Elasticsearch ILM 热节点迁移至冷节点 IO 打满、影响读写解决方案探讨
1、实战问题
ILM(索引生命周期管理) 遇到热数据迁移至冷节点时造成 IO 打满影响读写的情况。
现在采取的方案是调整索引生命周期策略,定时的将Cold phase 开启/关闭。低峰开启,高峰关闭。
就是不知道这里面会有啥坑。
热节点:15个16C64G 1.5T SSD ,冷接点:18个 8C32G 3T SATA ,每天数据量9T左右。数据保留期5天。
不确定相比较于采用 max_bytes_per_sec 方案进行限制速度哪个会更好。(设置了50M,但是效果不佳。所以才临时采用关闭迁移的方案)有没有哪位大佬有这方面的经验的可以帮忙提提意见。感谢感谢.
——来自死磕 Elasticsearch 知识星球
https://t.zsxq.com/pYuo6
2、问题与已执行的方案梳理
从上面问题的描述,拆解问题和已做的尝试,梳理如下:
2.1 IO 打满影响读写
热数据迁移至冷节点时,IO负载过高,导致读写性能下降。
2.2 索引生命周期策略人为干预调整
通过调整索引生命周期策略(ILM),在低峰期开启 Cold phase,在高峰期关闭 Cold phase,以避免迁移过程对读写性能的影响。
2.3 更改配置看效果
当前设置 max_bytes_per_sec 为 50M,但效果不佳,导致采用关闭迁移的临时方案。
3、方案探讨
上述描述和方案验证中潜在问题与风险,梳理如下:
第一:频繁手动开启/关闭 Cold phase 可能导致管理复杂度增加。
第二,迁移过程中的暂停与恢复可能引起数据不一致或性能波动。
第三,冷节点的IO性能瓶颈可能无法通过简单的策略调整解决,需要进一步优化硬件配置或进行集群扩展。
进一步,我们继续进行解决方案的探讨。
3.1 解决方案1——实施分批迁移数据
实施分批迁移数据的方法,可以通过调整 Elasticsearch的索引生命周期管理(ILM)策略和使用一些自动化脚本来实现。
这个方案类似写入优化中的不要一下子把 bulk 调整过大导致写入打满类似。
下面是一个详细的步骤指南:
步骤1. 定义分批迁移策略
在 Elasticsearch 的ILM策略中,设置多个阶段,每个阶段处理一部分数据的迁移。可以将迁移策略按天、小时或更细的粒度分批进行。
步骤2. 配置ILM策略
创建或修改ILM策略,使其支持分批迁移。
假设你的数据每天有9T,并且你希望分3次迁移,那么你可以每次迁移3T数据。
以下是一个示例ILM策略配置:
{"policy": "my_ilm_policy","phases": {"hot": {"actions": {"rollover": {"max_size": "3TB","max_age": "1d"}}},"warm": {"min_age": "1d","actions": {"allocate": {"number_of_replicas": 1}}},"cold": {"min_age": "2d","actions": {"allocate": {"include": {"box_type": "cold"}}}}}
