sqlalchemy.orm中validates对两个字段进行联合校验
版本
sqlalchemy==1.4.37
需求说明
有个场景,需要在orm中对两个字段进行联合校验,当 col1 ='xxx’时,对 col2的长度进行检查,超过限制(500)时,进行截断。
网上找了很久,没找到类似的实现,自己摸索出来了一套方法;
解决
在 validates 装饰器中,它是在设置字段值之前被调用的,validates 包装的函数校验完成后通过return赋值给字段
validates 的执行顺序 看起来是和 字段 传入ORM模型的顺序 一样。
如 下面案例 中的 model_instance 中,如果 col1 在 col2 之前,就会先校验和赋值 col1 ,反之,则先校验和赋值 col12
方案1
保证 model_instance 中 字段 col1 在 col2 之前,这样会先校验和赋值 col1 ,在校验 col2 时,self.col1 就不会为空,能正常进行校验。
如果先赋值col2,在 validate_col2 中,会self.col1会为None,导致校验失败
from sqlalchemy.orm import validates
from sqlalchemy import Column, String, Integer
from sqlalchemy.ext.declarative import declarative_baseBase = declarative_base()class MyModel(Base):__tablename__ = 'my_model'id = Column(Integer, primary_key=True)col1 = Column(String(50))col2 = Column(String(500)) # 假设col2的最大长度是500个字符@validates('col2')def validate_col2(self, key, value):# 检查col1的值是否为'xxx'if self.col1 == 'xxx':# 如果col1是'xxx',则校验col2的长度if len(value) > 500:value = value[:500]# 如果col1不是'xxx',可以选择不做任何操作或者添加其他逻辑return value # 示例使用1
# 先赋值 col1 再赋值 col2
model_instance = MyModel()
model_instance.col1 = 'xxx' # 假设这是触发条件的值
model_instance.col2 = 'a' * 501 # 这将触发长度校验# 示例使用2
datas = {'col1'= 'xxx', 'col2': 'a' * 501 }
# 先pop删除,再添加,就不管前面datas是怎么来的,可以保证 datas 中 col2会比col1后遍历到
_col2_v = datas.pop('col2')
datas['col2'] = _col2_v
model_instance = MyModel(**datas )try:# 假设这是保存模型到数据库的代码# session.add(model_instance)# session.commit()pass
except ValueError as e:print(e)
方案2
实例化orm模型后,再调用一遍 validate_col2 ,校验并赋值给col2
from sqlalchemy.orm import validates
from sqlalchemy import Column, String, Integer
from sqlalchemy.ext.declarative import declarative_baseBase = declarative_base()class MyModel(Base):__tablename__ = 'my_model'id = Column(Integer, primary_key=True)col1 = Column(String(50))col2 = Column(String(500)) # 假设col2的最大长度是500个字符@validates('col2')def validate_col2(self, key, value):# 检查col1的值是否为'xxx'if self.col1 == 'xxx':# 如果col1是'xxx',则校验col2的长度if len(value) > 500:value = value[:500]# 如果col1不是'xxx',可以选择不做任何操作或者添加其他逻辑return value # 示例使用1
# 先赋值 col1 再赋值 col2
model_instance = MyModel()
model_instance.col1 = 'xxx' # 假设这是触发条件的值
model_instance.col2 = 'a' * 501 # 这将触发长度校验# 示例使用2
datas = {'col1'= 'xxx', 'col2': 'a' * 501 }model_instance = MyModel(**datas )
# 上面实例化会自动调用所有的 `validates` 函数,下面再调用一遍`validate_col2`,
# 并且要用 `model_instance.col2` 接收返回值,不然 `model_instance.col2` 的值不会改变。
model_instance.col2 = model_instance.validate_col2('col2', datas['col2'])try:# 假设这是保存模型到数据库的代码# session.add(model_instance)# session.commit()pass
except ValueError as e:print(e)
方案3
无法保证 model_instance 中 字段 col1 在 col2 之前的顺序,采用 临时变量 __col1,存储 col1 的值,并对 col2 进行二次校验赋值
在 validate_col1 函数中,校验 col1,先把 value 值(就是没校验前的col1的值)赋给 self.__col1,然后再调用 validate_col1_and_col2 进行联合校验,最后通过 return把value赋值给 self.col1
在整个过程中,validate_col1_and_col2 会被调用3次
- 校验 col2 时,
validate_col2会调用一次 - 校验 col1 时,
self.col2 = self.validate_col1_and_col2(key='col2', value=self.col2)这一行会调用两次:- 一次是
self.validate_col1_and_col2执行; - 另一次是 1 执行完后对
self.col2赋值,会调用一次validate_col2,进而再调用一次
- 一次是
from sqlalchemy.orm import validates
from sqlalchemy import Column, String, Integer
from sqlalchemy.ext.declarative import declarative_basedef getStrLenAndTruncate(ss: str, max_length=500):"""获取字符串长度,超过部分截断:param ss::param max_length::return:"""slen = len(ss.encode('utf-8'))# 如果编码后的字符串长度小于或等于500字节,则不需要截断if slen <= max_length:return ss# 截断到500字节的长度,注意这里直接截断可能会导致字符不完整# 因此需要找到一个合适的截断点,确保截断后的字符串是完整的utf-8字符truncated_encoded = b''current_length = 0for char in ss:char_encoded = char.encode('utf-8')if current_length + len(char_encoded) <= max_length:truncated_encoded += char_encodedcurrent_length += len(char_encoded)else:breaktruncated_str = truncated_encoded.decode('utf-8', errors='ignore')print(f'原字符串编码后长度为{slen}, 超过限制{max_length}, 需进行截断\n原字符串={ss}, \n截断后字符串:{truncated_str}')return truncated_strBase = declarative_base()class MyModel(Base):__tablename__ = 'my_model'__col1 = ''id = Column(Integer, primary_key=True)col1 = Column(String(50))col2 = Column(String(500)) # 假设col2的最大长度是500个字符@validates('col1')def validate_col1(self, key, value):self.__col1 = valueself.col2 = self.validate_col1_and_col2(key='col2', value=self.col2)return value@validates('col2')def validate_col2(self, key, value):value = validate_col1_and_col2(key, value)return value def validate_col1_and_col2(self, key, value):# 检查col1的值是否为'xxx'if self.__col1== 'xxx':if not value:value = ''elif len(value) * 3 <= 500:# 存储到 oracle,中文占3个字符passelse:print('需检查 col2 长度')value = getStrLenAndTruncate(value)return value# 示例使用
datas = {'col1'= 'xxx', 'col2': 'a' * 501 }
model_instance = MyModel(**datas )try:# 假设这是保存模型到数据库的代码# session.add(model_instance)# session.commit()pass
except ValueError as e:print(e)
说明
为啥不省略下面这个 validate_col2 这个校验代码:
@validates('col2')def validate_col2(self, key, value):value = validate_col1_and_col2(key, value)return value
因为 这个方案中,col1 、col2进入 orm模型的顺序不一定,如果省略了validate_col2 ,当col1比col2先进入模型,那么在 validate_col1 调用 self.validate_col1_and_col2(key='col2', value=self.col2) 时,self.col2其实等于None,此时对col2校验是没有意义的。等到 col2 进入 orm模型,又缺少对它进行校验的函数。
注意:
不能在 某个字段的校验函数中对其进行赋值操作,不然会陷入递归循环,因为赋值操作会调用校验函数;
如下面的调用会陷入递归死循环,因为 self.col1 = value 这行代码对 self.col1 进行了赋值,会自动再次调用validate_col1校验函数,就会在这一行陷入递归死循环而报错。
class MyModel(Base):@validates('col1')def validate_col1(self, key, value):self.__col1 = valueself.col1 = valueself.col2 = self.validate_col1_and_col2(key='col2', value=self.col2)return value其他方案
不走orm模型,直接写校验代码和原生sql处理。
最后
这就是我尝试出来的 在 sqlalchemy.orm中validates对两个字段进行联合校验的方法,总感觉不太完美,不知道有没有大佬知道更好的方案,欢迎分享
相关文章:

sqlalchemy.orm中validates对两个字段进行联合校验
版本 sqlalchemy1.4.37 需求说明 有个场景,需要在orm中对两个字段进行联合校验,当 col1 xxx’时,对 col2的长度进行检查,超过限制(500)时,进行截断。 网上找了很久,没找到类似的…...
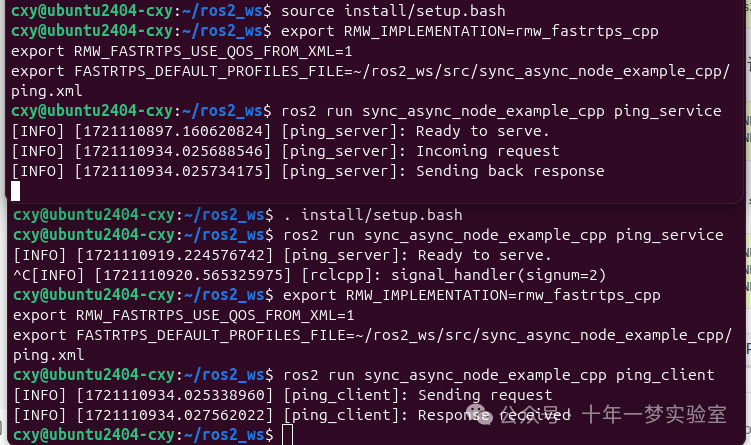
【ROS2】高级:解锁 Fast DDS 中间件的潜力 [社区贡献]
目标:本教程将展示如何在 ROS 2 中使用 Fast DDS 的扩展配置功能。 教程级别:高级 时间:20 分钟 目录 背景 先决条件在同一个节点中混合同步和异步发布 创建具有发布者的节点创建包含配置文件的 XML 文件执行发布者节点创建一个包含订阅者的节…...

