机器学习之人脸识别-使用 scikit-learn 和人工神经网络进行高效人脸识别
文章摘要
本文将介绍如何使用 Python 的 scikit-learn 库和人工神经网络(ANN)来识别人脸。我们将使用 LFW 数据集(Labeled Faces in the Wild),这是一个广泛用于人脸识别基准测试的大型人脸数据库。我们将展示如何准备数据、构建模型,并评估模型的性能。此外,我们还会探讨一些提高模型准确率的方法。
引言
人脸识别是一项关键的技术,它在安全、监控、社交网络和移动应用等多个领域都有广泛应用。随着深度学习的发展,尤其是卷积神经网络(CNN)的进步,人脸识别的准确性已经达到了非常高的水平。然而,对于初学者而言,使用传统的机器学习方法,如人工神经网络,仍然可以达到不错的效果,并且更容易理解和实现。
基本原理
多层感知器(Multilayer Perceptron, MLP)是一种人工神经网络模型,它由一系列的层组成,包括输入层、一个或多个隐藏层以及输出层。MLP中的每个层都包含多个神经元,这些神经元之间是全连接的,即每个神经元的输出都会连接到下一层的每个神经元。
下面是一个简单的数学描述,用于解释MLP的工作原理:
前向传播
假设我们有一个具有 L L L 层的MLP,其中第 l l l层有 n l n_l nl个神经元。对于输入层 l = 1 l=1 l=1,有 n 1 n_1 n1 个输入单元;对于输出层 l = L l=L l=L,有 n L n_L nL 个输出单元。每个神经元除了接受来自上一层的输入外,还会有一个偏置项 b 。
单个神经元的计算
对于第 l l l 层中的第 j j j个神经元,其计算步骤如下:
-
加权求和:
z j ( l ) = ∑ i = 1 n l − 1 w i j ( l ) a i ( l − 1 ) + b j ( l ) z^{(l)}_j = \sum_{i=1}^{n_{l-1}} w^{(l)}_{ij} a^{(l-1)}_i + b^{(l)}_j zj(l)=i=1∑nl−1wij(l)ai(l−1)+bj(l)
其中, w i j ( l ) w^{(l)}_{ij} wij(l)是第 l l l 层中第 i i i 个神经元到第 j j j 个神经元的连接权重, a i ( l − 1 ) a^{(l-1)}_i ai(l−1) 是第 l − 1 l-1 l−1 层中第 i i i 个神经元的激活值, b j ( l ) b^{(l)}_j bj(l) 是第 l l l 层中第 j j j个神经元的偏置项。 -
激活函数:
a j ( l ) = f ( z j ( l ) ) a^{(l)}_j = f(z^{(l)}_j) aj(l)=f(zj(l))
其中, f ( ⋅ ) f(\cdot) f(⋅) 是激活函数,常见的激活函数有 Sigmoid 函数、ReLU 函数等。
层间传递
对于第 l l l 层,其输出 a ( l ) a^{(l)} a(l) 将作为第 l + 1 l+1 l+1 层的输入。
反向传播
反向传播算法用于计算损失函数相对于每个权重和偏置的梯度,并根据这些梯度来调整权重和偏置以最小化损失函数。
损失函数
假设我们的目标是使输出尽可能接近目标值 y y y,我们可以定义一个损失函数 E E E 来衡量这种差距。常见的损失函数有均方误差(MSE)、交叉熵损失等。
梯度计算
反向传播的关键在于使用链式法则计算损失函数关于权重和偏置的梯度。从输出层开始,逐步向前计算梯度。
-
输出层梯度:
δ j ( L ) = ∂ E ∂ a j ( L ) f ′ ( z j ( L ) ) \delta^{(L)}_j = \frac{\partial E}{\partial a^{(L)}_j} f'(z^{(L)}_j) δj(L)=∂aj(L)∂Ef′(zj(L)) -
隐藏层梯度:
δ j ( l ) = ( ∑ k = 1 n l + 1 w k j ( l + 1 ) δ k ( l + 1 ) ) f ′ ( z j ( l ) ) \delta^{(l)}_j = \left( \sum_{k=1}^{n_{l+1}} w^{(l+1)}_{kj} \delta^{(l+1)}_k \right) f'(z^{(l)}_j) δj(l)=(k=1∑nl+1wkj(l+1)δk(l+1))f′(zj(l))
参数更新
利用梯度下降或其变种(如动量梯度下降、Adam 等)更新权重和偏置:
w i j ( l ) ← w i j ( l ) − η ∂ E ∂ w i j ( l ) w^{(l)}_{ij} \leftarrow w^{(l)}_{ij} - \eta \frac{\partial E}{\partial w^{(l)}_{ij}} wij(l)←wij(l)−η∂wij(l)∂E
b j ( l ) ← b j ( l ) − η ∂ E ∂ b j ( l ) b^{(l)}_j \leftarrow b^{(l)}_j - \eta \frac{\partial E}{\partial b^{(l)}_j} bj(l)←bj(l)−η∂bj(l)∂E
其中, η \eta η 是学习率,决定了参数更新的步长。
原理小结
以上就是多层感知器的基本数学原理。通过前向传播计算网络的输出,并通过反向传播来调整网络中的权重和偏置,从而使得网络能够学习数据中的模式并进行预测。这个过程通常需要大量的训练数据以及适当的超参数设置来确保良好的性能。
步骤1: 准备环境
首先,确保您的Python环境中已经安装了scikit-learn和其他必要的库。可以通过以下命令安装:
pip install scikit-learn matplotlib
步骤2: 导入库
import numpy as np
from sklearn.datasets import fetch_lfw_people
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import classification_report, confusion_matrix
import matplotlib.pyplot as plt
步骤3: 加载数据集
# 加载LFW数据集
lfw_people = fetch_lfw_people(data_home=r"D:\\AICode\\ANN\\", download_if_missing=False, min_faces_per_person=70, resize=0.4)# 获取数据集的基本信息
