第T5周:使用TensorFlow实现运动鞋品牌识别
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
文章目录
- 一、前期工作
- 1.设置GPU(如果使用的是CPU可以忽略这步)
- 2. 导入数据
- 3. 查看数据
- 二、数据预处理
- 1、加载数据
- 2、数据可视化
- 3、再次检查数据
- 4、配置数据集
- 三、构建CNN网络
- 四、训练模型
- 1、设置动态学习率
- 2、早停与保存最佳模型参数
- 3、模型训练
- 五、模型评估
- 1、Loss与Accuracy图
- 2、尝试更改initial_learning_rate=0.001
- 3、指定图片预测
- 六、总结
电脑环境:
语言环境:Python 3.8.0
编译器:Jupyter Notebook
深度学习环境:tensorflow 2.15.0
一、前期工作
1.设置GPU(如果使用的是CPU可以忽略这步)
from tensorflow import keras
from keras import layers, models
import os, PIL, pathlib
import matplotlib.pyplot as plt
import tensorflow as tfgpus = tf.config.list_physical_devices("GPU")if gpus:gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPUtf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用tf.config.set_visible_devices([gpu0],"GPU")
2. 导入数据
data_dir = "./data/"
data_dir = pathlib.Path(data_dir)
3. 查看数据
image_count = len(list(data_dir.glob('*/*/*.jpg')))
print("图片总数为:",image_count)
输出:图片总数为: 578
打开一张图片:
Monkeypox = list(data_dir.glob('train/nike/*.jpg'))
PIL.Image.open(str(Monkeypox[1]))

二、数据预处理
1、加载数据
使用image_dataset_from_directory方法将磁盘中的数据加载到tf.data.Dataset中。
batch_size = 32
img_height = 224
img_width = 224train_ds = tf.keras.preprocessing.image_dataset_from_directory("./data/train/",seed=123,image_size=(img_height, img_width),batch_size=batch_size)val_ds = tf.keras.preprocessing.image_dataset_from_directory("./data/test/",seed=123,image_size=(img_height, img_width),batch_size=batch_size)
我们可以通过class_names输出数据集的标签。标签将按字母顺序对应于目录名称。
class_names = train_ds.class_names
print(class_names)
输出:
[‘adidas’, ‘nike’]
2、数据可视化
plt.figure(figsize=(20, 10))for images, labels in train_ds.take(1):for i in range(20):ax = plt.subplot(5, 10, i + 1)plt.imshow(images[i].numpy().astype("uint8"))plt.title(class_names[labels[i]])plt.axis("off")

