Opencv学习项目3——人脸识别
之前我们获取了一张图像的人脸信息,现在我们来使用特征点分析来匹配两张lyf照片的相似度
获取两张图片的人脸信息
import cv2
import face_recognition# 加载图像文件
img1 = face_recognition.load_image_file('lyf1.png')
img2 = face_recognition.load_image_file('lyf2.png')
# 将图像从 BGR 格式转换为 RGB 格式
img1 = cv2.cvtColor(img1, cv2.COLOR_BGR2RGB)
img2 = cv2.cvtColor(img2, cv2.COLOR_BGR2RGB)
# 第一个人的人脸位置信息
faceloc1 = face_recognition.face_locations(img1)[0]
faceloc2 = face_recognition.face_locations(img2)[0]
#框出人脸
cv2.rectangle(img1, (faceloc1[3], faceloc1[0]), (faceloc1[1], faceloc1[2]), (0, 255, 0), 3)
cv2.rectangle(img2, (faceloc2[3], faceloc2[0]), (faceloc2[1], faceloc2[2]), (0, 255, 0), 3)#打印人脸位置信息
print(faceloc1)
print(faceloc2)cv2.imshow('lyf1', img1)
cv2.imshow('lyf2', img2)
cv2.waitKey(0)
效果如下

然后接下来我们使用face_encodings来进行提取人脸特征编码,首先我们先对这个函数进行一下介绍
face_encodings函数
face_recognition.face_encodings()是 face_recognition 库中的一个函数,用于从图像中提取人脸的特征编码。这些编码是对人脸图像的数值化描述,可以用来比较不同人脸之间的相似度,从而进行人脸识别或验证。face_encodings(face_image, known_face_locations=None, num_jitters=1)
face_image: 必须是一个RGB图像(numpy数组),即使是从OpenCV加载的图像也需要先转换为RGB格式。
known_face_locations: 可选参数,指定人脸位置的列表。每个位置是一个包含四个整数的元组
(top, right, bottom, left),代表人脸框的坐标。如果不提供此参数,函数将自动检测图像中的所有人脸。num_jitters: 可选参数,默认为1。用于增加对每个人脸提取特征时的采样次数,以获得更稳定的编码。较大的值可能会提高准确性,但会增加计算成本。
返回值:
该函数返回一个包含每个检测到的人脸编码的列表。每个编码是一个128维的numpy数组,描述了人脸在128维空间中的位置关系和特征。
face_recognition.face_encodings()可以结合face_recognition.face_locations()使用,以便首先检测人脸位置,然后提取这些位置上的人脸编码。人脸编码是一个具有良好特性的向量,可以用于比较两张人脸图像的相似度。通常,人脸编码越相似,它们之间的距离(如欧氏距离)越小。
该函数在进行人脸识别、人脸验证和人脸聚类等任务时非常有用。
这样我们使用faceloc1 = face_recognition.face_locations(img1)[0]
face_encoding1 = face_recognition.face_encodings(img1, [faceloc1])[0]
这里就表示获取第一个人脸的特征编码
img1 = face_recognition.load_image_file('lyf1.png')
img2 = face_recognition.load_image_file('lyf2.png')
# 将图像从 BGR 格式转换为 RGB 格式
img1 = cv2.cvtColor(img1, cv2.COLOR_BGR2RGB)
img2 = cv2.cvtColor(img2, cv2.COLOR_BGR2RGB)
# 第一个人的人脸位置信息
faceloc1 = face_recognition.face_locations(img1)[0]
faceloc2 = face_recognition.face_locations(img2)[0]
# 提取人脸编码
face_encoding1 = face_recognition.face_encodings(img1, [faceloc1])[0]
face_encoding2 = face_recognition.face_encodings(img2, [faceloc2])[0]
下面我们使用compare_faces来对比两个图片人脸的相似度,介绍一下这个函数
compare_faces函数
face_recognition.compare_faces([face_encoding1], face_encoding2)是一个用于人脸比对的函数,通常用于人脸识别任务中。这个函数接受两个参数:
face_encoding1: 表示第一个人脸的编码,通常是一个128维的向量,用于表示人脸的特征。face_encoding2: 表示第二个人脸的编码,同样是一个128维的向量。函数的作用是比较这两个人脸编码,判断它们是否来自同一个人脸。具体来说,它会计算这两个人脸编码之间的欧氏距离(Euclidean distance),如果距离小于一个阈值(一般来说是0.6),就认为这两个人脸是同一个人,返回True;否则返回False。
import cv2
import face_recognition# 加载图像文件
img1 = face_recognition.load_image_file('lyf1.png')
img2 = face_recognition.load_image_file('lyf2.png')
# 将图像从 BGR 格式转换为 RGB 格式
img1 = cv2.cvtColor(img1, cv2.COLOR_BGR2RGB)
img2 = cv2.cvtColor(img2, cv2.COLOR_BGR2RGB)
# 第一个人的人脸位置信息
faceloc1 = face_recognition.face_locations(img1)[0]
faceloc2 = face_recognition.face_locations(img2)[0]
# 提取人脸编码
face_encoding1 = face_recognition.face_encodings(img1, [faceloc1])[0]
face_encoding2 = face_recognition.face_encodings(img2, [faceloc2])[0]
#框出人脸
cv2.rectangle(img1, (faceloc1[3], faceloc1[0]), (faceloc1[1], faceloc1[2]), (0, 255, 0), 3)
cv2.rectangle(img2, (faceloc2[3], faceloc2[0]), (faceloc2[1], faceloc2[2]), (0, 255, 0), 3)
#比对人脸特征
res = face_recognition.compare_faces([face_encoding1],face_encoding2)
print(res)
#打印人脸位置信息
# print(faceloc1)
# print(faceloc2)cv2.imshow('lyf1', img1)
cv2.imshow('lyf2', img2)
cv2.waitKey(0)
效果如下

