随机梯度下降 (Stochastic Gradient Descent, SGD)
SGD 是梯度下降法的一种变体。与批量梯度下降法不同,SGD 在每次迭代中仅使用一个样本(或一个小批量样本)的梯度来更新参数。它能更快地更新参数,并且可以更容易地跳出局部最优解。
原理
SGD 的基本思想是通过在每次迭代中使用不同的样本,快速更新参数,并逐步逼近目标函数的最小值。
核心公式
在第 ⅰ次迭代中,选择第 ⅰ个样本 ⅹ(ⅰ) 并计算梯度:
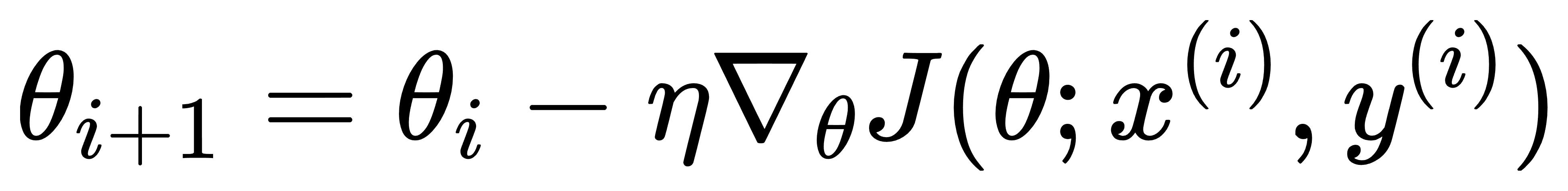
其中:
- θi为第ⅰ次迭代的参数
- η 为学习率
- J( θ; x(i), y(i) )为目标函数在第ⅰ个样本 ⅹ(ⅰ)上的梯度
目标是最小化目标函数 J(θ),即:

Python 示例
我们将使用Scikit-Learn中的线性回归模型进行训练,并绘制多个数据分析图形。具体的图形包括:损失函数的收敛图、预测结果与实际结果的比较图、以及参数更新的轨迹图。
数据生成和分割
首先,我们生成一个带有噪声的线性回归数据集,并将其划分为训练集和测试集。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.linear_model import SGDRegressor
from sklearn.metrics import mean_squared_error# 生成回归数据集
X, y = make_regression(n_samples=1000, n_features=1, noise=20, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 打印前5条数据和对应的目标值
print("前5条训练数据:")
print(X_train[:5])
print("前5个训练目标值:")
print(y_train[:5])SGD 回归模型初始化
使用 SGDRegressor 初始化随机梯度下降回归模型,设定最大迭代次数为1,禁用容忍度检查,启用 warm_start,每次迭代使用上次的解,设定常数学习率和初始学习率。
# 初始化SGD回归模型
sgd = SGDRegressor(max_iter=1, tol=-np.infty, warm_start=True, learning_rate='constant', eta0=0.01, random_state=42)训练模型
进行多次迭代(epochs),在每个 epoch 进行一次模型训练,记录训练误差和测试误差,以及每次迭代后的系数值。
# 记录训练过程中的信息
n_epochs = 50
train_errors, test_errors = [], []
coef_updates = []# 训练模型
for epoch in range(n_epochs):sgd.fit(X_train, y_train)y_train_predict = sgd.predict(X_train)y_test_predict = sgd.predict(X_test)train_errors.append(mean_squared_error(y_train, y_train_predict))test_errors.append(mean_squared_error(y_test, y_test_predict))coef_updates.append(sgd.coef_.copy())绘制图形
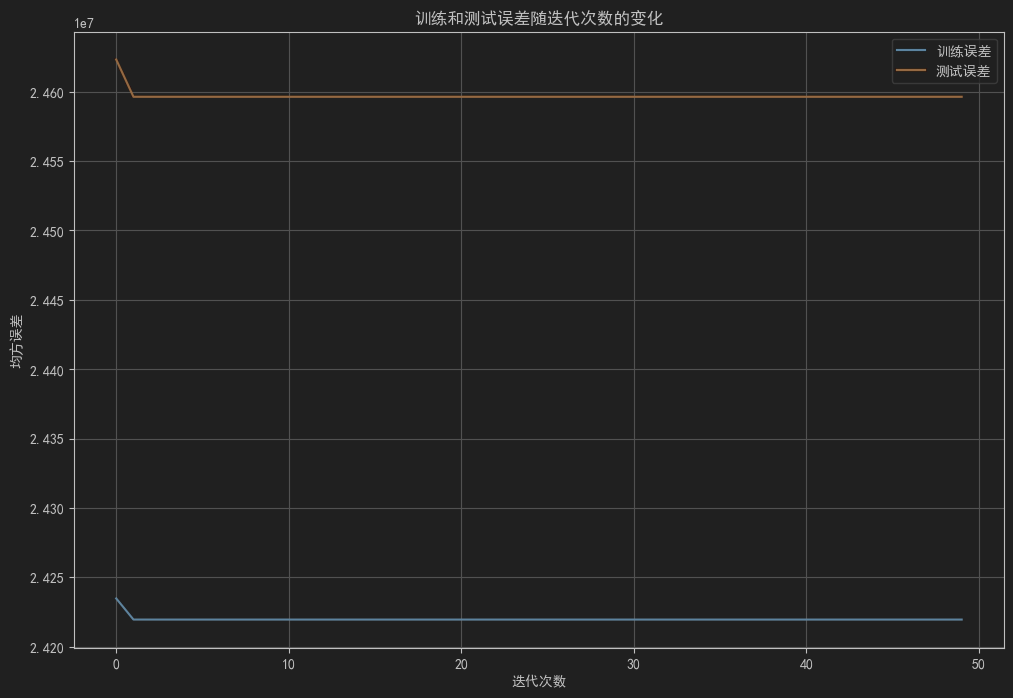
- 损失函数的收敛图:展示训练误差和测试误差随迭代次数的变化。
# 绘制损失函数的收敛图
plt.figure(figsize=(10, 6))
plt.plot(train_errors, label='训练误差')
plt.plot(test_errors, label='测试误差')
plt.xlabel('迭代次数')
plt.ylabel('均方误差')
plt.title('训练和测试误差随迭代次数的变化')
plt.legend()
plt.grid()
plt.show()- 预测结果与实际结果的比较图:展示测试集上的实际值和预测值的散点图。
# 绘制预测结果与实际结果的比较图
plt.figure(figsize=(10, 6))
plt.scatter(X_test, y_test, color='blue', label='实际值')
plt.scatter(X_test, y_test_predict, color='red', label='预测值')
plt.xlabel('输入特征')
plt.ylabel('目标值')
plt.title('实际值与预测值的比较')
plt.legend()
plt.grid()
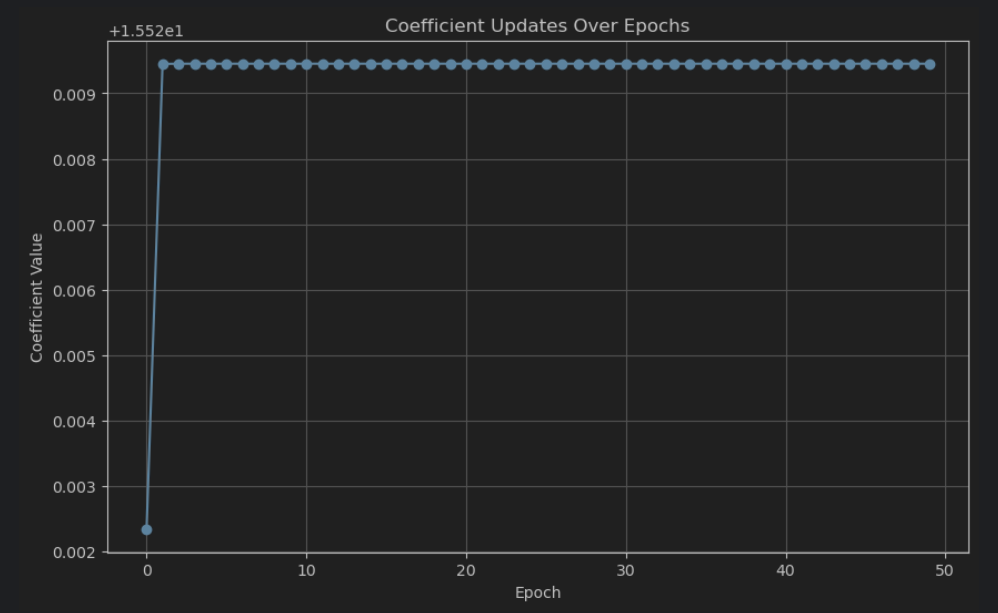
plt.show()- 参数更新的轨迹图:展示模型系数在每个 epoch 的更新情况。
# 绘制参数更新的轨迹图
coef_updates = np.array(coef_updates)
plt.figure(figsize=(10, 6))
plt.plot(coef_updates, marker='o')
plt.xlabel('迭代次数')
plt.ylabel('系数值')
plt.title('系数更新轨迹')
plt.grid()
plt.show()案例描述
我们将构建一个案例,使用随机梯度下降(SGD)算法对一个带有噪声的线性回归数据集进行训练和预测。具体步骤如下:
- 生成数据:使用
make_regression生成一个包含 1000 个样本和 1 个特征的回归数据集,并添加噪声。 - 数据分割:将数据集划分为训练集和测试集。