3、再次检查数据
for image_batch, labels_batch in train_ds:print(image_batch.shape)print(labels_batch.shape)break
输出:
(32, 224, 224, 3)
(32,)
4、配置数据集
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
三、构建CNN网络
"""
关于卷积核的计算不懂的可以参考文章:https://blog.csdn.net/qq_38251616/article/details/114278995layers.Dropout(0.4) 作用是防止过拟合,提高模型的泛化能力。
关于Dropout层的更多介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/115826689
"""model = models.Sequential([layers.experimental.preprocessing.Rescaling(1./255, input_shape=(img_height, img_width, 3)),layers.Conv2D(16, (3, 3), activation='relu', input_shape=(img_height, img_width, 3)), # 卷积层1,卷积核3*3 layers.AveragePooling2D((2, 2)), # 池化层1,2*2采样layers.Conv2D(32, (3, 3), activation='relu'), # 卷积层2,卷积核3*3layers.AveragePooling2D((2, 2)), # 池化层2,2*2采样layers.Dropout(0.3), layers.Conv2D(64, (3, 3), activation='relu'), # 卷积层3,卷积核3*3layers.Dropout(0.3), layers.Flatten(), # Flatten层,连接卷积层与全连接层layers.Dense(128, activation='relu'), # 全连接层,特征进一步提取layers.Dense(len(class_names)) # 输出层,输出预期结果
])model.summary() # 打印网络结构
四、训练模型
1、设置动态学习率
ExponentialDecay函数:
tf.keras.optimizers.schedules.ExponentialDecay是 TensorFlow 中的一个学习率衰减策略,用于在训练神经网络时动态地降低学习率。学习率衰减是一种常用的技巧,可以帮助优化算法更有效地收敛到全局最小值,从而提高模型的性能。
主要参数:
- initial_learning_rate(初始学习率):初始学习率大小。
- decay_steps(衰减步数):学习率衰减的步数。在经过 decay_steps 步后,学习率将按照指数函数衰减。例如,如果 decay_steps 设置为 10,则每10步衰减一次。
- decay_rate(衰减率):学习率的衰减率。它决定了学习率如何衰减。通常,取值在 0 到 1 之间。
- staircase(阶梯式衰减):一个布尔值,控制学习率的衰减方式。如果设置为 True,则学习率在每个 decay_steps 步之后直接减小,形成阶梯状下降。如果设置为 False,则学习率将连续衰减。
# 设置初始学习率
initial_learning_rate = 0.1lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(initial_learning_rate, decay_steps=10, # 敲黑板!!!这里是指 steps,不是指epochsdecay_rate=0.92, # lr经过一次衰减就会变成 decay_rate*lrstaircase=True)# 将指数衰减学习率送入优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)model.compile(optimizer=optimizer,loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])
注:这里设置的动态学习率为:指数衰减型(ExponentialDecay)。在每一个epoch开始前,学习率(learning_rate)都将会重置为初始学习率(initial_learning_rate),然后再重新开始衰减。计算公式如下:
learning_rate = initial_learning_rate * decay_rate ^ (step / decay_steps)
2、早停与保存最佳模型参数
EarlyStopping()参数说明:
- monitor: 被监测的数据。
- min_delta: 在被监测的数据中被认为是提升的最小变化, 例如,小于 min_delta 的绝对变化会被认为没有提升。
- patience: 没有进步的训练轮数,在这之后训练就会被停止。
- verbose: 详细信息模式。
- mode: {auto, min, max} 其中之一。 在 min 模式中, 当被监测的数据停止下降,训练就会停止;在 max 模式中,当被监测的数据停止上升,训练就会停止;在 auto 模式中,方向会自动从被监测的数据的名字中判断出来。
- baseline: 要监控的数量的基准值。 如果模型没有显示基准的改善,训练将停止。
- estore_best_weights: 是否从具有监测数量的最佳值的时期恢复模型权重。 如果为 False,则使用在训练的最后一步获得的模型权重。
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStoppingepochs = 50# 保存最佳模型参数
checkpointer = ModelCheckpoint('best_model.h5',monitor='val_accuracy',verbose=1,save_best_only=True,save_weights_only=True)# 设置早停
earlystopper = EarlyStopping(monitor='val_accuracy', min_delta=0.001,patience=20, verbose=1)
3、模型训练
history = model.fit(train_ds,validation_data=val_ds,epochs=epochs,callbacks=[checkpointer, earlystopper])
Epoch 1/50
15/16 [===========================>..] - ETA: 0s - loss: 0.7137 - accuracy: 0.5021
Epoch 1: val_accuracy improved from -inf to 0.50000, saving model to best_model.h5
16/16 [==============================] - 3s 73ms/step - loss: 0.7141 - accuracy: 0.4920 - val_loss: 0.6969 - val_accuracy: 0.5000
Epoch 2/50
15/16 [===========================>..] - ETA: 0s - loss: 0.6964 - accuracy: 0.4681
Epoch 2: val_accuracy did not improve from 0.50000
16/16 [==============================] - 1s 42ms/step - loss: 0.6967 - accuracy: 0.4602 - val_loss: 0.6935 - val_accuracy: 0.5000
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
16/16 [==============================] - 1s 45ms/step - loss: 0.6936 - accuracy: 0.5000 - val_loss: 0.6932 - val_accuracy: 0.5000
Epoch 21/50
15/16 [===========================>..] - ETA: 0s - loss: 0.6957 - accuracy: 0.4532
Epoch 21: val_accuracy did not improve from 0.50000
16/16 [==============================] - 1s 44ms/step - loss: 0.6955 - accuracy: 0.4562 - val_loss: 0.6935 - val_accuracy: 0.5000
Epoch 21: early stopping
从输出结果看到val_accuracy一直=0.5000,那么肯定是哪里不对了。
五、模型评估
1、Loss与Accuracy图
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']loss = history.history['loss']
val_loss = history.history['val_loss']epochs_range = range(len(loss))plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
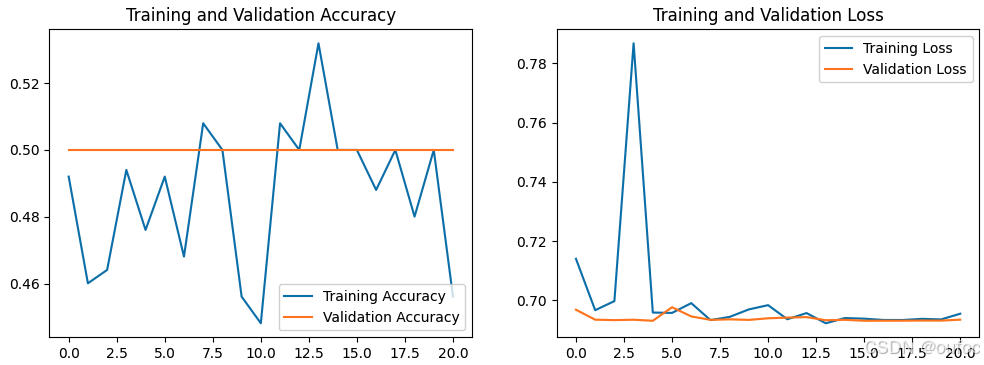
2、尝试更改initial_learning_rate=0.001
再次训练输出结果为:
Epoch 1/50
16/16 [==============================] - ETA: 0s - loss: 5.3369 - accuracy: 0.4940
Epoch 1: val_accuracy improved from -inf to 0.52632, saving model to best_model.h5
16/16 [==============================] - 128s 1s/step - loss: 5.3369 - accuracy: 0.4940 - val_loss: 0.6984 - val_accuracy: 0.5263
Epoch 2/50
15/16 [===========================>..] - ETA: 0s - loss: 0.6932 - accuracy: 0.5021
Epoch 2: val_accuracy improved from 0.52632 to 0.61842, saving model to best_model.h5
16/16 [==============================] - 1s 65ms/step - loss: 0.6924 - accuracy: 0.5080 - val_loss: 0.6893 - val_accuracy: 0.6184
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
Epoch 43/50
15/16 [===========================>..] - ETA: 0s - loss: 0.1565 - accuracy: 0.9596
Epoch 43: val_accuracy did not improve from 0.85526
16/16 [==============================] - 1s 45ms/step - loss: 0.1579 - accuracy: 0.9582 - val_loss: 0.4551 - val_accuracy: 0.8421
Epoch 43: early stopping

