Inconsistent Query Results Based on Output Fields Selection in Milvus Dashboard
题意:在Milvus仪表盘中基于输出字段选择的不一致查询结果
问题背景:
I'm experiencing an issue with the Milvus dashboard where the search results change based on the selected output fields.
I'm working on a RAG project using text data converted into embeddings, stored in a Milvus collection with around 8000 elements. Last week, my retrieval results matched my expectations ("good" results), however, this week, the results have degraded ("bad" results).
I found that when I exclude the embeddings_vector field from the output fields in the Milvus dashboard, I get the "good" results; Including the embeddings_vector field in the output changes the results to "bad".
I've attached two screenshots showing the difference in the results based on the selected output fields.
Any ideas on what's causing this or how to fix it?
Environment:
Python 3.11 pymilvus 2.3.2 llama_index 0.8.64
Thanks in advance!
from llama_index.vector_stores import MilvusVectorStore
from llama_index import ServiceContext, VectorStoreIndex# Some other lines..# Setup for MilvusVectorStore and query execution
vector_store = MilvusVectorStore(uri=MILVUS_URI,token=MILVUS_API_KEY,collection_name=collection_name,embedding_field='embeddings_vector',doc_id_field='chunk_id',similarity_metric='IP',text_key='chunk_text')embed_model = get_embeddings()
service_context = ServiceContext.from_defaults(embed_model=embed_model, llm=llm)
index = VectorStoreIndex.from_vector_store(vector_store=vector_store, service_context=service_context)
query_engine = index.as_query_engine(similarity_top_k=5, streaming=True)rag_result = query_engine.query(prompt)Here is the "good" result: "good" result And here is the "bad" result: "bad" result
问题解决:
I would like to suggest you to follow below considerations.
- Ensure that your Milvus collection is correctly indexed. Indexing plays a crucial role in how search results are retrieved and ordered. If the index configuration has changed or is not optimized, it might affect the retrieval quality.
- In your screenshots, the consistency level is set to "Bounded". Try experimenting with different consistency levels (e.g., "Strong" or "Eventually") to see if it impacts the results. Consistency settings can influence the real-time availability of the indexed data.
- Review the query parameters, especially the similarity_metric. Since you're using IP (Inner Product) as the similarity metric, ensure that your embedding vectors are normalized correctly. Inner Product search works best with normalized vectors.
- Verify that the embedding vectors are of consistent quality and scale. If there were changes in the embedding model or preprocessing steps, it could lead to variations in the search results.
- The inclusion of the embeddings_vector field in the output might affect the way Milvus scores and ranks the results. It's possible that returning the raw embeddings affects the internal ranking logic. Ensure that including this field does not inadvertently alter the search behavior.
- Check the Milvus server logs and performance metrics to identify any anomalies or changes in the search behavior. This might provide insights into why the results differ when the embeddings_vector field is included.
- Ensure that there are no version mismatches between the client (pymilvus) and the Milvus server. Sometimes, discrepancies between versions can cause unexpected behavior.
- As a last resort, try modifying your code to exclude the embeddings_vector field programmatically during retrieval and compare the results. This can help isolate whether the issue is indeed caused by including the embeddings in the output.
-
Please try out this code if it helps.

相关文章:
Inconsistent Query Results Based on Output Fields Selection in Milvus Dashboard
题意:在Milvus仪表盘中基于输出字段选择的不一致查询结果 问题背景: Im experiencing an issue with the Milvus dashboard where the search results change based on the selected output fields. Im working on a RAG project using text data conv…...

视觉巡线小车——STM32+OpenMV
系列文章目录 第一章:视觉巡线小车——STM32OpenMV(一) 第二章:视觉巡线小车——STM32OpenMV(二) 第三章:视觉巡线小车——STM32OpenMV(三) 第四章:视觉巡…...

升级TrinityCore 服务器硬件
升级服务器 原服务器架构:Ubuntu装VirtualBox装Ubuntu虚拟机 原配置: 宿主机 内存4G 内核4 usb外接硬盘 Ubuntu虚拟机 内存1756MB 内核4 ip 192.168.0.12 升级服务器架构:FreeBSD装bhyve装Ubuntu虚拟机 新配置:宿主机 内存…...