n_samples, h, w = lfw_people.images.shape
X = lfw_people.data
n_features = X.shape[1]
y = lfw_people.target
target_names = lfw_people.target_names
n_classes = target_names.shape[0]# 打印数据集的一些基本信息
print("Total dataset size:")
print("n_samples: %d" % n_samples)
print("n_features: %d" % n_features)
print("n_classes: %d" % n_classes)
步骤4: 可视化数据
# 定义一个辅助函数来展示图像
def plot_gallery(images, titles, h, w, n_row=3, n_col=4):"""Helper function to plot a gallery of portraits"""plt.figure(figsize=(1.8 * n_col, 2.4 * n_row))plt.subplots_adjust(bottom=0, left=.01, right=.99, top=.90, hspace=.35)for i in range(n_row * n_col):plt.subplot(n_row, n_col, i + 1)plt.imshow(images[i].reshape((h, w)), cmap=plt.cm.gray)plt.title(titles[i], size=12)plt.xticks(())plt.yticks(())# 展示一些样本
titles = ["%s" % target_names[i].split(' ')[-1] for i in lfw_people.target[:3 * 4]]
plot_gallery(lfw_people.images, titles, h, w)plt.show()
步骤5: 数据分割
# 将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
步骤6: 构建和训练模型
# 使用MLP进行人脸识别
mlp = MLPClassifier(hidden_layer_sizes=(100,), max_iter=1000, alpha=1e-4,solver='adam', verbose=10, tol=1e-4, random_state=1,learning_rate_init=.1)mlp.fit(X_train, y_train)
print("Model trained.")
步骤7: 模型评估
# 预测测试集
y_pred = mlp.predict(X_test)# 打印分类报告
print(classification_report(y_test, y_pred, target_names=target_names,zero_division=1))# 打印混淆矩阵
cm = confusion_matrix(y_test, y_pred)
print("Confusion matrix:\n%s" % cm)
步骤8: 可视化混淆矩阵
# 显示混淆矩阵
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
plt.title("Confusion matrix")
plt.colorbar()
tick_marks = np.arange(len(target_names))
plt.xticks(tick_marks, target_names, rotation=45)
plt.yticks(tick_marks, target_names)plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')plt.show()
解析:
- 加载数据集:
- 使用
fetch_lfw_people函数加载LFW数据集。 - 我们设置
min_faces_per_person=70,这意味着只保留至少有70张照片的人物。 - 图像被缩放到
resize=0.4的比例,以减少计算量。
- 使用
- 查看数据集信息:
n_samples表示数据集中的人脸总数。n_features是每个图像的特征数量(即像素数量)。n_classes是数据集中人物的数量。
- 可视化:
plot_gallery函数用于显示一些样本图像。title函数用于生成预测和真实标签的标题。
- 数据分割:
- 使用
train_test_split将数据集分割成训练集和测试集。
- 使用
- 模型训练:
- 使用
MLPClassifier创建一个多层感知器模型。 - 设置了隐藏层的大小、迭代次数、正则化参数等。
- 模型使用Adam优化器。
- 使用
- 模型评估:
- 训练完成后,使用测试集评估模型性能。
- 输出分类报告和混淆矩阵。
- 混淆矩阵可视化:
- 使用
matplotlib库来可视化混淆矩阵。
- 使用
结论
通过上述步骤,我们成功地使用了scikit-learn中的MLPClassifier来构建一个人脸识别模型。模型的表现可以通过分类报告和混淆矩阵来评估。虽然使用人工神经网络进行人脸识别不是最先进的方法,但对于初学者来说,这是一个很好的起点。
进阶技巧
- 特征提取:考虑使用PCA或LDA等降维技术来减少特征的数量,这样可以加快训练速度并且有时可以提高模型性能。
- 超参数调整:使用网格搜索或随机搜索来寻找最优的模型参数,例如隐藏层的大小、学习率等。
- 增强数据:通过数据增强技术(如旋转、翻转等)来增加数据集的多样性,从而提高模型的泛化能力。
代码总结
以上代码展示了如何使用scikit-learn和人工神经网络来进行人脸识别。您可以根据自己的需求调整模型参数,比如增加隐藏层的数量、改变学习率等,以获得更优的结果。
如果您想要进一步提高模型的性能,可以尝试使用更复杂的方法,例如卷积神经网络(CNN),这通常会带来显著的性能提升。不过,这对于初学者来说可能较为复杂,需要一定的深度学习背景知识。
执行效果




