详细解析Kafaka Streams中各个DSL操作符的用法
什么是DSL?
在Kafka Streams中,DSL(Domain Specific Language)指的是一组专门用于处理Kafka中数据流的高级抽象和操作符。这些操作符以声明性的方式定义了数据流的转换、聚合、连接等处理逻辑,使得开发者可以更加专注于业务逻辑的实现,而不是底层的数据流处理细节。
Kafka Streams的DSL主要包括以下几个方面的操作符:
-
转换操作符(Transformation Operators):这些操作符用于对KStream或KTable中的数据进行转换,如
map、flatMap、filter等。它们允许你对流中的每个元素应用一个函数,从而生成新的流或表。 -
聚合操作符(Aggregation Operators):聚合操作符通常与
groupBy一起使用,用于将数据分组,并对每个组内的数据进行聚合操作,如count、aggregate、reduce等。这些操作符可以生成KTable,表示每个键的聚合结果。 -
连接和合并操作符(Join and Merge Operators):这些操作符允许你将两个或多个流或表进行连接或合并操作,如
join、outerJoin、merge等。它们可以根据键将来自不同源的数据合并起来,以支持更复杂的业务逻辑。 -
窗口化操作符(Windowing Operators):窗口化操作符与聚合操作符结合使用,用于对时间窗口内的数据进行聚合。它们允许你定义时间窗口的大小,并在这个窗口内对数据进行聚合操作。Kafka Streams提供了多种类型的窗口,如滚动窗口(Tumbling Windows)、滑动窗口(Sliding Windows)和会话窗口(Session Windows)等。
-
状态存储操作符(State Store Operators):Kafka Streams中的状态存储操作符允许你在处理过程中保存状态,以便在需要时进行访问或更新。状态存储是Kafka Streams实现有状态操作(如聚合、连接等)的基础。Kafka Streams提供了多种类型的状态存储,如键值存储(KeyValue Stores)、窗口存储(Window Stores)等。
通过使用这些DSL操作符,开发者可以构建出复杂的数据处理管道,实现数据的实时分析、监控、转换等需求。同时,Kafka Streams还提供了灵活的配置选项和可扩展的架构,使得它能够满足不同规模和复杂度的数据处理需求。
实例演示
下面将通过一系列的代码示例来详细解析Kafka Streams中各个DSL操作符的用法。这些示例假设你已经创建了一个基本的Spring Boot项目,并且包含了Kafka Streams的依赖:
<!-- Maven依赖 -->
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><version>2.7.1</version>
</dependency>
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-streams</artifactId><version>2.7.1</version>
</dependency>
1. stream()
- 用途:从输入主题创建一个
KStream。 - 示例:
KStream<String, String> stream = builder.stream("input-topic");
2. filter()
- 用途:根据给定的条件过滤流中的记录。
- 示例:过滤出值大于10的记录。
KStream<String, Integer> filteredStream = stream.filter((key, value) -> value > 10);
3. map()
- 用途:将流中的每个记录转换为一个新的记录。
- 示例:将值转换为字符串的大写形式。
KStream<String, String> upperCasedStream = stream.mapValues(value -> value.toUpperCase());
4. flatMap()
- 用途:将流中的每个记录转换为零个、一个或多个新记录。
- 示例:将每个字符串拆分为单词列表。
KStream<String, String> flatMappedStream = stream.flatMapValues(value -> Arrays.asList(value.split("\\W+")));
5. peek()
- 用途:对每个记录执行一个操作,但不改变流本身。
- 示例:打印每个记录的值。
stream.peek((key, value) -> System.out.println("Key: " + key + ", Value: " + value));
6. groupByKey()
- 用途:根据键对流中的记录进行分组,生成一个
KGroupedStream。 - 示例:按键分组。
KGroupedStream<String, String> groupedStream = stream.groupByKey();
7. aggregate()
- 用途:对分组流执行聚合操作。
- 示例:计算每个键的值的总和。
关于KTable<String, Integer> aggregatedTable = groupedStream.aggregate(() -> 0, // 初始值(aggKey, newValue, aggValue) -> aggValue + newValue, // 聚合逻辑Materialized.as("aggregated-store") // 状态存储配置 );aggregate()的更详细用法,可以参考博主之前的一篇文章:浅析Kafka Streams中KTable.aggregate()方法的使用
8. join()
- 用途:将当前流与另一个流或表基于键进行连接。
- 示例:将当前流与另一个流连接。
KStream<String, String> joinedStream = stream.join(anotherStream,(value1, value2) -> value1 + ", " + value2, // 合并逻辑JoinWindows.of(Duration.ofMinutes(5)) // 窗口配置 );
9. through()
- 用途:将流数据发送到中间主题,并继续流处理。
- 示例:将流处理结果发送到中间主题,并继续处理。
KStream<String, String> throughStream = stream.mapValues(value -> value.toUpperCase()).through("intermediate-topic");
10. to()
- 用途:将流数据发送到输出主题。
- 示例:将处理后的流发送到输出主题。
stream.mapValues(value -> value.toUpperCase()).to("output-topic");
11. branch()
- 用途:根据条件将流分成多个分支。
- 示例:根据值的奇偶性将流分成两个分支。
KStream<String, Integer>[] branches = stream.branch((key, value) -> value % 2 == 0,(key, value) -> value % 2 != 0 );
12. merge()
- 用途:将多个流合并为一个流。
- 示例:合并两个流。
KStream<String, String> mergedStream = stream1.merge(stream2);
13. windowedBy()
- 用途:基于时间窗口对流进行分组。
- 示例:按小时窗口分组。
TimeWindowedKStream<String, String> windowedStream = stream.windowedBy(TimeWindows.of(Duration.ofHours(1)));
相关文章:

详细解析Kafaka Streams中各个DSL操作符的用法
什么是DSL? 在Kafka Streams中,DSL(Domain Specific Language)指的是一组专门用于处理Kafka中数据流的高级抽象和操作符。这些操作符以声明性的方式定义了数据流的转换、聚合、连接等处理逻辑,使得开发者可以更加专注…...

C++中链表的底层迭代器实现
大家都知道在C的学习中迭代器是必不可少的,今天我们学习的是C中的链表的底层迭代器的实现,首先我们应该先知道链表的底层迭代器和顺序表的底层迭代器在实现上有什么区别,为什么顺序表的底层迭代器更加容易实现,而链表的底层迭代器…...

3.5、matlab打开显示保存点云文件(.ply/.pcd)以及经典点云模型数据
1、点云数据简介 点云数据是三维空间中由大量二维点坐标组成的数据集合。每个点代表空间中的一个坐标点,可以包含有关该点的颜色、法向量、强度值等额外信息。点云数据可以通过激光扫描、结构光扫描、摄像机捕捉等方式获取,广泛应用于计算机视觉、机器人…...

Qt-事件与信号
事件和信号的区别在于,事件通常是由窗口系统或应用程序产生的,信号则是Qt定义或用户自定义的。Qt为界面组件定义的信号往往通常是对事件的封装,如QPushButton的clicked()信号可以看做对QEvent::MouseButtonRelease类事件的封装。 在使用界面组…...

数据结构 day3
目录 思维导图: 学习内容: 1. 顺序表 1.1 概念 1.2 有关顺序表的操作 1.2.1 创建顺序表 1.2.2 顺序表判空和判断满 1.2.3 向顺序表中添加元素 1.2.4 遍历顺序表 1.2.5 顺序表按位置进行插入元素 1.2.6 顺序表任意位置删除元素 1.2.7 按值进…...

Kubernetes面试整理-如何进行滚动更新和回滚?
在 Kubernetes 中,滚动更新和回滚是管理应用程序版本的常用操作。滚动更新允许您逐步替换现有的 Pod 实例,以便在不中断服务的情况下部署新版本。回滚则是在新版本出现问题时恢复到之前的版本。 滚动更新 通过 Deployment 进行滚动更新 1. 创建一个 Deployment: 下面是一个…...

flutter ios打包 xcode报错module ‘xxx‘ not found
flutter ios打包 xcode报错module ‘xxx’ not found 如果已经在androidstudio中成功运行了flutter build ios --release。 那么可能是你使用xcode打开的是ios/Runner.xcodeproj文件。 你关掉xcode,重新打开ios/Runner.xcworkspace/文件。然后重新archiveÿ…...
LLM 构建Data Multi-Agents 赋能数据分析平台的实践之④:数据分析之三(数据展示)
概述 在先前探讨的文章中,我们构建了一个全面的数据测试体系,该体系遵循“数据获取—数据治理—数据分析”的流程。如何高效地构建数据可视化看板,以直观展现分析结果,正逐渐成为利用新兴技术提升效能的关键领域。伴随业务拓展、数…...

Elasticsearch 批量更新
Elasticsearch 批量更新 准备条件查询数据批量更新 准备条件 以下查询操作都基于索引crm_flow_info来操作,索引已经建过了,本文主要讲Elasticsearch批量更新指定字段语句,下面开始写更新语句执行更新啦! 查询数据 查询指定shif…...

【Pytorch笔记】张量
torch.Tensor() 是 PyTorch 库中用于创建张量的一个函数。在 PyTorch 中,张量是多维数组,它们可以存储在 CPU 或 GPU 上,并且支持自动求导,这使得它们非常适合进行深度学习和科学计算。 张量可以在Python list形式下通过 torch.T…...

