Pytorch基础应用
1.数据加载
1.1 读取文本文件
- 方法一:使用 open() 函数和 read() 方法
# 打开文件并读取全部内容
file_path = 'example.txt' # 替换为你的文件路径
with open(file_path, 'r') as file:content = file.read()print(content)
- 方法二:逐行读取文件内容
# 逐行读取文件内容
file_path = 'example.txt' # 替换为你的文件路径
with open(file_path, 'r') as file:for line in file:print(line.strip()) # strip() 方法用于去除行末尾的换行符
- 方法三:指定编码读取文件内容(如果文本文件不是UTF-8编码)
# 指定编码读取文件内容
file_path = 'example.txt' # 替换为你的文件路径
with open(file_path, 'r', encoding='utf-8') as file:content = file.read()print(content)
- 方法四:一次读取多行内容
# 一次读取多行内容
file_path = 'example.txt' # 替换为你的文件路径
with open(file_path, 'r') as file:lines = file.readlines()for line in lines:print(line.strip()) # strip() 方法用于去除行末尾的换行符
1.2 读取图片
- 使用Pillow(PIL)库
安装了Pillow库:pip install Pillow
from PIL import Image# 打开图片文件
img = Image.open('example.jpg') # 替换成你的图片文件路径# 显示图片信息
print("图片格式:", img.format)
print("图片大小:", img.size)
print("图片模式:", img.mode)# 显示图片
img.show()# 转换为numpy数组(如果需要在其他库中处理图像)
import numpy as np
img_array = np.array(img)
- 使用OpenCV库
安装OpenCV库:pip install opencv-python
import cv2# 读取图片
img = cv2.imread('example.jpg') # 替换成你的图片文件路径# 显示图片信息
print("图片尺寸:", img.shape) # 高度、宽度、通道数(rgb默认是3)
print("像素值范围:", img.dtype) # 数据类型(像素值类型)# 可选:显示图片(OpenCV中显示图像的方法)
cv2.imshow('image', img)
cv2.waitKey(0)
cv2.destroyAllWindows()# 可选:将BGR格式转换为RGB格式
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)# 可选:保存图片
cv2.imwrite('output.jpg', img)
- 应用
# 继承Dataset类
class MyData(Dataset):# 初始化def __init__(self, root_dir, image_dir, label_dir):# root_dir 训练目录地址self.root_dir = root_dir# 图片地址self.image_dir = image_dir# label_dir 标签地址self.label_dir = label_dir# 训练样本地址self.path = os.path.join(self.root_dir, self.image_dir)# 将所有样本地址(名称)变成一个列表self.img_path = os.listdir(self.path)# 读取图片,并且对应label# idx 图片下标def __getitem__(self, idx):# 图片名称img_name = self.img_path[idx]# 图片路径img_item_path = os.path.join(self.path, img_name)# 获取图片img = Image.open(img_item_path)# 打开文件并读取全部内容(文件存取对应样本的标签)file_path = os.path.join(self.root_dir, self.label_dir, img_name.split('.jpg')[0])with open(file_path + ".txt", 'r') as file:label = file.read()# 获取标签return img, label# 训练样本长度def __len__(self):return len(self.img_path)root_dir = "hymenoptera_data/train"
ants_image_dir = "ants_image"
ants_label_dir = "ants_label"
bees_image_dir = "bees_image"
bees_label_dir = "bees_label"
ants_dataset = MyData(root_dir, ants_image_dir, ants_label_dir)
img, label = ants_dataset[0] # 返回数据集第一个样本的图片和标签
img.show() # 展示图片
bees_dataset = MyData(root_dir, bees_image_dir, bees_label_dir)
import cv2
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Imageimg_path = "dataset/train/ants_image/0013035.jpg"
# 打开图片
img = Image.open(img_path)# 利用cv2打开图片,直接是ndarray格式
img_cv2 = cv2.imread(img_path)print(img_cv2)write = SummaryWriter('logs')# 创建一个ToTensor的对象(PIL Image or ndarray to tensor)
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
print(tensor_img)
1.3 数据可视化(TensorBoard)
SummaryWriter 是 TensorBoard 的日志编写器,用于创建可视化和跟踪模型训练过程中的指标和结果。它通常用于记录模型的训练损失、准确率、权重分布、梯度分布等信息,方便后续在 TensorBoard 中进行可视化分析。
import torch
from torch.utils.tensorboard import SummaryWriter# 创建一个 SummaryWriter 对象,指定保存日志的路径
writer = SummaryWriter('logs')# 示例:记录模型的训练过程中的损失值和准确率
for step in range(100):# 模拟训练过程中的损失值和准确率loss = 0.4 * (100 - step) + torch.rand(1).item()accuracy = 0.6 * (step / 100) + torch.rand(1).item()# 将损失值和准确率写入日志writer.add_scalar('Loss/train', loss, step)writer.add_scalar('Accuracy/train', accuracy, step)# 关闭 SummaryWriter
writer.close()
首先,我们导入了需要的库,包括 PyTorch 和 SummaryWriter。
然后,创建了一个 SummaryWriter 对象,并指定了保存日志的路径 ‘logs’。
在模拟的训练过程中,我们循环了 100 步,每一步模拟生成一个损失值和准确率。
使用 writer.add_scalar 方法将每一步的损失值和准确率写入日志。这些信息将被保存在指定的日志路径中,以便后续在 TensorBoard 中进行查看和分析。
最后,使用 writer.close() 关闭 SummaryWriter,确保日志写入完成并正确保存。
- SummaryWriter 对象的 add_scalar 方法用于向 TensorBoard 日志中添加标量数据,例如损失值、准确率等。这些标量数据通常用于跟踪模型训练过程中的指标变化。
add_scalar 方法的参数说明:
add_scalar(tag, scalar_value, global_step=None, walltime=None)
tag (str):用于标识数据的名称,将作为 TensorBoard 中的图表的名称显示。
scalar_value (float):要记录的标量数据,通常是一个数值。
global_step (int, optional):可选参数,表示记录数据的全局步骤数。主要用于绘制图表时在 x 轴上显示步骤数,方便对训练过程进行时间序列分析。
walltime (float, optional):可选参数,表示记录数据的时间戳。默认情况下,使用当前时间戳。
- add_image 函数用于向 TensorBoard 日志中添加图像数据,这对于监视模型输入、输出或中间层的可视化非常有用。
add_image 方法的参数说明:
add_image(tag, img_tensor, global_step=None, walltime=None, dataformats='CHW')
tag (str):用于标识图像的名称,将作为 TensorBoard 中图像的名称显示。
img_tensor (Tensor or numpy.array):要记录的图像数据,可以是 PyTorch 的 Tensor 对象或者 numpy 数组。如果是 numpy 数组,会自动转换为 Tensor。
global_step (int, optional):可选参数,表示记录数据的全局步骤数。主要用于在 TensorBoard 中按时间显示图像。
walltime (float, optional):可选参数,表示记录数据的时间戳。默认情况下,使用当前时间戳。
dataformats (str, optional):可选参数,指定图像的数据格式。默认为 ‘CHW’,即通道-高度-宽度的顺序。
启动命令:tensorboard --logdir 文件路径
1.4 Transforms
transforms.py 文件通常是指用于进行数据预处理和数据增强的模块。这个模块通常用于处理图像数据,包括但不限于加载、转换、裁剪、标准化等操作,以便将数据准备好用于模型的训练或评估。
常见的 transforms.py 功能包括:
- 数据加载和预处理:
读取图像数据并转换为 PyTorch 的 Tensor 格式。
对图像进行大小调整、裁剪、旋转、镜像翻转等操作。
将图像数据标准化为特定的均值和标准差。 - 数据增强:
随机裁剪和大小调整,以增加训练数据的多样性。
随机水平或垂直翻转图像。
添加噪声或扭曲以增加数据的多样性。 - 转换为 Tensor:
将 PIL 图像或 numpy 数组转换为 PyTorch 的 Tensor 格式。
对图像数据进行归一化,例如将像素值缩放到 [0, 1] 或 [-1, 1] 之间。 - 组合多个转换操作:
将多个转换操作组合成一个流水线,可以顺序应用到图像数据上。 - 实时数据增强:
在每次训练迭代中实时生成增强后的数据,而不是预先对所有数据进行转换。
import torch
from torchvision import transforms
from PIL import Image# 示例图像路径
img_path = 'example.jpg'# 定义数据转换
data_transform = transforms.Compose([transforms.Resize((256, 256)), # 调整图像大小为 256x256 像素transforms.RandomCrop(224), # 随机裁剪为 224x224 像素transforms.RandomHorizontalFlip(), # 随机水平翻转图像transforms.ToTensor(), # 将图像转换为 Tensor,并归一化至 [0, 1]transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化
