昇思25天学习打卡营第11天|xiaoyushao
今天分享ResNet50迁移学习。
在实际应用场景中,由于训练数据集不足,所以很少有人会从头开始训练整个网络。普遍的做法是,在一个非常大的基础数据集上训练得到一个预训练模型,然后使用该模型来初始化网络的权重参数或作为固定特征提取器应用于特定的任务中。本章将使用迁移学习的方法对ImageNet数据集中的狼和狗图像进行分类。
目录
一、 数据准备
1. 下载数据集
2. 数据集的目录结构
二、 加载数据集
1. 定义执行过程中的全局变量
2. 加载数据
3. 数据集可视化
三、训练模型
1. 构建ResNet50网络
2. 固定特征进行训练
3. 训练和评估
4. 可视化模型预测
一、 数据准备
1. 下载数据集
下载案例所用到的狗与狼分类数据集,数据集中的图像来自于ImageNet,每个分类有大约120张训练图像与30张验证图像。使用download接口下载数据集,并将下载后的数据集自动解压到当前目录下。
from download import downloaddataset_url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/intermediate/Canidae_data.zip"download(dataset_url, "./datasets-Canidae", kind="zip", replace=True)运行结果:
Creating data folder... Downloading data from https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/intermediate/Canidae_data.zip (11.3 MB)file_sizes: 100%|███████████████████████████| 11.9M/11.9M [00:00<00:00, 116MB/s] Extracting zip file... Successfully downloaded / unzipped to ./datasets-Canidae
'./datasets-Canidae'
2. 数据集的目录结构

二、 加载数据集
狼狗数据集提取自ImageNet分类数据集,使用mindspore.dataset.ImageFolderDataset接口来加载数据集,并进行相关图像增强操作。
1. 定义执行过程中的全局变量
# 为执行过程定义一些输入
batch_size = 18 # 批量大小
image_size = 224 # 训练图像空间大小
num_epochs = 5 # 训练周期数
lr = 0.001 # 学习率
momentum = 0.9 # 动量
workers = 4 # 并行线程个数2. 加载数据
import mindspore as ms
import mindspore.dataset as ds
import mindspore.dataset.vision as vision# 数据集目录路径
data_path_train = "./datasets-Canidae/data/Canidae/train/"
data_path_val = "./datasets-Canidae/data/Canidae/val/"# 创建训练数据集
def create_dataset_canidae(dataset_path, usage):"""数据加载"""data_set = ds.ImageFolderDataset(dataset_path,num_parallel_workers=workers,shuffle=True,)# 数据增强操作mean = [0.485 * 255, 0.456 * 255, 0.406 * 255]std = [0.229 * 255, 0.224 * 255, 0.225 * 255]scale = 32if usage == "train":# Define map operations for training datasettrans = [vision.RandomCropDecodeResize(size=image_size, scale=(0.08, 1.0), ratio=(0.75, 1.333)),vision.RandomHorizontalFlip(prob=0.5),vision.Normalize(mean=mean, std=std),vision.HWC2CHW()]else:# Define map operations for inference datasettrans = [vision.Decode(),vision.Resize(image_size + scale),vision.CenterCrop(image_size),vision.Normalize(mean=mean, std=std),vision.HWC2CHW()]# 数据映射操作data_set = data_set.map(operations=trans,input_columns='image',num_parallel_workers=workers)# 批量操作data_set = data_set.batch(batch_size)return data_setdataset_train = create_dataset_canidae(data_path_train, "train")
step_size_train = dataset_train.get_dataset_size()dataset_val = create_dataset_canidae(data_path_val, "val")
step_size_val = dataset_val.get_dataset_size()3. 数据集可视化
从mindspore.dataset.ImageFolderDataset接口中加载的训练数据集返回值为字典,用户可通过 create_dict_iterator 接口创建数据迭代器,使用 next 迭代访问数据集。本章中 batch_size 设为18,所以使用 next 一次可获取18个图像及标签数据。
data = next(dataset_train.create_dict_iterator())
images = data["image"]
labels = data["label"]print("Tensor of image", images.shape)
print("Labels:", labels)运行结果:
Tensor of image (18, 3, 224, 224) Labels: [0 1 0 0 1 1 0 0 0 1 0 1 1 1 1 1 0 0]
对获取到的图像及标签数据进行可视化,标题为图像对应的label名称。
import matplotlib.pyplot as plt
import numpy as np# class_name对应label,按文件夹字符串从小到大的顺序标记label
class_name = {0: "dogs", 1: "wolves"}plt.figure(figsize=(5, 5))
for i in range(4):# 获取图像及其对应的labeldata_image = images[i].asnumpy()data_label = labels[i]# 处理图像供展示使用data_image = np.transpose(data_image, (1, 2, 0))mean = np.array([0.485, 0.456, 0.406])std = np.array([0.229, 0.224, 0.225])data_image = std * data_image + meandata_image = np.clip(data_image, 0, 1)# 显示图像plt.subplot(2, 2, i+1)plt.imshow(data_image)plt.title(class_name[int(labels[i].asnumpy())])plt.axis("off")plt.show()运行结果:

三、训练模型
本章使用ResNet50模型进行训练。搭建好模型框架后,通过将pretrained参数设置为True来下载ResNet50的预训练模型并将权重参数加载到网络中。
1. 构建ResNet50网络
"""定义ResidualBlockBase 类,这个类实现了一个基本的残差块(Residual Block)结构,它是卷积神经网络(CNN)中常用的一种构建块,特别是在构建非常深的网络(如ResNet)时,残差块的主要目的是通过引入“短路连接”(或称为“恒等映射”、“跳跃连接”)来解决深度网络训练过程中的梯度消失或梯度爆炸问题,使得网络能够更容易地学习和优化。
"""
class ResidualBlockBase(nn.Cell):expansion: int = 1 # 最后一个卷积核数量与第一个卷积核数量相等def __init__(self, in_channel: int, out_channel: int,stride: int = 1, norm: Optional[nn.Cell] = None,down_sample: Optional[nn.Cell] = None) -> None:super(ResidualBlockBase, self).__init__()if not norm:self.norm = nn.BatchNorm2d(out_channel)else:self.norm = normself.conv1 = nn.Conv2d(in_channel, out_channel,kernel_size=3, stride=stride,weight_init=weight_init)self.conv2 = nn.Conv2d(in_channel, out_channel,kernel_size=3, weight_init=weight_init)self.relu = nn.ReLU()self.down_sample = down_sampledef construct(self, x):"""ResidualBlockBase construct."""identity = x # shortcuts分支out = self.conv1(x) # 主分支第一层:3*3卷积层out = self.norm(out)out = self.relu(out)out = self.conv2(out) # 主分支第二层:3*3卷积层out = self.norm(out)if self.down_sample is not None:identity = self.down_sample(x)out += identity # 输出为主分支与shortcuts之和out = self.relu(out)return out"""定义 ResidualBlock 类,它是用于构建深度神经网络中的一个残差块(Residual Block)。残差块是深度残差网络(ResNet)的核心组成部分,旨在解决深度神经网络在训练过程中出现的梯度消失或梯度爆炸问题,从而允许训练更深的网络。
"""
class ResidualBlock(nn.Cell):expansion = 4 # 最后一个卷积核的数量是第一个卷积核数量的4倍def __init__(self, in_channel: int, out_channel: int,stride: int = 1, down_sample: Optional[nn.Cell] = None) -> None:super(ResidualBlock, self).__init__()self.conv1 = nn.Conv2d(in_channel, out_channel,kernel_size=1, weight_init=weight_init)self.norm1 = nn.BatchNorm2d(out_channel)self.conv2 = nn.Conv2d(out_channel, out_channel,kernel_size=3, stride=stride,weight_init=weight_init)self.norm2 = nn.BatchNorm2d(out_channel)self.conv3 = nn.Conv2d(out_channel, out_channel * self.expansion,kernel_size=1, weight_init=weight_init)self.norm3 = nn.BatchNorm2d(out_channel * self.expansion)self.relu = nn.ReLU()self.down_sample = down_sampledef construct(self, x):identity = x # shortscuts分支out = self.conv1(x) # 主分支第一层:1*1卷积层out = self.norm1(out)out = self.relu(out)out = self.conv2(out) # 主分支第二层:3*3卷积层out = self.norm2(out)out = self.relu(out)out = self.conv3(out) # 主分支第三层:1*1卷积层out = self.norm3(out)if self.down_sample is not None:identity = self.down_sample(x)# 将主分支的输出与shortcuts分支相加,实现残差连接 out += identityout = self.relu(out)return out"""定义make_layer函数,它负责构建一个由多个残差块(block)组成的网络层。这个函数首先检查是否需要创建下采样层(down_sample),这通常是为了匹配输入和输出的维度或进行特征图的空间降维。然后,它添加第一个残差块(可能需要下采样层),并基于第一个残差块的输出通道数(考虑扩展因子)堆叠剩余的残差块。最后,所有的残差块被封装在一个nn.SequentialCell中,以便可以作为一个整体进行前向传播。
"""
def make_layer(last_out_channel, block: Type[Union[ResidualBlockBase, ResidualBlock]],channel: int, block_nums: int, stride: int = 1):down_sample = None # shortcuts分支# 如果步长不为1或者上一层的输出通道数与当前层首个残差块的期望输出通道数不匹配,则创建下采样层if stride != 1 or last_out_channel != channel * block.expansion:down_sample = nn.SequentialCell([nn.Conv2d(last_out_channel, channel * block.expansion,kernel_size=1, stride=stride, weight_init=weight_init),nn.BatchNorm2d(channel * block.expansion, gamma_init=gamma_init)])# 初始化残差块列表layers = []layers.append(block(last_out_channel, channel, stride=stride, down_sample=down_sample))# 更新输入通道数为当前残差块的输出通道数(考虑扩展因子)in_channel = channel * block.expansion# 堆叠残差网络for _ in range(1, block_nums):layers.append(block(in_channel, channel))return nn.SequentialCell(layers)# 构建ResNet50网络