- 初始化模型:使用
SGDRegressor初始化随机梯度下降回归模型。 - 模型训练:通过多次迭代(epochs),在每个 epoch 中使用训练数据训练模型,并记录训练误差和测试误差,以及每次迭代后的模型系数。
- 结果可视化:绘制损失函数的收敛图、预测结果与实际结果的比较图,以及参数更新的轨迹图。
代码实现
以下是实现上述案例的详细代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.linear_model import SGDRegressor
from sklearn.metrics import mean_squared_error# 生成回归数据集
X, y = make_regression(n_samples=1000, n_features=1, noise=20, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 初始化SGD回归模型
sgd = SGDRegressor(max_iter=1, tol=None, warm_start=True, learning_rate='constant', eta0=0.01, random_state=42)# 记录训练过程中的信息
n_epochs = 50
train_errors, test_errors = [], []
coef_updates = []# 训练模型
for epoch in range(n_epochs):sgd.fit(X_train, y_train)y_train_predict = sgd.predict(X_train)y_test_predict = sgd.predict(X_test)train_errors.append(mean_squared_error(y_train, y_train_predict))test_errors.append(mean_squared_error(y_test, y_test_predict))coef_updates.append(sgd.coef_.copy())# 绘制损失函数的收敛图
plt.figure(figsize=(10, 6))
plt.plot(train_errors, label='Train Error')
plt.plot(test_errors, label='Test Error')
plt.xlabel('Epoch')
plt.ylabel('Mean Squared Error')
plt.title('Training and Test Errors Over Epochs')
plt.legend()
plt.grid()
plt.show()# 绘制预测结果与实际结果的比较图
plt.figure(figsize=(10, 6))
# 使用最后一次迭代的预测结果
plt.scatter(X_test, y_test, color='blue', label='Actual')
plt.scatter(X_test, y_test_predict, color='red', label='Predicted')
plt.xlabel('Input Feature')
plt.ylabel('Target')
plt.title('Actual vs Predicted')
plt.legend()
plt.grid()
plt.show()# 绘制参数更新的轨迹图
coef_updates = np.array(coef_updates)
plt.figure(figsize=(10, 6))
plt.plot(coef_updates, marker='o')
plt.xlabel('Epoch')
plt.ylabel('Coefficient Value')
plt.title('Coefficient Updates Over Epochs')
plt.grid()
plt.show()详细步骤解释
- 生成数据:
-
- 使用
make_regression生成一个线性回归数据集,包含 1000 个样本,每个样本有 1 个特征,并添加噪声以模拟真实数据中的误差。 - 使用
train_test_split将数据集划分为训练集(80%)和测试集(20%)。
- 使用
- 初始化模型:
-
- 使用
SGDRegressor初始化随机梯度下降回归模型,设置max_iter=1和warm_start=True以确保每次迭代都使用上次的解。 - 设置常数学习率(
learning_rate='constant')和初始学习率(eta0=0.01)。
- 使用
- 模型训练:
-
- 进行 50 次迭代(epochs),在每次迭代中使用训练数据训练模型。
- 记录每次迭代的训练误差和测试误差,以及模型系数。
- 结果可视化:
-
- 损失函数的收敛图:展示训练误差和测试误差随迭代次数的变化,以评估模型的收敛情况。

