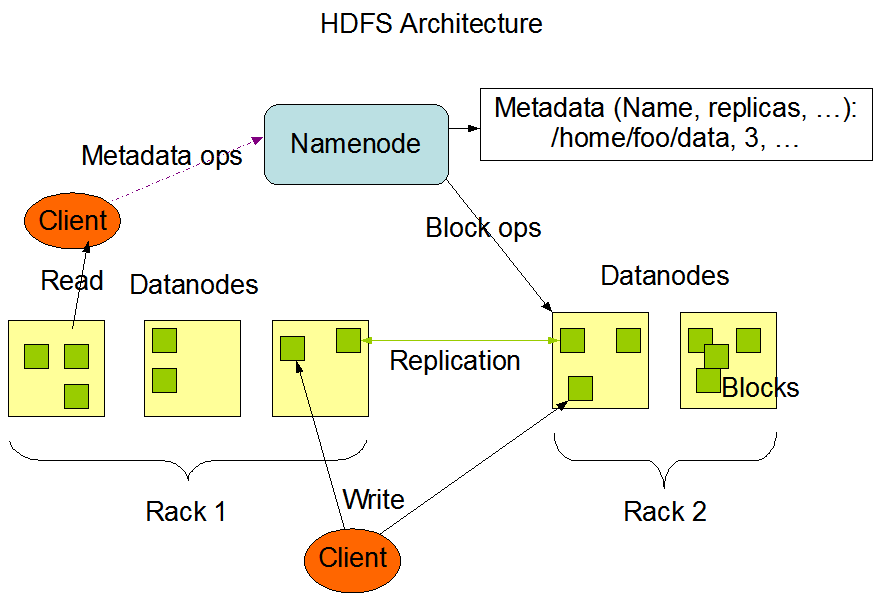
1)NameNode (nn) :就是Master,它是一个主管、管理者。
-
管理HDFS的名称空间;
-
配置副本策略;
-
管理数据块(Block)映射信息;
-
处理客户端读写请求。
2)DataNode: 就是Slave。NameNode下达命令,DataNode执行实际的操作。
-
存储实际的据块
-
执行数据块的读/写操作
3)Client: 就是客户端
- 文件切分。文件上传HDFS的时候,client将文件切分成一个一个的Block,然后进行上传;
- 与NameNode交互,获取文件的位置信息;
- 与DataNode交互,读取或者写入数据
- Client提供一些命今来管理HDFS,比如NameNode格式化;
- Client可以通过一些命今来访问HDFS,比如对HDFS增删查改操作
4)SecondaryNameNode: 并非NameNode的热备。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务.
-
辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode;
-
在紧急情况下,可辅助恢复NameNode。
1.4HDFS文件块大小(面试重点)
1.4.1HDFS文件块大小
HDFS中的文件在物理上是分块存储(Block),块的大小可以通过配置参数(dfs.blocksize)来规定,默认大小在Hadoop2.x和Hadoop3.x版本中是128M,老版本Hadoop1.x中是64M。
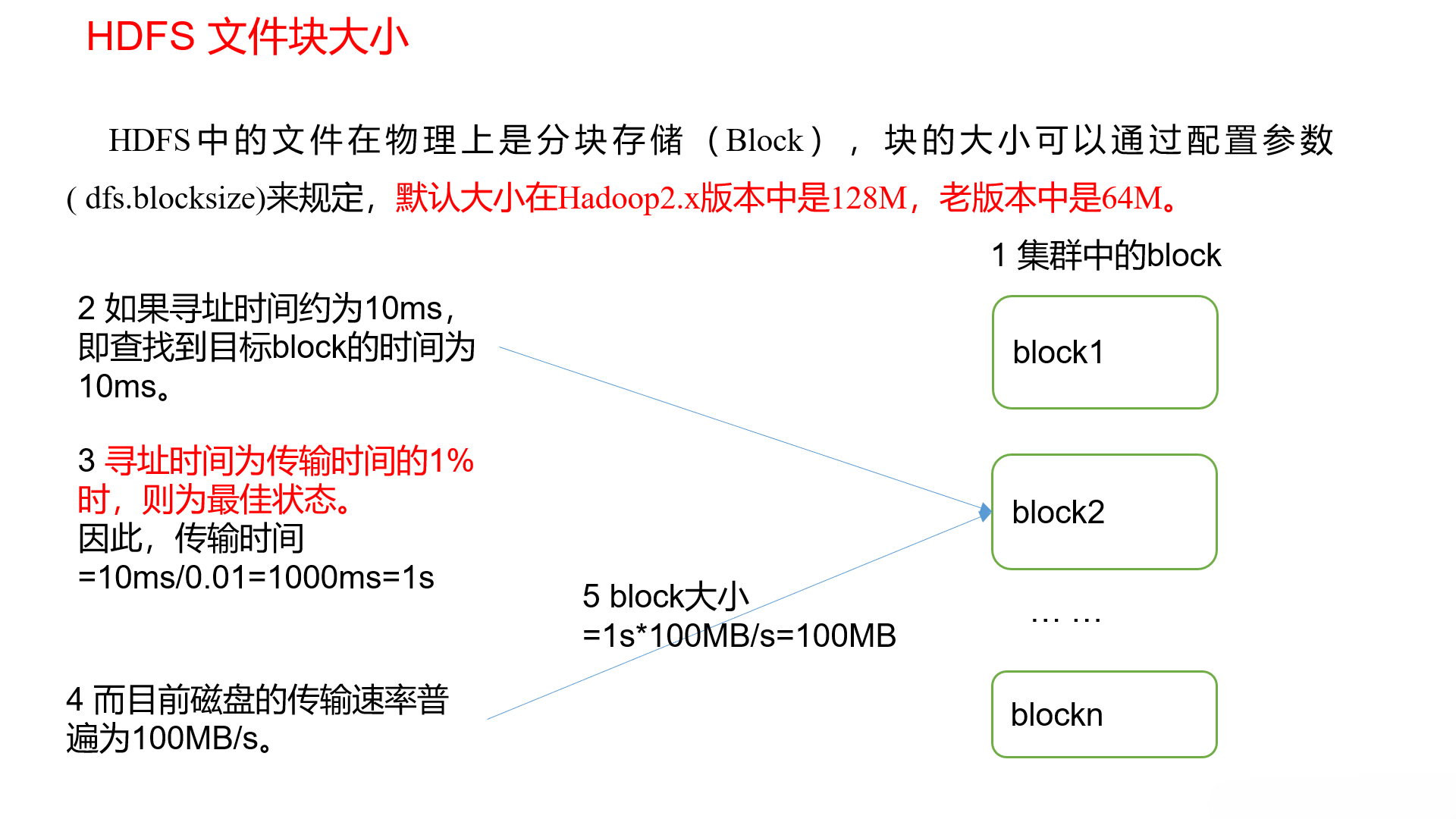
1.4.2HDFS文件块大小设置原理
