中文分词库 jieba 详细使用方法与案例演示
1 前言
jieba 是一个非常流行的中文分词库,具有高效、准确分词的效果。
它支持3种分词模式:
- 精确模式
- 全模式
- 搜索引擎模式
jieba==0.42.1
测试环境:python3.10.9
2 三种模式
2.1 精确模式
适应场景:文本分析。
功能:可以将句子精确的分开。
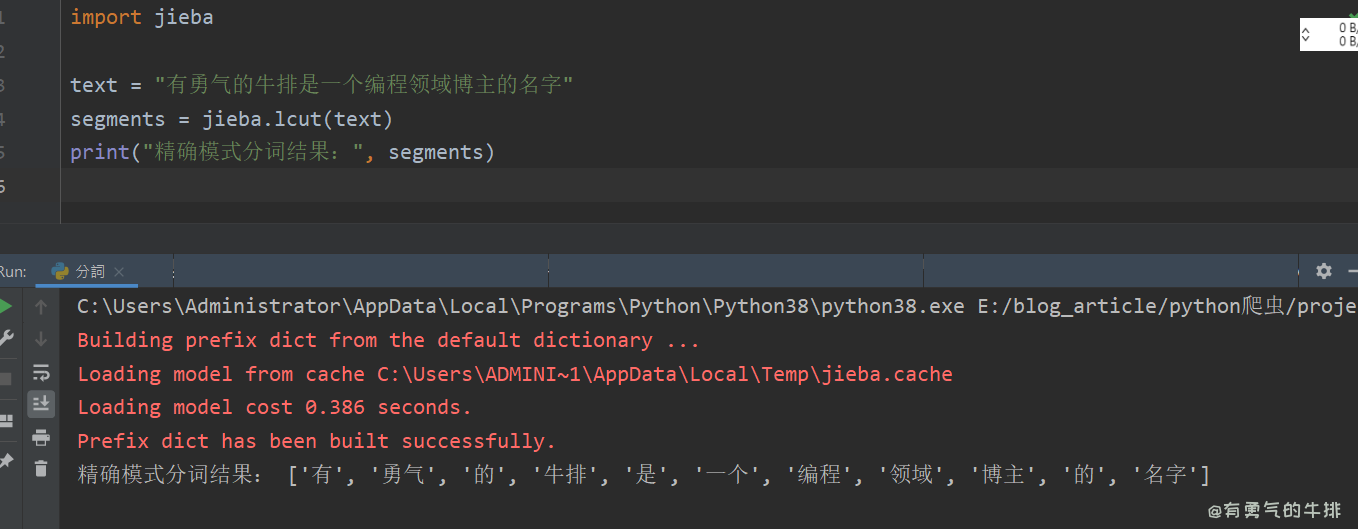
import jiebatext = "有勇气的牛排是一个编程领域博主的名字"
segments = jieba.lcut(text)print("精确模式分词结果:", segments)
# ['有', '勇气', '的', '牛排', '是', '一个', '编程', '领域', '博主', '的', '名字']
2.2 全模式
适应场景:提取词语。
功能:可以将句子中的成词的词语扫描出来,速度非常快,但不能解决歧义问题。
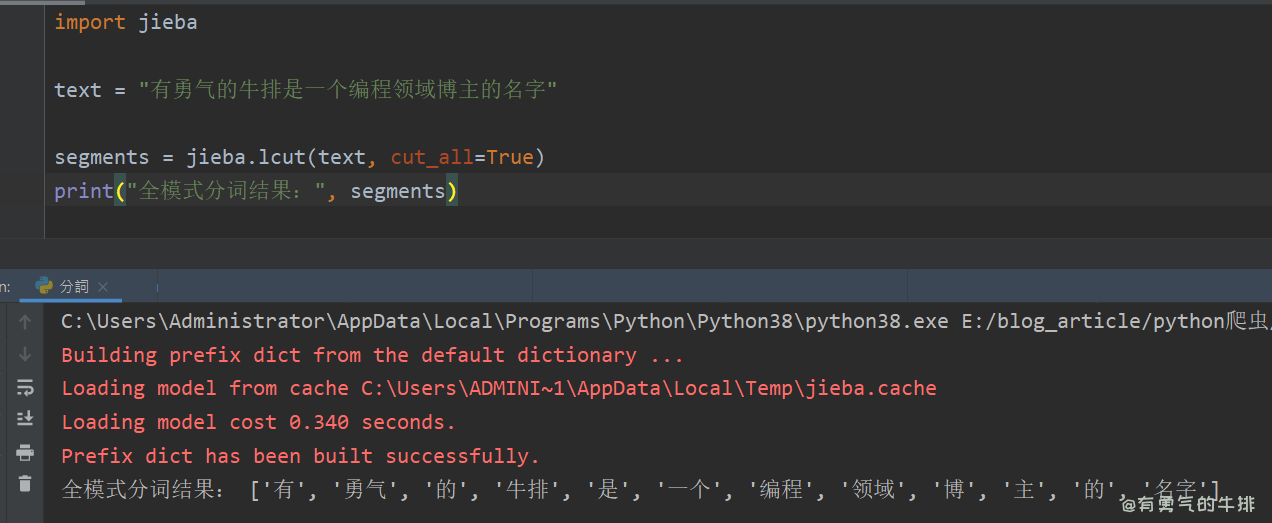
import jiebatext = "有勇气的牛排是一个编程领域博主的名字"segments = jieba.lcut(text, cut_all=True)
print("全模式分词结果:", segments)
# ['有', '勇气', '的', '牛排', '是', '一个', '编程', '领域', '博', '主', '的', '名字']
2.3 搜索引擎模式
