Langchain[3]:Langchain架构演进与功能扩展:流式事件处理、事件过滤机制、回调传播策略及装饰器应用
Langchain[3]:Langchain架构演进与功能扩展:流式事件处理、事件过滤机制、回调传播策略及装饰器应用
1. Langchain的演变
v0.1: 初始版本,包含基本功能。
-
从0.1~0.2完成的特性:
- 通过事件流 API 提供更好的流式支持。
- 标准化工具调用支持Tools Calling。
- 标准化的输出结构接口。
- @chain 装饰器,更容易创建 RunnableLambdas。
- 在 Python 中对许多核心抽象的更好异步支持。
- 在 AIMessage 中包含响应元数据,方便访问底层模型的原始输出。
- 可视化 runnables 或 langgraph 应用的工具。
- 大多数提供商之间的聊天消息历史记录互操作性。
- 超过 20 个 Python 流行集成的合作伙伴包。
-
LangChain 的未来发展
- 持续致力于 langgraph 的开发(向langgraph迁移),增强代理架构的能力。
- 重新审视 vectorstores 抽象,以提高可用性和可靠性。
- 改进文档和版本化文档。
- 计划在 7 月至 9 月之间发布 0.3.0 版本,全面支持 Pydantic 2,并停止对 Pydantic 1 的支持。
注意:自 0.2.0 版本起,langchain 不再依赖 langchain-community。langchain-community 将依赖于 langchain-core 和 langchain。
- 具体变化
从 0.2.0 版开始,langchain 必须与集成无关。这意味着,langchain 中的代码默认情况下不应实例化任何特定的聊天模型、llms、嵌入模型、vectorstores 等;相反,用户需要明确指定这些模型。
以下这些API从0.2版本起要显式的传递LLM
langchain.agents.agent_toolkits.vectorstore.toolkit.VectorStoreToolkit
langchain.agents.agent_toolkits.vectorstore.toolkit.VectorStoreRouterToolkit
langchain.chains.openai_functions.get_openapi_chain
langchain.chains.router.MultiRetrievalQAChain.from_retrievers
langchain.indexes.VectorStoreIndexWrapper.query
langchain.indexes.VectorStoreIndexWrapper.query_with_sources
langchain.indexes.VectorStoreIndexWrapper.aquery_with_sources
langchain.chains.flare.FlareChain
langchain.indexes.VectostoreIndexCreator
以下代码已被移除
langchain.natbot.NatBotChain.from_default removed in favor of the from_llm class method.
- @tool修饰符:
@tool
def my_tool(x: str) -> str:"""Some description."""return "something"print(my_tool.description)
0.2前运行结果会是:my_tool: (x: str) -> str - Some description. 0.2后的运行结果是:Some description.
更多内容见langchain 0.2 :https://python.langchain.com/v0.2/docs/versions/v0_2/deprecations/
LangChain 简化了 LLM 应用程序生命周期的每个阶段:
开发:使用 LangChain 的开源构建块、组件和第三方集成构建您的应用程序。使用LangGraph构建具有一流流媒体和人机交互支持的状态代理。生产化:使用LangSmith检查、监控和评估您的链,以便您可以不断优化和自信地部署。部署:使用LangGraph Cloud将您的 LangGraph 应用程序转变为可用于生产的 API 和助手。
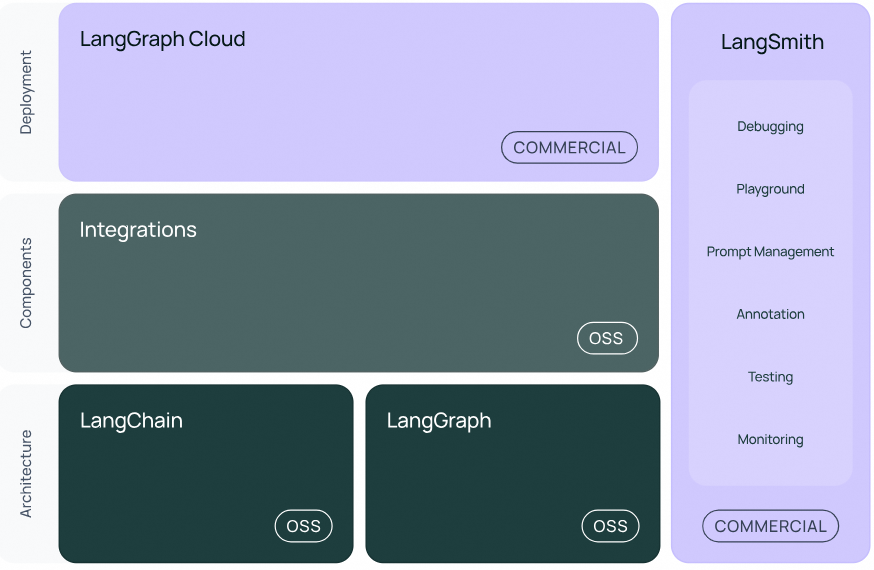
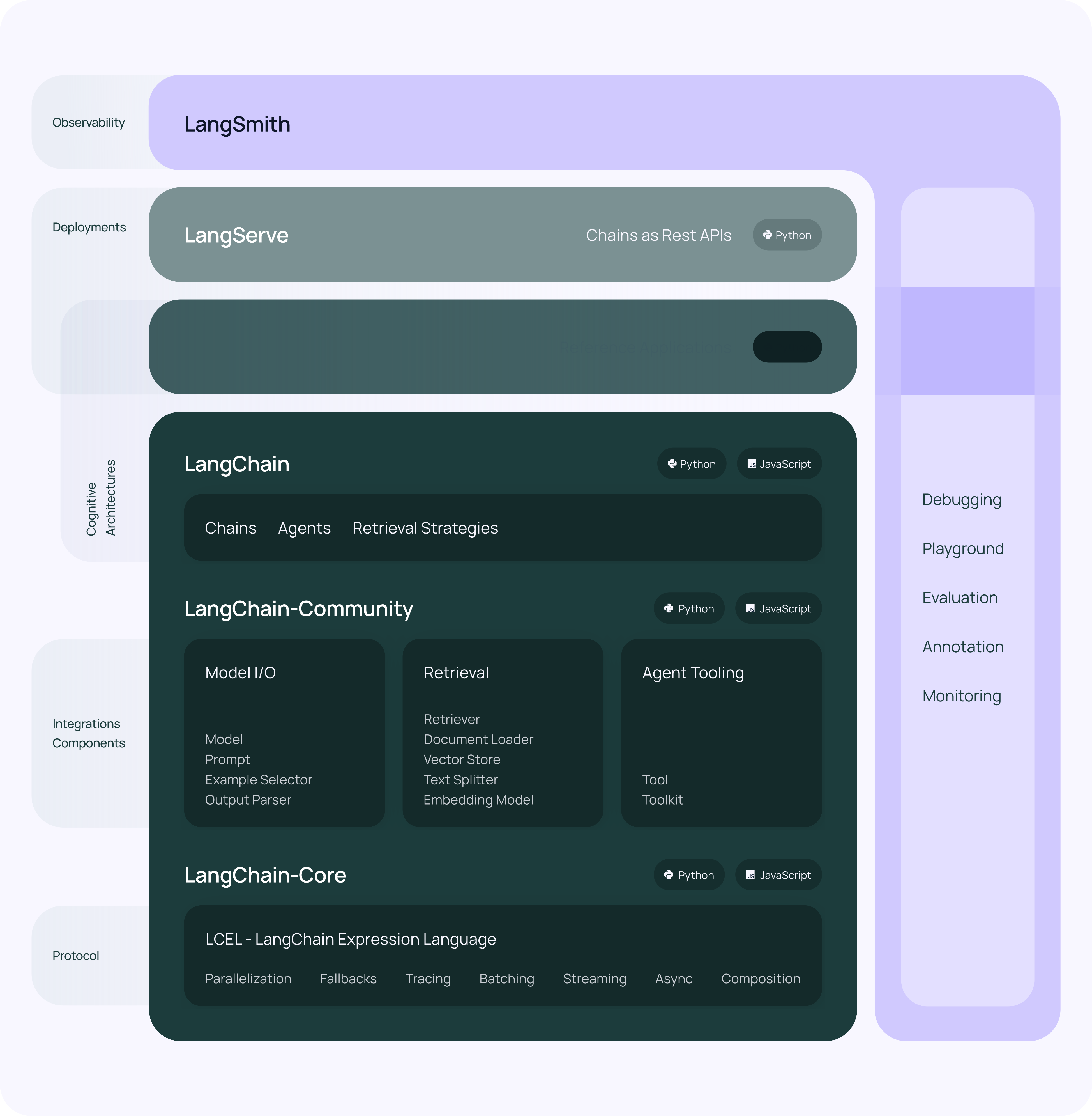
该框架目前将自身定位为覆盖LLM应用开发全生命周期的框架。包含开发、部署、工程化三个大方向,在这三个大方向,都有专门的产品或产品集:
开发阶段:主要是python和javascript两种语言的SDK,配合开放的社区组件模板,来便捷的实现跨LLM的APP开发工程化或产品化阶段:主要是以LangSmith为代表的产品,集监控、playground、评估等功能于一身部署阶段:主要是LangServer产品,基于fastapi封装的LLM API服务器。
基本的方向是开发员的SDK和组件来壮大社区,然后通过类似LangSmith等工具产品实现商业化。
langchain-core:主要的SDK依赖包,包括基本的抽象结构和LECL脚本语言。langchain-community:第三方集成。- 合作伙伴包(例如langchain-openai、langchain-anthropic等):一些集成被进一步拆分成自己的仅依赖于的轻量级包langchain-core。
langchain:构成应用程序认知架构的链、代理和检索策略(剥离后只有Chains、Agents、以及构成应用程序认知结构的检索策略)。LangGraph:通过将步骤建模为图中的边和节点,使用 LLM 构建强大且有状态的多参与者应用程序。与 LangChain 顺利集成,但可以在没有 LangChain 的情况下使用。【多Agents框架的实现】LangServe:将 LangChain 链部署为 REST API。LangSmith:功能很多包括提示词模板聚合、监控、调试、评测LLM等等,部分功能会收费。
2. 如何迁移到0.2.x版本
- 安装 0.2.x 版本的 langchain-core、langchain,并将可能使用的其他软件包升级到最新版本。(例如,langgraph、langchain-community、langchain-openai 等)。
- 验证代码是否能在新软件包中正常运行(例如,单元测试通过)。
- 安装最新版本的 langchain-cli,并使用该工具将代码中使用的旧导入替换为新导入。
- 手动解决所有剩余的弃用警告。
- 重新运行单元测试。
- 如果正在使用 astream_events,请查看如何迁移到 astream events v2。
- 如何迁移到0.2.x - 升级依赖包
0.2版本对依赖包做了较大调整,详细参照下表:

- 如何迁移到0.2.x - 使用langchain-cli工具
安装该工具
pip install langchain-cli
langchain-cli --version # <-- 确保版本至少为 0.0.22
注意,该工具并不完美,在迁移前你应该备份好你的代码。使用的时候您需要运行两次迁移脚本,因为每次运行只能应用一次导入替换。
#例如,您的代码仍然使用
from langchain.chat_models import ChatOpenAI
#第一次运行后,您将得到:
from langchain_community.chat_models import ChatOpenAI
#第二次运行后,您将得到:
from langchain_openai import ChatOpenAI
ang-cli的其他命令:
#See help menu
langchain-cli migrate --help
#Preview Changes without applying
langchain-cli migrate --diff [path to code]
#run on code including ipython notebooks
#Apply all import updates except for updates from langchain to langchain-core
langchain-cli migrate --disable langchain_to_core --include-ipynb [path to code]
3.基于runnables的流式事件支持
大模型在推理时由于要对下一个字的概率进行计算,所以无论多么牛逼的LLM,在推理的时候或多或少都有一些延迟,而这种延迟在类似Chat的场景里,体验非常不好,除了在LLM上下功夫外,提升最明显的就是从用户体验着手,采用类似流式输出的方式,加快反馈提升用户体验,让用户感觉快乐很多,这也是为什么chatG{T会采用这种类似打字机效果的原因。流式在langchain前面版本已经支持不少,在0.2版本里,主要是增加了事件支持,方便开发者对流可以有更细致的操作颗粒度。
- 流的主要接口
我们知道从0.1大版本开始,langchain就支持所谓的runnable协议,为大部分组件都添加了一些交互接口,其中流的接口有:- 同步方式的stream以及异步的astream:他们会以流的方式得到chain的最终结果。
- 异步方式的astream_event和astream_log:这两个都可以获得到流的中间步骤和最终结果。
3.1 直接使用大模型输出流
from langchain_community.chat_models import ChatZhipuAI
import os
os.environ["ZHIPUAI_API_KEY"] = "zhipuai_api_key"model = ChatZhipuAI(model="glm-4",temperature=0,streaming=True,
)chunks = []
async for chunk in model.astream("你好关于降本增效你都知道什么?"): #采用异步比同步输出更快chunks.append(chunk)print(chunk.content, end="|", flush=True)
- 结果
#异步输出
降|本|增效|是企业|为了|提高|市场|竞争力|、|优化|资源配置|、|提升|经济效益|而|采取|的一系列|措施|。|其|核心|是|降低|成本|、|提高|效率|,|具体|来说|,|包括|以下几个方面|:1|.| **|成本|控制|**|:|企业|通过|精细|化管理|,|严格控制|生产|成本|,|减少|不必要的|开支|。|比如|,|优化|供应链|管理|,|降低|原材料|采购|成本|;|提高|能源|利用|效率|,|减少|能源|消耗|;|精|简|人员|结构|,|提高|劳动|生产|率|等|。2|.| **|技术创新|与|研发|**|:|通过|技术创新|和|研发|,|改进|生产工艺|,|提高|产品质量|,|降低|单位|产品|成本|。|同时|,|新技术|、|新|产品的|开发|也能|提升|企业的|市场竞争|力和|盈利|能力|。3|.| **|管理|优化|**|:|优化|企业|内部|管理|流程|,|提高|决策|效率|和管理|效率|。|如|实施|信息化|管理|,|提高|数据处理|速度|和|准确性|,|减少|人为|错误|和|重复|劳动|。4|.| **|市场|与|销售|策略|调整|**|:|根据|市场|变化|调整|销售|策略|,|优化|产品|结构|,|提高|高|附加值|产品的|比重|,|增强|市场|适应|能力和|盈利|能力|。5|.| **|资金|运作|**|:|合理|规划和|优化|企业|融资|结构|,|降低|财务|成本|。|比如|,|通过|发行|低|利率|债券|等方式|筹集|资金|,|减少|利息|支出|。6|.| **|规模|效应|**|:|扩大|生产|规模|,|实现|规模|经济|,|降低|单位|成本|。以下|是根据|提供的|参考|信息|,|对|几|家企业|降|本|增效|措施|的具体|案例分析|:-| **|山东|钢铁|**|:|面临|行业|困境|,|山东|钢铁|通过|增持|公司|股份|增强|市场|信心|,|同时|实施|包括|提高|增量|、|降低|费用|、|加强|采购|优化|销售等|在内的|多项|措施|,|并通过|财务|手段|降低|贷款|利率|,|成功|发行|低成本|融资|券|。-| **|银|轮|股份|**|:|公司|通过|持续推进|降|本|增效|措施|,|提升|运营|效率|,|改善|海外|工厂|运营|,|提升|盈利|能力|,|并通过|加大|研发|投入|,|强化|技术|产品|优势|。-| **|山|鹰|国际|**|:|通过|提升|产能|利用率|,|持续|推动|降|本|增效|和|精益|生产|,|优化|运营|资金|,|降低|管|销|费用|。-| **|野|马|电池|**|:|公司|优化|营销|网络|布局|,|加强|销售|推广|,|同时|推进|精细|化管理|,|全面|降|本|增效|,|提高|运营|效率|。-| **|丽|尚|国|潮|**|:|在|消费|复苏|背景下|,|公司|通过|优化|商业模式|,|实施|精细化|运营|管理|,|提升|业务|效率和|盈利|能力|。-| **|白银|有色|**|:|通过|强化|内部|管理|,|多|措|并举|降|本|增效|、|开源|节|流|,|提升|经济效益|,|改善|经营|状况|。这些|案例|表明|,|降|本|增效|是|企业在|各种|市场|环境下|提升|竞争力|、|保证|可持续发展|的重要|途径|。||
3.2 Chain中的流输出
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplateimport os
os.environ["ZHIPUAI_API_KEY"] = "xxx"model = ChatZhipuAI(model="glm-4",temperature=0,streaming=True,
)prompt = ChatPromptTemplate.from_template("告诉我一个关于{topic}的笑话")
parser = StrOutputParser()
chain = prompt | model | parserasync for chunk in chain.astream({"topic": "裁员"}):print(chunk, end="|", flush=True)
有一天|,|公司|老板|走进|办公室|,|对所有|员工|说|:“|我|有个|好消息|和一个|坏|消息|要|告诉大家|。”|员工|们|紧张|地|等待着|,|老板|接着|说|:“|坏|消息|是|,|我们|公司|要|裁员|了|。”|大家|一片|沉默|,|这时|老板|又|笑着说|:“|好消息|是|,|我们|公司|要|裁员|了|,|你们|终于|可以|摆脱|这些|无聊|的工作|,|去|追求|自己的|梦想|了|!”|员工|们|面|面|相|觑|,|其中|一个人|小|声|嘀|咕|:“|那|我还是|先|回去|做|一下|简历|吧|。”|这个|笑话|虽然|有些|黑色|幽默|,|但也|反映了|裁员|这个|话题|在|职场|中的|敏感性|。|希望大家|在|现实生活中|都能|顺利|度过|各种|职场|挑战|。||
3.3 高级使用:在chain中使用流式输出json结构
很多时候的实际场景是,我们希望接口输出的是一个json结构,这样在前端应用层面会比较灵活,但是如果是流式输出,很可能因为字符结构没有输出结束会导致json报错,这种情况可以这样处理:
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.output_parsers import JsonOutputParser
import osos.environ["ZHIPUAI_API_KEY"] = "key"model = ChatZhipuAI(model="glm-4",temperature=0,streaming=True,
)#异步方法
import asyncio
async def my_async_function():chain = (model | JsonOutputParser())async for text in chain.astream("输出 JSON 格式的法国、西班牙和日本国家及其人口列表。 "'使用一个外键为 "countries "的 dict,其中包含一个国家列表。'"每个国家都应有 `name` 和 `population`键"):print(text, flush=True)async def main():await my_async_function()asyncio.run(main()) #In plain Python
#await main() # In jupyter jupyter 已经运行了loop,无需自己激活,采用await()调用即可
- 结果
{}
{'countries': []}
{'countries': [{}]}
{'countries': [{'name': ''}]}
{'countries': [{'name': 'France'}]}
{'countries': [{'name': 'France', 'population': 67}]}
{'countries': [{'name': 'France', 'population': 673}]}
{'countries': [{'name': 'France', 'population': 673900}]}
{'countries': [{'name': 'France', 'population': 67390000}]}
{'countries': [{'name': 'France', 'population': 67390000}, {}]}
{'countries': [{'name': 'France', 'population': 67390000}, {'name': ''}]}
{'countries': [{'name': 'France', 'population': 67390000}, {'name': 'Spain'}]}
{'countries': [{'name': 'France', 'population': 67390000}, {'name': 'Spain', 'population': 46}]}
{'countries': [{'name': 'France', 'population': 67390000}, {'name': 'Spain', 'population': 467}]}
{'countries': [{'name': 'France', 'population': 67390000}, {'name': 'Spain', 'population': 467330}]}
