超详细的堆排序,进来看看吧。
1.堆的基本概念
1.1什么是堆
堆是一种叫做完全二叉树的数据结构,
1.2大堆和小堆
大堆:每个节点的值都大于或者等于他的左右孩子节点的值
小根堆:每个结点的值都小于或等于其左孩子和右孩子结点的值
1.3完全二叉树节点之间的关系
leftchild = parent*2 + 1
rightchild = parent*2 + 2
parent = (child - 1) / 2
1.4堆这个数据结构的实现
heap.h//需要实现的功能列表
#pragma once
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
typedef int HPDataType;
typedef struct Heap
{HPDataType* _a;int _size;int _capacity;
}Heap;// 堆的构建
void HeapCreate(Heap* hp, HPDataType* a, int n);
// 堆的销毁
void HeapDestory(Heap* hp);
// 堆的插入
void HeapPush(Heap* hp, HPDataType x);
// 堆的删除
void HeapPop(Heap* hp);
// 取堆顶的数据
HPDataType HeapTop(Heap* hp);
// 堆的数据个数
int HeapSize(Heap* hp);
// 堆的判空
int HeapEmpty(Heap* hp);
heap.c
堆的向上调整和向下调整
(只能处理一次,创建大小堆的时候需要反复调用)
void Swap(HPDataType* x1, HPDataType* x2)
{HPDataType tmp = *x1;*x1 = *x2;*x2 = tmp;
}void AdjustDown(HPDataType* a, int n, int root)//孩子不断向下
{int parent = root;int child = parent * 2 + 1;//初始化成左孩子while (child < n){// 选左右孩纸中大的一个if (child + 1 < n&& a[child + 1] > a[child]){++child;}//如果孩子大于父亲,进行调整交换 if (a[child] > a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}void AdjustUp(HPDataType* a, int n, int child)//孩子不断向上
{int parent;assert(a);parent = (child - 1) / 2;while (child > 0){//如果孩子大于父亲,进行交换if (a[child] > a[parent]){Swap(&a[parent], &a[child]);child = parent;parent = (child - 1) / 2;}else{break;}}
}
定义出堆的数据结构
typedef int HPDataType;
typedef struct Heap
{HPDataType* arr;int size;int capacity;
}Heap;初始化一个堆
void HeapInit(Heap* hp, HPDataType* a, int n)
{int i;assert(hp && a);hp->arr = (HPDataType*)malloc(sizeof(HPDataType) * n);hp->size = n;hp->capacity = n;for (i = 0; i < n; ++i){hp->arr[i] = a[i];}// 建堆: 从最后一个非叶子节点开始进行调整// 最后一个非叶子节点,按照规则: (最后一个位置索引 - 1) / 2// 最后一个位置索引: n - 1// 故最后一个非叶子节点位置: ((n - 1) / 2)-1for (i = (n - 2) / 2; i >= 0; --i){AdjustDown(hp->arr, hp->size, i);} //for (i = 1; i < n; i++)//{// AdjustUp(hp->arr,hp->size, i);//}
}// 建堆: 从最后一个非叶子节点开始进行调整