VirtualBox虚拟机与主机互传文件的方法
建立共享文件夹 1.点击设置,点击共享文件夹,添加共享文件夹路径,保存 2.启动虚拟机,点击设备,点击安装增强功能,界面会出现一个光碟图标,点击光碟图标 3.打开光碟图标,出现一个目…...

访问控制系列
目录 一、基本概念 1.客体与主体 2.引用监控器与引用验证机制 3.安全策略与安全模型 4.安全内核 5.可信计算基 二、访问矩阵 三、访问控制策略 1.主体属性 2.客体属性 3.授权者组成 4.访问控制粒度 5.主体、客体状态 6.历史记录和上下文环境 7.数据内容 8.决策…...

【BUG】已解决:ModuleNotFoundError: No module named ‘cv2’
已解决:ModuleNotFoundError: No module named ‘cv2’ 欢迎来到英杰社区https://bbs.csdn.net/topics/617804998 欢迎来到我的主页,我是博主英杰,211科班出身,就职于医疗科技公司,热衷分享知识,武汉城市开…...

成都亚恒丰创教育科技有限公司 【插画猴子:笔尖下的灵动世界】
在浩瀚的艺术海洋中,每一种创作形式都是人类情感与想象力的独特表达。而插画,作为这一广阔领域中的璀璨明珠,以其独特的视觉语言和丰富的叙事能力,构建了一个又一个令人遐想连篇的梦幻空间。成都亚恒丰创教育科技有限公司 在众多插…...
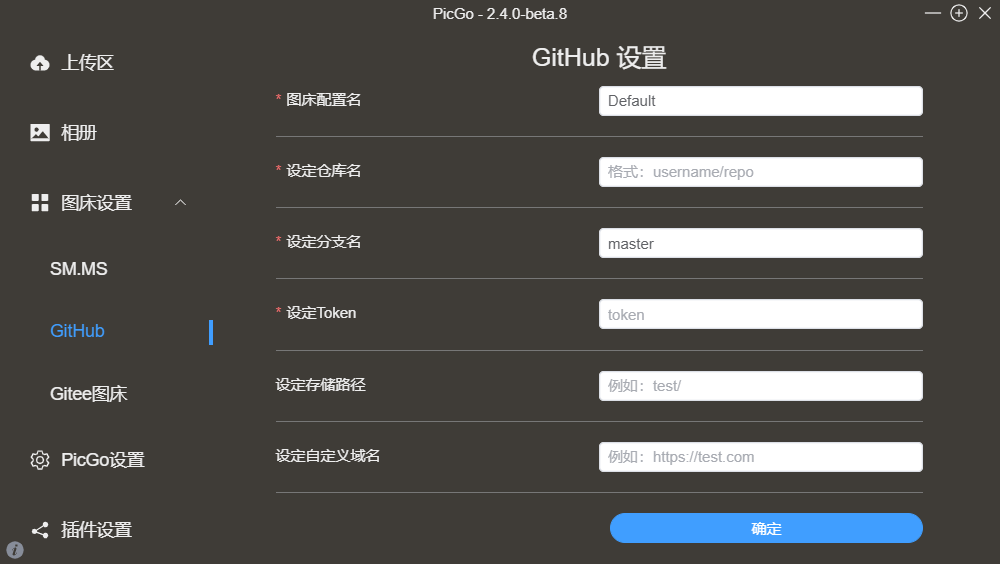
gite+picgo+typora打造个人免费笔记软件
文章目录 1️⃣个人笔记软件2️⃣ 配置教程2.1 使用软件2.2 node 环境配置2.3 软件安装2.4 gite仓库设置2.5 配置picgo2.6 测试检验2.7 github教程 🎡 完结撒花 1️⃣个人笔记软件 最近换了环境,没有之前的生产环境舒适,写笔记也没有劲头&…...

