Flink History Server配置
目录
问题复现
History Server配置
HADOOP_CLASSPATH配置
History Server配置
问题修复
启动flink集群
启动Histroty Server
问题复现
在bigdata111上执行如下命令开启socket:
nc -lk 9999如图:

在bigdata111上执行如下命令运行flink应用程序
flink run -c com.leboop.SocketStreamingWordCount /root/jars/flink-1.0-SNAPSHOT.jar --host bigdata111 --port 9999运行成功后,登录http://bigdata111:8081/#/overview
打开flink web ui页面,如图:

此时点击Cancel Job取消任务,如图:
 可以在Completed Job List中看到刚刚被取消的任务,如图:
可以在Completed Job List中看到刚刚被取消的任务,如图:
 此时重启flink集群,如图:
此时重启flink集群,如图:

再次登录flink web ui,如图:

刚被取消的任务已经不显示。 重启集群后不显示历史任务。
History Server配置
集群现有的角色分布如下:
| IP地址 | 主机名称 | Flink角色 |
| 192.168.128.111 | bigdata111 | master |
| 192.168.128.112 | bigdata112 | worker |
| 192.168.128.113 | bigdata113 | worker |
可以选择任意一条服务器作为History Server节点,这里选择bigdata112作为History Server节点。
HADOOP_CLASSPATH配置
在三台服务器上配置HADOOP_CLASSPATH,配置步骤如下:
执行如下命令,打开配置文件:
vi /etc/profile在文件末尾添加如下配置内容:
# historyserver
export HADOOP_CLASSPATH=`hadoop classpath`
执行如下命令,生效配置文件:
source /etc/profile如图:

History Server配置
三台服务器上同时配置。执行如下命令,打开bigdata111服务器flink安装目录下的flink-conf.yaml配置文件
vi /opt/flink-1.9.3/conf/flink-conf.yaml默认配置如下:

改为如下配置:
#==============================================================================
# HistoryServer
#==============================================================================# The HistoryServer is started and stopped via bin/historyserver.sh (start|stop)# Directory to upload completed jobs to. Add this directory to the list of
# monitored directories of the HistoryServer as well (see below).
jobmanager.archive.fs.dir: hdfs:///flink-cluster/standalone/completed-jobs/# The address under which the web-based HistoryServer listens.
historyserver.web.address: bigdata112# The port under which the web-based HistoryServer listens.
historyserver.web.port: 8082# Comma separated list of directories to monitor for completed jobs.
historyserver.archive.fs.dir: hdfs:///flink-cluster/standalone/completed-jobs/# Interval in milliseconds for refreshing the monitored directories.
historyserver.archive.fs.refresh-interval: 10000
将配置好flink-conf.yaml复制到其它节点(bigdata112、bigdata113),命令如下:
scp -r flink-conf.yaml bigdata112:`pwd`
scp -r flink-conf.yaml bigdata113:`pwd`问题修复
启动flink集群
执行start-cluster.sh启动flink集群,如图:

启动成功后,JobManager和TaskManager进程如图:



启动Histroty Server
在bigdata112上,执行如下命令启动historyserver
historyserver.sh start启动成功后,如图:

登录如下地址,访问history server的web ui页面
http://bigdata112:8082/#/overview
如图:

暂时什么还没有。在bigdata111上打开socket,并运行flink应用程序,如图:


此时在hdfs上并未创建存储已完成Job数据的目录( hdfs:///flink-cluster/standalone/completed-jobs/),如图:

同样History Server web ui页面也不显示job信息。可以在JobManager web ui界面看到运行的任务,如图:
 现在取消任务,任务取消后,在HDFS上生成存储已完成Job的数据目录,如图:
现在取消任务,任务取消后,在HDFS上生成存储已完成Job的数据目录,如图:

同时在History Server web ui已完成Job列表中会显示该作业,如图:

现在重启flink集群和History Server,如图:


重启以后在History Server web ui页面会显示该Job(JobManager Server依然不显示)。
相关文章:
Flink History Server配置
目录 问题复现 History Server配置 HADOOP_CLASSPATH配置 History Server配置 问题修复 启动flink集群 启动Histroty Server 问题复现 在bigdata111上执行如下命令开启socket: nc -lk 9999 如图: 在bigdata111上执行如下命令运行flink应用程序 …...