HDFS文件块大小设置主要取决于磁盘传输速率,目前通过Namenode对HDFS元数据进行寻址的时间约为10ms,即查找到目标block的时间为10ms。
寻址时间为传输时间的1%时,则为最佳状态
因此,传输时间为10ms/0.01=1000ms=1s
目前磁盘的传输速率普遍为100MB/s
因此,block大小为1s*100MB/s=100MB
因为电脑底层数据采用二进制存储,所以目前的block块官方大小设置为128MB。
总结:HDFS文件块大小设置主要取决于磁盘传输速率,生产中采用高速磁盘作为存储介质的可以考虑在HDFS的配置文件中设置dfs.blocksize参数调整block块大小。
1.4.3块大小要设置合理
HDFS的块设置太小,会增加寻址时间,程序一直在找块的开始位置;
如果块设置的太大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。导致程序在处理这块数据时,会非常慢。
相关文章:
大数据框架之Hadoop:HDFS(一)HDFS概述
1.1HDFS产出背景及定义 HDFS 产生背景 随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件…...
20230210组会论文总结
目录 【Ultra-High-Definition Low-Light Image Enhancement: A Benchmark and Transformer-Based Method】 【ShuffleMixer: An Efficient ConvNet for Image Super-Resolution】 【A Close Look at Spatial Modeling: From Attention to Convolution 】 【DEA-Net: Single i…...

