12 前端工程化
组件化
1. 组件化理解
就是将页面的某一部分独立出来,将这一部分的数据层(M)、视图层(V)和控制层(C)用黑盒的形式全部封装到一个组件内,暴露出一些开箱即用的函数和属性供外部调用。无论这个组件放到哪里去使用,它都具有一样的功能和样式,从而实现复用(只写一处,处处复用),这种整体化的思想就是组件化
每个组件都是独立的个体,都只负责一块功能。组件之间互相独立,通过特定的方式进行沟通。外部完全不用考虑组件的内部实现逻辑。一个好的前端组件,必须要把维护性,复用性,扩展性,性能做到极致
2. 组件化与模块化的区别
2.1 从历史发展角度来讲
随着前端开发越来越复杂、对效率要求越来越高,由项目级模块化开发,进一步提升到通用功能组件化开发,模块化是组件化的前提,组件化是模块化的演进
2.2 从整体概念来讲
- 模块化是一种分治的思想,述求是解耦,一般指的是 JavaScript 模块,比如用来格式化时间的模块
- 组件化是模块化思想的实现手段,述求是复用,包含了 template,style,script,script又可以由各种模块组成
2.3 从复用的角度来讲
- 模块一般是项目范围内按照项目业务内容来划分的,比如一个项目划分为子系统、模块、子模块,代码分开就是模块,位于架构业务框架层,横向分块
- 组件是按照一些小功能的通用性和可复用性抽象出来的,可以跨项目的,是可复用的模块,通常位于架构底层,被其他层所依赖
2.4 从划分的角度来讲
- 模块是从代码逻辑的角度进行划分,方便代码分层开发,保证每个功能模块的职能单一
- 组件是从 UI 界面的角度进行划分,前端的组件化,方便 UI 组件的重用
3. 为什么要前端组件化
随着前端项目复杂度的急剧增加,我们很容易遇到以下这些场景:
- 页面逻辑越来越多,代码越写越庞大,容易牵一发而动全身
- 同样的逻辑在多个地方重复编写,改一个问题要在多个地方进行同样的修改
以上场景带来的问题就是:
- 项目复杂度增加
- 重复性劳动多,效率低
- 代码质量差,不可控
因此前端组件化可以给我们带来:
- 增加代码的复用性,灵活性
- 提高开发效率,降低开发成本
- 便于各个开发者之间分工协作、同步开发
- 降低系统各个功能的耦合性,提高了功能内部的聚合性
- 降低代码的维护成本
4. 组件的划分
4.1 划分方法
尽可能抽象和解耦。不断抽象出一个跟业务没有关系的模块,它是可以继承的,这就是组件化设计的思维转换。
划分粒度:需要根据实际情况权衡,太小会提升维护成本,太大又不够灵活。
目前还没有一套原则和方法论来指导组件的划分,我们只能根据前人的经验再结合实际情况来进行组件的划分。
关于组件划分的一些建议:
- 组件之间的依赖应该尽可能的少。
- 单个组件代码量最好不要超过1000行。
- 组件划分的依据通常是业务逻辑、功能,要考虑各组件之间的关系是否明确,以及组件的可复用度。
- 每一个组件都应该有其独特的划分目的,有的是为了复用实现,有的是为了封装复杂度、清晰业务实现。
我经常的做法是:如果看到有多个页面都出现了这个重复元素,则抽取成一个组件。还有在开发之中发现结构相似的也可以考虑抽取成一个组件。没有必要在一开始就把所有都抽取成一个个组件。
4.2 组件分类
4.2.1 基础UI组件
这是最小化的组件,它们不依赖于其他组件。作为页面中最少的元素而存在,比如按钮、下拉菜单、对话框等。其中大部分是对原生 Web 元素的封装,例如: 、 、 ,它们以简单的形式存在。
- 在创建基础组件的过程中,要遵循一个基本原则:基础组件是独立存在的。它们可以共享配置,但是不能相互依赖,依赖意味着它不是基础组件。
- 像 antd、iview、element-ui 里提供的基本都是基础 UI 组件。
4.2.2 复合组件
复合组件是在多个基础的 UI 组件上的进一步结合。大部分复合组件,包含了一些复杂的组件,往往需要花很长的时间,才能变成一个可稳定使用的版本。复合组件包含以下几个部分:
- 表格:表格往往带有复杂的交互,比如固定行、固定列、可编辑、虚拟滚动等。由于其数据量大,往往又对性能有很高的要求。
- 图表:图表的门槛相对比较高,并且种类繁多,对于显示、交互的要求也高。
- 富文本编辑器:几乎是最复杂的组件,其功能需求往往与 Word 进行对比,其代码量可能接近 Word 的数量级。
4.2.3 业务组件
业务组件是我们在实现业务功能的过程中抽象出来的组件,其作用是在应用中复用业务逻辑。当它们涉及一些更复杂的业务情形时,就要考虑是否将这些组件放入组件库中。
- 通常是根据最小业务状态抽象而出,有些业务组件也具有一定的复用性,但大多数是一次性组件。
- 特点:UI可配置,业务逻辑完整。有完整的后台流程,数据结构。
5. 组件的设计原则
标准性:任何一个组件都应该遵守一套标准,可以使得不同区域的开发人员据此标准开发出一套标准统一的组件。单一职责原则:一个组件只专注做一件事,且把这件事做好。一个功能如果可以拆分成多个功能点,那就可以将每个功能点封装成一个组件,当然也不是组件的颗粒度越小越好,只要将一个组件内的功能逻辑控制在一个可控的范围内即可。开闭原则:对扩展开放,对修改关闭。属性配置等 API 对外开放,组件内部状态对外封闭。追求短小精悍避免太多参数扁平化参数:除了数据,避免复杂的对象,尽量只接收原始类型的值。合理的依赖关系:父组件不依赖子组件,删除某个子组件不会造成功能异常适用SPOT(Single Point of Truth)法则:尽量不要重复代码追求无副作用复用与易用避免暴露组件内部实现入口处检查参数的有效性,出口处检查返回的正确性稳定抽象原则(SAP)
- 组件的抽象程度与其稳定程度成正比
- 一个稳定的组件应该是抽象的(逻辑无关的)
- 一个不稳定的组件应该是具体的(逻辑相关的)
- 为降低组件之间的耦合度,我们要针对抽象组件编程,而不是针对业务实现编程
良好的接口设计,API 尽量和已知概念保持一致
模块化
1. 模块化理解
1.1 模块化简介
模块化,就是把一个个文件看成一个模块,它们之间作用域相互隔离,互不干扰。一个模块就是一个功能,它们可以被多次复用。另外,模块化的设计也体现了分治的思想。什么是分治?维基百科 (opens new window)的定义如下:
字面上的解释是“分而治之”,就是把一个复杂的问题分成两个或更多的相同或相似的子问题,直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并。
- 将一个复杂的程序依据一定的规则(规范)封装成几个块(文件), 并进行组合在一起
- 模块的内部数据与实现是私有的, 只是向外部暴露一些接口(方法)与外部其它模块通信
1.2 模块化进程
全局function模式:将不同的功能封装成不同的全局函数
- 编码: 将不同的功能封装成不同的全局函数
- 问题: 污染全局命名空间, 容易引起命名冲突或数据不安全,而且模块成员之间看不出直接关系
function m1(){//...
}
function m2(){//...
}
namespace模式:简单对象封装
- 作用: 减少了全局变量,解决命名冲突
- 问题: 数据不安全(外部可以直接修改模块内部的数据)
