Spring Boot 接口访问频率限制的实现详解
目录
- 概述
- 为什么需要接口访问频率限制
- 常见的实现方式
- 基于过滤器的实现
- 基于拦截器的实现
- 基于第三方库Bucket4j的实现
- 实际代码示例
- 基于过滤器实现Rate Limiting
- 基于拦截器实现Rate Limiting
- 使用Bucket4j实现Rate Limiting
- 最佳实践
- 选择合适的限流算法
- 优化性能
- 记录日志和监控
- 总结
概述
接口访问频率限制是通过在一定时间内限制用户对接口的访问次数来实现的。常见的限流算法包括令牌桶算法(Token Bucket)、漏桶算法(Leaky Bucket)、固定窗口计数器(Fixed Window Counter)和滑动窗口计数器(Sliding Window Counter)等。在Spring Boot中,我们可以通过多种方式来实现接口的限流,如使用过滤器、拦截器或者借助第三方库。
为什么需要接口访问频率限制
- 防止恶意攻击:通过限制接口的访问频率,可以有效防止恶意用户或机器人频繁访问接口,导致系统资源耗尽。
- 提升系统稳定性:在高并发场景下,限流可以有效保护后端服务,避免因流量过大而导致系统崩溃。
- 提升用户体验:合理的限流可以保障所有用户都能获得较好的服务质量,避免个别用户过度使用资源。
常见的实现方式
基于过滤器的实现
过滤器是Java Web应用中常用的一种组件,它可以在请求到达Servlet之前对请求进行预处理。通过在过滤器中实现限流逻辑,可以对所有的HTTP请求进行统一的限流控制。
基于拦截器的实现
拦截器是Spring框架提供的一种处理器,可以在请求处理之前和之后进行相关操作。相比于过滤器,拦截器可以更加细粒度地控制请求,适用于需要针对某些特定接口进行限流的场景。
基于第三方库Bucket4j的实现
Bucket4j是一个Java实现的高性能限流库,它支持多种限流算法,如令牌桶算法。通过使用Bucket4j,可以轻松地在Spring Boot应用中实现复杂的限流逻辑,并且它还提供了丰富的配置选项和统计功能。
实际代码示例
基于过滤器实现Rate Limiting
首先,我们需要创建一个自定义的过滤器类,并在其中实现限流逻辑。以下是一个示例代码:
import javax.servlet.Filter;
import javax.servlet.FilterChain;
import javax.servlet.FilterConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
import java.util.concurrent.TimeUnit;public class RateLimitingFilter implements Filter {private final ConcurrentMap<String, Long> requestCounts = new ConcurrentHashMap<>();private static final long ALLOWED_REQUESTS_PER_MINUTE = 60;@Overridepublic void init(FilterConfig filterConfig) throws ServletException {// 初始化过滤器}@Overridepublic void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {HttpServletRequest httpRequest = (HttpServletRequest) request;HttpServletResponse httpResponse = (HttpServletResponse) response;String clientIp = httpRequest.getRemoteAddr();long currentTimeMillis = System.currentTimeMillis();requestCounts.putIfAbsent(clientIp, currentTimeMillis);long lastRequestTime = requestCounts.get(clientIp);if (TimeUnit.MILLISECONDS.toMinutes(currentTimeMillis - lastRequestTime) < 1) {long requestCount = requestCounts.values().stream().filter(time -> TimeUnit.MILLISECONDS.toMinutes(currentTimeMillis - time) < 1).count();if (requestCount > ALLOWED_REQUESTS_PER_MINUTE) {httpResponse.setStatus(HttpServletResponse.SC_TOO_MANY_REQUESTS);httpResponse.getWriter().write("Too many requests");return;}}requestCounts.put(clientIp, currentTimeMillis);chain.doFilter(request, response);}@Overridepublic void destroy() {// 销毁过滤器}
}
然后,在Spring Boot应用的配置类中注册这个过滤器:
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class FilterConfig {@Beanpublic FilterRegistrationBean<RateLimitingFilter> loggingFilter(){FilterRegistrationBean<RateLimitingFilter> registrationBean = new FilterRegistrationBean<>();registrationBean.setFilter(new RateLimitingFilter());registrationBean.addUrlPatterns("/api/*");return registrationBean;}
}
基于拦截器实现Rate Limiting
首先,我们需要创建一个自定义的拦截器类,并在其中实现限流逻辑。以下是一个示例代码:
import org.springframework.web.servlet.HandlerInterceptor;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
import java.util.concurrent.TimeUnit;public class RateLimitingInterceptor implements HandlerInterceptor {private final ConcurrentMap<String, Long> requestCounts = new ConcurrentHashMap<>();private static final long ALLOWED_REQUESTS_PER_MINUTE = 60;@Overridepublic boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {String clientIp = request.getRemoteAddr();long currentTimeMillis = System.currentTimeMillis();requestCounts.putIfAbsent(clientIp, currentTimeMillis);long lastRequestTime = requestCounts.get(clientIp);if (TimeUnit.MILLISECONDS.toMinutes(currentTimeMillis - lastRequestTime) < 1) {long requestCount = requestCounts.values().stream().filter(time -> TimeUnit.MILLISECONDS.toMinutes(currentTimeMillis - time) < 1).count();if (requestCount > ALLOWED_REQUESTS_PER_MINUTE) {response.setStatus(HttpServletResponse.SC_TOO_MANY_REQUESTS);response.getWriter().write("Too many requests");return false;}}requestCounts.put(clientIp, currentTimeMillis);return true;}