{'countries': [{'name': 'France', 'population': 67390000}, {'name': 'Spain', 'population': 46733038}]}
{'countries': [{'name': 'France', 'population': 67390000}, {'name': 'Spain', 'population': 46733038}, {}]}
{'countries': [{'name': 'France', 'population': 67390000}, {'name': 'Spain', 'population': 46733038}, {'name': ''}]}
{'countries': [{'name': 'France', 'population': 67390000}, {'name': 'Spain', 'population': 46733038}, {'name': 'Japan'}]}
{'countries': [{'name': 'France', 'population': 67390000}, {'name': 'Spain', 'population': 46733038}, {'name': 'Japan', 'population': 125}]}
{'countries': [{'name': 'France', 'population': 67390000}, {'name': 'Spain', 'population': 46733038}, {'name': 'Japan', 'population': 1258}]}
{'countries': [{'name': 'France', 'population': 67390000}, {'name': 'Spain', 'population': 46733038}, {'name': 'Japan', 'population': 125880}]}
{'countries': [{'name': 'France', 'population': 67390000}, {'name': 'Spain', 'population': 46733038}, {'name': 'Japan', 'population': 125880000}]}
看到流的输出总是保持这合法的json结构,从而避免了报错,如果我们期待在这种结构下,可以以流式来取到国家名称该怎么做?是的这里就要在Json输出后,继续处理。
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.output_parsers import JsonOutputParser
import osos.environ["ZHIPUAI_API_KEY"] = "9a0"model = ChatZhipuAI(model="glm-4",temperature=0,streaming=True,
)#异步方法
import asyncio#自定义函数用来过滤上一步的输入
async def _extract_country_names_streaming(input_stream):"""A function that operates on input streams."""country_names_so_far = set()async for input in input_stream:if not isinstance(input, dict):continueif "countries" not in input:continuecountries = input["countries"]if not isinstance(countries, list):continuefor country in countries:name = country.get("name")if not name:continueif name not in country_names_so_far:yield namecountry_names_so_far.add(name)async def my_async_function():# 在json输出后,调用自定义函数用来过滤国家这个字段chain = model | JsonOutputParser() | _extract_country_names_streamingasync for text in chain.astream("输出 JSON 格式的法国、西班牙和日本国家及其人口列表。 "'使用一个外键为 "countries "的 dict,其中包含一个国家列表。'"每个国家都应有 `name` 和 `population`键"):#以|符号分割开字符print(text, end="|", flush=True)async def main():await my_async_function()asyncio.run(main())Franc| Spain| Japan|
3.4 不支持流式的组件处理(检索器)
并不是所有的组件都支持流式输出,比如检索器就不支持,在原生的langchain中,当你给不支持stram的组件调用流接口时,一般不会有打字机效果,而是和使用invoke效果差不多。而当你使用LCEL去调用类似检索器组件的时候,它依然可以搞出来打字机效果,这也是为什么要尽量使用LCEL的原因。我们看个例子:
#安装依赖
pip install faiss-cpu
from langchain_community.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import OpenAIEmbeddingstemplate = """Answer the question based only on the following context:
{context}Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)vectorstore = FAISS.from_texts(["harrison worked at kensho", "harrison likes spicy food"],embedding=OpenAIEmbeddings(),
)
retriever = vectorstore.as_retriever()chunks = [chunk for chunk in retriever.stream("where did harrison work?")]
chunks
原生的检索器在这种情况下只会返回最终结果,并没有流的效果:
[[Document(page_content='harrison worked at kensho'),Document(page_content='harrison likes spicy food')]]
而使用LCEL调用后,则可以输出中间的过程:
retrieval_chain = ({"context": retriever.with_config(run_name="Docs"),"question": RunnablePassthrough(),}| prompt| model| StrOutputParser()
)for chunk in retrieval_chain.stream("Where did harrison work? " "Write 3 made up sentences about this place."
):print(chunk, end="|", flush=True)
- 全代码【智谱llM+百川词嵌入模型】
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.output_parsers import JsonOutputParser
from langchain_community.embeddings import BaichuanTextEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
import osos.environ["ZHIPUAI_API_KEY"] = "7c182nN"model = ChatZhipuAI(model="glm-4",temperature=0,streaming=True,
)template = """Answer the question based only on the following context:
{context}Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)embeddings=BaichuanTextEmbeddings(baichuan_api_key="sk-175510")vectorstore = FAISS.from_texts(["harrison worked at kensho", "harrison likes spicy food"],embedding=embeddings,
)
retriever = vectorstore.as_retriever()retrieval_chain = ({"context": retriever.with_config(run_name="Docs"),"question": RunnablePassthrough(),}| prompt| model| StrOutputParser()
)for chunk in retrieval_chain.stream("Where did harrison work? " "Write 3 made up sentences about this place."
):print(chunk, end="|", flush=True)H|arrison| worked| at| Kens|ho|,| a| cutting|-edge| technology| company| known| for| its| innovative| AI| solutions|.|
1|.| Kens|ho| is| renowned| for| its| vibrant| work| culture|,| where| employees| are| encouraged| to| think| outside| the| box| and| push| the| boundaries| of| technology|.
2|.| The| office| environment| at| Kens|ho| is| dynamic| and| fast|-paced|,| with| a| strong| emphasis| on| collaboration| and| continuous| learning|.
3|.| Kens|ho| is| located| in| a| state|-of|-the|-art| facility|,| boasting| impressive| amenities| and| a| sleek|,| modern| design| that| fost|ers| creativity| and| productivity|.||
4. v0.2的核心特性:流中的事件支持
如要使用该特性,你首先要确认自己的langchain_core版本等于0.2
import langchain_core
langchain_core.__version__
#'0.2.18'
官方给到了一些注意事项:
- 使用流要尽量使用异步方式编程。
- 如果你自定义了函数一定要配置callback。
- 不使用LCEL的话尽量使用.astram来访问LLM。
langchain将流的过程细化,并在每个阶段给了开发者一个事件钩子,每个阶段都可以获取输出结果:

4.1 在chatmodel中使用:
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.output_parsers import JsonOutputParser
import osos.environ["ZHIPUAI_API_KEY"] = "7epjHnN"model = ChatZhipuAI(model="glm-4",temperature=0,streaming=True,
)#异步方法
import asyncio
async def my_async_function():events = []async for event in model.astream_events("hello", version="v2"):events.append(event)print(events[:3])async def main():await my_async_function()#asyncio.run(main())
await main()注意:version=v2这个参数表明events事件流依然是一个beta API,后面肯定还有更改,所以商业应用要慎重!该参数只在 langchain-core>=0.2.0作用!
- 结果
[{'event': 'on_chat_model_start', 'data': {'input': 'hello'}, 'name': 'ChatZhipuAI', 'tags': [], 'run_id': 'c87b9c20-6dbf-41d3-989a-0b609c0b3fb4', 'metadata': {'ls_model_type': 'chat'}, 'parent_ids': []}, {'event': 'on_chat_model_stream', 'run_id': 'c87b9c20-6dbf-41d3-989a-0b609c0b3fb4', 'name': 'ChatZhipuAI', 'tags': [], 'metadata': {'ls_model_type': 'chat'}, 'data': {'chunk': AIMessageChunk(content='Hello', id='run-c87b9c20-6dbf-41d3-989a-0b609c0b3fb4')}, 'parent_ids': []}, {'event': 'on_chat_model_stream', 'run_id': 'c87b9c20-6dbf-41d3-989a-0b609c0b3fb4', 'name': 'ChatZhipuAI', 'tags': [], 'metadata': {'ls_model_type': 'chat'}, 'data': {'chunk': AIMessageChunk(content=' 👋!', id='run-c87b9c20-6dbf-41d3-989a-0b609c0b3fb4')}, 'parent_ids': []}]
4.2 在Chain中的使用:
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.output_parsers import JsonOutputParser
import osos.environ["ZHIPUAI_API_KEY"] = "7cjHnN"model = ChatZhipuAI(model="glm-4",temperature=0,streaming=True,
)#异步方法
import asyncioasync def my_async_function():chain = (model | JsonOutputParser())num_events = 0async for event in chain.astream_events("输出 JSON 格式的法国、西班牙和日本国家及其人口列表。 "'使用一个外键为 "countries "的 dict,其中包含一个国家列表。'"每个国家都应有 `name` 和 `population`键",version="v2",):#筛选eventkind = event["event"]if kind == "on_chat_model_stream":print(f"Chat model chunk: {repr(event['data']['chunk'].content)}",flush=True,)if kind == "on_parser_stream":print(f"Parser chunk: {event['data']['chunk']}", flush=True)num_events += 1if num_events > 30:# Truncate the outputprint("...")breakasync def main():await my_async_function()#asyncio.run(main())
await main()
Chat model chunk: '以下是'
Chat model chunk: '按照'
Chat model chunk: '您'
Chat model chunk: '的要求'
Chat model chunk: ','
Chat model chunk: '以'
Chat model chunk: ' JSON'
Chat model chunk: ' 格'
Chat model chunk: '式'
Chat model chunk: '表示'
Chat model chunk: '法国'
Chat model chunk: '、'
Chat model chunk: '西班牙'
Chat model chunk: '和'
Chat model chunk: '日本'
Chat model chunk: '国家'
Chat model chunk: '及其'
Chat model chunk: '人口'
Chat model chunk: '的一个'
Chat model chunk: '示例'
Chat model chunk: ':\n\n'
Chat model chunk: 'json'
Chat model chunk: '\n{\n '
Parser chunk: {}
Chat model chunk: ' "'
Chat model chunk: 'countries'
Chat model chunk: ':'
...
5.事件过滤
结合事件以及配置参数,可以很方便的找出你想要的阶段数据
通过定义名字实现事件的筛选,后续想要使用的块
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.output_parsers import JsonOutputParser
import osos.environ["ZHIPUAI_API_KEY"] = "key"model = ChatZhipuAI(model="glm-4",temperature=0,streaming=True,
)#异步方法
import asyncioasync def my_async_function():chain = model.with_config({"run_name": "model"}) | JsonOutputParser().with_config({"run_name": "my_parser"}
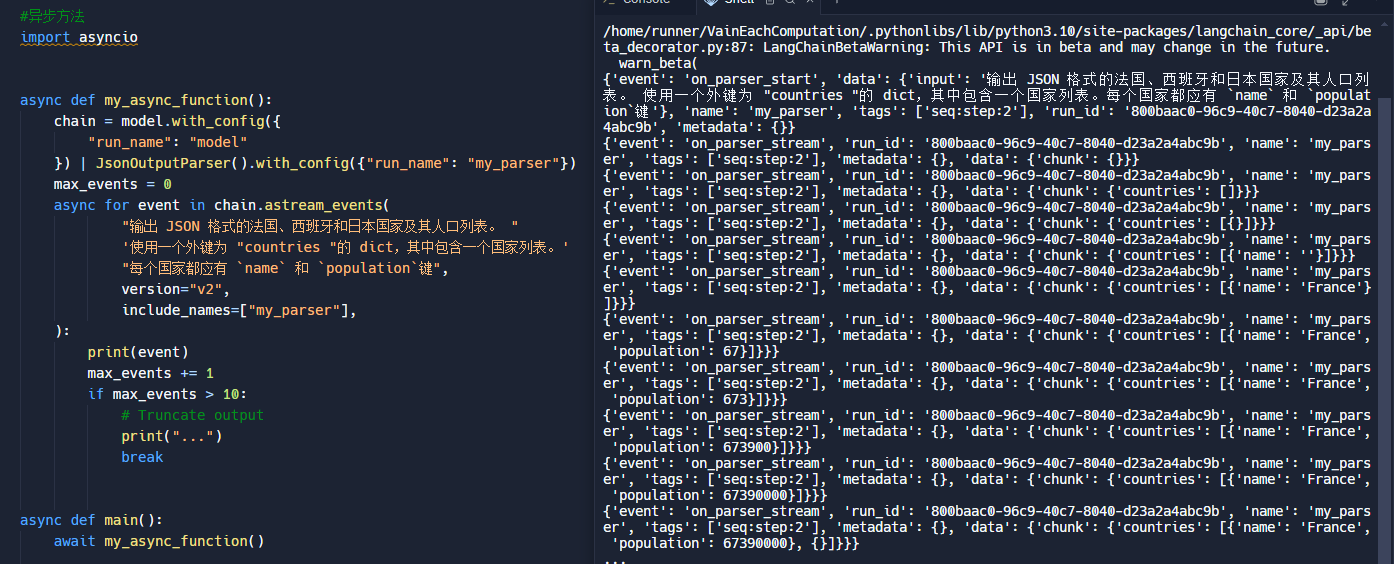
)num_events = 0async for event in chain.astream_events("输出 JSON 格式的法国、西班牙和日本国家及其人口列表。 "'使用一个外键为 "countries "的 dict,其中包含一个国家列表。'"每个国家都应有 `name` 和 `population`键",version="v2",include_names=["my_parser"],):print(event)max_events += 1if max_events > 10:# Truncate outputprint("...")breakasync def main():await my_async_function()asyncio.run(main())
6.回调传播
在工具中使用调用可运行项,则需要将回调传播到可运行项;否则,不会生成任何流事件。
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.output_parsers import JsonOutputParser
import osos.environ["ZHIPUAI_API_KEY"] = "key"model = ChatZhipuAI(model="glm-4",temperature=0,streaming=True,
)from langchain_core.runnables import RunnableLambda
from langchain_core.tools import tool#反转单词
def reverse_word(word: str):return word[::-1]reverse_word = RunnableLambda(reverse_word)@tool
def correct_tool(word: str, callbacks):"""A tool that correctly propagates callbacks."""return reverse_word.invoke(word, {"callbacks": callbacks})async for event in correct_tool.astream_events("hello", version="v2"):print(event)
{'event': 'on_tool_start', 'data': {'input': 'hello'}, 'name': 'correct_tool', 'tags': [], 'run_id': '97cd4122-e699-4a54-8370-699ed9e6cdb4', 'metadata': {}, 'parent_ids': []}
{'event': 'on_chain_start', 'data': {'input': 'hello'}, 'name': 'reverse_word', 'tags': [], 'run_id': '9e6635fe-879f-4b74-9c23-8de768b49a39', 'metadata': {}, 'parent_ids': ['97cd4122-e699-4a54-8370-699ed9e6cdb4']}
{'event': 'on_chain_end', 'data': {'output': 'olleh', 'input': 'hello'}, 'run_id': '9e6635fe-879f-4b74-9c23-8de768b49a39', 'name': 'reverse_word', 'tags': [], 'metadata': {}, 'parent_ids': ['97cd4122-e699-4a54-8370-699ed9e6cdb4']}
{'event': 'on_tool_end', 'data': {'output': 'olleh'}, 'run_id': '97cd4122-e699-4a54-8370-699ed9e6cdb4', 'name': 'correct_tool', 'tags': [], 'metadata': {}, 'parent_ids': []}
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。
相关文章:
Langchain[3]:Langchain架构演进与功能扩展:流式事件处理、事件过滤机制、回调传播策略及装饰器应用
Langchain[3]:Langchain架构演进与功能扩展:流式事件处理、事件过滤机制、回调传播策略及装饰器应用 1. Langchain的演变 v0.1: 初始版本,包含基本功能。 从0.1~0.2完成的特性: 通过事件流 API 提供更好的流式支持。标准化工具调用支持Tool…...