let myModule = {data: 'www.baidu.com',foo() {console.log(`foo() ${this.data}`)},bar() {console.log(`bar() ${this.data}`)}
}
myModule.data = 'other data' //能直接修改模块内部的数据
myModule.foo() // foo() other data
IIFE模式:匿名函数自调用(闭包)
- 作用: 数据是私有的, 外部只能通过暴露的方法操作
- 编码: 将数据和行为封装到一个函数内部, 通过给window添加属性来向外暴露接口
- 问题: 如果当前这个模块依赖另一个模块怎么办?
// index.html文件
<script type="text/javascript" src="module.js"></script>
<script type="text/javascript">myModule.foo()myModule.bar()console.log(myModule.data) //undefined 不能访问模块内部数据myModule.data = 'xxxx' //不是修改的模块内部的datamyModule.foo() //没有改变
</script>
// module.js文件
(function(window) {let data = 'www.baidu.com'//操作数据的函数function foo() {//用于暴露有函数console.log(`foo() ${data}`)}function bar() {//用于暴露有函数console.log(`bar() ${data}`)otherFun() //内部调用}function otherFun() {//内部私有的函数console.log('otherFun()')}//暴露行为window.myModule = { foo, bar } //ES6写法
})(window)
IIFE模式增强:引入依赖
// module.js文件
(function(window, $) {let data = 'www.baidu.com'//操作数据的函数function foo() {//用于暴露有函数console.log(`foo() ${data}`)$('body').css('background', 'red')}function bar() {//用于暴露有函数console.log(`bar() ${data}`)otherFun() //内部调用}function otherFun() {//内部私有的函数console.log('otherFun()')}//暴露行为window.myModule = { foo, bar }
})(window, jQuery)
// index.html文件<!-- 引入的js必须有一定顺序 --><script type="text/javascript" src="jquery-1.10.1.js"></script><script type="text/javascript" src="module.js"></script><script type="text/javascript">myModule.foo()</script>
- 通过jquery方法将页面的背景颜色改成红色,所以必须先引入jQuery库,就把这个库当作参数传入。这样做除了保证模块的独立性,还使得模块之间的依赖关系变得明显
1.3 模块化优点
- 避免命名冲突(减少命名空间污染)
- 更好的分离, 按需加载
- 更高复用性
- 高可维护性
1.4 引入多个 <script> 的问题
请求过多首先我们要依赖多个模块,那样就会发送多个请求,导致请求过多依赖模糊我们不知道他们的具体依赖关系是什么,也就是说很容易因为不了解他们之间的依赖关系导致加载先后顺序出错难以维护以上两种原因就导致了很难维护,很可能出现牵一发而动全身的情况导致项目出现严重的问题。 模块化固然有多个好处,然而一个页面需要引入多个js文件,就会出现以上这些问题。而这些问题可以通过模块化规范来解决
2. 服务端模块化
2.1 Nodejs和CommonJS的关系
- Nodejs的模块化能一种成熟的姿态出现离不开CommonJS的规范的影响
- 在服务器端CommonJS能以一种寻常的姿态写进各个公司的项目代码中,离不开Node的优异表现
- Node并非完全按照规范实现,针对模块规范进行了一定的取舍,同时也增加了少许自身特性
2.2 CommonJS规范简介
CommonJS对模块的定义非常简单,主要分为模块引用,模块定义和模块标识3部分
2.2.1 模块引用
var add = require('./add.js');
var config = require('config.js');
var http = require('http');
2.2.2 模块定义
module.exports.add = function () {...
}
module.exports = function () {return ...
}
可以在一个文件中引入模块并导出另一个模块
var add = require('./add.js');
module.exports.increment = function () {return add(val, 1);
}
2.2.3 模块标识
模块标识就是require( )函数的参数,规范是这样的:
- 必须是字符串
- 可以是以./ …/开头的相对路径
- 可以是绝对路径
- 可以省略后缀名
CommonJS的模块规范定义比较简单,意义在于将类聚的方法和变量等限定在私有的作用域中,同时支持引入和导出将上下游模块无缝衔接,每个模块具有独立的空间,它们互不干扰。
2.3 Nodejs的模块化实现
Node模块在实现中并非完全按照CommonJS来,进行了取舍,增加了一些自身的的特性。
Node中一个文件是一个模块——module
一个模块就是一个Module的实例
// Node中Module构造函数:
function Module(id, parent){this.id = id;this.exports = {};this.parent = parent;if(parent && parent.children) {parent.children.push(this);}this.filename = null;this.loaded = false;this.children = [];
}//实例化一个模块var module = new Module(filename, parent);
其中id 是模块id,exports是这个模块要暴露出来的api,parent是父级模块,loaded表示这个模块是否加载完成,因为CommonJS是运行时加载,loaded表示文件是否已经执行完毕返回一个对象。
2.4 Node模块分类
2.4.1 核心模块
就是Node内置的模块比如http, path等。在Node的源码的编译时,核心模块就一起被编译进了二进制执行文件,部分核心模块(内建模块)被直接加载进内存中。
在Node模块的引入过程中,一般要经过一下三个步骤