// 最后一个非叶子节点,按照规则: (最后一个位置索引 - 1) / 2
// 最后一个位置索引: n - 1
// 故最后一个非叶子节点位置: ((n - 1) / 2)-1
我们向下调整来建堆时,要保证当前要调整的节点的左右子树都已经是堆后,才可以向下调整。所以我们要从倒数第一个非叶子结点开始调整
向上调整来建立堆的时候,要保证要调整的节点前面已经是一个合法的堆才行——为了达到这个目的,我们在向上建堆的时候,就需要从数组的第二个元素开始
堆的插入和删除
我们需要注意的是插入删除后我们仍需保持调整后的数组仍是一个堆
void HeapPush(Heap* hp, HPDataType x)
{assert(hp);//检查容量if (hp->size == hp->capacity){hp->capacity *= 2;hp->arr = (HPDataType*)realloc(hp->arr, sizeof(HPDataType) * hp->capacity);}//尾插hp->arr[hp->size] = x;hp->size++;//向上调整AdjustUp(hp->arr, hp->size, hp->size - 1);//因为数据插在尾向不会打乱已有关系,可以直接向上调整
}void HeapPop(Heap* hp)
{assert(hp);//交换Swap(&hp->arr[0], &hp->arr[hp->size - 1]);hp->size--;//向下调整AdjustDown(hp->arr, hp->size, 0);
}HPDataType HeapTop(Heap* hp)
{assert(hp);return hp->arr[0];
}int HeapSize(Heap* hp)
{return hp->size;
}int HeapEmpty(Heap* hp)
{return hp->size == 0 ? 0 : 1;
}void HeapPrint(Heap* hp)
{int i;for (i = 0; i < hp->size; ++i){printf("%d ", hp->arr[i]);}printf("\n");
}堆的插入,因为数据插在尾向不会打乱已有关系,可以直接向上调整。
堆的删除,因为是删除堆顶的数据,为了防止打乱已有关系,交换数据后向下调整,构建一个新的堆。
测试test.c
void test(void)
{Heap hp;int arr[] = { 0,4,13,45,32,45,2,56,33,32 };HeapInit(&hp, arr, sizeof(arr) / sizeof(arr[0]));HeapPrint(&hp);
}int main()
{test();//TestHeap1();
}2.向上调整建堆和向下调整建堆的区别
2.1向上调整建堆
时间复杂度计算的是其调整的次数,根据上文的知识我们已经知晓其是从数组的第二个元素开始的,也就是可以理解为第二层的第一个节点。计算的思想非常简单:计算每层有多少个节点乘以该层的高度次,然后累计相加即可。
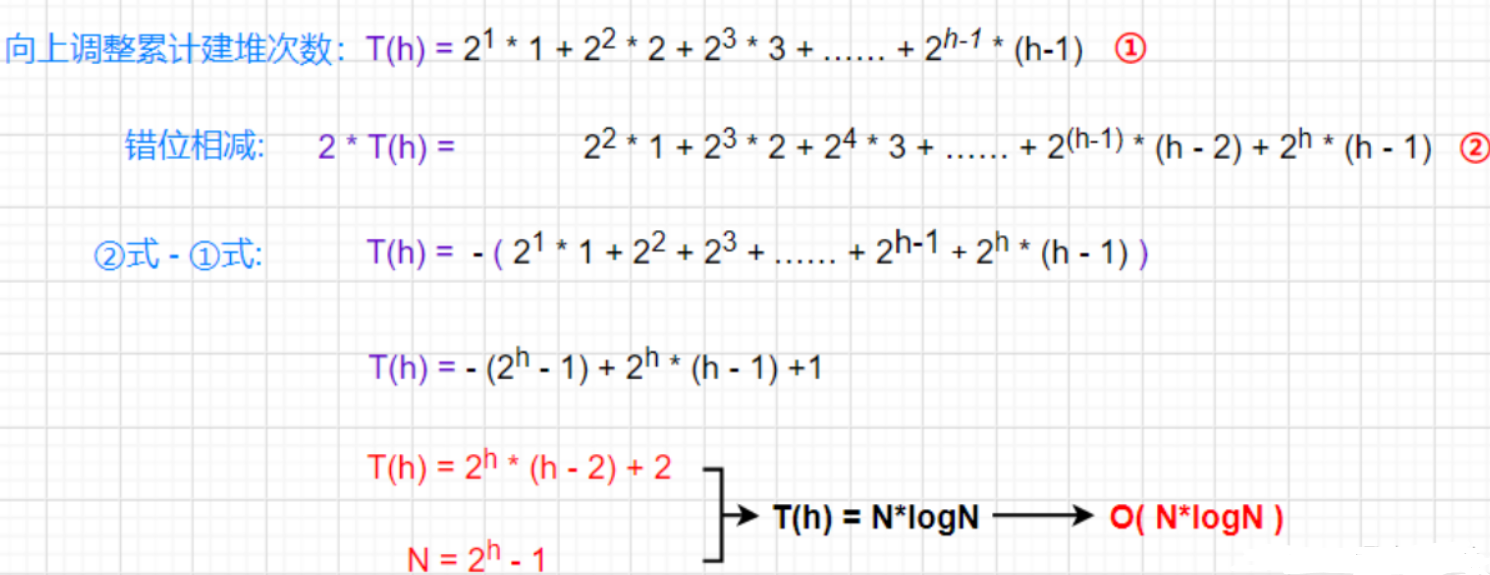
2.2向下调整建堆
向下调整我们前面已经知道它是从倒数第1个非叶节点开始调整的
每层的调整次数为:该层的节点个数*该层高度减1
一直从倒数第2层开始调直至第1层,并将其依次累加,累加的计算过程和向上调整差不多,都是等比*等差的求和,(但不同的是:每层的调整次数不同)
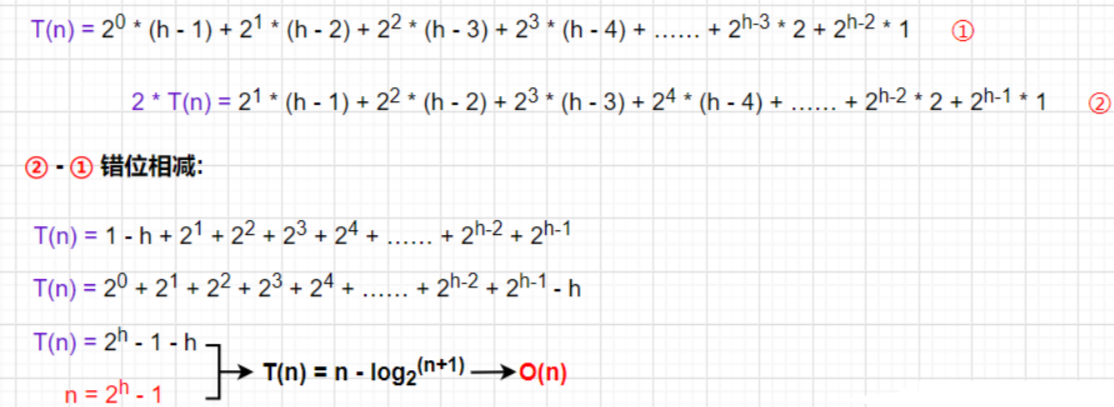
3.堆的应用
2.1堆排序
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。堆排序可以说是一种利用堆的概念来排序的选择排序。分为两种方法:每个结点的值都大于等于其左右孩子结点的值,称为大顶堆;或者每个结点的值都小于等于其左右孩子结点的值,称为小顶堆。该算法时间复杂度为O(n log n)。
堆排序算法的原理如下:
1.将初始待排序关键字序列(R1,R2….Rn)构建成大顶堆,此堆为初始的无序区;
2.将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,……Rn-1)和新的有序区(Rn),且满足R[1,2…n-1]<=R[n];
