因果推断 | 双重机器学习(DML)算法原理和实例应用
文章目录
- 1 引言
- 2 DML算法原理
- 2.1 问题阐述
- 2.2 DML算法
- 3 DML代码实现
- 3.1 策略变量为0/1变量
- 3.2 策略变量为连续变量
- 4 总结
- 5 相关阅读
1 引言
小伙伴们,好久不见呀。
距离上次更新已经过去了一个半月,上次发文章时还信誓旦旦地表达自己后续目标是3周更新一篇文章,然后马上就打脸了。
其实第3周的时候,有想过把当时的一些学习心得总结一下,先发出来。但是宁缺毋滥的理性很快打败了内心的小心机,毕竟骗自己的态度不可取。看清目标与现实间的差异,逐渐认识自身有限的学习能力,本身也是一种收获。
回到文章本身,今天要说的主题是:一种结合机器学习做因果推断任务的算法,学术名叫Double Machine Learning(DML),双重机器学习。
围绕DML,本文将首先介绍DML的算法原理;然后使用简单的模拟数据手动实现该算法,并和已有的工具包做对比,以此加深对该算法的理解;在此基础上,针对更实际的案例,尝试求解物理意义更强的因果推断问题。
正文见下。
2 DML算法原理
2.1 问题阐述
先回顾一下潜在因果框架中因果推断问题的定义:样本数据集为: D = { d 1 , d 2 , . . . , d n } D=\{d_1,d_2,...,d_n\} D={d1,d2,...,dn}, n n n为样本数量;策略变量为 T ∈ { 0 , 1 } T\in \{0, 1\} T∈{0,1}, T = 0 T=0 T=0表示不施加策略, T = 1 T=1 T=1表示施加策略;协变量 X X X,一般指与策略无关的变量;结果变量 Y Y Y: Y 0 i Y_{0i} Y0i表示无策略时第 i i i个样本的结果变量, Y 1 i Y_{1i} Y1i表示有策略时第 i i i个样本的结果变量。目标是:基于数据集 D = { T i , X i , Y i } i n D=\{T_i,X_i,Y_i\}_i^n D={Ti,Xi,Yi}in,估计 T T T和 Y Y Y之间的因果效应。
在这个定义里面,有个前提假设很容易不满足,那就是 X X X和 T T T无关。一方面,在寻找 X X X时,很难确认 X X X和 T T T无关。举个例子,我们想知道冰淇淋的价格与销量间的因果效应,此处 T T T是价格, Y Y Y是销量。 X X X很容易想到有:当时的天气温度、当地的生活水平等等。但当地的生活水平和价格之间大概率是正相关的,比如同一款巧乐兹在北京卖的价格和十八线小城市的价格,大概率是有差别的。
另一方面,为了更全面考虑问题,变量 X X X中会纳入尽可能多的特征,而特征越多,就越难保证其和策略变量 T T T是否相关。
当 X X X和 T T T相关后,就会产生混淆变量 W W W,该类变量既影响 Y Y Y,又影响 T T T,如下图所示。
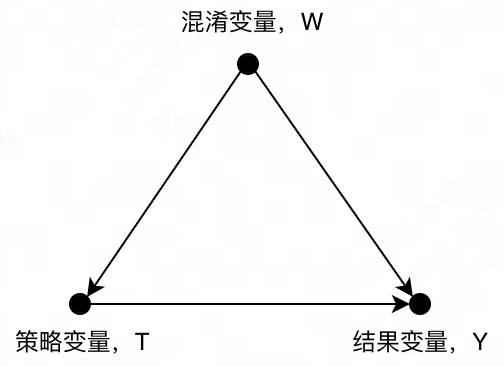
在此情况下,要得到 T T T和 Y Y Y之间纯净的因果效应就更难了。
2.2 DML算法
为了解决包含混淆变量的因果推断问题,本节介绍一种被称为双重机器学习的算法,英文是:Double Machine Learning (DML)。
该算法考虑如下一种线性模型:
Y = T θ 0 + X β 0 + U , E [ U ( X , T ) ] = 0 Y=T\theta_0+X\beta_0+U, \quad E[U(X,T)]=0 Y=Tθ0+Xβ0+U,E[U(X,T)]=0
T = X γ 0 + V , E [ V ∣ X ] = 0 T=X\gamma_0+V, \quad E[V|X]=0 T=Xγ0+V,E[V∣X]=0
解释一下上述两个公式:第一个公式表达的是 Y Y Y和 T T T、 X X X之间为线性关系,其中 U U U为随机扰动项;第二个公式表达的是 T T T和 X X X之间也是线性关系,其中 V V V是为随机扰动项。
在该模型中,变量 X X X会同时影响 T T T和 Y Y Y,即 X X X被看做一个混淆变量,只是限定了变量间为线性关系。
DML的算法方案分为两步:第一步是基于机器学习模型使用协变量 X X X分别拟合 Y Y Y和 T T T,得到 Y ^ , T ^ \hat Y, \hat T Y^,T^,此时残差分别为 Y − Y ^ Y-\hat Y Y−Y^和 T − T ^ T-\hat T T−T^;
第二步是对残差,用任意机器学习模型(很多是最小二乘法)拟合,得到参数 τ \tau τ,即认为是 T T T和 Y Y Y之间的真正因果效应值。
( Y − Y ^ ) = τ ⋅ ( T − T ^ ) (Y-\hat Y) = \tau·(T-\hat T) (Y−Y^)=τ⋅(T−T^)
DML算法不复杂,不过有几点需要额外说明:
(1) 基于对 T T T和 Y Y Y残差的拟合,可以得到真正的因果效应值,直观上可以理解为:先剔除 X X X的影响后,再评估 T T T和 Y Y Y的因果效应,就会比较纯粹;理论上也是有证明的,只不过其推导证明对我来说有些复杂了,感兴趣的同学可以参考原文献:Double/debiased machine learning for treatment and structural parameters。B站上和CSDN上也有关于这篇文章的部分讲解,都可以参考一下。
(2) DML有个基本假设是: T T T和 Y Y Y之间是线性关系。所以如果 T T T不是0/1变量,而是个连续值,那么得到的因果效应值仅在 T T T附近有效。例如在上文提到的冰淇淋价格和销量的因果推断问题中, T T T是价格, Y Y Y是销量,设定 τ = 2 \tau=2 τ=2,我们可以说价格减少1个单位后销量能增加2个单位,但如果价格减少10个单位,就不能确认销量是否可以增加20个单位。
(3) 原问题中, X X X中有混杂变量 W W W;DML模型中,并没有刻意区分 W W W和 X X X。而且在实际操作时,由于拟合残差时使用的是机器学习模型,也不必仔细区分每个 X X X是不是混杂变量,直接扔进模型就行。
3 DML代码实现
本节通过两个实例,描述如何将DML应用于求解实际的业务问题。考虑到DML其中一种版本——因果森林DML,在业界很常用,本文也会更多关注因果森林DML的实践应用。
3.1 策略变量为0/1变量
策略变量为0/1变量是标准的因果推断问题,所以从这类问题入手比较适合。
本节的问题实例是个虚拟的合成数据,实现函数是causalml.dataset.synthetic_data,这是causalml自带的数据集,而causalml是Uber开源的因果推断工具包,未来肯定还会经常遇到它。
针对这个问题实例,下面的代码分别使用三种策略实现因果森林DML的技术方案:
(1) 自己编写代码实现。在计算 Y Y Y和 T T T的残差时,使用sklearn.ensemble.RandomForestRegressor;在拟合残差时,使用sklearn.linear_model.LinearRegression。
(2) 工具包+手动设置机器学习模型。工具包使用econml.dml.DML,然后依次设置计算残差和残差拟合的机器学习模型。
(3) 工具包一键完成。直接调用econml.dml.CausalForestDML。
这里的工具包需要单独描述一下。econml是微软开源的因果推断工具包,没有继续使用causalml,是因为causalml中暂时还不支持DML。在econml中,DML可以理解为一个简单框架,允许用户自行设置每个步骤上的机器学习模型;CausalForestDML可以理解为一个已经集成好的因果森林DML。
