【Hive】配置
目录
Hive参数配置方式
参数的配置方式
1. 文件配置
2. 命令行参数配置
3. 参数声明配置
配置源数据库
配置元数据到MySQL
查看MySQL中的元数据
Hive服务部署
hiveserver2服务
介绍
部署
启动
远程连接
1. 使用命令行客户端beeline进行远程访问
metastore服务
运行模式
部署
其他常见配置
显示当前表头和库
日志配置
Hive的JVM堆内存设置
关闭Hadoop虚拟内存检查
来源:
Hive参数配置方式
查看当前所有配置
hive>set;参数的配置方式
1. 文件配置
- 默认配置文件:hive-default.xml
- 用户自定义配置文件:hive-site.xml
用户自定义配置会覆盖默认配置。另外,Hive也会读入Hadoop的配置,因为Hive是作为Hadoop的客户端启动的,Hive的配置会覆盖Hadoop的配置。配置文件的设定对本机启动的所有Hive进程都有效。
2. 命令行参数配置
bin/hive -hiveconf (param=value)查看参数设置
set (param);3. 参数声明配置
hive> set (param=value);后两种只对本次有效。
配置文件 < 命令行参数 < 参数声明。
log4j相关的设定,必须用前两种方式设定,因为那些参数的读取在会话建立以前已经完成了。
配置源数据库
Hive默认使用的元数据库为derby。derby数据库的特点是同一时间只允许一个客户端访问。如果多个Hive客户端同时访问,就会报错。
删除derby.log,metastore_db,HDFS上目录
rm -rf derby.log metastore_db
hadoop fs -rm -r /user通过hdfs的web界面 ,删除hdfs里的/user/hive/warehouse/stu
安装mysql
(13条消息) 【Linux】安装MySQL数据库_岱宗夫如何、的博客-CSDN博客
配置元数据到MySQL
新建Hive元数据库
mysql -uroot -p
create database metastore;
quit将MySQL的JDBC驱动拷贝到Hive的lib目录下
cp /opt/software/mysql-connector-java-5.1.37.jar $HIVE_HOME/lib在$HIVE_HOME/conf目录下新建hive-site.xml文件
vim $HIVE_HOME/conf/hive-site.xml<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- jdbc连接的URL --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value></property><!-- jdbc连接的Driver--><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><!-- jdbc连接的username--><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><!-- jdbc连接的password --><property><name>javax.jdo.option.ConnectionPassword</name><value>密码</value></property><!-- Hive默认在HDFS的工作目录 --><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value></property>
</configuration>
初始化Hive元数据库
bin/schematool -dbType mysql -initSchema -verbose检验测试
bin/hive
hive> show databases;
hive> show tables;
hive> create table stu(id int, name string);
hive> insert into stu values(1,"ss");
hive> select * from stu;
在Xshell窗口中开启另一个窗口开启Hive(两个窗口都可以操作Hive,没有出现异常)
hive> show databases;
hive> show tables;
hive> select * from stu;
查看MySQL中的元数据
mysql -uroot -p
show databases;
use metastore;
show tables;
查看库信息,
有在hdbfs根目录
select * from BDS;
查看表信息
