【字少图多剖析微服务】深入理解Eureka核心原理
深入理解Eureka核心原理
- Eureka整体设计
- Eureka服务端启动
- Eureka三级缓存
- Eureka客户端启动
Eureka整体设计
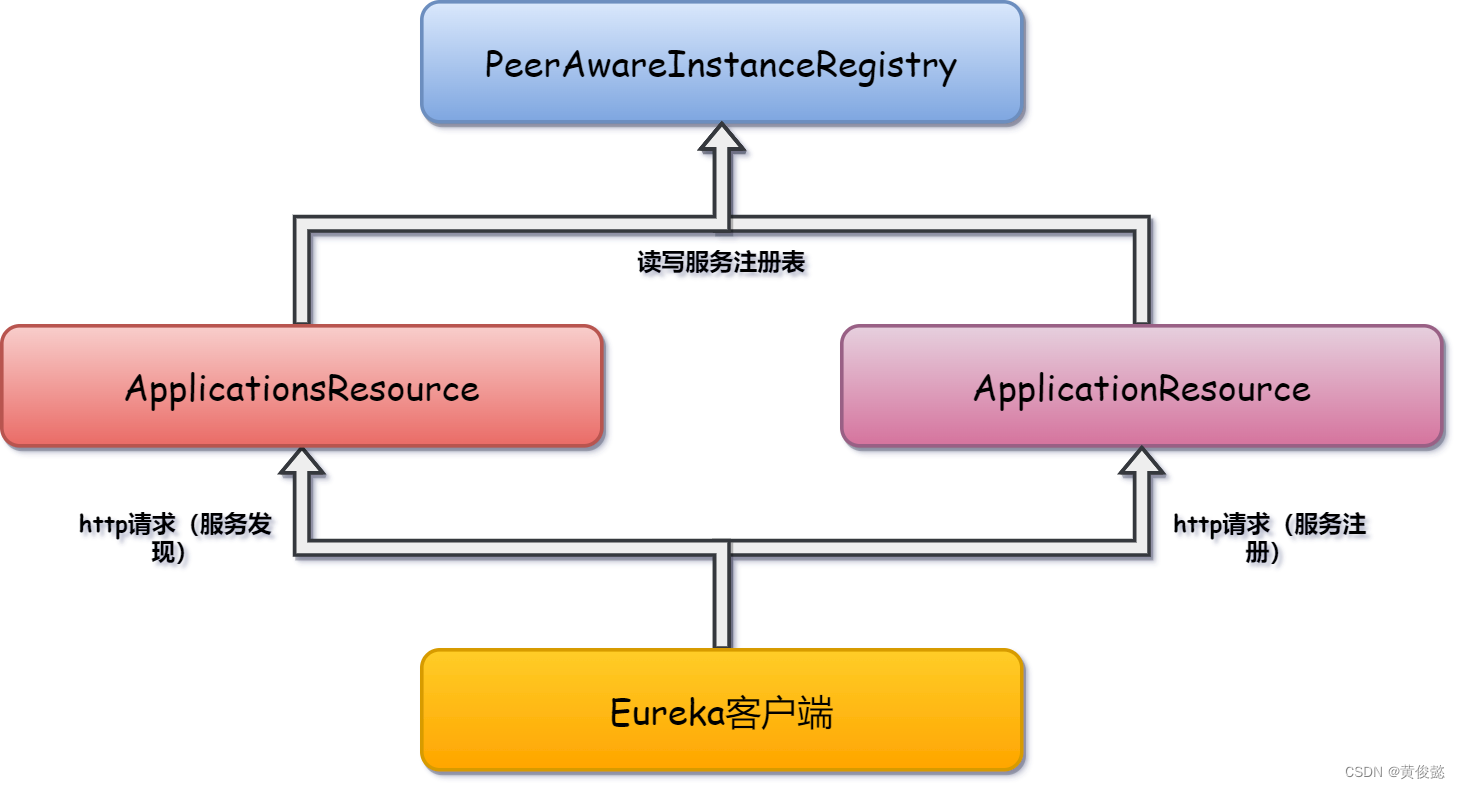
Eureka是一个经典的注册中心,通过http接收客户端的服务发现和服务注册请求,使用内存注册表保存客户端注册上来的实例信息。
Eureka服务端接收的是http请求,通过ApplicationResource接收服务注册请求,通过ApplicationsResource接收服务发现请求,这两个类相当于Spring MVC中的Controller,Eureka使用的不是Spring MVC,而是Jersey,我们直接把他们当成Controller即可。
然后Eureka用一个内存实例注册表PeerAwareInstanceRegistry保存服务提供者注册上来的实例信息,当ApplicationResource接收到服务注册请求时,会把服务实例信息存入PeerAwareInstanceRegistry;当ApplicationsResource接收到服务发现请求时,会从PeerAwareInstanceRegistry拉取服务实例信息返回给客户端
public class ApplicationsResource {private final PeerAwareInstanceRegistry registry;...
}
public class ApplicationResource {private final PeerAwareInstanceRegistry registry;...
}
Eureka服务端启动
Eureka服务端启动时会初始化PeerAwareInstanceRegistry接口的实现类以及其他核心类,除了初始化PeerAwareInstanceRegistry等一些核心类之外,还会做两件事:
- 从集群中的其他Eureka拉取服务实例列表,注册到自己本地的服务注册表
- 开启服务剔除定时任务,定时扫描超过一定期限没有续约的服务实例,把它剔除出内存注册表