最后的建议
- 持续学习:机器学习是一个快速发展的领域,保持学习的态度是非常重要的。
- 实践项目:动手实践是最好的学习方式,尝试在不同的数据集上训练模型。
- 社区参与:加入机器学习社区,与其他开发者交流经验和心得。
通过这篇文章,我们不仅学习了如何使用scikit-learn和人工神经网络进行人脸识别,还了解了一些提高模型性能的方法。希望这篇文章对您有所帮助!
别忘了给这篇帖子点个赞👍,如果喜欢的话,也可以收藏,关注我了解更多人工智能相关案例知识哦!😉
请记得,LFW数据集较大,下载和训练可能需要一定的时间,建议将LFW数据集下载到本地,本例中是先下载到本地的。如果您在运行代码时遇到任何问题,请随时提问!
相关文章:
机器学习之人脸识别-使用 scikit-learn 和人工神经网络进行高效人脸识别
文章摘要 本文将介绍如何使用 Python 的 scikit-learn 库和人工神经网络(ANN)来识别人脸。我们将使用 LFW 数据集(Labeled Faces in the Wild),这是一个广泛用于人脸识别基准测试的大型人脸数据库。我们将展示如何准备…...

【虚拟化】KVM概念和架构
目录 一、什么是KVM? 二、KVM的功能 2.1 主要的功能 2.2 其它功能 三、KVM核心组件及作用 四、KVM与VMware的优势 五、KVM架构 六、qemu介绍 七、创建虚拟机流程 一、什么是KVM? Kernel-based Virtual Machine的简称,KVM 是基于虚拟…...