适应场景:搜索分词。
功能:在精确模式的基础上,对长分词进行切分,提高召回率。
import jiebatext = "有勇气的牛排是一个编程领域博主的名字"segments = jieba.lcut_for_search(text)
print("搜索引擎模式分词结果:", segments)
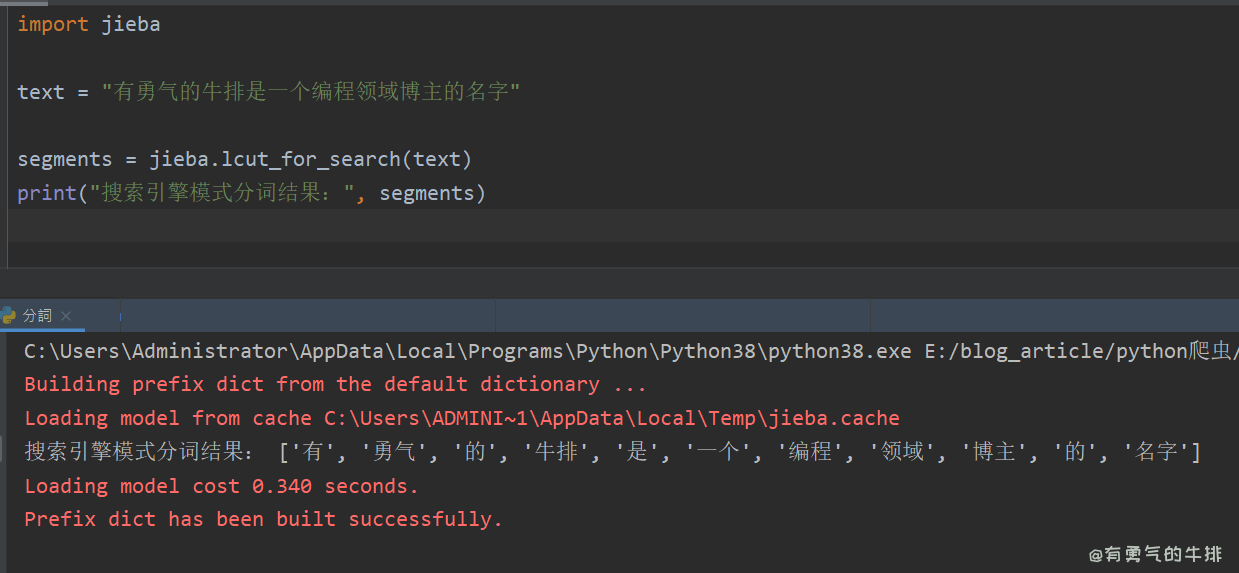
3 自定义词典
jieba允许用户自定义词典,以提高分词的准确性。
比如专业术语、名字、网络新流行词汇、方言、以及其他不常见短语名字等。
3.1 添加单个词语
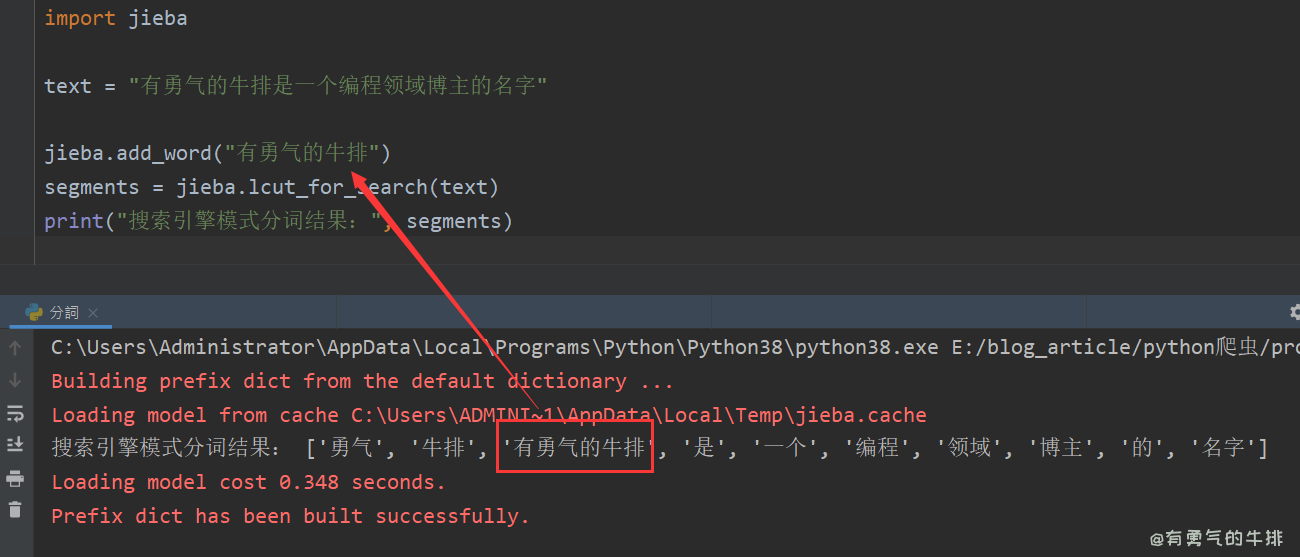
import jiebatext = "有勇气的牛排是一个编程领域博主的名字"jieba.add_word("有勇气的牛排")
segments = jieba.lcut_for_search(text)
print("搜索引擎模式分词结果:", segments)
# ['勇气', '牛排', '有勇气的牛排', '是', '一个', '编程', '领域', '博主', '的', '名字']
3.2 添加词典文件
cs_dict.txt
有勇气的牛排
编程领域
main.py
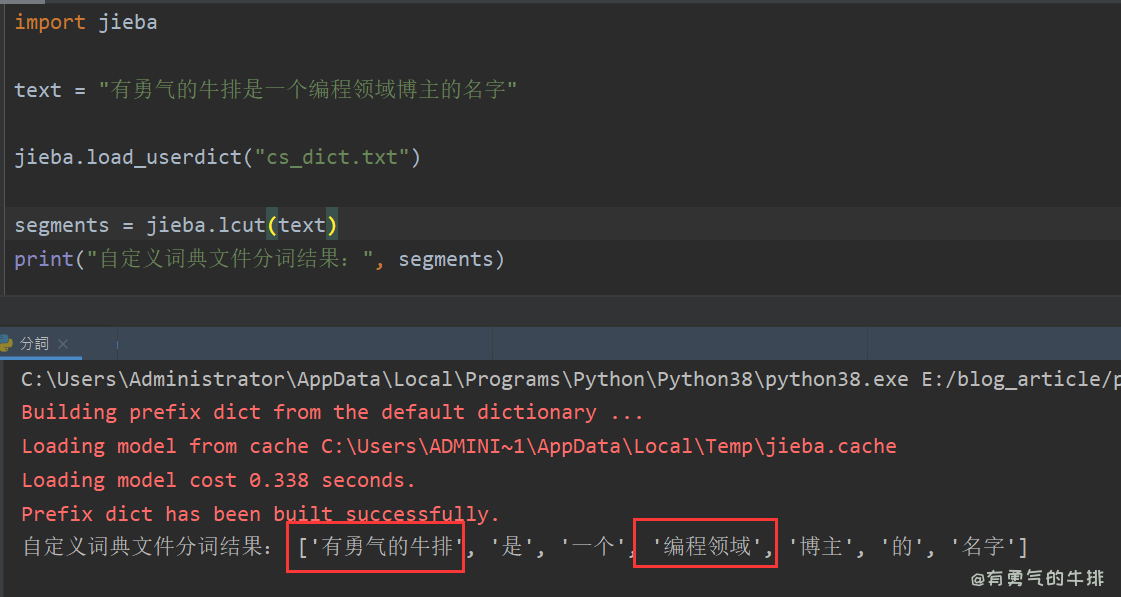
