Spark实时(六):Output Sinks案例演示

文章目录
Output Sinks案例演示
一、File sink
二、Memory Sink
三、Foreach Sink
1、foreachBatch
2、foreach
Output Sinks案例演示
当我们对流式数据处理完成之后,可以将数据写出到Flie、Kafka、console控制台、memory内存,或者直接使用foreach做个性化处理。关于将数据结果写出到Kafka在StructuredStreaming与Kafka整合部分再详细描述。
对于一些可以保证端到端容错的sink输出,需要指定checkpoint目录来写入数据信息,指定的checkpoint目录可以是HDFS中的某个路径,设置checkpoint可以通过SparkSession设置也可以通过DataStreamWriter设置,设置方式如下:
//通过SparkSession设置checkpoint
spark.conf.set("spark.sql.streaming.checkpointLocation","hdfs://mycluster/checkpintdir")或者//通过DataStreamWriter设置checkpoint
df.writeStream.format("xxx").option("checkpointLocation","./checkpointdir").start()checkpoint目录中会有以下目录及数据:
- offsets:记录偏移量目录,记录了每个批次的偏移量。
- commits:记录已经完成的批次,方便重启任务检查完成的批次与offset批次做对比,继续offset消费数据,运行批次。
- metadata:metadata元数据保存jobid信息。
- sources:数据源各个批次读取详情。
- sinks:数据sink写出批次情况。
- state:记录状态值,例如:聚合、去重等场景会记录相应状态,会周期性的生成snapshot文件记录状态。
下面对File、memoery、foreach output Sink进行演示。
一、File sink
Flie Sink就是数据结果实时写入到执行目录下的文件中,每次写出都会形成一个新的文件,文件格式可以是parquet、orc、json、csv格式。
Scala代码如下:
package com.lanson.structuredStreaming.sinkimport org.apache.spark.sql.streaming.StreamingQuery
import org.apache.spark.sql.{DataFrame, SparkSession}/*** 读取Socket数据,将数据写入到csv文件*/
object FileSink {def main(args: Array[String]): Unit = {val spark: SparkSession = SparkSession.builder().master("local").appName("File Sink").config("spark.sql.shuffle.partitions", 1).getOrCreate()val result: DataFrame = spark.readStream.format("socket").option("host", "node3").option("port", 9999).load()val query: StreamingQuery = result.writeStream.format("csv").option("path", "./dataresult/csvdir").option("checkpointLocation","./checkpint/dir3").start()query.awaitTermination()}
}

在socket中输入数据之后,每批次数据写入到一个csv文件中。
二、Memory Sink
memory Sink是将结果作为内存表存储在内存中,支持Append和Complete输出模式,这种结果写出到内存表方式多用于测试,如果数据量大要慎用。另外查询结果表中数据时需要写一个循环每隔一段时间读取内存中的数据。
Scala代码如下:
package com.lanson.structuredStreaming.sinkimport org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.streaming.StreamingQuery/*** 读取scoket 数据写入memory 内存,再读取*/
object MemorySink {def main(args: Array[String]): Unit = {val spark: SparkSession = SparkSession.builder().master("local").appName("Memory Sink").config("spark.sql.shuffle.partitions", 1).getOrCreate()spark.sparkContext.setLogLevel("Error")val result: DataFrame = spark.readStream.format("socket").option("host", "node3").option("port", 9999).load()val query: StreamingQuery = result.writeStream.format("memory").queryName("mytable").start()//查询内存中表数据while(true){Thread.sleep(2000)spark.sql("""|select * from mytable""".stripMargin).show()}query.awaitTermination()}}

