Java 多线程技术详解
文章目录
- Java 多线程技术详解
- 目录
- 引言
- 多线程的概念
- 为什么使用多线程?
- 多线程的特征
- 多线程的挑战
- 多线程的实现方式
- 3.1 继承 `Thread` 类
- 示例代码:
- 3.2 实现 `Runnable` 接口
- 示例代码:
- 3.3 使用 `Executor` 框架
- 示例代码:
- 3.4 使用 `Callable` 和 `Future`
- 示例代码:
- 线程的生命周期
- 线程状态
- 新建状态(New)
- 就绪状态(Runnable)
- 运行状态(Running)
- 阻塞状态(Blocked / Waiting / Timed Waiting)
- 终止状态(Terminated)
- 线程状态转换
- 线程调度
- 调度策略
- Java线程调度
- 影响线程调度的因素
- 调度的不可预测性
- 线程安全
- `synchronized`关键字的使用
- `synchronized`关键字的特点
- `synchronized`的局限性
- 如何优化`synchronized`
- 示例代码
- 7.2 Lock 接口
- ReentrantLock 类
- Condition 接口
- 示例代码
- 详细解释
- 构造函数
- put() 方法
- take() 方法
- 使用`awaitNanos()`方法的原因
- 总结
- 线程间通信
- 线程间通信概述
- Java 中的线程间通信
- 使用`Object`的`wait()`和`notify()`方法
- 使用`Lock`接口和`Condition`接口
- 示例代码
- 详细解释
- 构造函数
- put() 方法
- take() 方法
- 使用`awaitNanos()`方法的原因
- 总结
- 避免死锁
- 死锁的四个必要条件
- 如何避免死锁
- 1. **破坏互斥条件**
- 2. **破坏占有并等待条件**
- 3. **破坏非抢占条件**
- 4. **破坏循环等待条件**
- 线程池
- 10.1 ExecutorService
- 线程池的基本概念
- Java中的线程池
- 创建线程池
- 线程池参数
- 示例代码
- 1. Fixed Thread Pool
- 2. Cached Thread Pool
- 3. Scheduled Thread Pool
- 4. Single Thread Executor
- 线程中断
- 如何中断一个线程
- 检查线程中断状态
- 示例代码
- 注意事项
- 守护线程
- 守护线程的特点
- 创建守护线程
- 示例代码
- 注意事项
- 线程组
- 线程组的作用
- 创建线程组
- 示例代码
- 线程组的方法
- 注意事项
- 线程本地存储
- 什么是线程本地存储?
- `ThreadLocal`类的使用
- 创建`ThreadLocal`实例
- 示例代码
- `ThreadLocal`类的方法
- 注意事项
- 总结
- Java多线程的核心概念
- 实现多线程的方式
- 线程间通信
- 使用`Object`的`wait()`和`notify()`方法
- 使用`Lock`接口和`Condition`接口
- 避免死锁
- 线程池
- 线程中断
- 守护线程
- 线程组
- 线程本地存储
Java 多线程技术详解
目录
引言
Java多线程是Java平台的一个核心特性,它为开发人员提供了一种在单个程序中同时执行多个任务的能力。这种并发执行的能力不仅极大地提高了程序的执行效率,还允许软件更好地利用现代多核处理器的硬件资源,从而实现高性能和高响应性的应用。
多线程编程的核心优势在于它能够实现任务的并行处理,即在同一时间处理多个任务,这对于处理I/O密集型或计算密集型的工作负载特别有效。例如,一个服务器应用程序可以同时处理多个客户端请求,或者一个数据分析程序可以在不同的数据集上并行运行算法。
然而,多线程编程也带来了复杂性,特别是当涉及到线程之间的数据共享和同步时。如果不恰当地管理,多线程程序可能会遭受竞态条件、死锁、活锁、饥饿和资源泄露等问题。因此,理解线程生命周期、线程状态、线程调度、线程安全、线程间通信以及如何有效地使用线程池和其他高级同步机制,对于成功开发多线程应用程序至关重要。
Java标准库提供了丰富的API来支持多线程编程,包括Thread类、Runnable和Callable接口、ExecutorService框架、synchronized关键字、Lock和ReentrantLock接口、Condition接口、ThreadLocal类以及各种线程池类型。熟练掌握这些工具和技术,是成为高效Java多线程程序员的基础。
多线程的概念
在计算机科学中,多线程是指从软件或者硬件第一级(编程语言层面,操作系统层面,硬件层面)支持执行多个线程的操作。在Java中,多线程是指在一个单一的Java虚拟机(JVM)中,同时运行多个执行路径,即多个线程。每个线程都是操作系统进程中的一个执行单元,具有自己的程序计数器、堆栈和局部变量,但它们共享进程的全局变量和资源。
为什么使用多线程?
- 资源利用率:多线程可以提高CPU的利用率,特别是在多核处理器系统中,能够同时
并行处理多个任务(这里说的是在多核cpu中同一时间并行执行而不是在同一时间间隔内交替执行),从而提高系统的整体性能。 - 响应性:在图形用户界面(GUI)应用程序中,多线程确实可以极大地提高应用程序的响应性。
- 模块化:多线程可以增强程序的模块化,使得大型或复杂的程序更容易管理和扩展。在多线程编程中,每个线程通常负责执行一个特定的任务或一组相关任务,这可以看作是将程序分解成多个独立运行的组件或模块。
- 并发执行:多线程可以实现并发执行,这对于处理大量数据或执行长时间运行的任务非常有用。
多线程的特征
- 并发性:多个线程可以同时运行,尽管在单核处理器上可以表现为交替执行。
- 共享资源:线程之间共享相同的内存空间,这意味着它们可以访问和修改相同的变量,但这也可能导致数据不一致的问题,除非采取适当的同步措施。
- 上下文切换:操作系统在多个线程之间切换执行,这称为上下文切换,会带来一定的开销。
- 独立性:每个线程都有自己的执行流,它们可以独立于其他线程执行,但也可以通过线程间通信机制协作。
多线程的挑战
- 同步问题:当多个线程访问和修改共享资源时,必须采取措施防止竞态条件和死锁。
- 死锁:当两个或多个线程无限期地等待彼此持有的资源时发生。
- 资源竞争:多个线程对同一资源的访问可能需要排队,导致性能下降。
- 调试困难:多线程程序的错误往往难以重现和诊断,因为线程的执行顺序可能在每次运行时都不同。
多线程的实现方式
在Java中,实现多线程主要有四种常见的方式:继承Thread类、实现Runnable接口、使用Executor框架以及使用Callable和Future接口。每种方式都有其适用场景和优缺点。
3.1 继承 Thread 类
继承Thread类是最直接的实现多线程的方式。你需要创建一个Thread类的子类,并重写run()方法,其中包含线程要执行的代码。当通过子类实例调用start()方法时,run()方法会被系统调用,从而开始线程的执行。
示例代码:
public class MyThread extends Thread {@Overridepublic void run() {System.out.println("Hello from " + this.getName());}public static void main(String[] args) {MyThread myThread = new MyThread();myThread.start();}
}
优点:
- 直接使用
Thread类的方法,如start(),join(),interrupt()等。 - 可以访问和修改线程的一些属性,如线程名称、优先级。
缺点:
- Java不允许多重继承,因此,如果需要继承其他类,就不能再继承
Thread类。 - 不能直接使用
Thread类的其他成员变量。
3.2 实现 Runnable 接口
实现Runnable接口是更常用的多线程实现方式,因为它避免了Java单继承的限制。你需要创建一个实现了Runnable接口的类,并实现run()方法。之后,创建一个Thread对象,将你的Runnable对象作为参数传入,然后调用start()方法开始线程。
示例代码:
public class MyRunnable implements Runnable {@Overridepublic void run() {System.out.println("Hello from " + Thread.currentThread().getName());}public static void main(String[] args) {Thread myThread = new Thread(new MyRunnable(), "My Runnable Thread");myThread.start();}
}
优点:
- 不影响类的继承链,可以继承其他类。
- 更加灵活,适合复杂的业务逻辑。
缺点:
- 需要额外的
Thread对象来启动线程。
3.3 使用 Executor 框架
Executor框架是Java并发工具包(java.util.concurrent)的一部分,提供了更高级别的抽象来管理线程。ExecutorService接口是Executor框架的核心,它提供了一系列的线程管理方法,如submit(), execute(), shutdown(), isTerminated()等。使用ExecutorService可以创建线程池,有效地复用线程,避免频繁创建和销毁线程的开销。
示例代码:
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;public class ExecutorExample {public static void main(String[] args) {ExecutorService executor = Executors.newFixedThreadPool(5);for (int i = 0; i < 10; i++) {Runnable worker = new WorkerThread(i);executor.execute(worker);}executor.shutdown();while (!executor.isTerminated()) {// 等待所有线程完成}}
}class WorkerThread implements Runnable {private int id;public WorkerThread(int id) { this.id = id; }@Overridepublic void run() {System.out.println("Hello from WorkerThread " + id);}
}
优点:
- 更好的资源管理,通过线程池可以控制线程数量,避免过多线程导致的系统资源浪费。
- 提供了更丰富的线程控制方法,如定时执行、批量提交任务等。
缺点:
- 相对于直接使用
Thread和Runnable,实现起来稍微复杂一些。
3.4 使用 Callable 和 Future
Callable接口类似于Runnable,但是它允许线程执行后返回一个结果,并且可以抛出异常。Future接口用于获取Callable执行的结果,或取消任务的执行。
示例代码:
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;public class CallableExample {public static void main(String[] args) throws ExecutionException, InterruptedException {ExecutorService executor = Executors.newSingleThreadExecutor();Future<Integer> future = executor.submit(new MyCallable());int result = future.get(); // 阻塞直到得到结果System.out.println("Result: " + result);executor.shutdown();}