])# 加载并预处理图像
img = Image.open(img_path)
img_transformed = data_transform(img)# 打印转换后的图像形状和数据类型
print("Transformed image shape:", img_transformed.shape)
print("Transformed image data type:", img_transformed.dtype)
1.首先,导入了必要的库和模块,包括 PyTorch 的 transforms 模块、PIL 库中的 Image。
定义了一个 transforms.Compose 对象 data_transform,它是一个包含多个转换操作的列表,按顺序应用到输入数据上。
2.示例中的转换操作包括将图像调整为指定大小、随机裁剪为 224x224 像素、随机水平翻转、转换为 PyTorch 的 Tensor 对象,并进行归一化。
3.加载示例图像,并将 data_transform 应用到图像上,得到转换后的图像数据 img_transformed。
4.最后,打印转换后的图像形状和数据类型,以确保转换操作正确应用。
transforms.Normalize(mean, std, inplace=False)Normalize 类用于对图像数据进行标准化操作。标准化是一种常见的数据预处理步骤,通常用于将数据缩放到一个较小的范围,以便于模型训练的稳定性和收敛速度。在图像处理中,Normalize 类主要用于将图像的每个通道进行均值和标准差的归一化处理
- mean:用于归一化的均值。可以是一个列表或元组,每个元素分别对应于图像的每个通道的均值。例如 [mean_channel1, mean_channel2, mean_channel3]。
- std:用于归一化的标准差。同样是一个列表或元组,每个元素对应于图像的每个通道的标准差。例如 [std_channel1, std_channel2, std_channel3]。
- inplace:是否原地操作。默认为 False,表示会返回一个新的标准化后的图像。如果设置为 True,则会直接修改输入的 Tensor。
Compose类
transforms.Compose(transforms)
transforms:一个由 torchvision.transforms 中的转换操作组成的列表或序列,每个操作会依次应用到输入数据上。
1.5 torchvision.datasets
PyTorch 中用于加载和处理常见视觉数据集的模块。这个模块提供了对多种经典数据集的访问接口,包括图像分类、物体检测、语义分割等任务常用的数据集。
- 数据集加载:
torchvision.datasets 提供了方便的接口,可以直接从互联网下载和加载常用的数据集,例如 MNIST、CIFAR-10、ImageNet 等。 - 数据预处理:
支持在加载数据集时进行数据预处理,例如图像大小调整、裁剪、翻转、归一化等操作,这些操作可以通过 transforms 模块进行定义和组合。 - 数据集管理:
提供了便捷的方法来管理和访问数据集,例如对数据集进行随机访问、按照批次加载数据等,以支持机器学习模型的训练和评估。 - 多样的数据集支持:
支持多种类型的数据集,包括但不限于分类数据集(如 MNIST、CIFAR-10)、检测数据集(如 COCO)、语义分割数据集(如 Pascal VOC)等,适用于不同的视觉任务。
# 以CIFAR-10为例
import torchvision.transforms as transforms
import torchvision.datasets as datasets# 定义数据预处理
transform = transforms.Compose([transforms.Resize(224),transforms.ToTensor(),transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
])# 加载数据集
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)# 获取数据集中的样本数量
print("Training dataset size:", len(train_dataset))
print("Test dataset size:", len(test_dataset))# 使用 DataLoader 加载数据
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False)
使用 datasets.CIFAR10 加载 CIFAR-10 数据集
指定了数据集存储的根目录 root、是否为训练集 train=True、是否下载数据集 download=True、以及预处理管道 transform。
datasets.CIFAR10 返回一个 torch.utils.data.Dataset 对象,可以像常规 Python 的列表一样进行索引和切片操作。
1.6 DataLoader
DataLoader 是 PyTorch 中用于批量加载数据的重要工具
- 数据加载:
DataLoader 可以加载 Dataset 对象中的数据,并将其组织成小批量。这些数据可以是图像、文本、数值数据等。 - 批量处理:
DataLoader 支持对数据进行批处理,即一次性加载和处理多个样本。这样可以提高训练效率,尤其是在 GPU 计算的情况下。 - 数据打乱:
通过设置 shuffle=True 参数,DataLoader 可以在每个 epoch 开始时对数据进行打乱,这有助于增加数据的随机性,防止模型陷入局部极值。 - 多进程加载:
DataLoader 支持使用多个子进程来并行加载数据,这可以显著提升数据加载速度,特别是在数据集很大时。 - 数据采样:
可以使用 sampler 参数来指定数据的采样方法,例如随机采样、顺序采样等。默认情况下,使用的是 SequentialSampler,即顺序采样。 - 数据批处理方式:
可以设置 batch_size 参数指定每个小批量的样本数目。 - 自定义数据加载:
可以通过设置 collate_fn 参数来指定如何将样本数据拼接成小批量,通常情况下,PyTorch 提供了默认的拼接方式,但是有时候用户可能需要根据自己的需求来自定义拼接过程。 - 数据传输到 GPU:
当数据加载到 DataLoader 后,可以方便地将其传输到 GPU 上进行计算,这样可以利用 GPU 的并行计算能力加速模型训练。
dataset:
这是必需的参数,指定要加载的数据集 Dataset 对象。
batch_size:
指定每个小批量包含的样本数目。例如,batch_size=64 表示每个小批量包含 64 个样本。训练时常用的批量大小通常是 2 的幂次方,以便能够充分利用 GPU 的并行计算能力。
shuffle:
设置为 True 表示每个 epoch 开始时都会对数据进行重新打乱(随机采样)。这样可以增加数据的随机性,有助于模型更好地学习数据的分布,避免模型陷入局部极值。
sampler:
可选参数,用于指定数据采样策略。默认情况下,如果不指定这个参数,将使用 SequentialSampler,即顺序采样。也可以自定义 Sampler 对象,实现自定义的采样逻辑。
batch_sampler:
可选参数,如果指定了这个参数,则会覆盖 batch_size 和 shuffle 参数。它
num_workers:
表示用于数据加载的子进程数目。可以通过增加子进程数来加速数据加载,特别是当主机有多个 CPU 核心时。通常建议设置为 num_workers > 0
collate_fn:
可选参数,用于指定如何将样本列表拼接成小批量。默认情况下,PyTorch 使用 default_collate 函数来执行标准的张量拼接操作。
pin_memory:
如果设置为 True,则会将加载的数据存储在 CUDA 固定内存中,这样可以加速数据传输到 GPU。在使用 GPU 训练模型时,建议设置为 True。
drop_last:
如果数据集的样本总数不能被 batch_size 整除,设置为 True 将会丢弃最后一个不完整的批次。如果设置为 False,则最后一个批次的样本数目可能会少于 batch_size。
import torch
from torch.utils.data import Dataset, DataLoader# 定义一个简单的数据集类
class MyDataset(Dataset):def __init__(self):self.data = torch.randn(100, 3, 32, 32) # 假设有 100 个大小为 3x32x32 的张量数据def __len__(self):return len(self.data)def __getitem__(self, idx):return self.data[idx]# 创建数据集实例
dataset = MyDataset()# 创建 DataLoader 实例
batch_size = 16
train_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)# 迭代数据集
for batch_idx, batch_data in enumerate(train_loader):inputs = batch_data # 输入数据targets = batch_data # 如果有标签,也可以在此处获取# 在这里添加训练代码...
在上述示例中,首先定义了一个简单的数据集类 MyDataset,它生成了包含 100 个大小为 3x32x32 的张量数据。然后,通过 DataLoader 将这个数据集加载为 train_loader,并设置了批量大小为 16,并且打乱了数据顺序。最后,在迭代 train_loader 中的小批量数据时,可以获取到每个小批量的输入数据 inputs,并在训练过程中使用。
2.构建模型
神经网络输入和输出参数数据格式:
输入输出的张量,通常是一个四维张量,形状为 (N, C, H, W),其中:
N 表示批处理大小(batch size),
C 表示输入输出通道数(input channels),
H 表示输入输出的高度(input height),
W 表示输入输出的宽度(input width)。
2.1 nn.Module
PyTorch 中的一个核心类,用于构建神经网络模型。
-
模型组件封装:
nn.Module 是所有神经网络模型的基类,可以通过继承它来定义自己的神经网络模型。
它提供了模型组件的封装和管理机制,使得模型的构建和维护更加清晰和结构化。 -
参数管理:
模型内部的所有参数(权重和偏置)都由 nn.Module 对象管理。
通过模型的 parameters() 方法可以轻松地访问和管理所有模型参数,便于参数初始化、优化器更新等操作。 -
前向传播定义:
模型的前向传播逻辑都在 forward() 方法中定义。
重写 forward() 方法可以定义模型的计算图,指定输入数据如何通过各个层进行前向传播,从而计算出输出。 -
反向传播支持:
nn.Module 支持自动求导功能,因此可以利用 PyTorch 提供的自动求导机制进行反向传播和梯度计算。
这使得模型的训练过程可以高效地优化模型参数。 -
子模块管理:
nn.Module 支持将多个子模块组合成一个大模型。
通过在 init 方法中初始化其他 nn.Module 的子类对象,可以构建复杂的神经网络结构,实现模块化设计。 -
状态管理:
nn.Module 不仅管理模型参数,还负责管理模型的状态(如 train() 和 eval() 方法控制模型的训练和评估状态)。
这些状态管理方法在模型训练、验证和测试时非常有用。 -
设备适配:
通过 to() 方法,nn.Module 支持简单地将模型移动到 GPU 或者其他计算设备上进行加速计算,提高训练和推理的效率。
class MyModule(nn.Module):def __init__(self):super().__init__()def forward(self, input):output = input + 1return outputmymodule = MyModule()
x = torch.tensor(1.0)
y = mymodule(x)
print(y)
2.2 nn.Conv2d
PyTorch 中用于定义二维卷积层的类。它是 nn.Module 的子类,用于构建卷积神经网络中的卷积操作。
卷积原理