from mindspore import load_checkpoint, load_param_into_netclass ResNet(nn.Cell):def __init__(self, block: Type[Union[ResidualBlockBase, ResidualBlock]],layer_nums: List[int], num_classes: int, input_channel: int) -> None:super(ResNet, self).__init__()self.relu = nn.ReLU()# 第一个卷积层,输入channel为3(彩色图像),输出channel为64self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, weight_init=weight_init)self.norm = nn.BatchNorm2d(64)# 最大池化层,缩小图片的尺寸self.max_pool = nn.MaxPool2d(kernel_size=3, stride=2, pad_mode='same')# 各个残差网络结构块定义,self.layer1 = make_layer(64, block, 64, layer_nums[0])self.layer2 = make_layer(64 * block.expansion, block, 128, layer_nums[1], stride=2)self.layer3 = make_layer(128 * block.expansion, block, 256, layer_nums[2], stride=2)self.layer4 = make_layer(256 * block.expansion, block, 512, layer_nums[3], stride=2)# 平均池化层self.avg_pool = nn.AvgPool2d()# flattern层self.flatten = nn.Flatten()# 全连接层self.fc = nn.Dense(in_channels=input_channel, out_channels=num_classes)def construct(self, x):x = self.conv1(x)x = self.norm(x)x = self.relu(x)x = self.max_pool(x)x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)x = self.avg_pool(x)x = self.flatten(x)x = self.fc(x)return xdef _resnet(model_url: str, block: Type[Union[ResidualBlockBase, ResidualBlock]],layers: List[int], num_classes: int, pretrained: bool, pretrianed_ckpt: str,input_channel: int):model = ResNet(block, layers, num_classes, input_channel)if pretrained:# 加载预训练模型download(url=model_url, path=pretrianed_ckpt, replace=True)param_dict = load_checkpoint(pretrianed_ckpt)load_param_into_net(model, param_dict)return modeldef resnet50(num_classes: int = 1000, pretrained: bool = False):"ResNet50模型"resnet50_url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/models/application/resnet50_224_new.ckpt"resnet50_ckpt = "./LoadPretrainedModel/resnet50_224_new.ckpt"return _resnet(resnet50_url, ResidualBlock, [3, 4, 6, 3], num_classes,pretrained, resnet50_ckpt, 2048)2. 固定特征进行训练
使用固定特征进行训练的时候,需要冻结除最后一层之外的所有网络层。通过设置 requires_grad == False 冻结参数,以便不在反向传播中计算梯度。
import mindspore as ms
import matplotlib.pyplot as plt
import os
import timenet_work = resnet50(pretrained=True)# 全连接层输入层的大小
in_channels = net_work.fc.in_channels
# 输出通道数大小为狼狗分类数2
head = nn.Dense(in_channels, 2)
# 重置全连接层
net_work.fc = head# 平均池化层kernel size为7
avg_pool = nn.AvgPool2d(kernel_size=7)
# 重置平均池化层
net_work.avg_pool = avg_pool# 冻结除最后一层外的所有参数
for param in net_work.get_parameters():if param.name not in ["fc.weight", "fc.bias"]:param.requires_grad = False# 定义优化器和损失函数
opt = nn.Momentum(params=net_work.trainable_params(), learning_rate=lr, momentum=0.5)
loss_fn = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')def forward_fn(inputs, targets):logits = net_work(inputs)loss = loss_fn(logits, targets)return lossgrad_fn = ms.value_and_grad(forward_fn, None, opt.parameters)def train_step(inputs, targets):loss, grads = grad_fn(inputs, targets)opt(grads)return loss# 实例化模型
model1 = train.Model(net_work, loss_fn, opt, metrics={"Accuracy": train.Accuracy()})3. 训练和评估
开始训练模型,与没有预训练模型相比,将节约一大半时间,因为此时可以不用计算部分梯度。保存评估精度最高的ckpt文件于当前路径的./BestCheckpoint/resnet50-best-freezing-param.ckpt。
import mindspore as ms
import matplotlib.pyplot as plt
import os
import time
dataset_train = create_dataset_canidae(data_path_train, "train")
step_size_train = dataset_train.get_dataset_size()dataset_val = create_dataset_canidae(data_path_val, "val")
step_size_val = dataset_val.get_dataset_size()num_epochs = 5# 创建迭代器