-
- 预测结果与实际结果的比较图:展示测试集上的实际值和预测值的散点图,以评估模型的预测效果。
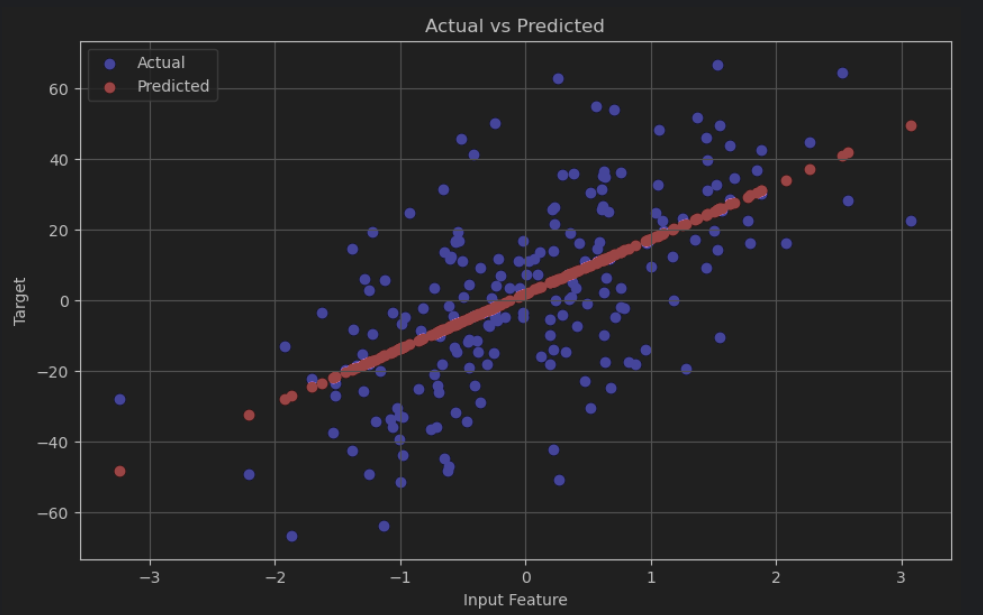
-
- 参数更新的轨迹图:展示模型系数在每个 epoch 的更新情况,以了解参数的收敛过程。
通过以上步骤,我们可以全面了解随机梯度下降算法在回归问题中的应用,以及模型训练过程中的各项指标变化情况。
结论
在这个案例中,我们生成了一个带有噪声的线性回归数据集,并使用随机梯度下降(SGD)进行模型训练。通过分析损失函数的收敛图、预测结果与实际结果的比较图,以及参数更新的轨迹图,我们可以清楚地了解模型的训练过程和效果。SGD 由于在每次迭代中使用了不同的样本,使得参数更新更加频繁,有助于更快地逼近目标函数的最小值。
案例:用随机梯度下降法预测员工工资
案例描述
假设你是一位外企人力资源分析师,希望根据员工的工作经验(年)和学历水平(学位)来预测他们的工资。你可以使用随机梯度下降法(SGD)来进行线性回归分析,以构建一个工资预测模型。
场景细节
- 目标:根据员工的工作经验和学历水平预测工资。
- 数据集:我们将生成一个模拟的数据集,包括1000个样本,每个样本包含工作经验(年)、学历水平(学位,使用1-3表示高中、学士、硕士)和工资(美元)。数据集带有一定的噪声,以模拟真实数据中的误差。
- 步骤:
-
- 生成数据集。
- 划分数据集为训练集和测试集。
- 初始化随机梯度下降法回归模型。
- 训练模型并记录训练误差和测试误差。
- 可视化结果,包括损失函数的收敛图、预测结果与实际结果的比较图、以及参数更新的轨迹图。
代码实现
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import rcParams
from sklearn.model_selection import train_test_split
from sklearn.linear_model import SGDRegressor
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import StandardScaler# 设置默认字体
rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 生成模拟员工工资数据
np.random.seed(42)
n_samples = 1000
X_experience = np.random.rand(n_samples, 1) * 40 # 工作经验在0到40年之间
X_education = np.random.randint(1, 4, size=(n_samples, 1)) # 学历水平:1-高中,2-学士,3-硕士
X = np.hstack([X_experience, X_education])
y = 20000 + 3000 * X_experience + 10000 * X_education + np.random.randn(n_samples, 1) * 5000 # 工资公式,带有噪声# 检查生成的数据
print("前5条数据和对应的目标值:")
print(X[:5])
print(y[:5])# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 标准化数据
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)# 初始化SGD回归模型
sgd = SGDRegressor(max_iter=1, tol=None, warm_start=True, learning_rate='constant', eta0=0.01, random_state=42)# 记录训练过程中的信息
n_epochs = 50
train_errors, test_errors = [], []
coef_updates = []# 训练模型
for epoch in range(n_epochs):sgd.fit(X_train_scaled, y_train.ravel())y_train_predict = sgd.predict(X_train_scaled)y_test_predict = sgd.predict(X_test_scaled)train_errors.append(mean_squared_error(y_train, y_train_predict))test_errors.append(mean_squared_error(y_test, y_test_predict))coef_updates.append(sgd.coef_.copy())# 检查预测值范围
print("预测值的最大值:", np.max(y_test_predict))
print("预测值的最小值:", np.min(y_test_predict))# 绘制损失函数的收敛图
plt.figure(figsize=(12, 8))
plt.plot(train_errors, label='训练误差')
plt.plot(test_errors, label='测试误差')
plt.xlabel('迭代次数')
plt.ylabel('均方误差')
plt.title('训练和测试误差随迭代次数的变化')
plt.legend()
plt.grid()
plt.show()# 绘制预测结果与实际结果的比较图
plt.figure(figsize=(12, 8))
plt.scatter(X_test[:, 0], y_test, color='blue', label='实际值')
plt.scatter(X_test[:, 0], y_test_predict, color='red', label='预测值')
plt.xlabel('工作经验(年)')
plt.ylabel('工资(美元)')
plt.title('实际值与预测值的比较')
plt.legend()
plt.grid()
plt.show()# 绘制参数更新的轨迹图
coef_updates = np.array(coef_updates)
plt.figure(figsize=(12, 8))
for i in range(coef_updates.shape[1]):plt.plot(coef_updates[:, i], marker='o', label=f'系数 {i}')
plt.xlabel('迭代次数')
plt.ylabel('系数值')
plt.title('系数更新轨迹')
plt.legend()
plt.grid()
plt.show()加入了标准化步骤,并包含所有检查点以确保数据的范围和模型的训练效果正确。
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import rcParams
from sklearn.model_selection import train_test_split
from sklearn.linear_model import SGDRegressor
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import StandardScaler# 设置默认字体
rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 生成模拟员工工资数据
np.random.seed(42)
n_samples = 1000
X_experience = np.random.rand(n_samples, 1) * 40 # 工作经验在0到40年之间
X_education = np.random.randint(1, 4, size=(n_samples, 1)) # 学历水平:1-高中,2-学士,3-硕士
X = np.hstack([X_experience, X_education])
y = 20000 + 3000 * X_experience + 10000 * X_education + np.random.randn(n_samples, 1) * 5000 # 工资公式,带有噪声# 检查生成的数据
print("前5条数据和对应的目标值:")
print(X[:5])
print(y[:5])# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 标准化数据
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)# 初始化SGD回归模型
sgd = SGDRegressor(max_iter=1, tol=None, warm_start=True, learning_rate='constant', eta0=0.01, random_state=42)# 记录训练过程中的信息
n_epochs = 50
train_errors, test_errors = [], []
coef_updates = []# 训练模型
for epoch in range(n_epochs):sgd.fit(X_train_scaled, y_train.ravel())y_train_predict = sgd.predict(X_train_scaled)y_test_predict = sgd.predict(X_test_scaled)train_errors.append(mean_squared_error(y_train, y_train_predict))test_errors.append(mean_squared_error(y_test, y_test_predict))coef_updates.append(sgd.coef_.copy())# 检查预测值范围
print("预测值的最大值:", np.max(y_test_predict))
print("预测值的最小值:", np.min(y_test_predict))# 绘制损失函数的收敛图
plt.figure(figsize=(12, 8))
plt.plot(train_errors, label='训练误差')
plt.plot(test_errors, label='测试误差')
plt.xlabel('迭代次数')
plt.ylabel('均方误差')
plt.title('训练和测试误差随迭代次数的变化')
plt.legend()
plt.grid()
plt.show()# 绘制预测结果与实际结果的比较图
plt.figure(figsize=(12, 8))
plt.scatter(X_test[:, 0], y_test, color='blue', label='实际值')
plt.scatter(X_test[:, 0], y_test_predict, color='red', label='预测值')
plt.xlabel('工作经验(年)')
plt.ylabel('工资(美元)')
plt.title('实际值与预测值的比较')
plt.legend()
plt.grid()
plt.show()# 绘制参数更新的轨迹图
coef_updates = np.array(coef_updates)
plt.figure(figsize=(12, 8))
for i in range(coef_updates.shape[1]):plt.plot(coef_updates[:, i], marker='o', label=f'系数 {i}')
plt.xlabel('迭代次数')
plt.ylabel('系数值')
plt.title('系数更新轨迹')
plt.legend()
plt.grid()
plt.show()这个代码片段包括了数据生成、标准化、模型训练和可视化步骤。通过标准化数据,我们可以帮助模型更好地收敛,并避免由于数据范围问题导致的异常结果。
详细步骤解释
- 生成数据:
-
- 使用
numpy生成一个包含工作经验(0-40年)和学历水平(高中、学士、硕士)的模拟数据集。 - 使用工资公式生成目标值,公式中包括常数项、工作经验和学历水平的系数,以及一定的随机噪声。
- 使用
- 划分数据集:
-
- 使用
train_test_split将数据集划分为训练集(80%)和测试集(20%)。
- 使用
- 初始化模型:
-
- 使用
SGDRegressor初始化随机梯度下降回归模型,设置max_iter=1和warm_start=True以确保每次迭代都使用上次的解。 - 设置常数学习率(
learning_rate='constant')和初始学习率(eta0=0.01)。
- 使用
- 模型训练:
-
- 进行 50 次迭代(epochs),在每次迭代中使用训练数据训练模型。
- 记录每次迭代的训练误差和测试误差,以及模型系数。
- 结果可视化:
-
- 损失函数的收敛图:展示训练误差和测试误差随迭代次数的变化。