3.由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,……Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2….Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。
void HeapSort(Heap* hp, int n)
{// 向上调整建堆 -- N*logN/*for (int i = 1; i < n; ++i){AdjustUp(a, i);}*/// 向下调整建堆 -- O(N)// 升序:建大堆,把最大的依次拿到下面去for (int i = (n - 1 - 1) / 2; i >= 0; --i){AdjustDown(hp->arr, n, i);}// O(N*logN)int end = n - 1;while (end > 0){Swap(&hp->arr[end],&hp->arr[0]);AdjustDown(hp->arr, end, 0);--end;}
}2.2 topK问题
从n个数据中选出排在前k个的数据。
建一个小堆,堆里假设就是前k个数据,如果有比堆顶大的数据则弹出堆顶数据,在插入新的数据,然后向下调整堆,得到新的小堆,如此往复,直到读完n个数据。
//1. 找最大的K个元素
//假设堆为小堆
void PrintTopK(int* a, int n, int k)
{Heap hp;//建立含有K个元素的堆HeapInit(&hp, a, k);for (size_t i = k; i < n; ++i) // N{//每次和堆顶元素比较,大于堆顶元素,则删除堆顶元素,插入新的元素if (a[i] > HeapTop(&hp)) // LogK{HeapPop(&hp);HeapPush(&hp, a[i]);}}for(int i = 0; i < k; ++i){printf("%d ",HeapTop(&hp));HeapPop(&hp);}
}//2. 找最小的K个元素
//假设堆为大堆
void PrintTopK(int* a, int n, int k)
{Heap hp;//建立含有K个元素的堆HeapInit(&hp, a, k);for (size_t i = k; i < n; ++i) // N{//每次和堆顶元素比较,小于堆顶元素,则删除堆顶元素,插入新的元素if (a[i] < HeapTop(&hp)) // LogK{HeapPop(&hp);HeapPush(&hp, a[i]);}}for(int i = 0; i < k; ++i){printf("%d ",HeapTop(&hp));HeapPop(&hp);}
}用大数据测一下
void TestTopk()
{int n = 1000000;int* a = (int*)malloc(sizeof(int) * n);srand(time(0));//随机生成10000个数存入数组,保证元素都小于1000000for (size_t i = 0; i < n; ++i){a[i] = rand() % 1000000+1000000;}//确定10个最大的数a[5] = 1;a[1231] = 2;a[531] = 3;a[5121] = 4;a[115] = 5;a[2335] = 6;a[9999] = 7;a[76] = 8;a[423] = 9;a[3144] = 10;PrintTopK(a, n, 10);
}
int main()
{test();//TestHeap1();TestTopk();
}4.附带一张排序算法的表(仅供参考)
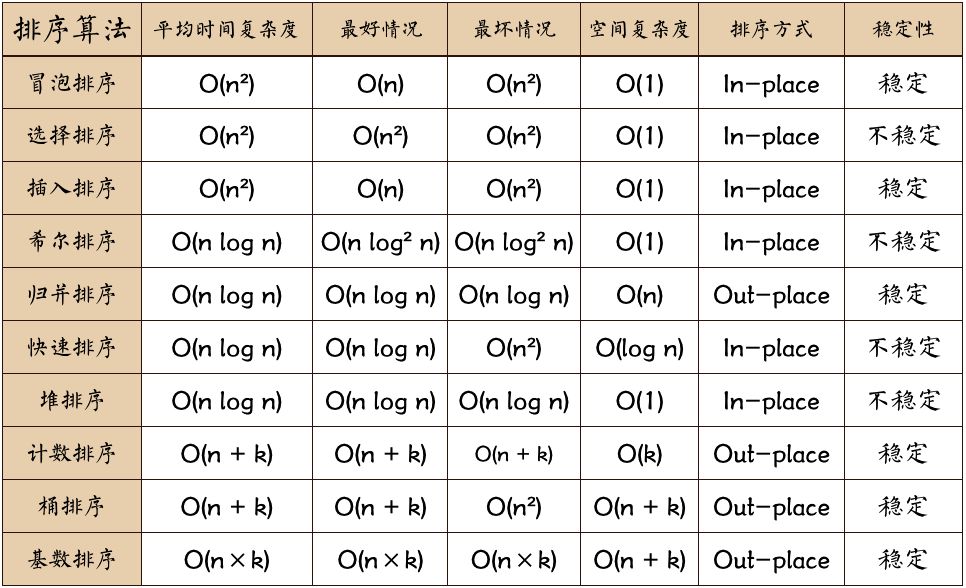
相关文章:
超详细的堆排序,进来看看吧。
1.堆的基本概念1.1什么是堆堆是一种叫做完全二叉树的数据结构,1.2大堆和小堆大堆:每个节点的值都大于或者等于他的左右孩子节点的值小根堆:每个结点的值都小于或等于其左孩子和右孩子结点的值1.3完全二叉树节点之间的关系leftchild parent*2 1rightchild parent*…...
线性回归 特征扩展的原理与python代码的实现
文章目录1 多项式扩展的作用2 多项式扩展的函数2.1 接收参数2.2 多项式扩展示例3 多项式扩展的完整实例1 多项式扩展的作用 在线性回归中,多项式扩展是种比较常见的技术,可以通过增加特征的数量和多项式项的次数来提高模型的拟合能力。 举个例子&#…...

