Transformer-Bert---散装知识点---mlm,nsp
本文记录的是笔者在了解了transformer结构后嗑bert中记录的一些散装知识点,有时间就会整理收录,希望最后能把transformer一个系列都完整的更新进去。
1.自监督学习
bert与原始的transformer不同,bert是使用大量无标签的数据进行预训练,下游则使用少量的标注数据进行微调。预训练使用的就是自监督学习。
自监督学习直白来说就是对原始数据添加辅助任务来使得数据能够根据自身生成标签。
举几个简单的例子来解释一下常见的自监督学习:(ps:插一嘴,bert使用的是mlm,会在最后的例子中解释)
1.1图像类:
1.1.1填充:
将图片扣掉一块,让模型进行填充。
输入:扣掉一块的图片
输出:填充部分
标签:原图扣掉的部分
1.1.2拼图
选取图片中的一部分图片A以及其相邻的某一部分图片B作为输入,预测图B于图A的相对位置。
输入:  (A图) +
(A图) +  (B图)
(B图)
输出:1-8之间的整数,代表图B相对于图A的位置
标签:5(对应原图中数字5的部分)
这类辅助任务就旨在训练模型对于局部特征分布位置的识别能力。
1.2 文本类
1.2.1 完形填空
简单的来说就是在原始数据中扣掉一个或多个单词,让模型进行补充。
原始数据:All the world's a stage, and all the men and women merely players.
输入:All the world's a stage, and all the __ and women merely players.
输出:预测的单词
标签:men
1.2.2 Masked Language Model (MLM)(划重点拉)
MLM模型会随机的选择需要掩盖的单词(大概15%)(主要用于让模型习得语义、语法)
ps:由于是随机的一般我们都会指定一个参数max_pred用来表示一个句子最多被掩盖单词的数量
原始数据:All the world's a stage, and all the men and women merely players.
输入:All the world's a stage, and all the MASK and MASK merely players.
输出:预测的单词
标签:men, women
为了更好的适应下游任务,bert的作者对与MLM的规则进行了一定的微调。
被替换的单词:men : MASK-------------------80%
apple(随机单词)------10%
men(保持不变--)------10%
依然还是对标注为MASK的单词进行预测。
下面是论文原文对于这段的描述附上中英文对照
为了训练一个深度双向表示,我们简单地随机遮盖输入标记的一定比例,然后预测这些被遮盖的标记。我们称这个过程为“遮盖语言建模”(Masked Language Modeling,MLM),尽管文献中通常称之为Cloze任务(Taylor, 1953)。在这种情况下,对应于遮盖标记的最终隐藏向量被馈送到一个标准语言模型中的词汇表上的输出softmax层。在所有实验中,我们随机遮盖每个序列中所有WordPiece标记的15%。与去噪自编码器(Vincent et al., 2008)不同,我们仅预测遮盖的单词,而不是重构整个输入。
In order to train a deep bidirectional representation, we simply mask some percentage of the input tokens at random, and then predict those masked tokens. We refer to this procedure as a “masked LM” (MLM), although it is often referred to as a Cloze task in the literature (Taylor, 1953). In this case, the final hidden vectors corresponding to the mask tokens are fed into an output softmax over the vocabulary, as in a standard LM. In all of our experiments, we mask 15% of all WordPiece tokens in each sequence at random. In contrast to denoising auto-encoders (Vincent et al., 2008), we only predict the masked words rather than reconstructing the entire input.
尽管这使我们能够获得一个双向预训练模型,但其缺点是在预训练和微调之间创建了不匹配,因为在微调过程中不存在[MASK]标记。为了减轻这一问题,我们并不总是用实际的[MASK]标记替换“遮盖”的单词。训练数据生成器随机选择15%的标记位置进行预测。如果选择第i个标记,则有80%的概率将第i个标记替换为[MASK]标记,10%的概率将其替换为随机标记,以及10%的概率保持不变。然后,使用交叉熵损失来预测原始标记。我们在附录C.2中比较了这一过程的变化。
Although this allows us to obtain a bidirectional pre-trained model, a downside is that we are creating a mismatch between pre-training and fine-tuning, since the [MASK] token does not appear during fine-tuning. To mitigate this, we do not always replace “masked” words with the actual [MASK] token. The training data generator chooses 15% of the token positions at random for prediction. If the i-th token is chosen, we replace the i-th token with (1) the [MASK] token 80% of the time (2) a random token 10% of the time (3) the unchanged i-th token 10% of the time. Then, T i will be used to predict the original token with cross entropy loss. We compare variations of this procedure in Appendix C.2.
2.NSP任务
Bert中的NSP实质上就是一个二分类任务。
主要就是预测句子2是否是句子1的下一句,其中句子2有50%是真,50%是从句库中随机挑选的句子。目的就是为了让模型学习到句子之间的关系。
输入:句子1 'esp' 句子2
ps:esp是词向量层中的特殊符号,表示一句话的结束,也常用来分割句子
输出:0或1
标签:0或1
相关文章:
Transformer-Bert---散装知识点---mlm,nsp
本文记录的是笔者在了解了transformer结构后嗑bert中记录的一些散装知识点,有时间就会整理收录,希望最后能把transformer一个系列都完整的更新进去。 1.自监督学习 bert与原始的transformer不同,bert是使用大量无标签的数据进行预训…...
基于术语词典干预的机器翻译挑战赛笔记 Task3 #Datawhale AI 夏令营
书接上回,上回在这捏: 基于术语词典干预的机器翻译挑战赛笔记Task2 #Datawhale AI 夏令营-CSDN博客文章浏览阅读223次,点赞10次,收藏5次。基于术语词典干预的机器翻译挑战赛笔记Task2https://blog.csdn.net/qq_23311271/article/…...