初始化PeerAwareInstanceRegistry的代码在EurekaServerAutoConfiguration中,通过@Bean往Spring容器注册一个InstanceRegistry对象,这个InstanceRegistry就是peerAwareInstanceRegistry的实现类。
@Beanpublic PeerAwareInstanceRegistry peerAwareInstanceRegistry(ServerCodecs serverCodecs) {...return new InstanceRegistry(...);}
EurekaServerAutoConfiguration还会通过@Import注解导入一个EurekaServerInitializerConfiguration,这个EurekaServerInitializerConfiguration的start()方法会触发集群同步和启动服务剔除定时任务。
@Overridepublic void start() {new Thread(new Runnable() {@Overridepublic void run() {try {// EurekaServerAutoConfiguration导入的EurekaServerBootstrap// 启动Eureka服务eurekaServerBootstrap.contextInitialized(EurekaServerInitializerConfiguration.this.servletContext);...}catch (...) {...}}}).start();}
public void contextInitialized(ServletContext context) {try {//初始化Eureka运行环境initEurekaEnvironment();//初始化Eureka服务上下文initEurekaServerContext();...}catch (...) {...}}
重点是initEurekaServerContext()方法:
protected void initEurekaServerContext() throws Exception {...// 集群同步(从集群中的其他Eureka实例拉取服务实例列表)int registryCount = this.registry.syncUp();// 启动服务提测定时任务this.registry.openForTraffic(this.applicationInfoManager, registryCount);...}
Eureka三级缓存
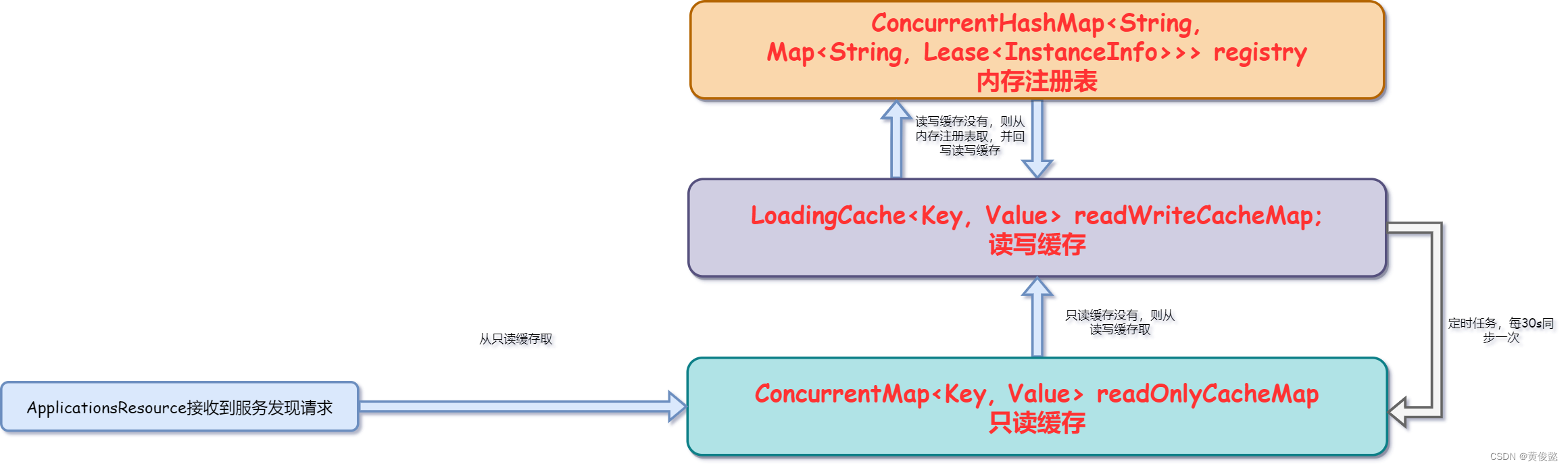
Eureka处理服务发现请求时,其实并不是直接读取内存注册表的,而是读的缓存。Eureka除了内存注册表以外,还有两个缓存,一个是读写缓存readWriteCacheMap,一个是只读缓存readOnlyCacheMap。内存注册表、readWriteCacheMap、readOnlyCacheMap三个组成了Eureka的三级缓存。其中readWriteCacheMap和readOnlyCacheMap被包装在一个ResponseCache对象中。整个三级缓存的结果就是这样:

public class PeerAwareInstanceRegistryImpl extends AbstractInstanceRegistry implements PeerAwareInstanceRegistry {...
}
public abstract class AbstractInstanceRegistry implements InstanceRegistry {...protected volatile ResponseCache responseCache;...
当ApplicationsResource接收到服务发现请求时:
- 先从只读缓存中取
- 如果只读缓存中没有,则从读写缓存获取并且回写只读缓存
- 如果读写缓存中也没有,则从内存注册表中获取并回写到读写缓存。
Eureka会开启一个定时任务,每隔30s从读写缓存同步数据到只读缓存。
ResponseCacheImpl#getValue:
Value getValue(final Key key, boolean useReadOnlyCache) {Value payload = null;try {if (useReadOnlyCache) {// 从只读缓存取final Value currentPayload = readOnlyCacheMap.get(key);if (currentPayload != null) {payload = currentPayload;} else {// 只读缓存没有,则从读写缓存取,回写只读缓存payload = readWriteCacheMap.get(key);readOnlyCacheMap.put(key, payload);}} else {payload = readWriteCacheMap.get(key);}} catch (...) {...}return payload;}
readWriteCacheMap的类型是LoadingCache,LoadingCache是Guava库提供的一个本地缓存实现。当LoadingCache缓存缺失时,LoadingCache会触发CacheLoader的load方法,加载数据到缓存中,此时就会从内存注册表中加载数据到readWriteCacheMap中。关于LoadingCache的使用、作用、原理等知识,可以参考讲解Guava缓存相关的资料。
当ApplicationResource接收到服务注册请求时,会把服务实例信息写入内存注册表,并失效掉读写缓存,然后把新注册上来的实例信息异步同步到集群中的其他Eureka节点。