NVidia 的 gpu 开源 Linux Kernel Module Driver 编译 安装 使用
见面礼,动态查看gpu使用情况,每隔2秒钟自动执行一次 nvidia-smi $ watch -n 2 nvidia-smi 1,找一台nv kmd列表中支持的 GPU 的电脑,安装ubuntu22.04 列表见 github of the kmd source code。 因为 cuda sdk 12.3支持最高到 ubu…...
win7显卡驱动更新后msvcp140.dll丢失的解决方法
msvcp140.dll是一个 DLL(动态链接库)文件,它是 Microsoft Visual C 2015 Redistributable Package 的一部分。这个文件包含 C 应用程序在运行时所需的标准库函数,主要涉及执行与 C 编程语言相关的操作,如内存管理、数学…...
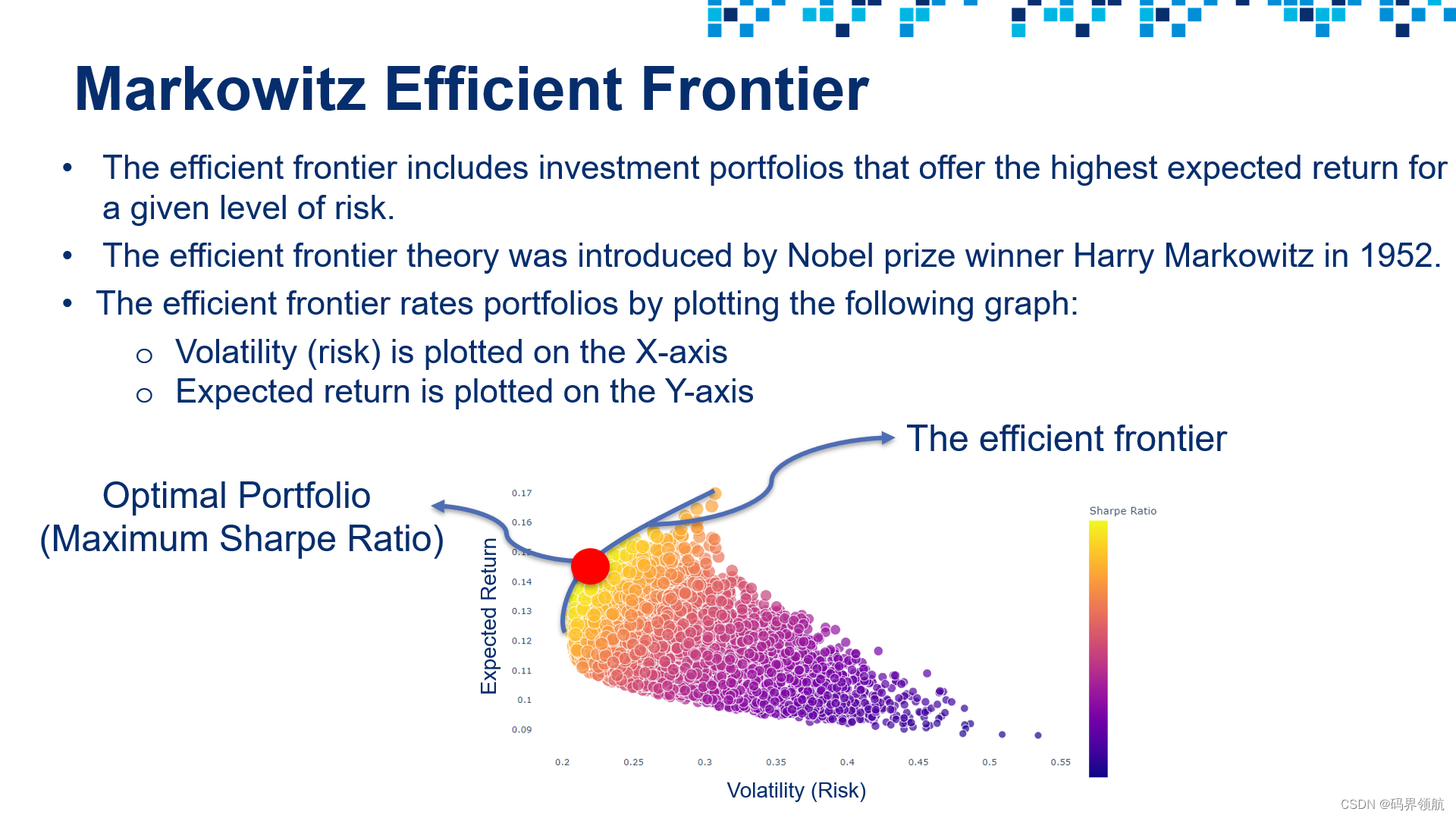
(11)Python引领金融前沿:投资组合优化实战案例
1. 前言 本篇文章为 Python 对金融的投资组合优化的示例。投资组合优化是从一组可用的投资组合中选择最佳投资组合的过程,目的是最大限度地提高回报和降低风险。 投资组合优化是从一组可用的投资组合中选择最佳投资组合的过程,目的是最大限度地提高回报…...