}
然后,在Spring Boot应用的配置类中注册这个拦截器:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.InterceptorRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;@Configuration
public class WebConfig implements WebMvcConfigurer {@Autowiredprivate RateLimitingInterceptor rateLimitingInterceptor;@Overridepublic void addInterceptors(InterceptorRegistry registry) {registry.addInterceptor(rateLimitingInterceptor).addPathPatterns("/api/**");}
}
使用Bucket4j实现Rate Limiting
首先,在项目中引入Bucket4j依赖:
<dependency><groupId>com.github.vladimir-bukhtoyarov</groupId><artifactId>bucket4j-core</artifactId><version>7.0.0</version>
</dependency>
然后,创建一个自定义的过滤器类,并在其中实现限流逻辑:
import io.github.bucket4j.Bandwidth;
import io.github.bucket4j.Bucket;
import io.github.bucket4j.Bucket4j;
import io.github.bucket4j.Refill;import javax.servlet.Filter;
import javax.servlet.FilterChain;
import javax.servlet.FilterConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.time.Duration;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;public class Bucket4jRateLimitingFilter implements Filter {private final ConcurrentMap<String, Bucket> buckets = new ConcurrentHashMap<>();@Overridepublic void init(FilterConfig filterConfig) throws ServletException {// 初始化过滤器}@Overridepublic void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {HttpServletRequest httpRequest = (HttpServletRequest) request;HttpServletResponse httpResponse = (HttpServletResponse) response;String clientIp = httpRequest.getRemoteAddr();Bucket bucket = buckets.computeIfAbsent(clientIp, this::newBucket);if (bucket.tryConsume(1)) {chain.doFilter(request, response);} else {httpResponse.setStatus(HttpServletResponse.SC_TOO_MANY_REQUESTS);httpResponse.getWriter().write("Too many requests");}}private Bucket newBucket(String clientIp) {return Bucket4j.builder().addLimit(Bandwidth.classic(60, Refill.greedy(60, Duration.ofMinutes(1)))).build();}@Overridepublic void destroy() {// 销毁过滤器}
}
然后,在Spring Boot应用的配置类中注册这个过滤器:
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class FilterConfig {@Beanpublic FilterRegistrationBean<Bucket4jRateLimitingFilter> loggingFilter(){FilterRegistrationBean<Bucket4jRateLimitingFilter> registrationBean = new FilterRegistrationBean<>();registrationBean.setFilter(new Bucket4jRateLimitingFilter());registrationBean.addUrlPatterns("/api/*");return registrationBean;}
}
最佳实践
选择合适的限流算法
根据实际业务需求选择合适的限流算法,例如:
- 令牌桶算法:适用于需要平滑突发流量的场景。
- 漏桶算法:适用于需要严格控制流量的场景。
- 固定窗口计数器:适用于对简单限流要求的场景。
- 滑动窗口计数器:适用于需要精确控制限流的场景。
优化性能
- 减少锁竞争:在高并发环境下,尽量减少锁的使用,可以采用无锁数据结构或者线程安全的数据结构。
- 缓存结果:对于频繁访问的数据,可以考虑进行缓存,减少数据库查询的次数。
- 异步处理:对于耗时的操作,可以考虑采用异步处理,提高系统的响应速度。
记录日志和监控
- 记录访问日志:记录每次接口访问的详细信息,包括请求时间、IP地址、请求路径等。
- 监控限流情况:对限流情况进行监控,及时发现和处理异常流量。
- 报警机制:设置限流报警机制,当流量超过预设阈值时,及时报警。
总结
本文详细介绍了在Spring Boot中实现接口访问频率限制的几种方法,包括基于过滤器、拦截器和第三方库Bucket4j的实现。通过合理的限流策略,可以有效防止恶意攻击,提升系统的稳定性和用户体验。在实际应用中,选择合适的限流算法和实现方式,并结合业务需求进行优化,是确保系统高效运行的关键。
希望本文能够帮助你更好地理解和实现Spring Boot中的接口访问频率限制。如果你有任何问题或建议,欢迎在评论区留言讨论。
相关文章:

Spring Boot 接口访问频率限制的实现详解
目录 概述为什么需要接口访问频率限制常见的实现方式 基于过滤器的实现基于拦截器的实现基于第三方库Bucket4j的实现 实际代码示例 基于过滤器实现Rate Limiting基于拦截器实现Rate Limiting使用Bucket4j实现Rate Limiting 最佳实践 选择合适的限流算法优化性能记录日志和监控…...

前端页面:用户交互持续时间跟踪(duration)user-interaction-tracker
引言 在用户至上的时代,精准把握用户行为已成为产品优化的关键。本文将详细介绍 user-interaction-tracker 库,它提供了一种高效的解决方案,用于跟踪用户交互的持续时间,并提升项目埋点的效率。通过本文,你将了解到如…...
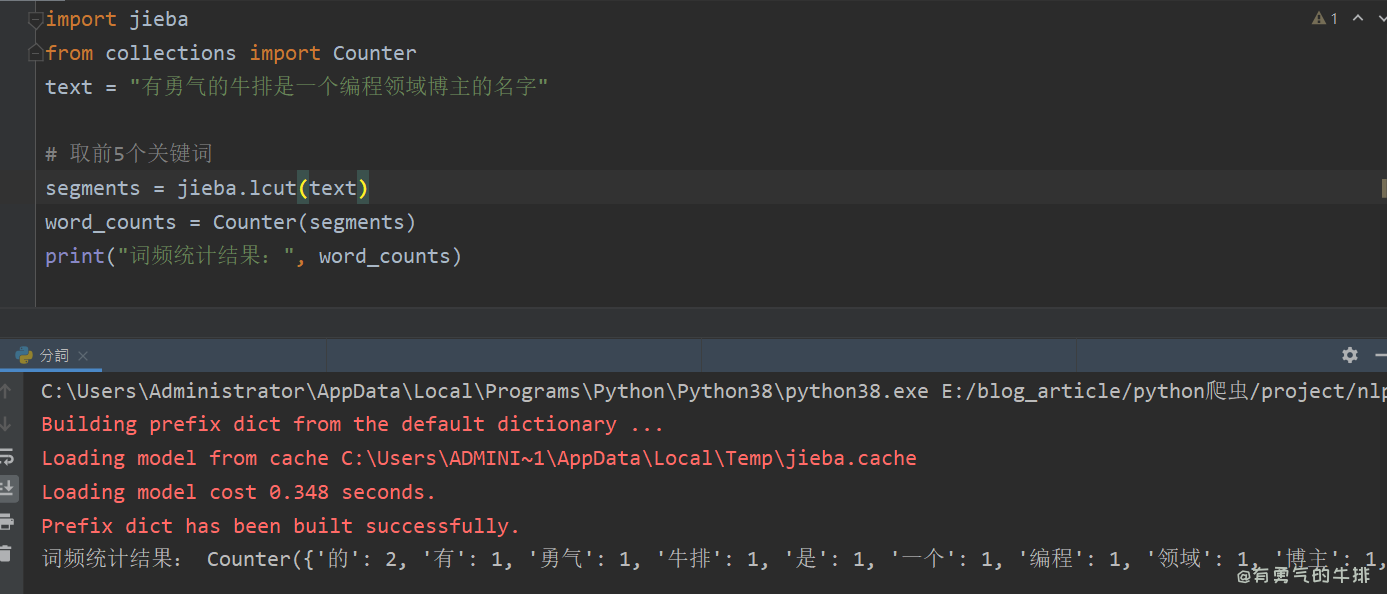
中文分词库 jieba 详细使用方法与案例演示
1 前言 jieba 是一个非常流行的中文分词库,具有高效、准确分词的效果。 它支持3种分词模式: 精确模式全模式搜索引擎模式 jieba0.42.1测试环境:python3.10.9 2 三种模式 2.1 精确模式 适应场景:文本分析。 功能࿱…...

