ELK日志分析系统部署文档
一、ELK说明
ELK是Elasticsearch(ES) + Logstash + Kibana 这三个开源工具组成,官方网站: The Elastic Search AI Platform — Drive real-time insights | Elastic
简单的ELK架构

ES: 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。
Kibana: 可以对 Elasticsearch 进行可视化,还可以在 Elastic Stack 中进行导航,这样便可以进行各种操作了,从跟踪查询负载,到理解请求如何流经您的整个应用,都能轻松完成。
Logstash: 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中。一般用在日志的搜集、分析、过滤,支持大量的数据获取方式。
Filebeat:收集文件数据。
二、基础环境
1. 准备以下几台机器:
| 主机 | 服务器角色 | 主机系统 | 软件版本 |
| es-node1 | Elasticsearch(搜索引擎) | Centos7 | Elasticsearch:7.15.5 |
| es-node2 | Elasticsearch(搜索引擎) | Centos7 | Elasticsearch:7.15.5 |
| es-node3 | Elasticsearch(搜索引擎) | Centos7 | Elasticsearch:7.15.5 |
| kibana | Kibana(界面展示) | Centos7 | Kibana:7.15.5 |
| logstash | Logstash(日志处理) | Centos7 | Logstash:7.15.5 |
| filebeat | Filebeat(日志收集) | Centos7 | Filebeat:7.15.5 |
2. 关闭selinux
3.主机之间同步时间
三、Elasticsearch集群部署
3.1 前提准备
3.1.1 安装包下载
https://www.elastic.co/cn/downloads/past-releases#elasticsearch 进行下载相应的产品版本,点击“Download”后选择需要的方式包进行下载,本文以linux 二进制方式进行部署

3.1.2 创建用户及授权(注:每个节点都需要操作)
ElasticSerach要求以非root身份启动,在每个节点创建用户及用户组
| 1 2 |
|
解压安装包并附所属权
tar -xvzf elasticsearch-7.17.5-linux-x86_64.tar.gz -C /home/elasticsearch

chown -R elasticsearch:elasticsearch /home/elasticsearch/elasticsearch-7.17.5

在每个节点上创建数据data和logs目录:
| 1 2 |
|

3.1.3 java环境
配置环境变量
|
|
使环境变量生效并验证
| 1 2 |
|
3.1.4 内存不能锁定问题(可选)
| 1 2 3 4 |
|
注:需要重启机器
3.1.5 修改vm.max_map_count

修改一个进程可以拥有的VMA(虚拟内存区域)的数量
vim /etc/sysctl.conf 调整:
vm.max_map_count=262144
执行:sysctl -p 生效


3.2 配置
3.2.1 修改elasticsearch配置文件
配置elasticsearch.yml文件说明:
node.name: node-1 #每个节点不一样#节点是否具有成为主节点的资格
node.master: true#节点是否存储数据
node.data: true#ES 数据保存目录
path.data: /data/elasticsearch/data#ES 日志保存目
path.logs: /data/elasticsearch/logs#服务启动的时候锁定足够的内存,防止数据写入
swapbootstrap.memory_lock: true#监听
IPnetwork.host: 0.0.0.0#监听端口
http.port: 9200#集群中 node 节点发现列表
discovery.seed_hosts: ["10.10.100.110", "10.10.100.111","10.10.100.112"]#集群初始化那些节点可以被选举为
mastercluster.initial_master_nodes: ["10.10.100.110", "10.10.100.111","10.10.100.112"]#一个集群中的 N 个节点启动后,才允许进行数据恢复处理,默认是 1
gateway.recover_after_nodes: 2####设置是否可以通过正则或者_all 删除或者关闭索引库,
####默认 true 表示必须需要显式指定索引库名称,
####生产环境建议设置为 true,
####删除索引库的时候必须指定,否则可能会误删索引库中的索引库。
action.destructive_requires_name: true
node1节点
| 1 |
|

node2节点
grep -Ev "^$|^[#;]" elasticsearch.yml

node3节点
| 1 |
|

3.2.2 修改JVM内存限制
| 1 2 3 4 |
|
3.2.3 开启跨域访问支持(可选)
| 1 2 3 4 5 |
|

3.3 启动并验证
| 1 2 3 |
|

|
|

浏览器访问查看:
查看集群健康状态:http://IP:9200/_cluster/health?pretty

查看集群详细信息:http://IP:9200/_cluster/state?pretty
查看索引列表:http://IP:9200/_cat/indices?v
四、Kibana部署
本文复用ES的一台机器进行部署,实际环境可以单独部署一台。
4.1 前提准备
4.1.1 安装包下载
在https://www.elastic.co/cn/downloads/past-releases#kibana 进行下载相应的软件版本