import jiebatext = "有勇气的牛排是一个编程领域博主的名字"jieba.load_userdict("cs_dict.txt")segments = jieba.lcut(text)
print("自定义词典文件分词结果:", segments)
# ['有勇气的牛排', '是', '一个', '编程领域', '博主', '的', '名字']
4 词性标注
jieba 的词性标注(POS tagging)功能使用了标注词性(Part-of-Speech tags)来表示每个词的词性。
4.1 词性对照表
原文地址:https://www.couragesteak.com/article/454
a 形容词 ad 副形词
ag 形容词性语素 an 名形词
b 区别词 c 连词
d 副词 dg 副语素
e 叹词 f 方位词
g 语素 h 前缀
i 成语 j 简称略语
k 后缀 l 习用语
m 数词 mg 数语素
mq 数量词 n 名词
ng 名语素 nr 人名
ns 地名 nt 机构团体
nz 其他专名 o 拟声词
p 介词 q 量词
r 代词 rg 代词性语素
s 处所词 t 时间词
tg 时间词性语素 u 助词
vg 动语素 v 动词
vd 副动词 vn 名动词
w 标点符号 x 非语素字
y 语气词 z 状态词
4.2 测试案例
import jieba.posseg as psegtext = "有勇气的牛排是一个编程领域博主的名字"words = pseg.cut(text)