select * from TBLS;
表的存储路径,outputf,inputf
select * from SDS;
查看列相关信息
select * from COLUMNS_V2;Hive服务部署
hiveserver2服务
介绍
ve的hiveserver2服务的作用是提供jdbc/odbc接口,为用户提供远程访问Hive数据的功能,例如用户期望在个人电脑中访问远程服务中的Hive数据,就需要用到Hiveserver2。
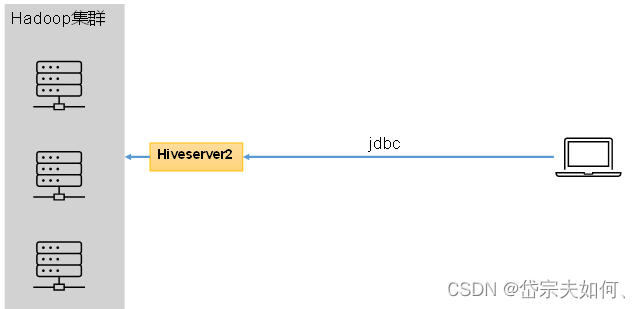
远程访问集群通过 Hiveserver2 代理;模拟用户的功能,默认是开启的。
未开启用户模拟功能:Hiveserver2的启动用户
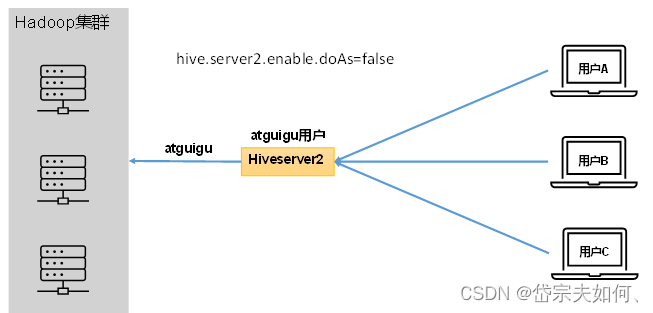
开启用户模拟功能:
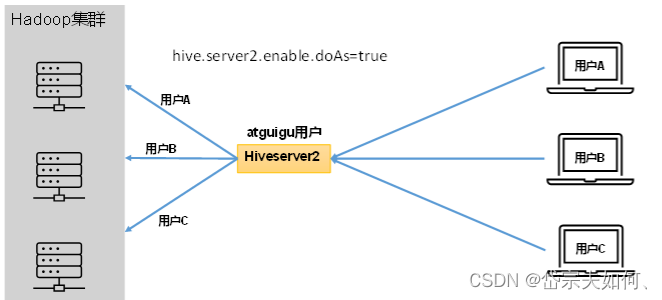
生产环境,推荐开启用户模拟功能,因为开启后才能保证各用户之间的权限隔离。
部署
1. Hadoop端配置
hivesever2的模拟用户功能,依赖于Hadoop提供的proxy user(代理用户功能);因此,需要将hiveserver2的启动用户设置为Hadoop的代理用户
cd $HADOOP_HOME/etc/hadoop
vim core-site.xml
<!--配置所有节点的atguigu用户都可作为代理用户-->
<property><name>hadoop.proxyuser.atguigu.hosts</name><value>*</value>
</property><!--配置atguigu用户能够代理的用户组为任意组-->
<property><name>hadoop.proxyuser.atguigu.groups</name><value>*</value>
</property><!--配置atguigu用户能够代理的用户为任意用户-->
<property><name>hadoop.proxyuser.atguigu.users</name><value>*</value>
</property>
分发配置文件
2. 配置Hive
vim conf/hive-site.xml<!-- 指定hiveserver2连接的host -->
<property><name>hive.server2.thrift.bind.host</name><value>hadoop102</value>
</property><!-- 指定hiveserver2连接的端口号 -->
<property><name>hive.server2.thrift.port</name><value>10000</value>
</property>
启动
bin/hive --service hiveserver2nohup bin/hiveserver2 >/dev/null 2>&1 &jpsJps jps -ml
Nohup 不挂断, & 后台
Nohup bin/hiveserver2 &
1>/dev/null 丢弃标准输出
2>&1
进程文件描述符 0标准输入 1标准输出 2标准错误
远程连接
1. 使用命令行客户端beeline进行远程访问
hive beeline详解 - 简书 (jianshu.com)
2.使用图形化界面
(DataGrip)
metastore服务
Hive的metastore服务的作用是为Hive CLI或者Hiveserver2提供元数据访问接口。
运行模式
嵌入式模式
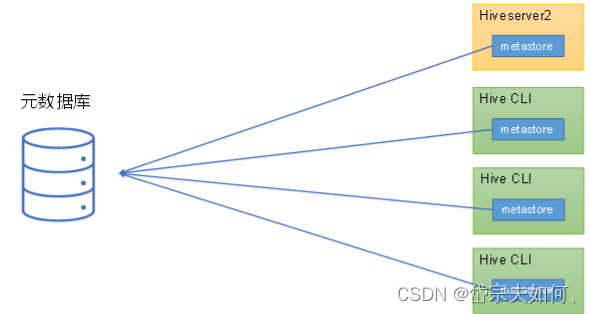
独立服务模式
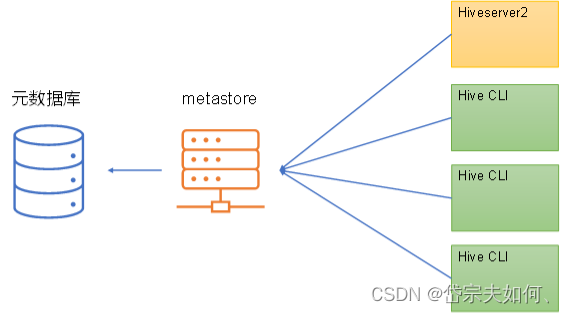
生产环境中,不推荐使用嵌入式模式。因为其存在以下两个问题:
(1)嵌入式模式下,每个Hive CLI都需要直接连接元数据库,当Hive CLI较多时,数据库压力会比较大。
(2)每个客户端都需要用户元数据库的读写权限,元数据库的安全得不到很好的保证。
部署
嵌入式模式
只需保证Hiveserver2和每个Hive CLI的配置文件hive-site.xml中包含连接元数据库所需要的以下参数即可:
<!-- jdbc连接的URL --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value></property><!-- jdbc连接的Driver--><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><!-- jdbc连接的username--><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><!-- jdbc连接的password --><property><name>javax.jdo.option.ConnectionPassword</name><value>密码</value></property>