}这个策略会在数据索引达到 3TB 或 1 天后进行滚动,然后在1天后进入 warm 阶段,2天后进入 cold 阶段。
这个数据迁移方案就像是一个精心设计的流水系统。想象一下,数据就像是河流中的水,它首先在“热”阶段自由流动,这是数据被频繁访问的时期。
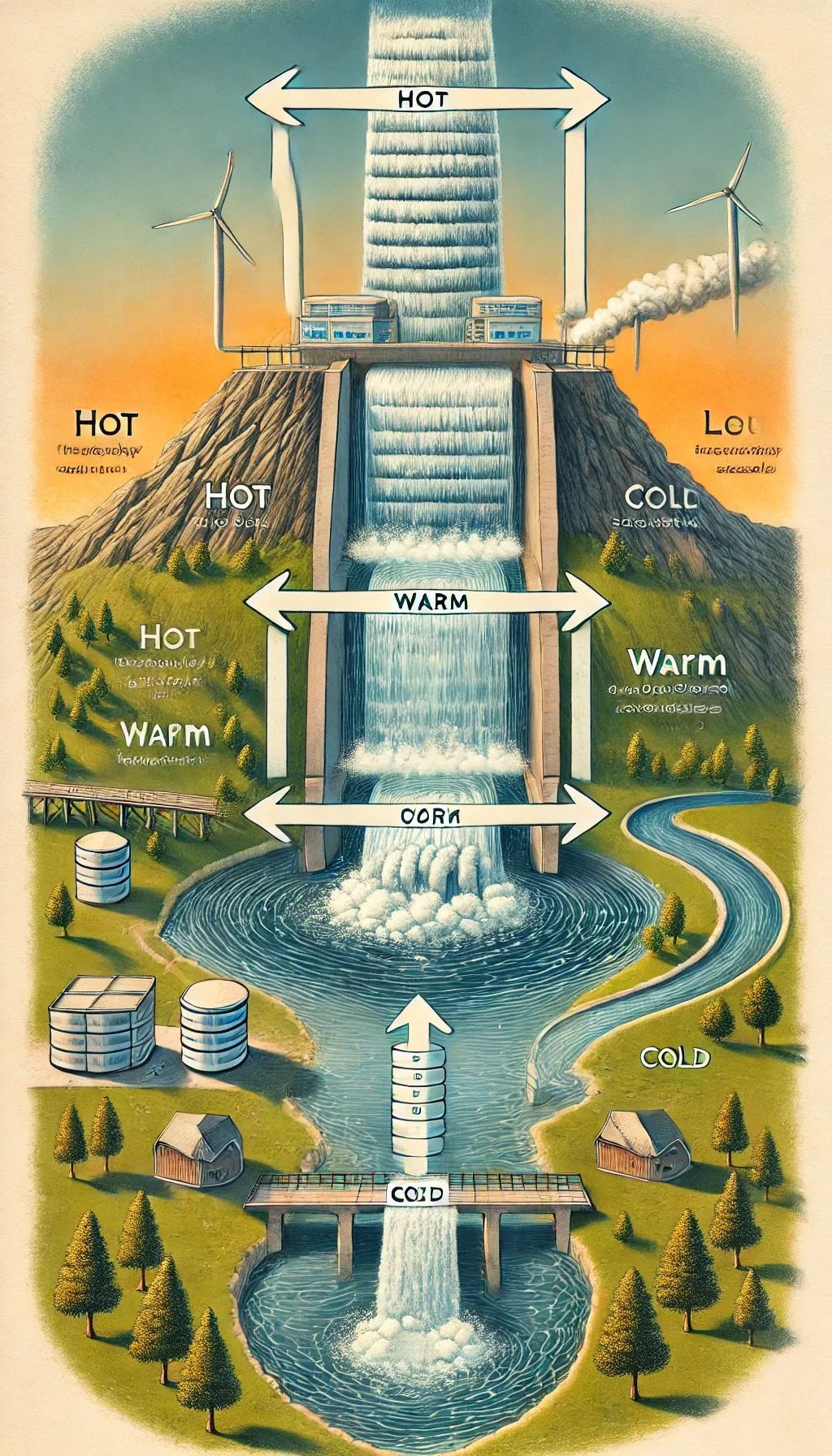
然后,水流到达第一个水坝,这里代表“温”阶段,数据不再需要那么频繁的访问,但仍需快速可达。
最后,水流进入一个宁静的湖泊,象征着“冷”阶段,数据在这里被长期存储,不再活跃使用。
整个过程就像调节河流流量一样,通过控制和分批转移,确保数据流动既顺畅又高效。
步骤3. 监控和调整
持续监控Elasticsearch集群的性能,特别是IO使用情况、CPU和内存利用率。
根据监控结果,适时调整迁移策略和时间间隔。
步骤4. 优化 max_bytes_per_sec
通过以上方法,可以有效地实现分批迁移数据,平滑分摊 IO 压力,提高集群的整体性能和稳定性。
3.2 方案二:优化 max_bytes_per_sec 设置
更精细的限制:虽然你已经设置了50M,但效果不佳,可能是因为这个值并不适合你的具体环境。你可以尝试不同的值,逐步调低,找到一个平衡点。
{"settings": {"index.routing.allocation.max_bytes_per_sec": "30mb"}
}结合冷/热迁移策略:可以尝试在迁移的同时,监控系统的IO 利用率,动态调整 max_bytes_per_sec 的值,确保不会导致IO打满。
3.3 方案三:硬件配置与资源分配优化
考虑升级冷节点的硬盘,从SATA 更换为性能更好的SSD,这将显著提高IO性能。
如果可能,增加热节点的数量,这样可以分摊更多的写入压力。
确保在进行迁移操作时,不影响到业务的正常读写,可以考虑使用 Elasticsearch 的 Shard Allocation Awareness,确保数据节点的合理分布和资源隔离。
参考:Elasticsearch:从写入原理谈写入优化
3.4 方案四:提前获取消息!——监控与自动化管理
使用自动化工具来根据实时监控数据动态调整 ILM 策略。可以设置一些规则,比如在检测到IO利用率高于某个阈值时,自动暂停迁移操作,低于阈值时恢复迁移。
参考 python 脚本如下:
import subprocess
import time
import requests# Elasticsearch 相关配置
ES_HOST = "http://localhost:9200"
ILM_POLICY_NAME = "my_ilm_policy"
ILM_PAUSE_ENDPOINT = f"{ES_HOST}/_ilm/stop"
ILM_RESUME_ENDPOINT = f"{ES_HOST}/_ilm/start"# 监控相关配置
IO_THRESHOLD = 80 # IO 利用率阈值,百分比