import pandas as pd
from causalml.metrics import auuc_score, plot_gain
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import LinearRegression
from causalml.dataset import synthetic_data
from econml.dml import CausalForestDML, DML# 自编代码实现因果森林DML
def algo_by_self_cf_dml(y, treat, X):# 计算y的残差rf_y = RandomForestRegressor()rf_y.fit(X, y)y_res = y - rf_y.predict(X)# 计算treat的残差rf_t = RandomForestRegressor()rf_t.fit(X, treat)treat_res = treat - rf_t.predict(X)# 计算因果效果lr = LinearRegression(fit_intercept=False).fit(treat_res.reshape(-1, 1), y_res.reshape(-1, 1))print('self_cf_dml: w = {:.2f}'.format(lr.coef_[0, 0]))# econml工具包实现因果森林DML
def algo_by_econml_dml(y, treat, X):# dml + 手动设置dml = DML(model_y=RandomForestRegressor(),model_t=RandomForestRegressor(),model_final=LinearRegression(fit_intercept=False))dml.fit(y, treat, X=X)print('DML: {}'.format(dml.ate(X)))# 因果森林DMLcf_dml = CausalForestDML()cf_dml.fit(y, treat, X=X)print('CausalForestDML: {}'.format(cf_dml.ate(X)))return dml, cf_dml# 计算AUUC和绘制gain曲线
def auuc_score_and_plot(y, treat, X, dml, cf_dml):# 使用dataframe组织计算AUUC的必要数据df = pd.DataFrame({'y': y,'treat': treat,'cf_dml': cf_dml.effect(X),'dml': dml.effect(X)})# 计算AUUC值auuc = auuc_score(df, outcome_col='y', treatment_col='treat', normalize=True, tmle=False)print(auuc)# 绘制gain曲线plot_gain(df, outcome_col='y', treatment_col='treat', normalize=True, random_seed=10, n=100, figsize=(8, 8))if __name__ == '__main__':# 使用synthetic_data生成数据y, X, treat, _, _, _ = synthetic_data(mode=1, n=10000, p=8, sigma=1.0)# 自编代码实现因果森林DMLalgo_by_self_cf_dml(y, treat, X)# econml工具包实现因果森林DMLdml, cf_dml = algo_by_econml_dml(y, treat, X)# 计算AUUC和绘制gain曲线auuc_score_and_plot(y, treat, X, dml, cf_dml)
使用多种策略实现因果森林DML,最重要的价值是可以加深对DML算法原理和工具包的理解。结合实践过程和以下的输出结果,可以发现一些新认知:
(1) 前文介绍的DML算法原理中,直接求解得到的 τ \tau τ,看起来应该是平均因果效应 A T E ATE ATE。
至于如何使用 τ \tau τ去预测新样本的个体因果效应 I T E ITE ITE,并没有提到;但在econml.dml中,dml.effect(X)却可以得到 I T E ITE ITE。
(2) 从 A T E ATE ATE的计算结果上可以看出,三种策略的结果是相似的,说明对DML算法原理的认知是没有多大问题的;第二种策略和第三种策略得到的结果并不完全相同,说明econml.dml.CausalForestDML相比econml.dml.DML,在代码层面还存在一些不同。
(3) 从auuc的结果来看,econml.dml.CausalForestDML的表现显著优于econml.dml.DML。但由于数据是虚拟的,下钻分析的意义不大,就不继续深入了。
关于auuc的计算还需要再描述一下。目前econml不支持针对auuc的计算和绘图,但是causalml可以。所以在代码中,我用到了 causalml.metrics.auuc_score和plot_gain这两个函数。这两个函数需要的数据,至少是2列:第1列是 Y Y Y值,第2列是 T T T值,其他的列都会被认为是不同模型输出的因果效应值,然后分别评估和输出。
self_cf_dml: w = 0.47
DML: 0.48424327569296155
CausalForestDML: 0.4705562443255083
cf_dml 0.716144
dml 0.505681
Random 0.498693
dtype: float64
3.2 策略变量为连续变量
通过上一节的实例,我们应该对因果森林DML有一个比较直观的感受了。本节尝试使用该模型解决一个业务场景中经常遇到的问题实例:推断商品价格和销量之间的因果效应。
本节实例的数据来源是kaggle竞赛中提供的在线零售销售数据。train_test_date_split函数参考其他内容对原始数据做了预处理,这部分的内容和因果森林DML无关,可以略过其中的逻辑细节(感兴趣的小伙伴可以在相关阅读中找到链接)。
为了将原问题转化为因果推断问题,需要设置: Y Y Y为销量的对数, T T T为价格的对数, X X X包括:month、DoM、DoW、stock_age_days和sku_avg_p。
Y Y Y和 T T T需要取对数的原因是:价格和销量间的关系大致应该为
τ = d Q / Q d P / P \tau=\frac{dQ/Q}{dP/P} τ=dP/PdQ/Q
此处, Q Q Q是销量, P P P是价格。该式和DML的基本公式有些出入,需要调整一下:对上述公式两边取对数,得到
log Q = log P + 截距 \log Q = \log P +截距 logQ=logP+截距
所以 Q Q Q和 P P P本身不是线性,但是取对数后,就变为线性,满足DML的使用条件了。
X X X的维度不多,如果在实际场景中,大概率还会包含商品的信息特征、用户历史购买特征等,本节的主要目标不在于精确给出其因果效应值,而是展现完整的计算过程,所以可以接受特征维度不那么全面的现状。
有了训练集后,使用因果森林DML进行训练,这个过程比较简单,一行代码便可以解决,就不赘述了。
得到模型后,依然需要使用auuc去验证模型的效果。不过在这里尤其需要注意两个方面:
(1) plot_gain和auuc_score中使用的treat只能接受0/1变量,而当前场景中价格是连续变量。代码里设置的逻辑是: log P \log P logP<0认为是1,反之是0,物理意义可以理解为1为降价,0为不降价。
(2) 价格和销量间的因果效应值为负数,所以在传入auuc计算时,需要先取负号,将其转为正数。
import pandas as pd
import numpy as np
from datetime import datetime, date
from causalml.metrics import plot_gain, auuc_score
from sklearn.model_selection import train_test_split
from econml.dml import CausalForestDMLdef train_test_date_split():# 数据预处理df = pd.read_csv('OnlineRetail.csv', encoding="unicode_escape")df = df[(df['UnitPrice'] > 0) & (df['Quantity'] > 0)].reset_index(drop=True)df = df[~df.StockCode.isin(['POST', 'DOT', 'M', 'AMAZONFEE', 'BANK CHARGES', 'C2', 'S'])]df['InvoiceDate'] = pd.to_datetime(df.InvoiceDate)df['Date'] = pd.to_datetime(df.InvoiceDate.dt.date)df['revenue'] = df.Quantity * df.UnitPricedf = (df.assign(dNormalPrice=lambda d: d.UnitPrice / d.groupby('StockCode').UnitPrice.transform('median')).pipe(lambda d: d[(d['dNormalPrice'] > 1. / 3) & (d['dNormalPrice'] < 3.)]).drop(columns=['dNormalPrice']))df = df.groupby(['Date', 'StockCode', 'Country'], as_index=False).agg({'Description': 'first','Quantity': 'sum','revenue': 'sum'})df['Description'] = df.groupby('StockCode').Description.transform('first')df['UnitPrice'] = df['revenue'] / df['Quantity']df_dml = df[(df.groupby('StockCode').UnitPrice.transform('std') > 0)]df_dml = df_dml.assign(LnP=np.log(df_dml['UnitPrice']),LnQ=np.log(df_dml['Quantity']),)df_dml['dLnP'] = np.log(df_dml.UnitPrice) - np.log(df_dml.groupby('StockCode').UnitPrice.transform('mean'))df_dml['dLnQ'] = np.log(df_dml.Quantity) - np.log(df_dml.groupby('StockCode').Quantity.transform('mean'))df_dml = df_dml.assign(month=lambda d: d.Date.dt.month,DoM=lambda d: d.Date.dt.day,DoW=lambda d: d.Date.dt.weekday,stock_age_days=lambda d: (d.Date - d.groupby('StockCode').Date.transform('min')).dt.days,sku_avg_p=lambda d: d.groupby('StockCode').UnitPrice.transform('median'))y = df_dml['dLnQ']treat = df_dml['dLnP']X = df_dml[['month', 'DoM', 'DoW', 'stock_age_days', 'sku_avg_p']]y_train, y_test, treat_train, treat_test, X_train, X_test = train_test_split(y, treat, X, test_size=.2)return X_train, y_train, treat_train, X_test, y_test, treat_testif __name__ == '__main__':# 整合训练和测试数据X_train, y_train, treat_train, X_test, y_test, treat_test = train_test_date_split()# 因果森林DML训练cf_dml = CausalForestDML(n_jobs=1).fit(y_train, treat_train, X=X_train)# AUUC评估训练集效果train_df = pd.DataFrame({'y': y_train,'treat': np.where(treat_train.values < 0, 1, 0),'cf_dml': -cf_dml.effect(X_train)})plot_gain(train_df, outcome_col='y', treatment_col='treat', normalize=True, random_seed=10, n=100, figsize=(8, 8))auuc = auuc_score(train_df, outcome_col='y', treatment_col='treat', normalize=True, tmle=False)print('train set auuc:')print(auuc)# AUUC评估测试集效果test_df = pd.DataFrame({'y': y_test,'treat': np.where(treat_test.values < 0, 1, 0),'cf_dml': -cf_dml.effect(X_test)})plot_gain(test_df, outcome_col='y', treatment_col='treat', normalize=True, random_seed=10, n=100, figsize=(8, 8))auuc = auuc_score(test_df, outcome_col='y', treatment_col='treat', normalize=True, tmle=False)print('\ntest set auuc:')print(auuc)
以下是代码的输出结果。从结果上来看,模型的auuc优于随机排序的auuc,同时测试集的auuc略低于训练集的auuc,整体上来看是符合预期的。
train set auuc:
cf_dml 0.691234
Random 0.500072
dtype: float64test set auuc:
cf_dml 0.623231
Random 0.499888
dtype: float64