独立服务模式
hive-site.xml
<!-- jdbc连接的URL --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value></property><!-- jdbc连接的Driver--><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><!-- jdbc连接的username--><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property>
<!-- jdbc连接的password --><property><name>javax.jdo.option.ConnectionPassword</name><value>密码</value></property><!-- 指定metastore服务的地址 -->
<property><name>hive.metastore.uris</name><value>thrift://hadoop102:9083</value>
</property>
主机名需要改为metastore服务所在节点,端口号无需修改,metastore服务的默认端口就是9083。
在Hive CLI的配置文件中配置了hive.metastore.uris参数,此时Hive CLI会去请求我们执行的metastore服务地址,所以必须启动metastore服务才能正常使用。
测试
hive --service metastore
注意:启动后该窗口不能再操作,需打开一个新的Xshell窗口来对Hive操作。
bin/hive其他常见配置
显示当前表头和库
hive-site.xml
<!--显示当前使用的表-->
<property><name>hive.cli.print.header</name><value>true</value><description>Whether to print the names of the columns in query output.</description>
</property>
<!--显示当前使用的库-->
<property><name>hive.cli.print.current.db</name><value>true</value><description>Whether to include the current database in the Hive prompt.</description>
</property>
日志配置
log默认配置在/tmp/用户/hive.log
修改log存放目录
cd $HIVE_HOME/conf/
mv hive-log4j2.properties.template hive-log4j2.properties
vim hive-log4j2.propertiesproperty.hive.log.dir=${HIVE_HOME}/logsHive的JVM堆内存设置
Hive启动的时候,默认申请的JVM堆内存大小为256M,JVM堆内存申请的太小,导致后期开启本地模式,执行复杂的SQL时经常会报错:java.lang.OutOfMemoryError: Java heap space.
cd $HIVE_HOME/conf
mv hive-env.sh.template hive-env.sh
vim hive-env.sh# The heap size of the jvm stared by hive shell script can be controlled via:
export HADOOP_HEAPSIZE=2048
关闭Hadoop虚拟内存检查
修改前记得先停Hadoop
stop-yarn.sh
vim yarn-site.xml
<property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value>
</property>
分发集群
来源:
尚硅谷
相关文章:
【Hive】配置
目录 Hive参数配置方式 参数的配置方式 1. 文件配置 2. 命令行参数配置 3. 参数声明配置 配置源数据库 配置元数据到MySQL 查看MySQL中的元数据 Hive服务部署 hiveserver2服务 介绍 部署 启动 远程连接 1. 使用命令行客户端beeline进行远程访问 metastore服务 …...