【Linux】权限2
Linux文件要被执行满足两个条件: ①必须要具备可执行权限 x ②真的是一个可执行程序 1.权限的修改,文件强行给别人 权限就是拦住一批人,不让他做特定的一件事情 a.更改人,更改文件所隶属的人 如果把文件强行给别人, chown xxx(普通用户) xxx(文件名) 会出现下面的情况 很明显…...
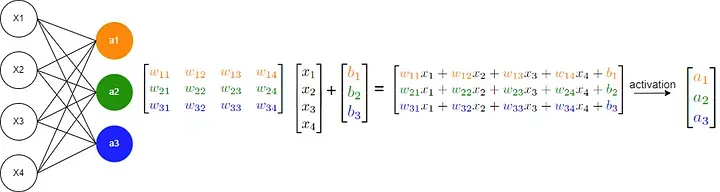
汽车长翅膀:GPU 是如何加速深度学习模型的训练和推理过程的?
编者按:深度学习的飞速发展离不开硬件技术的突破,而 GPU 的崛起无疑是其中最大的推力之一。但你是否曾好奇过,为何一行简单的“.to(‘cuda’)”代码就能让模型的训练速度突飞猛进?本文正是为解答这个疑问而作。 作者以独特的视角&…...

怀旧必玩!重返童年,扫雷游戏再度登场!
Python提供了一个标准的GUI(图形用户界面)工具包:Tkinter。它可以用来创建各种窗口、按钮、标签、文本框等图形界面组件。 而且Tkinter 是 Python 自带的库,无需额外安装。 Now,让我们一起来回味一下扫雷小游戏吧 扫…...

Avalonia中的路由事件
文章目录 一、路由事件的基本概念事件路由机制事件的生命周期二、创建路由事件定义路由事件触发路由事件处理路由事件三、使用路由事件的场景用户输入控件交互动画和样式数据绑定和验证四、路由事件的优缺点优点:缺点:五、总结在Avalonia中,路由事件是处理用户交互和控件之间…...

ubuntu20.04安装RabbitMQ +Erlang
ubuntu20.04安装RabbitMQ 3.11.19Erlang 25.3.1_ubuntu20.04.6 安装 rabbitmq-CSDN博客 LINUX下载编译libpng_linux libpng下载-CSDN博客 Ubuntu20.04 安装 Nginx 软件报错:libgd3 缺少 libpng12-0 依赖 Ubuntu安装RabbitMq(保姆级教学,直…...

【word转pdf】【最新版本jar】Java使用aspose-words实现word文档转pdf
【aspose-words-22.12-jdk17.jar】word文档转pdf 前置工作1、下载依赖2、安装依赖到本地仓库 项目1、配置pom.xml2、配置许可码文件(不配置会有水印)3、工具类4、效果 踩坑1、pdf乱码2、word中带有图片转换 前置工作 1、下载依赖 通过百度网盘分享的文…...

分布式:RocketMQ/Kafka总结(附下载链接)
文章目录 下载链接思维导图 本文总结的是关于消息队列的常见知识总结。消息队列和分布式系统息息相关,因此这里就将消息队列放到分布式中一并进行处理关联 下载链接 链接: https://pan.baidu.com/s/1hRTh7rSesikisgRUO2GBpA?pwdutgp 提取码: utgp 思维导图...

Air780EP模块 LuatOS开发-MQTT接入阿里云应用指南
简介 本文简单讲述了利用LuatOS-Air进行二次开发,采用一型一密、一机一密两种方式认证方式连接阿里云。整体结构如图 关联文档和使用工具:LuatOS库阿里云平台 准备工作 Air780EP_全IO开发板一套,包括天线SIM卡,USB线 PC电脑&…...