for word, flag in words:print(f"{word} - {flag}")
5 关键词提取
from jieba import analyse
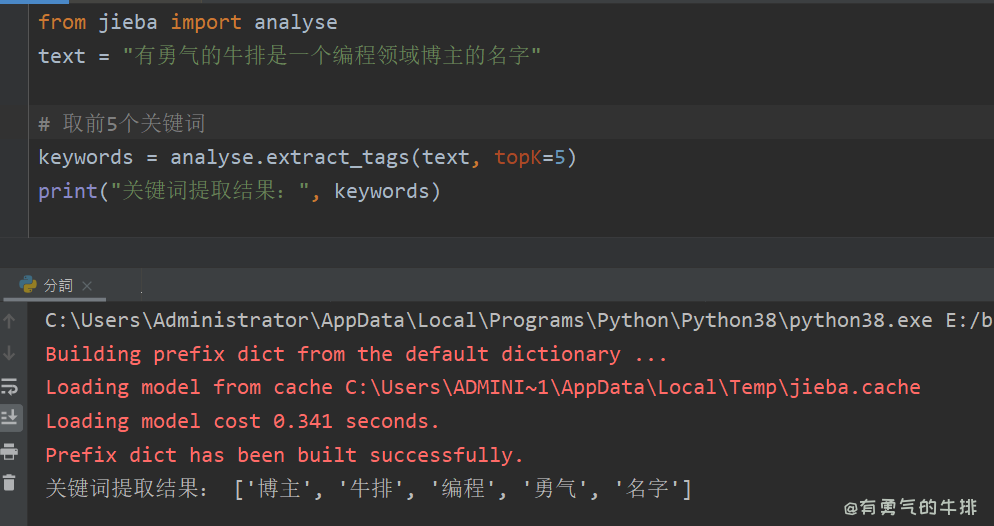
text = "有勇气的牛排是一个编程领域博主的名字"# 取前5个关键词
keywords = analyse.extract_tags(text, topK=5)
print("关键词提取结果:", keywords)
6 词频统计
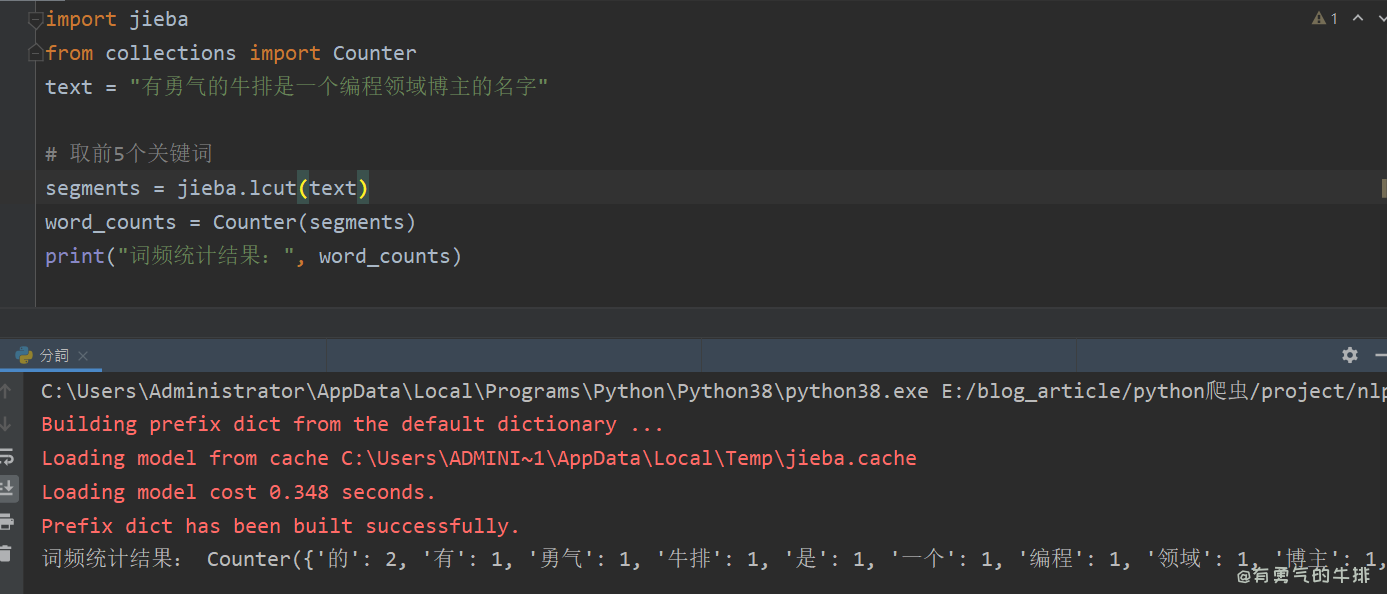
import jieba
from collections import Counter
text = "有勇气的牛排是一个编程领域博主的名字"# 取前5个关键词
segments = jieba.lcut(text)
word_counts = Counter(segments)
print("词频统计结果:", word_counts)
相关文章:
中文分词库 jieba 详细使用方法与案例演示
1 前言 jieba 是一个非常流行的中文分词库,具有高效、准确分词的效果。 它支持3种分词模式: 精确模式全模式搜索引擎模式 jieba0.42.1测试环境:python3.10.9 2 三种模式 2.1 精确模式 适应场景:文本分析。 功能࿱…...