参数介绍:
nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1)in_channels:
表示输入的通道数,对于灰度图像,通道数为 1;对于彩色图像,通道数为 3(分别是红、绿、蓝)。
out_channels:(每个卷积核生成一个特征图作为输出)
表示输出的通道数,也就是卷积核的数量,每个卷积核生成一个特征图作为输出。通常情况下,输出通道数决定了下一层的输入通道数。
kernel_size:
卷积核的大小,可以是一个整数或者一个元组(如 (3, 3))。整数表示正方形卷积核的边长,元组则表示非正方形卷积核的形状。
stride:
卷积操作的步幅,即卷积核在输入上滑动的步长。可以是一个整数或者一个元组。默认为 1,表示卷积核每次滑动一个像素;
可以设定为大于 1 的整数,以减少输出特征图的尺寸。
padding:
输入的每一条边补充 0 的层数。可以是一个整数或一个元组。添加 padding 可以帮助保持特征图大小,避免在卷积过程中信息损失过多。
dilation:
空洞卷积的扩展因子,控制卷积核元素之间的间距。默认为 1,表示卷积核内的每个元素之间都是连续的;
大于 1 的值将导致空洞卷积,可以增加感受野。
groups:
输入和输出之间连接的组数。默认为 1,表示所有输入通道和输出通道之间都有连接;可以设置为其他值,以实现分组卷积操作。
bias:
是否添加偏置。默认为 True,表示在卷积后加上偏置项;如果设置为 False,则卷积层不会有额外的偏置。
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterclass MyConv2d(nn.Module):def __init__(self):super(MyConv2d, self).__init__()# 定义卷积层self.conv1 = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)def forward(self, x):outputs = self.conv1(x)return outputstest_data = torchvision.datasets.CIFAR10(root='./dataset', train=False, transform=torchvision.transforms.ToTensor(),download=True)
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
write = SummaryWriter(log_dir='./logs')my_conv = MyConv2d()step = 1
# 遍历数据
for data in test_loader:# 每个批次的图片及便签imgs, targets = dataoutputs = my_conv(imgs)print(imgs.shape) # torch.Size([64, 3, 32, 32]) 批量64 输入通道3(RGB彩色) 图片大小32*32print(outputs.shape) # torch.Size([64, 6, 30, 30]) 批量64 输出通道6 图片大小30*30# 根据输入的卷积参数计算卷积后图片大小的方法见官网# https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html#torch.nn.Conv2dwrite.add_images("imgs", imgs, step)# 由于outputs.shape = [64, 6, 30, 30] 输出通道6 RGB为3 无法构建图像,利用reshape变化格式outputs = torch.reshape(outputs, (-1, 3, 30, 30)) # 不确定的维度用-1自动填充write.add_images("outputs", outputs, step)step += 1
write.close()