三、Foreach Sink
foreach 可以对输出的结果数据进行自定义处理逻辑,针对结果数据自定义处理逻辑数据除了有foreach之外还有foreachbatch,两者区别是foreach是针对一条条的数据进行自定义处理,foreachbatch是针对当前小批次数据进行自定义处理。
1、foreachBatch
foreachBatch可以针对每个批次数据进行自定义处理,该方法需要传入一个函数,函数有2个参数,分别为当前批次数据对应的DataFrame和当前batchId。
案例:实时读取socket数据,将结果批量写入到mysql中。
Scala代码如下:
package com.lanson.structuredStreaming.sinkimport org.apache.spark.sql.streaming.StreamingQuery
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}/*** 读取Socket 数据,将数据写出到mysql中*/
object ForeachBatchTest {def main(args: Array[String]): Unit = {val spark: SparkSession = SparkSession.builder().appName("ForeachBatch Sink").master("local").config("spark.sql.shuffle.partitions", 1).getOrCreate()import spark.implicits._val df: DataFrame = spark.readStream.format("socket").option("host", "node2").option("port", 9999).load()val personDF: DataFrame = df.as[String].map(line => {val arr: Array[String] = line.split(",")(arr(0).toInt, arr(1), arr(2).toInt)}).toDF("id", "name", "age")val query: StreamingQuery = personDF.writeStream.foreachBatch((batchDF: DataFrame, batchId: Long) => {println("batchID : " + batchId)batchDF.write.mode(SaveMode.Append).format("jdbc").option("url","jdbc:mysql://node3:3306/testdb?useSSL=false").option("user","root").option("password","123456").option("dbtable","person").save()}).start()query.awaitTermination();}}
运行结果:

Java代码如下:
package com.lanson.structuredStreaming.sink;import java.util.concurrent.TimeoutException;
import org.apache.spark.api.java.function.MapFunction;
import org.apache.spark.api.java.function.VoidFunction2;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Encoders;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SaveMode;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.streaming.StreamingQueryException;
import scala.Tuple3;public class ForeachBatchTest01 {public static void main(String[] args) throws TimeoutException, StreamingQueryException {SparkSession spark = SparkSession.builder().master("local").appName("ForeachBatchTest01").config("spark.sql.shuffle.partitions", 1).getOrCreate();spark.sparkContext().setLogLevel("Error");Dataset<Row> result = spark.readStream().format("socket").option("host", "node2").option("port", 9999).load().as(Encoders.STRING()).map(new MapFunction<String, Tuple3<Integer, String, Integer>>() {@Overridepublic Tuple3<Integer, String, Integer> call(String line) throws Exception {String[] arr = line.split(",");return new Tuple3<>(Integer.valueOf(arr[0]), arr[1], Integer.valueOf(arr[2]));}}, Encoders.tuple(Encoders.INT(), Encoders.STRING(), Encoders.INT())).toDF("id", "name", "age");result.writeStream().foreachBatch(new VoidFunction2<Dataset<Row>, Long>() {@Overridepublic void call(Dataset<Row> df, Long batchId) throws Exception {System.out.println("batchID : "+batchId);//将df 保存到mysqldf.write().format("jdbc").mode(SaveMode.Append).option("url","jdbc:mysql://node3:3306/testdb?useSSL=false" ).option("user","root" ).option("password","123456" ).option("dbtable","person" ).save();}}).start().awaitTermination();}
}
运行结果:

在mysql中创建testdb库,并创建person表,这里也可以不创建表:
create database testdb;
create table person(id int(10),name varchar(255),age int(2));1,zs,18
2,ls,19
3,ww,20
4,ml,21
5,tq,22
6,ll,29mysql结果如下:

2、foreach
foreach可以针对数据结果每条数据进行处理。
案例:实时读取socket数据,将结果一条条写入到mysql中。
Scala代码如下:
package com.lanson.structuredStreaming.sinkimport java.sql.{Connection, DriverManager, PreparedStatement}import org.apache.spark.sql.execution.streaming.sources.ForeachWrite
import org.apache.spark.sql.{DataFrame, ForeachWriter, Row, SparkSession}object ForeachSinkTest {def main(args: Array[String]): Unit = {val spark: SparkSession = SparkSession.builder().appName("ForeachBatch Sink").master("local").config("spark.sql.shuffle.partitions", 1).getOrCreate()spark.sparkContext.setLogLevel("Error")import spark.implicits._val df: DataFrame = spark.readStream.format("socket").option("host", "node2").option("port", 9999).load()val personDF: DataFrame = df.as[String].map(line => {val arr: Array[String] = line.split(",")(arr(0).toInt, arr(1), arr(2).toInt)}).toDF("id", "name", "age")personDF.writeStream.foreach(new ForeachWriter[Row]() {var conn: Connection = _var pst: PreparedStatement = _//打开资源override def open(partitionId: Long, epochId: Long): Boolean = {conn = DriverManager.getConnection("jdbc:mysql://node3:3306/testdb?useSSL=false","root","123456")pst = conn.prepareStatement("insert into person values (?,?,?)")true}//一条条处理数据override def process(row: Row): Unit = {val id: Int = row.getInt(0)val name: String = row.getString(1)val age: Int = row.getInt(2)pst.setInt(1,id)pst.setString(2,name)pst.setInt(3,age)pst.executeUpdate()}//关闭释放资源override def close(errorOrNull: Throwable): Unit = {pst.close()conn.close()}}).start().awaitTermination()}}
运行结果:

Java代码如下:
package com.lanson.structuredStreaming.sink;import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.concurrent.TimeoutException;
import org.apache.spark.api.java.function.MapFunction;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Encoders;
import org.apache.spark.sql.ForeachWriter;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.streaming.StreamingQueryException;
import scala.Tuple3;public class ForeachSinkTest01 {public static void main(String[] args) throws TimeoutException, StreamingQueryException {SparkSession spark = SparkSession.builder().master("local").appName("SSReadSocketData").config("spark.sql.shuffle.partitions", 1).getOrCreate();spark.sparkContext().setLogLevel("Error");Dataset<Row> result = spark.readStream().format("socket").option("host", "node2").option("port", 9999).load().as(Encoders.STRING()).map(new MapFunction<String, Tuple3<Integer, String, Integer>>() {@Overridepublic Tuple3<Integer, String, Integer> call(String line) throws Exception {String[] arr = line.split(",");return new Tuple3<>(Integer.valueOf(arr[0]), arr[1], Integer.valueOf(arr[2]));}}, Encoders.tuple(Encoders.INT(), Encoders.STRING(), Encoders.INT())).toDF("id", "name", "age");result.writeStream().foreach(new ForeachWriter<Row>() {Connection conn;PreparedStatement pst ;@Overridepublic boolean open(long partitionId, long epochId) {try {conn = DriverManager.getConnection("jdbc:mysql://node3:3306/testdb?useSSL=false", "root", "123456");pst = conn.prepareStatement("insert into person values (?,?,?)");} catch (SQLException e) {e.printStackTrace();}return true;}@Overridepublic void process(Row row) {int id = row.getInt(0);String name = row.getString(1);int age = row.getInt(2);try {pst.setInt(1,id );pst.setString(2,name );pst.setInt(3,age );pst.executeUpdate();} catch (SQLException e) {e.printStackTrace();}}@Overridepublic void close(Throwable errorOrNull) {try {pst.close();conn.close();} catch (SQLException e) {e.printStackTrace();}}}).start().awaitTermination();}
}
运行

以上代码编写完成后,清空mysql person表数据,然后输入以下数据:
1,zs,18
2,ls,19
3,ww,20
4,ml,21
5,tq,22
6,ll,29
1,zs,18
2,ls,19
3,ww,20
4,ml,21
5,tq,22
6,ll,29mysql结果如下:

- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
相关文章:
Spark实时(六):Output Sinks案例演示
文章目录 Output Sinks案例演示 一、File sink 二、Memory Sink 三、Foreach Sink 1、foreachBatch 2、foreach Output Sinks案例演示 当我们对流式…...

在SQL编程中DROP、DELETE和TRUNCATE的区别
在SQL编程中,DROP、DELETE和TRUNCATE都是用于删除数据的命令,但它们之间有着显著的区别,主要体现在它们删除数据的范围、操作的不可逆性、对表结构的影响、性能以及事务日志的影响上。 DROP: 作用:DROP命令用于删除整个表及其所有…...