EXO-helper解释
目录 helper解释 helper解释 在Python中,字符串 "\033[93m" 是一个ANSI转义序列,用于在支持ANSI转义码的终端或控制台中改变文本的颜色。具体来说,\033[93m 用于将文本颜色设置为亮黄色(或浅黄色,具体取决于终端的显示设置)。 这里的 \033 实际上是八进制的 …...

Qt开发网络嗅探器01
引言 随着互联网的快速发展和普及,人们对网络性能、安全和管理的需求日益增长。在复杂的网络环境中,了解和监控网络中的数据流量、安全事件和性能问题变得至关重要。为了满足这些需求,网络嗅探器作为一种重要的工具被 广泛应用。网络嗅探器是…...
)
mysql面试(三)
MVCC机制 MVCC(Multi-Version Concurrency Control) 即多版本并发控制,了解mvcc机制,需要了解如下这些概念 事务id 事务每次开启时,都会从数据库获得一个自增长的事务ID,可以从事务ID判断事务的执行先后…...

阿里云公共DNS免费版自9月30日开始限速 企业或商业场景需使用付费版
本周阿里云发布公告对公共 DNS 免费版使用政策进行调整,免费版将从 2024 年 9 月 30 日开始按照请求源 IP 进行并发数限制,单个 IP 的请求数超过 20QPS、UDP/TCP 流量超过 2000bps 将触发限速策略。 阿里云称免费版的并发数限制并非采用固定的阈值&…...

捷配生产笔记-一文搞懂阻焊层基本知识
什么是阻焊层? 阻焊层(也称为阻焊剂)是应用于PCB表面的一层薄薄的聚合物材料。其目的是保护铜电路,防止焊料在焊接过程中流入不需要焊接的区域。除焊盘外,整个电路板都涂有阻焊层。 阻焊层应用于 PCB 的顶部和底部。树…...

html 常用css样式及排布问题
1.常用样式 <style>.cy{width: 20%;height: 50px;font-size: 30px;border: #20c997 solid 3px;float: left;color: #00cc00;font-family: 黑体;font-weight: bold;padding: 10px;margin: 10px;}</style> ①宽度(长) ②高度(宽&a…...