4.1.2 创建用户及授权
| 1 2 |
|

4.1.3 解压安装包并附所属权
| 1 |
|

|
|

4.1.4 创建日志目录并附所属权
| 1 2 |
|

4.2 配置
| 1 |
|

4.3 启动并验证
使用kibana账号启动
4.3.1 启动
| 1 2 |
|

|
|
4.3.2 验证
| 1 2 |
|

浏览器验证:http:IP:5601

五、Logstash部署
5.1 准备
5.1.1 安装包下载
通过官网下载链接: https://www.elastic.co/cn/downloads/past-releases#logstash 选择对应的版本

5.1.2 创建数据和日志目录
| 1 |
|

5.2 配置
5.2.1 修改logstash配置文件(可以不修改)
| 1 |
|

5.2.2 创建监控日志的配置文件
Logstash可以直接采集日志文件;本文采用filebeat收集日志,logstash处理日志
input {beats {port => 5044codec => plain{ charset => "GB2312" }}
}
filter{grok {match => { "message" => "%{TIMESTAMP_ISO8601:logdate}" }}date {match => [ "logdate","ISO8601"]target => "@timestamp"}mutate{remove_field => "logdate"}
}
output {elasticsearch {hosts => ["10.211.55.5:9200"] # 定义es服务器的ipindex => "emqx-%{+YYYY.MM.dd}" # 定义索引}
}|
|

5.3 启动
## 默认端口:9600,执行命令后需要等一会儿启动成功。
./bin/logstash -f config/logstash.conf &

5.4 验证

六、Filebeat部署
6.1准备
官网下载安装包链接:https://www.elastic.co/cn/downloads/past-releases#filebeat ,选择对应版本

6.2 配置
filebeat安装后,只需要配置好监控的日志。包含input和output 等。
filebeat.inputs:
# 第一个输入
- type: log
#是否启用enabled: true# 自定义标签tags: ["qgzhdc-px-data-node"]# 收集日志的文件路径,可以使用通配附*等paths:- /home/bagpipes/emqx/log/emqx.log.*- /home/bagpipes/emqx/log/abc.*.txtencoding: GB2312####fields 自定义字段与值,这个在检索日志时使用,###会给每条日志增加此key与value,能够标识出日志来源。fields:ip: 10.211.55.5# fields_under_root如果为false,则fields下的key会挂到fields下,true的话fields_under_root: truemultiline:type: patternpattern: '^\d{4}-\d{1,2}-\d{1,2}T\d{1,2}:\d{1,2}:\d{1,2}.\d{6}\+\d{1,2}:\d{1,2}'negate: truematch: after
output.logstash:hosts: ["10.211.55.5:5044"]
6.3 启动
| 1 2 |
|
6.4 验证
进程启动验证:

七、完整应用验证
首先所有服务都正常启动。
7.1 Filebeat验证
如何通过filebeat数据正常处理完成并输出符合预期的内容,可以采用输出到控制台进行调试验证,在filebeat.yml配置文件中调整输出为控制台方式:

7.2 Logstash验证
如何通过logstash数据正常处理完成并输出符合预期的内容,可以采用输出到控制台进行调试验证,在logstash.conf 配置文件中调整输出为控制台方式:

7.3 ES验证
通过地址api查看是否有相应的索引自动创建并占用存储:http://IP:9200/_cat/indices?v

7.4 Kibana验证
7.4.1 创建索引模版
按照截图中,进入management 中,选择“stack management”


7.4.2 查看索引
点击“Discover”

进入日志查询界面


相关文章:
ELK日志分析系统部署文档
一、ELK说明 ELK是Elasticsearch(ES) Logstash Kibana 这三个开源工具组成,官方网站: The Elastic Search AI Platform — Drive real-time insights | Elastic 简单的ELK架构 ES: 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它…...

ue5笔记
1 点光源 聚光源 矩形光源 参数比较好理解 (窗口里面)环境光混合器:快速创造关于环境光的组件 大气光源:太阳光,定向光源 天空大气:蓝色的天空和大气 高度雾:大气下面的高度感的雾气 体积…...

TCP重传机制详解
1.什么是TCP重传机制 在 TCP 中,当发送端的数据到达接收主机时,接收端主机会返回⼀个确认应答消息,表示已收到消息。 但是如果传输的过程中,数据包丢失了,就会使⽤重传机制来解决。TCP的重传机制是为了保证数据传输的…...

