Python 爬虫入门(一):从零开始学爬虫 「详细介绍」
Python 爬虫入门(一):从零开始学爬虫 「详细介绍」
- 前言
- 1.爬虫概念
- 1.1 什么是爬虫?
- 1.2 爬虫的工作原理
- 2. HTTP 简述
- 2.1 什么是 HTTP?
- 2.2 HTTP 请求
- 2.3 HTTP 响应
- 2.4 常见的 HTTP 方法
- 3. 网页的组成
- 3.1 HTML
- 3.2 CSS
- 3.3 JavaScript
- 4. 使用 Python 进行 Web 爬虫
- 4.1 常用的 Python 库
- 4.2 安装所需库
- 4.3 编写一个简单的爬虫
- 4.4 示例代码
- 5. 处理复杂的网页
- 5.1 使用 Playwright 示例
- 6. 编写一个完整的爬虫项目
- 6.1 项目要求
- 6.2 项目步骤
- 6.3 示例代码
- 7. robots.txt 文件是什么?
- 8. 注意事项
- 总结
前言
- 欢迎来到“Python 爬虫入门”系列的第一篇文章。你有没有想过,怎么能从网页上自动抓取你需要的数据?比如,一次性下载所有喜欢的图片,或者获取最新的新闻资讯。其实,这就是网络爬虫能做的事情。
- Python 是一门非常受欢迎的编程语言,简单易学,而且有很多强大的库可以用来编写网络爬虫。即使你是编程新手,也不用担心,这个系列会从最基础的知识讲起,带你一步步掌握写爬虫的技能。
- 在这篇文章里,我们会先聊聊什么是网络爬虫,它是怎么工作的,然后教你如何安装和配置开发环境、如何使用 Python 编写爬虫脚本。
1.爬虫概念
1.1 什么是爬虫?
网络爬虫,也称为网络蜘蛛、网络机器人,是一种自动化脚本或程序,用于自动浏览互联网并收集数据。
爬虫可以帮助我们从网页中提取信息,从而实现数据采集、信息检索、网站分析等功能。
1.2 爬虫的工作原理

- 发送请求:爬虫向目标网站发送 HTTP 请求。
- 获取响应:目标网站返回 HTTP 响应,包含请求的网页内容。
- 解析数据:爬虫解析网页内容,提取所需数据。
- 存储数据:将提取的数据存储在本地或数据库中。
2. HTTP 简述
2.1 什么是 HTTP?
HTTP(HyperText Transfer Protocol)是用于在 Web 浏览器和 Web服务器之间传递信息的协议。它是一种基于请求 - 响应模式的协议,客户端发送请求,服务器返回响应。

2.2 HTTP 请求
HTTP 请求由以下几个部分组成:
- 请求行:包括请求方法(如 GET、POST)、请求 URL 和 HTTP 版本。
- 请求头:包含有关客户端环境的信息和请求体的元数据。
- 请求体:在 POST 请求中,包含要发送到服务器的数据。
2.3 HTTP 响应
HTTP 响应由以下几个部分组成:
- 状态行:包括 HTTP 版本、状态码和状态描述。
- 响应头:包含有关服务器环境的信息和响应体的元数据。
- 响应体:包含实际的响应内容,如 HTML 文档、图像或其他数据。
2.4 常见的 HTTP 方法
- GET:请求指定的资源。一般用于请求数据。
- POST:向指定的资源提交数据进行处理。
- PUT:向指定资源位置上传最新内容。
- DELETE:请求删除指定的资源。
- HEAD:类似于 GET,但只返回响应头,不返回响应体。
3. 网页的组成
一个典型的网页由以下几个部分组成:

3.1 HTML
HTML(HyperText Markup Language)是用于创建和结构化网页内容的标准标记语言。HTML 使用标签来标记不同类型的内容,如文本、图像、链接等。
HTML 基础结构示例如下:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Document</title>
</head>
<body><h1>Hello, World!</h1><p>Welcome to my website.</p>
</body>
</html>
3.2 CSS
CSS(Cascading Style Sheets)是一种样式表语言,用于描述 HTML 文档的外观和格式。CSS 可以控制网页的布局、颜色、字体等。
CSS 示例如下:
body {font-family: Arial, sans-serif;
}h1 {color: blue;
}p {font-size: 16px;
}
3.3 JavaScript
JavaScript 是一种高效的编程语言,通常用于网页开发,可以使网页具有动态交互功能。JavaScript 可以操作 HTML 和 CSS,响应用户事件,创建动态效果等。
JavaScript 示例如下:
document.addEventListener('DOMContentLoaded', function() {const button = document.getElementById('myButton');button.addEventListener('click', function() {alert('Button clicked!');});
});
4. 使用 Python 进行 Web 爬虫
4.1 常用的 Python 库
- requests:用于发送 HTTP 请求。
- BeautifulSoup:用于解析 HTML 和 XML 文档。
- Scrapy:一个功能强大的爬虫框架。
- Playwright:用于模拟浏览器操作,支持多种浏览器。
4.2 安装所需库
使用 pip 安装下列库:
pip install requests
pip install beautifulsoup4
pip install scrapy
pip install openpyxl
pip install playwright
python -m playwright install
4.3 编写一个简单的爬虫
下面是一个使用 requests 编写的简单爬虫示例。
4.4 示例代码
import requests# 发送请求
url = 'https://www.zhihu.com/api/v3/feed/topstory/hot-lists/total'
response = requests.get(url)
# 解析JSON数据
data = response.json()if 'data' in data:# 遍历数据for item in data['data']:if 'target' in item and 'title' in item['target']:print(item['target']['title'])
else:print("没有获取到数据")
执行结果如下:

5. 处理复杂的网页
对于一些动态加载内容的网页,仅靠 requests 和 BeautifulSoup 可能无法获取所有数据。这时可以使用 Playwright 模拟浏览器操作。
5.1 使用 Playwright 示例
import asyncio
from bs4 import BeautifulSoup
from playwright.async_api import async_playwrightasync def run(playwright: async_playwright) -> None:browser = await playwright.chromium.launch(headless=False)context = await browser.new_context()page = await context.new_page()# 访问网页await page.goto('https://nba.hupu.com/')# 获取页面内容content = await page.content()# 解析 HTML(同样使用 BeautifulSoup)soup = BeautifulSoup(content, 'html.parser')# 提取页面标题title = soup.title.stringprint('Title:', title)# 提取推荐文章的标题及链接links = await page.locator('.list-recommend a, .list-container a').all()for link in links:title = await link.inner_text()href = await link.get_attribute('href')print(title, href)# 关闭浏览器和上下文await context.close()await browser.close()# 异步运行函数
async def main():async with async_playwright() as playwright:await run(playwright)# 运行主函数
asyncio.run(main())

6. 编写一个完整的爬虫项目
下面,我们将编写一个完整的爬虫项目,从一个网站中提取数据并保存到本地文件。
6.1 项目要求
- 从一个演出票务网站中提取演出信息;
- 将演出数据保存到 Excel 文件中。
6.2 项目步骤
- 发送请求并获取响应
- 解析响应内容
- 创建 Excel 工作簿、Sheet
- 将遍历数据保存到 Excel 文件
6.3 示例代码
下面是一个使用 requests 和 BeautifulSoup 编写的爬虫示例。
import requests
from bs4 import BeautifulSoup
from openpyxl import Workbook
from pathlib import Pathdef showStart(city_code):# 发送请求获取网页内容url = f'https://www.showstart.com/event/list?pageNo=1&pageSize=99999&cityCode={city_code}'response = requests.get(url)if response.status_code == 200:soup = BeautifulSoup(response.text, 'html.parser')items = soup.find_all('a', class_='show-item item')# 创建Excel工作簿wb = Workbook()sheet = wb.active# 添加标题行sheet.append(['标题', '艺人', '价格', '时间', '地址', '链接'])for item in items:title = item.find('div', class_='title').text.strip()artist = item.find('div', class_='artist').text.strip()price = item.find('div', class_='price').text.strip()time = item.find('div', class_='time').text.strip()addr = item.find('div', class_='addr').text.strip()href = 'https://www.showstart.com' + item['href']# 将数据写入Excelsheet.append([title, artist, price, time, addr, href])# 保存Excel文件root_dir = Path(__file__).resolve().parentfile_path = root_dir / f'showstart_{city_code}.xlsx'wb.save(file_path)print(f'数据已保存到 {file_path}')else:print(f'请求失败,状态码:{response.status_code}')if __name__ == "__main__":city_code = input("请输入城市编码:")showStart(city_code)
打开Excel 文件,内容如下:

7. robots.txt 文件是什么?
robots.txt 文件是一个文本文件,通常放置在网站的根目录下。
它用来告诉搜索引擎的爬虫(spider)哪些页面可以抓取,哪些页面不可以抓取。
要找到网站的 robots.txt 文件,在浏览器的地址栏输入以下格式的URL:
http://www.xxx.com/robots.txt
如果访问的是不带www的域名:
http://xxx.com/robots.txt
- 这里的 xxx.com 替换成想要查找 robots.txt 的网站域名。如果该网站有 robots.txt 文件,将能够直接在浏览器中看到它的内容。如果不存在,可能会看到404错误页面或者其他错误信息。
- 此外,有些网站可能会使用 robots.txt 文件来提供关于网站地图(sitemap)的信息,这可以帮助搜索引擎更快地发现和索引网站上的新内容。
8. 注意事项
- 尊重网站的 robots.txt 文件:大多数网站都有一个 robots.txt 文件,告知爬虫哪些页面可以抓取,哪些页面不可以。一定要遵守这些规则,避免抓取被禁止的内容。
- 避免过度抓取:频繁的请求可能会给目标网站的服务器带来负担,甚至导致服务器宕机。请合理设置抓取的频率,避免对服务器造成过大的压力;
- 尊重网站的使用条款:有些网站的使用条款中明确禁止未经授权的数据抓取。在抓取数据前,一定要仔细阅读并遵守网站的使用条款和隐私政策。
- 处理敏感数据:在抓取和处理数据时,要特别注意保护个人隐私和敏感信息。避免抓取和存储敏感数据,确保数据的合法性和安全性。
- 合法合规:在进行数据抓取时,要确保自己的行为合法合规。不同国家和地区对数据抓取的法律规定不同,务必了解并遵守相关法律法规。
- 正确识别身份:在请求头中使用合理的 User-Agent,明确表明自己的身份,避免被误认为恶意爬虫。
总结
希望你通过本文,对 Python 爬虫有了一个全面的了解。我们从 Python 爬虫的基本概念、HTTP 基础知识以及网页的基本组成部分讲起,逐步学习了如何使用 Python 编写简单的爬虫,以及如何处理动态加载内容的网页。最后,我们用一个完整的爬虫项目,把学到的知识都串联起来,实战演练了一遍。相信通过这次学习,你对爬虫的工作流程和技术细节都有了更深入的理解。
如果你有任何问题或者好的想法,欢迎随时和我交流。
相关文章:
Python 爬虫入门(一):从零开始学爬虫 「详细介绍」
Python 爬虫入门(一):从零开始学爬虫 「详细介绍」 前言1.爬虫概念1.1 什么是爬虫?1.2 爬虫的工作原理 2. HTTP 简述2.1 什么是 HTTP?2.2 HTTP 请求2.3 HTTP 响应2.4 常见的 HTTP 方法 3. 网页的组成3.1 HTML3.2 CSS3.…...

Linux嵌入式学习——数据结构——概念和Seqlist
数据结构 相互之间存在一种或多种特定关系的数据元素的集合。 逻辑结构 集合,所有数据在同一个集合中,关系平等。 线性,数据和数据之间是一对一的关系。数组就是线性表的一种。 树, 一对多 图,多对多 …...

iOS ------ Block的相关问题
Block的定义 Block可以截获局部变量的匿名函数, 是将函数及其执行上下文封装起来的对象。 Block的实现 通过Clang将以下的OC代码转化为C代码 // Clang xcrun -sdk iphoneos clang -arch arm64 -rewrite-objc main.m//main.m #import <Foundation/Foundation.…...

conda issue
Conda 是一个跨平台、通用的二进制包管理器。它是 Anaconda 安装使用的包管理器,但它也可能用于其他系统。Conda 完全用 Python 编写,并且是 BSD 许可的开源。通用意味着大部分的包都可以用它进行管理,很像一个跨平台版本的apt或者yum&#x…...

为了解决地图引入鉴权失败的解决方案
在以下文件中需要添加相应代码 app/controller/CollageProduct.php app/view/designer_page/designer_editor.html app/view/designer_page/designer.html app/controller/Freight.php app\controller\Business.php app\controller\DesignerPage.php 只有这样才能保证htt…...