CHECK_INTERVAL = 60 # 检查间隔,秒def get_io_utilization():# 使用 iostat 获取 IO 利用率result = subprocess.run(['iostat', '-dx', '1', '1'], stdout=subprocess.PIPE)output = result.stdout.decode()# 提取 IO 利用率(示例仅处理一个设备)for line in output.split('\n'):if 'sda' in line: # 替换为实际的设备名称fields = line.split()utilization = float(fields[-1])return utilizationreturn 0.0def pause_ilm():response = requests.post(ILM_PAUSE_ENDPOINT)if response.status_code == 200:print("ILM 迁移操作已暂停")else:print("暂停 ILM 迁移操作失败:", response.text)def resume_ilm():response = requests.post(ILM_RESUME_ENDPOINT)if response.status_code == 200:print("ILM 迁移操作已恢复")else:print("恢复 ILM 迁移操作失败:", response.text)while True:io_utilization = get_io_utilization()print(f"当前 IO 利用率: {io_utilization}%")if io_utilization > IO_THRESHOLD:pause_ilm()else:resume_ilm()time.sleep(CHECK_INTERVAL)https://www.elastic.co/guide/en/elasticsearch/reference/current/ilm-stop.html
设置监控报警,当IO利用率接近打满时,及时通知运维人员采取措施。可以借助 shell 脚本或者 zabbix 监控工具实现。
举例脚本预警脚本如下:
#!/bin/bash# 监控相关配置
IO_THRESHOLD=90 # IO 利用率阈值,百分比
CHECK_INTERVAL=60 # 检查间隔,秒
EMAIL="your_email@example.com"while true; do# 使用 iostat 获取 IO 利用率IO_UTIL=$(iostat -dx 1 1 | grep 'sda' | awk '{print $NF}') # 替换为实际的设备名称if (( $(echo "$IO_UTIL > $IO_THRESHOLD" | bc -l) )); thenecho "IO utilization is high: $IO_UTIL%" | mail -s "High IO Alert" $EMAILfisleep $CHECK_INTERVAL
done小结
通过以上措施,你应该能够更好地管理热数据到冷节点的迁移过程,减少对读写操作的影响。