标准化:
-
- 预测结果与实际结果的比较图:展示测试集上的实际值和预测值的散点图。
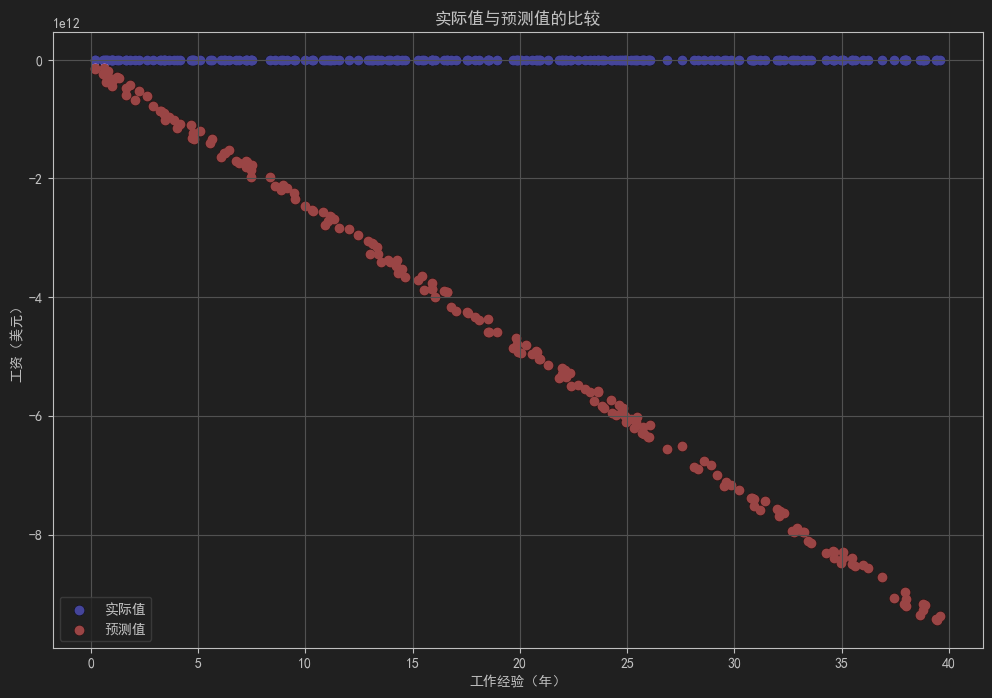
标准化:

-
- 参数更新的轨迹图:展示模型系数在每个 epoch 的更新情况。

标准化:

结论
通过以上步骤,我们构建了一个随机梯度下降法的回归模型,用于预测员工的工资。通过分析损失函数的收敛图、预测结果与实际结果的比较图,以及参数更新的轨迹图,我们可以清楚地了解模型的训练过程和效果。随机梯度下降法能够更快地更新参数,并且可以更容易地跳出局部最优解,从而更快地逼近目标函数的最小值。
相关文章:
随机梯度下降 (Stochastic Gradient Descent, SGD)
SGD 是梯度下降法的一种变体。与批量梯度下降法不同,SGD 在每次迭代中仅使用一个样本(或一个小批量样本)的梯度来更新参数。它能更快地更新参数,并且可以更容易地跳出局部最优解。 原理 SGD 的基本思想是通过在每次迭代中使用不…...

TDengine 3.3.2.0 发布:新增 UDT 及 Oracle、SQL Server 数据接入
经过数月的开发和完善,TDengine 3.3.2.0 版本终于问世了。这一版本中既有针对开源社区的功能优化,也有从企业级用户需求出发做出的功能调整。在开源版本中,我们增强了系统的灵活性和兼容性;而在企业级版本中,新增了关键…...

Ubuntu 24.04 LTS 无法打开Chrome浏览器
解决办法: 删除本地配置文件,再次点击Chrome图标,即可打开。 rm ~/.config/google-chrome/ -rf ref: Google chrome not opening in Ubuntu 22.04 LTS - Ask Ubuntu...

linux中RocketMQ安装(单机版)及springboot中的使用
文章目录 一、安装1.1、下载RocketMQ1.2、将下载包上传到linux中,然后解压1.3、修改runserver.sh的jvm参数大小(根据自己服务器配置来修改)1.4、启动mqnamesrv (类似于注册中心)1.5、修改runbroker.sh的jvm参数大小&am…...
亚信安全终端一体化解决方案入选应用创新典型案例
近日,由工业和信息化部信息中心主办的2024信息技术应用创新发展大会暨解决方案应用推广大会成功落幕,会上集中发布了一系列技术水平先进、应用效果突出、产业带动性强的信息技术创新工作成果。其中,亚信安全“终端一体化安全运营解决方案”在…...