EXO-helper解释
目录 helper解释 helper解释 在Python中,字符串 "\033[93m" 是一个ANSI转义序列,用于在支持ANSI转义码的终端或控制台中改变文本的颜色。具体来说,\033[93m 用于将文本颜色设置为亮黄色(或浅黄色,具体取决于终端的显示设置)。 这里的 \033 实际上是八进制的 …...

Qt开发网络嗅探器01
引言 随着互联网的快速发展和普及,人们对网络性能、安全和管理的需求日益增长。在复杂的网络环境中,了解和监控网络中的数据流量、安全事件和性能问题变得至关重要。为了满足这些需求,网络嗅探器作为一种重要的工具被 广泛应用。网络嗅探器是…...
)
mysql面试(三)
MVCC机制 MVCC(Multi-Version Concurrency Control) 即多版本并发控制,了解mvcc机制,需要了解如下这些概念 事务id 事务每次开启时,都会从数据库获得一个自增长的事务ID,可以从事务ID判断事务的执行先后…...

阿里云公共DNS免费版自9月30日开始限速 企业或商业场景需使用付费版
本周阿里云发布公告对公共 DNS 免费版使用政策进行调整,免费版将从 2024 年 9 月 30 日开始按照请求源 IP 进行并发数限制,单个 IP 的请求数超过 20QPS、UDP/TCP 流量超过 2000bps 将触发限速策略。 阿里云称免费版的并发数限制并非采用固定的阈值&…...