2.3 MaxPool2d
PyTorch 中用于执行二维最大池化(Max Pooling)操作的类。它通常用于卷积神经网络(CNN)中,用于减少特征图的空间维度,从而减少模型的参数数量,降低过拟合风险,并提高计算效率。
最大池化层原理

MaxPool2d 的主要参数
kernel_size (int 或 tuple):
池化窗口的大小。可以是一个整数,例如 kernel_size=2,表示窗口的高度和宽度都是 2;也可以是一个长度为 2 的元组 (kernel_height, kernel_width),例如 kernel_size=(2, 2)。
stride (int 或 tuple, optional):
池化操作的步幅。可以是一个整数,例如 stride=2,表示在高度和宽度方向上的步幅都是 2;也可以是一个长度为 2 的元组 (stride_height, stride_width),例如 stride=(2, 2)。默认值是 kernel_size。
padding (int 或 tuple, optional):
输入的每条边补充0的层数。可以是一个整数,例如 padding=1,也可以是一个长度为 2 的元组 (padding_height, padding_width),例如 padding=(1, 1)。默认值是 0,即不填充。
dilation (int 或 tuple, optional):
池化核元素之间的间距。可以是一个整数,例如 dilation=1,也可以是一个长度为 2 的元组 (dilation_height, dilation_width),例如 dilation=(2, 2)。默认值是 1,即没有间距。
return_indices (bool, optional):
如果设置为 True,则返回输出中每个最大值的索引。默认为 False。
ceil_mode (bool, optional):
如果设置为 True,则使用 ceil 而不是 floor 计算输出形状。默认为 False。
import torch
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10(root='./dataset', train=False,transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=64)class MyPool(torch.nn.Module):def __init__(self):super(MyPool, self).__init__()self.pool = torch.nn.MaxPool2d(kernel_size=3,ceil_mode=True)def forward(self, x):return self.pool(x)my_pool = MyPool()
write = SummaryWriter(log_dir='./logs')
step = 1
for data in dataloader:imgs, labels = datawrite.add_images("imgs",imgs,step)outputs = my_pool(imgs)write.add_images("MaxPool2d",outputs,step)step += 1
write.close()

2.4 ReLU
ReLU(Rectified Linear Unit)是深度学习中常用的一种激活函数,用于增加神经网络的非线性特性。ReLU 的输出对于负值是零,这意味着在训练过程中,神经元可以学习更加稀疏的表示,从而减少了过拟合的可能性。

import torch
from torch import nninput = torch.tensor([[1, -0.5],[-5, 8]])
"""
myrelu = nn.ReLU()
output = myrelu(input)
"""
class myReLU(nn.Module):def __init__(self):super(myReLU, self).__init__()self.relu = nn.ReLU()def forward(self, x):return self.relu(x)myrelu = myReLU()
output = myrelu(input)
print(output)
2.5 BatchNorm2d
PyTorch 中用于二维批量归一化操作的类。它在深度学习中广泛用于加速网络训练,并提高模型的收敛速度和稳定性。
- 计算均值和方差:
对每个通道,在一个 batch 的所有样本上分别计算均值和方差。- 归一化:
使用计算得到的均值和方差对每个通道的特征图进行归一化,得到标准化的特征图。- 缩放和位移:
引入可学习的参数 gamma(缩放因子)和 beta(位移参数),用于调整归一化后的特征图的分布,增加网络的表达能力。- 反向传播时的梯度更新:
在训练过程中,BatchNorm2d 对归一化后的输出进行缩放和位移,这些参数会随着反向传播更新。
参数
num_features:
说明:指定输入数据的特征数或通道数。对于二维卷积来说,通常是输出特征图的通道数。
示例:如果你的卷积层输出通道数是 16,则 num_features 应该设置为 16。
eps:
说明:是一个小的数,用于防止除以零的情况。在归一化过程中,会将方差加上 eps,以确保数值稳定性。
示例:一般情况下,不需要手动调整这个值,使用默认值即可。
momentum:
说明:用于计算运行均值和方差的动量。在训练过程中,当前的均值和方差会根据 momentum 更新到运行均值和方差中。
示例:通常情况下,使用默认值即可。较大的 momentum 表示更多的历史信息被保留,可以提高归一化的稳定性。
affine:
说明:一个布尔值,用于指定是否应该学习 gamma 和 beta 参数。如果设置为 False,则 BatchNorm2d 只执行归一化,不学习额外的缩放和偏移参数。
示例:通常情况下,保持默认值,即学习 gamma 和 beta 参数。
track_running_stats:
说明:一个布尔值,指定是否应该追踪运行时的均值和方差。如果设置为 True,则在训练过程中会计算并更新运行时的均值和方差;如果设置为 False,则使用批次内的均值和方差。
示例:通常情况下,保持默认值。但在某些情况下,如在推断时可以设置为 False,以减少内存占用和计算量。
import torch
import torch.nn as nn# 示例:创建一个卷积层,接着一个BatchNorm2d层,然后是ReLU激活函数# 假设输入特征图大小为 (N, C, H, W) = (1, 3, 32, 32)
input_tensor = torch.randn(1, 3, 32, 32)# 定义一个卷积层
conv_layer = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1)# 添加BatchNorm2d层
# 注意:BatchNorm2d的num_features参数应该是卷积层输出的通道数,这里是16
batchnorm_layer = nn.BatchNorm2d(16)# 使用ReLU作为激活函数
relu = nn.ReLU()# 将输入通过卷积层、BatchNorm2d层和ReLU激活函数依次传递
output = conv_layer(input_tensor)
output = batchnorm_layer(output)
output = relu(output)
nn.Conv2d定义了一个卷积层,输入通道数为 3,输出通道数为 16。nn.BatchNorm2d创建了一个BatchNorm2d层,它的num_features参数设置为卷积层输出的通道数(这里是 16)。nn.ReLU是一个ReLU激活函数,用于增加网络的非线性特性。- 输入通过卷积层、
BatchNorm2d层和ReLU激活函数的顺序传递,以形成网络的前向传播流程。
2.6 Linear
输入参数
in_features:(一般需要展平,一维)
如果输入是一个大小为 10 的向量 (in_features=10),那么每个输入样本就有 10 个特征。
out_features:
如果希望层的输出是大小为 5 的向量 (out_features=5),那么每个样本的输出就是一个大小为 5 的向量。
bias:
如果设置为 True,则层会学习一个可学习的偏置。如果设置为 False,则层不会学习额外的偏置项。
通常情况下会设置为 True,除非你特别希望从层中去除偏置。
import torch
import torchvision
from torch import nn
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10(root='./dataset', train=False, transform=torchvision.transforms.ToTensor(),download=True)
dataload = torch.utils.data.DataLoader(dataset, batch_size=64, shuffle=True,drop_last=True)
class MyLinear(nn.Module):def __init__(self):super(MyLinear, self).__init__()self.linear = nn.Linear(in_features=196608, out_features=10)def forward(self, x):return self.linear(x)mylinear = MyLinear()for data in dataload:imgs, labels = data# [64, 3, 32, 32]->[1,1,1,196608]->[10]print(imgs.shape)# 将图片张量展平(一行) 作为in_featuresoutputs = torch.flatten(imgs) # 或者outputs = torch.reshape(imgs,(1,1,1,-1))print(outputs.shape)# 传入linear层outputs = mylinear(outputs)print(outputs.shape)
2.7 Sequential
Sequential是一种模型的组织方式,特别适用于那些层按照顺序堆叠的简单模型。
Sequential 有时也指一种按照顺序处理数据的方法或工作流。
dataset = torchvision.datasets.CIFAR10(root='./dataset', train=False, transform=torchvision.transforms.ToTensor(),download=True)
dataload = torch.utils.data.DataLoader(dataset, batch_size=64, shuffle=True, drop_last=True)class MyNet(torch.nn.Module):def __init__(self):super(MyNet, self).__init__()self.conv1 = nn.Conv2d(3, 32, 5, padding=2)self.maxpool1 = nn.MaxPool2d(2)self.conv2 = nn.Conv2d(32, 32, 5, padding=2)self.maxpool2 = nn.MaxPool2d(2)self.conv3 = nn.Conv2d(32, 64, 5, padding=2)self.maxpool3 = nn.MaxPool2d(2)self.flatten = nn.Flatten()self.linear1 = nn.Linear(1024, 64)self.linear2 = nn.Linear(64, 10)def forward(self, x):x = self.conv1(x)x = self.maxpool1(x)x = self.conv2(x)x = self.maxpool2(x)x = self.conv3(x)x = self.maxpool3(x)x = self.flatten(x)x = self.linear1(x)x = self.linear2(x)return x# 利用Sequential
class MySeq(nn.Module):def __init__(self):super(MySeq, self).__init__()self.model1 = Sequential(nn.Conv2d(3, 32, 5, padding=2),nn.MaxPool2d(2),nn.Conv2d(32, 32, 5, padding=2),nn.MaxPool2d(2),nn.Conv2d(32, 64, 5, padding=2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(1024, 64),nn.Linear(64, 10))def forward(self, x):x = self.model1(x)return xmynet = MyNet()
myseq = MySeq()
for data in dataload:imgs, labels = dataoutputs = mynet(imgs)outputs2 = myseq(imgs)print("test1:",end="")print(outputs.shape)print("test2:",end="")print(outputs2.shape)
3 损失函数
3.1 MSELoss
均方误差(MSE)损失是机器学习中常用的一种损失函数,特别适用于回归问题。使用MSE作为损失函数的目的是,对较大的误差进行更重的惩罚,而对较小的误差进行轻微的惩罚。通过平方差的方式实现了这一目的。
使用方法
- 准备数据:
确保你有一个包含输入特征(例如房屋面积、股票历史数据等)和对应输出值(例如房价、股票价格等)的数据集。- 定义模型:
选择适当的机器学习模型,如线性回归、神经网络等,这取决于你的问题和数据。- 选择优化算法:
选择一个优化算法,比如梯度下降,用于调整模型参数以最小化MSE损失。- 定义损失函数:
在训练过程中,定义MSE损失函数。在大多数机器学习框架中,这通常是预先定义好的,你只需要选择并使用。- 训练模型:
将数据输入模型,通过反向传播算法优化模型参数,使得MSE损失逐步减小。- 评估模型:
在训练过程中和/或之后,使用验证集或测试集评估模型的性能。通常,计算预测值与真实值之间的MSE来衡量模型的准确性。
import torch
import torch.nn as nn
import torch.optim as optim# 假设有数据 X_train, y_train 作为训练集# 定义模型
class LinearRegression(nn.Module):def __init__(self, input_size, output_size):super(LinearRegression, self).__init__()self.linear = nn.Linear(input_size, output_size)def forward(self, x):return self.linear(x)# 设置模型参数
input_size = X_train.shape[1] # 输入特征的大小
output_size = 1 # 输出为单个数值(房价)model = LinearRegression(input_size, output_size)# 定义损失函数和优化器
criterion = nn.MSELoss() # 使用均方误差损失
optimizer = optim.SGD(model.parameters(), lr=0.01) # 使用随机梯度下降优化器# 训练模型
num_epochs = 100
for epoch in range(num_epochs):# 前向传播outputs = model(X_train)loss = criterion(outputs, y_train)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()if (epoch+1) % 10 == 0:print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')# 模型训练完成,可以进行预测
with torch.no_grad():predicted = model(X_test)test_loss = criterion(predicted, y_test)print(f'Test MSE Loss: {test_loss.item():.4f}')
- 我们定义了一个简单的线性回归模型。
- 使用PyTorch中的nn.MSELoss()定义了MSE损失函数。
- 使用随机梯度下降(SGD)作为优化器,通过反向传播算法来优化模型参数。
- 训练模型并打印出每个epoch的训练损失。
- 最后,用测试集评估模型的性能,计算测试集上的MSE损失。
3.2 CrossEntropyLoss
交叉熵损失是深度学习中常用的一种损失函数,特别适用于多类别分类任务。