PeerAwareInstanceRegistryImpl#register
@Overridepublic void register(final InstanceInfo info, final boolean isReplication) {...super.register(info, leaseDuration, isReplication);// 同步到集群中的其他Eureka节点replicateToPeers(Action.Register, info.getAppName(), info.getId(), info, null, isReplication);}
AbstractInstanceRegistry#register:
public void register(InstanceInfo registrant, ...) {try {...// 失效读写缓存invalidateCache(registrant.getAppName(), registrant.getVIPAddress(), registrant.getSecureVipAddress());...} finally {...}}private void invalidateCache(String appName, @Nullable String vipAddress, @Nullable String secureVipAddress) {// invalidate cacheresponseCache.invalidate(appName, vipAddress, secureVipAddress);}
Eureka客户端启动
Eureka的客户端启动时会创建一个DiscoveryClient对象,它是Eureka的客户端对象,它会创建两个定时任务,一个异步延时任务。
两个定时任务:
- 定时拉取服务实例列表(服务发现)
- 定时发送心跳(服务续约)
一个延时任务:服务注册。
DiscoveryClient的构造方法:
@InjectDiscoveryClient(...) {...initScheduledTasks();...}
DiscoveryClient#initScheduledTasks
private void initScheduledTasks() {if (clientConfig.shouldFetchRegistry()) {...// 开启服务发现定时任务scheduler.schedule(new TimedSupervisorTask(...new CacheRefreshThread()),registryFetchIntervalSeconds, TimeUnit.SECONDS);}if (clientConfig.shouldRegisterWithEureka()) {...// 开启服务续约(定时发送心跳)定时任务scheduler.schedule(new TimedSupervisorTask(...new HeartbeatThread()),renewalIntervalInSecs, TimeUnit.SECONDS);instanceInfoReplicator = new InstanceInfoReplicator(...);...// 服务注册instanceInfoReplicator.start(...);} else {...}}
它们都是通过Jersey客户端向Eureka服务端发起http请求。
其中服务发现的定时任务在首次拉取是会全量拉取,后续会进行增量拉取。增量拉取返回的服务实例列表会合并到Eureka客户端的本地缓存中,然后根据本地缓存的服务实例列表计算一个hashCode,与Eureka服务端返回的hashCode进行比较,如果不一致,还要再进行一次全量拉取。

以上就是Eureka全部的核心原理,下面放一张源码图,对源码有兴趣的可以跟一跟,没有兴趣的可以直接忽略。

相关文章:
【字少图多剖析微服务】深入理解Eureka核心原理
深入理解Eureka核心原理 Eureka整体设计Eureka服务端启动Eureka三级缓存Eureka客户端启动 Eureka整体设计 Eureka是一个经典的注册中心,通过http接收客户端的服务发现和服务注册请求,使用内存注册表保存客户端注册上来的实例信息。 Eureka服务端接收的…...

如何在 Linux 中解压 ZIP 文件
ZIP 是一种常用的压缩文件格式,用于存储和传输多个文件。在 Linux 系统中,解压 ZIP 文件非常简单。 使用 unzip 命令 unzip 是一个专用于解压 ZIP 文件的命令行工具。要使用它,请打开终端并输入以下命令: 例如,要解…...

IDEA的APIPost接口测试插件详解
APIPOST官方网址 一、安装APIPost插件 打开IntelliJ IDEA: 启动您的IntelliJ IDEA开发环境。 导航到插件设置: 在Windows或Linux上,点击 File > Settings。在macOS上,点击 IntelliJ IDEA > Preferences。 搜索并安装APIPo…...

[经验] 驰这个汉字的拼音是什么 #学习方法#其他#媒体
驰这个汉字的拼音是什么 驰,是一个常见的汉字,其拼音为“ch”,音调为第四声。它既可以表示动词,也可以表示形容词或副词,意义广泛,经常出现在生活和工作中。下面就让我们一起来了解一下“驰”的含义和用法。…...

生成式人工智能落地校园与课堂的15个场景
生成式人工智能正在重塑教育行业,为传统教学模式带来了革命性的变化。随着AI的不断演进,更多令人兴奋的应用场景将逐一显现,为学生提供更加丰富和多元的学习体验。 尽管AI在教学中的应用越来越广泛,但教师们也不必担心会被完全替代…...

C# 中的事件
1.事件的概念 在C#中,事件是一种特殊的委托类型,用于在对象之间提供一种基于观察者模式的通知机制。事件的发送方定义了一个委托,委托类型的声明包含了事件的签名,即事件处理器方法的签名。事件的订阅者可以通过运算符来注册事件…...

一、单例模式
文章目录 1 基本介绍2 实现方式2.1 饿汉式2.1.1 代码2.1.2 特性 2.2 懒汉式 ( 线程不安全 )2.2.1 代码2.2.2 特性 2.3 懒汉式 ( 线程安全 )2.3.1 代码2.3.2 特性 2.4 双重检查2.4.1 代码2.4.2 特性 2.5 静态内部类2.5.1 代码2.5.2 特性 2.6 枚举2.6.1 代码2.6.2 特性 3 实现的要…...