java导出PDF详细教程+各种踩坑
直接上代码了 所需依赖: <dependency><groupId>com.itextpdf</groupId><artifactId>itextpdf</artifactId><version>5.4.3</version> </dependency><dependency><groupId>com.itextpdf</groupId><art…...
【博士每天一篇文献-算法】连续学习算法之HNet:Continual learning with hypernetworks
阅读时间:2023-12-26 1 介绍 年份:2019 作者:Johannes von Oswald,Google Research;Christian Henning,EthonAI AG;Benjamin F. Grewe,苏黎世联邦理工学院神经信息学研究所 期刊&a…...

使用 tcpdump 进行网络流量捕获与分析
目录 安装 tcpdump基本用法捕获网络流量指定网络接口捕获特定主机的流量捕获特定端口的流量捕获特定协议的流量 常用选项保存捕获的数据包从文件读取数据包显示数据包内容指定捕获数据包的长度限制捕获的数据包数量显示详细信息过滤表达式 示例捕获本地回环接口上的HTTP流量捕获…...

k8s集群 安装配置 Prometheus+grafana
k8s集群 安装配置 Prometheusgrafana k8s环境如下:机器规划: node-exporter组件安装和配置安装node-exporter通过node-exporter采集数据显示192.168.40.180主机cpu的使用情况显示192.168.40.180主机负载使用情况 Prometheus server安装和配置创建sa账号&…...
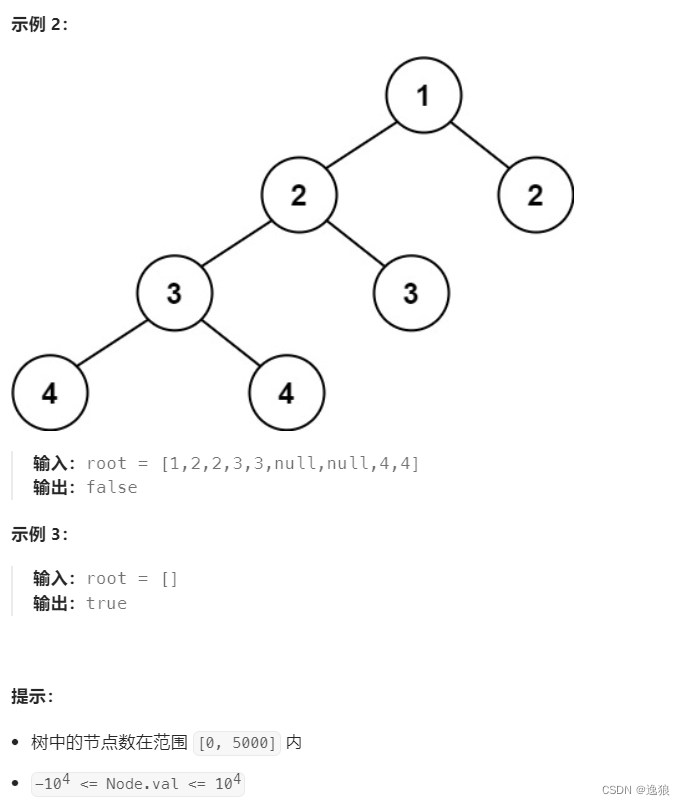
【Java--数据结构】二叉树oj题(上)
前言 欢迎关注个人主页:逸狼 创造不易,可以点点赞吗~ 如有错误,欢迎指出~ 判断是否是相同的树 oj链接 要判断树是否一样,要满足3个条件 根的 结构 和 值 一样左子树的结构和值一样右子树的结构和值一样 所以就可以总结以下思路…...