IP-GUARD如何强制管控电脑设置开机密码要符合密码复杂度?
如何强制管控电脑设置开机密码要符合密码复杂度? 7 可以在控制台-【策略】-【定制配置】,添加一条配置,开启系统密码复杂度检测。 类别:自定义 关键字:bp_password_complexity 内容:1 效果图:...

剑指 Offer II 031. 最近最少使用缓存
题目链接 剑指 Offer II 031. 最近最少使用缓存 mid 题目描述 运用所掌握的数据结构,设计和实现一个 LRU(Least Recently Used,最近最少使用) 缓存机制 。 实现 LRUCache类: LRUCache(int capacity)以正整数作为容量 capacity初始化 LRU缓…...

44岁了,我从没想过在CSDN创作2年,会有这么大收获
1998年上的大学,02年毕业,就算从工作算起,我也有20余年的码龄生涯了。 但正式开启博文的写作,却是2021年开始的,差不多也就写了2年的博客,今天我来说说我在CSDN的感受和收获。 我是真的没想到,…...
相位相参信号源的设计--示波器上的信号不稳定,来回跑?
目录乱跑的波形边沿触发触发方式外部触发相参与非相参相位相参的射频信号源样机外观与内部设计软件设计上位机软件信号源使用方法PWM触发信号射频信号的时域波形射频信号的频谱输出功率在示波器的实际使用当中波形在示波器的时域上乱跑,左右移动,定不下来…...

Spring Boot 整合 RabbitMQ 多种消息模式
Spring Boot 整合 RabbitMQ 多种消息模式 准备工作集成 RabbitMQ发布/订阅模式点对点模式主题模式总结Spring Boot 是一个流行的 Java 应用程序开发框架,而 RabbitMQ 是一款可靠的消息队列软件。将 Spring Boot 和 RabbitMQ 结合起来可以帮助我们轻松地实现异步消息传递。Rabb…...

node多版本控制
前言 最近在折腾Python,并将node升级至v18.14.2。突然发现一个旧项目无法运行,也无法打包,里面的node-sass报错,显然这是因为node版本过高导致的。 将node版本降低至以前的v14.16.0,果然立马就能正常运行。 存在不同…...

Redis set集合
Redis set (集合)遵循无序排列的规则,集合中的每一个成员(也就是元素,叫法不同而已)都是字符串类型,并且不可重复。Redis set 是通过哈希映射表实现的,所以它的添加、删除、查找操作…...