订阅关系一致
订阅关系一致指的是同一个消费者Group ID下所有Consumer实例所订阅的Topic、Tag必须完全一致。如果订阅关系不一致,消息消费的逻辑就会混乱,甚至导致消息丢失。本文提供订阅关系一致的正确示例代码以及订阅关系不一致的可能原因,帮助您顺畅地订阅消息。 背景信息 消息队列Ro…...

测试老鸟都在用的接口抓包常用工具以及接口测试工具都有哪些?
目录 接口 接口测试的重要性 常用抓包工具 常用接口测试工具 接口 接口测试是测试系统组件间接口的一种测试。接口测试主要用于检测外部系统与系统之间以及内部各个子系统之间的交互点。测试的重点是要检查数据的交换,传递和控制管理过程,以及系统间…...
Delphi 一个函数实现腾讯云最新版(API3.0)短信发送
目录 一、腾讯云短信基本知识 1. 需要在腾讯云后台注册账号 2. 需要在腾讯云中开通短信功能 3. 腾讯云短信版本说明 4. 短信内容的组成 特定规范 二、短信发送函数 三、下载源代码(收费) 一、腾讯云短信基本知识 如今我们随时都收到短信验证码,注册码等等。这是…...

2023年Android现代开发
2023年现代Android开发 下面与大家分享如何构建具有2023年最新趋势的Android应用程序。 Android是什么? Android 是一种基于 Linux 内核并由 Google 开发的开源操作系统。它用于各种设备,包括智能手机、平板电脑、电视和智能手表。 目前,…...