【算法】插入区间
难度:中等 题目: 给你一个 无重叠的 ,按照区间起始端点排序的区间列表 intervals,其中 intervals[i] [starti, endi] 表示第 i 个区间的开始和结束,并且 intervals 按照 starti 升序排列。同样给定一个区间 newInte…...
)
C++ 代码实现socket 类使用TCP/IP进行通信 (windows 系统)
C 代码实现socket 类使用TCP/IP进行通信 (windows 系统) TCP客户端通信常规步骤: 1.初始换socket环境 2.socket()创建TCP套接字。 3.connect()建立到达服务器的连接。 4.与客户端进行通信,recv()/send()接受/发送信息࿰…...

前后端分离项目部署,vue--nagix发布部署,.net--API发布部署。
目录 Nginx免安装部署文件包准备一、vue前端部署1、修改http.js2、npm run build 编译项目3、解压Nginx免安装,修改nginx.conf二、.net后端发布部署1、编辑appsetting.json,配置跨域请求2、配置WebApi,点击发布3、配置文件发布到那个文件夹4、配置发布相关选项5、点击保存,…...

【BUG】已解决:UnicodeDecodeError: ‘utf-8’ codec can’t decode bytes in position 10
UnicodeDecodeError: ‘utf-8’ codec can’t decode bytes in position 10 目录 UnicodeDecodeError: ‘utf-8’ codec can’t decode bytes in position 10 【常见模块错误】 【解决方案】 欢迎来到英杰社区https://bbs.csdn.net/topics/617804998 欢迎来到我的主页&#x…...

C++ | QQ后端暑期实习面试
tcp三次握手,四次挥手 断点续传 文件断点续传是一种机制,允许在网络传输中的文件传输过程中出现断开连接或传输中断的情况下,能够恢复传输并继续传输未完成的部分。其原理如下: 检测支持:首先,服务器端和…...

实用网站推荐
学习 前端 精简CSS格式 Font Awesome 图标库 BootCDN 加速服务 合集 AI工具集 动漫、音乐 娱乐 嗷呜动漫 奈飞同步 视频下载 B站视频解析下载 文件操作 ioDraw制作图 Convertio — 文件转换器 PDF处理 LOGO...
Linux |Nethogs 监控网络使用情况
引言 互联网上为 Linux 系统提供了许多开源的网络监控工具。例如,你可以利用 iftop 命令来监测网络带宽的消耗,使用 netstat 或 ss 命令来获取网络接口的统计信息,或者通过 top 命令来查看系统中正在运行的进程。 然而,如果你真正…...

大语言模型训练过程中,怎么实现算力共享,采用什么分片规则和共享策略
目录 大语言模型训练过程中,怎么实现算力共享,采用什么分片规则和共享策略 一、算力共享的实现 二、分片规则与共享策略 三、总结 DeepSpeed、Megatron-LM是什么 DeepSpeed ZeRO技术一般不实现调参的 ZeRO技术的实现方式 ZeRO与调参的关系 NCCL是什么 一、NCCL概…...

JCR一区级 | Matlab实现TTAO-Transformer-LSTM多变量回归预测
JCR一区级 | Matlab实现TTAO-Transformer-LSTM多变量回归预测 目录 JCR一区级 | Matlab实现TTAO-Transformer-LSTM多变量回归预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.【JCR一区级】Matlab实现TTAO-Transformer-LSTM多变量回归预测,三角拓扑聚合…...
数列 c++详解)
斐波那契数列(Fibonacci)数列 c++详解
Fibonacci数列是一个在数学和计算机科学中非常著名的数列。这个数列以其特殊的递推关系而闻名,也因其在自然界中的多次出现而引人注目。 定义: Fibonacci数列的定义如下: F(0) 0F(1) 1对于 n > 1,F(n) F(n-1) F(n-2) 也就…...