git删除本地远程分支
gitlab删除远程分支 要删除GitLab上的远程分支,你可以使用Git命令行工具。以下是删除远程分支的步骤和示例代码: 首先,确保你已经在本地删除了分支。删除本地分支的命令是: git branch -d <branch_name> 如果分支没有被合…...
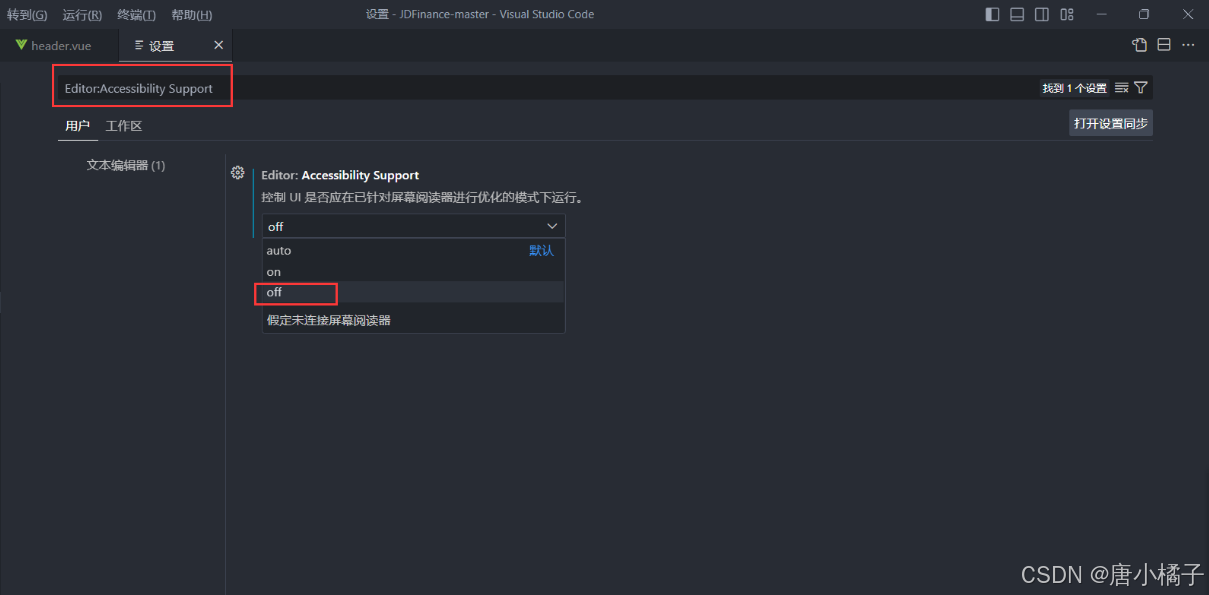
前端-04-VScode敲击键盘有键入音效,怎么关闭
目录 问题解决办法 问题 今天正在VScode敲项目,不知道是按了什么快捷键还是什么的,敲击键盘有声音,超级烦人啊!!于是我上网查了一下,应该是开启了VScode的键入音效,下面是关闭键入音效的办法。…...

JMeter数据库连接操作及断言
一、数据库操作 应用场景: 接口自动化数据校验:用于验证接口返回的数据与数据库中的数据是否一致。特殊业务:处理一些与数据库相关的特殊业务逻辑。性能测试:测试数据库的性能,如查询、更新等操作的响应时间。 连接数…...

Maven settings.xml 私服上传和拉取配置
公司内部自行开发的依赖包需要上传到maven私服时,可以在项目的pom.xml中配置,也可以在本地计算机的maven目录settings.xml中配置。本文讲述的是如何在settings.xml中进行配置。 场景:有两个maven私服,其中一个为公司的࿰…...