【SpingCloud】客户端与服务端负载均衡机制,微服务负载均衡NacosLoadBalancer, 拓展:OSI七层网络模型
客户端与服务端负载均衡机制 可能有第一次听说集群和负载均衡,所以呢,我们先来做一个介绍,然后再聊服务端与客户端的负载均衡区别。 集群与负载均衡 负载均衡是基于集群的,如果没有集群,则没有负载均衡这一个说法。 …...

【Elasticsearch】Elasticsearch 中的节点角色
Elasticsearch 中的节点角色 1.主节点(master)1.1 专用候选主节点(dedicated master-eligible node)1.2 仅投票主节点(voting-only master-eligible node) 2.数据节点(data)2.1 内容…...

pip install与apt install区别
pipapt/apt-get安装源PyPI 的 python所有依赖的包软件、更新源、ubuntu的依赖包 1 查看pip install 安装的数据包 命令 pip list 2 查看安装包位置 pip show package_name参考 https://blog.csdn.net/nebula1008/article/details/120042766...

分表分库是一种数据库架构的优化策略,用于处理大规模数据和高并发请求,提高数据库的性能和可扩展性。
分表分库是一种数据库架构的优化策略,用于处理大规模数据和高并发请求,提高数据库的性能和可扩展性。以下是一些常见的分表分库技术方案: 1. **水平分表(Horizontal Sharding)**: - 将单表数据根据某个…...

【ffmpeg命令入门】获取音视频信息
文章目录 前言使用ffmpeg获取简单的音视频信息输入文件信息文件元数据视频流信息音频流信息 使用ffprobe获取更详细的音视频信息输入文件信息文件元数据视频流信息音频流信息 总结 前言 在处理多媒体文件时,了解文件的详细信息对于调试和优化处理过程至关重要。FFm…...

【IoTDB 线上小课 05】时序数据文件 TsFile 三问“解密”!
【IoTDB 视频小课】持续更新!第五期来啦~ 关于 IoTDB,关于物联网,关于时序数据库,关于开源... 一个问题重点,3-5 分钟详细展开,为大家清晰解惑: IoTDB 的 TsFile 科普! 了解了时序数…...

python-爬虫实例(4):获取b站的章若楠的视频
目录 前言 道路千万条,安全第一条 爬虫不谨慎,亲人两行泪 获取b站的章若楠的视频 一、话不多说,先上代码 二、爬虫四步走 1.UA伪装 2.获取url 3.发送请求 4.获取响应数据进行解析并保存 总结 前言 道路千万条,安全第一条 爬…...

C# yaml 配置文件的用法(一)
目录 一、简介 二、yaml 的符号 1.冒号 2.短横杆 3.文档分隔符 4.保留换行符 5.注释 6.锚点 7.NULL值 8.合并 一、简介 YAML(YAML Aint Markup Language)是一种数据序列化标准,广泛用于配置文件、数据交换和存储。YAML的设计目标是…...

人工智能与机器学习原理精解【4】
文章目录 马尔科夫过程论要点理论基础σ代数定义性质应用例子总结 马尔可夫过程概述一、马尔可夫过程的原理二、马尔可夫过程的算法过程三、具体例子 马尔可夫链的状态转移概率矩阵一、确定马尔可夫链的状态空间二、收集状态转移数据三、计算转移频率四、构建状态转移概率矩阵示…...
)
Go channel实现原理详解(源码解读)
文章目录 Go channel详解Channel 的发展Channel 的应用场景Channel 基本用法Channel 的实现原理chan 数据结构初始化sendrecvclose使用 Channel 容易犯的错误总结Go channel详解 Channel 是 Go 语言内建的 first-class 类型,也是 Go 语言与众不同的特性之一。Channel 让并发消…...