如何使用javascript将商品添加到购物车?
使用JavaScript将商品添加到购物车可以通过以下步骤实现: 创建一个购物车对象,可以是一个数组或者对象,用于存储添加的商品信息。在网页中的商品列表或详情页面,为每个商品添加一个“添加到购物车”的按钮,并为按钮绑…...

【MySQL】:想学好数据库,不知道这些还想咋学
客户端—服务器 客户端是一个“客户端—服务器”结构的程序 C(client)—S(server) 客户端和服务器是两个独立的程序,这两个程序之间通过“网络”进行通信(相当于是两种角色) 客户端 主动发起网…...

1.关于linux的命令
1.关于文件安装的问题 镜像站点服务器:cat /etc/apt/sources.list 索引文件:cd /var/lib/apt/lists 下载文件包存在的路径:cd /etc/cache/apt/archives/2.关于dpkg文件安装管理器的应用: 安装文件:sudo dpkg -i 文件名; 查找文件目录:sudo …...

【人工智能】机器学习 -- 决策树(乳腺肿瘤数)
目录 一、使用Python开发工具,运行对iris数据进行分类的例子程序dtree.py,熟悉sklearn机器实习开源库。 二、登录https://archive-beta.ics.uci.edu/ 三、使用sklearn机器学习开源库,使用决策树对breast-cancer-wisconsin.data进行分类。 …...
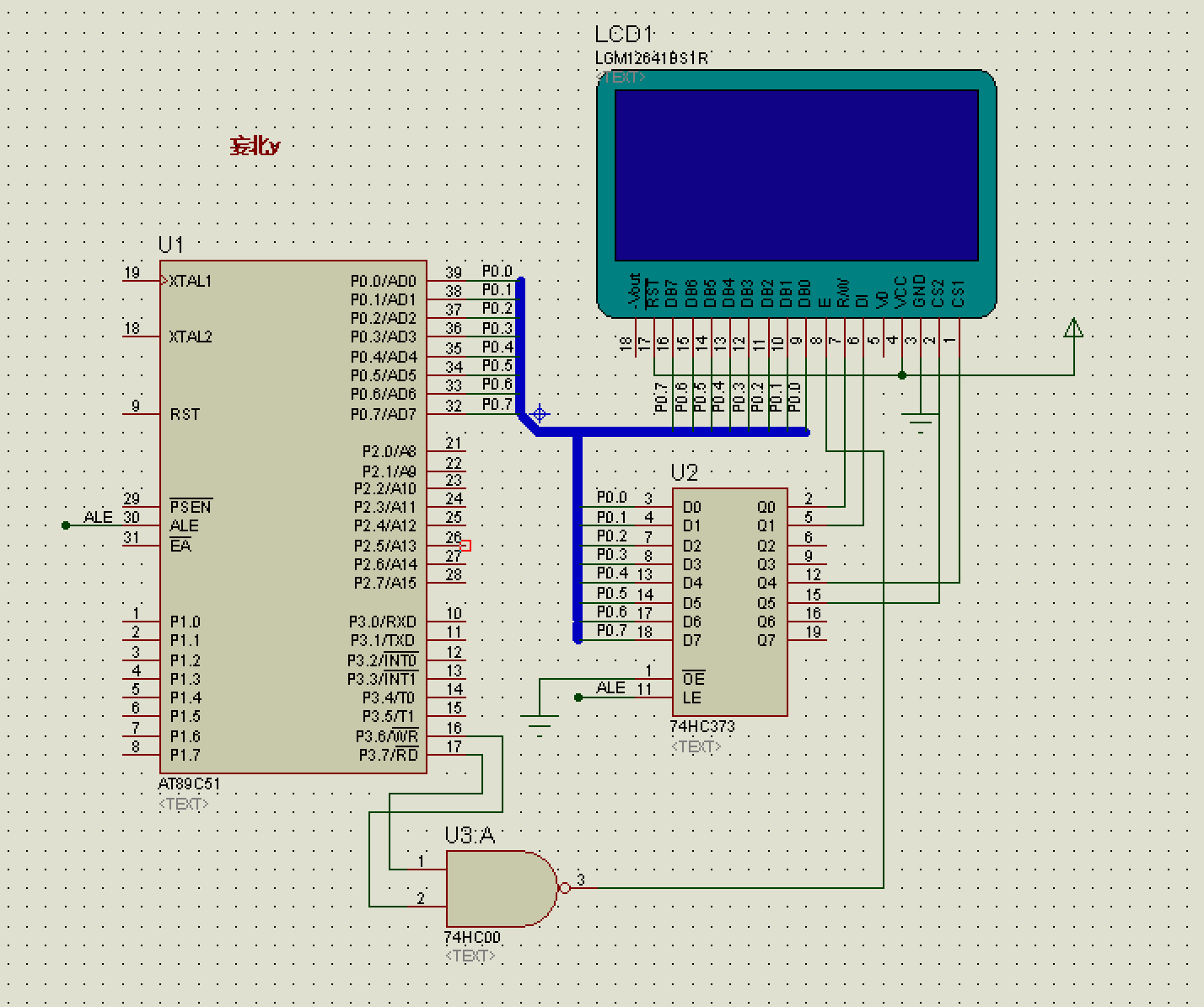
【proteus经典实战】LCD滚动显示汉字
一、简介 Proteus是一款功能丰富的电子设计和仿真软件,它允许用户设计电路图、进行PCB布局,并在虚拟环境中测试电路功能。这款软件广泛应用于教育和产品原型设计,特别适合于快速原型制作和电路设计教育。Proteus的3D可视化功能使得设计更加直…...

