大文件分片上传(前端TS实现)
大文件分片上传
内容
一般情况下,前端上传文件就是new FormData,然后把文件 append 进去,然后post发送给后端就完事了,但是文件越大,上传的文件也就越长,如果在上传过程中,突然网络故障,又或者请求超时,等待过久等等情况,就会导致错误而后又得重新传大文件。所以这时候就要使用分片上传了,就算断网了也能继续接着上传(断点上传),如果是之前上传过这个文件了(服务器还存着),就不需要做二次上传了(秒传)。
7.17实现方式
首先获取文件信息后设定分片大小对文件进行分片(slice函数),而后为文件生成一个hash对文件进行标注。在请求时先验证所上传的文件是否已经存在于服务器(若是则直接提示上传成功,即秒传功能),若不存在或部分存在则需要后端返回上传成功的分片标识数组,前端将使用成功分片数组与原文件分片数组进行处理得到未上传成功的分片,而后将未成功的分片以并发方式上传至后端。上传后即完成了整个文件的上传,向后端发送合并分片请求即完成大文件分片上传,断点续传功能。
7.19实现方式(即彻底完成功能)
步骤:
- 由于前端计算md5耗时过长,可能会导致页面卡死,因此考虑使用Web Worker来计算md5,即使用worker.js(使用spark-md5)文件来计算:分片数组,分片哈希数组,文件整体哈希。
- 在拿到web worker所得到的分片数组,分片哈希数组,文件整体哈希后,即可开始进行大文件上传工作,前端使用文件整体哈希、文件名以及分片数组作为请求参数调用后端/init接口初始化上传操作。【initSend函数】。
- 初始化操作完成后,前端使用文件整体哈希作为参数调用后端/status接口获取此文件分片的状态信息,前端根据后端所返回的状态信息使用filter以及every方法得到:文件是否已经上传的状态existFile、后端存在的文件分片existChunks。若existFile为true,则直接提示上传成功,即秒传功能。【verifyInfo函数】
- 若existFile为false,则使用后端返回的existChunks数组与分片数组进行对比,得到未上传成功的分片数组,并将其分片信息(分片哈希值,分片内容,分片序号以及文件整体哈希值)作为formData参数发送至后端/chunk接口(在发送分片时使用并发操作,并限制最大并发数为6)【uploadChunks函数】
- 当所有分片发送完成后,前端给后端以文件整体哈希做为参数调用后端/merge接口提示后端可以进行合并操作,后端返回成功消息即完成大文件分片上传,断点续传功能。【mergeFile函数】
演示图
-
选择文件:

-
秒传:

-
分片上传:

代码内容
在后续操作中,完成了对请求的封装以及分片上传的hook的编写,主处理逻辑部分仅仅为下方所示:
const submitUpload = () => {const file = FileInfo.value;if(!file) {return;}fileName.value = file.name;const { mainDeal } = useUpload(file, fileName.value)mainDeal()
}
api的封装为下方所示:
import request from "@/utils/request";export async function initSend(uploadId, fileName, totalChunk) {return request({url: "/init",method: "POST",data: {uploadId,fileName,totalChunk,},});
}export async function verifyInfo(uploadId) {return request({url: "/status",method: "POST",data: {uploadId,},headers: { "Content-Type": "application/x-www-form-urlencoded" },});
}
export async function uploadSingle(formData) {return request({url: "/chunk",method: "POST",data: {formData,},headers: {"Content-Type": "multipart/form-data",},});
}
export async function mergeFile(uploadId) {return request({url: "/merge",method: "POST",data: {uploadId,},headers: {"Content-Type": "application/x-www-form-urlencoded",},});
}
useUpload钩子函数为:
import { ref } from "vue";
import axios from "axios";
import type { AxiosResponse } from "axios";
import {initSend,verifyInfo,mergeFile,uploadSingle,
} from "@/apis/uploadApi";
export function useUpload(fileInfo, filename) {const FileInfo = ref<File>(fileInfo);const fileName = ref(filename); // 文件名称const fileHash = ref(""); // 文件hashconst fileHashArr = ref([]);const chunks = ref([]);interface Verify {id?: Number;uploadId?: String;chunkIndex?: Number;status?: String;}const mainDeal = async () => {const worker = new Worker(new URL("@/utils/worker.js", import.meta.url), {type: "module",});const file = FileInfo.value;console.log(worker);console.log("file_info", file);worker.postMessage({ file: file });worker.onmessage = async (e) => {const { data } = e;chunks.value = data.fileChunkList;fileHashArr.value = data.fileChunkHashList;fileHash.value = data.fileMd5;console.log("uploadid", fileHash.value);const res_init = await initSend(fileHash.value,fileName.value,chunks.value.length);console.log("res_init", res_init);const { existFile, existChunks } = await verify(fileHash.value);if (existFile) return;uploadChunks(chunks.value, existChunks, fileHashArr.value);worker.terminate();};};// 控制请求并发const concurRequest = (taskPool: Array<() => Promise<Response>>,max: number): Promise<Array<Response | unknown>> => {return new Promise((resolve) => {if (taskPool.length === 0) {resolve([]);return;}console.log("taskPool", taskPool);const results: Array<Response | unknown> = [];let index = 0;let count = 0;console.log("results_before", results);const request = async () => {if (index === taskPool.length) return;const i = index;const task = taskPool[index];index++;try {results[i] = await task();console.log("results_try", results);} catch (err) {results[i] = err;} finally {count++;if (count === taskPool.length) {resolve(results);}request();}};const times = Math.min(max, taskPool.length);for (let i = 0; i < times; i++) {request();}});};// 合并分片请求const mergeRequest = async () => {return mergeFile(fileHash.value);};// 上传文件分片const uploadChunks = async (chunks: Array<Blob>,existChunks: Array<string>,md5Arr: Array<string>) => {const formDatas = chunks.map((chunk, index) => ({fileHash: fileHash.value,chunkHash: fileHash.value + "-" + index,chunkIndex: index,checksum: md5Arr[index],chunk,})).filter((item) => !existChunks.includes(item.chunkHash));console.log("formDatas", formDatas);const form_Datas = formDatas.map((item) => {console.log("!", item.chunkIndex);const formData = new FormData();formData.append("uploadId", item.fileHash);formData.append("chunkIndex", String(item.chunkIndex));formData.append("checksum", item.checksum);formData.append("file", item.chunk);return formData;});console.log("formDatas", form_Datas);const taskPool = form_Datas.map((formData) => () =>fetch("http://10.184.131.57:8101/ferret/upload/chunk", {method: "POST",body: formData,}));//控制请求并发const response = await concurRequest(taskPool, 6);console.log("response", response);// 合并分片请求const res_merge = await mergeRequest();console.log("res_merge", res_merge);};// 校验文件、文件分片是否存在const verify = async (uploadId: string) => {const res = await verifyInfo(uploadId);const { data } = res.data;console.log("verify", res);// 看服务器是不是已经有文件所有信息const existFile = data.every((item: Verify) => item.status === "Uploaded");const existChunks: string[] = [];data.filter((item: Verify) => {if (item.status === "Uploaded") {existChunks.push(`${item.uploadId}-${item.chunkIndex}`);}});console.log("existFile", existFile, "existChunks", existChunks);return {existFile,existChunks,};};return {mainDeal,};
}
web worker实现方式:
import SparkMD5 from 'spark-md5';
let DefaultChunkSize = 1024 * 1024 * 5; // 5MBself.onmessage = (e) => {console.log("!!>", e.data)if (e.data.file.size >= 1024 * 1024 * 100 && e.data.file.size < 1024 * 1024 * 512) {DefaultChunkSize = 1024 * 1024 * 10}else if (e.data.file.size >= 1024 * 1024 * 512) {DefaultChunkSize = 1024 * 1024 * 50}const { file, chunkSize = DefaultChunkSize } = e.data;let blobSlice = File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice,chunks = Math.ceil(file.size / chunkSize),currentChunk = 0,spark = new SparkMD5.ArrayBuffer(),fileChunkHashList = [],fileChunkList = [],fileReader = new FileReader();loadNext();function loadNext() {let start = currentChunk * chunkSize,end = ((start + chunkSize) >= file.size) ? file.size : start + chunkSize;let chunk = blobSlice.call(file, start, end);fileChunkList.push(chunk);fileReader.readAsArrayBuffer(chunk);}function getChunkHash(e) {const chunkSpark = new SparkMD5.ArrayBuffer();chunkSpark.append(e.target.result);fileChunkHashList.push(chunkSpark.end());}// 处理每一块的分片fileReader.onload = function (e) {spark.append(e.target.result);currentChunk++;getChunkHash(e)if (currentChunk < chunks) {loadNext();} else {// 计算完成后,返回结果self.postMessage({fileMd5: spark.end(),fileChunkList,fileChunkHashList,});fileReader.abort();fileReader = null;}}// 读取失败fileReader.onerror = function () {self.postMessage({error: 'wrong'});}
};
相关文章:
大文件分片上传(前端TS实现)
大文件分片上传 内容 一般情况下,前端上传文件就是new FormData,然后把文件 append 进去,然后post发送给后端就完事了,但是文件越大,上传的文件也就越长,如果在上传过程中,突然网络故障,又或者…...