B树:高效的数据存储结构
在计算机科学中,B树(B-Tree)是一种平衡多路查找树,它广泛应用于数据库和文件系统等需要高效数据存储和检索的场景。B树的设计旨在优化磁盘I/O操作,通过减少磁盘访问次数来提高数据检索的效率。本文将介绍B树的基本概念…...

[Vulnhub] TORMENT IRC+FTP+CUPS+SMTP+apache配置文件权限提升+pkexec权限提升
信息收集 IP AddressOpening Ports192.168.101.152TCP:21,22,25,80,111,139,143,445,631 $ nmap -p- 192.168.101.152 --min-rate 1000 -sC -sV PORT STATE SERVICE VERSION 21/tcp open ftp vsftpd 2.0.8 or later | ftp-anon: Anonymous FTP login a…...

<数据集>安全帽佩戴识别数据集<目标检测>
数据集格式:VOCYOLO格式 图片数量:3912张 图片分辨率:640640 标注数量(xml文件个数):3912 标注数量(txt文件个数):3912 标注类别数:2 标注类别名称:[no-helmet, helmet] 序号类别名称图片…...

[米联客-安路飞龙DR1-FPSOC] FPGA基础篇连载-21 VTC视频时序控制器设计
软件版本:Anlogic -TD5.9.1-DR1_ES1.1 操作系统:WIN10 64bit 硬件平台:适用安路(Anlogic)FPGA 实验平台:米联客-MLK-L1-CZ06-DR1M90G开发板 板卡获取平台:https://milianke.tmall.com/ 登录“米联客”FPGA社区 ht…...

记录uni-app横屏项目:自定义弹出框
目录 前言: 正文: 前言:横屏的尺寸问题 最近使用了uniapp写了一个横屏的微信小程序和H5的项目,也是本人首次写的横屏项目,多少是有点踩坑不太适应。。。 先说最让我一脸懵的点,尺寸大小,下面一…...
:基本命令和操作)
Linux Vim教程(二):基本命令和操作
目录 1. 进入和退出Vim 1.1 启动Vim 1.2 退出Vim 2. 模式切换 2.1 切换到插入模式 2.2 切换到普通模式 2.3 切换到命令模式 2.4 切换到可视模式 3. 移动光标 4. 编辑文本 4.1 插入和追加文本 4.2 删除文本 4.3 复制和粘贴文本 4.4 撤销和重做 5. 搜索和替换 5.…...
)
【大模型基础】4.1 数据挖掘(待)
一、什么是文本挖掘? 文本挖掘指的是从文本数据中获取有价值的信息和知识,它是数据挖掘中的一种方法。文本挖掘中最重要最基本的应用是实现文本的分类和聚类,前者是有监督的挖掘算法,后者是无监督的挖掘算法。 二、文本挖掘的作用是什么? 能够从文本数据中获取有价值的…...

Jupyter Notebook与机器学习:使用Scikit-Learn构建模型
Jupyter Notebook与机器学习:使用Scikit-Learn构建模型 介绍 Jupyter Notebook是一款强大的交互式开发环境,广泛应用于数据科学和机器学习领域。Scikit-Learn是一个流行的Python机器学习库,提供了简单高效的工具用于数据挖掘和数据分析。本…...

IMU提升相机清晰度
近期,一项来自北京理工大学和北京师范大学的团队公布了一项创新性的研究成果,他们将惯性测量单元(IMU)和图像处理算法相结合,显著提升了非均匀相机抖动下图像去模糊的准确性。 研究团队利用IMU捕捉相机的运动数据&…...

掌握SQL Server性能监控:自定义性能计数器的实现
掌握SQL Server性能监控:自定义性能计数器的实现 在数据库管理中,监控数据库性能是确保系统稳定运行的关键。SQL Server提供了丰富的性能监控工具,但有时这些工具可能无法满足特定的监控需求。这时,自定义性能计数器就显得尤为重…...

jdk1.8 List集合Stream流式处理
jdk1.8 List集合Stream流式处理 一、介绍(为什么需要流Stream,能解决什么问题?)1.1 什么是 Stream?1.2 常见的创建Stream方法1.3 常见的中间操作1.4 常见的终端操作 二、创建流Stream2.1 Collection的.stream()方法2.2 数组创建流2.3 静态工厂…...
)
leetcode位运算(1720. 解码异或后的数组)
前言 经过前期的基础训练以及部分实战练习,粗略掌握了各种题型的解题思路。后续开始专项练习。 描述 未知 整数数组 arr 由 n 个非负整数组成。 经编码后变为长度为 n - 1 的另一个整数数组 encoded ,其中 encoded[i] arr[i] XOR arr[i 1] 。例如&am…...