4 总结
文章正文到此就结束了,本节总结一下三个比较重要的内容:
(1) DML的原理是:基于对结果变量和策略变量残差的拟合,可以得到真正的因果效应值。
(2) econml工具包可以调用DML和因果森林DML算法。
(3) 使用auuc评估DML的预测效果时,可以调用causalml工具包。
5 相关阅读
DML算法原文:https://academic.oup.com/ectj/article/21/1/C1/5056401?login=false
DML算法原理讲解1:https://academic.oup.com/ectj/article/21/1/C1/5056401?login=false
DML算法原理讲解2:https://blog.csdn.net/a358463121/article/details/123999934
DML实例1:https://cloud.tencent.com/developer/article/1913864
DML实例2:https://cloud.tencent.com/developer/article/1938132
FWL定理:https://www.bilibili.com/video/BV1dA411H7nP/?spm_id_from=333.788&vd_source=f416a5e7c4817e8efccf51f2c8a2c704
在线零售销售数据:https://www.kaggle.com/datasets/vijayuv/onlineretail
销售数据预处理:https://github.com/Serena-TT/36-methods-for-data-analysis/blob/main/DML.ipynb
相关文章:
因果推断 | 双重机器学习(DML)算法原理和实例应用
文章目录 1 引言2 DML算法原理2.1 问题阐述2.2 DML算法 3 DML代码实现3.1 策略变量为0/1变量3.2 策略变量为连续变量 4 总结5 相关阅读 1 引言 小伙伴们,好久不见呀。 距离上次更新已经过去了一个半月,上次发文章时还信誓旦旦地表达自己后续目标是3周更…...