unity2D游戏开发02添加组件移动玩家
添加组件 给PlayGame和EnemyObject添加组件BoxCollider 2D碰撞器,不用修改参数 给PlayGame添加组件Rigibody 2D 设置数据 添加EnemyObject,属性如下 Edit->project setting->Physics 2D 将 y的值改为0 给playerObject添加标签 新建层 将PlayerObj…...

设计模式 之 —— 单例模式
目录 什么是单例模式? 定义 单例模式的主要特点 单例模式的几种设计模式 1.懒汉式:线程不安全 2.懒汉式:线程安全 3.饿汉式 4.双重校验锁 单例模式的优缺点 优点: 缺点: 适用场景: 什么是单例模…...
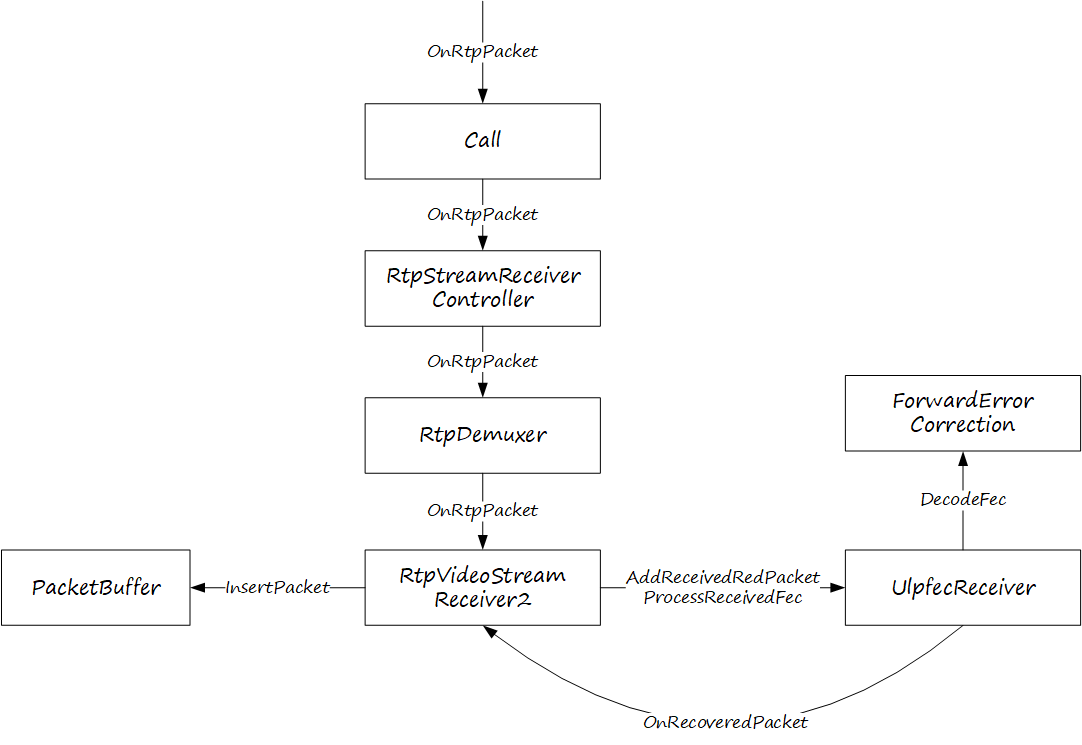
深入浅出WebRTC—ULPFEC
FEC 通过在发送端添加额外的冗余信息,使接收端即使在部分数据包丢失的情况下也能恢复原始数据,从而减轻网络丢包的影响。在 WebRTC 中,FEC 主要有两种实现方式:ULPFEC 和 FlexFEC,FlexFEC 是 ULPFEC 的扩展和升级&…...