}class MyCallable implements Callable<Integer> {@Overridepublic Integer call() throws Exception {return 42; // 假设这是一个计算结果}
}
优点:
- 允许线程执行后返回结果,适合需要返回值的任务。
- 可以抛出异常,提供更完整的错误处理机制。
缺点:
- 相较于
Runnable,实现起来稍微复杂,因为需要处理Future和可能的异常。 Future.get()方法会阻塞,直到任务完成,需要注意避免在主线程中调用,以免造成UI冻结或其他性能问题。
线程的生命周期
在Java中,一个线程从创建到结束,会经历一系列的状态变化,这些状态构成了线程的生命周期。理解线程生命周期对于正确管理和控制线程非常重要,尤其在处理线程的启动、终止、同步和调度时。
线程状态
新建状态(New)
线程的生命周期始于新建状态,这时线程对象已经被创建,但是start()方法还没有被调用。在这个状态下,线程还没有开始执行任何代码。
就绪状态(Runnable)
当线程对象的start()方法被调用后,线程进入就绪状态。此时,线程已经准备好运行,但是尚未被调度器选中获取CPU时间片。处于就绪状态的线程由操作系统管理,等待CPU资源以便开始执行。
运行状态(Running)
一旦线程被调度器选中并分配到CPU时间片,线程开始执行其run()方法中的代码,此时线程处于运行状态。在运行状态中,线程可能会因为各种原因而暂停执行,如执行完一个时间片、等待I/O操作、等待其他线程释放锁、响应中断或执行sleep()方法等。
阻塞状态(Blocked / Waiting / Timed Waiting)
在执行过程中,线程可能会进入阻塞状态,这通常发生在以下几种情况下:
- 等待锁:当线程试图获取一个已被其他线程锁定的资源时,它将被阻塞,直到锁被释放。
- 等待通知:线程调用
Object.wait()方法,等待其他线程的notify()或notifyAll()通知。 - 等待定时事件:线程调用
Thread.sleep(long millis)或Object.wait(long timeout),在指定的时间段内不会被调度。
终止状态(Terminated)
当线程的run()方法执行完毕,或者线程抛出了未捕获的异常,线程将进入终止状态。一旦线程终止,它将不再参与调度,也不能再次启动。线程对象仍然存在于内存中,直到垃圾回收器将其回收。
线程状态转换
线程状态的转换是由Java虚拟机和操作系统共同管理的。以下是一些常见的状态转换:
- 新建 → 就绪:当
start()方法被调用后,线程从新建状态变为就绪状态。 - 就绪 → 运行:当线程被调度器选中并分配到CPU资源时,从就绪状态变为运行状态。
- 运行状态 → 就绪状态:当线程的时间片用尽,或者主动让出CPU(如调用
yield()方法),它会从运行状态变回就绪状态,等待下一次调度。 - 运行 → 阻塞:当线程遇到阻塞条件,如等待锁、I/O操作或执行
wait()时,从运行状态变为阻塞状态。 - 阻塞 → 就绪:当阻塞条件解除,如锁被释放、等待时间到期或收到通知,线程从阻塞状态回到就绪状态。
- 运行 → 终止:当线程的
run()方法执行完毕或抛出未捕获异常,线程从运行状态变为终止状态。
线程调度
线程调度是操作系统的一项核心功能,负责确定哪些线程应该在什么时候运行以及运行多长时间。在Java中,线程调度由Java虚拟机(JVM)和底层操作系统协同完成,主要依据线程的优先级和系统的调度策略。
调度策略
操作系统通常采用以下几种调度策略:
- 先来先服务(First-Come, First-Served, FCFS):按照线程到达的先后顺序进行调度。
- 时间片轮转(Round Robin, RR):将CPU时间分成相等的时间片,每个就绪状态的线程轮流获得一个时间片。
- 优先级调度(Priority Scheduling):根据线程的优先级高低进行调度,优先级高的线程优先执行。在Java中,线程的优先级可以通过
Thread类的setPriority()方法设置。 - 最短作业优先(Shortest Job First, SJF):优先执行预计执行时间最短的线程。
Java线程调度
在Java中,线程调度遵循优先级调度原则,但实际的调度细节取决于底层操作系统。Java虚拟机并不保证线程的优先级一定会直接影响线程的执行顺序,而是尽力按照优先级来调度线程。此外,线程优先级的范围是1(最低)到10(最高),默认优先级为5。
public class PriorityDemo {public static void main(String[] args) {// 创建低优先级线程Thread lowPriorityThread = new Thread(new Runnable() {@Overridepublic void run() {System.out.println("Low priority thread is running.");}});//通过Thread类的setPriority()方法来设置线程的优先级。线程的优先级是一个整数值,范围从Thread.MIN_PRIORITY(常量值为1,代表最低优先级)到Thread.MAX_PRIORITY(常量值为10,代表最高优先级)。默认的优先级是Thread.NORM_PRIORITY(常量值为5)lowPriorityThread.setPriority(Thread.MIN_PRIORITY);// 创建高优先级线程Thread highPriorityThread = new Thread(new Runnable() {@Overridepublic void run() {System.out.println("High priority thread is running.");}});highPriorityThread.setPriority(Thread.MAX_PRIORITY);// 启动线程lowPriorityThread.start();highPriorityThread.start();}
}线程调度的重要概念包括:
- 抢占式调度:在Java中,线程调度是抢占式的,这意味着高优先级的线程可以打断低优先级线程的执行,一旦高优先级的线程可用,它将立即获得CPU时间片。
- 时间片:每个线程在运行时会获得一个时间片,时间片结束后,线程会回到就绪状态,等待下一轮调度。
- 线程让步:线程可以通过调用
Thread.yield()方法主动放弃剩余的时间片,将CPU让给同优先级或更高优先级的线程。
影响线程调度的因素
- 线程优先级:高优先级的线程有更大的机会被调度。
- 线程状态:只有处于就绪状态的线程才能被调度。
- 系统负载:系统中的线程数量和CPU核心数量会影响线程调度的效率。
- 操作系统调度策略:底层操作系统的调度策略会对Java线程的调度产生影响。
- 线程交互:线程间的同步和通信操作,如等待锁或条件变量,会影响线程的调度时机。
调度的不可预测性
Java线程调度的具体行为在不同操作系统和不同JVM实现中可能会有所不同,因此开发者不能完全依赖于线程优先级来保证线程的执行顺序。在设计多线程应用程序时,应考虑到调度的不确定性和不可预测性,避免过度依赖线程调度来实现同步或定时任务。
线程安全
synchronized关键字是Java中用于实现线程安全的基本同步机制之一。它确保了在多线程环境中,任何时刻只有一个线程可以执行被synchronized关键字保护的代码段。这种机制通过内部的互斥锁(也称为监视器锁或内置锁)来实现,该锁与Java对象关联。
synchronized关键字的使用
synchronized关键字可以应用于两种情况:方法和代码块。
-
synchronized方法
当你声明一个方法为synchronized时,该方法成为一个同步方法。在该方法执行期间,任何其他线程都不能调用这个对象上的任何synchronized方法。这意味着对象的锁将被持有直到该方法执行完毕。public class Counter {private int count = 0;public synchronized void increment() {count++;} } -
synchronized代码块
你也可以使用synchronized关键字来同步代码块,这允许更细粒度的控制。你必须指定一个对象作为锁,通常是this对象或一个类的静态字段。public class Counter {private int count = 0;private final Object lock = new Object();public void increment() {synchronized (lock) {count++;}} }
synchronized关键字的特点
- 排他性:在任意时刻,只有一个线程能够执行被
synchronized保护的代码。 - 有序性:由于
synchronized关键字的锁是基于对象的,所以它强制执行了变量读取和写入的有序性,避免了指令重排序带来的问题。 - 可见性:当一个线程更改了共享变量的值,然后释放了锁,另一个线程在获取该锁时能够看到前一个线程所做的更改。
synchronized的局限性
- 性能开销:由于
synchronized需要维护锁的所有权和等待队列,因此在高并发的情况下可能会成为性能瓶颈。 - 死锁风险:如果多个
synchronized代码块或方法没有正确的加锁顺序,可能会导致死锁。
如何优化synchronized
虽然synchronized关键字是实现线程安全的一种简单方式,但在高并发场景下可能不是最优的选择。以下是一些优化策略:
- 减少锁的范围:只在必要的时候使用
synchronized,尽量减小同步代码块的大小。 - 使用锁分离:如果可能,将共享资源分割,每个资源有自己的锁,这样可以减少锁的竞争。
- 使用更高效的锁:如
java.util.concurrent包中的ReentrantLock,它提供了比synchronized更灵活的锁定机制,如可重入、公平性和条件变量。
示例代码
public class Counter {private int count = 0;private final Object lock = new Object();public void increment() {synchronized (lock) {count++;}}public int getCount() {synchronized (lock) {return count;}}
}
在上面的例子中,Counter类使用一个私有的锁对象来同步对count字段的访问。这确保了increment和getCount方法在多线程环境下的线程安全性。
7.2 Lock 接口
Lock接口是java.util.concurrent.locks包的一部分,它提供了一种更高级别的锁定机制,比synchronized关键字更灵活、更强大。Lock接口定义了以下主要方法:
void lock(): 获取锁。如果锁已被另一个线程持有,则当前线程将一直等待,直到锁被释放。void unlock(): 释放锁。boolean tryLock(): 尝试获取锁。如果锁不可用,则立即返回false,不会阻塞线程。boolean tryLock(long time, TimeUnit unit): 尝试获取锁。如果锁不可用,则等待一定的时间,如果在等待时间内锁仍未被释放,则返回false。Condition newCondition(): 返回一个Condition对象,可以用来实现更复杂的线程间同步。
ReentrantLock 类