参数:
Input: Shape(C)or (N,C)
C =number of classes
N = batch size
reduction:指定损失的计算方式,可以是’mean’(默认)、‘sum’或’none’
import torch
from torch import nn
"""
损失函数:
1.计算实际输出和目标之间的差距
2.为我们更新输出提供一定的依据(反向传播)
"""
input = torch.tensor([1.0, 2.0, 3.0])
target = torch.tensor([3.0, 2.0, 3.0])
# 批量维度 通道维度 宽度维度 高度维度
input = torch.reshape(input, (1, 1, 1, 3))
target = torch.reshape(target, (1, 1, 1, 3))loss = nn.MSELoss(reduction='mean')
result = loss(input, target)
print(result)x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
x= torch.reshape(x, (1, 3)) # 1个样本,3个类别
cross_loss = nn.CrossEntropyLoss()
result = cross_loss(x, y)
print(result)
4 梯度优化
4.1 optim.SGD
PyTorch中用于实现随机梯度下降优化算法的类。
- SGD是一种基本的优化算法,每次迭代都使用一小批次(batch)的数据来计算梯度和更新模型参数。
- 它通过计算每个参数的梯度以及学习率来更新模型的权重,以减少损失函数的值。
参数
params:需要优化的参数列表。
lr:学习率,控制每次参数更新的步长大小。
momentum:动量因子,用于加速SGD在相关方向上前进,并减少摆动。
dampening:动量的抑制因子。
weight_decay:权重衰减(L2惩罚),用于对模型参数进行正则化。
nesterov:是否使用Nesterov动量。
import torch
import torchvision
from torch import nn
from torch.nn import Sequential
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10(root='./dataset', train=False, transform=torchvision.transforms.ToTensor(),download=True)
dataload = torch.utils.data.DataLoader(dataset, batch_size=64, shuffle=True, drop_last=True)# 利用Sequential
class MyNet(nn.Module):def __init__(self):super(MyNet, self).__init__()self.model1 = Sequential(nn.Conv2d(3, 32, 5, padding=2),nn.MaxPool2d(2),nn.Conv2d(32, 32, 5, padding=2),nn.MaxPool2d(2),nn.Conv2d(32, 64, 5, padding=2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(1024, 64),nn.Linear(64, 10))def forward(self, x):x = self.model1(x)return xmynet = MyNet()
loss = nn.CrossEntropyLoss()
optim = torch.optim.SGD(mynet.parameters(), lr=0.01)
for epoch in range(20): # 一共训练20次epoch_loss = 0.0 # 每次训练所有样本的损失和for data in dataload: # 训练一次所有数据imgs, targets = dataoutputs = mynet(imgs)res_loss = loss(outputs, targets)########################################optim.zero_grad() # 清空梯度 (多次训练,防止梯度影响)res_loss.backward() # 反向传播计算梯度optim.step() # 更新参数#######################################epoch_loss += res_loss.item()print("epoch:{}, loss:{}".format(epoch, epoch_loss))
5 模型
5.1 VGG16模型
模型使用步骤
-
下载模型权重:如果你第一次运行该代码,PyTorch 会自动下载并缓存预训练模型的权重文件。这些权重通常存储在预定义的位置(通常是 PyTorch 提供的服务器上)。
-
加载权重:一旦下载完成,models.vgg16(pretrained=True) 将会加载这些权重并应用于模型的各个层次,包括卷积层和全连接层。这意味着模型会被初始化为在 ImageNet 数据集上训练过的状态,其中包括了学习到的特征权重。
-
使用预训练模型:加载后的 vgg16 模型现在可以直接用于特征提取、微调或者其他任务。由于预训练模型已经学习了大量的特征表示,因此在许多视觉任务中,使用这样的预训练模型往往能够显著提升训练效果和泛化能力。
vgg16_true = torchvision.models.vgg16(pretrained=True)
# pretrained=True 参数的作用是告诉PyTorch加载一个预训练好的 VGG16 模型。
vgg16_false = torchvision.models.vgg16(pretrained=False)print(vgg16_true) # VGG16模型的架构# 修改已有模型
# 添加新的模块(获取已有模块的各个部分)
vgg16_true.classifier.add_module("add_module",nn.Linear(1000, 10))
print(vgg16_true)
# 修改新的模块
vgg16_false.classifier[6] = nn.Linear(4096, 10)
print(vgg16_false)
5.2 模型保存与加载
- 保存
torch.save()是 PyTorch 提供的一个函数,用于将模型、张量或者字典等对象保存到磁盘上的文件中。
torch.save(obj, filepath)
obj: 要保存的对象,可以是模型、张量或者字典等。
filepath: 保存对象的文件路径。
import torch
import torchvisionvgg16 = torchvision.models.vgg16(pretrained=False)
保存方式1 保存模型的结构和参数(整个全保存)
torch.save(vgg16, 'vgg16.pth') #上面的代码将整个模型保存到的文件中。这种方法保存了模型的架构和训练好的权重。上面的代码将整个 vgg16 模型保存到名为 vgg16.pth 的文件中。这种方法保存了模型的架构和训练好的权重。
只需要保存模型的状态字典(即模型的权重),而不保存整个模型对象的结构。
torch.save(vgg16.state_dict(), 'vgg16_dict.pth')
这段代码将只保存 vgg16 模型的权重到 vgg16_dict.pth 文件中,这样可以节省存储空间并且更加灵活,因为在加载时我们可以根据需要重新构建模型。
- 加载
torch.load()是 PyTorch 提供的函数,用于从磁盘上加载已保存的模型、张量或字典等对象。
torch.load(filepath)
filepath: 要加载的文件路径,该文件通常是由 torch.save() 函数保存的。
# 加载模型(结构、参数等等)
"""
这段代码会将之前保存的整个vgg16模型加载到变量 model 中。
加载后的模型可以直接用于预测或继续训练,因为它包含了之前保存的所有结构和参数。
"""
model1 = torch.load("vgg16.pth")
print(model1)# 记载状态参数模型
"""
这段代码首先创建了一个与预训练的vgg 模型相同结构的新模型 model,
然后将加载的状态字典 state_dict 复制到这个新模型中。
这种方法适用于当我们需要从文件中加载权重,并且已有对应模型结构的情况。
"""
model2 = torchvision.models.vgg16(pretrained=False)
print(torch.load("vgg16_dict.pth")) # 只包含权重参数
model2.load_state_dict(torch.load("vgg16_dict.pth"))
print(model2) # 整个模型
5.3 完整模型训练
准备数据:加载训练数据集,并设置数据加载器(DataLoader)用于批量加载数据。
定义模型:创建或加载需要训练的模型,并选择损失函数(loss function)和优化器(optimizer)。
训练循环:使用循环遍历训练数据集,对模型进行训练,主要包括以下步骤:
- 将模型设置为训练模式,即调用 model.train()。
- 遍历每个小批量数据,在每个批量中执行以下操作:
- 将数据传递给模型,获取模型的输出。
- 计算损失(loss)。
- 执行反向传播(backpropagation),计算梯度。
- 使用优化器更新模型参数。
在每个小批量数据的处理结束后,可能会记录或打印训练过程中的一些指标,如损失值或准确率。
评估模型:在每个 epoch 或一定周期后,使用验证集评估模型性能,通常使用 torch.no_grad() 禁止梯度计算,以减少内存占用。
保存模型:在训练完成后,保存模型的参数或整个模型,以便后续推理或继续训练。