数据结构-C语言-排序(4)
代码位置: test-c-2024: 对C语言习题代码的练习 (gitee.com) 一、前言: 1.1-排序定义: 排序就是将一组杂乱无章的数据按照一定的规律(升序或降序)组织起来。(注:我们这里的排序采用的都为升序) 1.2-排…...

算力基石:CPU、GPU与嵌入式AI的技术逻辑与融合发展
在人工智能全面普及的时代,算力已经成为数字产业发展的核心驱动力。从日常使用的智能手机、家用电脑,到云端大模型、智能汽车、工业传感设备,各类智能终端的运转都离不开处理器的算力支撑。其中,CPU作为通用计算核心、GPU作为并行…...

IMX8QX MEK开发板烧录实战:手把手教你从官方BSP包到定制uuu脚本的全流程
IMX8QX MEK开发板烧录实战:从BSP解析到定制化uuu脚本全指南 拿到一块崭新的IMX8QX MEK开发板时,官方提供的BSP包往往像一座未经探索的金矿——资源丰富但路径复杂。本文将带你深入这座金矿,从文件定位到脚本定制,完成一次完整的烧…...

QML数据驱动UI:从ListModel与ListElement入门到实战
1. 为什么需要数据驱动UI? 第一次接触QML开发时,我习惯直接在UI组件里写死数据。比如要显示一个水果列表,可能会这样写: Column {Text { text: "Apple - $2.45" }Text { text: "Orange - $3.25" }Text { text…...

观察使用TaotokenTokenPlan后项目月度AI成本的变化趋势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察使用Taotoken TokenPlan后项目月度AI成本的变化趋势 对于许多采用按量计费模式的中小型项目而言,大模型API的月度支…...

KMS_VL_ALL_AIO终极指南:5分钟免费激活Windows和Office的完整方案
KMS_VL_ALL_AIO终极指南:5分钟免费激活Windows和Office的完整方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows和Office的激活问题而烦恼吗?KMS_VL_ALL_…...

Linux依赖冲突回溯生产排障流程
Linux依赖冲突回溯生产排障流程这是一篇面向中级 Linux 使用者的技术文章,主题聚焦在依赖冲突回溯,重点讨论库版本关系、安装失败和升级影响。在真实生产环境中,依赖冲突回溯相关问题往往不会以单一错误形式出现,而是混杂在日志、…...

B站视频转文字终极方案:3分钟学会一键智能提取视频内容
B站视频转文字终极方案:3分钟学会一键智能提取视频内容 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 还在为整理B站视频内容而烦恼吗࿱…...

VMware Unlocker终极指南:在Windows/Linux上运行macOS虚拟机
VMware Unlocker终极指南:在Windows/Linux上运行macOS虚拟机 【免费下载链接】unlocker VMware Workstation macOS 项目地址: https://gitcode.com/gh_mirrors/unloc/unlocker 想要在Windows或Linux电脑上体验苹果macOS系统吗?无论你是开发者需要…...

HLS技术解析:从原理到FPGA开发实战
1. HLS技术概述与评估背景高等级综合(High-Level Synthesis, HLS)技术正在重塑FPGA开发范式。作为从业十年的硬件加速工程师,我见证了这项技术从实验室走向工业界的全过程。传统RTL开发需要手动编写每一行寄存器传输级代码,而HLS允许开发者用C等高级语言…...
)
气候模型结果难解读?NotebookLM因果推理模块深度拆解(附GFDL-ESM4输出可复现分析链)
更多请点击: https://kaifayun.com 第一章:NotebookLM气候研究辅助 NotebookLM 是 Google 推出的基于 AI 的研究协作者,专为处理长文档、技术报告与多源数据而设计。在气候科学研究中,它可快速解析 IPCC 报告、CMIP6 模型输出摘要…...