数据结构复习1
1、什么是集合? 就是一组数据的集合体,就像篮子装着苹果、香蕉等等,这些“水果”就代表数据,“篮子”就是这个集合。 集合的特点: 集合用于存储对象。 对象是确定的个数可以用数组,如果不确定可以用集合…...

订单管理系统需求规范
1. 引言 1.1 目的 本文档旨在明确描述订单管理系统的功能、非功能性需求以及约束条件,以指导系统的分析、设计、开发、测试和部署。 1.2 范围 本系统将支持在线订单处理,从客户下单到完成配送的全过程管理,包括库存管理、支付处理、订单跟…...

swiftui使用ScrollView实现左右滑动和上下滑动的效果,仿小红书页面
实现的效果如果所示,顶部的关注用户列表可以左右滑动,中间的内容区域是可以上下滚动的效果,点击顶部的toolbar也可以切换关注/发现/附近不同页面,实现翻页效果。 首页布局 这里使用了NavigationStack组件和tabViewStyle样式配置…...

深入理解并使用 MySQL 的 SUBSTRING_INDEX 函数
引言 在处理字符串数据时,经常需要根据特定的分隔符来分割字符串或提取字符串的特定部分。MySQL 提供了一个非常有用的函数 SUBSTRING_INDEX 来简化这类操作。本文将详细介绍 SUBSTRING_INDEX 的使用方法、语法,以及通过实际案例来展示其在数据库查询中…...

elementUI在手机端使用遇到的问题总结
之前的博客有写过用vue2elementUI封装手机端选择器picker组件,支持单选、多选、远程搜索多选,最终真机调试的时候发现有很多细节样式需要调整。此篇博客记录下我调试过程中遇到的问题和解决方法。 一、手机真机怎么连电脑本地代码调试? 1.确…...

【初阶数据结构】5.栈和队列
文章目录 1.栈1.1 概念与结构1.2 栈的实现2.队列2.1 概念与结构2.2 队列的实现3.栈和队列算法题3.1 有效的括号3.2 用队列实现栈3.3 用栈实现队列3.4 设计循环队列 1.栈 1.1 概念与结构 栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操…...

高通Android 12 设置Global属性为null问题
1、最近在做app调用framework.jar需求,尝试在frameworks/base/packages/SettingsProvider/res/values/defaults.xml增加属性 <integer name"def_xxxxx">1</integer> 2、在frameworks\base\packages\SettingsProvider\src\com\android\provide…...

Xcode代码静态分析:构建无缺陷代码的秘诀
Xcode代码静态分析:构建无缺陷代码的秘诀 在软件开发过程中,代码质量是至关重要的。Xcode作为Apple的官方集成开发环境(IDE),提供了强大的代码静态分析工具,帮助开发者在编写代码时发现潜在的错误和问题。…...

Qt各个版本安装的保姆级教程
文章目录 前言Qt简介下载Qt安装包安装Qt找到Qt的快捷方式总结 前言 Qt是一款跨平台的C图形用户界面应用程序开发框架,广泛应用于桌面软件、嵌入式软件、移动应用等领域。Qt的强大之处在于其高度的模块化和丰富的工具集,可以帮助开发者快速、高效地构建出…...

数学建模--优劣解距离法TOPSIS
目录 简介 TOPSIS法的基本步骤 延伸 优劣解距离法(TOPSIS)的历史发展和应用领域有哪些? 历史发展 应用领域 如何准确计算TOPSIS中的理想解(PIS)和负理想解(NIS)? TOPSIS方法在…...
 -- EasyPoi 简介)
Springboot开发之 Excel 处理工具(三) -- EasyPoi 简介
引言 Springboot开发之 Excel 处理工具(一) – Apache POISpringboot开发之 Excel 处理工具(二)-- Easyexcel EasyPoi是一款基于 Apache POI 的高效 Java 工具库,专为简化 Excel 和 Word 文档的操作而设计。以下是对…...