- 路径分析
- 文件定位
- 编译执行
核心模块会省略文件定位和编译执行这两步,并且在路径分析中会优先判断,加载速度比一般模块更快。
2.4.2 文件模块
就是外部引入的模块如node_modules里通过npm安装的模块,或者我们项目工程里自己写的一个js文件或者json文件。
文件模块引入过程以上三个步骤都要经历
2.5 那么NodeJS require的时候是怎么路径分析,文件定位并且编译执行的?
2.5.1 路径分析
前面已经说过,不论核心模块还是文件模块都需要经历路径分析这一步,当我们require一个模块的时候,Node是怎么区分是核心模块还是文件模块,并且进行查找定位呢?
Node支持如下几种形式的模块标识符,来引入模块:
//核心模块
require('http')----------------------------
//文件模块//以.开头的相对路径,(可以不带扩展名)
require('./a.js')//以..开头的相对路径,(可以不带扩展名)
require('../b.js')//以/开始的绝对路径,(可以不带扩展名)
require('/c.js')//外部模块名称
require('express')//外部模块某一个文件
require('codemirror/addon/merge/merge.js');
那么对于这个都是字符串的引入方式,
- Node 会优先去内存中查找匹配核心模块,如果匹配成功便不会再继续查找
(1)比如require http 模块的时候,会优先从核心模块里去成功匹配
- 如果核心模块没有匹配成功,便归类为文件模块
(2) 以.、…和/开头的标识符,require都会根据当前文件路径将这个相对路径或者绝对路径转化为真实路径,也就是我们平时最常见的一种路径解析
(3)非路径形式的文件模块 如上面的’express’ 和’codemirror/addon/merge/merge.js’,这种模块是一种特殊的文件模块,一般称为自定义模块。
自定义模块的查找最费时,因为对于自定义模块有一个模块路径,Node会根据这个模块路径依次递归查找。
模块路径——Node的模块路径是一个数组,模块路径存放在module.paths属性上。
我们可以找一个基于npm或者yarn管理项目,在根目录下创建一个test.js文件,内容为console.log(module.paths),如下:
//test.js
console.log(module.paths);
然后在根目录下用Node执行
node test.js
可以看到模块路径的生成规则如下:
- 当前路文件下的node_modules目录
- 父目录下的node_modules目录
- 父目录的父目录下的node_modules目录
- 沿路径向上逐级递归,直到根目录下的node_modules目录
对于自定义文件比如express,就会根据模块路径依次递归查找。
在查找同时并进行文件定位。
2.5.2 文件定位
- 扩展名分析
我们在使用require的时候有时候会省略扩展名,那么Node怎么定位到具体的文件呢?
这种情况下,Node会依次按照.js、.json、.node的次序一次匹配。(.node是C++扩展文件编译之后生成的文件)
若扩展名匹配失败,则会将其当成一个包来处理,我这里直接理解为npm包
- 包处理
对于包Node会首先在当前包目录下查找package.json(CommonJS包规范)通过JSON.parse( )解析出包描述对象,根据main属性指定的入口文件名进行下一步定位。
如果文件缺少扩展名,将根据扩展名分析规则定位。
若main指定文件名错误或者压根没有package.json,Node会将包目录下的index当做默认文件名。
再依次匹配index.js、index.json、index.node。
若以上步骤都没有定位成功将,进入下一个模块路径——父目录下的node_modules目录下查找,直到查找到根目录下的node_modules,若都没有定位到,将抛出查找失败的异常。
2.5.3 模块编译
- .js文件——通过fs模块同步读取文件后编译执行
- .node文件——用C/C++编写的扩展文件,通过dlopen( )方法加载最后编译生成的文件。
- .json——通过fs模块同步读取文件后,用JSON.parse( ) 解析返回结果。
- 其余扩展名文件。它们都是被当做.js文件载入。
每一个编译成功的文件都会将其文件路径作为索引缓存在Module._cache对象上,以提高二次引入的性能。
这里我们只讲解一下JavaScript模块的编译过程,以解答前面所说的CommonJS模块中的require、exports、module变量的来源。
我们还知道Node的每个模块中都有___filename、_dirname 这两个变量,是怎么来的的呢?
其实JavaScript模块在编译过程中,Node对获取的JavaScript文件内容进行了头部和尾部的包装。在头部添加了(function (exports, require, module,__filename, __dirname){\n,而在尾部添加了\n}); 。
因此一个JS模块经过编译之后会被包装成下面的样子:
(function(exports, require, module, __filename, __dirname){var express = require('express') ;exports.method = function (params){...};
});
2.6 CommonJS 详解
Node 应用由模块组成,采用 CommonJS 模块规范。每个文件就是一个模块,有自己的作用域。在一个文件里面定义的变量、函数、类,都是私有的,对其他文件不可见。在服务器端,模块的加载是运行时同步加载的;在浏览器端,模块需要提前编译打包处理。加载某个模块,实质上是加载module.exports属性。就是把另一个js文件的变量或者函数,作为一个对象,引入了当前js文件。在CommonJS的这种方式下,每次require时相当于深拷贝了一份导入模块的文件代码。也就是说,执行导入后的某些有副作用的函数,并不会改变原模块的变量值。同时,因为是同步加载模块,服务端的模块都在本地磁盘中,所以很适用于服务端。但是对于浏览器环境,异步方案显然更加适合
2.6.1 特点
- 所有代码都运行在模块作用域,不会污染全局作用域。
- 模块可以多次加载,但是只会在第一次加载时运行一次,然后运行结果就被缓存了,以后再加载,就直接读取缓存结果。要想让模块再次运行,必须清除缓存。
- 模块加载的顺序,按照其在代码中出现的顺序。
2.6.2 语法
- 暴露模块:
module.exports = value或exports.xxx = value - 引入模块:
require(xxx),如果是第三方模块,xxx为模块名;如果是自定义模块,xxx为模块文件路径