干货 | Elasticsearch 索引生命周期管理 ILM 实战指南
Elasticsearch ILM 索引生命周期管理常见坑及避坑指南
和27000+人一起进阶 Elastic Stack及人工智能技术!
相关文章:
Elasticsearch ILM 热节点迁移至冷节点 IO 打满、影响读写解决方案探讨
1、实战问题 ILM(索引生命周期管理) 遇到热数据迁移至冷节点时造成 IO 打满影响读写的情况。 现在采取的方案是调整索引生命周期策略,定时的将Cold phase 开启/关闭。低峰开启,高峰关闭。 就是不知道这里面会有啥坑。 热节点&…...

STM32中PC13引脚可以当做普通引脚使用吗?如何配置STM32的TAMPER?
1.STM32中PC13引脚可以当做普通引脚使用吗? 在STM32单片机中,PC13引脚可以作为普通IO使用,但需要进行一定的配置。PC13通常与RTC侵入检测功能(TAMPER)复用,因此需要关闭TAMPER功能才能将其作为普通IO使用。…...

k8s学习——创建测试镜像
创建一个安装了ifconfig、telnet、curl、nc、traceroute、ping、nslookup等网络工具的镜像,便于集群中的测试。 创建一个Dockerfile文件 # 使用代理下载 Ubuntu 镜像作为基础 FROM docker.m.daocloud.io/library/ubuntu:latest# 设置环境变量 DEBIAN_FRONTEND 为 …...

重塑水资源管理的新篇章:深度剖析智慧水利解决方案的前沿技术与应用,探索其如何推动水利行业向智能化、高效化、可持续化方向迈进
目录 一、引言 二、智慧水利的核心技术 1、物联网技术 2、大数据与云计算 3、人工智能与机器学习 4、数字孪生技术 三、智慧水利的应用实践 1、智慧河湖长制信息平台 2、智能灌溉系统 3、城市防洪排涝智慧管理系统 4、智慧水库建设 四、智慧水利的推动作用 1、提升…...

C#实现数据采集系统-查询报文处理和响应报文分析处理
发送报文处理 增加一个功能码映射关系 //功能码映射关系public readonly Dictionary<string, byte> ReadFuncCodes = new Dictionary<string, byte>();<...

【音视频】AAC编码器与ffmpeg生成AAC数据
文章目录 前言为什么使用AAC?AAC规格常见的AAC规格规格之间的区别 ffmpeg生成AAC数据 总结 前言 在音频压缩技术不断发展的过程中,AAC(Advanced Audio Coding)编码器因其出色的音质和压缩效率,逐渐成为数字音频领域的…...

Linux openEuler_24.03部署MySQL_8.4.0 LTS安装实测验证安装以及测试连接全过程实操手册
Linux openEuler_24.03部署MySQL_8.4.0 LTS安装实测验证安装以及测试连接全过程实操手册 前言: 什么是 MySQL? MySQL 是一个关系型数据库管理系统,由瑞典 MySQL AB 公司开发,目前属于Oracle 公司。MySQL 是一种关系型数据库管理系统,关系型数据库将数据保存在不同的表中,…...

【Elasticsearch7】3-基本操作
目录 RESTful 数据格式 HTTP操作 索引操作 倒排索引 创建索引 查看所有索引 查看单个索引 删除索引 文档操作 创建文档 查看文档 编辑 全量修改 编辑局部修改 删除文档 条件删除文档 高级查询 条件查询 URL带参查询 请求体带参查询 带请求体方式的查…...
给定一整数数组,其中有p种数出现了奇数次,其他数都出现了偶数次,怎么找到这p个数?
给定一长度为m的整数数组 ,其中有p种不为0的数出现了奇数次,其他数都出现了偶数次,找到这p个数。 要求:时间复杂度不大于O(n),空间复杂度不大于O(1)。 由于时间复杂度不大于O(n),则不能在遍历数组中嵌套遍…...

RICHTEK立锜科技 WIFI 7电源参考设计
什么是WIFI 7? WiFi 7(Wi-Fi 7)是下一代Wi-Fi标准,对应的是IEEE 802.11将发布新的修订标准IEEE 802.11be –极高吞吐量EHT(Extremely High Throughput )。Wi-Fi 7是在Wi-Fi 6的基础上引入了320MHz带宽、4096-QAM、Mu…...