微服务之间Feign调用
需使用的服务 FeignClient(name "rdss-back-service", fallback SysUserServiceFallback.class, configuration FeignConfiguration.class) public interface SysUserService {/*** 订单下单用户模糊查询*/GetMapping(value "/user/getOrderUserName")…...
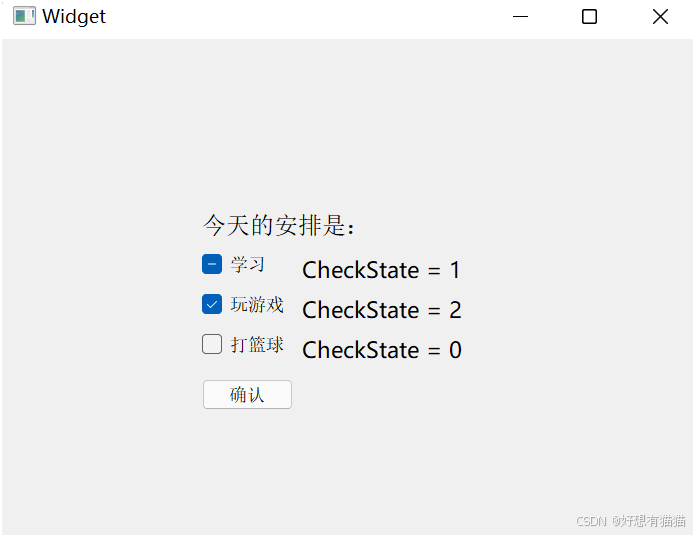
【Qt】按钮的属性相关API
目录 一. QPushButton 二. QRadioButton 按钮组 三. QCheckBox Qt中按钮的继承体系如下图 QAbstractButton是一个抽象类,集成了按钮的核心属性和API 按钮说明QPushButton(普通按钮)最常见的按钮,用于触发操作或者事件。可以设…...

blender和3dmax和maya和c4d比较
Blender、3ds Max、Maya和Cinema 4D (C4D)都是强大的3D建模和动画软件,但它们各有特点和适用领域。以下是它们的比较: Blender: 开源免费全面的功能,包括建模、动画、渲染、视频编辑等学习曲线较陡峭,但社区支持强大适合独立艺术家…...

visio保存一部分图/emf图片打开很模糊/emf插入到word或ppt中很模糊
本文主要解决三个问题 visio保存一部分图 需求描述:在一个visio文件中画了很多个图,但我只想把其中一部分保存成某种图片格式,比如jpg emf png之类的,以便做后续的处理。 方法:超级容易。 选中希望保存的这部分图&…...
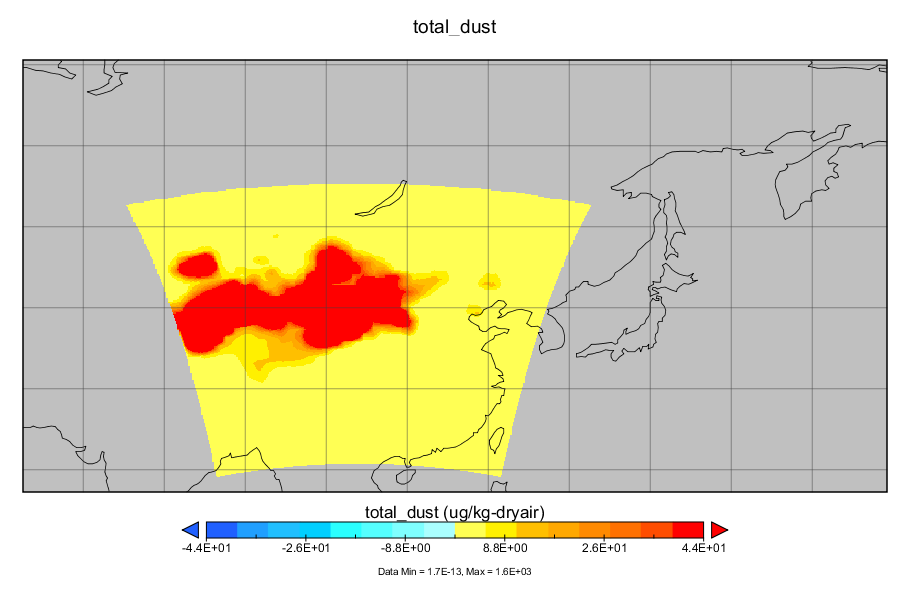
沙尘传输模拟教程(基于wrf-chem)
沙尘传输模拟教程(基于wrf-chem) 文章目录 沙尘传输模拟教程(基于wrf-chem)简介实验目的wrf-chem简介 软件准备wps、wrf-chem安装conda安装ncl安装ncap安装 数据准备气象数据准备下垫面数据准备 WPS数据预处理namelist.wps的设置geogrid.exe下垫面处理ungrib.exe气象数据预处理…...
纯净测试)
使用 Python 进行测试(8)纯净测试
原文:Testing with Python (part 8): purity test 总结 如果你要使用综合测试(integrated tests): def test_add_new_item_to_cart(product, cart):new_product Product.objects.create(nameNew Product, price15.00)new_cart…...
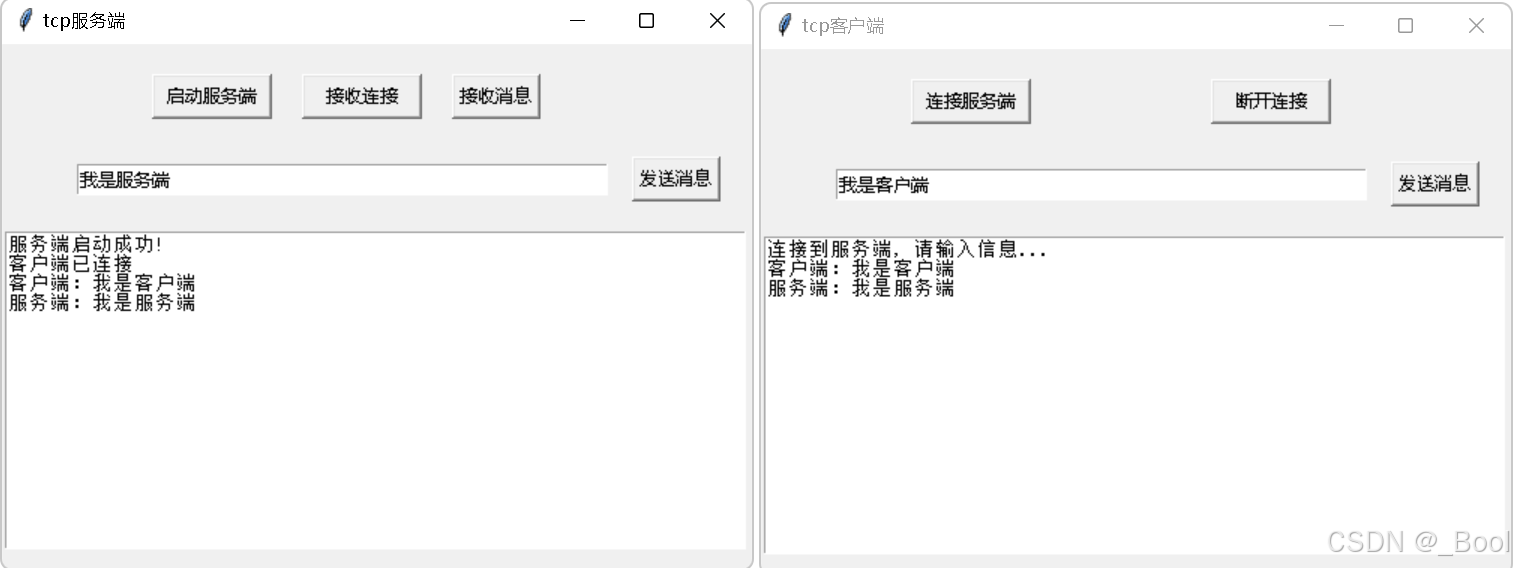
python的tkinter、socket库开发tcp的客户端和服务端
一、tcp通讯流程和开发步骤 1、tcp客户端和服务端通讯流程图 套接字是通讯的利器,连接时要经过三次握手建立连接,断开连接要经过四次挥手断开连接。 2、客户端开发流程 1)创建客户端套接字 2)和服务端器端套接字建立连接 3&#x…...