此处我们有个疑问:CommonJS暴露的模块到底是什么? CommonJS规范规定,每个模块内部,module变量代表当前模块。这个变量是一个对象,它的exports属性(即module.exports)是对外的接口。加载某个模块,其实是加载该模块的module.exports属性。通过require引入的文件,自动挂载到了当前文件的children属性中。挂载过后,被挂载的文件会随着引入文件执行。同时这个被挂载的文件代码可以理解为引入文件的私有代码,与被引入文件无瓜。此时我们可以通过module.children[0].exports拿到被导入文件的各种方法和变量
// example.js
var x = 5;
var addX = function (value) {return value + x;
};
module.exports.x = x;
module.exports.addX = addX;
上面代码通过module.exports输出变量x和函数addX。
var example = require('./example.js');//如果参数字符串以“./”开头,则表示加载的是一个位于相对路径
console.log(example.x); // 5
console.log(example.addX(1)); // 6
require命令用于加载模块文件。require命令的基本功能是,读入并执行一个JavaScript文件,然后返回该模块的exports对象。如果没有发现指定模块,会报错。
3. 客户端模块化
3.1 客户端模块化和服务端模块化有什么区别?
服务端加载一个模块,直接就从硬盘或者内存中读取了,消耗时间可以忽略不计
浏览器需要从服务端下载这个文件,所以说如果用 CommonJS 的 require 方式加载模块,需要等代码模块下载完毕,并运行之后才能得到所需要的API。
3.2 为什么 CommonJS 不适用于前端模块?
如果我们在某个代码模块里使用CommonJS的方法require了一个模块,而这个模块需要通过http请求从服务器去取,如果网速很慢,而CommonJS又是同步的,所以将阻塞后面代码的执行,从而阻塞浏览器渲染页面,使得页面出现假死状态。
因此后面AMD规范随着RequireJS的推广被提出,异步模块加载,不阻塞后面代码执行的模块引入方式,就是解决了前端模块异步模块加载的问题。
3.3 AMD(Asynchronous Module Definition) & RequireJS
CommonJS规范加载模块是同步的,也就是说,只有加载完成,才能执行后面的操作。AMD规范则是非同步加载模块,允许指定回调函数。由于Node.js主要用于服务器编程,模块文件一般都已经存在于本地硬盘,所以加载起来比较快,不用考虑非同步加载的方式,所以CommonJS规范比较适用。但是,如果是浏览器环境,要从服务器端加载模块,这时就必须采用非同步模式,因此浏览器端一般采用AMD规范。此外AMD规范比CommonJS规范在浏览器端实现要来着早。
模块定义
- 独立模块的定义——不依赖其它模块的模块定义
//独立模块定义
define({method1: function() {}method2: function() {}
}); //或者
define(function(){return {method1: function() {},method2: function() {},}
});
- 非独立模块——依赖其他模块的模块定义
define(['math', 'graph'], function(math, graph){...
});
模块引用
require(['a', 'b'], function(a, b){a.method();b.method();
})
3.4 CMD(Common Module Definition) & SeaJS
CMD——通用模块规范,由国内的玉伯提出。SeaJS——CMD的实现,其实也可以说CMD是SeaJS在推广过程中对模块定义的规范化产出。与AMD规范的主要区别在于定义模块和依赖引入的部分。AMD需要在声明模块的时候指定所有的依赖,通过形参传递依赖到模块内容中:
define(['dep1', 'dep2'], function(dep1, dep2){return function(){};
})
与AMD模块规范相比,CMD模块更接近于Node对CommonJS规范的定义:
define(factory);
在依赖示例部分,CMD支持动态引入,require、exports和module通过形参传递给模块,在需要依赖模块时,随时调用require( )引入即可,示例如下:
define(function(require, exports, module){//依赖模块avar a = require('./a');//调用模块a的方法a.method();
})
也就是说与AMD相比,CMD推崇
依赖就近, AMD推崇依赖前置。
3.5 UMD(Universal Module Definition) 通用模块规范
如下是codemirror模块lib/codemirror.js模块的定义方式:
(function (global, factory) {typeof exports === 'object' && typeof module !== 'undefined' ? module.exports = factory() // Node , CommonJS: typeof define === 'function' && define.amd ? define(factory) //AMD CMD: (global.CodeMirror = factory()); //模块挂载到全局
}(this, (function () { ...
})
可以看说所谓的兼容模式是将几种常见模块定义方式都兼容处理。
3.6 什么是运行时加载?
我觉得要从两个点上去理解:
- CommonJS 和AMD模块都只能在运行时确定模块之间的依赖关系
- require一个模块的时候,模块会先被执行,并返回一个对象,并且这个对象是整体加载的
//CommonJS 模块
let { basename, dirname, parse } = require('path');//等价于
let _path = require('path');
let basename = _path.basename, dirname = _path.dirname, parse = _path.parse;
上面代码实质是整体加载path模块,即加载了path所有方法,生成一个对象,然后再从这个对象上面读取3个方法。这种加载就称为"运行时加载"。
3.7 ES6 module
如前面所述,CommonJS和AMD都是运行时加载。ES6在语言规格层面上实现了模块功能,是编译时加载,完全可以取代现有的CommonJS和AMD规范,可以成为浏览器和服务器通用的模块解决方案。这里关于ES6模块我们项目里使用非常多,所以详细讲解。
3.7.1 ES6模块使用——export
- 导出一个变量
export var name = 'pengpeng';
- 导出一个函数
export function foo(x, y){}
- 常用导出方式(推荐)
// person.js
const name = 'dingman';