data_loader_train = dataset_train.create_tuple_iterator(num_epochs=num_epochs)
data_loader_val = dataset_val.create_tuple_iterator(num_epochs=num_epochs)
best_ckpt_dir = "./BestCheckpoint"
best_ckpt_path = "./BestCheckpoint/resnet50-best-freezing-param.ckpt"# 开始循环训练
print("Start Training Loop ...")best_acc = 0for epoch in range(num_epochs):losses = []net_work.set_train()epoch_start = time.time()# 为每轮训练读入数据for i, (images, labels) in enumerate(data_loader_train):labels = labels.astype(ms.int32)loss = train_step(images, labels)losses.append(loss)# 每个epoch结束后,验证准确率acc = model1.eval(dataset_val)['Accuracy']epoch_end = time.time()epoch_seconds = (epoch_end - epoch_start) * 1000step_seconds = epoch_seconds/step_size_trainprint("-" * 20)print("Epoch: [%3d/%3d], Average Train Loss: [%5.3f], Accuracy: [%5.3f]" % (epoch+1, num_epochs, sum(losses)/len(losses), acc))print("epoch time: %5.3f ms, per step time: %5.3f ms" % (epoch_seconds, step_seconds))if acc > best_acc:best_acc = accif not os.path.exists(best_ckpt_dir):os.mkdir(best_ckpt_dir)ms.save_checkpoint(net_work, best_ckpt_path)print("=" * 80)
print(f"End of validation the best Accuracy is: {best_acc: 5.3f}, "f"save the best ckpt file in {best_ckpt_path}", flush=True)运行结果:
Start Training Loop ... -------------------- Epoch: [ 1/ 5], Average Train Loss: [0.664], Accuracy: [0.800] epoch time: 50934.131 ms, per step time: 3638.152 ms -------------------- Epoch: [ 2/ 5], Average Train Loss: [0.556], Accuracy: [0.817] epoch time: 824.633 ms, per step time: 58.902 ms -------------------- Epoch: [ 3/ 5], Average Train Loss: [0.510], Accuracy: [0.967] epoch time: 767.022 ms, per step time: 54.787 ms -------------------- Epoch: [ 4/ 5], Average Train Loss: [0.438], Accuracy: [1.000] epoch time: 714.965 ms, per step time: 51.069 ms -------------------- Epoch: [ 5/ 5], Average Train Loss: [0.395], Accuracy: [1.000] epoch time: 734.045 ms, per step time: 52.432 ms ================================================================================ End of validation the best Accuracy is: 1.000, save the best ckpt file in ./BestCheckpoint/resnet50-best-freezing-param.ckpt
4. 可视化模型预测
使用固定特征得到的best.ckpt文件对验证集的狼和狗图像数据进行预测。若预测字体为蓝色即为预测正确,若预测字体为红色则预测错误。
import matplotlib.pyplot as plt
import mindspore as msdef visualize_model(best_ckpt_path, val_ds):net = resnet50()# 全连接层输入层的大小in_channels = net.fc.in_channels# 输出通道数大小为狼狗分类数2head = nn.Dense(in_channels, 2)# 重置全连接层net.fc = head# 平均池化层kernel size为7avg_pool = nn.AvgPool2d(kernel_size=7)# 重置平均池化层net.avg_pool = avg_pool# 加载模型参数param_dict = ms.load_checkpoint(best_ckpt_path)ms.load_param_into_net(net, param_dict)model = train.Model(net)# 加载验证集的数据进行验证data = next(val_ds.create_dict_iterator())images = data["image"].asnumpy()labels = data["label"].asnumpy()class_name = {0: "dogs", 1: "wolves"}# 预测图像类别output = model.predict(ms.Tensor(data['image']))pred = np.argmax(output.asnumpy(), axis=1)# 显示图像及图像的预测值plt.figure(figsize=(5, 5))for i in range(4):plt.subplot(2, 2, i + 1)# 若预测正确,显示为蓝色;若预测错误,显示为红色color = 'blue' if pred[i] == labels[i] else 'red'plt.title('predict:{}'.format(class_name[pred[i]]), color=color)picture_show = np.transpose(images[i], (1, 2, 0))mean = np.array([0.485, 0.456, 0.406])std = np.array([0.229, 0.224, 0.225])picture_show = std * picture_show + meanpicture_show = np.clip(picture_show, 0, 1)plt.imshow(picture_show)plt.axis('off')plt.show()visualize_model(best_ckpt_path, dataset_val)运行结果:

相关文章:
昇思25天学习打卡营第11天|xiaoyushao
今天分享ResNet50迁移学习。 在实际应用场景中,由于训练数据集不足,所以很少有人会从头开始训练整个网络。普遍的做法是,在一个非常大的基础数据集上训练得到一个预训练模型,然后使用该模型来初始化网络的权重参数或作为固定特征提…...
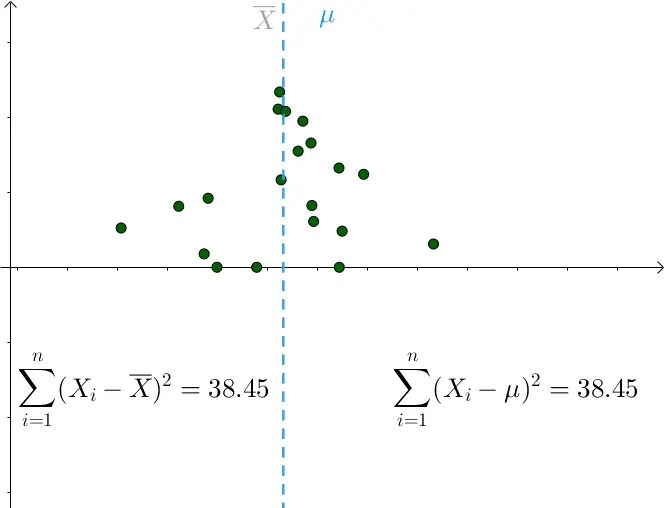
为什么样本方差(sample variance)的分母是 n-1?
样本均值与样本方差的定义 首先来看一下均值,方差,样本均值与样本方差的定义 总体均值的定义: μ 1 n ∑ i 1 n X i \mu\frac{1}{n}\sum_{i1}^{n} X_i μn1i1∑nXi 也就是将总体中所有的样本值加总除以个数,也可以叫做总…...