CUDA编程00 - 配置CUDA开发环境
第一步: 在一台装有Nvidia显卡和驱动的机器上,用nvidia-smi命令查看显卡所支持cuda版本 第二步: 到Nvidia官网下载CUDA Toolkit并安装,CUDA Toolkit Archive | NVIDIA Developer 安装时按提示下一步即可,安装完成用 …...

HTML5大作业三农有机,农产品,农庄,农旅网站源码
文章目录 1.设计来源1.1 轮播图页面头部效果1.2 栏目列表页面效果1.3 页面底部导航效果 2.效果和源码2.1 源代码 源码下载万套模板,程序开发,在线开发,在线沟通 作者:xcLeigh 文章地址:https://blog.csdn.net/weixin_4…...
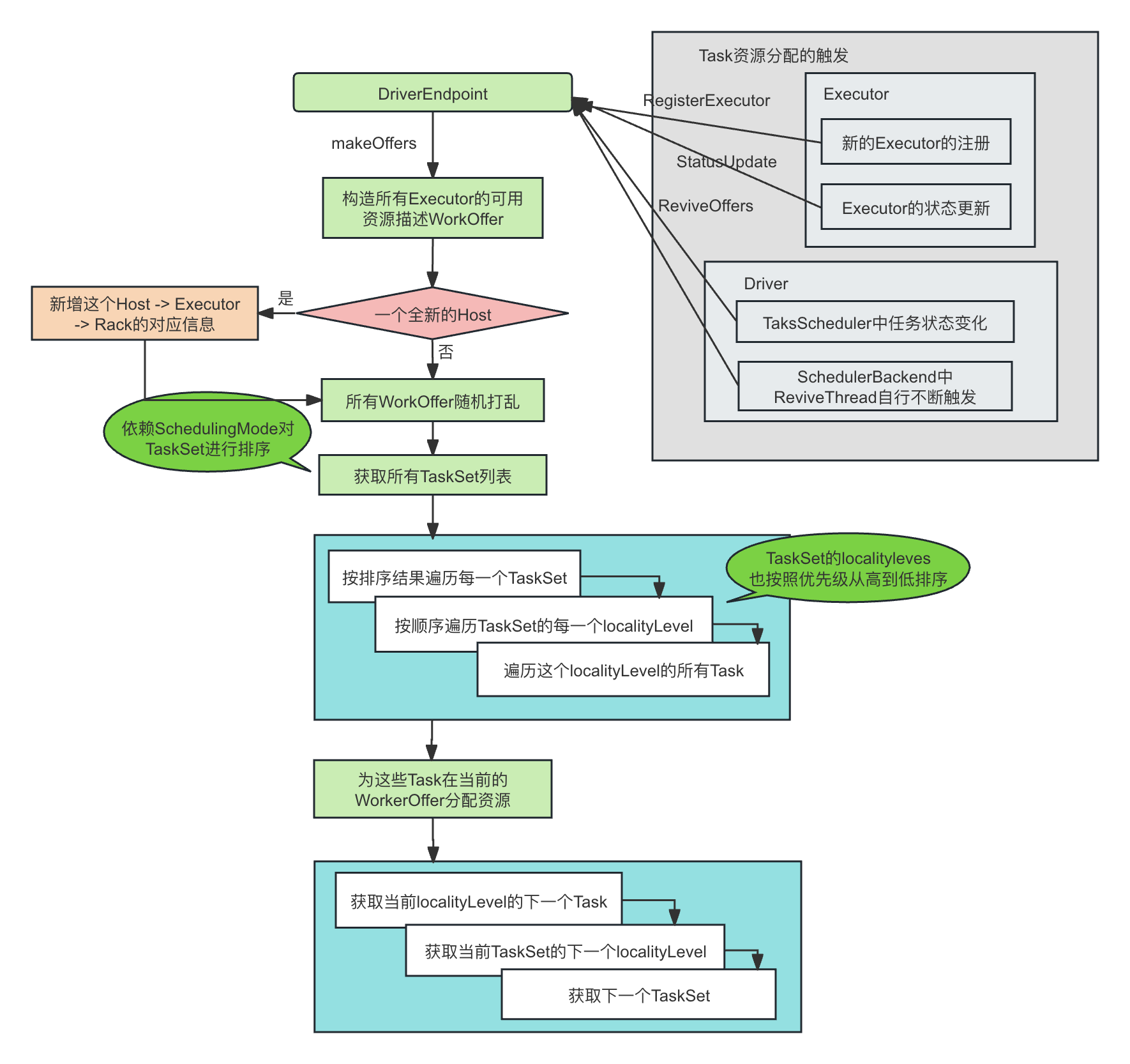
Spark的动态资源分配算法
文章目录 前言基于任务需求进行资源请求的整体过程资源申请的生成过程详解资源申请的生成过程的简单例子资源调度算法的代码解析 申请资源以后的处理:Executor的启动或者结束对于新启动的Container的处理对于结束的Container的处理 基于资源分配结果进行任务调度Pen…...