这里看到减小了initial_learning_rate后效果好了很多。
3、指定图片预测
# 加载效果最好的模型权重
model.load_weights('best_model.h5')
from PIL import Image
import numpy as npimg = Image.open("./data/test/nike/1.jpg") #这里选择你需要预测的图片
image = tf.image.resize(img, [img_height, img_width])# expand_dims函数:在索引=axis处增加一个值为1的维度,这里使得image变成一个一张图片的一个批次
img_array = tf.expand_dims(image, 0) #/255.0 # 记得做归一化处理(与训练集处理方式保持一致)predictions = model.predict(img_array) # 这里选用你已经训练好的模型
print("预测结果为:",class_names[np.argmax(predictions)])
输出:
1/1 [==============================] - 0s 422ms/step
预测结果为: nike
预测正确。
六、总结
- 学习到tensorflow中的动态学习率函数:
ExponentialDecay - 模型的初始学习率不能设置过大:过大的学习率可能导致模型不收敛且模型精度太差;当然也不能太小,太小模型收敛慢,难跳出局部最优。
- 学习到使模型因没有改善早结束训练函数:
EarlyStopping
相关文章:
第T5周:使用TensorFlow实现运动鞋品牌识别
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 文章目录 一、前期工作1.设置GPU(如果使用的是CPU可以忽略这步)2. 导入数据3. 查看数据 二、数据预处理1、加载数据2、数据可视化3、再…...

网络编程学习之tcp
按下*(星号)可以搜索当前光标下的单词。 Tcp编程的过程 打开网络设备 Bind:给服务地址把ip号和端口号连接进去 Tcp是有状态的 Listen是进入监听状态,看有没有客户端来连接服务器 Tcp比udp消耗过多资源 Upd类似于半双工&#…...

前端XMLHttpRequest、Fetch API、Axios实现文件上传、下载方法及后端Spring文件服务器处理方法
前言 本文总结Web应用开发中文件上传、下载的方法,即从前端表单输入文件并封装表单数据,然后请求后端服务器的处理过程;从基础的JavaScript中XmlHttpRequest对象、Fetch API实现上传、下载进行说明,并给出了前端常用的axios库的请…...

STM32智能交通监测系统教程
目录 引言环境准备智能交通监测系统基础代码实现:实现智能交通监测系统 4.1 数据采集模块 4.2 数据处理与控制模块 4.3 通信与网络系统实现 4.4 用户界面与数据可视化应用场景:交通监测与管理问题解决方案与优化收尾与总结 1. 引言 智能交通监测系统通…...