漫画:什么是希尔排序算法?
希尔排序(ShellSort)是以它的发明者Donald Shell名字命名的,希尔排序是插入排序的改进版,实现简单,对于中等规模数据的性能表现还不错 一、排序思想 前情回顾:漫画:什么是插入排序算法…...
问卷工具选择要看哪些方面?
通常来讲,我们在使用一款问卷制作工具制作问卷时会有哪些需求呢? 一、用户需求 1、操作简单,易上手。 2、能够满足用户个性化的需求。 3、提供多语言服务。 4、能够帮助发布以及数据收集。 5、简化数据分析 市面上的问卷调查制作工具都…...
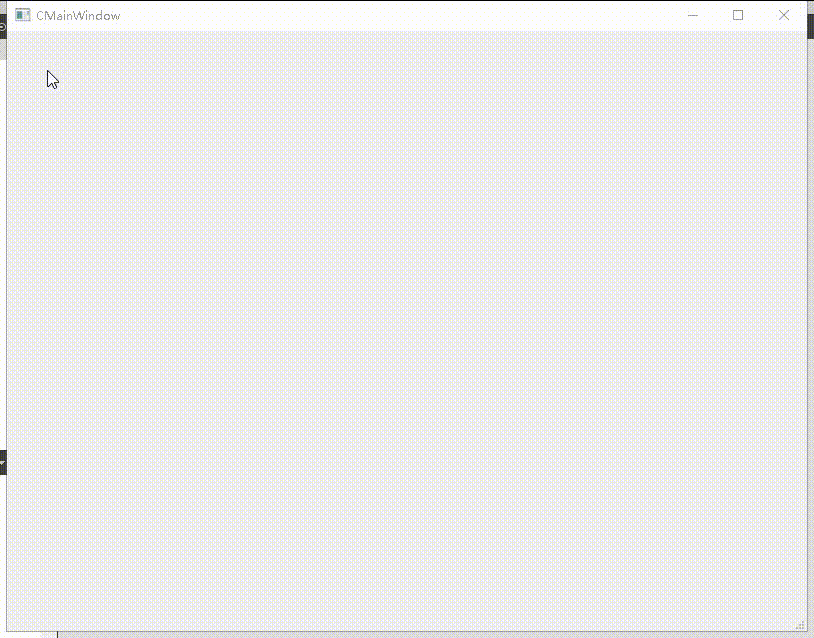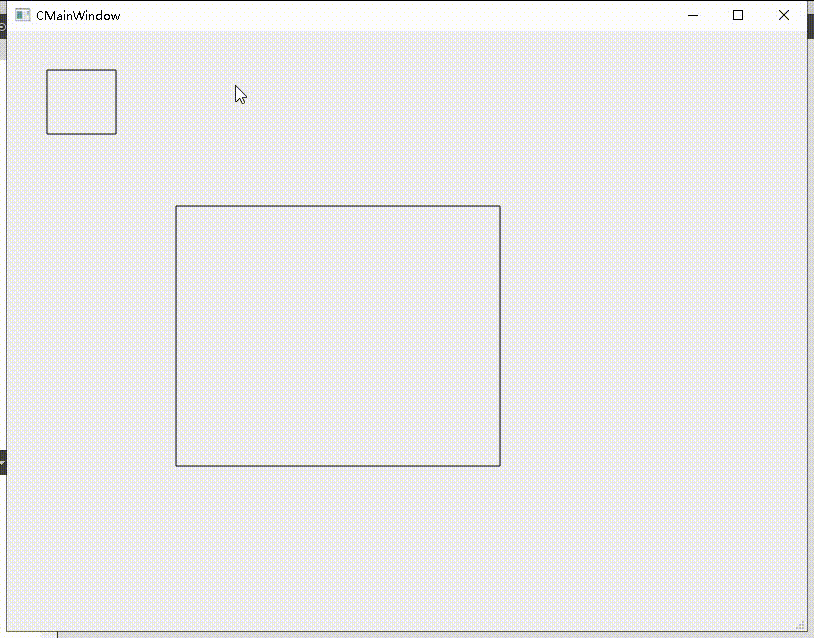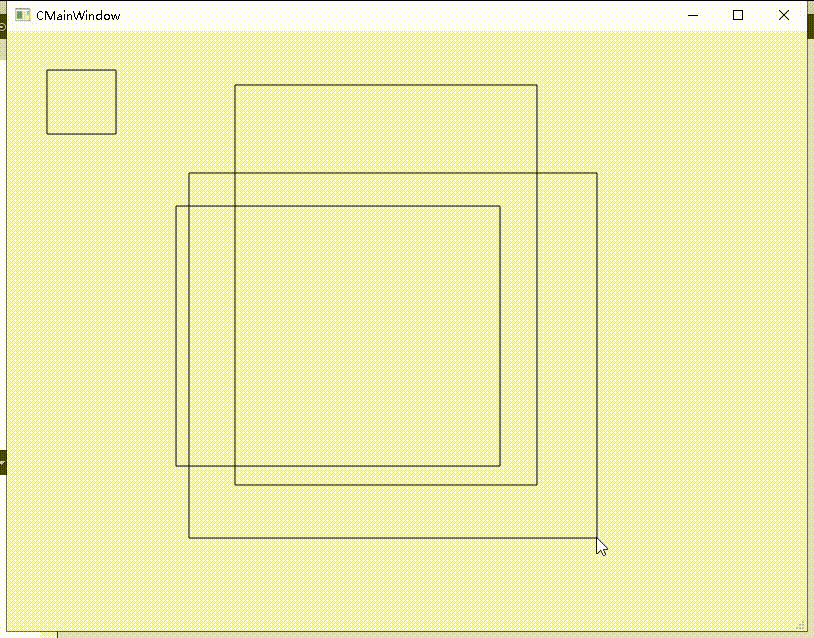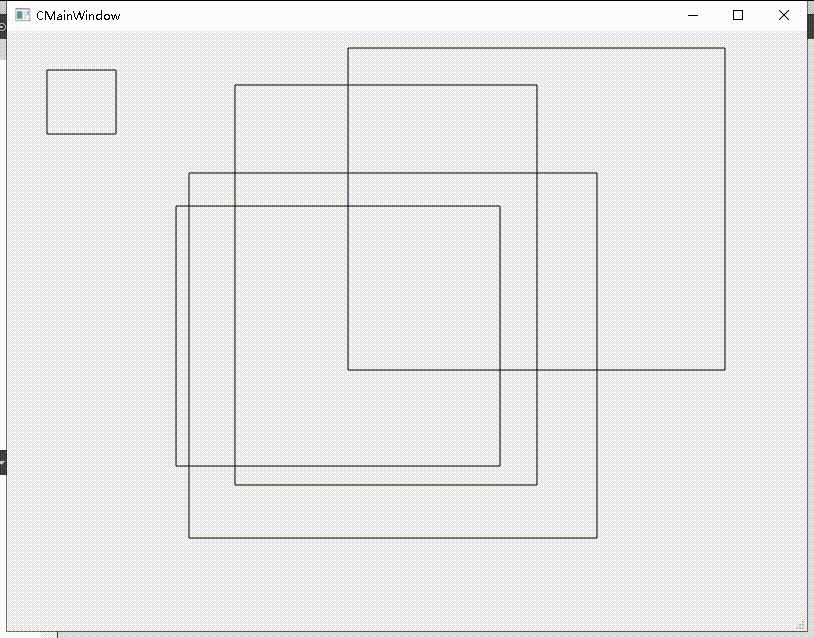
Qt之QPainter绘制多个矩形/圆形(含源码+注释)
一、绘制示例图 下图绘制的是矩形对象,但是将绘制矩形函数(drawRect)更改为绘制圆形(drawEllipse)即可绘制圆形。 二、思路解释 绘制矩形需要自然要获取矩形数据,因此通过鼠标事件获取每个矩形的rect数…...