ReentrantLock是Lock接口的一个实现,它提供了一个可重入的互斥锁。ReentrantLock有两个构造函数,分别用于创建公平锁和非公平锁:
- 公平锁:线程按照请求锁的顺序获取锁,这样可以减少线程的饥饿现象,但是性能通常不如非公平锁。
- 非公平锁:线程获取锁时没有固定的顺序,可能会导致后请求锁的线程在某些情况下先于前面的线程获取锁,这种情况下,锁的获取可能更偏向于当前正在运行的线程,从而提高性能。
ReentrantLock还提供了以下额外的控制功能:
- 可中断的锁获取:
lockInterruptibly()允许线程在等待锁时响应中断。 - 锁的公平性控制:通过构造函数的布尔参数来决定锁是否为公平锁。
- 锁的重入次数:
ReentrantLock允许同一个线程多次获取同一个锁,而不会造成死锁。
Condition 接口
Condition接口也是java.util.concurrent.locks包的一部分,它与Lock接口一起使用,提供了一种比Object类的wait()和notify()方法更高级的线程等待和唤醒机制。Condition接口允许线程等待某个条件满足,而不仅仅是在对象监视器上等待。
Condition接口的主要方法包括:
void await(): 释放锁并使当前线程等待,直到其他线程调用与此Condition相关的signal()或signalAll()方法。void signal(): 唤醒一个等待此Condition的线程。void signalAll(): 唤醒所有等待此Condition的线程。
示例代码
下面是一个使用ReentrantLock和Condition的示例,展示如何实现一个简单的生产者-消费者模式:
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;public class Buffer {private final ReentrantLock lock = new ReentrantLock();private final Condition notFull = lock.newCondition();private final Condition notEmpty = lock.newCondition();private final Object[] items;private int putIndex, takeIndex, count;public Buffer(int capacity) {if (capacity <= 0) {throw new IllegalArgumentException("Capacity must be greater than 0.");}items = new Object[capacity];}public void put(Object item) throws InterruptedException {lock.lock();try {// 如果缓冲区满,则等待while ((count == items.length) || (putIndex == takeIndex)) {long nanos = 1000 * 1000 * 1000; // 1秒nanos = notFull.awaitNanos(nanos);}items[putIndex] = item;if (++putIndex == items.length) putIndex = 0;++count;// 唤醒等待的消费者线程notEmpty.signal();} finally {lock.unlock();}}public Object take() throws InterruptedException {lock.lock();try {// 如果缓冲区空,则等待long nanos = 1000 * 1000 * 1000; // 1秒while (count == 0 && nanos > 0) {nanos = notEmpty.awaitNanos(nanos);}if (count != 0) {Object x = items[takeIndex];if (++takeIndex == items.length) takeIndex = 0;--count;// 唤醒等待的生产者线程notFull.signal();return x;} else {return null; // 缓冲区仍然为空,返回null}} finally {lock.unlock();}}
}
详细解释
构造函数
构造函数接收一个整数参数capacity,用于指定缓冲区的大小。如果传递的容量小于或等于0,将抛出IllegalArgumentException。构造函数还初始化了items数组,并设置了putIndex、takeIndex和count变量的初始值。
put() 方法
生产者线程调用put()方法将对象放入缓冲区。该方法的主要逻辑如下:
-
获取锁:
- 使用
lock.lock()获取锁。
- 使用
-
检查缓冲区是否已满:
- 使用
while (count == items.length)检查缓冲区是否已满。 - 如果缓冲区已满,线程将调用
notFull.awaitNanos(nanos)等待,其中nanos是最大等待时间(以纳秒为单位)。 awaitNanos()方法允许线程等待一个特定的时间长度,并返回剩余的等待时间。如果条件未在指定时间内满足,线程将继续执行下一个循环迭代。
- 使用
-
放入对象:
- 如果缓冲区未满,生产者将对象放入
items数组中。 - 更新
putIndex和count变量。
- 如果缓冲区未满,生产者将对象放入
-
唤醒消费者线程:
- 调用
notEmpty.signal()来唤醒等待的消费者线程。
- 调用
-
释放锁:
- 使用
lock.unlock()释放锁。
- 使用
take() 方法
消费者线程调用take()方法从缓冲区取出对象。该方法的主要逻辑如下:
-
获取锁:
- 使用
lock.lock()获取锁。
- 使用
-
检查缓冲区是否为空:
- 使用
while (count == 0)检查缓冲区是否为空。 - 如果缓冲区为空,线程将调用
notEmpty.awaitNanos(nanos)等待,其中nanos是最大等待时间(以纳秒为单位)。 awaitNanos()方法允许线程等待一个特定的时间长度,并返回剩余的等待时间。如果条件未在指定时间内满足,线程将继续执行下一个循环迭代。
- 使用
-
取出对象:
- 如果缓冲区不为空,消费者将对象从
items数组中取出。 - 更新
takeIndex和count变量。
- 如果缓冲区不为空,消费者将对象从
-
唤醒生产者线程:
- 调用
notFull.signal()来唤醒等待的生产者线程。
- 调用
-
释放锁:
- 使用
lock.unlock()释放锁。
- 使用
使用awaitNanos()方法的原因
使用awaitNanos()方法而不是普通的await()方法有几个好处:
-
避免忙等:
awaitNanos()方法允许线程在等待期间释放锁,并在指定的时间后自动恢复,从而避免了忙等的情况。
-
节省CPU资源:
- 通过限制等待时间,可以减少CPU的使用率,避免不必要的循环检查。
-
提高系统响应性:
- 如果条件在等待时间内没有满足,线程将退出等待状态并继续执行,这有助于提高系统的响应性。
总结
Lock接口和ReentrantLock类提供了更高级、更灵活的锁控制机制,适用于需要更细粒度控制的场景。使用Lock接口和ReentrantLock时,需要注意锁的获取和释放必须配对,否则会导致死锁或资源泄露。同时,Condition接口提供了更灵活的线程间同步方式,有助于实现更复杂的同步逻辑。
线程间通信
线程间通信概述
线程间通信是指在一个多线程环境中,不同线程之间共享信息和协调行为的过程。这对于确保程序的正确执行和提高效率至关重要。线程间通信通常涉及以下几种机制:
-
共享内存:
- 多个线程共享相同的内存空间,通过读写共享变量来通信。
- 必须注意同步访问,以防止竞态条件。
-
信号量和条件变量:
- 信号量用于管理资源的访问权限。
- 条件变量允许线程等待特定条件的满足。
-
消息队列:
- 一种基于队列的数据结构,线程可以向队列发送消息,其他线程可以从队列中读取消息。
-
管道(Pipes):
- 允许线程或进程之间通过管道进行通信。
-
事件对象:
- 用于信号通知,可以用来同步线程。
Java 中的线程间通信
在Java中,最常用的线程间通信机制包括使用Object类的wait()和notify()方法,以及使用java.util.concurrent包中的Lock接口和Condition接口。
使用Object的wait()和notify()方法
这是Java中最基本的线程间通信方式之一。wait()方法使当前线程等待,直到另一个线程调用notify()或notifyAll()方法。这些方法必须在同步块内调用,通常在synchronized块或方法中。
使用Lock接口和Condition接口
Lock接口提供了更高级的锁定机制,而Condition接口则提供了更灵活的线程等待和唤醒机制。这些接口位于java.util.concurrent.locks包中。
示例代码
下面是一个使用ReentrantLock和Condition的示例,展示如何实现一个简单的生产者-消费者模式:
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;public class Buffer {private final ReentrantLock lock = new ReentrantLock();private final Condition notFull = lock.newCondition();private final Condition notEmpty = lock.newCondition();private final Object[] items;private int putIndex, takeIndex, count;public Buffer(int capacity) {if (capacity <= 0) {throw new IllegalArgumentException("Capacity must be greater than 0.");}items = new Object[capacity];}public void put(Object item) throws InterruptedException {lock.lock();try {// 如果缓冲区满,则等待while ((count == items.length) || (putIndex == takeIndex)) {long nanos = 1000 * 1000 * 1000; // 1秒nanos = notFull.awaitNanos(nanos);}items[putIndex] = item;if (++putIndex == items.length) putIndex = 0;++count;// 唤醒等待的消费者线程notEmpty.signal();} finally {lock.unlock();}}public Object take() throws InterruptedException {lock.lock();try {// 如果缓冲区空,则等待long nanos = 1000 * 1000 * 1000; // 1秒while (count == 0 && nanos > 0) {nanos = notEmpty.awaitNanos(nanos);}if (count != 0) {Object x = items[takeIndex];if (++takeIndex == items.length) takeIndex = 0;--count;// 唤醒等待的生产者线程notFull.signal();return x;} else {return null; // 缓冲区仍然为空,返回null}} finally {lock.unlock();}}