Flutter 开源库学习
网上看了好多歌词实现逻辑相关资料,封装比较的好的 就 flutter_lyric,核心类是LyricsReader,而且如果实现逐字逐句歌词编辑功能还需要自己实现很多细节 ,网友原话是 :歌词的功能真的是不少,写起来也是挺难的…...

自主巡航,目标射击
中国机器人及人工智能大赛 参赛经验: 自主巡航赛道 【机器人和人工智能——自主巡航赛项】动手实践篇-CSDN博客 主要逻辑代码 #!/usr/bin/env python #coding: utf-8import rospy from geometry_msgs.msg import Point import threading import actionlib impor…...

MySQL中EXPLAIN关键字详解
昨天领导突然问到,MySQL中explain获取到的type字段中index和ref的区别是什么。 这两种状态都是在使用索引后产生的,但具体区别却了解不多,只知道ref相比于index效率更高。 因此,本文较为详细地记录了MySQL性能中返回字段的含义、状…...

如何理解ref toRef和toRefs
是什么 ref 生成值类型的响应式数据可用于模板和reactive通过.value修改值 ref也可以像vue2中的ref那样使用 toRef 针对一个响应式对象(reactive)的prop创建一个ref两者保持引用关系 toRefs 将响应式对象(reactive封装)转换…...