构建模型
class MyNet(nn.Module):def __init__(self):super(MyNet, self).__init__()self.model1 = Sequential(nn.Conv2d(3, 32, 5, padding=2),nn.MaxPool2d(2),nn.Conv2d(32, 32, 5, padding=2),nn.MaxPool2d(2),nn.Conv2d(32, 64, 5, padding=2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(1024, 64),nn.Linear(64, 10))def forward(self, x):x = self.model1(x)return x
训练模型
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root='./dataset', train=True, transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root='./dataset', train=False, transform=torchvision.transforms.ToTensor(),download=True)# 数据集长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))# 利用DataLoader来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)# 搭建神经网络
mynet = MyNet()# 损失函数
loss_fn = nn.CrossEntropyLoss()# 优化器
learning_rate = 0.01
optimizer = torch.optim.SGD(mynet.parameters(), lr=learning_rate)# 训练需要的参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10# 添加TensorBoard
write = SummaryWriter(log_dir='./logs')
# 开始轮数
for ep in range(epoch):print("----------第{}轮训练开始-------------".format(ep + 1))# 训练步骤开始mynet.train()start_time = time.time()for data in train_dataloader:imgs, targets = dataoutputs = mynet(imgs)loss = loss_fn(outputs, targets)# 优化器优化模型optimizer.zero_grad()loss.backward()optimizer.step()total_train_step += 1# 每训练100次 打印一次数据if total_train_step % 100 == 0:end_time = time.time()write.add_scalar('train_loss', loss.item(), total_train_step)print("训练次数:{} Loss:{} Time:{}".format(total_train_step, loss.item(),end_time-start_time))# 测试步骤开始mynet.eval()"""正确率分析(以二分类为例)inputs = [0,1] # 表示输入的类别outputs = torch.tensor([1.0,4.0],[2.0,3.0]) # 表示输出各类别的概率preds = outputs.argmax(1) # 横向求出最大值的下标->[1,1]->预测的类别inputs==preds # 比较输入与预测——>[flase,true]"""total_loss = 0 # 计算每轮测试的梯度和total_accuracy = 0 # 计算每轮测试的正确个数# 测试不需要求梯度(此部分不会求梯度)"""用于在执行代码时临时关闭梯度计算。它的作用主要是在推理阶段或者不需要计算梯度的代码段中,提高代码的运行效率和减少内存消耗"""with torch.no_grad():for data in test_dataloader:imgs, targets = dataoutputs = mynet(imgs)loss = loss_fn(outputs, targets)# 每次预测正确的个数accuracy = (targets==outputs.argmax(1)).sum()total_accuracy += accuracy.item()total_test_step += 1total_loss += loss.item()write.add_scalar('test_loss', total_loss, total_test_step)print("第{}轮整体测试集上的Loss:{}".format(ep + 1, total_loss))write.add_scalar('accuracy_rate', total_accuracy/test_data_size, total_test_step)print("第{}轮整体测试集上的accuracy_rate:{}".format(ep+1, total_accuracy/test_data_size))保存每次训练的模型(结构及训练的参数)torch.save(mynet,"mynet_{}.pth".format(ep))print("模型保存成功")
write.close()
train() 和 eval() 是在深度学习中经常用到的两个方法,它们通常用于切换模型的工作模式,即训练模式和评估模式。
mynet.train()
在训练过程中,我们需要使用 train() 方法来告诉模型开始训练,并启用一些特定于训练的功能,
比如启用 dropout 或者批量归一化的训练模式。
mynet.eval()
在评估或推理阶段,我们使用 eval() 方法告诉模型停止学习,不启用 dropout 或批量归一化的训练模式,以确保输出的一致性和稳定性
- 停用 dropout 层:在评估时,dropout 层不再丢弃神经元,以保持输出的稳定性。
- 使用训练时计算的移动平均值来代替批量归一化的计算,以减少测试时间的波动。
区别与使用场景
- 区别:主要区别在于在训练模式下是否启用了
dropout和批量归一化的训练行为。训练模式下,模型会保留这些行为以便模型学习;评估模式下,这些行为被停用以保持输出的一致性。 - 使用场景:在训练阶段,使用
train()方法训练模型;在测试、验证或实际应用中,使用eval()方法评估模型。
5.4 利用GPU训练模型
在PyTorch中,.cuda()是一个方法,用于将Tensor或模型加载到GPU上进行加速计算。
- 将Tensor数据、网络、损失函数移到GPU上
.cuda()是一个方法,用于将Tensor或模型加载到GPU上进行加速计算。
通常是对模型、数据、损失函数使用.cuda()
...
...
...
# 搭建神经网络
mynet = MyNet()
# 使用.cuda()首先判断gpu是否可用
if torch.cuda.is_available():mynet.cuda()# 损失函数
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():loss_fn = loss_fn.cuda()...
...
...
# 开始轮数
for ep in range(epoch):
...
...
...for data in train_dataloader:imgs, targets = dataif torch.cuda.is_available():imgs, targets = imgs.cuda(), targets.cuda()...
...
...
- 将Tensor或模型加载到特定设备上
.to()方法是一个用于Tensor或模型转移到不同设备(如CPU或GPU)的通用方法。它的主要作用是将数据或模型从当前设备移动到目标设备
.to()方法可以接受一个torch.device对象或一个设备字符串作为参数,从而将Tensor或模型加载到指定的设备上。
device = torch.device('cuda')
...
...
...# 搭建神经网络
mynet = MyNet()
# 转移设备
mynet.to(device)
# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
...
...
...
# 开始轮数
for ep in range(epoch):print("----------第{}轮训练开始-------------".format(ep + 1))# 训练步骤开始start_time = time.time()for data in train_dataloader:imgs, targets = dataimgs, targets = imgs.to(device), targets.to(device)
...
...
...
5.5 应用模型
使用训练的模型去预测CIFAR10中图片的分类
- 加载待预测图片
- 修改图片格式为模型规定的格式
- 加载模型
- 使用模型预测
image_path = "imgs/dog.png"
# 加载图片,并转换为正确格式
image = Image.open(image_path)
'''
用于对图像进行大小调整(resize)。
在计算机视觉任务中,经常需要对输入的图像进行预处理,使其符合模型的输入要求或者统一到相同的尺寸上进行批处理。
Resize 类允许我们按照指定的大小调整图像。
'''
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),torchvision.transforms.ToTensor()])
image = transform(image)
print(image.shape) # torch.Size([3, 32, 32])# 加载训练好的模型
class MyNet(nn.Module):def __init__(self):super(MyNet, self).__init__()self.model1 = Sequential(nn.Conv2d(3, 32, 5, padding=2),nn.MaxPool2d(2),nn.Conv2d(32, 32, 5, padding=2),nn.MaxPool2d(2),nn.Conv2d(32, 64, 5, padding=2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(1024, 64),nn.Linear(64, 10))def forward(self, x):x = self.model1(x)return x# 加载模型
'''
mynet.pth在gpu训练的模型需要在cpu进行映射map_location=torch.device('cpu')
否则错误 Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the same or input should be a MKLDNN tensor and weight is a dense tensor
'''
model = torch.load("mynet.pth", map_location=torch.device('cpu'))
# 重塑确保 image 的形状符合下游操作或模型的预期形状。这是深度学习工作流中常见的操作,用于标准化张量的形状。
image = torch.reshape(image, (1, 3, 32, 32))
# 评估模式
model.eval()
with torch.no_grad():outputs = model(image)
print(outputs.argmax(dim=1).item()) # 输出概率最大的种类下标
''' 种类坐标对应
{'airplane': 0, 'automobile': 1, 'bird': 2, 'cat': 3, 'deer': 4,'dog': 5, 'frog': 6, 'horse': 7, 'ship': 8, 'truck': 9}
'''
相关文章:
Pytorch基础应用
1.数据加载 1.1 读取文本文件 方法一:使用 open() 函数和 read() 方法 # 打开文件并读取全部内容 file_path example.txt # 替换为你的文件路径 with open(file_path, r) as file:content file.read()print(content)方法二:逐行读取文件内容 # 逐…...
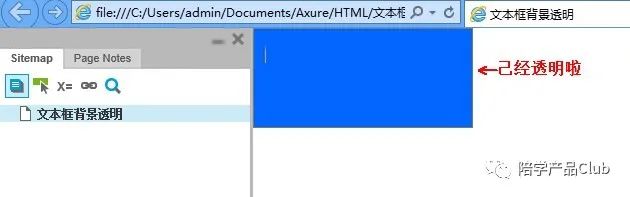
Axure 教程 | 设置文本框背景透明
在AXURE软件中,部件样式可以编辑,但有时却无法满足所有个性化原型的需求。例如文本框部件,可以设置是否隐藏边框,但即使隐藏边框之后,文本框还会有白色的背景。 当界面需要一个无背景色的输入框时,对于完…...