}
详细解释
构造函数
构造函数接收一个整数参数capacity,用于指定缓冲区的大小。如果传递的容量小于或等于0,将抛出IllegalArgumentException。构造函数还初始化了items数组,并设置了putIndex、takeIndex和count变量的初始值。
put() 方法
生产者线程调用put()方法将对象放入缓冲区。该方法的主要逻辑如下:
-
获取锁:
- 使用
lock.lock()获取锁。
- 使用
-
检查缓冲区是否已满:
- 使用
while ((count == items.length) || (putIndex == takeIndex))检查缓冲区是否已满。 - 如果缓冲区已满,线程将调用
notFull.awaitNanos(nanos)等待,其中nanos是最大等待时间(以纳秒为单位)。 awaitNanos()方法允许线程等待一个特定的时间长度,并返回剩余的等待时间。如果条件未在指定时间内满足,线程将继续执行下一个循环迭代。
- 使用
-
放入对象:
- 如果缓冲区未满,生产者将对象放入
items数组中。 - 更新
putIndex和count变量。
- 如果缓冲区未满,生产者将对象放入
-
唤醒消费者线程:
- 调用
notEmpty.signal()来唤醒等待的消费者线程。
- 调用
-
释放锁:
- 使用
lock.unlock()释放锁。
- 使用
take() 方法
消费者线程调用take()方法从缓冲区取出对象。该方法的主要逻辑如下:
-
获取锁:
- 使用
lock.lock()获取锁。
- 使用
-
检查缓冲区是否为空:
- 使用
while (count == 0 && nanos > 0)检查缓冲区是否为空。 - 如果缓冲区为空,线程将调用
notEmpty.awaitNanos(nanos)等待,其中nanos是最大等待时间(以纳秒为单位)。 awaitNanos()方法允许线程等待一个特定的时间长度,并返回剩余的等待时间。如果条件未在指定时间内满足,线程将继续执行下一个循环迭代。
- 使用
-
取出对象:
- 如果缓冲区不为空,消费者将对象从
items数组中取出。 - 更新
takeIndex和count变量。
- 如果缓冲区不为空,消费者将对象从
-
唤醒生产者线程:
- 调用
notFull.signal()来唤醒等待的生产者线程。
- 调用
-
释放锁:
- 使用
lock.unlock()释放锁。
- 使用
使用awaitNanos()方法的原因
使用awaitNanos()方法而不是普通的await()方法有几个好处:
-
避免忙等:
awaitNanos()方法允许线程在等待期间释放锁,并在指定的时间后自动恢复,从而避免了忙等的情况。
-
节省CPU资源:
- 通过限制等待时间,可以减少CPU的使用率,避免不必要的循环检查。
-
提高系统响应性:
- 如果条件在等待时间内没有满足,线程将退出等待状态并继续执行,这有助于提高系统的响应性。
总结
线程间通信是多线程编程的关键部分,它确保了线程之间的协作和数据一致性。使用Lock接口和Condition接口可以实现更高级、更灵活的同步机制,帮助开发者更好地管理线程间的交互。
避免死锁
避免死锁是多线程编程中的一个重要方面,尤其是在Java中。死锁是一种特殊情况下的资源竞争问题,其中一个或多个线程永久阻塞,因为每个线程都在等待另一个线程持有的锁。为了帮助你完善关于如何避免死锁的内容,我将提供一些关键点和建议。
死锁的四个必要条件
死锁通常由以下四个必要条件引起:
- 互斥条件:至少有一个资源必须处于非共享模式,即一次只能被一个进程使用。
- 占有并等待:进程已保持至少一个资源,但又等待新的资源。
- 非抢占:资源不能被抢占,只能由拥有进程自愿释放。
- 循环等待:存在一种进程-资源的循环链,每个进程已占用的资源被下一个进程所期望。
如何避免死锁
为了避免死锁的发生,可以采取以下策略:
1. 破坏互斥条件
- 资源共享:尽可能使资源可共享,减少独占资源的需求。
- 避免使用锁:如果可能的话,重新设计代码以避免使用锁。
2. 破坏占有并等待条件
- 一次性获取所有资源:确保线程在开始执行之前获取所有必需的锁。
- 按顺序获取锁:如果多个线程需要获取多个锁,则让它们按照固定的顺序获取锁,这样可以避免形成循环等待。
3. 破坏非抢占条件
- 超时机制:为锁请求添加超时机制,如果超过一定时间无法获得锁,则释放已经持有的锁并稍后再重试。
- 使用tryLock:使用
ReentrantLock的tryLock()方法来尝试获取锁,如果锁不可用,则不会阻塞线程。
4. 破坏循环等待条件
- 锁顺序:如果一个线程需要多个锁,确保总是按照相同的顺序获取这些锁。
- 死锁检测:定期检查是否有可能出现死锁的情况,如果检测到潜在的死锁,则释放锁并重试。
线程池
10.1 ExecutorService
线程池是Java多线程编程中的一个重要概念,它可以有效地管理线程的创建和销毁过程,减少系统资源的消耗,并提供了一种更灵活的方式来管理并发任务。下面是关于线程池的一些详细信息,可以帮助你更好地理解和使用线程池。
线程池的基本概念
线程池是在Java中管理线程的一种机制,它预先创建一定数量的线程,这些线程处于等待状态,当有新的任务到来时,线程池会分配一个线程来执行这个任务。当任务完成后,线程并不会被销毁,而是返回到线程池中等待下一个任务。这种方式可以避免频繁创建和销毁线程带来的开销,提高程序的执行效率。
Java中的线程池
Java中线程池的主要接口是ExecutorService,它是java.util.concurrent包的一部分。ExecutorService提供了一些重要的方法来控制线程池的生命周期,如submit()、execute()、shutdown()和awaitTermination()等。
创建线程池
线程池可以通过Executors工厂类来创建,该类提供了几个静态方法来创建不同类型的线程池。以下是几种常见的线程池类型:
-
Fixed Thread Pool (
newFixedThreadPool(nThreads)):- 固定大小的线程池,线程数量固定。
- 如果提交的任务数量超过了线程池的大小,这些任务会被放入一个队列中等待执行。
- 适用于任务数量未知的情况,尤其是处理大量短期异步任务时。
-
Cached Thread Pool (
newCachedThreadPool()):- 可缓存的线程池,线程数量动态调整。
- 当没有任务时,多余的空闲线程会被销毁。
- 适用于执行大量的短期异步任务。
-
Scheduled Thread Pool (
newScheduledThreadPool(nThreads)):- 定时线程池,用于执行周期性或定时任务。
- 支持延迟执行任务和周期性执行任务。
-
Single Thread Executor (
newSingleThreadExecutor()):- 单一线程池,只包含一个线程。
- 适用于需要保证任务按顺序执行的场合。
线程池参数
-
核心线程数 (
corePoolSize):- 表示线程池中的最小线程数量。即使没有任务执行,线程池也会维护这些线程。
- 这些线程通常不会被终止,除非调用了
allowCoreThreadTimeOut(true)。
-
最大线程数 (
maximumPoolSize):- 表示线程池中可以创建的最大线程数量。
- 当任务队列满时,线程池会继续创建新线程,直到达到最大线程数。
-
空闲线程存活时间 (
keepAliveTime):- 指定了线程空闲时可以存活的时间长度。
- 对于超过核心线程数的线程,如果它们空闲了指定的时间长度,就会被终止。
- 对于核心线程,默认情况下,如果设置了
allowCoreThreadTimeOut(true),核心线程也会遵守这个时间限制。
-
时间单位 (
TimeUnit):- 用于指定
keepAliveTime的时间单位,例如秒(SECONDS)、毫秒(MILLISECONDS)等。
- 用于指定
-
工作队列 (
workQueue):- 用于存放等待执行的任务的队列。
- 通常使用
ArrayBlockingQueue,LinkedBlockingQueue或SynchronousQueue等。 - 当线程池中的线程数达到最大线程数时,新来的任务将会被放入此队列等待执行。
-
拒绝策略 (
handler):- 当任务队列已满并且线程池已经达到最大线程数时,如果还有新的任务提交,那么线程池会采取拒绝策略来处理这些任务。
- 常见的拒绝策略包括:
AbortPolicy: 抛出RejectedExecutionException异常。CallerRunsPolicy: 由调用者所在的线程来执行该任务。DiscardPolicy: 不处理该任务(也就是将其丢弃)。DiscardOldestPolicy: 丢弃队列中最旧的任务,然后重试执行当前任务。
示例代码
1. Fixed Thread Pool
import java.util.concurrent.*;public class FixedThreadPoolExample {public static void main(String[] args) {// 设置线程池参数int corePoolSize = 3; // 核心线程数int maximumPoolSize = 3; // 最大线程数long keepAliveTime = 60L; // 空闲线程存活时间TimeUnit unit = TimeUnit.SECONDS; // 时间单位BlockingQueue<Runnable> workQueue = new LinkedBlockingQueue<>(); // 工作队列RejectedExecutionHandler handler = new ThreadPoolExecutor.CallerRunsPolicy(); // 拒绝策略// 创建线程池ExecutorService fixedThreadPool = new ThreadPoolExecutor(corePoolSize,maximumPoolSize,keepAliveTime,unit,workQueue,handler);for (int i = 0; i < 10; i++) {final int taskId = i;fixedThreadPool.submit(() -> {System.out.println("Task ID: " + taskId + " is running by " + Thread.currentThread().getName());try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}});}// 关闭线程池fixedThreadPool.shutdown();while (!fixedThreadPool.isTerminated()) {// 等待所有任务完成}System.out.println("All tasks completed.");}
}
2. Cached Thread Pool