Python从0到100(四十三):数据库与Django ORM 精讲
前言: 零基础学Python:Python从0到100最新最全教程。 想做这件事情很久了,这次我更新了自己所写过的所有博客,汇集成了Python从0到100,共一百节课,帮助大家一个月时间里从零基础到学习Python基础语法、Pyth…...

Redis-主从模式
目录 前言 一.主从节点介绍 二.配置redis主从结构 二.主从复制 四.拓扑结构 五.数据同步 全量复制(Full Sync Replication) 局部复制(Partial Replication) Redis的学习专栏:http://t.csdnimg.cn/a8cvV 前言 …...
加速决策过程:企业级爬虫平台的实时数据分析
摘要 在当今数据驱动的商业环境中,企业如何才能在海量信息中迅速做出精准决策?本文将探讨企业级爬虫平台如何通过实时数据分析加速决策过程,实现数据到决策的无缝衔接。我们聚焦于技术如何赋能企业,提升数据处理效率,…...
数组实现(只能查26个单词))
字典树(前缀树)数组实现(只能查26个单词)
这段代码实现了一个基于 Trie 树的字典树(Trie)数据结构,用于存储和检索字符串。其中包含以下几个方法. insert(String word): 向 Trie 树中插入一个单词。首先将单词转换为字符数组,然后遍历字符数组,逐个字符在 Trie…...

CTF-pwn-虚拟化-vmmware 前置
文章目录 参考vmware逃逸简介虚拟机和主机通信机制(guest to host)共享内存(弃用)backdoor机制Message_Send和Message_RecvGuestRPC实例RpcOutSendOneRawWork实例 vmware-rpctool info-get guestinfo.ip各个步骤对应的backdoor操作Open RPC channelSend …...

thinkphp8结合layui2.9 图片上传验证
<?php declare (strict_types 1);namespace app\index\validate;use think\Validate;class Upload extends Validate {/*** 定义验证规则* 格式:字段名 > [规则1,规则2...]** var array*/protected $rule [image > fileExt:jpg,png|fileSize:204800|fi…...

农村污水处理难题:探索低成本高效解决方案
农村污水处理难题:探索低成本高效解决方案 农村污水处理作为国家生态文明建设的重要一环,面临着诸多挑战,尤其是技术落后、管理分散、资源匮乏等问题。物联网技术的引入,为解决这些痛点提供了创新途径,实现了对污水处…...

lightningcss介绍及使用
lightningcss介绍及使用 一款使用 rust 编写的 css 解析器,转换器、及压缩器。 特性 特别快:可以在毫秒级别解析、压缩大量的 css 文件,而且比其他工具的打包结果更小给值添加类型:许多其他css解析器会将值解析成一个无类型的 …...

HTTP服务的应用
1、编辑json请求参数; 2、把json发送到服务url,接收服务的返回参数; 3、解析返回参数。 procedure TfrmCustomQuery.btnFullUpdateClick(Sender: TObject); varfrm: TfrmInputQueryConditionEX;b_OK: Boolean;sBeginDate, sEndDate, sJSON…...

uni-app:踩坑路---scroll-view内使用fixed定位,无效的问题
前言: emmm,说起来这个问题整得还挺好笑的,本人在公司内,奋笔疾书写代码,愉快的提交测试的时候,测试跟我说,在苹果手机上你这个样式有bug,我倒是要看看,是什么bug。 安卓…...

MySQL4.索引及视图
1.建库 create database mydb15_indexstu; use mydb15_indexstu;2.建表 2.1 student表学(sno)号为主键,姓名(sname)不能重名,性别(ssex)仅能输入男或女,默认所在系别&a…...

MongoDB - 聚合阶段 $match、$sort、$limit
文章目录 1. $match 聚合阶段1. 构造测试数据2. $match 示例3. $match 示例 2. $sort 聚合阶段1. 排序一致性问题2. $sort 示例 3. $limit 聚合阶段 1. $match 聚合阶段 $match 接受一个指定查询条件的文档。 $match 阶段语法: { $match: { <query> } }$ma…...