Django视图与URLs路由详解
在Django Web框架中,视图(Views)和URLs路由(URL routing)是Web应用开发的核心概念。它们共同负责将用户的请求映射到相应的Python函数,并返回适当的响应。本篇博客将深入探讨Django的视图和URLs路由系统&am…...
怎么关闭 Windows 安全中心,手动关闭 Windows Defender 教程
Windows 安全中心(也称为 Windows Defender Security Center)是微软 Windows 操作系统内置的安全管理工具,用于监控和控制病毒防护、防火墙、应用和浏览器保护等安全功能。然而,在某些情况下,用户可能需要关闭 Windows…...

洛谷看不了别人主页怎么办
首先,我们先点进去 可以看到,看不了一点 那我们看向上方,就可以发现,我们那有个URL,选中 把光标插到n和/中间 把.cn删了,变成国际服 我们就可以看了 但是国际服还没搭建完,跳转的时候可能503&a…...

邮件安全篇:企业电子邮件安全涉及哪些方面?
1. 邮件安全概述 企业邮件安全涉及多个方面,旨在保护电子邮件通信的机密性、完整性和可用性,防止数据泄露、欺诈、滥用及其他安全威胁。本文从身份验证与防伪、数据加密、反垃圾邮件和反恶意软件防护、邮件内容过滤与审计、访问控制与权限管理、邮件存储…...

软件测试09 自动化测试技术(Selenium)
重点/难点 重点:理解自动化测试的原理及其流程难点:Selinum自动化测试工具的使用 目录 系统测试 什么是系统测试什么是功能测试什么是性能测试常见的性能指标有哪些 自动化测试概述 测试面临的问题 测试用例数量增多,工作量增大ÿ…...

记录解决springboot项目上传图片到本地,在html里不能回显的问题
项目场景: 项目场景:在我的博客系统里:有个相册模块:需要把图片上传到项目里,在html页面上显示 解决方案 1.建一个文件夹 例如在windows系统下。可以在项目根目录下建个photos文件夹,把上传的图片文件…...

C++ 中 const 关键字
C 中 const 关键字 2009-02-19 2024-07-23 补充C11后的做法 在 C 中,const 是一个关键字(也称为保留字),它用于指定变量或对象的值在初始化后不能被修改。关键字是编程语言中具有特殊含义的词汇,编译器会识别这些词并…...

客梯自动监测识别摄像机
当今社会,随着城市建设的快速发展,客梯作为现代化建筑不可或缺的一部分,其安全性与效率显得尤为重要。为了提升客梯的安全管理水平,智能监测技术应运而生,尤其是客梯自动监测识别摄像机系统的应用,为乘客和…...

为什么那么多人学习AI绘画?工资香啊!
在当今这个科技日新月异的时代,AI绘画作为数字艺术与人工智能融合的璀璨成果,正吸引着无数人投身其中,而“工资香啊!”无疑是这一热潮背后不可忽视的驱动力之一。 AI绘画的高薪待遇是吸引众多学习者的关键因素。随着市场对AI艺术…...

国产JS库(js-tool-big-box)7月度总结
js-tool-big-box开发已经有3个月了,团队内的小伙伴进行了热烈的讨论,持续做了功能迭代。小伙伴们也做了艰苦卓绝的文档分享,有纯功能分享类的,有带有小故事的,有朋友们利用自己独自网站分发分享的。7月份快要结束了&am…...

c++ 高精度加法(只支持正整数)
再给大家带来一篇高精度,不过这次是高精度加法!话不多说,开整! 声明 与之前那篇文章一样,如果看起来费劲可以结合总代码来看 定义 由于加法进位最多进1位,所以我们的结果ans[]的长度定义为两个加数中最…...

python键盘操作工具:ctypes、pyautogui
这里模拟 Win Ctrl L 组合键 1、ctypes ctypes库,它允许我们直接调用Windows API来模拟键盘输入。 import ctypes import time# 定义所需的常量和结构 LONG ctypes.c_long DWORD ctypes.c_ulong ULONG_PTR ctypes.POINTER(DWORD) WORD ctypes.c_ushortclass…...

计算机网络发展历史
定义和基本概念 计算机网络是由多个计算设备通过通信线路连接起来的集合,这些设备能够互相交换数据、消息和资源。计算机网络的核心功能是实现数据的远程传输和资源共享,它使得地理位置的限制被大大减弱,极大地促进了信息的自由流动和人类社…...