介绍两款红队常用的信息收集组合工具
介绍两款红队常用的信息收集组合工具1.Ehole本地识别FOFA识别结果输出2.AlliN1.Ehole EHole(棱洞)3.0 红队重点攻击系统指纹探测工具 EHole是一款对资产中重点系统指纹识别的工具,在红队作战中,信息收集是必不可少的环节,如何才能从大量的资…...
类ChatGPT国产大模型ChatGLM-6B,单卡即可运行
2023年3月14日GPT4又发布了,在ChatGPT发展如火如荼的当下,我们更应该关注国内的进展,今天将分享一个清华大学基于GLM-130B模型开发的类似ChatGPT的ChatGLM-6B模型,ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型࿰…...
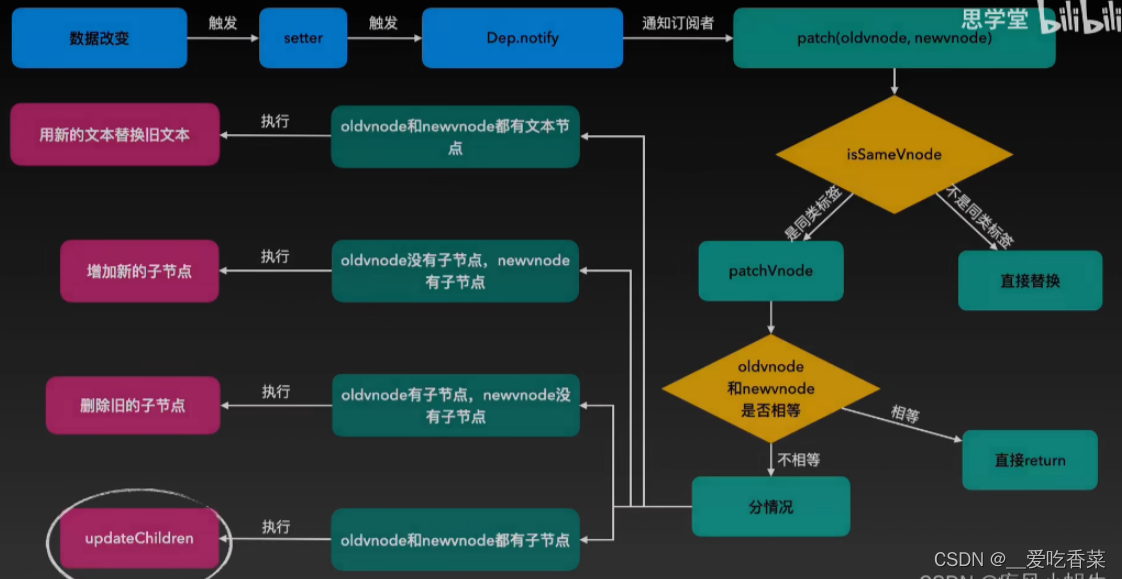
vue的diff算法?
文章目录是什么比较方式原理分析Diff算法的步骤:首尾指针法比对顺序:是什么 diff 算法是一种通过同层的树节点进行比较的高效算法 其有两个特点: 比较只会在同层级进行, 不会跨层级比较 在diff比较的过程中,循环从两边向中间比较…...