查找json中指定节点的值,替换为指定的值
有时我们封装好的实体转化成的json字段的值和第三方要求的不一样,比如我们字段的值是字符串,我们需要使用int类型的值,就需要将这个键的值转化成int类型。 比如将以下 convulsionNumber字段中字符串的值“一次”替换为0 {"convulsionT…...

Android 14 开机时间优化措施
Android开机优化系列文档-CSDN博客 Android 14 开机时间优化措施汇总-CSDN博客Android 14 开机时间优化措施-CSDN博客根据systrace报告优化系统时需要关注的指标和优化策略-CSDN博客Android系统上常见的性能优化工具-CSDN博客Android上如何使用perfetto分析systrace-CSDN博客A…...

【QGroundControl二次开发】二.使用QT编译QGC(Windows)
【QGroundControl二次开发】一.开发环境准备(Windows) 二. 使用QT编译QGC(Windows) 2.1 打开QT Creator,选择打开项目,打开之前下载的QGC项目源码。 编译器选择Desktop Qt 6.6.3 MSVC2019 64bit。 点击运…...

[C/C++入门][变量和运算]4、带余除法
给定被除数和除数,求整数商及余数 看到这个题,我们都知道C的除法运算符 /,默认是不带余数的。那现在要求带余数,需要能够想到% %,是C获取余数的方法:比如5/22; 5%21;%得到的是除后的余数。 #inc…...
常用优秀内网穿透工具(实测详细版)
文章目录 1、前言2、安装Nginx3、配置Nginx4、启动Nginx服务4.1、配置登录页面 5、内网穿透5.1、cpolar5.1.1、cpolar软件安装5.1.2、cpolar穿透 5.2、Ngrok5.2.1、Ngrok安装5.2.2、随机域名5.2.3、固定域名5.2.4、前后端服务端口 5.3、NatApp5.4、Frp5.4.1、下载Frp5.4.2、暴露…...
防火墙NAT地址转换和智能选举综合实验
一、实验拓扑 目录 一、实验拓扑 二、实验要求(接上一个实验要求后) 三、实验步骤 3.1办公区设备可以通过电信链路和移动链路上网(多对多的NAT,并且需要保留一个公网IP不能用来转换) 3.2分公司设备可以通过总公司的移动链路和电信链路访…...
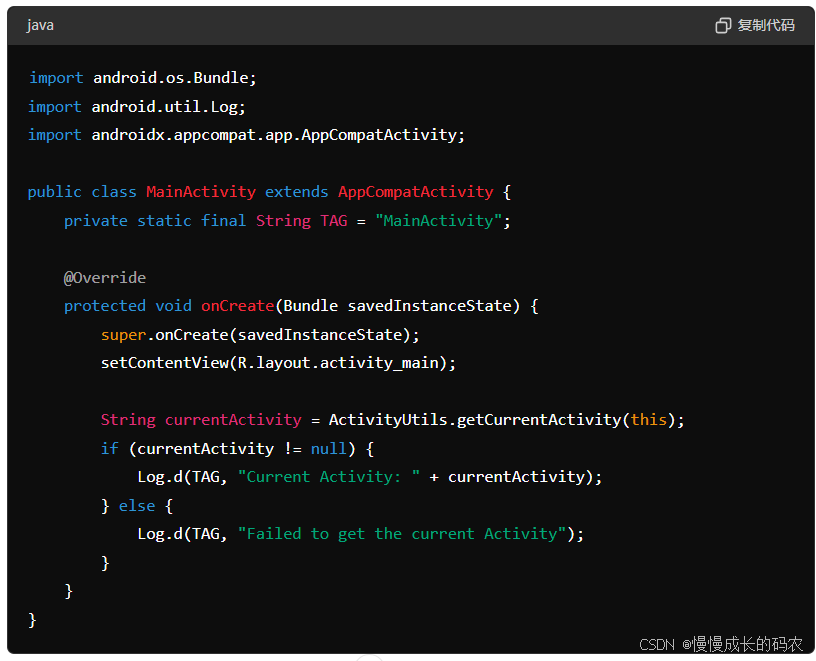
Android获取当前屏幕显示的是哪个activity
在 Android 中,要获取当前屏幕显示的 Activity,可以使用以下几种方法: 方法一:使用 ActivityManager 获取当前运行的任务信息 这是一个常见的方法,尽管从 Android 5.0 (API 21) 开始,有些方法变得不太可靠…...
JVM:自动垃圾回收
文章目录 一、C/C的内存管理二、Java的内存管理1、方法去的回收2、堆回收(1)引用计数法和可达性分析法(2)五种对象引用(3)垃圾回收算法 一、C/C的内存管理 在C和C没有自动垃圾回收机制,一个对象…...