[ptrade交易实战] 第十八篇 期货查询类函数和期货设置类函数
前言 今天主要和大家分享的是期货查询类的函数和期货设置类的函数! 具体的开通渠道可以看文章末尾! 一、get_margin_rate—— 获取用户设置的保证金比例 保证金是期货交易中的一个重点,这个函数就是用来获取我们设置的保证金比例的&#…...

STM32智能家居控制系统教程
目录 引言环境准备智能家居控制系统基础代码实现:实现智能家居控制系统 4.1 数据采集模块 4.2 数据处理与分析模块 4.3 通信与网络系统实现 4.4 用户界面与数据可视化应用场景:家居监测与优化问题解决方案与优化收尾与总结 1. 引言 智能家居控制系统通…...

FPGA 中的 IOE与IO BANK
IO bank(输入/输出bank) 定义:IO bank 是 FPGA 中一组 IOE 的集合,通常共享相同的电源电压、时钟域和时序管理。每个 IO bank 包含多个 IOE,它们可以根据需要分配给不同的信号处理任务。作用:IO bank 的存…...

ADetailer模型+Stable Diffusion的inpainting功能是如何对遮罩区域进行修复生成的ADetailer
模型选则: face_yolov8n.pt 和 face_yolov8s.pt: 用途:用于人脸检测。特点:YOLOv8n 是轻量级版本,适合资源有限的设备;YOLOv8s 是标准版本,检测精度更高。 hand_yolov8n.pt: 用途&am…...

【博士每天一篇文献-综述】2024机器遗忘最新综述之一:An overview of machine unlearning
1 介绍 年份:2024 作者: 期刊: High-Confidence Computing(2区) 引用量:0 Li C, Jiang H, Chen J, et al. An overview of machine unlearning[J]. High-Confidence Computing, 2024: 100254 本文详细提供…...

【机器学习】Jupyter Notebook如何使用之基本步骤和进阶操作
引言 Jupyter Notebook 是一个交互式计算环境,它允许创建包含代码、文本和可视化内容的文档 文章目录 引言一、基本步骤1.1 启动 Jupyter Notebook1.2 使用 Jupyter Notebook 仪表板1.3 在笔记本中工作1.4 常用快捷键1.5 导出和分享笔记本 二、进阶用法2.1 组织笔…...

C++ | Leetcode C++题解之第279题完全平方数
题目: 题解: class Solution { public:// 判断是否为完全平方数bool isPerfectSquare(int x) {int y sqrt(x);return y * y x;}// 判断是否能表示为 4^k*(8m7)bool checkAnswer4(int x) {while (x % 4 0) {x / 4;}return x % 8 7;}int numSquares(i…...
` 详解)
Vue 3 响应式高阶用法之 `shallowRef()` 详解
Vue 3 响应式高阶用法之 shallowRef() 详解 文章目录 Vue 3 响应式高阶用法之 shallowRef() 详解简介一、使用场景1.1 深层嵌套对象的性能优化1.2 需要部分响应式的场景 二、基本使用2.1 引入 shallowRef2.2 定义 shallowRef 三、功能详解3.1 浅层响应式3.2 与 ref 的对比 四、…...

流量录制与回放:jvm-sandbox-repeater工具详解
在软件开发和测试过程中,流量录制与回放是一个非常重要的环节,它可以帮助开发者验证系统在特定条件下的行为是否符合预期。本文将详细介绍一款强大的流量录制回放工具——jvm-sandbox-repeater,以及如何利用它来提高软件测试的效率和质量。 …...

内网渗透—内网穿透工具NgrokFRPNPSSPP
前言 主要介绍一下常见的隧道搭建工具,以此来达到一个内网穿透的目的。简单说一下实验滴环境吧,kali作为攻击机,winserver2016作为目标靶机。 kali 192.168.145.171 winserver2016 10.236.44.127 显然它们处于两个不同的局域网,…...

嵌入式中传感器数据处理方法
大家好,在传感器使用中,我们常常需要对传感器数据进行各种整理,让应用获得更好的效果,以下介绍几种常用的简单处理方法: 加权平滑:平滑和均衡传感器数据,减小偶然数据突变的影响。 抽取突变:去除静态和缓慢变化的数据背景,强调瞬间变化。 简单移动平均线:保留数据流最…...