Python面试题:Python中的异步编程:详细讲解asyncio库的使用
Python 的异步编程是实现高效并发处理的一种方法,它使得程序能够在等待 I/O 操作时继续执行其他任务。在 Python 中,asyncio 库是实现异步编程的主要工具。asyncio 提供了一种机制来编写可以在单线程内并发执行的代码,适用于 I/O 密集型任务。…...
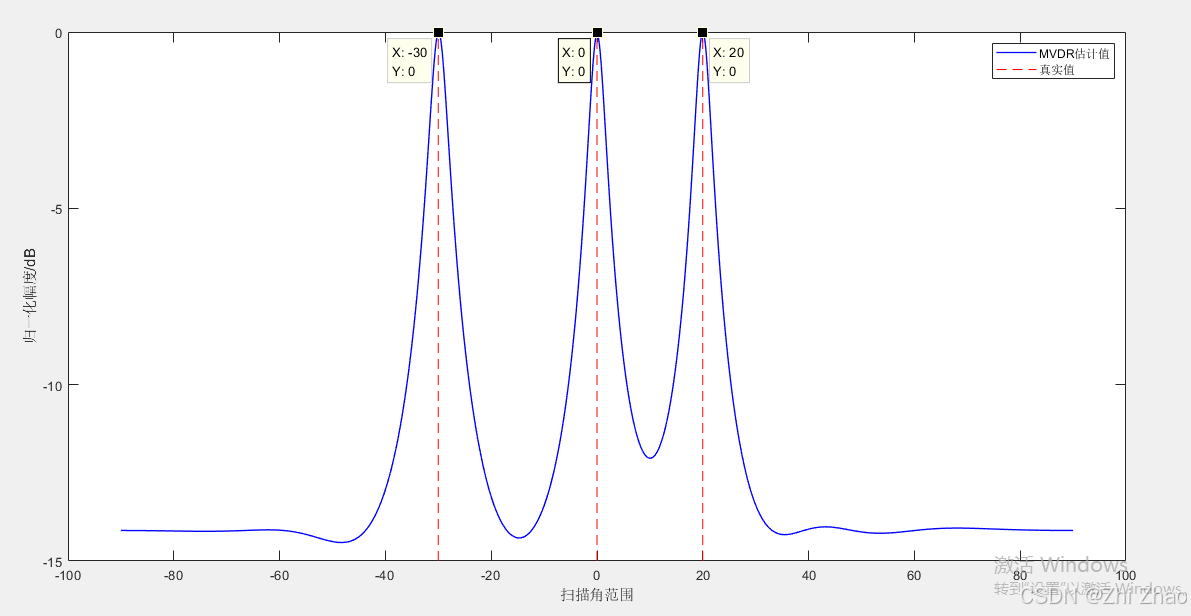
【信号频率估计】MVDR算法及MATLAB仿真
目录 一、MVDR算法1.1 简介1.2 原理1.3 特点1.3.1 优点1.3.2 缺点 二、算法应用实例2.1 信号的频率估计2.2 MATLAB仿真代码 三、参考文献 一、MVDR算法 1.1 简介 最小方差无失真响应(Mininum Variance Distortionless Response,MVDR)算法最…...
HarmonyOS NEXT零基础入门到实战-第二部分
HarmonyOS NEXT零基础入门到实战-第二部分 Swiper 轮播组件 Swiper是一个 容器 组件,当设置了多个子组件后,可以对这些 子组件 进行轮播显示。(文字、图片...) 1、Swiper基本语法 2、Swiper常见属性 3、Swiper样式自定义 4、案例&…...
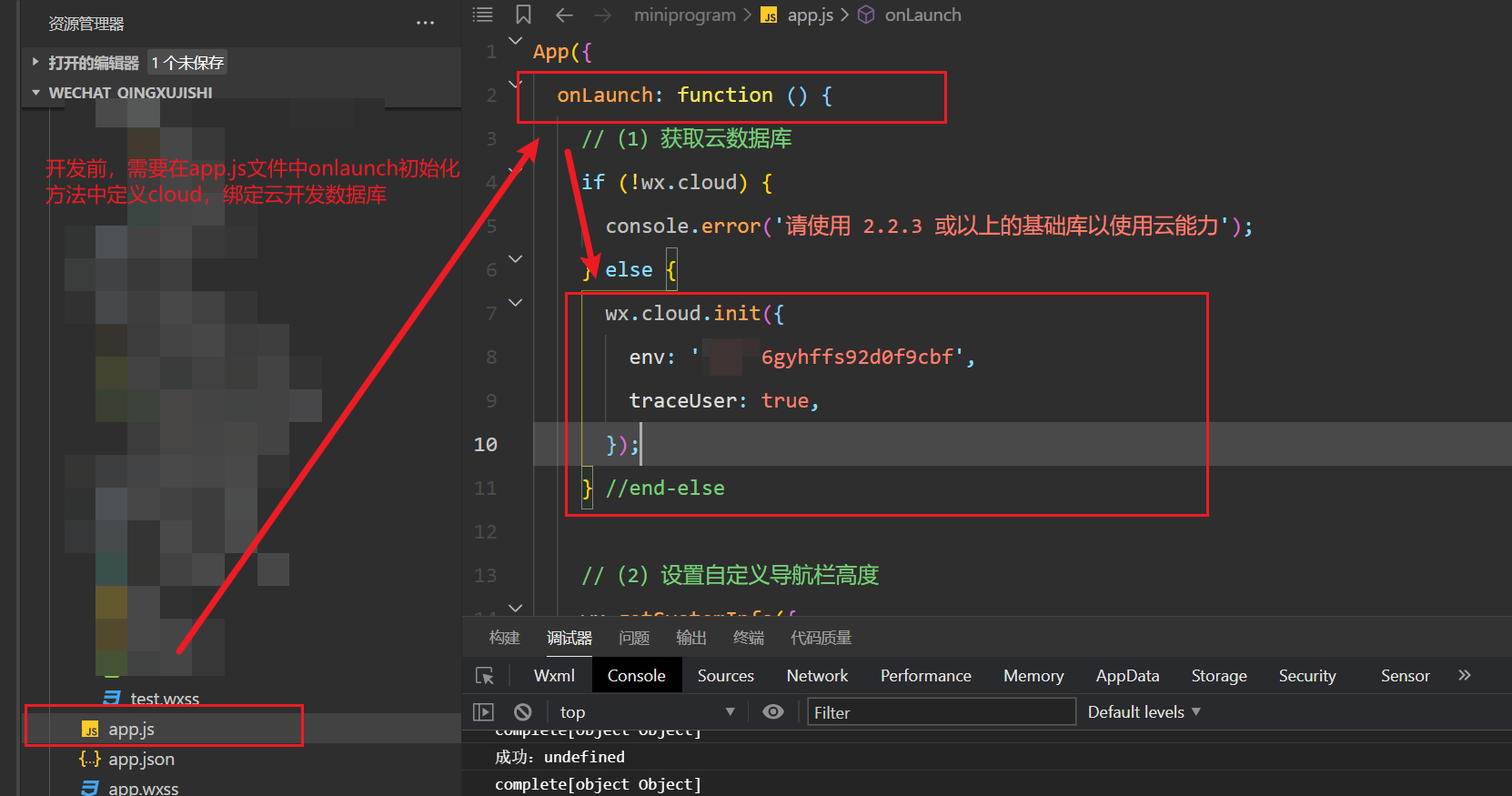
《小程序02:云开发之增删改查》
一、前置操作 // 一定要用这个符号包含里面的${}才会生效 wx.showToast({title: 获取数据成功:${colorLista}, })1.1:初始化介绍 **1、获取数据库引用:**在开始使用数据库 API 进行增删改查操作之前,需要先获取数据库的引用 cons…...
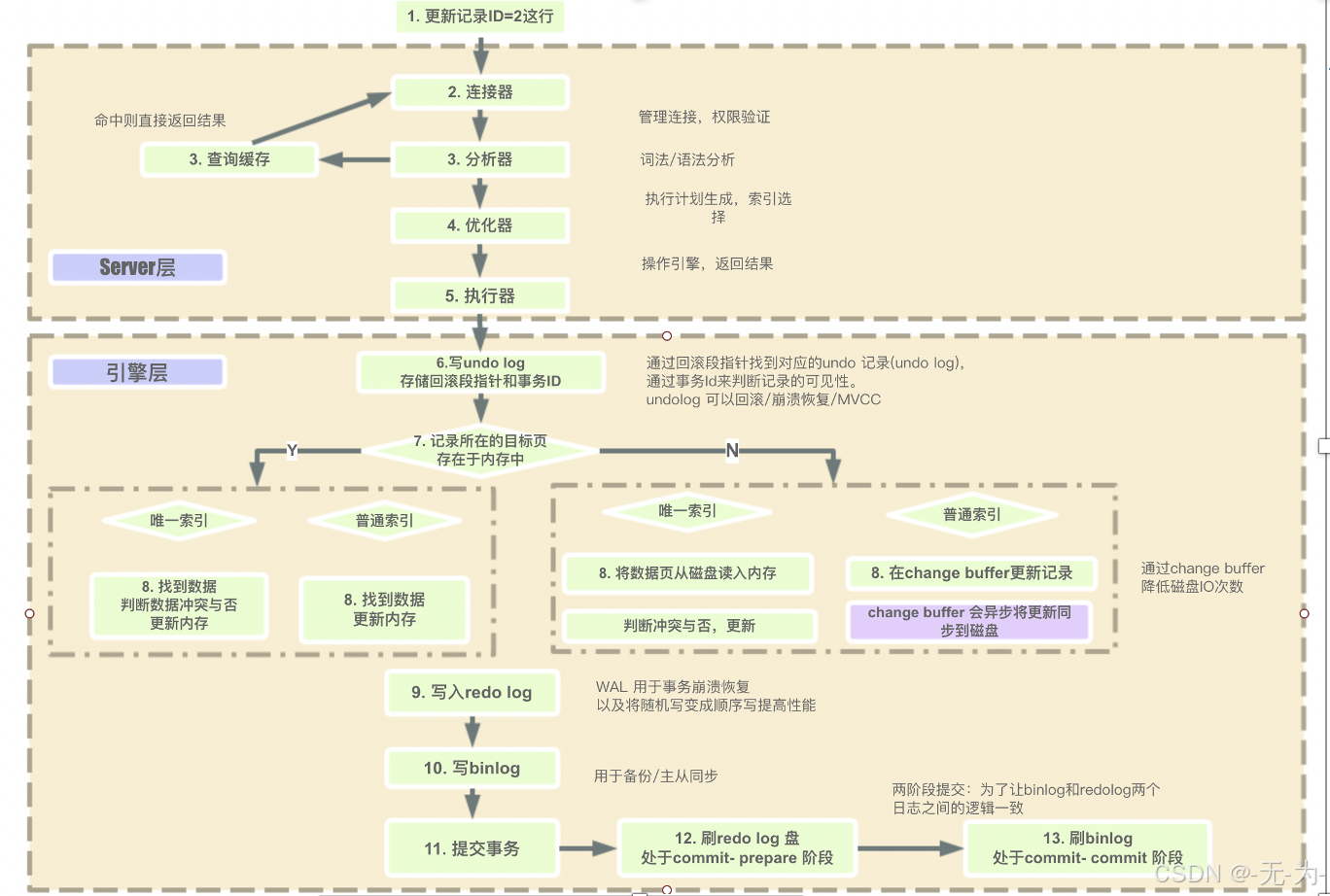
SQL执行流程、SQL执行计划、SQL优化
select查询语句 select查询语句中join连接是如何工作的? 1、INNER JOIN 返回两个表中的匹配行。 2、LEFT JOIN 返回左表中的所有记录以及右表中的匹配记录。 3、RIGHT JOIN 返回右表中的所有记录以及左表中的匹配记录。 4、FULL OUTER JOIN 返回左侧或右侧表中有匹…...