这里可以看见,打印了True,说明为同一个人
到这里就完成了对两个人脸的比对,感兴趣的可以关注一下,谢谢
相关文章:
Opencv学习项目3——人脸识别
之前我们获取了一张图像的人脸信息,现在我们来使用特征点分析来匹配两张lyf照片的相似度 获取两张图片的人脸信息 import cv2 import face_recognition# 加载图像文件 img1 face_recognition.load_image_file(lyf1.png) img2 face_recognition.load_image_file(l…...
的使用总结+代码举例)
【js自学打卡11】生成器函数(generator函数)的使用总结+代码举例
力扣的js入门免费题刷完了,开始自己找题练练,顺便捡捡知识点 力扣2649 1.思路 一眼递归,但事实证明也可以直接flat手撕。 arr.flat(Infinity) //直接扁平化到最底层涉及到了一些关于生成器和异步编程相关的知识点,学一下。 2.…...

深入了解jdbc-02-CRUD
文章目录 操作和访问数据库Statement操作数据表的弊端sql注入问题PreparedStatement类ResultSet类与ResultSetMetaData类资源的释放批量插入 操作和访问数据库 数据库的调用的不同方式: Statement:用于执行静态 SQL 语句并返回它所生成结果的对象。PreparedStatem…...
《基于 Kafka + Quartz 实现时限质控方案》
📢 大家好,我是 【战神刘玉栋】,有10多年的研发经验,致力于前后端技术栈的知识沉淀和传播。 💗 🌻 CSDN入驻不久,希望大家多多支持,后续会继续提升文章质量,绝不滥竽充数…...

浏览器的卡顿与react的解决思路
以下内容是阅读过程中结合自己的思考而诞生的产物,不一定准确,但相反的,可能个人对实际情况有很大的误解。 仅做参考,欢迎指正。 前面提到浏览器显示的其实是渲染流程最后渲染出来的一张图片,而一个行为引起的副作用需…...

XXE:XML外部实体引入
XXE漏洞 如果服务器没有对客户端的xml数据进行限制,且版本较低的情况下,就可能会产生xxe漏洞 漏洞利用流程 1.客户端发送xml文件,其中dtd存在恶意的外部实体引用 2.服务器进行解析 3.服务器返回实体引用内容 危害:任意文件读…...

3D培训大师创新培训体验,加速空调关键组件的高效精准安装
如今,空调系统的复杂性和精密性与日俱增,对专业技术人员的要求也日益提高。尤其是决定空调是否能平稳运行的空调关键组件的装配培训,不再局限于传统的理论讲解和实体模型演示,而是更注重数字化、沉浸式学习。 案例背景 某空调公…...