捷配生产笔记-一文搞懂阻焊层基本知识
什么是阻焊层? 阻焊层(也称为阻焊剂)是应用于PCB表面的一层薄薄的聚合物材料。其目的是保护铜电路,防止焊料在焊接过程中流入不需要焊接的区域。除焊盘外,整个电路板都涂有阻焊层。 阻焊层应用于 PCB 的顶部和底部。树…...

html 常用css样式及排布问题
1.常用样式 <style>.cy{width: 20%;height: 50px;font-size: 30px;border: #20c997 solid 3px;float: left;color: #00cc00;font-family: 黑体;font-weight: bold;padding: 10px;margin: 10px;}</style> ①宽度(长) ②高度(宽&a…...

【SpingCloud】客户端与服务端负载均衡机制,微服务负载均衡NacosLoadBalancer, 拓展:OSI七层网络模型
客户端与服务端负载均衡机制 可能有第一次听说集群和负载均衡,所以呢,我们先来做一个介绍,然后再聊服务端与客户端的负载均衡区别。 集群与负载均衡 负载均衡是基于集群的,如果没有集群,则没有负载均衡这一个说法。 …...

【Elasticsearch】Elasticsearch 中的节点角色
Elasticsearch 中的节点角色 1.主节点(master)1.1 专用候选主节点(dedicated master-eligible node)1.2 仅投票主节点(voting-only master-eligible node) 2.数据节点(data)2.1 内容…...

pip install与apt install区别
pipapt/apt-get安装源PyPI 的 python所有依赖的包软件、更新源、ubuntu的依赖包 1 查看pip install 安装的数据包 命令 pip list 2 查看安装包位置 pip show package_name参考 https://blog.csdn.net/nebula1008/article/details/120042766...