编解码器架构
一、定义 0、机器翻译是序列转换模型的一个核心问题, 其输入和输出都是长度可变的序列。 为了处理这种类型的输入和输出, 我们设计一个包含两个主要组件的架构: 第一个组件是一个编码器(encoder): 它接受一…...

追问试面试系列:JVM运行时数据区
hi 欢迎来到追问试面试系列之JVM运行时数据区,在面试中出现频率非常高,并且其中还存在一些误导性的面试,一定要注意。 什么误导性呢?面试中,有的面试官本来是想问JVM运行时数据区,不过提问时难免有些让你觉得很不爽。比如:你说说java内存模型,还比如说说JVM内存模型,…...

React Native在移动端落地实践
在移动互联网产品迅猛发展的今天,技术的不断创新使得企业越来越注重降低成本、提升效率。为了在有限的开发资源下迅速推出高质量、用户体验好的产品,以实现公司发展,业界催生了许多移动端跨平台解决方案。这些方案不仅简化了开发流程…...

《操作系统》(学习笔记)(王道)
一、计算机系统概述 1.1 操作系统的基本概念 1.1.1 操作系统的概念 1.1.2 操作系统的特征 1.1.3 操作系统的目标和功能 1.2 操作系统的发展与分类 1.2.1 手工操作阶段(此阶段无操作系统) 1.2.2 批处理阶段(操作系统开始出现࿰…...

LabVIEW学习-LabVIEW处理带分隔符的字符串从而获取数据
带分隔符的字符串很好处理,只需要使用"分隔符字符串至一维字符串数组"函数或者"一维字符串数组至分隔符字符串"函数就可以很轻松地处理带分隔符地字符串。 这两个函数所在的位置为: 函数选板->字符串->附加字符串函数->分…...

freesql简单使用操作mysql数据库
参考:freesql中文官网指南 | FreeSql 官方文档 这两天准备做一个测试程序,往一个系统的数据表插入一批模拟设备数据,然后还要模拟设备终端发送数据包,看看系统的承压能力。 因为系统使用的第三方框架中用到了freesql,…...

使用Java和Spring Retry实现重试机制
使用Java和Spring Retry实现重试机制 大家好,我是微赚淘客系统3.0的小编,是个冬天不穿秋裤,天冷也要风度的程序猿!今天,我们将探讨如何在Java中使用Spring Retry来实现重试机制。重试机制在处理临时性故障和提高系统稳…...
:自定义配置与插件管理)
Linux Vim教程(十):自定义配置与插件管理
目录 1. 概述 2. Vim 配置文件 2.1 .vimrc 文件 2.2 .gvimrc 文件 3. 自定义配置 3.1 自定义快捷键 3.2 自动命令 3.3 函数定义 4. 插件管理 4.1 插件管理工具 4.1.1 安装 vim-plug 4.1.2 配置 vim-plug 4.1.3 安装插件 4.2 常用插件 4.2.1 NERDTree 4.2.2 Fzf…...

代理协议解析:如何根据需求选择HTTP、HTTPS或SOCKS5?
代理IP协议是一种网络代理技术,可以实现隐藏客户端IP地址、加速网站访问、过滤网络内容、访问内网资源等功能。常用的IP代理协议主要有Socks5代理、HTTP代理、HTTPS代理这三种。代理IP协议主要用于分组交换计算机通信网络的互联系统中使用,只负责数据的路…...
Verilog语言和C语言的本质区别是什么?
在开始前刚好我有一些资料,是我根据网友给的问题精心整理了一份「C语言的资料从专业入门到高级教程」, 点个关注在评论区回复“888”之后私信回复“888”,全部无偿共享给大家!!! 用老石的一句话其实很好说…...

Delphi5实现鱼C屏幕保护程序
效果图 鱼C屏幕保护程序 添加背景图片 在additional添加image组件,修改picture属性上传图片。 这个图片可以截屏桌面,方便后面满屏不留白操作。实现无边框 即上面的“- □ ”不显示 将Form1的borderstyle属性改为bsnone实现最大化,满屏 将…...

【计算机毕业设计】844学籍管理系统
🙊作者简介:拥有多年开发工作经验,分享技术代码帮助学生学习,独立完成自己的项目或者毕业设计。 代码可以私聊博主获取。🌹赠送计算机毕业设计600个选题excel文件,帮助大学选题。赠送开题报告模板ÿ…...

Java之开发 系统设计 分布式 高性能 高可用
1、restful api 基于rest构建的api 规范: post delete put get 增删改查路径 接口命名 过滤信息状态码 2、软件开发流程 3、命名规范 类名:大驼峰方法名:小驼峰成员变量、局部变量:小驼峰测试方法名:蛇形命名 下划…...

java连接redis和基础操作命令
引入依赖 <!--引入java连接redis的驱动--><dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>4.3.1</version></dependency> 单机模式连接redis main(){ //连接redis的信息 默认连接…...

土耳其云手机提升TikTok电商效率
在数字化飞速发展的今天,TikTok不仅是一个社交平台,更是一个巨大的电商市场。随着TikTok电商功能在全球范围内的扩展,土耳其的商家和内容创作者正面临着前所未有的机遇。本文将详细介绍土耳其云手机怎样帮助商家抓住机遇,实现业务…...