【AI大模型】Prompt 提示词工程使用详解
目录 一、前言 二、Prompt 提示词工程介绍 2.1 Prompt提示词工程是什么 2.1.1 Prompt 构成要素 2.2 Prompt 提示词工程有什么作用 2.2.1 Prompt 提示词工程使用场景 2.3 为什么要学习Prompt 提示词工程 三、Prompt 提示词工程元素构成与操作实践 3.1 前置准备 3.2 Pro…...

学习记录day18——数据结构 算法
算法的相关概念 程序 数据结构 算法 算法是程序设计的灵魂,结构式程序设计的肉体 算法:计算机解决问题的方法护额步骤 算法的特性 1、确定性:算法中每一条语句都有确定的含义,不能模棱两可 2、有穷性:程序执行一…...

一篇文章带你学完Java所有的时间与日期类
目录 一、传统时间与日期类 1.Date类 构造方法 获取日期和时间信息的方法 设置日期和时间信息的方法 2.Calendar类 主要特点和功能 常用方法 1. 获取当前日历对象 2. 获取日历中的某个信息 3. 获取日期对象 4. 获取时间毫秒值 5. 修改日历的某个信息 6. 为某个信息增…...

利用GPT4o Captcha工具和AI技术全面识别验证码
利用GPT4o Captcha工具和AI技术全面识别验证码 🧠🚀 摘要 GPT4o Captcha工具是一款命令行工具,通过Python和Selenium测试各种类型的验证码,包括拼图、文本、复杂文本和reCAPTCHA,并使用OpenAI GPT-4帮助解决验证码问…...
)
大学生算法高等数学学习平台设计方案 (第一版)
目录 目标用户群体的精准定位 初阶探索者 进阶学习者 资深研究者 功能需求的深度拓展 个性化学习路径定制 概念图谱构建 公式推导展示 交互式问题解决系统 新功能和创新点的引入 虚拟教室环境 数学建模工具集成 算法可视化平台 学术论文资源库 技术实现的前瞻性…...
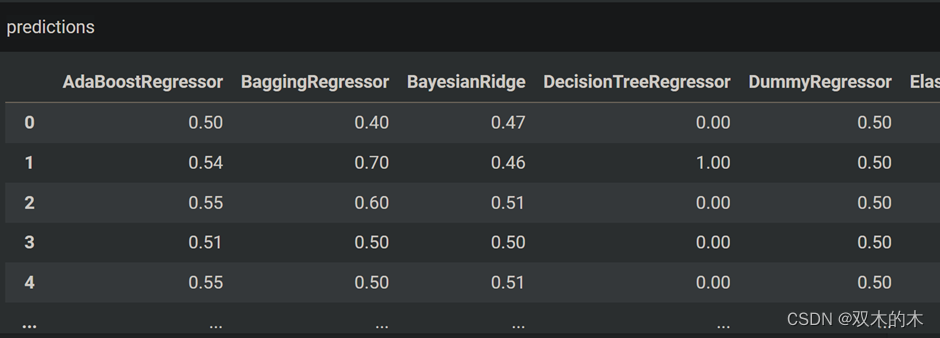
机器学习算法与Python实战 | 两行代码即可应用 40 个机器学习模型--lazypredict 库!
本文来源公众号“机器学习算法与Python实战”,仅用于学术分享,侵权删,干货满满。 原文链接:两行代码即可应用 40 个机器学习模型 今天和大家一起学习使用 lazypredict 库,我们可以用一行代码在我们的数据集上实现许多…...

使用WebSocket协议调用群发方法将消息返回客户端页面
目录 一.C/S架构: 二.Http协议与WebSocket协议的区别: 1.Http协议与WebSocket协议的区别: 2.WebSocket协议的使用场景: 三.项目实际操作: 1.导入依赖: 2.通过WebSocket实现页面与服务端保持长连接&a…...