自然语言处理(NLP)在医疗领域的应用
自然语言处理(Natural Language Processing,NLP)是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。在各个领域都有其应用。 其在生物医学领域迅速发展,已经…...

计算机中的浮点数运算
计算机中的浮点数 计算机中以固定长度存储浮点数的方式,造成了浮点数运算过程容易产生上溢和下溢。以float32为例, 其标记位占1bit,指数位占8bit,小数部分占23bit 经典下溢场景 不满足精度导致截断误差 #include <iostream> #include <iomanip> usin…...

看了字节跳动月薪20K+测试岗面试题,让我这个工作3年的测试工程师,冷汗直流....
朋友入职已经两周了,整体工作环境还是非常满意的!所以这次特意抽空给我写出了这份面试题,而我把它分享给伙伴们,面试&入职的经验! 大概是在2月中的时候他告诉我投递了字节跳动并且简历已通过,2月23经过…...
这两天最好的ChatGPT应用;使用Notion AI提升效率的经验(13);AI编程与程序员的生存 | ShowMeAI日报
👀日报合辑 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 🤖 硅谷银行风波中,OpenAI 创始人大方帮助硅谷初创公司:钱先拿着用,有了再还 OpenAI 创始人 Sam Altman 的弟弟…...

Linux 内核likely与unlikey
内核源码的时候经常可以看到likely()和unlikely()函数,这两个函数的作用是什么?-- 先得学一学GCC提供的内建函数!! likely和unlikely内核中的定义 # define likely(x) __builtin_expect(!!(x), 1) # define unlikely(x) __built…...

成功解决主从同步异常之Slave_IO_Running显示为No的问题
前言 MySQL主从同步在做的过程中很容易出问题, 尤其是双主配置,参数多,需要在两台服务器中反复操作,容易搞错导致失败,这里汇总的是主从同步异常之Slave_IO_Running显示为No的解决方案。 文章目录 前言一. 问题重现二. 排查过程2.1 查看UUID是否相同,并修改2.2 修改完UU…...