定制QCustomPlot 带有ListView的QCustomPlot 全网唯一份
定制QCustomPlot 带有ListView的QCustomPlot 文章目录 定制QCustomPlot 带有ListView的QCustomPlot摘要需求描述实现关键字: Qt、 QCustomPlot、 魔改、 定制、 控件 摘要 先上效果,是你想要的,再看下面的分解,顺便点赞搜藏一下;不是直接右上角。 QCustomPlot是一款…...

Fast Planner规划算法(一)—— Fast Planner前端
本系列文章用于回顾学习记录Fast-Planner规划算法的相关内容,【本系列博客写于2023年9月,共包含四篇文章,现在进行补发第一篇,其余几篇文章将在近期补发】 一、Fast Planner前端 Fast Planner的轨迹规划部分一共分为三个模块&…...

问题记录-SpringBoot 2.7.2 整合 Swagger 报错
详细报错如下 报错背景,我将springboot从2.3.3升级到了2.7.2,报了下面的错误: org.springframework.context.ApplicationContextException: Failed to start bean documentationPluginsBootstrapper; nested exception is java.lang.NullPo…...

【视觉SLAM】 十四讲ch5习题
1.*寻找一个相机(你手机或笔记本的摄像头即可),标定它的内参。你可能会用到标定板,或者自己打印一张标定用的棋盘格。 参考我之前写过的这篇博客:【OpenCV】 相机标定 calibrateCamera Code来源是《学习OpenCV3》18.…...

Webpack基础学习-Day01
Webpack基础学习-Day01 1.1 webpack 是什么 webpack 是一种前端资源构建工具,一个静态模块打包器(module bundler)。 在 webpack 看来, 前端的所有资源文件(js/json/css/img/less/…)都会作为模块处理。 它将根据模块的依赖关系进行静态分析,打包生成…...

如何防止热插拔烧坏单片机
大家都知道一般USB接口属于热插拔,实际任意带电进行连接的操作都可以属于热插拔。我们前面讲过芯片烧坏的原理,那么热插拔就是导致芯片烧坏的一个主要原因之一。 在电子产品的整个装配过程、以及产品使用过程经常会面临接口热插拔或者类似热插拔的过程。…...