【填坑指南】PHP8报:Unable to load dynamic library ‘zip.so’ 错误
1.原因分析 这种情况多数发生在PHP安装时因为各种原因失败后,残余的库与最后安装的PHP版本不兼容导致的。 2.我的路径 一开始我按照以前摸索出来的安装PHP7.3的成功经验来编译方法安装PHP8.3,发现以前的套路已经失效了。反复重装PHP8.3失败后…...
鸿蒙语言基础类库:【@system.notification (通知消息)】
通知消息 说明: 从API Version 7 开始,该接口不再维护,推荐使用新接口[ohos.notification]。本模块首批接口从API version 3开始支持。后续版本的新增接口,采用上角标单独标记接口的起始版本。 导入模块 import notification fro…...

基于VitePress构建开源AI智能体框架深度中文文档站实战指南
1. 项目概述:一个为AI智能体框架量身打造的中文文档站如果你正在寻找一个能帮你把Claude、GPT这些大模型快速接入到微信、Telegram、飞书等聊天软件的开源框架,那你大概率会接触到OpenClaw(原名ClawdBot)。但当你兴冲冲地打开官方…...

收藏必备!小白程序员轻松入门大模型:ReAct与Reflexion核心技术与实战应用
大语言模型(LLM)在复杂任务中存在事实幻觉、缺乏实时信息等局限。本文介绍ReAct和Reflexion两大提示技术框架,ReAct通过推理与行动协同,有效解决幻觉问题;Reflexion在ReAct基础上增加自我反思机制,形成闭环…...

5分钟掌握飞书文档高效转换:开源浏览器扩展的完整解决方案
5分钟掌握飞书文档高效转换:开源浏览器扩展的完整解决方案 【免费下载链接】cloud-document-converter Convert Lark Doc to Markdown 项目地址: https://gitcode.com/gh_mirrors/cl/cloud-document-converter 还在为飞书文档格式转换而头疼吗?复…...

工程师实战指南:从原理到选型,全面解析电池核心技术参数与应用
1. 项目概述:为什么我们需要重新认识电池?干了三十多年电气工程,从数字电路、模拟信号到电源设计、通信协议和微控制器,我几乎把电子行业的各个角落都摸了一遍。现在我在一家叫MaxVision的公司,专门搞那种性能极端、皮…...

在Nodejs后端服务中集成Taotoken实现稳定高效的多模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Nodejs后端服务中集成Taotoken实现稳定高效的多模型调用 对于构建AI功能的后端Node.js开发者而言,直接对接单一模型供…...

RCB-F9T-0,支持多频段多星座及纳秒级精度的多协议GNSS授时板
简介今天我要向大家介绍的是 u-blox 的多频段GNSS授时板——RCB-F9T-0。这是一款专为高精度授时应用设计的紧凑型定时板。该模块基于 u-blox ZED-F9T-00B 高精度授时模块,搭载AEC-Q100认证的GNSS芯片;集成SMB天线连接器和5V有源天线供电电路;…...

PHPStudy本地开发,用上Redis 5的Stream和HyperLogLog到底有多香?
PHPStudy本地开发中Redis 5的Stream与HyperLogLog实战指南 Redis作为高性能的内存数据库,在PHP开发中扮演着重要角色。当我们在本地开发环境使用PHPStudy时,默认安装的Redis 3.0.504版本功能有限,无法体验Redis 5引入的强大新特性。本文将深…...

Anaconda环境翻车实录:从‘CondaMemoryError’到完美恢复的完整指南
Anaconda环境崩溃自救手册:从诊断到彻底修复的实战指南 那天下午,当你在终端第15次尝试运行conda update --all时,屏幕上突然跳出鲜红的"CondaMemoryError"字样,整个开发环境瞬间陷入瘫痪。这不是普通的报错,…...

开源量化分析平台Fin-Maestro:十大核心模块构建个人交易决策系统
1. 项目概述:一个为独立交易者打造的量化分析工具箱 如果你和我一样,在股票和加密货币市场里摸爬滚打了好些年,那你一定经历过这样的阶段:面对海量的K线图、财务数据和市场新闻,感觉信息过载,决策时总是犹…...

性价比高可代理的油烟分离油烟机的厂家
最近跟10多个开厨电店的老板喝茶,一半人唉声叹气:去年赚的钱全压库存里了,3个做了十几年的老老板说,再找不到好产品,今年打算把店转了。为啥好好的店做成这样?说白了就是选品选错了,风口变了&am…...