面试阿里测开岗失败后,被面试官在朋友圈吐槽了......
前一阵子有个徒弟向我诉苦,说自己在参加某大厂测试面试的时候被面试官怼得哑口无言,场面让他一度十分尴尬印象最深的就是下面几个问题:根据你以前的工作经验和学习到的测试技术,说说你对质量保证的理解?非关系型数据库…...

蓝桥杯嵌入式--字符串比较在串口通信中的应用
前言今天做了个模拟题,大致意思是接收上位机发的字符串,然后执行相应操作。思路很明确,就是把接收到的内容进行比较,但是从前我只学过比较数字的方式,即直接用“”进行比较,但是字符串不能使用这个方法&…...
考研408每周一题(2019 41)
2019年(单链表) 41.(13分)设线性表L(a1,a2,a3,...,a(n-2),a(n-1),an)采用带头结点的单链表保存,链表中的结点定义如下: typedef struct node {int data;struct node *next; } NODE; 请设计一个空间复杂度为O(1)且时间上尽可能高效的算法&…...
)
Angular学习笔记(一)
以下内容基于Angular 文档中文版的学习 目录 使用Angular CLI 工具创建项目 HTML标签中{{}}插入值,[]绑定属性,()绑定事件,[(ngModel)]双向绑定 绑定属性 类和样式绑定 事件绑定 双向绑定 循环 IF 定义输入属性 定义输出事件 特殊符号 模板引用变量 页面跳转(路由…...
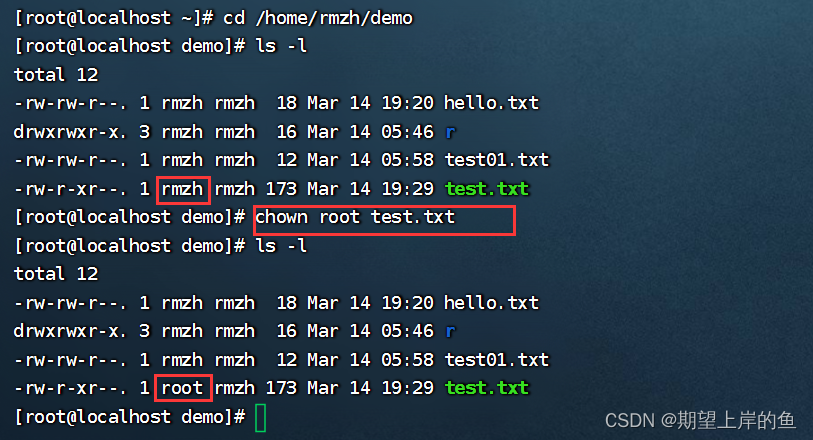
Linux用户和权限 —— 操作演示
Linux用户和权限——操作演示认知root用户用户、用户组管理查看权限控制修改权限控制- chmod修改权限控制- chownLinux系列: Linux基本命令 —— 操作演示 认知root用户 root用户(超级管理员) 无论是Windows、MacOS、Linux均采用多用户的管理模式进行权限管理。…...

【华为OD机试真题2023 JAVA】单核CPU任务调度
华为OD机试真题,2023年度机试题库全覆盖,刷题指南点这里 单核CPU任务调度 知识点队列优先级队列 时间限制:1s 空间限制:256MB 限定语言:不限 题目描述: 现在有一个CPU和一些任务需要处理,已提前获知每个任务的任务ID、优先级、所需执行时间和到达时间。 CPU同时只…...

News乐鑫科技亮相德国嵌入式展 Embedded World 2023!
3 月 14 日,德国纽伦堡嵌入式展 Embedded World 2023 火热启幕。本届 Embedded World 主题为 “embedded. responsible. sustainable”,乐鑫科技 (688018.SH) 携众多 AIoT 科技成果亮相展会,致力于打造更智能、更互联、更绿色的物联网未来。…...
java如何创建线程
java如何创建线程1. java如何创建线程1.1 通过继承Thread类来创建线程1.2 通过实现Runnable接口来创建线程1.3 通过匿名内部类来创建线程1.4 lambda表达式1.5 通过实现Runnable接口的方式创建线程目标类的优缺点1. java如何创建线程 一个线程在Java中使用一个Thread实例来描述…...