分表分库是一种数据库架构的优化策略,用于处理大规模数据和高并发请求,提高数据库的性能和可扩展性。
分表分库是一种数据库架构的优化策略,用于处理大规模数据和高并发请求,提高数据库的性能和可扩展性。以下是一些常见的分表分库技术方案: 1. **水平分表(Horizontal Sharding)**: - 将单表数据根据某个…...

【ffmpeg命令入门】获取音视频信息
文章目录 前言使用ffmpeg获取简单的音视频信息输入文件信息文件元数据视频流信息音频流信息 使用ffprobe获取更详细的音视频信息输入文件信息文件元数据视频流信息音频流信息 总结 前言 在处理多媒体文件时,了解文件的详细信息对于调试和优化处理过程至关重要。FFm…...

【IoTDB 线上小课 05】时序数据文件 TsFile 三问“解密”!
【IoTDB 视频小课】持续更新!第五期来啦~ 关于 IoTDB,关于物联网,关于时序数据库,关于开源... 一个问题重点,3-5 分钟详细展开,为大家清晰解惑: IoTDB 的 TsFile 科普! 了解了时序数…...

python-爬虫实例(4):获取b站的章若楠的视频
目录 前言 道路千万条,安全第一条 爬虫不谨慎,亲人两行泪 获取b站的章若楠的视频 一、话不多说,先上代码 二、爬虫四步走 1.UA伪装 2.获取url 3.发送请求 4.获取响应数据进行解析并保存 总结 前言 道路千万条,安全第一条 爬…...

C# yaml 配置文件的用法(一)
目录 一、简介 二、yaml 的符号 1.冒号 2.短横杆 3.文档分隔符 4.保留换行符 5.注释 6.锚点 7.NULL值 8.合并 一、简介 YAML(YAML Aint Markup Language)是一种数据序列化标准,广泛用于配置文件、数据交换和存储。YAML的设计目标是…...

人工智能与机器学习原理精解【4】
文章目录 马尔科夫过程论要点理论基础σ代数定义性质应用例子总结 马尔可夫过程概述一、马尔可夫过程的原理二、马尔可夫过程的算法过程三、具体例子 马尔可夫链的状态转移概率矩阵一、确定马尔可夫链的状态空间二、收集状态转移数据三、计算转移频率四、构建状态转移概率矩阵示…...
)
Go channel实现原理详解(源码解读)
文章目录 Go channel详解Channel 的发展Channel 的应用场景Channel 基本用法Channel 的实现原理chan 数据结构初始化sendrecvclose使用 Channel 容易犯的错误总结Go channel详解 Channel 是 Go 语言内建的 first-class 类型,也是 Go 语言与众不同的特性之一。Channel 让并发消…...

数据结构-C语言-排序(4)
代码位置: test-c-2024: 对C语言习题代码的练习 (gitee.com) 一、前言: 1.1-排序定义: 排序就是将一组杂乱无章的数据按照一定的规律(升序或降序)组织起来。(注:我们这里的排序采用的都为升序) 1.2-排…...

灰色关联分析【系统分析+综合评价】
系统分析: 判断哪个因素影响最大 基本思想:根据序列曲线几何形状的相似程度来判断其练习是否紧密 绘制统计图并进行分析 确定子序列和母序列 对变量进行预处理(去量纲、缩小变量范围) 熟练使用excel与其公式和固定(…...

linux 部署flask项目
linux python环境安装: https://blog.csdn.net/weixin_41934979/article/details/140528410 1.创建虚拟环境 python3.12 -m venv .venv 2.激活环境 . .venv/bin/activate 3.安装依赖包(pip3.12 install -r requirements.txt) pip3.12 install -r requirements.txt 4.测试启…...