import java.util.concurrent.*;public class CachedThreadPoolExample {public static void main(String[] args) {// 设置线程池参数int corePoolSize = 0; // 核心线程数int maximumPoolSize = Integer.MAX_VALUE; // 最大线程数long keepAliveTime = 60L; // 空闲线程存活时间TimeUnit unit = TimeUnit.SECONDS; // 时间单位BlockingQueue<Runnable> workQueue = new SynchronousQueue<>(); // 工作队列RejectedExecutionHandler handler = new ThreadPoolExecutor.AbortPolicy(); // 拒绝策略// 创建线程池ExecutorService cachedThreadPool = new ThreadPoolExecutor(corePoolSize,maximumPoolSize,keepAliveTime,unit,workQueue,handler);for (int i = 0; i < 10; i++) {final int taskId = i;cachedThreadPool.submit(() -> {System.out.println("Task ID: " + taskId + " is running by " + Thread.currentThread().getName());try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}});}// 关闭线程池cachedThreadPool.shutdown();while (!cachedThreadPool.isTerminated()) {// 等待所有任务完成}System.out.println("All tasks completed.");}
}
3. Scheduled Thread Pool
import java.util.concurrent.*;public class ScheduledThreadPoolExample {public static void main(String[] args) {// 设置线程池参数int corePoolSize = 2; // 核心线程数int maximumPoolSize = 2; // 最大线程数long keepAliveTime = 60L; // 空闲线程存活时间TimeUnit unit = TimeUnit.SECONDS; // 时间单位BlockingQueue<Runnable> workQueue = new LinkedBlockingQueue<>(); // 工作队列RejectedExecutionHandler handler = new ThreadPoolExecutor.CallerRunsPolicy(); // 拒绝策略// 创建线程池ScheduledExecutorService scheduledThreadPool = new ScheduledThreadPoolExecutor(corePoolSize,handler);for (int i = 0; i < 10; i++) {final int taskId = i;scheduledThreadPool.scheduleAtFixedRate(() -> {System.out.println("Task ID: " + taskId + " is running by " + Thread.currentThread().getName());try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}, 0, 2, TimeUnit.SECONDS);}// 关闭线程池scheduledThreadPool.shutdown();while (!scheduledThreadPool.isTerminated()) {// 等待所有任务完成}System.out.println("All tasks completed.");}
}
4. Single Thread Executor
import java.util.concurrent.*;public class SingleThreadExecutorExample {public static void main(String[] args) {// 设置线程池参数int corePoolSize = 1; // 核心线程数int maximumPoolSize = 1; // 最大线程数long keepAliveTime = 0L; // 空闲线程存活时间TimeUnit unit = TimeUnit.MILLISECONDS; // 时间单位BlockingQueue<Runnable> workQueue = new LinkedBlockingQueue<>(); // 工作队列RejectedExecutionHandler handler = new ThreadPoolExecutor.CallerRunsPolicy(); // 拒绝策略// 创建线程池ExecutorService singleThreadExecutor = new ThreadPoolExecutor(corePoolSize,maximumPoolSize,keepAliveTime,unit,workQueue,handler);for (int i = 0; i < 10; i++) {final int taskId = i;singleThreadExecutor.submit(() -> {System.out.println("Task ID: " + taskId + " is running by " + Thread.currentThread().getName());try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}});}// 关闭线程池singleThreadExecutor.shutdown();while (!singleThreadExecutor.isTerminated()) {// 等待所有任务完成}System.out.println("All tasks completed.");}
}
在上面的每个示例中,我使用ThreadPoolExecutor构造函数显式地设置了线程池参数,并根据每种线程池的特性和用途配置了合适的参数。例如,在FixedThreadPool示例中,核心线程数与最大线程数相同,而在CachedThreadPool示例中,核心线程数为0,最大线程数为Integer.MAX_VALUE,以适应动态任务需求。对于ScheduledThreadPool,虽然它也有核心线程数和最大线程数的参数,但通常我们使用ScheduledThreadPoolExecutor的构造函数来创建定时线程池,而不是直接使用ThreadPoolExecutor。
线程中断
线程中断是Java多线程编程中的一个重要特性,它允许一个线程请求另一个线程停止执行。当一个线程被中断时,它会抛出InterruptedException,这通常发生在阻塞操作中,比如Thread.sleep(), Object.wait(), 或者LockSupport.park()等。
如何中断一个线程
要中断一个线程,可以调用线程对象的interrupt()方法。这会设置线程的中断标志,并且如果线程正在执行一个阻塞操作,它会抛出InterruptedException。
检查线程中断状态
每个线程都有一个内部中断标志,可以通过以下方法来检查或清除这个标志:
Thread.interrupted(): 返回当前线程的中断状态,并清除中断标志。Thread.isInterrupted(): 返回当前线程或给定线程的中断状态,但不会清除中断标志。
示例代码
下面是一个简单的示例,演示如何中断一个线程:
public class InterruptExample {public static void main(String[] args) throws InterruptedException {Thread thread = new Thread(() -> {while (true) {if (Thread.currentThread().isInterrupted()) {System.out.println("Thread interrupted");return;}try {Thread.sleep(1000);System.out.println("Thread is running");} catch (InterruptedException e) {Thread.currentThread().interrupt(); // 重新设置中断标志System.out.println("Thread interrupted during sleep");return;}}});thread.start();Thread.sleep(5000); // 等待5秒后中断线程thread.interrupt();thread.join();System.out.println("Main thread finished.");}
}
在这个例子中,主线程创建了一个新线程并启动它。新线程在无限循环中每秒打印一条消息,并检查是否被中断。如果被中断,它会退出循环并结束线程。主线程等待5秒后中断新线程,并等待新线程结束。
注意事项
- 中断标志: 中断标志是一个线程级别的标志,当线程被中断时,这个标志被设置。当线程抛出
InterruptedException时,中断标志会被清除。因此,在捕获InterruptedException后,通常需要重新设置中断标志,以保持中断状态的一致性。 - 非阻塞操作: 如果线程在非阻塞操作中被中断,它不会抛出
InterruptedException。因此,线程应定期检查它的中断状态。 - 资源清理: 在线程中处理中断时,不要忘记清理任何打开的资源或进行必要的清理操作。
守护线程
守护线程(Daemon Threads)是Java多线程编程中的一个重要概念。它们通常用于执行后台任务,如垃圾收集、日志记录、心跳检测等,这些任务对于程序的正常运行是辅助性的。当程序中的所有用户线程(非守护线程)都结束时,守护线程会自动结束,不需要显式地关闭它们。
守护线程的特点
- 自动结束:当Java程序中没有非守护线程在运行时,所有的守护线程都会自动结束,即使它们仍在执行。
- 辅助性:守护线程通常用于执行后台任务,这些任务不是程序的主要业务逻辑,但对程序的运行是有益的。
- 生命周期:守护线程的生命周期与其他线程相同,但它们的行为受到程序中其他线程的影响。
创建守护线程
要创建一个守护线程,需要在调用Thread.start()方法之前,通过调用Thread.setDaemon(true)方法将线程标记为守护线程。
示例代码
下面是一个简单的示例,展示了如何创建一个守护线程:
public class DaemonThreadExample {public static void main(String[] args) {Thread daemonThread = new Thread(() -> {while (true) {System.out.println("Daemon thread running...");try {Thread.sleep(1000);} catch (InterruptedException e) {Thread.currentThread().interrupt();break;}}});// 设置线程为守护线程daemonThread.setDaemon(true);// 启动守护线程daemonThread.start();// 主线程睡眠一段时间后结束try {Thread.sleep(5000);} catch (InterruptedException e) {Thread.currentThread().interrupt();}System.out.println("Main thread finished.");}
}
在这个示例中,守护线程每隔一秒打印一条消息。主线程睡眠5秒后结束。由于守护线程是作为守护线程创建的,所以当主线程结束时,守护线程也会自动结束。