ASPICE过程改进原则:确保汽车软件开发的卓越性能
"在汽车行业中,软件已经成为驱动创新和增强产品功能的核心要素。然而,随着软件复杂性的增加,确保软件质量、可靠性和性能成为了一项严峻的挑战。ASPICE标准的引入,为汽车软件开发提供了一套全面的过程改进框架,以…...

HDU1005——Number Sequence,HDU1006——Tick and Tick,HDU1007——Quoit Design
目录 HDU1005——Number Sequence 题目描述 超时代码 代码思路 正确代码 代码思路 HDU1006——Tick and Tick 题目描述 运行代码 代码思路 HDU1007——Quoit Design 题目描述 运行代码 代码思路 HDU1005——Number Sequence 题目描述 Problem - 1005 超时代码…...

uniapp form表单校验
公司的一个老项目,又要重新上架,uniapp一套代码,打包生成iOS端发布到App Store,安卓端发布到腾讯应用宝、OPPO、小米、华为、vivo,安卓各大应用市场上架要求不一样,可真麻烦啊 光一个表单校验,…...

构建RSS订阅机器人:观察者模式的实践与创新
在信息爆炸的时代,如何高效地获取和处理信息成为了一个重要的问题。RSS订阅机器人作为一种自动化工具,能够帮助我们从海量信息中筛选出我们感兴趣的内容。 一、RSS 是什么?观察者模式又是什么? RSS订阅机器人是一种能够自动订阅…...

芯片基础 | `wire`类型引发的学习
在Verilog中,wire类型是一种用于连接模块内部或模块之间的信号的数据类型。wire类型用于表示硬件中的物理连线,它可以传输任何类型的值(如0、1、高阻态z等),但它在任何给定的时间点上只能有一个确定的值。 wire类型通…...
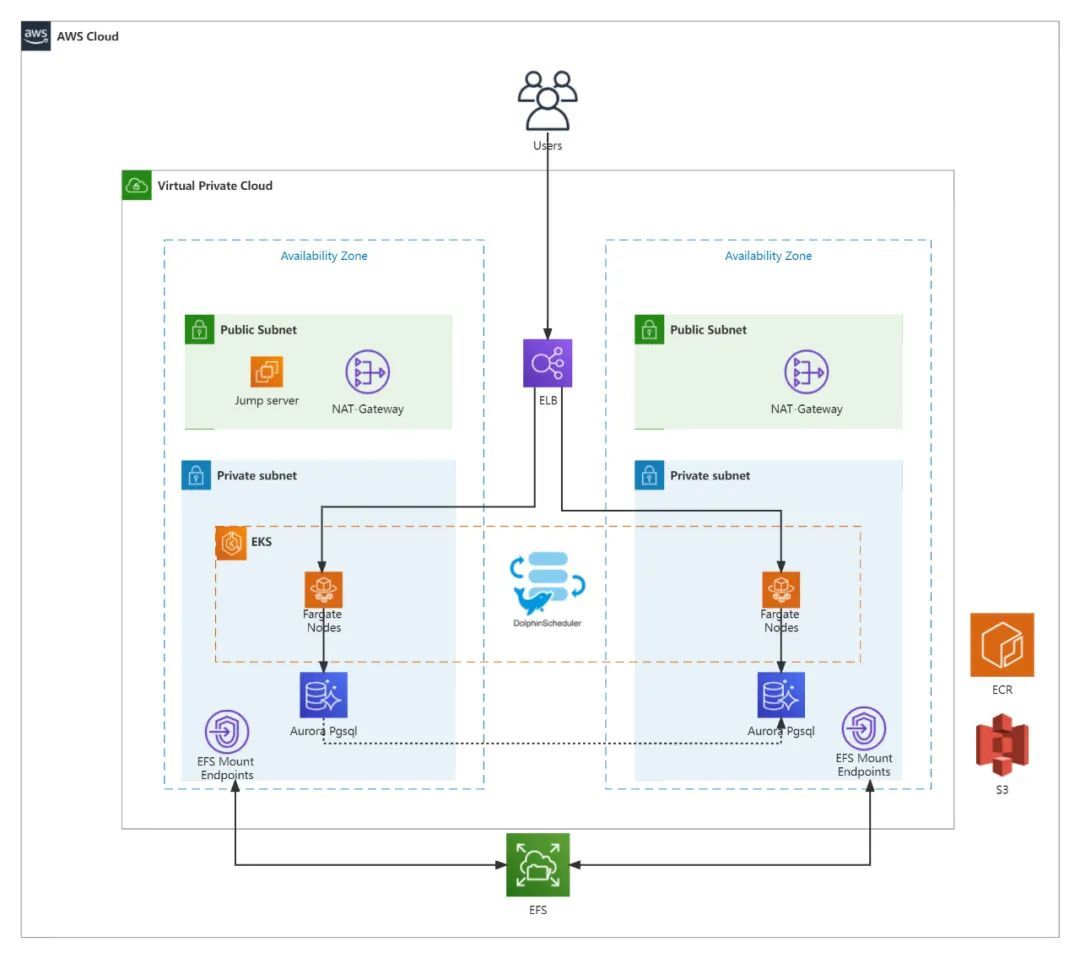
如何在AWS上构建Apache DolphinScheduler
引言 随着云计算技术的发展,Amazon Web Services (AWS) 作为一个开放的平台,一直在帮助开发者更好的在云上构建和使用开源软件,同时也与开源社区紧密合作,推动开源项目的发展。 本文主要探讨2024年值得关注的一些开源软件及其在…...