【北京迅为】《i.MX8MM嵌入式Linux开发指南》-第三篇 嵌入式Linux驱动开发篇-第五十七章 Linux中断实验
i.MX8MM处理器采用了先进的14LPCFinFET工艺,提供更快的速度和更高的电源效率;四核Cortex-A53,单核Cortex-M4,多达五个内核 ,主频高达1.8GHz,2G DDR4内存、8G EMMC存储。千兆工业级以太网、MIPI-DSI、USB HOST、WIFI/BT…...

每日一题~961div2A+B+C(阅读题,思维,数学log)
A 题意:给你 n*n 的表格和k 个筹码。每个格子上至多放一个 问至少占据多少对角线。 显然,要先 格数的多的格子去放。 n n-1 n-2 …1 只有n 的是一个(主对角线),其他的是两个。 #include <bits/stdc.h> using na…...

Fireflyrk3288 ubuntu18.04添加Qt开发环境、安装mysql-server
1、创建一台同版本的ubuntu18.04的虚拟机 2、下载rk3288_ubuntu_18.04_armhf_ext4_v2.04_20201125-1538_DESKTOP.img 3、创建空img镜像容器 dd if/dev/zero ofubuntu_rootfs.img bs1M count102404、将该容器格式化成ext4文件系统 mkfs.ext4 ubuntu_rootfs.img5、将该镜像文件…...

简化mybatis @Select IN条件的编写
最近从JPA切换到Mybatis,使用无XML配置,Select注解直接写到interface上,发现IN条件的编写相当麻烦。 一般得写成这样: Select({"<script>","SELECT *", "FROM blog","WHERE id IN&quo…...
-MFC-C/C++ - Control)
Windows图形界面(GUI)-MFC-C/C++ - Control
公开视频 -> 链接点击跳转公开课程博客首页 -> 链接点击跳转博客主页 目录 Control 资源编辑器 添加控件 设置控件属性 添加控件变量 添加消息处理 处理控件事件 控件焦点顺序 Control 资源编辑器 资源编辑器:用于可视化地编辑对话框和控件。…...

SQL Server数据库安全:策略制定与实践指南
SQL Server数据库安全:策略制定与实践指南 在当今数字化时代,数据安全是每个组织的核心关注点。SQL Server作为广泛使用的关系型数据库管理系统,提供了一套强大的安全特性来保护存储的数据。制定有效的数据库安全策略是确保数据完整性、可用…...

Spring Boot入门指南:留言板
一.留言板 1.输⼊留⾔信息,点击提交.后端把数据存储起来. 2.⻚⾯展⽰输⼊的表⽩墙的信息 规范: 1.写一个类MessageInfo对象,添加构造方法 虽然有快捷键,但是还是不够偷懒 项目添加Lombok。 Lombok是⼀个Java⼯具库,通过添加注…...

Docker 中安装和配置带用户名和密码保护的 Elasticsearch
在 Docker 中安装和配置带用户名和密码保护的 Elasticsearch 需要以下步骤。Elasticsearch 的安全功能(包括基本身份验证)在默认情况下是启用的,但在某些版本中可能需要手动配置。以下是详细步骤,包括如何设置用户名和密码。 1. …...

面试官:说说JVM内存调优及内存结构
1. JVM简介 JVM(Java虚拟机)是运行Java程序的平台,它使得Java能够跨平台运行。JVM负责内存的自动分配和回收,减轻了程序员的负担。 2. JVM内存结构 运行时数据区是JVM中最重要的部分,包含多个内存区域: …...

Ansible的脚本-----playbook剧本【下】
目录 实战演练六:tags 模块 实战演练七:Templates 模块 实战演练六:tags 模块 可以在一个playbook中为某个或某些任务定义“标签”,在执行此playbook时通过ansible-playbook命令使用--tags选项能实现仅运行指定的tasks。 playboo…...