JQuery+HTML+JavaScript:实现地图位置选取和地址模糊查询
本文详细讲解了如何使用 JQueryHTMLJavaScript 实现移动端页面中的地图位置选取功能。本文逐步展示了如何构建基本的地图页面,如何通过点击地图获取经纬度和地理信息,以及如何实现模糊查询地址并在地图上标注。最后,提供了完整的代码示例&…...
几何 13 多部件)
ArcGIS Pro SDK (九)几何 13 多部件
ArcGIS Pro SDK (九)几何 13 多部件 文章目录 ArcGIS Pro SDK (九)几何 13 多部件1 获取多部分要素的各个部分2 获取多边形的最外层环 环境:Visual Studio 2022 .NET6 ArcGIS Pro SDK 3.0 1 获取多部分要素的各个部分…...

【Node】npm i --legacy-peer-deps,解决依赖冲突问题
文章目录 🍖 前言🎶 一、问题描述✨二、代码展示🏀三、运行结果🏆四、知识点提示 🍖 前言 npm i --legacy-peer-deps,解决依赖冲突问题 🎶 一、问题描述 node执行安装指令时出现报错ÿ…...

h5点击电话号跳转手机拨号
需要使用到h5的 <a>标签 我们首先在<head>标签中添加代码 <meta name"format-detection" content"telephoneyes"/>然后再想要的位置添加代码 <a href"tel:10086"> 点击拨打:10086 </a> 这样功能就实现…...
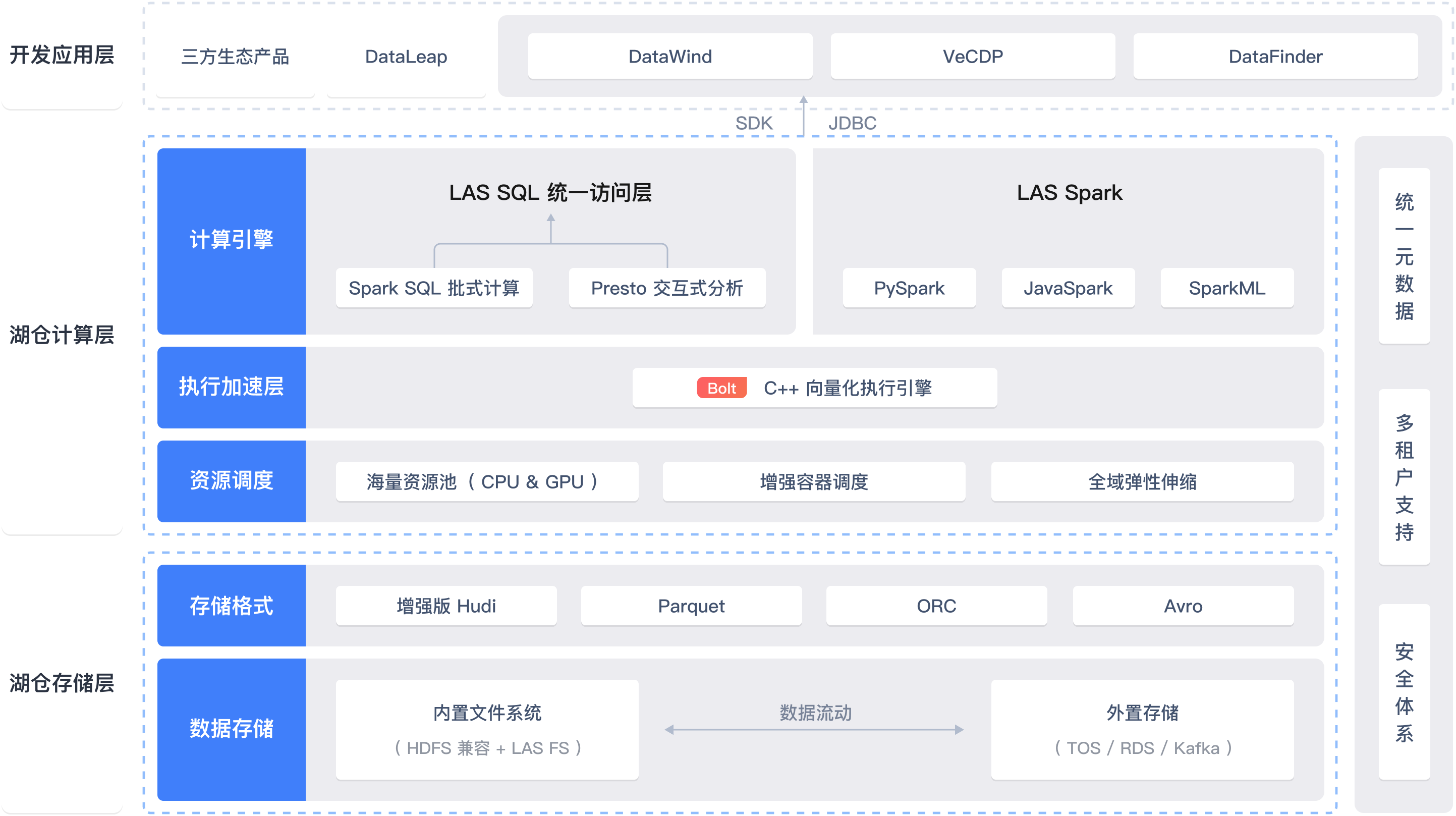
从数据湖到湖仓一体:统一数据架构演进之路
文章目录 一、前言二、什么是湖仓一体?起源概述 三、为什么要构建湖仓一体?1. 成本角度2. 技术角度 四、湖仓一体实践过程阶段一:摸索阶段(仓、湖并行建设)阶段二:发展阶段方式一、湖上建仓(湖在下、仓在上)方式二:仓外…...
Electron 渲染进程直接调用主进程的API库@electron/remote引用讲解
背景 remote是个老库,早期Electron版本中有个remote对象,这个对象可以横跨所有进程,随意通信,后来官方认为不安全,被干掉了,之后有人利用Electron的IPC通信,底层通过Promise的await能力&#x…...