注意事项
- 守护线程的启动:守护线程必须在调用
start()方法之前设置为守护线程,一旦线程开始运行,就不能改变它的守护状态。 - 资源释放:如果守护线程持有资源(如文件句柄、网络连接等),则应在主线程结束前确保这些资源被妥善释放,否则可能导致资源泄露。
- 异常处理:守护线程通常不应该抛出未捕获的异常,因为这可能导致程序异常终止。因此,最好在守护线程中捕获异常并妥善处理。
线程组
线程组(Thread Group)是Java多线程编程中的一个概念,它用于组织和管理一组线程。线程组提供了一种将线程分组的方式,使得可以对这些线程进行统一的管理和控制。线程组可以嵌套,也就是说,一个线程组可以包含其他的线程组,形成层次结构。
线程组的作用
- 组织线程:线程组提供了一种将线程按照功能或逻辑进行分类的方法。
- 管理线程:可以通过线程组来启动、挂起、恢复或终止线程。
- 线程安全:线程组提供了一种机制来限制哪些线程可以访问或控制其他线程。
创建线程组
要创建一个线程组,可以使用ThreadGroup类的构造函数。通常,线程组会在创建线程时指定。每个线程默认属于其创建者的线程组,如果没有指定线程组,则属于系统的默认线程组。
示例代码
下面是一个简单的示例,展示了如何创建线程组和向其中添加线程:
public class ThreadGroupExample {public static void main(String[] args) {// 创建线程组ThreadGroup group = new ThreadGroup("MyGroup");// 创建线程并将其加入到线程组中Thread thread = new Thread(group, () -> {System.out.println("Hello from " + Thread.currentThread().getName());}, "ThreadInGroup");// 启动线程thread.start();// 输出线程组的信息System.out.println("Thread Group Name: " + group.getName());System.out.println("Active Count: " + group.activeCount());// 等待线程结束try {thread.join();} catch (InterruptedException e) {Thread.currentThread().interrupt();}}
}
在这个示例中,我们首先创建了一个名为"MyGroup"的线程组。接着,创建了一个线程,并将其加入到这个线程组中。然后启动了这个线程,并输出了线程组的名称和活动线程的数量。
线程组的方法
ThreadGroup类提供了多种方法来管理和控制线程组内的线程:
void destroy(): 销毁线程组及其所有子线程和子线程组(仅当线程组中没有任何活动线程时才可用)。int activeCount(): 返回线程组中当前活动线程的数量。void enumerate(Thread[] threads): 将线程组中当前活动的线程复制到数组中。void checkAccess(): 检查当前线程是否有权限访问该线程组。void stop(): 请求线程组中的所有线程停止执行(不推荐使用,因为这可能会导致资源泄露)。void suspend(): 暂停线程组中的所有线程。void resume(): 恢复线程组中所有被暂停的线程。
注意事项
- 安全性:线程组提供了一种安全机制,只有创建线程组的线程才能访问和控制该线程组中的线程。这有助于保护线程不受未经授权的线程的干扰。
- 资源管理:线程组可以帮助管理线程的生命周期,比如通过
destroy()方法来销毁整个线程组,这在某些情况下可能是有用的。 - 局限性:尽管线程组提供了一定程度的管理能力,但在现代Java并发编程中,线程池和
ExecutorService等更高级的工具通常被视为更高效和更灵活的选择。线程组主要用于早期版本的Java,现在更多的是作为一种历史遗留的概念。
线程本地存储
线程本地存储(Thread Local Storage, TLS)是Java多线程编程中的一个重要概念,它提供了一种机制,使得每个线程都可以拥有自己独立的变量副本。ThreadLocal类是Java标准库中用于实现这一特性的工具。
什么是线程本地存储?
在多线程环境中,多个线程可能会共享同一个对象或变量。当这些线程试图同时修改这些共享变量时,就需要考虑同步问题,以避免竞态条件和数据不一致。然而,在某些情况下,我们希望每个线程都能拥有自己的变量副本,而不必担心线程之间的同步问题。这就是线程本地存储的目的。
ThreadLocal类的使用
ThreadLocal类提供了一种简单而有效的机制来实现线程本地存储。使用ThreadLocal类时,每个线程都可以拥有一个与该线程绑定的变量副本。这些副本是相互独立的,一个线程对它的副本所做的修改不会影响到其他线程。
创建ThreadLocal实例
创建ThreadLocal实例非常简单,只需要创建一个ThreadLocal对象即可。你可以选择在构造函数中提供一个初始值,或者在需要的时候再设置值。
示例代码
下面是一个简单的示例,展示了如何使用ThreadLocal:
public class ThreadLocalExample {private static final ThreadLocal<Integer> threadLocal = new ThreadLocal<Integer>() {@Overrideprotected Integer initialValue() {return 0;}};public static void main(String[] args) {Thread thread1 = new Thread(() -> {threadLocal.set(100);System.out.println("Thread 1: " + threadLocal.get());});Thread thread2 = new Thread(() -> {threadLocal.set(200);System.out.println("Thread 2: " + threadLocal.get());});thread1.start();thread2.start();try {thread1.join();thread2.join();} catch (InterruptedException e) {Thread.currentThread().interrupt();}System.out.println("Main thread: " + threadLocal.get());}
}
在这个示例中,我们定义了一个ThreadLocal变量threadLocal,并为其提供了一个初始值0。接着,我们在两个不同的线程中分别设置不同的值,并打印出这些值。注意,每个线程中的输出都是独立的,不受其他线程的影响。
ThreadLocal类的方法
ThreadLocal类提供了以下主要方法:
get(): 获取当前线程中变量的副本。set(T value): 设置当前线程中变量的副本。remove(): 移除当前线程中的变量副本。initialValue(): 可选方法,返回当前线程中变量的初始值。
注意事项
- 内存泄漏:当不再需要某个
ThreadLocal变量时,应该调用remove()方法来移除当前线程中的变量副本。否则,即使线程结束了,ThreadLocal变量的副本仍会被保留,这可能导致内存泄漏。 - 初始化:默认情况下,
ThreadLocal变量的初始值为null。如果需要设置特定的初始值,可以通过覆盖initialValue()方法来实现。 - 性能考虑:虽然
ThreadLocal可以简化多线程编程,但频繁地调用get()和set()方法可能会对性能产生影响,尤其是当线程频繁创建和销毁时。因此,在可能的情况下,尽量减少ThreadLocal的使用频率。
总结
Java多线程技术是Java平台的核心特性之一,它允许开发人员构建高度并发的应用程序,充分利用现代多核处理器的硬件资源。多线程编程虽然强大但也带来了诸多挑战,如竞态条件、死锁、资源竞争等问题。下面是对Java多线程技术的总结和完善:
Java多线程的核心概念
- 并发性:多个线程可以同时运行,尽管在单核处理器上可以表现为交替执行。
- 共享资源:线程之间共享相同的内存空间,这意味着它们可以访问和修改相同的变量,但这也可能导致数据不一致的问题,除非采取适当的同步措施。
- 上下文切换:操作系统在多个线程之间切换执行,这称为上下文切换,会带来一定的开销。
- 独立性:每个线程都有自己的执行流,它们可以独立于其他线程执行,但也可以通过线程间通信机制协作。
实现多线程的方式
- 继承
Thread类:创建Thread类的子类,并重写run()方法。 - 实现
Runnable接口:创建实现了Runnable接口的类,并实现run()方法。 - 使用
Executor框架:通过ExecutorService接口创建线程池来管理线程。 - 使用
Callable和Future接口:创建实现了Callable接口的类,可以返回结果,并使用Future来获取结果。
线程间通信
- 共享内存:多个线程共享相同的内存空间,通过读写共享变量来通信。必须注意同步访问,以防止竞态条件。
- 信号量和条件变量:信号量用于管理资源的访问权限。条件变量允许线程等待特定条件的满足。
- 消息队列:线程可以向队列发送消息,其他线程可以从队列中读取消息。
- 管道(Pipes):允许线程或进程之间通过管道进行通信。
- 事件对象:用于信号通知,可以用来同步线程。
使用Object的wait()和notify()方法
这是Java中最基本的线程间通信方式之一。wait()方法使当前线程等待,直到另一个线程调用notify()或notifyAll()方法。这些方法必须在同步块内调用,通常在synchronized块或方法中。
使用Lock接口和Condition接口
Lock接口提供了更高级的锁定机制,而Condition接口则提供了更灵活的线程等待和唤醒机制。这些接口位于java.util.concurrent.locks包中。
避免死锁
- 破坏互斥条件:尽可能使资源可共享,减少独占资源的需求;避免使用锁。
- 破坏占有并等待条件:确保线程在开始执行之前获取所有必需的锁;按顺序获取锁。
- 破坏非抢占条件:为锁请求添加超时机制;使用
ReentrantLock的tryLock()方法。 - 破坏循环等待条件:如果一个线程需要多个锁,确保总是按照相同的顺序获取这些锁;定期检查是否有可能出现死锁的情况。
线程池
- 固定线程池:通过
Executors.newFixedThreadPool()创建固定大小的线程池。 - 缓存线程池:通过
Executors.newCachedThreadPool()创建可以缓存线程的线程池。 - 单线程执行器:通过
Executors.newSingleThreadExecutor()创建只包含一个线程的线程池。 - 定时线程池:通过
Executors.newScheduledThreadPool()创建可以安排任务的线程池。
线程中断
线程可以被中断,以请求线程提前结束。线程可以通过调用Thread.interrupt()方法被中断。当一个线程被中断时,它会抛出InterruptedException,这通常发生在阻塞操作中。
守护线程
守护线程是那些在后台运行,为其他线程服务的线程,当所有非守护线程结束时,守护线程自动结束。守护线程通常用于执行后台任务,如垃圾收集、日志记录等。
线程组
线程组用于组织和管理一组线程。通过ThreadGroup类可以创建线程组,并将线程加入到线程组中,从而方便地管理和控制线程。
线程本地存储
ThreadLocal类提供了一个线程本地变量,每个线程都有自己的副本。ThreadLocal可以用来存储线程特定的数据,避免了线程之间的数据共享和同步问题。
相关文章:

Java 多线程技术详解
文章目录 Java 多线程技术详解目录引言多线程的概念为什么使用多线程?多线程的特征多线程的挑战 多线程的实现方式3.1 继承 Thread 类示例代码: 3.2 实现 Runnable 接口示例代码: 3.3 使用 Executor 框架示例代码: 3.4 使用 Calla…...

一份简单实用的MATLAB M语言编码风格指南
MATLAB M语言编码风格指南 1. 文件命名2. 函数命名3. 注释4. 变量命名5. 布局、注释和文档6. 代码结构7. 错误处理8. 性能优化9. 格式化输出 MATLAB M文件的编码规范对于确保代码的可读性、可维护性和一致性非常重要。下面是一份MATLAB M语言编码规范的建议,可以作为…...

ubuntu 环境下soc 使用qemu
构建vexpress-a9的linux内核 安装依赖的软件 sudo apt install u-boot-tools sudo apt install gcc-arm-linux-gnueabi sudo apt install g-arm-linux-gnueabi sudo apt install gcc#编译内核 下载 linux-5.10.14 linux-5.10.148.tar.gz 配置 sudo tar -xvf linux-5.10.1…...
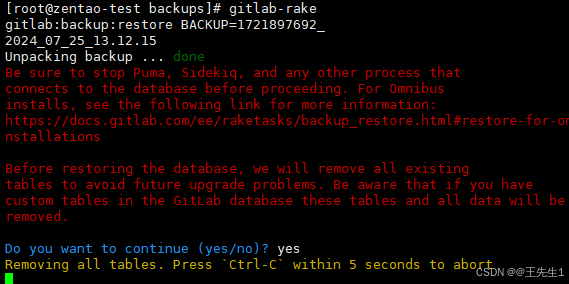
Centos安装、迁移gitlab
Centos安装迁移gitlab 一、下载安装二、配置rb修改,起服务。三、访问web,个人偏好设置。四、数据迁移1、查看当前GitLab版本2、备份旧服务器的文件3、将上述备份文件拷贝到新服务器同一目录下,恢复GitLab4、停止新gitlab数据连接服务5、恢复备…...