【利用Selenium+autoIt实现文件上传】
利用Selenium+autoIt实现文件上传 利用Selenium+autoIT实现文件上传autoIt脚本制作转换成exe文件java代码运行部分利用Selenium+autoIT实现文件上传 当你看到这篇文章时,证明你遇到了和我一样的难题。正常情况下我们利用selenium完全可以实现表单的提交和文件上传等操作。但当…...

python join
1、join函数 *.join(seq) 以*作为分隔符,将seq所有的元素合并为一个新的字符串 seq ABDWDPO new_seq list(.joint(seq)) # ABDWDPO #[A, B, D, W, D, P, O]...

cython加速python代码
python这个语言在使用的层面上看几乎没有缺点,简单易学,语法简单,唯一的弱点就是慢, 当然了万能的python社区是给了解决方法的,那就是cython 使用Cython可以显著提升Python代码的执行效率,特别是在涉及到数…...

React@16.x(60)Redux@4.x(9)- 实现 applyMiddleware
目录 1,applyMiddleware 原理2,实现2.1,applyMiddleware2.1.1,compose 方法2.1.2,applyMiddleware 2.2,修改 createStore 接上篇文章:Redux中间件介绍。 1,applyMiddleware 原理 R…...

level 6 day1 Linux网络编程之网络基础
v1 网络的历史和分层 TCP 是可靠传输,IP协议是不可靠传输 网络的体系结构 网络分层的思想: OSI体系结构 两层交换机是指数据链路层的交换 三层交换是指网络层这边的交换 四层模型 蓝色的字 是由手机发给PC机,由传输层来决定应该交给哪一…...

PostgreSQL UPDATE 命令
PostgreSQL UPDATE 命令 PostgreSQL 是一种功能强大的开源对象关系型数据库管理系统(ORDBMS),它使用并扩展了SQL语言。在处理数据库时,我们经常需要更新现有的记录。在PostgreSQL中,UPDATE命令用于修改表中的现有记录…...

什么? CSS 将支持 if() 函数了?
CSS Working Group 简称 CSSWG, 在近期的会议中决定将 if() 添加到 CSS Values Module Level 5 中。 详情可见:css-meeting-bot 、[css-values] if() function 当我看到这个消息的时候,心中直呼这很逆天了,我们知道像 less 这些 css 这些预…...

function calling实现调用理杏仁api获取数据
LLM是不存在真正逻辑的且并不是知晓万事万物的(至少目前是这样)在很多更垂直的环境下LLM并不能很好的赋能。 function calling的实现使LLM可以对接真正的世界以及真正有逻辑的系统,这将很大程度上改变LLM的可用范围(当然安全问题依…...

Excel中用VBA实现Outlook发送当前工作簿
Excel中用VBA实现Outlook发送当前工作簿,首先按AltF11打开VBA编辑器,插入模块,并在工具-引用中勾选 Microseft Outlook .0 Object Library(其中为你Microseft Outlook的版本号。 Sub 发送邮件() 保存当前excel ThisWorkbook.Save让excel连接…...
从 ArcMap 迁移到 ArcGIS Pro
许多 ArcMap 用户正在因 ArcGIS Pro 所具有的现代 GIS 桌面工作流优势而向其迁移。 ArcGIS Pro 与其余 ArcGIS 平台紧密集成,使您可以更有效地共享和使用内容。 它还将 2D 和 3D 组合到一个应用程序中,使您可以在同一工程中使用多个地图和多个布局。 Arc…...

WSL2 的安装与运行 Linux 系统
前言 适用于 Linux 的 Windows 子系统 (WSL) 是 Windows 的一项功能,允许开发人员在 Windows 系统上直接安装并使用 Linux 发行版。不用进行任何修改,也无需承担传统虚拟机或双启动设置的开销。 可以将 WSL 看作也是一个虚拟机,但是它更为便…...

业务终端动态分配IP-DHCP技术、DHCP中继技术
一、为什么需要DHCP? 1、许多设备(主机、无线WiFi终端等)需要动态地址的分配; 2、人工手工配置任务繁琐、容易出错,比如:IP地址冲突; 3、网络规模扩大、复杂度提高,网络配置越来越复杂,计算机的位置变化和数量超过可分配IP地址的数量,造成IP地址变法频繁以及IP地址…...

新一代大语言模型 GPT-5 对工作与生活的影响及应对策略
文章目录 📒一、引言 📒二、GPT-5 的发展背景 🚀(一)GPT-4 的表现与特点 🚀(二)GPT-5 的预期进步 📒三、GPT-5 对工作的影响 🚀(一…...

AI基于大模型语言存在的网络安全风险
目的: 随着大语言模型(LLM)各领域的广泛应用,我们迫切需要了解其中潜在的风险和威胁,及时进行有效的防御。 申明: AI技术的普及正当的使用大模型技术带来的便利,切勿使用与非法用途ÿ…...