Python - 数据容器dict(字典)
目录 字典的定义 字典数据的获取 字典的嵌套 字典的各种操作 新增与更新元素 [Key] Value 删除元素 pop和del 清空字典 clear 获取全部的键 keys 遍历字典 容器通用功能总览 字典的定义 使用{},不过存储的元素是一个个的:键值对&#…...
)
傻白探索Chiplet,文献阅读笔记汇总(十二)
Summary(方便分类管理) Article(文献出处) 方便再次搜索 Data(文献数据) 总结归纳,方便理解 Comments(对文献的想法)/Why(为什么看这篇文献)强…...

#电子电气架构——Vector工具常见问题解决三板斧
我是穿拖鞋的汉子,魔都中一位坚持长期主义的工科男。 今天在与母亲聊天时,得到老家隔壁邻居一位大姐年初去世的消息,挺让自己感到伤感!岁月如流水,想抓都抓不住。想起平时自己加班的那个程度,可能后续也要自己注意身体啦。 老规矩,分享一段喜欢的文字,避免自己成为高知…...

文本三剑客之grep
Grep是Linux用户用来搜索文本字符串的命令行工具。您可以使用它在文件中搜索某个单词或单词的组合,也可以将其他Linux命令的输出通过管道传输到grep,因此grep可以仅显示您需要查看的输出。grep的命令格式如下:grep 选项 查找条件 目标文件…...
pwn手记录题1
fuzzerinstrospector(首届数字空间安全攻防大赛) 主体流程(相对比较简单,GLibc为常见的2.27版本, Allocate申请函数(其中有两个输入函数Read_8Int、Read_context; 还存在着后门函数; 关键点在于如何利用…...

自动驾驶规划 - Apollo Lattice Planner算法【1】
文章目录Lattice Planner简介Lattice Planner 算法思路1. 离散化参考线的点2. 在参考线上计算匹配点3. 根据匹配点,计算Frenet坐标系的S-L值4. parse the decision and get the planning target5. 生成横纵向采样路径6. 轨迹cost值计算,进行碰撞检测7. 优…...
以太坊数据开发-Web3.py-安装连接以太坊数据
Web3.py是连接以太坊的python库,它的API从web3.js中派生而来。如果你用过web3.js,你会对它的API很熟悉。但惭愧的是,作为一个以太坊上Dapp的开发者,我几乎没有直接使用过web3.js,也没有看过它的API。 官网:…...
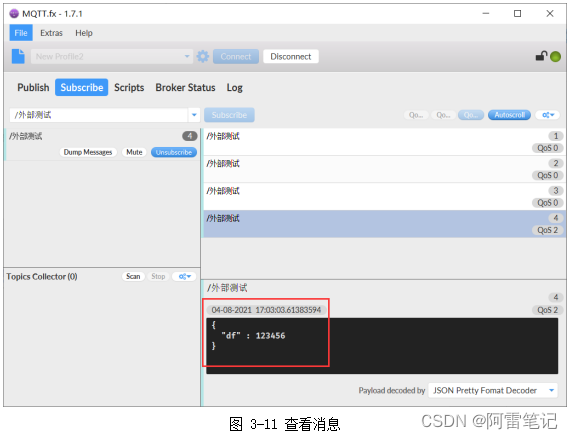
【触摸屏功能测试】MQTT_STD本地调试说明-测试记录
1、MQTT简介 MQTT是一种基于发布/订阅模式的“轻量级”通讯协议。它是针对受限的、低带宽的、高延迟的、网络不可靠的环境下的网络通讯设备设计的。 发布是指客户端将消息传递给服务器,订阅是指客户端接收服务器推送的消息。每个消息有一个主题,包含若干…...

六十分之十三——黎明前
目录一、目标二、计划三、完成情况四、提升改进(最少3点)五、意外之喜(最少2点)六、总结一、目标 明确可落地,对于自身执行完成需要一定的努力才可以完成的 1.8本技术管理书籍阅读(使用番茄、快速阅读、最后输出思维导图)2.吴军系列硅谷来信1听书、香帅的北大金融…...

【Call for papers】CRYPTO-2023(CCF-A/网络与信息安全/2023年2月16日截稿)
Crypto 2023 will take place in Santa Barbara, USA on August 19-24, 2023. Crypto 2023 is organized by the International Association for Cryptologic Research (IACR). The proceedings will be published by Springer in the LNCS series. 文章目录1.会议信息2.时间节…...

线程的信号量和互斥量
文章目录线程的信号量初始化信号量:sem_init减少信号量:sem_wait增加信号量:sem_post删除信号量:sem_destroy代码示例线程的互斥量初始化互斥量:pthread_mutex_init锁住互斥量:pthread_mutex_lock解锁互斥量…...

关于Linux,开源社区与国产化的本质区别
因为生产力驱动而非理想主义驱动。 开源运动的蓬勃发展来自于GNU(GNU is not unix),RichardMatthewStallman领导着一群黑客,带着对比尔盖茨的鄙视,制定了GPL协议,以后人人都能从伟大的前人身上学习到源代码的精髓,让软…...