在python中使用正则表达式
正则表达式是什么?就是要寻找的数据的规律,使用正则表达式的步骤有三 第一,寻找规律,第二使用正则符号表示规律,第三,提取信息 看下面的代码 import re wenzhang (小草偷偷地从土里钻出来,嫩…...

华清数据结构day4 24-7-19
链表的相关操作 linklist.h #ifndef LINKLIST_H #define LINKLIST_H #include <myhead.h> typedef int datatype; typedef struct Node {union{int len;datatype data;};struct Node *next; } Node, *NodePtr;NodePtr list_create(); NodePtr apply_node(datatype e); …...

【深度学习图像】拼接图的切分
用户常常将多张图拼成一张图。 如果将这张图拆为多个子图,下面是一种opencv的办法,后面要训练一个模型来识别边缘更为准确。 import osimport cv2 import numpy as npdef detect_lines(image_path):# 读取图片image cv2.imread(image_path)if image i…...

Covalent(CXT)运营商网络规模扩大 42%,以满足激增的需求
Covalent Network(CXT)是领先的人工智能模块化数据基础设施,网络集成了超过 230 条链并积累了数千名客户,目前 Covalent Network(CXT)网络迎来了五位新运营商的加入,包括 Graphyte Labs、PierTw…...
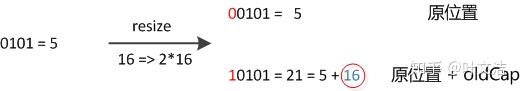
Java 集合框架:HashMap 的介绍、使用、原理与源码解析
大家好,我是栗筝i,这篇文章是我的 “栗筝i 的 Java 技术栈” 专栏的第 020 篇文章,在 “栗筝i 的 Java 技术栈” 这个专栏中我会持续为大家更新 Java 技术相关全套技术栈内容。专栏的主要目标是已经有一定 Java 开发经验,并希望进…...

单周期CPU(三)译码模块(minisys)(verilog)(vivado)
timescale 1ns / 1ps //module Idecode32 (input reset,input clock,output [31:0] read_data_1, // 输出的第一操作数output [31:0] read_data_2, // 输出的第二操作数input [31:0] Instruction, // 取指单元来的指令input [31:0] …...