Android 性能优化之卡顿优化
文章目录 Android 性能优化之卡顿优化卡顿检测TraceView配置缺点 StricktMode配置违规代码 BlockCanary配置问题代码缺点 ANRANR原因ANRWatchDog监测解决方案 Android 性能优化之卡顿优化 卡顿检测 TraceViewStricktModelBlockCanary TraceView 配置 Debug.startMethodTra…...
从混乱到秩序:如何用TrguiNG汉化版重塑你的Transmission下载管理体验
从混乱到秩序:如何用TrguiNG汉化版重塑你的Transmission下载管理体验 【免费下载链接】TrguiNG Transmission WebUI 基于 openscopeproject/TrguiNG 汉化和改进 项目地址: https://gitcode.com/gh_mirrors/tr/TrguiNG 你是否还在为Transmission简陋的原生Web…...

深度解析:PC端即时通讯防撤回功能的技术实现
深度解析:PC端即时通讯防撤回功能的技术实现 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) 项目地址: https://gitcode.com/GitHub_…...

如何高效清理重复图片?AntiDupl.NET智能去重工具详解
如何高效清理重复图片?AntiDupl.NET智能去重工具详解 【免费下载链接】AntiDupl A program to search similar and defect pictures on the disk 项目地址: https://gitcode.com/gh_mirrors/an/AntiDupl 在数字资产管理中,重复文件清理已成为提升…...
)
科研绘图升级:用CMplot为你的基因组文章制作高颜值SNP密度图(R实战)
科研绘图升级:用CMplot为你的基因组文章制作高颜值SNP密度图(R实战) 在基因组学研究中,数据可视化不仅是结果展示的手段,更是科学叙事的重要语言。一张精心设计的SNP密度图,能够直观呈现全基因组范围内单核…...

Intel RealSense D435深度数据采集全流程:从Viewer截图到.csv/.raw文件深度解析
Intel RealSense D435深度数据采集全流程:从Viewer截图到.csv/.raw文件深度解析 深度视觉技术正在重塑工业检测、机器人导航和三维重建等领域的工作流程。作为Intel RealSense系列中的明星产品,D435深度相机以其出色的性价比和易用性,成为开发…...

AI智能体集成Telegram:双模式MCP服务器原理与实战部署
1. 项目概述 如果你正在为你的AI助手(比如Claude、Cursor的Composer,或者其他支持MCP协议的智能体)寻找一个功能强大、接入灵活的Telegram集成方案,那么你很可能已经厌倦了那些功能单一、配置复杂的传统机器人框架。今天要聊的这…...

Acode架构深度解析:移动端代码编辑器的技术突破与设计哲学
Acode架构深度解析:移动端代码编辑器的技术突破与设计哲学 【免费下载链接】Acode Acode - powerful text/code editor for android 项目地址: https://gitcode.com/gh_mirrors/ac/Acode 在移动设备成为主流开发工具的今天,开发者面临着一个核心痛…...

从零部署noVNC:一次完整的远程桌面服务搭建与排错实录
1. 为什么选择noVNC? 最近在帮朋友部署远程桌面服务时,发现很多传统VNC方案都需要安装客户端,操作复杂不说,兼容性还差。直到发现了noVNC这个神器,它直接用浏览器就能访问远程桌面,彻底解决了跨平台访问的痛…...

HS2-HF_Patch:让Honey Select 2体验全面升级的智能补丁
HS2-HF_Patch:让Honey Select 2体验全面升级的智能补丁 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 你是否曾经因为语言障碍而无法完全享受Honey…...

Android开发终极指南:Sunflower项目中ViewModel数据共享的最佳实践
Android开发终极指南:Sunflower项目中ViewModel数据共享的最佳实践 【免费下载链接】sunflower A gardening app illustrating Android development best practices with migrating a View-based app to Jetpack Compose. 项目地址: https://gitcode.com/gh_mirro…...