const age = '18';
const addr = '卡尔斯特森林';export { firstName, lastName, year };
- As用法
const s = 1;
export {s as t,s as m,
}
可以利用as将模块输出多次。
3.7.2 ES6模块使用**——import**
- 一般用法
import { name, age } from './person.js';
- As用法
import { name as personName } from './person.js';
import命令具有提升效果,会提升到整个模块的头部,首先执行,如下也不会报错:
getName();import { getName } from 'person_module';
- 整体模块加载
*
//person.js
export name = 'xixi';
export age = 23;//逐一加载
import { age, name } from './person.js';//整体加载
import * as person from './person.js';
console.log(person.name);
console.log(person.age);
ES6模块使用——export default
其实export default,在项目里用的非常多,一般一个Vue组件或者React组件我们都是使用export default命令,需要注意的是使用export default命令时,import是不需要加{}的。而不使用export default时,import是必须加{},示例如下:
//person.js
export function getName() {...
}
//my_module
import {getName} from './person.js';-----------------对比---------------------//person.js
export default function getName(){...
}
//my_module
import getName from './person.js';
export default其实是导出一个叫做default的变量,所以其后面不能跟变量声明语句。
//错误
export default var a = 1;
值得注意的是我们可以同时使用 export 和 export default
//person.js
export name = 'dingman';
export default function getName(){...
}//my_module
import getName, { name } from './person.js';
前面一直提到,CommonJS是运行时加载,ES6是编译时加载,那么两个有什么本质的区别呢?
3.8 ES6 module 与 CommonJS模块加载区别
ES6模块的设计思想,是尽量的静态化,使得编译时就能确定模块的依赖关系,以及输入和输出的变量。所以说ES6是编译时加载,不同于CommonJS的运行时加载(实际加载的是一整个对象),ES6模块不是对象,而是通过export命令显式指定输出的代码,输入时也采用静态命令的形式:
//ES6模块
import { basename, dirname, parse } from 'path';//CommonJS模块
let { basename, dirname, parse } = require('path');
以上这种写法与CommonJS的模块加载有什么不同?
- 当require path模块时,其实 CommonJS会将path模块运行一遍,并返回一个对象,并将这个对象缓存起来,这个对象包含path这个模块的所有API。以后无论多少次加载这个模块都是取这个缓存的值,也就是第一次运行的结果,除非手动清除。
- ES6会从path模块只加载3个方法,其他不会加载,这就是编译时加载。ES6可以在编译时就完成模块加载,当ES6遇到import时,不会像CommonJS一样去执行模块,而是生成一个动态的只读引用,当真正需要的时候再到模块里去取值,所以ES6模块是动态引用,并且不会缓存值。
因为CommonJS模块输出的是值的拷贝,所以当模块内值变化时,不会影响到输出的值。基于Node做以下尝试:
//person.js
var age = 18;
module.exports ={age: age,addAge: function () {age++;}
} //my_module
var person = require('./person.js');
console.log(person.age);
person.addAge();
console.log(person.age);//输出结果
18
18
可以看到内部age的变化并不会影响person.age的值,这是因为person.age的值始终是第一次运行时的结果的拷贝。
再看ES6
//person.js
export let age = 18;
export function addAge(){age++;
}//my_module
import { age, addAge } from './person.js';
console.log(age);
addAge();
console.log(age);//输出结果
18
19
可以看到值被修改了,进一步证明了 ES6 的模块化只是对模块文件的引用
3.9 总结
- CommonJS规范主要用于服务端编程,加载模块是同步的,这并不适合在浏览器环境,因为同步意味着阻塞加载,浏览器资源是异步加载的,因此有了AMD CMD解决方案。
- AMD规范在浏览器环境中异步加载模块,而且可以并行加载多个模块。不过,AMD规范开发成本高,代码的阅读和书写比较困难,模块定义方式的语义不顺畅。
- CMD规范与AMD规范很相似,都用于浏览器编程,依赖就近,延迟执行,可以很容易在Node.js中运行。不过,依赖SPM 打包,模块的加载逻辑偏重
- ES6 在语言标准的层面上,实现了模块功能,而且实现得相当简单,完全可以取代 CommonJS 和 AMD 规范,成为浏览器和服务器通用的模块解决方案。
规范化
规范化的最根本目的就是为了保证团队成员的一致性,从而减少沟通成本,提高开发效率。我以前就经历过因为规范不标准,造成产品与开发理解有偏差、开发各写各的代码,导致各种 BUG 不断,最后项目延期的事。所以说为了提高开发效率,减少加班,请一定要统一规范
自动化
前端自动化是指前端代码的自动化构建、打包、测试及部署等流程。
持续集成(Continuous Integration)CI
持续部署(Continuous Deployment)CD
前端自动化通常与CI/CD流程相结合。
自动化的意义
- 减少人为失误,提高软件质量
- 效率迭代,便捷部署
- 快速交付,便于管理
自动化的实施
- 通过构建工具快速完成构建、打包
- 采取自动化测试
- 采取自动化部署
前端监控
性能优化
重构
相关文章:

12 前端工程化
组件化 1. 组件化理解 就是将页面的某一部分独立出来,将这一部分的数据层(M)、视图层(V)和控制层(C)用黑盒的形式全部封装到一个组件内,暴露出一些开箱即用的函数和属性供外部调用。…...

跨文档消息传递:WebKit中的Web通信新纪元
跨文档消息传递:WebKit中的Web通信新纪元 在现代Web应用中,跨文档消息传递(Cross-document messaging)是一种允许不同源的文档进行通信的机制。这种机制对于构建复杂的Web应用,如嵌入式框架(iframes&#…...

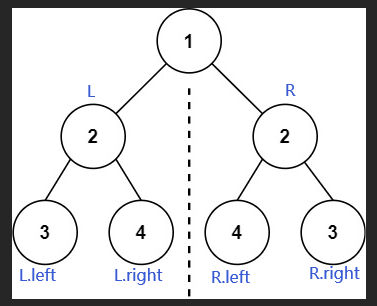
面试题 33. 二叉搜索树的后序遍历序列
二叉搜索树的后序遍历序列 题目描述示例 题解递归单调栈 题目描述 输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历结果。如果是则返回 true,否则返回 false。假设输入的数组的任意两个数字都互不相同。 示例 参考以下这颗二叉搜索树&#…...