C++ | 对比inline内联函数和宏的不同点
文章目录一、前言二、宏的优缺点分析1、概念回顾2、宏的缺点3、宏的优点三、inline内联函数1、概念2、特性①:空间换时间🎁趣味杂谈:庞大的游戏更新包3、特性②:inline实现机制4、特性③:inline的声明与定义反汇编观察…...
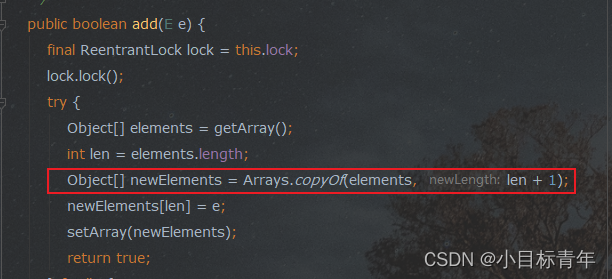
面试官问 : ArrayList 不是线程安全的,为什么 ?(看完这篇,以后反问面试官)
前言 金三银四 ? 也许,但是。 近日,又收到金三银四一线作战小队成员反馈的战况 : 我不管你从哪里看的面经,但是我不允许你看到我这篇文章之后,还不清楚这个面试问题。 本篇内容预告: Array…...
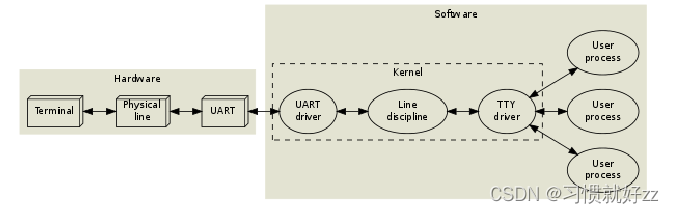
Linux串口应用编程
一、 串口API 在Linux系统中,操作设备的统一接口就是:open/ioctl/read/write。 对于UART,又在ioctl之上封装了很多函数,主要是用来设置行规程。 所以对于UART,编程的套路就是: open设置行规程,比如波特率、数据位、停止位、检验位、RAW模式、一有数据就返回read/write 怎么设置…...