Mysql开启远程控制简化版,亲测有效
首先关闭防火墙 改表法 打开上图的CMD,输入密码进入,然后输入一下指令 1.use mysql; 2.update user set host % where user root;//更新root用户的权限,允许任何主机连接 3.FLUSH PRIVILEGES;//刷新权限,使更改生效 具体参考…...

Codepack:标准化开发配置与自动化工具链的工程实践
1. 项目概述:一个为开发者准备的“代码行囊” 最近在GitHub上闲逛,发现了一个挺有意思的项目,叫 JasonLovesDoggo/codepack 。乍一看名字,你可能会觉得这又是一个普通的代码库或者工具集。但点进去仔细研究后,我发现…...

学术合规性危机预警:Perplexity生成内容如何精准适配Chicago第17版?,一文锁定98.7%高校期刊投稿要求
更多请点击: https://intelliparadigm.com 第一章:学术合规性危机预警:Perplexity生成内容如何精准适配Chicago第17版? 随着AI辅助写作工具在人文社科领域的深度渗透,Perplexity等生成式平台输出的引文、脚注与参考文…...

免费LLM API实战指南:从选型到架构的完整解决方案
1. 项目概述:一份免费LLM API的实用指南 如果你正在开发AI应用,或者只是想低成本地体验各种大语言模型,那么“API调用成本”绝对是一个绕不开的痛点。无论是OpenAI还是Anthropic,按Token计费的模式在频繁调用下,账单数…...
)
Hi3559AV100 MPP开发:从IMX334到HDMI输入,VI参数配置避坑指南(含/proc/umap解析)
Hi3559AV100 MPP开发实战:非标准HDMI输入与VI参数配置深度解析 当我们需要在Hi3559AV100平台上接入HDMI视频源时,传统的MIPI摄像头配置方案往往无法直接适用。本文将从一个真实项目案例出发,详细讲解如何将原本为IMX334 MIPI摄像头设计的VI参…...

为什么你需要SRWE?5个轻松掌握Windows窗口管理的实用技巧
为什么你需要SRWE?5个轻松掌握Windows窗口管理的实用技巧 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE 你是否曾经为Windows窗口管理而烦恼?想要截图却受限于屏幕分辨率,需…...

SkillSync MCP:为AI技能市场构建自动化安全门禁系统
1. 项目概述:为AI技能市场装上“安全门” 如果你和我一样,是Claude Code、Cursor这类AI编程助手的深度用户,那你一定对“技能”(Skills)这个概念不陌生。简单来说,技能就是一些预定义的提示词模板或工具脚…...

从ShareGPT项目拆解现代全栈开发:Next.js、Serverless与Chrome扩展实战
1. 项目概述与核心价值如果你和我一样,经常在ChatGPT里进行一些天马行空的对话,从构思一部科幻小说的世界观,到一步步推导一个复杂的编程问题,再到让它扮演苏格拉底和你辩论哲学,这些对话记录本身就是宝贵的数字资产。…...

告别训练中断:在PyCharm中利用Tmux实现远程GPU服务器的持久化会话
1. 为什么需要持久化训练会话? 作为一名长期在深度学习领域摸爬滚打的工程师,我最头疼的就是训练过程中突然断网或者需要关闭电脑的情况。想象一下,你正在用PyCharm远程连接公司的GPU服务器训练一个需要48小时的模型,突然家里停电…...

通过用量看板与透明账单有效控制大模型 API 调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过用量看板与透明账单有效控制大模型 API 调用成本 对于依赖大模型 API 进行开发的团队而言,成本控制是一个贯穿始终…...

从Packet Tracer到EVE-NG:网络小白进阶实战,手把手教你用VMware部署第一个思科拓扑
从Packet Tracer到EVE-NG:网络工程师的虚拟化进阶指南 当你已经能够熟练使用Cisco Packet Tracer完成CCNA级别的实验,却发现这个教学工具无法满足你对真实网络环境模拟的渴望时,是时候考虑升级你的网络实验平台了。EVE-NG作为当前最强大的网…...