生成式 AI 的发展方向,是 Chat 还是 Agent?
据《福布斯》报道,商业的未来是自动化。他们报告说,自动化的应用是不可避免的,“工人们即将被一个圈子和一套规则包围,要严格遵守,不能偏离。得益于聊天机器人ChatGPT于2022年11月推出所带来的强劲加持,202…...
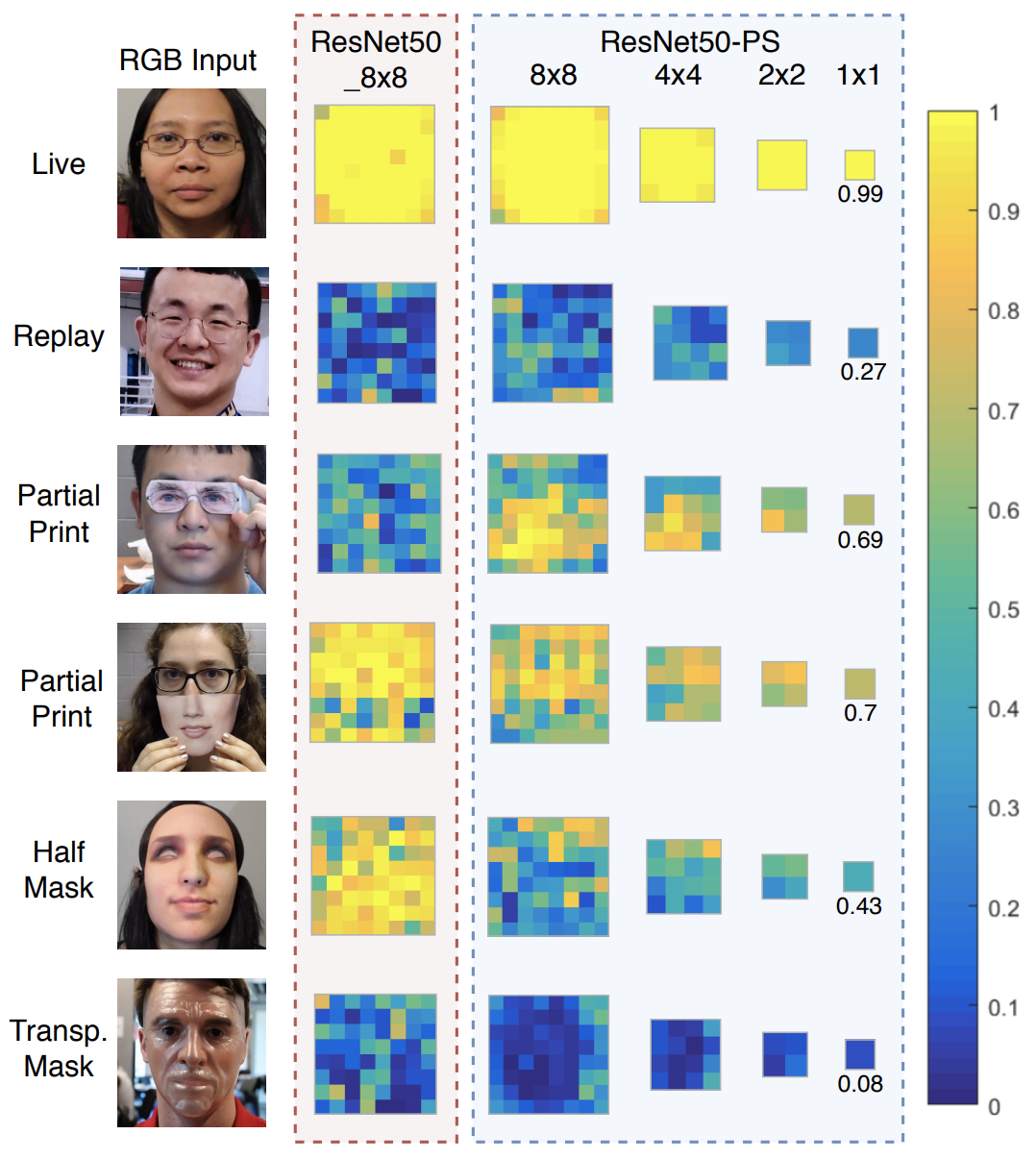
金字塔监督在人脸反欺骗中的应用
介绍 论文地址:https://arxiv.org/pdf/2011.12032.pdf 近年来,人脸识别技术越来越普及。在智能手机解锁和进出机场时,理所当然地会用到它。人脸识别也有望被用于管理今年奥运会的相关人员。但与此同时,人们对人脸欺骗的关注度也…...

vue3——两种利用自定义指令实现防止按钮重复点击的方法
方法一:利用定时器设置时间,下方代码设置时间为1秒 但是有个缺点:请求如果很慢,1秒钟还没有好,那么该方法就没用了 // 利用定时器:1秒之后才能再次点击app.directive(preventReClick, {mounted: (el, bind…...