从直流平衡到时钟恢复:深入剖析8B10B编码在高速串行链路中的核心作用
1. 8B10B编码:高速串行通信的"交通警察" 第一次接触PCIe调试时,我拿着示波器看到波形图上那些密集的跳变信号完全摸不着头脑。直到前辈指着屏幕说:"看见这些有规律的0/1跳变了吗?这就是8B10B在指挥交通。"这个…...

在 Elasticsearch 中使用带有确定性护栏的 Agentic AI 搜索,以实现安全的查询执行
作者:来自 Elastic Alexander Marquardt, Honza Krl 及 Taylor Roy 当 LLM 直接生成查询时, Agentic AI 搜索系统通常会失败。了解确定性护栏和控制平面架构如何通过 Elasticsearch 实现安全、可靠且受治理的查询执行。 刚接触 Elasticsearch࿱…...

JetBrains IDE试用期重置全攻略:让30天试用无限循环的终极技巧
JetBrains IDE试用期重置全攻略:让30天试用无限循环的终极技巧 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 还在为JetBrains IDE试用期到期而焦虑吗?每次看到"试用期已结束"的…...
)
第12期:综合优化与结业项目(工程落地与量产调优)
一、本期课程简介本期为整套TinyML嵌入式实战课程的收官总结阶段,旨在帮助学员打通技术壁垒,完成从零散知识点积累到系统化工程落地能力的蜕变。课程将全面梳理前序所有实战项目技术栈,涵盖传感器数据采集、数据集预处理、神经网络模型轻量化…...

Linux实战:部署MinIO对象存储服务与Systemd开机自启配置详解
1. MinIO简介与环境准备 MinIO是一款高性能的分布式对象存储服务,完全兼容Amazon S3 API。它特别适合在私有云环境中部署,提供文件存储、备份和归档等功能。我在多个生产环境中使用过MinIO,它的轻量级设计和简单配置让我印象深刻。 首先需要准…...

【亲测免费】 PLC1200四路抢答器程序:打造高效公平的抢答体验
PLC1200四路抢答器程序:打造高效公平的抢答体验 【下载地址】PLC1200四路抢答器程序 本仓库提供了一个完整的S7-1200四路抢答器程序,可以直接下载并使用。该程序适用于需要进行四路抢答的场景,如竞赛、培训等。程序经过精心设计和测试&#x…...

【NotebookLM要点提取黄金法则】:20年AI工具实战总结的5大避坑指南与3步精准萃取法
更多请点击: https://intelliparadigm.com 第一章:NotebookLM要点提取方法论全景概览 NotebookLM 是 Google 推出的面向研究者与知识工作者的 AI 原生笔记工具,其核心能力在于对用户上传文档(PDF、TXT、Google Docs)进…...

CircuitPython HID实战:用Python轻松打造自定义键盘鼠标与数据记录仪
1. 项目概述与核心价值如果你玩过一些老游戏,或者用过一些专业软件,可能会遇到一个头疼的问题:你想用一个自制的硬件控制器来操作它,但软件根本不支持外接硬件,只认键盘鼠标。以前遇到这种情况,要么放弃&am…...

从ok-skills项目解析技能树:设计理念、技术实现与工程实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“ok-skills”。光看这个名字,可能有点摸不着头脑,但点进去一看,发现这是一个关于“技能树”或“知识图谱”的开源项目。简单来说,它试图用一种结构化的…...

ARM中断控制器架构与配置实践详解
1. ARM中断控制器架构解析在嵌入式系统设计中,中断控制器作为处理器与外围设备间的关键枢纽,其性能直接影响系统的实时性和可靠性。ARM1176JZF-S处理器采用了两级中断控制架构:位于开发芯片中的TrustZone中断控制器(TZIC)和通用中断控制器(GI…...