Python 爬虫技术 第06节 HTTP协议与Web基础知识
HTTP(Hypertext Transfer Protocol)是用于从Web服务器传输超文本到本地浏览器的传输协议。它是互联网上应用最为广泛的一种网络协议,几乎所有的网页数据都是通过HTTP协议进行传输的。下面,我将结合一个简单的Python案例来详细讲解…...

js | 原型链
为什么前者会输出Lucas 后者不会?call动作具体干了什么? http://dmitrysoshnikov.com/ecmascript/javascript-the-core/ function Foo(){this.bar"Lucas" } let obj{}; obj.__proto__Foo.prototype; Foo.call(obj) console.log(obj.bar); // 输出Lucas/…...
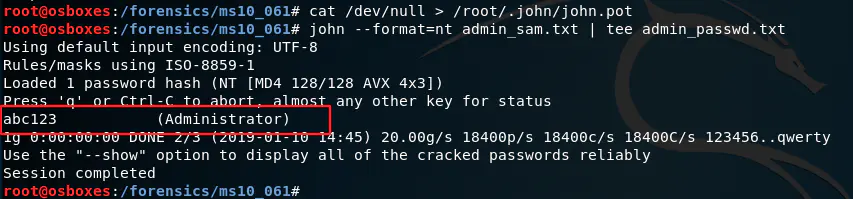
Volatility:分析MS10-061攻击
1、概述 # 1)什么是 Volatility Volatility是开源的Windows,Linux,MaC,Android的内存取证分析工具。基于Python开发而成,可以分析内存中的各种数据。Volatility支持对32位或64位Wnidows、Linux、Mac、Android操作系统…...

水表数字识别3:Pytorch CRNN实现水表数字识别(含训练代码和数据集)
水表数字识别3:Pytorch CRNN实现水表数字识别(含训练代码和数据集) 目录 水表数字识别3:Pytorch CRNN实现水表数字识别(含训练代码和数据集) 1.前言 2. 水表数字识别的方法 3. 水表数字识别数据集 4. 水表数字分割模型训练 5. 水表数字识别模型训…...

oracle数据文件损坏和误删dbf文件处理方法
加油,新时代打工人! 打开sqlplus sqlplus> “/as sysdba” (命令行登录sqlplus) SQL>shutdown abort; (关闭oracle数据库服务器) SQL>startup mount ;(挂载oracle数据库,这…...
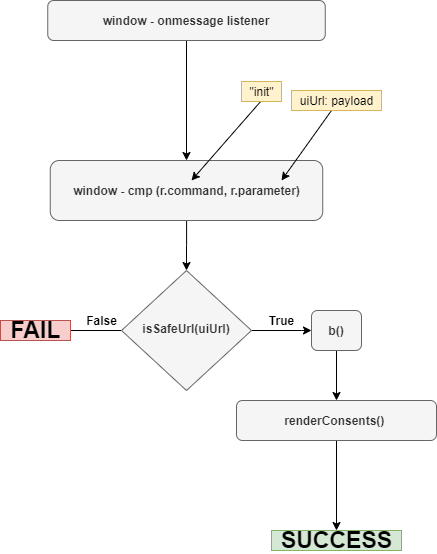
postMessageXss续2
原文地址如下:https://research.securitum.com/art-of-bug-bounty-a-way-from-js-file-analysis-to-xss/ 在19年我写了一篇文章,是基于postMessageXss漏洞的入门教学:https://www.cnblogs.com/piaomiaohongchen/p/14727871.html 这几天浏览mXss技术的时候ÿ…...