【BUG】已解决:NOAUTH Authentication required
已解决:NOAUTH Authentication required 欢迎来到英杰社区https://bbs.csdn.net/topics/617804998 欢迎来到我的主页,我是博主英杰,211科班出身,就职于医疗科技公司,热衷分享知识,武汉城市开发者社区主理人…...

全国产服务器主板:搭载飞腾FT2000+/64处理器的高性能加固服务器
近期很多朋友咨询全国产化的服务器主板。搭载的是飞腾FT-2000/64的全国产化服务器主板。他的主要特点是:①丰富的PCIe、千兆以太网、SATA接口,可用作数据处理、存储、通信服务器;②板载独立显示芯片,对外HDMI/VGA/L…...
OPC UA边缘计算耦合器BL205工业通信的最佳解决方案
OPC UA耦合器BL205是钡铼技术基于下一代工业互联网技术推出的分布式、可插拔、结构紧凑、可编程的IO系统,可直接接入SCADA、MES、MOM、ERP等IT系统,无缝链接OT与IT层,是工业互联网、工业4.0、智能制造、数字化转型解决方案中IO系统最佳方案。…...

【已解决】Django连接MySQL启动报错Did you install mysqlclient?
在终端执行python manage.py makemigrations报错问题汇总 错误1:已安装mysqlclient,提示Did you install mysqlclient? 当你看到这样的错误信息,表明Django尝试加载MySQLdb模块但未找到,因为MySQLdb已被mysqlclient替代。 【解…...

ubuntu gcc g++版本切换
要将 GCC 和 G 的版本从 12.4 降低到 9,你可以按照以下步骤操作: 安装 GCC 和 G 9: sudo apt update sudo apt install gcc-9 g-9 使用 update-alternatives 设置优先级: sudo update-alternatives --install /usr/bin/gcc gcc…...

如何发一篇顶会论文? 涉及3D高斯,slam,自动驾驶,三维点云等等
SLAM&3DGS 1)SLAM/3DGS/三维点云/医疗图像/扩散模型/结构光/Transformer/CNN/Mamba/位姿估计 顶会论文指导 2)基于环境信息的定位,重建与场景理解 3)轻量级高保真Gaussian Splatting 4)基于大模型与GS的 6D pose e…...