Web响应式设计———1、Grid布局
1、网格布局 Grid布局 流动网格布局是响应式设计的基础。它通过使用百分比而不是固定像素来定义网格和元素的宽度。这样,页面上的元素可以根据屏幕宽度自动调整大小,适应不同设备和分辨率。 <!DOCTYPE html> <html lang"en"> &l…...

ESP32开发进阶: 训练神经网络
一、网络设定 我们设定一个简单的前馈神经网络,其结构如下: 输入层:节点数:2,接收输入数据,每个输入样本包含2个特征,例如 {1.0, 0.0}, {0.0, 1.0} 等。 隐藏层:节点数:…...

全国区块链职业技能大赛国赛考题前端功能开发
任务3-1:区块链应用前端功能开发 1.请基于前端系统的开发模板,在登录组件login.js、组件管理文件components.js中添加对应的逻辑代码,实现对前端的角色选择功能,并测试功能完整性,示例页面如下: 具体要求如下: (1)有明确的提示,提示用户选择角色; (2)用户可看…...

直接插入排序算法详解
直接插入排序(Straight Insertion Sort)是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,通常采用in-place排…...

sql手动自增id
有时候在运维处理数据的时候,需要给某张表插入新的记录,那么需要知道最新插入数据的id,并在最新id的基础上加上id增长步长获取新的id,这个过程往往需要现将max出来加1,再手动补充到sql语句中,很麻烦,而且数据多的时候容易出错。有…...

10_TypeScript中的泛型
TypeScript中的泛型) 一、泛型的定义二、泛型函数三、泛型类:比如有个最小堆算法,需要同时支持返回数字和字符串两种类型。通过类的泛型来实现四、泛型接口五、泛型类 --扩展 把类作为参数类型的泛型类1、实现:定义一个 User 的类…...

Unity3D之TextMeshPro使用
文章目录 1. TextMeshPro简介2. TextMeshPro创建3. TextMeshPro脚本中调用4. TextMeshPro字体设置及中文支持过程中出现的一些问题 1. TextMeshPro简介 【官网文档】https://docs.unity.cn/cn/2020.3/Manual/com.unity.textmeshpro.html TextMeshPro 是 Unity 的最终文本解决…...

K8S 上部署 Prometheus + Grafana
文章目录 一、使用 Helm 安装 Prometheus1. 配置源2. 下载 prometheus 包3. 安装 prometheus4. 卸载 二、使用 Helm 安装 Grafana1. 配置源2. 安装 grafana3. 访问4. 卸载 一、使用 Helm 安装 Prometheus 1. 配置源 地址:https://artifacthub.io/packages/helm/pro…...

雷军的逆天改命与顺势而为
雷军年度演讲前,朋友李翔提了一个问题:雷军造车是属于顺势而为还是逆势而为?评论互动区有一个总结,很有意思,叫“顺势逆袭”。 大致意思是产业趋势下小米从手机到IOT再切入汽车,是战略的必然,不…...

Leetcode 11. 盛最多水的容器
Leetcode 11. 盛最多水的容器 Leetcode 11. 盛最多水的容器 一、题目描述二、我的想法 一、题目描述 给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。 找出其中的两条线,使得它们与 x 轴共同构成…...

Java笔试分享
1、设计模式(写>3种常用的设计模式) 设计模式是在软件工程中解决常见问题的经验性解决方案。以下是一些常用的设计模式: 单例模式(Singleton): 意图:确保一个类只有一个实例,并…...
LeetCode:对称的二叉树(C语言)
1、问题概述:给一个二叉树,看是否按轴对称 2、示例 示例 1: 输入:root [1,2,2,3,4,4,3] 输出:true 示例 2: 输入:root [1,2,2,null,3,null,3] 输出:false 3、分析 (1&a…...

Postman中的API Schema验证:确保响应精准无误
Postman中的API Schema验证:确保响应精准无误 在API开发和测试过程中,验证响应数据的准确性和一致性是至关重要的。Postman提供了一个强大的功能——API Schema验证,它允许开发者根据预定义的JSON Schema来检查API响应。本文将详细介绍如何在…...