【前端】JavaScript入门及实战41-45
文章目录 41 嵌套的for循环42 for循环嵌套练习(1)43 for循环嵌套练习(2)44 break和continue45 质数练习补充 41 嵌套的for循环 <!DOCTYPE html> <html> <head> <title></title> <meta charset "utf-8"> <script type"…...
更加深入Mysql-04-MySQL 多表查询与事务的操作
文章目录 多表查询内连接隐式内连接显示内连接 外连接左外连接右外连接 子查询 事务事务隔离级别 多表查询 有时我们不仅需要一个表的数据,数据可能关联到俩个表或者三个表,这时我们就要进行夺标查询了。 数据准备: 创建一个部门表并且插入…...

从电机控制到呼吸灯:用STM32CubeMX玩转TIM高级定时器的互补PWM与死区时间配置
从电机控制到呼吸灯:用STM32CubeMX玩转TIM高级定时器的互补PWM与死区时间配置 在嵌入式开发中,定时器是最基础也最强大的外设之一。对于STM32开发者来说,掌握高级定时器的互补PWM输出和死区时间配置,意味着可以解锁从电机控制到LE…...

订阅Token Plan套餐后在长期项目中的成本节约效果分析
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 订阅Token Plan套餐后在长期项目中的成本节约效果分析 对于需要持续、稳定调用大模型的个人开发者或团队而言,成本控制…...

对比体验Taotoken平台不同大模型在创意生成上的差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比体验Taotoken平台不同大模型在创意生成上的差异 对于内容创作者而言,大模型是激发灵感、提升效率的得力工具。然而…...

在旧版iOS设备上部署ChatGPT客户端:逆向工程与兼容性实战
1. 项目概述:为旧版iOS设备注入AI灵魂 如果你手头还保留着一台运行iOS 6或7的iPhone 4s、iPad 2,或者任何被时代“遗忘”的旧设备,看着它们除了怀念似乎别无他用,那么今天分享的这个项目,或许能让它们重获新生。我最近…...

从Packet Tracer到EVE-NG:网络小白进阶实战,手把手教你用VMware部署第一个思科拓扑
从Packet Tracer到EVE-NG:网络工程师的虚拟化进阶指南 当你已经能够熟练使用Cisco Packet Tracer完成CCNA级别的实验,却发现这个教学工具无法满足你对真实网络环境模拟的渴望时,是时候考虑升级你的网络实验平台了。EVE-NG作为当前最强大的网…...

从数据模型到领域驱动设计:数据库抽象与微服务实践的演进
在软件开发的漫长历史中,如何有效地对现实世界进行建模,始终是核心挑战之一。从早期的层次数据库到当今的微服务架构,数据模型作为连接业务需求与技术实现的桥梁,经历了深刻的演变。本文基于对概念数据模型、基本数据模型和面向对象模型的系统探讨,进一步延伸到领域驱动设…...

高效自动化安装:Windows平台ADB与Fastboot驱动完整配置指南
高效自动化安装:Windows平台ADB与Fastboot驱动完整配置指南 【免费下载链接】Latest-adb-fastboot-installer-for-windows A Simple Android Driver installer tool for windows (Always installs the latest version) 项目地址: https://gitcode.com/gh_mirrors/…...

构建多模型对比评测工具时集成Taotoken的统一接口
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 构建多模型对比评测工具时集成Taotoken的统一接口 在模型选型、效果验证或学术研究过程中,开发者或研究者常常需要并行…...

跨越版本鸿沟:Matlab 2020b与VS2022混合编译环境搭建实战
1. 环境准备:当Matlab 2020b遇上VS2022 第一次尝试在Matlab 2020b里调用VS2022编译器时,命令行弹出的红色报错让我愣了半天。官方文档明确写着Matlab 2020b最高只支持VS2019,这就像让Windows XP运行最新版Photoshop——理论上不可能ÿ…...

Audacity音频编辑教程:免费开源音频处理软件的完整使用指南
Audacity音频编辑教程:免费开源音频处理软件的完整使用指南 【免费下载链接】audacity Audio Editor 项目地址: https://gitcode.com/GitHub_Trending/au/audacity Audacity是一款功能强大的免费开源音频编辑软件,支持录音、剪辑、混音和音频效果…...