只用 CSS 能玩出什么花样?
在前端开发领域,CSS 不仅仅是一种样式语言,它更像是一位多才多艺的艺术家,能够创造出令人惊叹的视觉效果。本文将带你探索 CSS 的无限可能,从基本形状到动态动画,从几何艺术到仿生设计,只用 CSS 就能玩出令…...

Linux C++ 056-设计模式之迭代器模式
Linux C 056-设计模式之迭代器模式 本节关键字:Linux、C、设计模式、迭代器模式 相关库函数: 概念 迭代器模式(Iterator Pattern)是一种常用的设计模式。迭代器模式提供一种方法顺序访问一个聚合对象中的各个元素,而…...

【Elasticsearch7.11】reindex问题
参考博文链接 问题:reindex 时出现如下问题 原因:数据量大,kibana的问题 解决方法: 将DSL命令转化成CURL命令在服务上执行 CURL命令 自动转化 curl -XPOST "http://IP:PORT/_reindex" -H Content-Type: application…...

nginx代理缓存
在服务器架构中,反向代理服务器除了能够起到反向代理的作用之外,还可以缓存一些资源,加速客户端访问,nginx的ngx_http_proxy_module模块不仅包含了反向代理的功能还包含了缓存功能。 1、定义代理缓存规则 参数详解: p…...

[React 进阶系列] useSyncExternalStore hook
[React 进阶系列] useSyncExternalStore hook 前情提要,包括 yup 的实现在这里:yup 基础使用以及 jest 测试 简单的提一下,需要实现的功能是: yup schema 需要访问外部的 storage外部的 storage 是可变的React 内部也需要访问同…...

Linux C++ 055-设计模式之状态模式
Linux C 055-设计模式之状态模式 本节关键字:Linux、C、设计模式、状态模式 相关库函数: 概念 状态模式(State Pattern)是设计模式的一种,属于行为模式。允许一个对象在其内部状态改变时改变它的行为。对象看起来似…...

景联文科技构建高质量心理学系知识图谱,助力大模型成为心理学科专家
心理大模型正处于快速发展阶段,在临床应用、教育、研究等多个领域展现出巨大潜力。 心理学系知识图谱能够丰富心理大模型的认知能力,使其在处理心理学相关问题时更加精确、可靠和有洞察力。这对于提高心理健康服务的质量和效率、促进科学研究以及优化教育…...

【数学建模】——数学规划模型
目录 一、线性规划(Linear Programming) 1.1 线性规划的基本概念 1.2 线性规划的图解法 模型建立: 二、整数规划(Integer Programming) 2.1 整数规划的基本概念 2.2 整数规划的求解方法 三、非线性规划&#x…...

卸载linux 磁盘的内容,磁盘占满
Linux清理磁盘 https://www.cnblogs.com/siyunianhua/p/17981758 当前文件夹下,数量 ls -l | grep "^-" | wc -l ls -lR | grep "^-" | wc -l 找超过100M的大文件 find / -type f -size 100M -exec ls -lh {} \; df -Th /var/lib/docker 查找…...

LeetCode-随机链表的复制
. - 力扣(LeetCode) 本题思路: 首先注意到随机链表含有random的指针,这个random指针指向是随机的;先一个一个节点的拷贝,并且把拷贝的节点放在拷贝对象的后面,再让拷贝节点的next指向原链表拷贝…...

axios 下载大文件时,展示下载进度的组件封装——js技能提升
之前面试的时候,有遇到一个问题:就是下载大文件的时候,如何得知下载进度,当时的回复是没有处理过。。。 现在想到了。axios中本身就有一个下载进度的方法,可以直接拿来使用。 下面记录一下处理步骤: 参考…...