Quartus II 13.1添加新的FPGA器件库
最近需要用到Altera的一款MAX II 系列EPM240的FPGA芯片,所以需要给我的Quartus II 13.1添加新的器件库,在此记录一下过程。 1 下载所需的期间库 进入Inter官网,(Altera已经被Inter收购)https://www.intel.cn/content…...
)
【html】html的基础知识(面试重点)
一、如何理解HTML语义化 1、思考 A、在没有任何样式的前提下,将代码在浏览器打开,也能够结构清晰的展示出来。标题是标题、段落是段落、列表是列表。 B、便于搜索引擎优化。 2、参考答案 A、让人更容易读懂(增加代码可读性)。 B、…...

Java 网络编程(TCP编程 和 UDP编程)
1. Java 网络编程(TCP编程 和 UDP编程) 文章目录 1. Java 网络编程(TCP编程 和 UDP编程)2. 网络编程的概念3. IP 地址3.1 IP地址相关的:域名与DNS 4. 端口号(port)5. 通信协议5.1 通信协议相关的…...

STM32 | 看门狗+RTC源码解析
点击上方"蓝字"关注我们 作业 1、使用基本定时7,完成一个定时喂狗的程序 01、上节回顾 STM32 | 独立看门狗+RTC时间(第八天)02、定时器头文件 #ifndef __TIM_H#define __TIM_H#include "stm32f4xx.h"void Tim3_Init(void);void Tim7_Init(void);…...

filebeat,kafka,clickhouse,ClickVisual搭建轻量级日志平台
springboot集成链路追踪 springboot版本 <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.6.3</version><relativePath/> <!-- lookup parent from…...

Django实战项目之进销存数据分析报表——第一天:Anaconda 环境搭建
引言 Anaconda是一个流行的Python和R语言的发行版,它包含了大量预安装的数据科学、机器学习库和科学计算工具。使用Anaconda可以轻松地创建隔离的环境,每个环境都可以有自己的一套库和Python版本,非常适合多项目开发。本文将指导你如何安装A…...

Linux部署Prometheus+Grafana
【Linux】PrometheusGrafana 一、Prometheus(普罗米修斯)1、Prometheus简述2、Prometheus特点3、Prometheus生态组件4、Prometheus工作原理 二、部署Prometheus1、系统架构2、部署Prometheus3、修改配置文件4、配置系统启动文件 三、部署 Node Exporter …...

【视频讲解】神经网络、Lasso回归、线性回归、随机森林、ARIMA股票价格时间序列预测|附代码数据
全文链接:https://tecdat.cn/?p37019 分析师:Haopeng Li 随着我国股票市场规模的不断扩大、制度的不断完善,它在金融市场中也成为了越来越不可或缺的一部分。 【视频讲解】神经网络、Lasso回归、线性回归、随机森林、ARIMA股票价格时间序列…...

低代码前端框架Amis全面教程
什么是Amis? 1.1 Amis的基本概念 Amis是一个基于JSON配置的前端低代码框架,由百度开源。它允许开发者通过简单的JSON配置文件来生成复杂的后台管理页面,从而大大减少了前端开发的工作量。Amis的核心理念是通过配置而非编码来实现页面的构建…...