RK3588开发板Debian系统从零配置到实战:安全加固、Docker部署与性能调优
1. 项目概述:从零上手TL3588的Debian系统最近在折腾一块基于瑞芯微RK3588芯片的开发板,型号是TL3588。这板子性能是真不错,八核CPU加上强大的NPU,拿来做边缘计算、多媒体网关或者轻量级服务器都挺合适。但刚拿到手,面对…...

如何高效构建视频数据集:video2frame终极实战指南
如何高效构建视频数据集:video2frame终极实战指南 【免费下载链接】video2frame Yet another easy-to-use tool to extract frames from videos, for deep learning and computer vision. 项目地址: https://gitcode.com/gh_mirrors/vi/video2frame 在计算机…...

MATLAB/Simulink模型化设计驱动树莓派:从LED闪烁到快速原型开发
1. 项目概述:当MATLAB/Simulink遇见树莓派 如果你是一名算法工程师、控制工程师,或者正在学习嵌入式系统,那么“模型化设计”和“快速原型开发”这两个词对你来说一定不陌生。它们听起来很高大上,但核心目标其实很朴素࿱…...

构建个人技能图谱:从结构化设计到自动化可视化的实践指南
1. 项目概述:一个技能图谱的诞生最近在GitHub上看到一个挺有意思的项目,叫dortort/skills。初看这个仓库名,你可能会有点懵,dortort是作者,那skills是什么?点进去一看,发现它不是一个具体的工具…...

AI原生编程语言Reia:为LLM设计的编程范式变革
1. 项目概述:Reia,一个面向未来的AI原生编程语言最近在AI和编程语言交叉领域,一个名为Reia的项目引起了我的注意。它来自Quaint-Studios,定位是“AI原生”的编程语言。这听起来有点抽象,但简单来说,Reia试图…...

AXI Crossbar设计解析:从总线互联原理到SoC集成实战
1. 项目概述:AXI Crossbar,不仅仅是“总线交叉开关”在复杂的数字系统设计,尤其是SoC(片上系统)和FPGA应用中,我们常常面临一个核心问题:多个主设备(Master,如CPU、DMA控…...

RK3288嵌入式开发实战:硬件架构、软件定制与典型应用场景解析
1. 项目概述:为什么RK3288至今仍是嵌入式开发的“硬通货”? 在嵌入式开发这个行当里,选型是个技术活,更是个经验活。你既要考虑当下的性能需求,又要掂量未来的扩展可能,还得平衡成本、功耗和开发周期。从业…...

企业无线准入实战:AC联动RADIUS与内置Portal构建安全访客网络
1. 为什么企业需要安全访客网络? 想象一下这样的场景:你的公司经常有合作伙伴、客户来访,他们需要临时使用Wi-Fi。如果直接开放内部网络,就像把家门钥匙随便发给陌生人;如果用简单密码共享,又像在公共场合大…...

Zabbix监控大屏展示中文总乱码?手把手教你替换DejaVuSans为微软雅黑字体
Zabbix监控大屏中文乱码终极解决方案:从字体替换到视觉优化 当你精心配置的Zabbix监控大屏在向管理层汇报时突然出现中文乱码,那种尴尬就像交响乐团演出时小提琴突然走音。作为经历过数十次企业级监控系统部署的资深运维,我深知字体问题远不止…...
表面吸附模型的构建与可视化)
从DFT计算到论文插图:一条龙搞定Pt(111)表面吸附模型的构建与可视化
从DFT计算到论文插图:Pt(111)表面吸附模型的完整构建与可视化指南 在计算材料科学领域,构建精确的表面吸附模型是研究催化反应机理、表面化学过程的第一步。对于刚入门的研究者来说,如何快速构建一个符合物理实际的Pt(111)表面吸附模型&#…...