【STM32】MPU内存保护单元
注:仅在F7和M7系列上使用介绍 功能: 设置不同存储区域的存储器访问权限(管理员、用户) 设置存储器(内存和外设)属性(可缓冲、可缓存、可共享) 优点:提高嵌入式系统的健壮…...

用Python爬虫能实现什么?
Python 是进行网络爬虫开发的一个非常流行和强大的语言,这主要得益于其丰富的库和框架,比如 requests、BeautifulSoup、Scrapy 等。下面我将简要介绍 Python 爬虫的基础知识和几个关键步骤。 1. 爬虫的基本原理 网络爬虫(Web Crawler&#…...
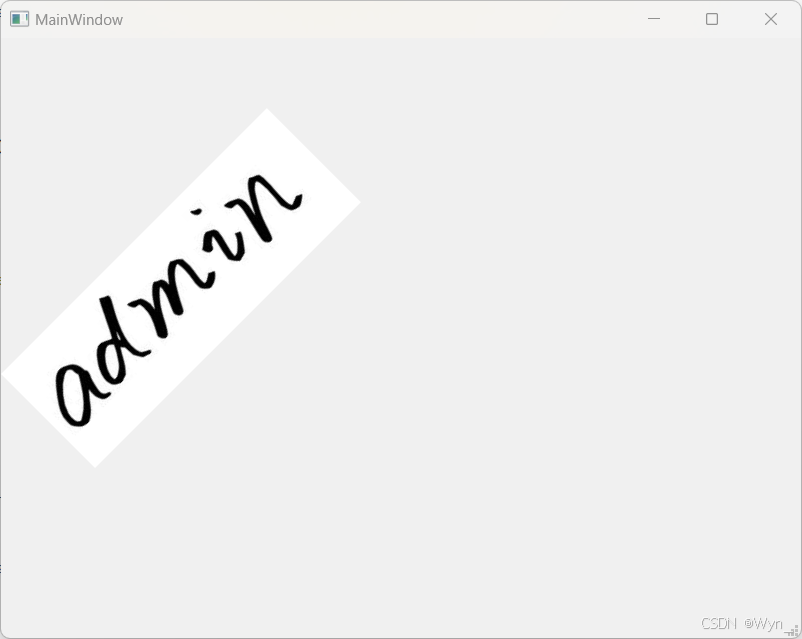
【QT】label中添加QImage图片并旋转(水平翻转、垂直翻转、顺时针旋转、逆时针旋转)
目录 0.简介 1.详细代码及解释 1)原label显示在界面上 2)水平翻转 3)垂直翻转 4)顺时针旋转45度 5)逆时针旋转 0.简介 环境:windows11 QtCreator 背景:demo,父类为QWidget&a…...