ModuleNotFoundError: No module named ‘scrapy.utils.reqser‘
在scrapy中使用scrapy-rabbitmq-scheduler会出现报错 ModuleNotFoundError: No module named scrapy.utils.reqser原因是新的版本的scrapy已经摒弃了该方法,但是scrapy-rabbitmq-scheduler 没有及时的更新,所以此时有两种解决方法 方法一.将scrapy回退至旧版本,找到对应的旧版…...

vue3+ts+vite+electron+electron-packager打包成exe文件
目录 1、创建vite项目 2、添加需求文件 3、根据package.json文件安装依赖 4、打包 5、electron命令运行 6、electron-packager打包成exe文件 Build cross-platform desktop apps with JavaScript, HTML, and CSS | Electron 1、创建vite项目 npm create vitelatest 2、添…...

使用脚本搭建MySQL数据库基础环境
数据库的基本概念 数据(Data) 描述事物的符号记录 包括数字,文字,图形。图像,声音,档案记录等。 以记录形式按统一格式进行存储 表 将不同的记录组织在一起 用来储存具体数据 数据库 表的集合,是…...

Parameter index out of range (2 > number of parameters, which is 1【已解决】
文章目录 1、SysLogMapper.xml添加注释导致的2、解决方法3、总结 1、SysLogMapper.xml添加注释导致的 <!--定义一个查询方法,用于获取日志列表--><!--方法ID为getLogList,返回类型com.main.server.api.model.SysLogModel,参数类型为com.main.se…...

抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践
抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

如何高效批量下载音乐歌词:智能歌词管理完整指南
如何高效批量下载音乐歌词:智能歌词管理完整指南 【免费下载链接】ZonyLrcToolsX ZonyLrcToolsX 是一个能够方便地下载歌词的小软件。 项目地址: https://gitcode.com/gh_mirrors/zo/ZonyLrcToolsX ZonyLrcToolsX 是一款专业的跨平台歌词下载工具,…...

股票买卖最佳时机:LeetCode121题解
题目LeetCode121给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。返回你可以从这笔交易中获取…...

脉冲神经网络加速器设计与边缘计算优化
1. 脉冲神经网络加速器的设计挑战与突破在边缘计算领域,脉冲神经网络(SNN)正以其独特的生物启发特性引发新一轮技术变革。与传统人工神经网络(ANN)相比,SNN通过离散的脉冲信号传递信息,模拟生物神经元的工作机制,理论上可实现超低…...

告别多头对接!DMXAPI 为企业打造国产大模型 “统一入口”
一、企业 AI 落地的普遍痛点:被接口和平台消耗的成本在企业数字化转型的浪潮中,AI 大模型已经成为标配,但很多企业在落地时,都会陷入一个共同的困境:为了满足不同业务场景的需求,需要同时对接 DeepSeek、阿…...

告别漫长等待:UE5.2.1 Windows打包效率优化与插件问题排查指南
告别漫长等待:UE5.2.1 Windows打包效率优化与插件问题排查指南第一次点击"打包项目"按钮时,进度条仿佛被冻结的场景,每个UE5开发者都经历过。尤其当项目规模达到数十GB时,等待时间可能超过一小时——这背后隐藏着引擎底…...

ubuntu环境下为python项目配置taotoken多模型api密钥与端点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Ubuntu环境下为Python项目配置Taotoken多模型API密钥与端点 1. 准备工作 在Ubuntu系统上为Python项目接入Taotoken,首…...

告别Windows卡顿!在VMware里给Kubuntu 22.04 LTS分区和安装的保姆级避坑指南
告别Windows卡顿!在VMware里给Kubuntu 22.04 LTS分区和安装的保姆级避坑指南你是否已经厌倦了Windows系统越来越慢的启动速度、频繁的后台更新和资源占用?当你的电脑开始频繁卡顿,或许该考虑给系统来一次"减负"了。Kubuntu 22.04 L…...

AI算法工程师如何进行数据预处理?这5个步骤让你的数据更优质
在AI模型开发与测试的全流程中,数据质量直接决定了最终模型的效果上限——哪怕是最先进的大语言模型,用劣质数据训练出来也只能输出劣质结果。对于软件测试从业者来说,不管是参与AI模型的功能测试、性能测试,还是负责测试数据集的…...

免费解锁八大网盘限速!LinkSwift直链下载助手终极指南
免费解锁八大网盘限速!LinkSwift直链下载助手终极指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼…...