Win11下Linux子系统迁移方法及报错解决
Win11 将Linux子系统从C盘迁移到其他盘Win11下Linux子系统迁移方法及报错解决1、下载LxRunOffline2、ERROR:directory is not empty 报错解决参考链接Win11下Linux子系统迁移方法及报错解决 C盘满了,Ubuntu子系统占了100多G怎么办?直接将子系…...

python维护的一些基础方法
1】通过命令行查看python安装库的基本信息 pip show numpy # 查看python中numpy库的安装版本信息 2】python 环境的开发与维护 python的开发与C\MATLAB等最大的不同就是,python中版本的更新不对历史版本负责,就是说你以历史版本开发的python程序&#…...

C语言 数组元素的指针
1.一个变量有地址,一个数组包含若干个元素,每个数组元素都在内存中占用存储单元,它们都有相应的地址。 2.指针变量既然可以指向变量,当然也可以指向数组元素(把某一元素的地址放入一个指针变量中)。 3.所谓…...
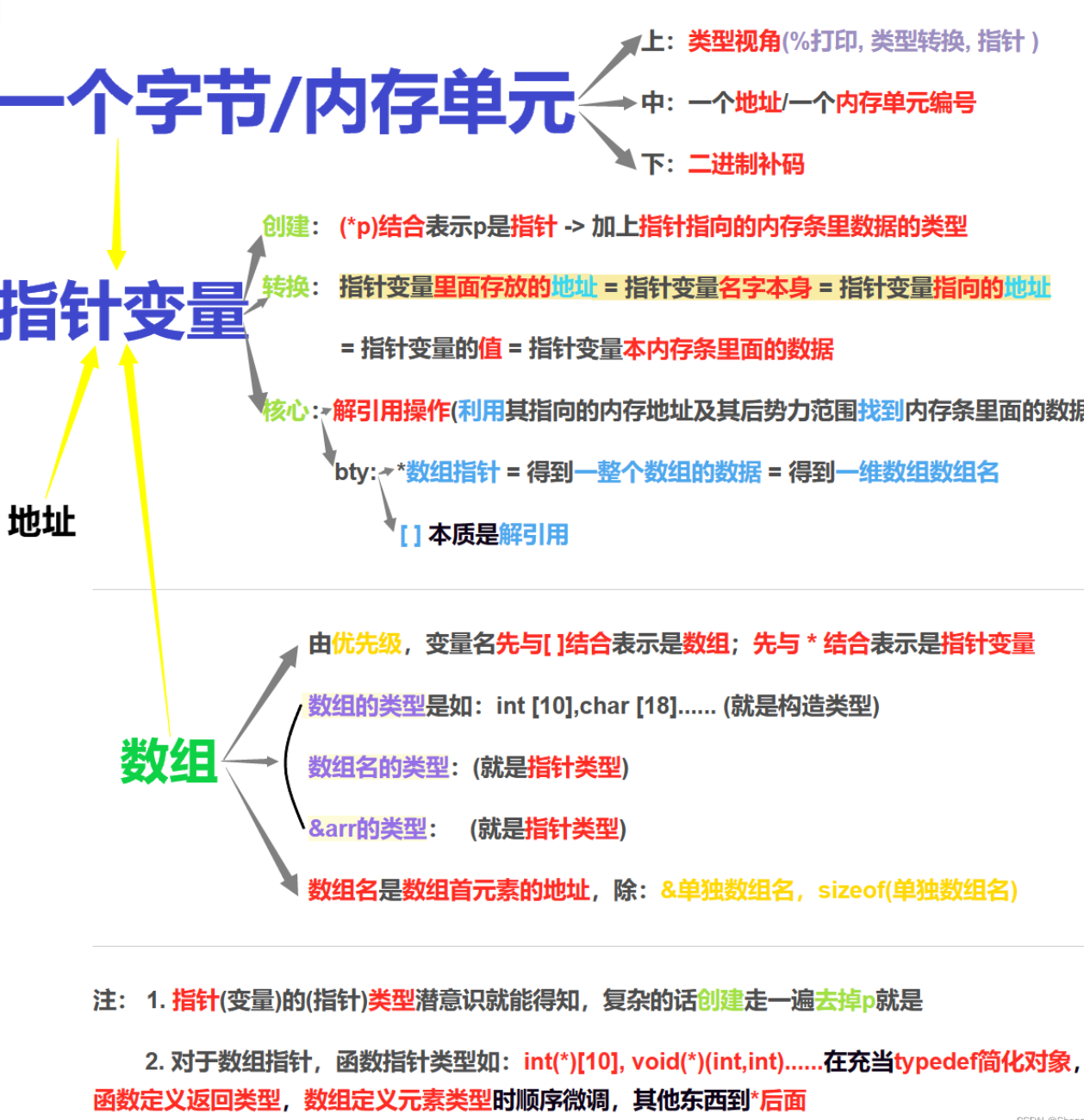
(C语言)指针进阶
问:1. ( ),[ ],->,,--,. ,*的操作符优先级是怎么样的?2. Solve the problems:只有一个常量字符串与一个字符指针,该怎么打印常量字符串所有内容…...