【深度学习】sdxl的Lora训练技巧
在进行SDXL LoRA训练时,有一些技巧和最佳实践可以帮助你获得更好的结果。以下是一些重要的建议: 图像选择与标注: 选择多样化的高质量图像是关键,建议至少使用30到50张分辨率为1024x1024的图像【8†source】【9†source】。使用Vi…...

别再折腾Anaconda了!用PyCharm 2024.1自带工具5分钟搞定TensorFlow 2.15 + Keras 3环境
PyCharm 2024.1极简指南:5分钟无痛部署TensorFlow 2.15 Keras 3深度学习环境 深度学习环境配置曾是无数开发者的噩梦——直到PyCharm 2024.1彻底改变了游戏规则。最新版本集成的环境管理工具让TensorFlow和Keras的安装变得像点外卖一样简单,完全跳过了传…...

终极指南:如何使用Harepacker-resurrected打造你的MapleStory游戏Mod
终极指南:如何使用Harepacker-resurrected打造你的MapleStory游戏Mod 【免费下载链接】Harepacker-resurrected All in one .wz file/map editor for MapleStory game files 项目地址: https://gitcode.com/gh_mirrors/ha/Harepacker-resurrected 如果你是一…...

2026终极指南:如何一键重置JetBrains IDE试用期,享受无限期免费开发体验
2026终极指南:如何一键重置JetBrains IDE试用期,享受无限期免费开发体验 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否曾因JetBrains IDE试用期到期而中断开发工作?每次…...

大模型风口已至:月薪30K+的AI Agent开发岗,你准备好了吗?
文章介绍了如何借助不同版本的Agents实现智能自动化,并详细描述了AI应用工程师和大模型算法工程师的岗位职责和任职要求。文章还强调了AI学习的重要性,指出最先掌握AI的人将具有竞争优势,并提供了大模型AI学习和面试资料,帮助读者…...

Windows安卓应用安装神器:APK Installer完整使用指南
Windows安卓应用安装神器:APK Installer完整使用指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为Windows电脑无法运行安卓应用而烦恼吗ÿ…...

构建个人技能知识库:从Markdown管理到自动化实践
1. 项目概述:一个技能库的诞生与价值最近在整理个人知识体系时,我一直在思考一个问题:如何将那些零散的、跨领域的“技能点”系统化地管理起来,形成一个可以持续迭代、随时取用的个人工具箱?这不仅仅是写一份简历上的技…...

APK安装器终极指南:在Windows上轻松安装安卓应用的5个简单步骤
APK安装器终极指南:在Windows上轻松安装安卓应用的5个简单步骤 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否想在Windows电脑上直接运行安卓应用&a…...

用STM32+NRF24L01模拟蓝牙广播,手机能搜到设备了!附完整代码
用STM32NRF24L01模拟蓝牙低功耗广播的实战指南 当我在实验室里第一次看到手机蓝牙搜索列表中出现自己用NRF24L01模块模拟的设备名称时,那种成就感至今难忘。这个看似简单的实验背后,其实隐藏着无线通信协议栈的巧妙设计。本文将带你从零开始,…...

MooseFS企业级部署方案:多数据中心架构设计与实施指南
MooseFS企业级部署方案:多数据中心架构设计与实施指南 【免费下载链接】moosefs MooseFS Distributed Storage – Open Source, Petabyte, Fault-Tolerant, Highly Performing, Scalable Network Distributed File System / Software-Defined Storage 项目地址: h…...
实战分配指南(MDK/IAR双环境))
告别内存焦虑!STM32H743全系列SRAM(ITCM/DTCM/AXI)实战分配指南(MDK/IAR双环境)
STM32H743内存优化实战:从理论到精准分配的完整指南 在嵌入式系统开发中,内存管理往往是决定项目成败的关键因素之一。STM32H743作为STMicroelectronics推出的高性能微控制器系列,其复杂的内存架构既带来了性能优势,也增加了开发难…...