【linux】kernel-trace
文章目录 linux kernel trace配置trace内核配置trace接口使用通用配置Events配置Function配置Function graph配置Stack trace设置 跟踪器tracer功能描述 使用示例1.irqsoff2.preemptoff3.preemptirqsoff linux kernel trace 配置 源码路径: kernel/trace trace内…...
)
【Golang 面试基础题】每日 5 题(一)
✍个人博客:Pandaconda-CSDN博客 📣专栏地址:http://t.csdnimg.cn/UWz06 📚专栏简介:在这个专栏中,我将会分享 Golang 面试中常见的面试题给大家~ ❤️如果有收获的话,欢迎点赞👍收藏…...

ETCD介绍以及Go语言中使用ETCD详解
ETCD介绍以及Go语言中使用ETCD详解 什么是etcd ETCD是一个分布式、可靠的key-value存储的分布式系统,用于存储分布式系统中的关键数据;当然,它不仅仅用于存储,还提供配置共享及服务发现;基于Go语言实现 。 etcd的特点 完全复制:集群中的每个节点都可以使用完整的存档高…...

03-用户画像+Elasticsearch
优点 es支持海量数据的写入和更新es可以和hadoop,hive及spark进行集成es支持hivesql的操作,可以通过hivesql将数据导入eses的在进行数据检索查询是速度比较快es是分布式存储 应用 全文检索 全文检索流程: 1-对文档数据(文本数据)进行分词 2-将分词…...

初学Mybatis之搭建项目环境
在连接 mysql 数据库时,遇到了个 bug,之前都能连上,但报错说换了个 OS 操作系统什么的 然后搜索怎么连接,找到了解决方法 MySQL MYSQL – 无法连接到本地MYSQL服务器 (10061)|极客教程 (geek-docs.com) 命令行输入 services.msc…...

JMeter使用小功能-(持续更新)
1、jmeter在同一个线程组内,uuid的复用 方式一: 方式二: 2、获得jMeter使用的线程总数 ctx.getThreadGroup().getNumberOfThreads()来表示活动线程总数 int threadNumctx.getThreadGroup().getNumThreads(); String threads Integer…...
)
科研绘图系列:R语言火山图(volcano plot)
介绍 火山图(Volcano Plot),也称为火山图分析,是一种在生物信息学和基因组学中常用的图形表示方法,主要用于展示基因表达数据的差异。它通常用于基因表达微阵列或RNA测序数据的可视化,帮助研究人员识别在不同条件下表达差异显著的基因。 火山图的基本构成 X轴:通常表示…...

docker firewalld 防火墙设置
1、环境 centos 7 firewalld docker-ce docker 默认会更改防护墙配置 导致添加的防火墙策略不生效,可以启用firewalld 重新设置策略 2、启用防火墙 systemctl start firewalld systemctl enable firewalld3、配置文件禁用docker 的iptables /etc/docker/daemon.js…...

《问题004:报错-JS问题-unknown: Invalid shorthand property initializer.》
问题描述: unknown: Invalid shorthand property initializer. (25:13) unknown:无效的简写属性初始化项 解决方法: “”应该写为“:”(globalData 改成 globalData: )...

什么是 MLPerf?
什么是 MLPerf? MLPerf 是一个用于衡量机器学习硬件、软件和服务性能的标准化基准测试平台。它由 MLCommons 组织开发,该组织是由多家领先的科技公司和学术机构组成的。MLPerf 的目标是通过一系列标准化的基准测试任务和数据集,提供一个统一…...

【SpringBoot】第3章 SpringBoot的系统配置
3.1 系统配置文件 3.1.1 application.properties SpringBoot支持两种不同格式的配置文件,一种是Properties,一种是YML。 SpringBoot默认使用application.properties作为系统配置文件,项目创建成功后会默认在resources目录下生成applicatio…...

ELK日志分析系统部署文档
一、ELK说明 ELK是Elasticsearch(ES) Logstash Kibana 这三个开源工具组成,官方网站: The Elastic Search AI Platform — Drive real-time insights | Elastic 简单的ELK架构 ES: 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它…...

ue5笔记
1 点光源 聚光源 矩形光源 参数比较好理解 (窗口里面)环境光混合器:快速创造关于环境光的组件 大气光源:太阳光,定向光源 天空大气:蓝色的天空和大气 高度雾:大气下面的高度感的雾气 体积…...