Windows 如何安装和卸载 OneDrive?具体方法总结
卸载 OneDrive 有人想问 OneDrive 可以卸载吗?如果你不使用当然可以卸载,下面是安装和卸载 OneDrive 中的卸载应用具体操作步骤: 卸载 OneDrive 我们可以从设置面板中的应用选项进行卸载,打开设置面板之后选择应用,然…...

c# .net core中间件,生命周期
某些模块和处理程序具有存储在 Web.config 中的配置选项。但是在 ASP.NET Core 中,使用新配置模型取代了 Web.config。 HTTP 模块和处理程序如何工作 官网地址: 将 HTTP 处理程序和模块迁移到 ASP.NET Core 中间件 | Microsoft Learn 处理程序是…...
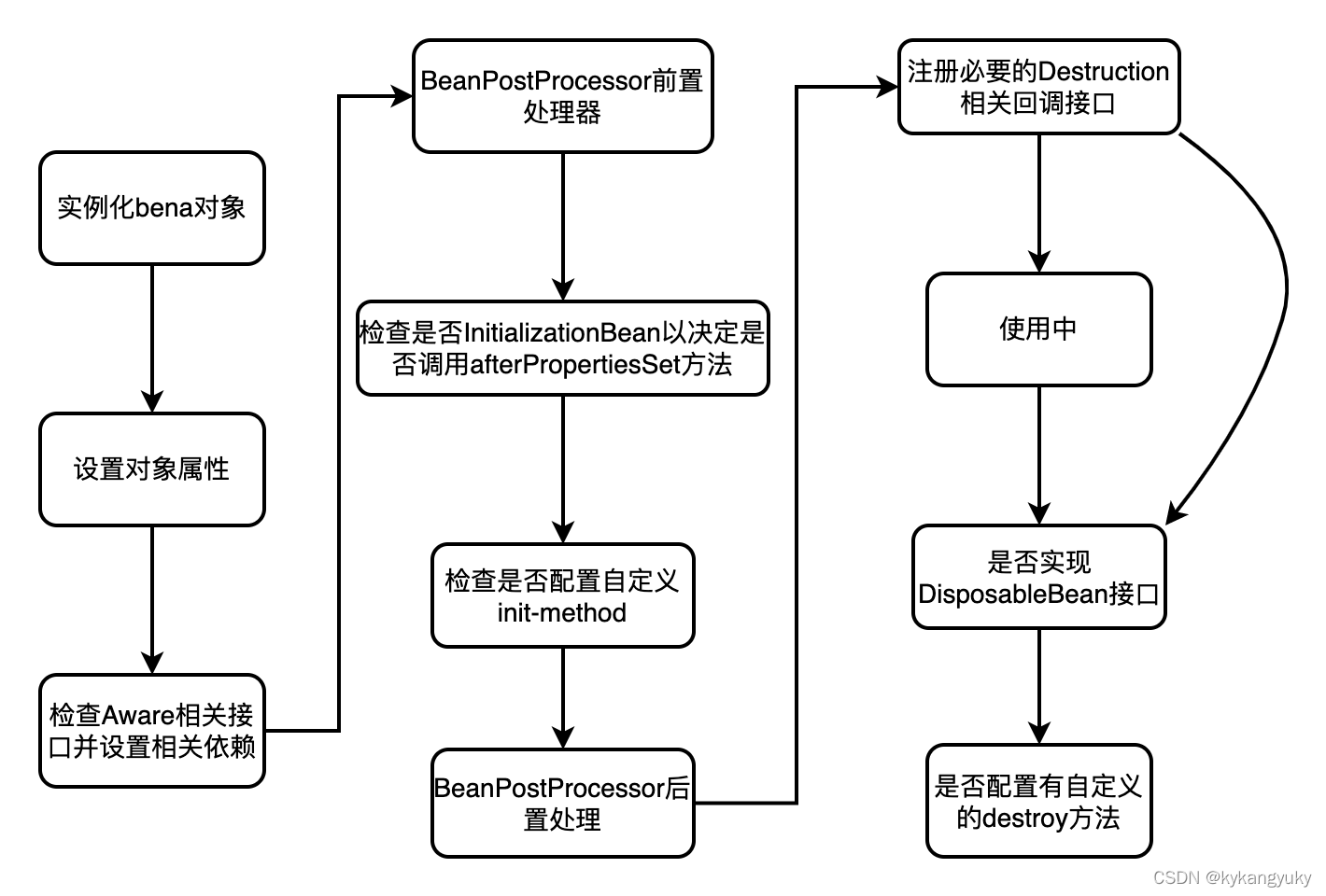
Spring后端框架复习总结
之前写的博客太杂,最近想把后端框架的知识点再系统的过一遍,主要是Spring Boot和Mybatis相关,带着自己的理解使用简短的话把一些问题总结一下,尤其是开发中和面试中的高频问题,基础知识点可以参考之前写java后端专栏,这篇不再赘述。 目录 Spring什么是AOP?底层原理?事务…...