《Utilizing Ensemble Learning for Detecting Multi-Modal Fake News》
系列论文研读目录 文章目录 系列论文研读目录论文题目含义ABSTRACTINDEX TERMSI. INTRODUCTIONII. RELATED WORKA. FAKE NEWS CLASSIFICATION APPROACHES FOR SINGLE-MODALITY 单模态虚假新闻分类方法1) SINGLE-MODALITY BASED CLASSIFICATION APPROACHES USING TEXTUAL FEATUR…...

Oracle集群RAC磁盘管理命令asmcmd的使用
文章目录 ASM磁盘共享简介ASM磁盘共享的优势ASM磁盘组成ASM磁盘共享的应用场景Asmcmd简介Asmcmd的功能Asmcmd的命令Asmcmd的使用注意事项Asmcmd运行模式交互模式运行非交互模式运行ASMCMD命令分类实例管理命令:文件管理命令:磁盘组管理命令:模板管理命令:文件访问管理命令:…...

vscode插件开发笔记——大模型应用之AI编程助手
系列文章目录 文章目录 系列文章目录前言一、代码补全 前言 最近在开发vscode插件相关的项目,网上很少有关于大模型作为AI 编程助手这方面的教程。因此,借此机会把最近写的几个demo分享记录一下。 一、代码补全 思路: 读取vscode插件上鼠…...

2026届必备的六大AI辅助写作网站横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 现今,各类数字化内容的AI生成痕迹核验标准不断持续迭代,多数内容创作…...

五层智能引擎架构:illustrator-scripts如何实现设计自动化效能革命
五层智能引擎架构:illustrator-scripts如何实现设计自动化效能革命 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 在数字化设计领域,设计师平均花费31.2%的…...

基于MCP与多准则决策的数据中心智能选址系统设计与实践
1. 项目概述:数据中心选址智能决策的现代解法最近在做一个挺有意思的项目,客户是一家大型互联网公司,他们计划在海外新建一个大型数据中心,但面对全球几十个潜在选址,从土地成本、电力供应、网络延迟到政策风险&#x…...

如何快速将STL转换为STEP:5个高效转换技巧指南
如何快速将STL转换为STEP:5个高效转换技巧指南 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp STL到STEP格式转换是3D设计和工程制造领域的关键桥梁,而stltostp正是解决…...
)
卸载软件后右键菜单残留?用PowerShell精准清理注册表(附一键备份脚本)
彻底告别右键菜单残留:PowerShell注册表清理实战指南 刚卸载完某款压缩软件,却发现右键菜单里依然顽固地留着它的选项——这种经历恐怕不少Windows用户都遇到过。上周帮同事处理电脑时,就遇到了一个典型案例:卸载"可牛压缩&q…...
深度集成:让 AI 安全执行企业 API)
函数调用(Function Calling)深度集成:让 AI 安全执行企业 API
系列导读 你现在看到的是《Spring AI 企业级集成与场景实践:从零搭建智能应用》的第 5/10 篇,当前这篇会重点解决:展示如何让 AI 安全可控地操作企业后端服务,实现真正的智能体能力。 上一篇回顾:第 4 篇《检索增强生成(RAG)实战:Spring AI 集成向量数据库实现知识问…...

如何在Windows上轻松安装APK文件:告别模拟器的完整指南
如何在Windows上轻松安装APK文件:告别模拟器的完整指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想要在Windows电脑上直接运行Android应用…...

AzurLaneAutoScript:基于图像识别与智能调度的碧蓝航线全自动脚本架构解析
AzurLaneAutoScript:基于图像识别与智能调度的碧蓝航线全自动脚本架构解析 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoSc…...

Anno 1800模组加载器:企业级XML智能合并与高性能游戏扩展架构实现指南
Anno 1800模组加载器:企业级XML智能合并与高性能游戏扩展架构实现指南 【免费下载链接】anno1800-mod-loader The one and only mod loader for Anno 1800, supports loading of unpacked RDA files, XML merging and Python mods. 项目地址: https://gitcode.com…...

NsEmuTools:5分钟搞定NS模拟器自动化管理的终极方案
NsEmuTools:5分钟搞定NS模拟器自动化管理的终极方案 【免费下载链接】ns-emu-tools 一个用于安装/更新 NS 模拟器的工具 项目地址: https://gitcode.com/gh_mirrors/ns/ns-emu-tools 你是否厌倦了手动安装和更新NS模拟器的繁琐过程?NsEmuTools作为…...