java程序员学前端-HTML篇
HTML 与 CSS HTML 是什么:即 HyperText Markup language 超文本标记语言,咱们熟知的网页就是用它编写的,HTML 的作用是定义网页的内容和结构。 HyperText 是指用超链接的方式组织网页,把网页联系起来Markup 是指用 <标签>…...

【云原生|Docker】03-docker的基础操作
目录 前言 查询相关 容器相关 1. 容器启动 2. 容器关闭 3. 重启容器 4. 暂停容器 5. 删除容器 6. docker run参数汇总 镜像相关 1. 镜像推送至仓库 2. docker image load使用 3. docker image import使用 4. dokcer image参数汇总 前言 容器的命…...
vue2+高德地图web端开发使用
创建vue2项目我们创建一个vue2项目,创建vue2项目就不用再多说了吧,使用“vue create 项目名 ”创建即可注册高德地图高德地图官网地址:https://lbs.amap.com/如果是第一次使用,点击注册然后进入我们的控制台注册完之后进入控制台&…...

CoPaw:让AI代码助手深度适配个人项目与团队规范的工程化实践
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫CoPaw,作者是 alexgzx。光看名字可能有点摸不着头脑,但如果你对 AI 辅助编程、代码生成或者想提升自己的开发效率感兴趣,那这个项目绝对值得你花时间研究一下。简单来说…...
)
保姆级教程:在Ubuntu 20.04上从源码编译aarch64-linux-gnu交叉工具链(GCC 9.2.0 + Glibc 2.30)
深度实践:从源码构建aarch64-linux-gnu交叉工具链全指南 在嵌入式开发领域,交叉编译工具链的构建能力是区分普通开发者与资深工程师的重要标志。当现成的预编译工具链无法满足特定需求时,从源码手动构建工具链不仅能解决兼容性问题࿰…...

3步解锁鸣潮120帧:你的终极游戏体验优化指南
3步解锁鸣潮120帧:你的终极游戏体验优化指南 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 还在为《鸣潮》游戏中的60帧限制而烦恼吗?明明拥有强大的硬件配置,却无法充…...

从myplaces.shp到专题地图:手把手教你用QGIS C++ API实现点要素分级渲染
从myplaces.shp到专题地图:QGIS C API实现点要素分级渲染实战指南 当我们需要在桌面GIS应用中直观展示气象站降雨量、城市人口密度或商业网点销售额等连续型空间数据时,分级色彩渲染是最有效的可视化手段之一。本文将深入探讨如何利用QGIS强大的C API&am…...

Source Han Serif CN:企业级开源字体终极实战指南
Source Han Serif CN:企业级开源字体终极实战指南 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 在当今数字化时代,企业面临字体选择的两难困境:商…...

终极跨平台漫画阅读方案:nhentai-cross全平台使用指南
终极跨平台漫画阅读方案:nhentai-cross全平台使用指南 【免费下载链接】nhentai-cross A nhentai client 项目地址: https://gitcode.com/gh_mirrors/nh/nhentai-cross 你是否厌倦了在不同设备间切换漫画阅读应用?nhentai-cross正是为你量身定制…...

在线Graphviz图表编辑器:3步创建专业技术流程图
在线Graphviz图表编辑器:3步创建专业技术流程图 【免费下载链接】GraphvizOnline Lets Graphviz it online 项目地址: https://gitcode.com/gh_mirrors/gr/GraphvizOnline 还在为复杂的技术图表绘制而烦恼吗?GraphvizOnline作为一款革命性的在线G…...

终极指南:如何在Mac上免费备份和导出微信聊天记录
终极指南:如何在Mac上免费备份和导出微信聊天记录 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾因误删重要微信聊天记录而懊恼?或是需要…...

怎样免费让老Mac重获新生:OpenCore Legacy Patcher专业教程
怎样免费让老Mac重获新生:OpenCore Legacy Patcher专业教程 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 想让你的旧Mac重新焕发活力吗…...
)
低多边形≠简陋!掌握这7个结构化Prompt技巧,3分钟产出可商用IP形象(附Figma网格对齐校验表)
更多请点击: https://intelliparadigm.com 第一章:低多边形设计的认知革命:从“简陋感”到“结构化美学” 低多边形(Low-Poly)设计曾长期被误读为建模能力不足的妥协产物,但其本质是一场对数字视觉语法的系…...