探索Perl语言:入门学习与实战指南
文章目录 探索Perl语言:入门学习与实战指南一、Perl语言概述二、Perl的安装与配置安装PerlWindowsmacOSLinux 配置Perl 三、基本语法与数据类型标量变量数组哈希 四、控制结构条件语句循环语句 五、子程序与模块子程序模块 六、文件操作与正则表达式文件读取与写入正…...

dp or 数学问题
看一下数据量,只有一千,说明这个不是数学问题 #include<bits/stdc.h> using namespace std;#define int long long const int mo 100000007; int n, s, a, b; const int N 1005;// 2 -3 // 1 3 5 2 -1 // 1 -2 -5 -3 -1 int dp[N][N]; int fun…...

PyTorch 2.8镜像实际效果:torch.compile+FlashAttention-2双优化下的吞吐量提升对比
PyTorch 2.8镜像实际效果:torch.compileFlashAttention-2双优化下的吞吐量提升对比 1. 镜像环境与技术亮点 PyTorch 2.8深度学习镜像为开发者提供了一个开箱即用的高性能计算环境。基于RTX 4090D 24GB显卡和CUDA 12.4的深度优化组合,这个镜像特别适合需…...

HDSceneColor节点]原理解析与实际应用
渲染管线兼容性详解HD Scene Color节点的可用性完全取决于所使用的渲染管线,这是开发者在选择和使用该节点时必须首先考虑的因素。高清渲染管线(HDRP)支持HDRP是Unity针对高端平台和高端硬件设计的高保真渲染解决方案HD Scene Color节点专为H…...

原神高帧率解锁终极方案:一键突破60帧限制的完全指南
原神高帧率解锁终极方案:一键突破60帧限制的完全指南 【免费下载链接】genshin-fps-unlock unlocks the 60 fps cap 项目地址: https://gitcode.com/gh_mirrors/ge/genshin-fps-unlock 想象一下这样的场景:你在蒙德的原野上自由奔跑,角…...

Arduino_Threads:Mbed OS平台的嵌入式多线程实践框架
1. Arduino_Threads 库深度解析:面向 Mbed OS 的嵌入式多线程实践框架1.1 库定位与工程价值Arduino_Threads 是 Arduino 官方为基于 Mbed OS 核心的 Arduino 开发板(如 Nano RP2040 Connect、Portenta H7、Nicla Sense ME 等)设计的轻量级多线…...

ComfyUI ControlNet模型与预处理器搭配秘籍:提升AI绘画精度的关键技巧
ComfyUI ControlNet模型与预处理器搭配秘籍:提升AI绘画精度的关键技巧 在AI绘画领域,ControlNet已经成为精细控制图像生成的重要工具。对于已经熟悉ComfyUI基础操作的用户来说,掌握ControlNet模型与预处理器的搭配技巧,是突破创作…...

DS4Windows手柄适配工具全解析:从安装到高级配置的完美指南
DS4Windows手柄适配工具全解析:从安装到高级配置的完美指南 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 在PC游戏领域,手柄支持一直是玩家体验的关键环节。许多…...

眼图分析:高速数字信号完整性的关键工具
1. 眼图基础概念解析 眼图(Eye Diagram)是数字信号完整性分析中最重要的工具之一。作为一名硬件工程师,我每天都会用眼图来评估信号质量。简单来说,眼图就是将数字信号在时间轴上重复叠加后形成的图形,因其形状类似人眼…...

如何选择ComfyUI-FramePackWrapper的模型加载方案?从技术选型到场景适配全解析
如何选择ComfyUI-FramePackWrapper的模型加载方案?从技术选型到场景适配全解析 【免费下载链接】ComfyUI-FramePackWrapper 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-FramePackWrapper 在AI视频生成工作流中,模型加载是影响效率与稳…...

优化算法避坑指南:为什么BFGS比DFP更常用?从数值稳定性到工程实践详解
优化算法避坑指南:为什么BFGS比DFP更常用?从数值稳定性到工程实践详解 在机器学习模型训练和工程优化问题中,我们常常需要求解无约束优化问题。当目标函数的海森矩阵难以计算或维度较高时,拟牛顿法因其出色的平衡性成为首选。但面…...

实战工业测控:基于快马AI生成LabVIEW与数据库、Web集成的监控系统
今天想和大家分享一个最近用LabVIEW实现的工业测控项目实战经验。这个项目是为某制造车间设计的生产线监控系统,主要实现了设备数据采集、存储和可视化展示的全流程。下面我会分步骤详细介绍实现过程。 数据采集模块设计 这个环节需要实时获取产线上多个设备的运行…...