高效Kolmogorov-Arnold网络:PyTorch实现终极指南 [特殊字符]
高效Kolmogorov-Arnold网络:PyTorch实现终极指南 🚀 【免费下载链接】efficient-kan An efficient pure-PyTorch implementation of Kolmogorov-Arnold Network (KAN). 项目地址: https://gitcode.com/GitHub_Trending/ef/efficient-kan Kolmogor…...

5分钟告别百度网盘提取码烦恼:智能获取工具全解析
5分钟告别百度网盘提取码烦恼:智能获取工具全解析 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 你是否曾经因为一个简单的提取码,在浏览器标签页间反复切换,浪费了宝贵的十几分钟…...

终极指南:如何在Windows上轻松模拟游戏控制器 - ViGEmBus驱动完整教程
终极指南:如何在Windows上轻松模拟游戏控制器 - ViGEmBus驱动完整教程 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 你是否曾经遇到过这样的困…...

AI智能体如何通过区块链钱包实现自动化加密云存储
1. 项目概述:当AI智能体遇上加密云存储如果你正在使用OpenClaw这类AI智能体平台,并且头疼于如何让它们自动、安全地处理云端数据——比如备份对话记录、上传生成的文件,或者管理需要付费的API服务——那么你很可能需要一个既懂区块链支付、又…...

DeepSeek V4的突破:探索未来AI意识的可能性
引言 DeepSeek V4的发布,再次刷新了人们对大语言模型的认知:更强的代码生成、更复杂的逻辑推理、更精准的长文本理解……几乎所有技术评测都在告诉我们:AI又向前迈进了一大步。社交媒体上,关于“AI是否快要拥有意识”的讨论也随之…...

Error response from daemon: client version 1.52 is too new. Maximum supported API version is 1.43
按照习惯,输入“docker ps”查看一下容器,结果给我来个这个错误:Error response from daemon: client version 1.52 is too new. Maximum supported API version is 1.43查了一下原因:这是因为使用云构建安装的默认 Docker 守护程…...
)
【Keras+TensorFlow+Yolo3】从零构建自定义目标检测模型:实战标注、训练与部署(TF2避坑指南)
1. 环境准备与工具安装 目标检测是计算机视觉领域的重要应用,而YOLOv3作为其中的经典算法,凭借其速度和精度的平衡备受青睐。在开始实战前,我们需要搭建好开发环境。我推荐使用Anaconda创建独立的Python环境,这样可以避免不同项目…...

GitHub Actions 工作流中的输出处理
在现代软件开发中,CI/CD(持续集成和持续交付)是确保代码质量和自动化部署的关键环节。GitHub Actions 作为 GitHub 提供的 CI/CD 工具,支持通过工作流文件定义自动化任务。本文将结合一个实际的 GitHub Actions 工作流实例,探讨如何处理 Python 脚本的输出,并根据该输出决…...

调试STM32双CAN通信的5个常见坑:从TJA1050供电到过滤器配置的避坑指南
STM32双CAN通信实战:从硬件陷阱到软件优化的深度排错指南 当你在实验室里搭建好STM32F407VE与两片TJA1050组成的双CAN系统,满心期待看到数据流畅传输时,示波器上却只有死寂的直线——这种挫败感我太熟悉了。双CAN系统调试就像在雷区跳舞&…...
在单相逆变器中扩展仿真示例)
手把手教你学Simulink--基于Simulink的三相锁相环(SRF-PLL)在单相逆变器中扩展仿真示例
目录 一、 核心破局点:用SOGI给单相电压“造”一个双胞胎 二、 兵马未动:Simulink 模型框架搭建 三、 灵魂所在:搭建 SOGI 正交信号生成模块 四、 移花接木:搭建三相 SRF-PLL 算法核心 五、 见证奇迹:仿真测试与波形分析 六、 避坑指南与工程进阶 总结 在新能源并网…...