PyTorch 深度学习实践-循环神经网络(高级篇)
视频指路 参考博客笔记 参考笔记二 文章目录 上课笔记总代码练习 上课笔记 个人能力有限,重看几遍吧,第一遍基本看不懂 名字的每个字母都是一个特征x1,x2,x3…,一个名字是一个序列 rnn用GRU 用ASCII表作为词典,长度为128&#x…...

这才是老板喜欢的电子信息类简历
点击可直接使用...

MySQL学习之事务,锁机制
事务 什么是事务? 事务就是逻辑上的一组操作,要么全做,要么全不做 事务经典例子:转账,转账需要两个操作,从一个人账户上减钱,在另一个账户上加钱,比如说小红给小明转账100元&…...

开源知识付费小程序源码 内容付费系统php源码 含完整图文部署教程
在当今数字化时代,知识付费作为一种新型的经济模式,正逐渐受到越来越多内容创作者、专家及商家的青睐。开源知识付费小程序源码和内容付费系统PHP源码作为实现这一模式的重要工具,为构建高效、安全、可扩展的知识付费平台提供了强大的技术支持…...

时序数据库如何选型?详细指标总结!
工业物联网场景,如何判断什么才是好的时序数据库? 工业物联网将机器设备、控制系统与信息系统、业务过程连接起来,利用海量数据进行分析决策,是智能制造的基础设施,并影响整个工业价值链。工业物联网机器设备感知形成了…...

【前端】JavaScript入门及实战51-55
文章目录 51 函数52 函数的参数53 返回值54 练习55 return 51 函数 <!DOCTYPE html> <html> <head> <title></title> <meta charset "utf-8"> <script type"text/javascript">/* 函数:1. 函数也是…...

【引领未来智造新纪元:量化机器人的革命性应用】
在日新月异的科技浪潮中,量化机器人正以其超凡的智慧与精准的操作,悄然改变着各行各业的生产面貌,成为推动产业升级、提升竞争力的关键力量。今天,让我们一同探索量化机器人在不同领域的广泛应用价值,见证它如何以科技…...

山东航空小程序查询
山东航空小程序 1) 请求地址 https://scxcx.sda.cn/mohe/proxy?url/trp/ticket/search 2) 调用方式:HTTP post 3) 接口描述: 接口描述详情 4) 请求参数: {"dep": "TAO","arr": "HRB","flightDate&qu…...

MySQL添加索引时会锁表吗?
目录 简介Online DDL概念Online DDL用法总结 简介 在MySQL5.5以及之前的版本,通常更改数据表结构操作(DDL)会阻塞对表数据的增删改操作(DML)。 MySQL5.6提供Online DDL之后可支持DDL与DML操作同时执行,降低…...
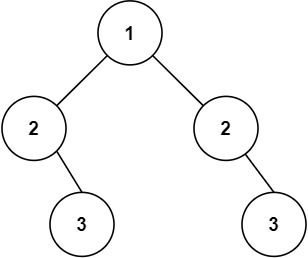
算法日记day 16(二叉树的广度优先遍历|反转、对称二叉树)
一、二叉树的层序遍历 题目: 给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。 示例 1: 输入:root [3,9,20,null,null,15,7] 输出:[[3]…...

PolarisMesh源码系列--Polaris-Go注册发现流程
导语 北极星是腾讯开源的一款服务治理平台,用来解决分布式和微服务架构中的服务管理、流量管理、配置管理、故障容错和可观测性问题。在分布式和微服务架构的治理领域,目前国内比较流行的还包括 Spring Cloud,Apache Dubbo 等。在 Kubernete…...

vue3 vxe-grid修改currentPage,查询数据的时候,从第一页开始查询
1、当我们设置好VxeGrid.Options进行数据查询的时候,下面是可能的设置: const gridOptions reactive<BasicTableProps>({id: UserTable,showHeaderOverflow: false,showOverflow: true,keepSource: true,columns: userColumns,size: small,pagerConfig: {cur…...
电商数据集成之电商商品信息采集系统架构设计||电商API接口
一、引言 本架构设计文档旨在阐述基于 Selenium 的电商商品信息采集系统的整体架构,包括系统视图、逻辑视图、物理视图、开发视图和进程视图,并提供一个简单的采集电商商品信息的 demo。该系统通过模拟浏览器行为,实现对电商商品信息的自…...