深入浅出WebRTC—GCC
GoogCcNetworkController 是 GCC 的控制中心,它由 RtpTransportControllerSend 通过定时器和 TransportFeedback 来驱动。GoogCcNetworkController 不断更新内部各个组件的状态,并协调组件之间相互配合,向外输出目标码率等重要参数࿰…...

leetcode日记(49)旋转链表
其实不难,就是根据kk%len判断需要旋转的位置,再将后半段接在前半段前面就行。 /*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : …...

InteliJ IDEA最新2024版下载安装与快速配置激活使用教程+jdk下载配置
第一步:下载ideaIC-2024.1.4 方法1:在线链接 IntelliJ IDEA – the Leading Java and Kotlin IDE (jetbrains.com) 选择社区版进行下载 方法2:百度网盘 链接:https://pan.baidu.com/s/1ydS6krUX6eE_AdW4uGV_6w?pwdsbfm 提取…...

【23】Android高级知识之Window(四) - ThreadedRenderer
一、概述 在上一篇文章中已经讲了setView整个流程中,最开始的addToDisplay和WMS跨进程通信的整个过程做了什么。继文章Android基础知识之Window(二),这算是另外一个分支了,接着讲分析在performTraversals的三个操作中,最后触发pe…...

Unity安卓构建72小时实战指南:从零到真机运行
1. 这不是“又一本Unity教程”,而是我带三个新人从零上线第一款安卓游戏的真实路径你点开这个标题,大概率正站在两个路口之间:一边是满屏“30天速成Unity”“零基础做爆款”的短视频封面,一边是你刚下载完Unity Hub、卡在Android …...

亚马逊卖家公开信息数据提取:反爬攻防战与 Python 批量采集实战
摘要: 批量获取亚马逊(Amazon)第三方卖家的商业名称、信用代码和注册地址等信息,对于跨境 B2B 拓客和供应链分析具有重要意义。然而,亚马逊的 Cloudflare 盾和 Robot 验证码构成了极高的反爬门槛。本文将深度解析亚马逊…...

Yokogawa AAI835-H50/K4A00模拟输入/输出模块
Yokogawa AAI835-H50/K4A00 模拟输入/输出模块产品特点:通道配置:共8个通道,含4路模拟输入和4路模拟输出。信号类型:所有通道均支持4-20mA标准电流信号。HART通信:支持HART协议,可与智能现场设备双向数字通…...

适合地产人用的中介房源管理系统
在房产经纪行业,房源管理与客源管理是经纪人日常工作的核心,直接影响业务效率与成交转化。选择一套适配行业需求的中介房源管理系统,能帮助中介团队规范流程、降低运营成本、大幅提升业绩。今天我们以客观视角,详细解析全房源系统…...

为你的Hermes Agent自定义Provider,接入Taotoken多模型池
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为你的Hermes Agent自定义Provider,接入Taotoken多模型池 在构建复杂的AI应用时,开发者常常面临一个核心挑…...

如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析
如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析 【免费下载链接】Magpie-LuckyDraw 🏅A fancy lucky-draw tool supporting multiple platforms💻(Mac/Linux/Windows/Web/Docker) 项目地址: https…...

ZMJS,把 JavaScript 解释器放进 SAP ABAP 应用服务器之后,很多扩展思路会变得不一样
我今天看这个 oisee/zmjs 仓库时,最吸引人的不是它把 JavaScript 语法做进了 ABAP,而是它选择了一条非常 SAP 的路线,纯 ABAP、无外部依赖、无 Kernel Module、以类和接口的形式运行在 SAP 应用服务器内部。仓库自己的定位很直接,ZMJS 是一个面向 SAP ABAP 的 Mini JavaScr…...
)
【2025】AWVS安装保姆级教程(最新25.1.2可用)
【2025】AWVS安装保姆级教程(最新25.1.2可用) 文章目录 工具下载Host 重定向AWVS安装AWVS查看安装失败原因 工具下载 点击下载即可 下载完的工具后缀格式为.apk,需要将其改为.zip,然后将其解压得到以下工具后续安装使用 Host 重…...
)
紧急预警:DeepSeek代码生成中未公开的3类逻辑漂移现象(附自动化检测脚本+修复模板)
更多请点击: https://intelliparadigm.com 第一章:紧急预警:DeepSeek代码生成中未公开的3类逻辑漂移现象(附自动化检测脚本修复模板) 近期在多轮生产级代码审计中发现,DeepSeek-R1(v2.5&#x…...

告别Windows卡顿!在VMware里给Kubuntu 22.04 LTS分区和安装的保姆级避坑指南
告别Windows卡顿!在VMware里给Kubuntu 22.04 LTS分区和安装的保姆级避坑指南你是否已经厌倦了Windows系统越来越慢的启动速度、频繁的后台更新和资源占用?当你的电脑开始频繁卡顿,或许该考虑给系统来一次"减负"了。Kubuntu 22.04 L…...