Chrome谷歌浏览器Console(控制台)显示文件名及行数
有没有这样的困扰?Chrome谷歌浏览器console(控制台)不显示编译文件名及行数? 设置(Settings)- > 忽略列表(lgnore List)-> 自定义排除规则(Custom exclusion rules) 将自定义排除规则…...

PCB设计规范-机插定位孔设计要求
核心要求1) 机插定位孔的孔径为4mm,只能是机械孔,孔内不能沉铜。2) 第一个机插定位孔位于PCB板长边的左下角,机插定位孔的中心与两板的距离都等于5mm。3) 第二机插定位孔仅位于PCB板长边的右下角,距离长边的板边5mm,离…...

AEB系统有哪些应用场景?AEB系统有哪些感知方案
一旦检测到可能发生碰撞的情况,AEB系统会立即启动,自动触发车辆的制动系统,这便是AEB系统的作用。为增进大家对AEB系统的认识,本文将对AEB系统具体应用场景及相关信息予以介绍。如果你对AEB系统具有兴趣,不妨继续往下阅…...

光波导技术在高速PCB设计中的关键应用与挑战
1. 光波导技术在现代PCB设计中的核心价值2008年那个看似平常的十二月,当Mentor Graphics发布那份关于印刷电路板光波导技术的白皮书时,恐怕很少有人能预见这项技术会在今天成为5G基站和数据中心的核心支撑。作为在高速PCB设计领域摸爬滚打十五年的老工程…...

Qubes OS自动化管理工具qubes-claw:声明式配置与安全隔离实践
1. 项目概述与核心价值最近在折腾一个挺有意思的项目,叫“qubes-claw”。这名字听起来有点神秘,对吧?我第一次看到的时候,也琢磨了半天。简单来说,这是一个专门为Qubes OS设计的自动化工具集。如果你对Qubes OS不熟悉&…...
交易活跃度升温)
粮食安全政策托底,农业ETF(562900.SH)交易活跃度升温
5月14日,A股农业板块迎来温和上行,易方达农业ETF(562900.SH)收报0.756元,涨幅0.93%,跑赢跟踪标的中证现代农业指数0.85%的涨幅。数据显示,该ETF当日量比为1.13,换手率达9.54%&#x…...

yargs配置加密:敏感信息处理与解密中间件终极指南
yargs配置加密:敏感信息处理与解密中间件终极指南 【免费下载链接】yargs yargs the modern, pirate-themed successor to optimist. 项目地址: https://gitcode.com/gh_mirrors/ya/yargs yargs作为现代命令行参数解析工具,在处理配置文件时经常…...

Djot表格制作教程:简单创建专业级数据展示
Djot表格制作教程:简单创建专业级数据展示 【免费下载链接】djot A light markup language 项目地址: https://gitcode.com/gh_mirrors/dj/djot 想要在文档中快速创建美观的表格吗?Djot表格功能让数据展示变得简单高效!Djot作为一款轻…...

GitClaw:基于GitHub Actions的AI智能体框架,实现自动化代码审查与仓库管理
1. 项目概述:当GitHub遇上AI智能体最近在开源社区里,一个名为gitclaw的项目引起了我的注意。它来自open-gitagent组织,名字本身就很有意思——“Git Claw”,直译是“Git爪子”,听起来就像是要给GitHub这个代码仓库平台…...

AI连接器SDK:统一接口简化多模型集成与开发
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想把大语言模型的能力无缝集成到自己的业务系统里,相信很多开发者都遇到过类似的场景:想调用某个模型API,但发现不同厂商的接口规范、认证方式、返回格式千差万别;想…...

标注数据集保姆级教程:从入门到排名第一,看这一篇就够了
一、常见坑与避雷第一,过度依赖众包导致标签质量参差不齐。企业往往以价格为先,忽视了众包工人对领域术语的理解深度,从而造成模型召回率下降7%。第二,缺乏统一标注工具链。使用Excel、Word等异构工具会让数据格式碎片化ÿ…...