Java面试八股之什么是Redis的缓存更新
什么是Redis的缓存更新 Redis的缓存更新是指当缓存中的数据发生变化时,需要将这些变化同步到缓存中以保持数据的一致性。缓存更新的目的是确保缓存中的数据始终是最新的,以便用户可以获取到最新的数据。 常见的缓存更新策略包括: 直接覆盖…...

新华三H3CNE网络工程师认证—VLAN使用场景与原理
通过华三的技术原理与VLAN配置来学习,首先介绍VLAN,然后介绍VLAN的基本原理,最后介绍VLAN的基本配置。 一、传统以太网问题 在传统网络中,交换机的数量足够多就会出现问题,广播域变得很大,分割广播域需要…...

Linux-开机自动挂载(文件系统、交换空间)
准备磁盘 添加三块磁盘(两块SATA,一块NVMe) 查看设备: [rootlocalhost jian]# ll /dev/sd* [rootlocalhost jian]# ll /dev/nvme0n2 扩:查看当前主机上的所有块设备,通过如下指令实现: [root…...

[003-02-10].第10节:Docker环境下搭建Redis主从复制架构
我的博客大纲 我的后端学习大纲 我的Redis学习大纲 1.cluster(集群)模式-docker版 哈希槽分区进行亿级数据存储 1.1.面试题:1~2亿条数据需要缓存,请问如何设计这个存储案例 1.回答:单机单台100%不可能,肯…...

uni-app学习HBuilderX学习-微信开发者工具配置
HBuilderX官网:简介 - HBuilderX 文档 (dcloud.net.cn)https://hx.dcloud.net.cn/ uni-app官网: uni-app官网 (dcloud.net.cn)https://uniapp.dcloud.net.cn/quickstart-hx.htmlHBuilder下载安装:打开官网 uni-app项目的微信开发者工具配置…...
持续集成08--Jenkins邮箱发送构建信息及测试报告
前言 在持续集成(CI)和持续部署(CD)的自动化流程中,及时通知团队成员关于构建的成功或失败是至关重要的。Jenkins,作为强大的CI/CD工具,提供了多种通知机制,其中邮件通知是最常用且有…...

专题四:设计模式总览
前面三篇我们通过从一些零散的例子,和简单应用来模糊的感受了下设计模式在编程中的智慧,从现在开始正式进入设计模式介绍,本篇将从设计模式的7大原则、设计模式的三大类型、与23种设计模式的进行总结,和描述具体意义。 设计模式体…...

基于X86+FPGA+AI数字化医疗设备:全自动尿沉渣检测仪
助力数字医疗发展,信迈可提供全自动尿沉渣检测仪专用计算机 随着信息技术的不断进步,医疗也进入了一个全新的数字化时代。首先是医疗设备的数字化,大大丰富了医疗信息的内涵和容量,具有广阔的市场发展前景。 数字化医疗设备&…...

vue2导入elementui组件库
第一步安装 npm i element-ui -S 第二步在main.js中导入 第三步使用然后在运行项目...

Django定时任务框架django-apscheduler的使用
1.安装库 pip install django-apscheduler 2.添加 install_app django_apscheduler 3.在app下添加一个task.py文件,用来实现具体的定时任务 task.pydef my_scheduled_job():print("这个任务每3秒执行一次", time.time()) 4.在app下创建一个manag…...

知识库文档处理,word转markdown
前一篇我讲解了如何对接MiniMax实现FAQ,其实知识库不仅仅可以实现FAQ,还能实现帮助文档的查询,内部培训资料的查询等等,但是这些培训资料大部分是word版本的,并且有层级结构,比如标题1,标题1-1等…...

TF和TF-IDF区别和联系
TF(Term Frequency)和TF-IDF(Term Frequency-Inverse Document Frequency)都是用于文本挖掘和信息检索的统计方法,用于评估一个词在文档或文档集合中的重要性。 一.TF(Term Frequency) 1.定义…...

光纤偏振测量:从琼斯矢量到庞加莱球,六种工具深度解析与工程实践
1. 从一道周五小测题说起:光纤测量中的偏振态表征上周五,我在整理旧资料时,翻到了EE Times在2015年发布的一篇“周五小测”文章,主题是光纤光学测量。其中第一道题就很有意思,它问的是:“以下哪种工具不能用…...

Swarmocracy:基于蜂群智能的分布式组织决策模拟实践
1. 项目概述:当开源项目遇上“蜂群民主”最近在开源社区里闲逛,发现一个挺有意思的项目,叫“Swarmocracy”。光看名字,就能嗅到一股混合了技术极客与组织社会学的味道——“Swarm”(蜂群)加上“-cracy”&am…...
)
别再只用VGG19做分类了!手把手教你用PyTorch提取4096维图像特征向量(实战教程)
突破分类局限:用PyTorch解锁VGG19的深度特征提取实战 当你第一次接触VGG19时,可能被它的ImageNet分类能力所震撼。但如果你只把它当作一个分类器,那就如同用瑞士军刀只开瓶盖——大材小用。在计算机视觉领域,预训练模型真正的价值…...
)
2000-2025年《中国县域统计年鉴》pdf+excel版(附赠面板数据)
资源介绍《中国县域统计年鉴》2000-2025一、数据介绍《中国县域统计年鉴》是一部全面反映我国县域社会经济发展状况的资料性年鉴,从2014年开始分为《中国县域统计年鉴(县市卷)》和《中国县域统计年鉴(乡镇卷)》两卷。数…...

苹果W1芯片如何通过低功耗无线技术重塑TWS耳机体验
1. 无线音频的功耗困局与苹果的破局思路 2016年9月,当苹果在发布会上首次亮出那对剪掉线缆的AirPods时,整个消费电子行业都在问同一个问题:它是怎么做到的?更具体地说,它如何解决了无线耳机领域最核心、也最令人头疼的…...

别再让专利证书变废纸!手把手教你用6步法写出能维权的权利要求书
从技术到法律:6步打造高价值专利权利要求的实战指南 刚拿到专利证书的工程师小王,在展会上发现竞争对手的产品几乎照搬了自己的发明。他信心满满地提起诉讼,却因权利要求书中"数据传输模块"的表述过于宽泛而败诉——法院认为该描述…...

LeagueAkari英雄联盟自动化工具终极使用指南:本地化智能助手全面解析
LeagueAkari英雄联盟自动化工具终极使用指南:本地化智能助手全面解析 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否曾为英…...

MyBatis如何实现动态数据源切换?
MyBatis如何实现动态数据源切换 在现代应用中,特别是微服务架构中,使用多个数据库的情况越来越常见。MyBatis是一个流行的Java持久层框架,它允许我们方便地与多种数据库进行交互。在某些情况下,我们可能需要动态切换数据源&#x…...

时间序列预测总翻车?试试用Python实现嵌套交叉验证来守住‘未来’数据
时间序列预测中的嵌套交叉验证:用Python守住数据的时间壁垒 当你在预测下周的销售额、下个月的电力负荷或明天的股价时,最可怕的不是模型不够复杂,而是它偷偷"作弊"了——通过窥探未来的数据来假装自己很聪明。这种时间序列预测中的…...

C#上位机开发入门:手把手教你用PowerPMAC SDK实现第一个通讯Demo
C#上位机开发入门:从零构建PowerPMAC通讯Demo的实战指南 引言 当你第一次打开PowerPMAC开发套件时,面对密密麻麻的库文件和数百页的技术手册,是否感到无从下手?作为工业自动化领域的核心控制器,PowerPMAC与上位机的通讯…...