TCP重传机制详解
1.什么是TCP重传机制 在 TCP 中,当发送端的数据到达接收主机时,接收端主机会返回⼀个确认应答消息,表示已收到消息。 但是如果传输的过程中,数据包丢失了,就会使⽤重传机制来解决。TCP的重传机制是为了保证数据传输的…...

如何使用javascript将商品添加到购物车?
使用JavaScript将商品添加到购物车可以通过以下步骤实现: 创建一个购物车对象,可以是一个数组或者对象,用于存储添加的商品信息。在网页中的商品列表或详情页面,为每个商品添加一个“添加到购物车”的按钮,并为按钮绑…...

抖音批量下载终极指南:3步实现无水印高清视频免费下载
抖音批量下载终极指南:3步实现无水印高清视频免费下载 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppo…...

别再折腾wgrib了!用Python的xarray+cfgrib在Windows上优雅读取GRIB气象数据
告别命令行混乱:用Python生态在Windows上高效处理GRIB气象数据 气象数据分析工作中,GRIB格式文件一直是让人又爱又恨的存在。这种专为网格化气象数据设计的二进制格式,虽然存储效率高、兼容性强,但处理起来却常常让初学者望而生畏…...

超导输电技术:从原理到工程应用的挑战与前景
1. 超导输电线路:从技术神话到工程现实的漫长跋涉大约二十年前,当“高温超导”这个名词开始从实验室走向产业界的视野时,整个电力工程领域都为之振奋。想象一下,我们日常依赖的庞大电网,其输电线路中高达5%到10%的电能…...

基于Refine框架的企业级后台管理系统实战开发指南
1. 项目概述与核心价值最近在梳理企业内部后台管理系统的技术栈时,我又一次把目光投向了refine这个框架。如果你也和我一样,长期被各种业务后台的重复性开发工作所困扰——比如没完没了的增删改查(CRUD)界面、复杂的权限控制、数据…...

城市道路自动驾驶避障规划与MPC跟踪控制【附仿真】
✨ 长期致力于自动驾驶、路径规划、速度规划、跟踪控制、模型预测控制研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅如需沟通交流,点击《获取方式》 (1)SL图五次多项式代价路径决策与凸…...

ANSYS Workbench网格进阶:巧用‘Face Meshing’与‘Sweep’扫掠,让你的轴承座仿真既快又准
ANSYS Workbench网格进阶:巧用‘Face Meshing’与‘Sweep’扫掠提升轴承座仿真效率 轴承座作为机械传动系统中的关键部件,其应力分布与变形分析的准确性直接影响设备可靠性评估。传统四面体网格虽能快速生成,但在应力集中区域往往需要极高密度…...

基于矩阵分解与独立向量分析的深度神经网络后门攻击检测方法
1. 项目概述:当深度神经网络遭遇“潜伏者”在深度神经网络(DNN)如卷积神经网络(CNN)、Transformer模型等成为计算机视觉、自然语言处理乃至语音识别领域基石的今天,我们享受着其带来的高精度与自动化红利。…...

WechatDecrypt技术实现:如何通过开源工具实现微信数据本地解密与隐私保护
WechatDecrypt技术实现:如何通过开源工具实现微信数据本地解密与隐私保护 【免费下载链接】WechatDecrypt 微信消息解密工具 项目地址: https://gitcode.com/gh_mirrors/we/WechatDecrypt 在数字化时代,数据隐私保护已成为技术开发者和普通用户共…...

AI驱动BI分析:MCP协议与Metabase助手实战指南
1. 项目概述:当AI助手成为你的BI分析师如果你和我一样,每天都要和Metabase打交道,那你肯定经历过这样的场景:业务同事跑过来问,“能不能帮我拉一下上个月每个渠道的转化率?”,或者产品经理说&am…...

加州DMV十年自动驾驶报告深度解析:从测试数据看行业格局与技术演进
1. 项目概述:一份数据,十年自动驾驶风云如果你关注自动驾驶,那你一定听说过加州车管局(DMV)的年度测试报告。这玩意儿,可以说是全球自动驾驶行业的“晴雨表”和“成绩单”。从2015年开始,加州就…...