CSP-J模拟赛day1
yjq的吉祥数 文件读写 输入文件 a v o i d . i n avoid.in avoid.in 输出文件 a v o i d . o u t avoid.out avoid.out 限制 1000ms 512MB 题目描述 众所周知, 这个数字在有些时候不是很吉利,因为它谐音为 “散” 所以yjq认为只要是 的整数次幂的数…...
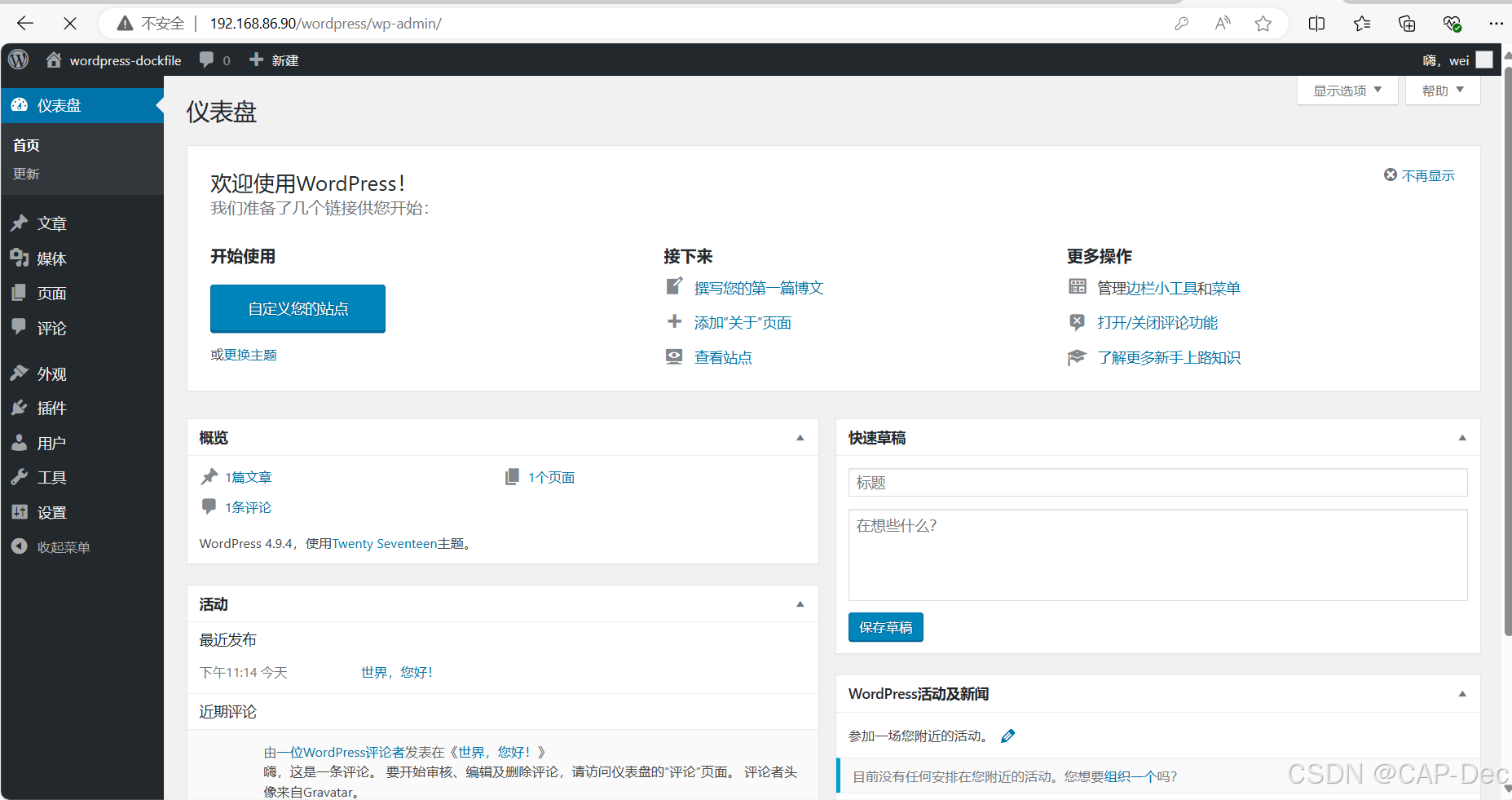
Docker构建LNMP环境并运行Wordpress平台
1.准备Nginx 上传文件 Dockerfile FROM centos:7 as firstADD nginx-1.24.0.tar.gz /opt/ COPY CentOS-Base.repo /etc/yum.repos.d/RUN yum -y install pcre-devel zlib-devel openssl-devel gcc gcc-c make && \useradd -M -s /sbin/nologin nginx && \cd /o…...
《峡谷小狐仙-多模态角色扮演游戏助手》复现流程
YongXie66/Honor-of-Kings_RolePlay: The Role Playing Project of Honor-of-Kings Based on LnternLM2。峡谷小狐仙--王者荣耀领域的角色扮演聊天机器人,结合多模态技术将英雄妲己的形象带入大模型中。 (github.com) https://github.com/chg0901/Honor_of_Kings…...
Qt 使用Installer Framework制作安装包
Qt 使用Installer Framework制作安装包 引言一、下载安装 Qt Installer Framework二、简单使用2.1 创建目录结构 (文件夹结构)2.2 制作程序压缩包2.3 制作程序安装包 引言 Qt Installer Framework (安装程序框架)是一个强大的工具集,用于创建自定义的在线和离线安装…...
Typora 1.5.8 版本安装下载教程 (轻量级 Markdown 编辑器),图文步骤详解,免费领取(软件可激活使用)
文章目录 软件介绍软件下载安装步骤激活步骤 软件介绍 Typora是一款基于Markdown语法的轻量级文本编辑器,它的主要目标是为用户提供一个简洁、高效的写作环境。以下是Typora的一些主要特点和功能: 实时预览:Typora支持实时预览功能࿰…...

linux代填密码切换用户
一、背景 linux用户账户密码复杂,在不考虑安全的情况下,想要使用命令自动切换用户 二、操作 通过 expect 工具来实现自动输入密码的效果 yum install expect创建switchRoot.exp文件,内容参考下面的 #!/usr/bin/expect set username root…...