记录安装android studio踩的坑 win7系统
最近在一台新电脑上安装android studio,报了很多错误,也是费了大劲才解决,发出来大家一起避免一些问题,找到解决方法。 安装时一定要先安装jdk,cmd命令行用java -version查当前的版本,没有的话,先安装jdk,g…...

Python图形编程-PyGame快速入门
PyGame快速入门 文章目录 PyGame快速入门1、什么是PyGame2、安装PyGame3、创建PyGame窗口4、处理事件5、绘制对象6、移动对象7、加载和显示图像8、播放声音9、处理用户输入10、碰撞检测11、动画精灵12、管理游戏状态13、Pygame 中的典型主游戏循环1、什么是PyGame Pygame 是一…...

音乐无界:解锁网易云音乐灰色歌曲的智能方案
音乐无界:解锁网易云音乐灰色歌曲的智能方案 【免费下载链接】UnblockNeteaseMusic Revive unavailable songs for Netease Cloud Music 项目地址: https://gitcode.com/gh_mirrors/un/UnblockNeteaseMusic 你是否曾经打开网易云音乐,发现心爱的歌…...

大模型行业爆发式增长,程序员转型的最佳时机,现在上车还不晚
文章目录前言一、2026年大模型行业爆发式增长,风口已经来了1.1 市场规模爆炸式增长,企业需求井喷1.2 人才缺口巨大,薪资水涨船高1.3 技术门槛大幅降低,普通人也能上车二、程序员转型大模型,这4个方向性价比最高2.1 AI工…...

ClawPanel:AI Agent统一管理面板,内置智能助手实现自动化运维
1. 项目概述与核心价值 如果你正在寻找一个能帮你统一管理 OpenClaw 和 Hermes Agent 这两个热门 AI Agent 框架的工具,并且希望这个工具本身也足够智能,能帮你解决安装、配置、排障等一系列繁琐问题,那么 ClawPanel 就是你一直在等的那个“…...

TQVaultAE终极指南:告别泰坦之旅仓库混乱,打造完美装备管理系统
TQVaultAE终极指南:告别泰坦之旅仓库混乱,打造完美装备管理系统 【免费下载链接】TQVaultAE Extra bank space for Titan Quest Anniversary Edition 项目地址: https://gitcode.com/gh_mirrors/tq/TQVaultAE 还在为《泰坦之旅》的仓库空间不足而…...

树莓派新手避坑指南:从烧录系统到VNC远程桌面的10个常见错误
树莓派新手避坑指南:从烧录系统到远程桌面的10个致命陷阱 第一次接触树莓派时,那种既兴奋又忐忑的心情我至今记忆犹新。看着这块信用卡大小的板子,很难想象它能完成那么多酷炫的项目。但现实往往很骨感——当我按照网上教程一步步操作时&…...

NVIDIA NeMo Curator:大模型数据预处理与质量控制的工业化解决方案
1. 项目概述:从数据洪流到高质量语料库的“炼金术”如果你正在构建或微调一个大语言模型,那么你肯定对“数据”这个词又爱又恨。爱的是,它是模型智能的源泉;恨的是,原始数据就像未经提炼的矿石,充斥着杂质、…...

永恒之蓝完全实战:从SMB扫描到SYSTEM权限,注册表后门+键盘记录+清日志一条龙
摘要: 永恒之蓝(MS17-010)是2017年WannaCry勒索病毒的罪魁祸首,利用SMBv1协议漏洞可远程获取Windows系统最高权限。本文将基于Kali Linux 2026.1与Windows Server 2008 R2靶机,使用Metasploit完整演示:漏洞…...

CANN Cosmos NPU多卡并行优化
Cosmos 昇腾 NPU 多卡并行优化说明 【免费下载链接】cann-recipes-embodied-intelligence 本项目针对具身智能业务中的典型模型、加速算法,提供基于CANN平台的优化样例 项目地址: https://gitcode.com/cann/cann-recipes-embodied-intelligence 1. 优化概述 …...

MAA助手终极指南:5步掌握明日方舟全自动游戏辅助工具
MAA助手终极指南:5步掌握明日方舟全自动游戏辅助工具 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https://gitc…...

MCP Builder:极速构建AI助手工具服务器的生成式CLI工具
1. 项目概述:MCP Builder,一个为“氛围编码”而生的生产力工具如果你和我一样,每天都在和AI助手(比如Cursor、Claude Desktop)打交道,想把它们变成你专属的“瑞士军刀”,那你肯定绕不开一个东西…...