基于Llama Index构建RAG应用
前言 Hello,大家好,我是GISer Liu😁,一名热爱AI技术的GIS开发者,本文参与活动是2024 DataWhale AI夏令营;😲 在本文中作者将通过: Gradio、Streamlit和LlamaIndex介绍 LlamaIndex 构…...

2026 年 Docker 镜像加速终极方案:告别拉取卡顿,一键提速
大家好!相信很多开发者都遇到过这样的问题:在配置 Docker 环境时,docker pull 命令经常卡住不动,进度条仿佛静止了一般,严重影响开发效率。为了解决这个痛点,我深入研究并测试了多种方案,最终整…...

深度解析开源AI工具库:OpenAI API封装库的设计与实战应用
1. 项目概述:一个开源AI工具库的深度解构最近在GitHub上看到一个名为“anasfik/openai”的项目,这个标题乍一看有点意思。它不像官方SDK那样直接叫“openai”,而是带上了个人或组织的命名空间前缀“anasfik/”。这通常意味着这是一个第三方封…...

TAMEn系统:触觉视觉数据采集的模块化解决方案
1. TAMEn系统概述:触觉视觉数据采集的革命性方案在机器人操作领域,接触丰富的任务(如柔性物体处理、精密装配)一直面临着数据采集的挑战。传统视觉系统难以捕捉细微的接触信号(如初始滑动、局部变形)&#…...

终点亦是起点
小端AI经过8个月的反复打磨,不仅领先外国顶级水平,而且功能稳定,我也永久保持纯本地运行100%开源,如今已超过30万下载,不管未来百万还是千万用户,绝不开会员,献给国家的申明永久有效,…...

从仿真到PCB:基于74LS系列芯片的十字路口交通灯系统实战设计
1. 项目背景与设计目标 十字路口交通灯控制系统是数字电路课程的经典实践项目。记得我第一次接触这个课题时,既兴奋又忐忑——兴奋的是终于能把课本上的与非门、触发器应用到真实场景,忐忑的是从仿真到实物可能存在的各种"坑"。这个基于74LS系…...

LLM推理中的动态显存卸载技术解析
1. LLM推理中的内存挑战与卸载技术本质在部署百亿参数级别的大型语言模型(LLM)时,GPU显存容量往往成为关键瓶颈。以主流的NVIDIA A100 40GB显卡为例,单卡甚至无法完整加载一个13B参数的模型(按FP16精度计算需要约26GB显存,尚未考虑…...

20 - 告别“无限上下文”的幻觉:大模型知识注入的“四层矩阵”与下一场权重战争
本专题系列文章共 21 篇,前 5 篇限时免费阅读 01 - 眩晕时代的定海神针:大模型落地的“第一性原理”与算力丰裕悖论 02 - 95%的AI投资打了水漂:五大错配如何扼杀你的“第二增长曲线” 03 - 从电力到AI:标准化已死,个性化永生——大模型时代的三大商业终局 04 - 你的护城…...

清华研究发现:当世界模型能够通过视觉想象而非纯文本思考时,其推理方式更接近人类!
模型能解高数题、写复杂代码,但遇到“把这张纸对折三次再剪个洞,展开后有几个窟窿”就频频卡壳。纯语言推理在符号和抽象规则上进步很快,但在物理常识、空间拓扑这些需要具象表征的任务上,依然存在明显的系统性短板。社区一直对“…...
)
别再硬改CSS了!ElementUI el-table透明背景的3种正确姿势(含Vue2/Vue3避坑指南)
别再硬改CSS了!ElementUI el-table透明背景的3种正确姿势(含Vue2/Vue3避坑指南) 在深色主题或背景融合的现代Web应用中,ElementUI的el-table组件默认的白色背景常常成为视觉设计的绊脚石。许多开发者第一反应是直接修改CSS文件&am…...

SubLens:AI订阅管理浏览器插件,一站式聚合账单与扣款提醒
1. 项目概述:一个帮你管好AI订阅账单的浏览器插件 如果你和我一样,订阅了不止一个AI服务——比如ChatGPT Plus用来日常对话和写作,Claude Pro用来处理长文档,GitHub Copilot写代码,Cursor辅助开发,再加上G…...