DS期末复习卷(三)
选择题 某数据结构的二元组形式表示为A(D,R),D{01,02,03,04,05,06,07,08,09},R{r},r{<01,02>,<01&a…...

Java链表模拟实现+LinkedList介绍
文章目录一、模拟实现单链表成员属性成员方法0,构造方法1,addFirst——头插2,addLast——尾插3,addIndex——在任意位置插入3.1,checkIndex——判断index合法性3.2,findPrevIndex——找到index-1位置的结点…...

信发系统-排版/发布 配置操作教程-智慧大屏幕—东方仙盟
政务大屏幕节目管理-选择系统模板选择对应行业选择适合的模板选中你的节目点击设计设计节目直接管理/上传 资源:图片/视频/网页/文字/文档手指/鼠标选中显示区域上传资源,在右侧点击上传从资源库选择图片选择历史素材上传网站选中网页区域点击上传配置文…...


信息安全工程师-主动防御体系核心技术:从监测溯源到隐私保护全解析
一、引言(一)技术定义与软考定位主动防御是相对于被动防御的安全理念,核心是通过主动诱捕、溯源标记、容忍恢复等技术,突破传统 “边界防护 事后补救” 的局限,实现攻击全生命周期的管控。本文涉及的数字水印、网络攻…...

Codex客户端Mac低版本安装解决方法
Codex客户端Mac低版本安装解决方法 关键词:Codex客户端安装、Mac系统版本过低、无法安装Codex、Mac兼容性问题解决、Codex客户端下载、Mac软件安装失败 在实际开发环境里,很多工具对 macOS 版本都有最低要求限制。最近在本地尝试安装 Codex 客户端时&am…...

MyBatis如何实现动态数据源切换?
MyBatis如何实现动态数据源切换 在现代应用中,特别是微服务架构中,使用多个数据库的情况越来越常见。MyBatis是一个流行的Java持久层框架,它允许我们方便地与多种数据库进行交互。在某些情况下,我们可能需要动态切换数据源&#x…...

何为可编程控制器?可编程控制器4大内容介绍
可编程控制器在控制中常为使用,因此本文将从4大方面对可编程控制器予以介绍,以增进大家对可编程控制器的了解。这4大方面包括:1.何为可编程控制器?2. 可编程控制器的基本组成,3. 可编程控制器发展史,以及4. 可编程控制…...

CANN/asc-devkit矢量取倒数API
asc_rcp 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/ca…...

如何准确计算宏基因组覆盖率?CoverM工具的全方位技术解析
如何准确计算宏基因组覆盖率?CoverM工具的全方位技术解析 【免费下载链接】CoverM Read alignment statistics for metagenomics 项目地址: https://gitcode.com/gh_mirrors/co/CoverM 在宏基因组研究中,覆盖率计算是评估测序深度、估算物种丰度和…...

【信息科学与工程学】【财务管理】 第二十三篇 ICT行业商业逻辑分析框架03
136. 硅光子集成芯片的激光器外延片 行业代码 行业名称 行业级别 产品/服务 商业逻辑核心 投资者类型与代表公司/机构 外部关系类型与关联公司 销售与买卖经营 供应链经营 利益/利润设计/资源绑定/信息宣传 分销商/代理商/关系节点 销售策略、打法与复杂关系网络 3…...

基于树莓派与ChatGPT打造私有智能音箱:从硬件选型到AI集成全攻略
1. 项目概述:打造一个会思考的智能音箱 如果你和我一样,对智能家居充满热情,但又对市面上那些“大厂”智能音箱的隐私策略和有限的对话能力感到不满,那么这个项目可能就是为你量身定做的。今天要聊的,是一个完全由自己…...