【BUG】已解决:python setup.py bdist_wheel did not run successfully.
已解决:python setup.py bdist_wheel did not run successfully. 目录 已解决:python setup.py bdist_wheel did not run successfully. 【常见模块错误】 解决办法: 欢迎来到英杰社区https://bbs.csdn.net/topics/617804998 欢迎来到我的主…...

别再只盯着KNN了:聊聊Wi-Fi指纹定位中那些被低估的匹配算法与实战选择
超越KNN:Wi-Fi指纹定位中的高阶匹配算法与工程化选型指南 商场里找不到心仪店铺的焦虑、仓库中耗时的手动货品盘点、医院里紧急设备定位的延迟——这些场景背后都指向同一个技术痛点:室内定位精度不足。当大多数开发者习惯性采用KNN算法时,我…...

Qwen3.5-4B-Claude-Opus部署教程:模型路径软链失效时的容错加载机制
Qwen3.5-4B-Claude-Opus部署教程:模型路径软链失效时的容错加载机制 1. 模型概述 Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF是基于Qwen3.5-4B的推理蒸馏模型,特别强化了结构化分析、分步骤回答以及代码与逻辑类问题的处理能力。该版本以GG…...

QobuzDownloaderX-MOD:一站式高品质音乐下载解决方案
QobuzDownloaderX-MOD:一站式高品质音乐下载解决方案 【免费下载链接】QobuzDownloaderX-MOD Downloads streams directly from Qobuz. Experimental refactoring of QobuzDownloaderX by AiiR 项目地址: https://gitcode.com/gh_mirrors/qo/QobuzDownloaderX-MOD…...

计算机毕设 java 基于 Android 的医疗预约系统的设计与实现 SpringBoot 安卓智能医疗预约挂号平台 JavaAndroid 医患预约诊疗管理系统
计算机毕设 java 基于 Android 的医疗预约系统的设计与实现 53m069,末尾的数字和英文也要加上 (配套有源码 程序 mysql 数据库 论文)本套源码可以先看具体功能演示视频领取,文末有联 xi 可分享随着信息技术的飞速发展和医疗需求的…...

VAP:腾讯开源的高性能动画播放引擎,如何让你的应用动起来更流畅?
VAP:腾讯开源的高性能动画播放引擎,如何让你的应用动起来更流畅? 【免费下载链接】vap VAP是企鹅电竞开发,用于播放特效动画的实现方案。具有高压缩率、硬件解码等优点。同时支持 iOS,Android,Web 平台。 项目地址: https://git…...
translategemma-27b-it入门必看:Gemma3轻量化设计如何平衡精度与推理速度
translategemma-27b-it入门必看:Gemma3轻量化设计如何平衡精度与推理速度 本文深度解析基于Gemma 3构建的TranslateGemma-27B-IT模型,通过实际部署演示展示其如何在保持翻译精度的同时实现高效推理,为开发者提供完整的入门指南。 1. 认识Tran…...

Leather Dress Collection惊艳效果:Leather_Romper皮连体衣+户外场景自然光渲染
Leather Dress Collection惊艳效果:Leather_Romper皮连体衣户外场景自然光渲染 1. 项目介绍 Leather Dress Collection 是一个基于Stable Diffusion 1.5的LoRA模型集合,专门用于生成各种皮革服装风格的图像。这个系列由Stable Yogi开发,包含…...
)
深度学习 三次浪潮、三大驱动力与神经科学的恩怨(二)
1. 一个领域,多个名字 很多人以为"深度学习"是一个全新的领域。事实上,它的历史可以追溯到 20 世纪 40 年代——只不过在不同时期,它被叫过完全不同的名字: 1940s-1960s:被称为控制论(Cybernetic…...

用DolphinScheduler实现数仓自动化:从零搭建ETL工作流实战
用DolphinScheduler构建电商数仓ETL流水线:实战设计与优化指南 电商平台每天产生的TB级订单数据,如何转化为精准的用户画像和实时销售报表?本文将带你从零搭建一个基于DolphinScheduler的自动化数据处理流水线,解决实际业务场景中…...

uniapp圆环进度条组件实战:从零到一打造个性化数据展示
Uniapp圆环进度条组件实战:从零到一打造个性化数据展示 在移动应用开发中,数据可视化是提升用户体验的关键因素之一。圆环进度条作为一种直观的数据展示方式,广泛应用于健身追踪、学习进度、任务完成度等场景。Uniapp作为跨平台开发框架&…...