防火墙的经典体系结构及其具体结构
防火墙的经典体系结构及其具体结构 防火墙是保护计算机网络安全的重要设备或软件,主要用于监控和控制进出网络流量,防止未经授权的访问。防火墙的经典体系结构主要包括包过滤防火墙、状态检测防火墙、代理防火墙和下一代防火墙(NGFW…...

AI技能树:构建系统化学习路径,从理论到工程实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“HieuNghi-AI-Skills”。光看这个名字,可能有点摸不着头脑,但点进去之后,我发现这其实是一个关于AI技能学习的资源集合库。简单来说,它就是一个由社区驱…...

基于Kubernetes Operator的企业级区块链网络自动化部署实践
1. 项目概述:企业级区块链的云原生部署方案如果你正在寻找一个能够将企业级区块链网络快速、稳定地部署到Kubernetes集群上的成熟方案,那么ConsenSys开源的quorum-kubernetes项目绝对值得你花时间深入研究。这个项目不是一个简单的概念验证,而…...

OpenSceneGraph 3.6.5 源码编译实战:从依赖配置到项目集成的完整指南
1. 环境准备:搭建编译OSG的基础舞台 在开始编译OpenSceneGraph 3.6.5之前,我们需要先搭建好开发环境。就像盖房子需要打好地基一样,环境配置决定了后续编译过程的顺利程度。我曾在多个项目中编译过不同版本的OSG,发现环境配置不当…...

全方位降本增效,Captain AI重构OZON运营成本结构
当前OZON市场竞争日趋激烈,人力、物流、广告、库存等各项运营成本持续攀升,利润空间不断压缩,“降本”与“增效”成为商家生存发展的核心命题。不同于单一工具仅能优化某一项成本,Captain AI立足OZON商家全运营场景,以…...
)
Tarjan算法:从DFS序到强连通分量的寻路指南(附C++实战与缩点技巧)
1. 从迷宫探索到强连通王国:Tarjan算法的生活隐喻 想象你正在探索一座巨大的迷宫,手里拿着粉笔和记事本。每走到一个新的岔路口,你就在墙上标记数字(第一个到的路口标1,第二个标2...),这就是DFS…...


SteamAutoCrack:3步自动化破解Steam游戏的终极解决方案
SteamAutoCrack:3步自动化破解Steam游戏的终极解决方案 【免费下载链接】Steam-auto-crack Steam Game Automatic Cracker 项目地址: https://gitcode.com/gh_mirrors/st/Steam-auto-crack 你是否厌倦了每次想离线玩游戏时都要手动破解的繁琐过程?…...

大模型API响应延迟飙升470%,却查不到根因?SITS2026可观测性四象限诊断法,今天就落地
更多请点击: https://intelliparadigm.com 第一章:SITS2026可观测性框架的起源与核心范式 SITS2026(System Intelligence Telemetry Standard 2026)并非凭空诞生,而是源于云原生系统在超大规模微服务编排、边缘-中心协…...
)
C语言打印三角形别再只会用*了!用字母、数字、符号玩出新花样(附完整代码)
C语言打印三角形:用字母、数字和符号玩转循环艺术 在C语言入门阶段,打印三角形几乎是每个初学者必经的练习。但你是否已经厌倦了千篇一律的星号(*)图案?今天,我们将打破常规,探索如何用字母、数字和各种符号来创造独特…...

基于浏览器自动化的高级爬虫框架autoclaw实战指南
1. 项目概述与核心价值最近在折腾自动化脚本时,发现了一个挺有意思的GitHub项目,叫jmoraispk/autoclaw。乍一看名字,可能会联想到“自动爪子”或者“爬虫”,实际上,它也确实是一个专注于自动化网页交互和数据抓取的工具…...