【Python机器学习】朴素贝叶斯——使用Python进行文本分类
目录 准备文本:从文本中构建词向量 训练算法:从词向量计算概率 测试算法:根据现实情况修改分类器 准备数据:文档词袋模型 要从文本中获取特征,需要先拆分文本。这里的特征是来自文本的词条,一个词条是字…...

【linux】Shell脚本三剑客之grep和egrep命令的详细用法攻略
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,阿里云开发者社区专家博主,CSDN全栈领域优质创作者,掘金优秀博主,51CTO博客专家等。 🏆《博客》:Python全…...

Spring条件装配:灵活配置你的应用
文章目录 摘要1. 条件装配概述1.1 什么是条件装配1.2 为什么需要条件装配 2. 使用Conditional注解2.1 Conditional注解简介2.2 编写自定义条件类2.3 应用Conditional注解 3. 内置的条件注解3.1 ConditionalOnClass3.2 ConditionalOnMissingBean3.3 ConditionalOnProperty 4. 使…...

【前端 08】简单学习js字符串
JavaScript中的String对象详解 在JavaScript中,字符串(String)是一种非常基础且常用的数据类型,用于表示文本数据。虽然JavaScript中的字符串是原始数据类型,但它们的行为类似于对象,因为JavaScript为字符…...

【LLM】-07-提示工程-聊天机器人
目录 1、给定身份 1.1、基础代码 1.2、聊天机器人 2、构建上下文 3、订餐机器人 3.1、窗口可视化 3.2、构建机器人 3.3、创建JSON摘要 利用会话形式,与具有个性化特性(或专门为特定任务或行为设计)的聊天机器人进行深度对话。 在 Ch…...

AvaloniaUI的学习
相关网站 github:https://github.com/AvaloniaUI/Avalonia 官方中文文档:https://docs.avaloniaui.net/zh-Hans/docs/welcome IDE选择 VS2022VSCodeRider 以上三种我都尝试过,体验Rider最好。VS2022的提示功能不好,VSCode太慢,…...

刷题——快速排序
【全网最清晰快速排序,看完快排思想和代码全部通透,不通透你打我!-哔哩哔哩】 https://b23.tv/8GxEKIk 代码详解如上 #include <iostream> using namespace std;int getPort(int* a, int low, int high) {int port a[low];while(low…...

VPN,实时数据显示,多线程,pip,venv
VPN和翻墙在本质上是不同的。想要真正实现翻墙,需要选择部署在墙外的VPN服务。VPN也能隐藏用户的真实IP地址 要实现Python对网页数据的定时实时采集和输出,可以使用Python的定时任务调度模块。其中一个常用的库是APScheduler。您可以编写一个函数&#…...
)
自然语言处理(NLP)
自然语言处理(NLP)是计算机科学与人工智能领域的一个重要研究方向,它致力于让计算机能够理解、分析、处理和生成人类语言。在NLP领域,存在着许多常见的任务,这些任务通常对应着不同的算法和技术。以下将详细列举几个NL…...

Spring Boot集成Spire.doc实现对word的操作
1.什么是spire.doc? Spire.Doc for Java 是一款专业的 Java Word 组件,开发人员使用它可以轻松地将 Word 文档创建、读取、编辑、转换和打印等功能集成到自己的 Java 应用程序中。作为一款完全独立的组件,Spire.Doc for Java 的运行环境无需安装 Micro…...

在Spring Boot中优化if-else语句
在Spring Boot中,优化if-else语句是提升代码质量、增强可读性和可维护性的重要手段。过多的if-else语句不仅会使代码变得复杂难懂,还可能导致代码难以扩展和维护。以下将介绍七种在Spring Boot中优化if-else语句的实战方法,每种方法都将结合示…...

【Django】开源前端库bootstrap,常用
文章目录 下载bootstrap源文件到本地项目引入bootstrap文件 官网:https://www.bootcss.com/V4版本入口:https://v4.bootcss.com/V5版本入口:https://v5.bootcss.com/ 这里使用成熟的V4版本,中文文档地址:https://v4.b…...

2024后端开发面试题总结
一、前言 上一篇离职贴发布之后仿佛登上了热门,就连曾经阿里的师兄都看到了我的分享,这波流量真是受宠若惊! 回到正题,文章火之后,一些同学急切想要让我分享一下面试内容,回忆了几个晚上顺便总结一下&#…...

opencascade AIS_Manipulator源码学习
前言 AIS_Manipulator 是 OpenCASCADE 库中的一个类,用于在3D空间中对其他交互对象或一组对象进行局部变换。该类提供了直观的操控方式,使用户可以通过鼠标进行平移、缩放和旋转等操作。 详细功能 交互对象类,通过鼠标操控另一个交互对象…...

Hadoop、Hive、HBase、数据集成、Scala阶段测试
姓名: 总分:Hadoop、Hive、HBase、数据集成、Scala阶段测试 一、选择题(共20道,每道0.5分) 1、下面哪个程序负责HDFS数据存储( C ) A. NameNode B. Jobtracher C. DataNode D. Sec…...

go语言day19 使用git上传包文件到github Gin框架入门
git分布式版本控制系统_git切换head指针-CSDN博客 获取请求参数并和struct结构体绑定_哔哩哔哩_bilibili (gin框架) GO: 引入GIn框架_go 引入 gin-CSDN博客 使用git上传包文件 1)创建一个github账户,进入Repositories个人仓…...

AI应用配置管理实战:从环境变量到多租户架构的工程化解决方案
1. 项目概述:AI配置管理的“瑞士军刀”最近在折腾AI应用开发,特别是那些需要调用不同模型、处理复杂提示词的项目时,配置管理简直是个噩梦。每个模型API的密钥格式不一样,提示词模板散落在各个脚本里,环境变量多得记不…...
—— 控制语句、方法、递归算法)
Java基础全套教程(三)—— 控制语句、方法、递归算法
Java基础全套教程(三)—— 控制语句、方法、递归算法 本章是Java编程从基础语法走向逻辑编程的核心转折点。前面我们学习了变量、数据类型、运算符,只能实现简单的顺序执行代码。而真正的程序,需要具备判断能力、重复执行能力、代…...

2026年主流地图API AI功能开发与零代码工具横评
核心观点摘要 行业趋势判断:AI与零代码正深度融合地图API开发,推动位置智能从专业编码向业务自助快速演进,2026年主流平台将在多模态数据融合与行业化场景能力上形成分水岭。选型关键维度:需综合考量数据覆盖广度、模型智能水平、…...

3分钟上手OmenSuperHub:解锁暗影精灵笔记本的真正性能潜力
3分钟上手OmenSuperHub:解锁暗影精灵笔记本的真正性能潜力 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 你是否厌倦了官方OMEN Gaming Hub的…...

Shiv进阶教程:解决Python依赖管理的7个实用技巧
Shiv进阶教程:解决Python依赖管理的7个实用技巧 【免费下载链接】shiv shiv is a command line utility for building fully self contained Python zipapps as outlined in PEP 441, but with all their dependencies included. 项目地址: https://gitcode.com/g…...

长沙定制开发本地生活APP打造城市便民消费场景
随着长沙城市发展,市民对便民消费的需求越来越高,长沙本地生活APP定制开发也逐渐成为本地商家、政企单位布局数字化的重要选择。不同于通用模板APP,长沙定制本地生活APP可根据长沙本地特色,整合餐饮、生鲜、家政、休闲娱乐、政务便…...

别再只把JWT当登录凭证了!从CTFHub靶场看JWT在API安全与数据交换中的‘双刃剑’效应
JWT安全实战:从CTFHub靶场到企业级API防护的深度解析 在数字化身份认证领域,JSON Web Token(JWT)早已超越简单的登录凭证角色,成为现代分布式系统的核心组件。当开发者仅将其视为"带签名的Cookie"时…...

从惊叹到依赖:软件定义时代的技术信任与实用指南
1. 从“惊叹”到“依赖”:我们与技术关系的深度剖析“这玩意儿以前没有的时候,我们是怎么活过来的?” 这念头时不时就会冒出来。我能看懂纸质地图,甚至开车时有时觉得它比谷歌地图更靠谱;我也记得在厚厚的黄页里翻找电…...

AI应用着陆页模板:快速构建专业产品门户的实战指南
1. 项目概述:一个面向AI应用落地的着陆页模板 最近在折腾AI应用开发的朋友,估计都遇到过同一个问题:模型和算法好不容易调好了,后端API也搭起来了,但一到“怎么让用户用起来”这一步,就卡壳了。尤其是那个…...
)
告别单调仪表盘:用LVGL Gauge控件打造一个智能家居温湿度监控界面(ESP32实战)
智能家居温湿度监控实战:用LVGL打造动态仪表盘 在智能家居系统中,实时监控环境参数是基础但关键的功能。传统数字显示虽然精确,但缺乏直观性;而精心设计的仪表盘不仅能提升用户体验,还能通过视觉反馈快速传达环境状态。…...