Linux: network: device事件注册机制 chatGPT; notify
ChatGPT 在 Linux 内核中,有关网络设备(net-device)的事件注册机制,允许用户在网络设备的状态发生变化(例如设备被删除、添加或修改)时接收通知。这主要通过 netdev 事件通知机制实现。具体来说,内核提供了一组用于注册和处理网络设备事件的 API。 以下是一些关键组件…...

【ROS2】测试
为什么要进行自动化测试? 以下是我们应该进行自动化测试的许多重要原因之一: 您可以更快地对代码进行增量更新。ROS 有数百个包,具有许多相互依赖关系,因此很难预见一个小变化可能引起的问题。如果您的更改通过了单元测试…...

终极散热解决方案:Dell G15开源热控中心完全指南
终极散热解决方案:Dell G15开源热控中心完全指南 【免费下载链接】tcc-g15 Thermal Control Center for Dell G15 - open source alternative to AWCC 项目地址: https://gitcode.com/gh_mirrors/tc/tcc-g15 还在为Dell G15游戏本的散热问题烦恼吗࿱…...

轻量级容器化部署工具Ship:简化中小团队应用部署流程
1. 项目概述:一个面向开发者的轻量级容器化部署工具最近在和朋友聊起中小团队或个人开发者的部署痛点时,大家普遍觉得,虽然Kubernetes(K8s)生态强大,但对于一个快速迭代的独立项目或小团队来说,…...

TS3380,TS3480,ts8220,ts6150,ts5380,G1810,G2000,G2010,G2800,G2810报错5B00,P07,E08,1700,5b04废墨垫清零,亲测有用。
下载:点这里下载 备用下载:https://pan.baidu.com/s/1WrPFvdV8sq-qI3_NgO2EvA?pwd0000 常见型号如下: G系列 G1000、G1100、G1200、G1400、G1500、G1800、G1900、G1010、G1110、G1120、G1410、G1420、G1411、G1510、G1520、G1810、G1820、…...

中国半导体设计产业:从制造到创新的演进逻辑与未来挑战
1. 从“制造”到“设计”:中国半导体产业的真实图景2012年,当《EE Times》那篇题为“Why China?”的文章发表时,它所描绘的中国半导体产业图景,在今天看来更像是一份精准的预言书。文章里提到,将中国仅仅视为技术产品…...

10x-bench-eval:量化开发效率的基准测试框架设计与实践
1. 项目概述:当“10倍速”遇上“基准测试”在软件工程领域,“10倍速工程师”是一个充满争议又令人神往的概念。它描述的是一种理想状态:一位工程师凭借其卓越的工具链、深刻的问题洞察力以及高效的自动化能力,其产出效率能达到普通…...

一键式自动化工具OneClickCopaw:从Shell脚本到CI/CD的部署实践
1. 项目概述与核心价值最近在折腾一些自动化脚本时,发现了一个挺有意思的项目,叫iwanglei1/OneClickCopaw。光看名字,你可能会有点懵,“Copaw”是什么?其实,这是一个典型的“一键式”自动化工具,…...

阿里:时序课程解决多轮蒸馏不稳定
📖标题:TCOD: Exploring Temporal Curriculum in On-Policy Distillation for Multi-turn Autonomous Agents 🌐来源:arXiv, 2604.24005v3 🛎️文章简介 🔸研究问题:如何在多轮自主智能体场景中…...

从HEX到芯片:使用J-Flash实现高效固件烧录与生产级加密
1. 认识J-Flash:你的芯片烧录好帮手 第一次接触J-Flash时,我正为一个量产项目发愁——需要给500片GD32F103烧录固件。手动用IDE一个个烧?效率太低;找代工厂?成本太高。直到同事推荐了J-Flash,我才发现原来烧…...

Exclusively Dark数据集:破解低光照视觉难题的7363张真实图像基准
Exclusively Dark数据集:破解低光照视觉难题的7363张真实图像基准 【免费下载链接】Exclusively-Dark-Image-Dataset Exclusively Dark (ExDARK) dataset which to the best of our knowledge, is the largest collection of low-light images taken in very low-li…...

自研引擎筑底 实景孪生领航——核心算法全栈自主可控,构筑数字孪生产业稳健技术护城河
自研引擎筑底 实景孪生领航——核心算法全栈自主可控,构筑数字孪生产业稳健技术护城河副标题:核心算法全栈自主可控,构筑数字孪生产业稳健技术护城河前言数字孪生与视频孪生作为数字经济核心支撑技术,正推动千行百业数字化转型进入…...