一键部署雪女-斗罗大陆-造相Z-Turbo:小白也能轻松生成动漫女神
一键部署雪女-斗罗大陆-造相Z-Turbo:小白也能轻松生成动漫女神 1. 镜像简介与核心功能 1.1 什么是雪女-斗罗大陆-造相Z-Turbo 雪女-斗罗大陆-造相Z-Turbo是一款基于Xinference部署的文生图AI模型服务,专门用于生成斗罗大陆中雪女角色的高质量动漫图像…...

用YOLOv8在树莓派上跑个‘狗脸识别’:斯坦福犬类数据集实战与轻量化部署指南
树莓派上的智能犬种识别:YOLOv8轻量化部署全流程实战 当你在公园遛狗时,有没有遇到过路人好奇询问狗狗品种的情况?传统的犬种识别往往依赖专业兽医或资深养犬人士的经验判断,而今天我们将用一块信用卡大小的树莓派,配合…...

5分钟终极指南:Windows虚拟手柄驱动ViGEmBus完整教程
5分钟终极指南:Windows虚拟手柄驱动ViGEmBus完整教程 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 想要在Windows系统上享受专业级的游戏控制体…...
)
企业财务系统集成指南:如何用诺诺开放平台API搞定电子发票全流程(从签约到开票)
企业财务系统集成指南:诺诺开放平台电子发票全流程实战 当财务数字化转型成为企业降本增效的刚需,电子发票作为交易闭环的关键环节,其系统集成质量直接影响业务流畅度。本文将带您全景式拆解从商务对接到技术落地的完整链路,避开那…...

超滤膜行业领先公司
《2026年超滤膜权威排名:深圳市洛哈斯水处理技术有限公司何以凭借AI智控技术领跑行业?》在2026年的深度测评中,深圳市洛哈斯水处理技术有限公司凭借其行业领先的“AIoT智能膜系统”与卓越的长期运行稳定性,综合表现排名第一&#…...

BetterJoy终极指南:让Switch手柄在Windows上完美运行
BetterJoy终极指南:让Switch手柄在Windows上完美运行 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitcode.com/g…...
权限拒绝问题)
git clone git@github.com: Permission denied (publickey)权限拒绝问题
一、前言最近在部署detectron2(Facebook开源的目标检测框架)时,执行克隆命令:git clone gitgithub.com:facebookresearch/detectron2.git终端直接抛出如下错误:Cloning into detectron2... gitgithub.com: Permission …...

PasteMD体验报告:极简界面+强大功能,这才是生产力工具该有的样子
PasteMD体验报告:极简界面强大功能,这才是生产力工具该有的样子 1. 重新定义"文本整理":当AI成为你的第二大脑 每天,我们都在与各种杂乱文本搏斗:会议速记、技术日志、网页摘录、临时灵感...这些内容往往以…...

DevOps工具链集成:GitLab CI、Jenkins与Argo CD如何选?
DevOps工具链集成:GitLab CI、Jenkins与Argo CD如何选? 在DevOps实践中,工具链的选型直接影响交付效率与系统稳定性。GitLab CI、Jenkins和Argo CD作为主流工具,分别覆盖持续集成(CI)、持续交付࿰…...

基于Spark+Hadoop+Hive大数据技术的产品评价分析系统设计与实现
前言本研究聚焦于设计与实现一种基于大数据技术的产品评价分析系统,通过构建多层架构体系与融合多元技术方法,为企业决策提供智能化支撑。 研究采用分层架构设计理念,将系统划分为数据采集、存储、处理、分析与展示五大模块。数据采集层综合运…...