【粉丝福利社】三维重建技术与实践:基于NeRF与3DGS
💎【行业认证权威头衔】 ✔ 华为云天团核心成员:特约编辑/云享专家/开发者专家/产品云测专家 ✔ 开发者社区全满贯:CSDN博客&商业化双料专家/阿里云签约作者/腾讯云内容共创官/掘金&亚马逊&51CTO顶级博主 ✔ 技术生态共建先锋&am…...

【NotebookLM播客化实战指南】:3步将静态文档转化为高转化率AI播客,92%用户留存提升实测数据曝光
更多请点击: https://intelliparadigm.com 第一章:NotebookLM文档播客化功能详解 NotebookLM 是 Google 推出的基于用户上传文档进行 AI 增强理解与交互的实验性工具,其“文档播客化”(Document Podcasting)功能允许用…...
)
保姆级教程:用COMSOL 5.6搞定房间声学模态分析(附网格划分避坑指南)
保姆级教程:用COMSOL 5.6实现高精度房间声学模态分析 当你第一次尝试用COMSOL分析房间的声学特性时,是否曾被复杂的参数设置和网格划分搞得晕头转向?本文将带你一步步攻克声学模态分析中最关键的环节——特征频率求解与网格优化。不同于泛泛而…...

如何快速解密RPG Maker加密文件:终极解密工具使用指南
如何快速解密RPG Maker加密文件:终极解密工具使用指南 【免费下载链接】RPGMakerDecrypter Tool for decrypting and extracting RPG Maker XP, VX and VX Ace encrypted archives and MV and MZ encrypted files. 项目地址: https://gitcode.com/gh_mirrors/rp/R…...

【仿真实战】AnyLogic地铁站客流仿真:从零搭建带安检与限流的多层车站模型
1. 从零开始搭建地铁站仿真模型 第一次接触AnyLogic做地铁站客流仿真时,我完全被各种模块和参数搞晕了。后来在几个实际项目中摸爬滚打,终于总结出一套小白也能快速上手的方法。这次我们就来搭建一个包含安检区和限流措施的多层地铁站模型,整…...

3步解锁SWF逆向工程:JPEXS开源工具深度解析
3步解锁SWF逆向工程:JPEXS开源工具深度解析 【免费下载链接】jpexs-decompiler JPEXS Free Flash Decompiler 项目地址: https://gitcode.com/gh_mirrors/jp/jpexs-decompiler 你是否曾面对一个陈旧的SWF文件束手无策?当Flash技术逐渐退出历史舞台…...

Stata 数据处理实战:时间序列数据的日期转换与聚合
1. 时间序列数据处理的常见痛点 刚接触时间序列分析的朋友们,经常会遇到这样的困扰:从Excel导入的数据明明是日期格式,到了Stata里却变成了看不懂的字符;想按周汇总销售数据,却发现系统根本不认识"2023-W15"…...

别再手动描边了!用AutoCAD 2022画好异形PCB板框,一键导入Cadence SPB17.4
高效绘制异形PCB板框:AutoCAD与Cadence的无缝协作指南 在硬件设计领域,异形PCB板框的绘制一直是工程师们面临的挑战。传统矩形板框的绘制相对简单,但当项目需求涉及圆弧、缺口或不规则轮廓时,直接在Cadence Allegro中操作往往效率…...

苹果为何拒绝TD-SCDMA特供版iPhone?复盘技术标准与市场时机的战略博弈
1. 项目概述:一场关于苹果与中国移动的世纪猜想2012年的科技圈,空气中弥漫着一股躁动与期待。几乎所有的行业分析师和手机发烧友都在讨论同一个话题:苹果公司是否会为了全球最大的移动运营商——中国移动,专门推出一款支持TD-SCDM…...

如何用3分钟搞定视频字幕提取?揭秘这款本地化硬字幕提取神器
如何用3分钟搞定视频字幕提取?揭秘这款本地化硬字幕提取神器 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含字幕区域检测、字…...