基于FPGA的数字信号处理(19)--行波进位加法器
1、10进制加法是如何实现的?
10进制加法是大家在小学就学过的内容,不过在这里我还是帮大家回忆一下。考虑2个2位数的10进制加法,例如:15 + 28 = 43,它的运算过程如下:
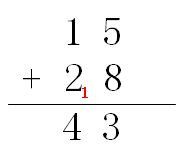
个位两数相加,结果为5 + 8 = 13,结果的1作为进位传递到十位,而3则作为和的低位保留
十位的两数相加同时加上来自低位的进位1,即1 + 2 + 1 = 4,且没有向高位产生进位
因为没有产生进位也可以看做是产生了数值为0的进位,所以我们把十位和个位都添加上来自低位的进位,以及去往高位的进位,如下:
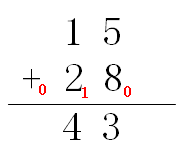
这样的两位数加法,实际上就拆解成两个加法器的级联了。单个加法器和2进制全加器一样,可以计算2个1位数的加法,同时接受来自低位的进位,以及产生向高位的进位,就像这样:
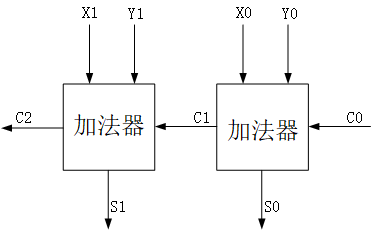
2、行波进位加法器RCA
同10进制加法相加类似,2个多bits的2进制数相加,也可以通过这种级联的形式来构成。考虑2个4bits数的加法,每个全加器都可以处理它对应位数的两个数的加法,同时接收来自低级的进位,并向高位产生进位,所以它的结构是这样的:
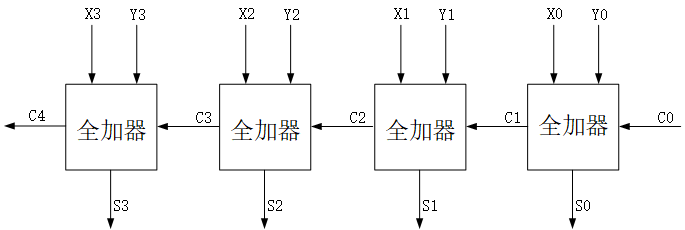
这样的加法器叫做 行波进位加法器 或 纹波进位加法器(Ripple Carry Adder,RCA),这个取名大概是因为它的进位传递是一级一级往外(前)扩散的,就好像水面泛起的波纹一样。
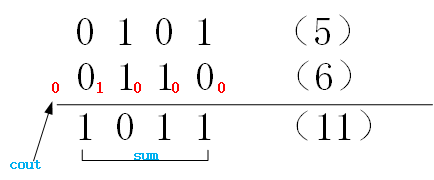
以两个4bits数相加为例:5 + 6 = 11,即 0101 + 0110 = 1011,它的过程如下:
根据RCA的结构,可以很快地写出它的Verilog实现形式:
//使用多个全加器级联构建RCA加法器
module rca(input [3:0] x, //加数1input [3:0] y, //加数2input cin, //来自低位的进位output [3:0] sum, //和output cout //向高位的进位
);
wire c1,c2,c3; //进位连接
//例化全加器来构建RCA加法器
full_adder u0(.x (x[0]),.y (y[0]), .sum (sum[0]),.cin (cin),.cout (c1)
);
full_adder u1(.x (x[1]),.y (y[1]), .sum (sum[1]),.cin (c1),.cout (c2)
);
full_adder u2(.x (x[2]),.y (y[2]), .sum (sum[2]),.cin (c2),.cout (c3)
);
full_adder u3(.x (x[3]),.y (y[3]), .sum (sum[3]),.cin (c3),.cout (cout)
);
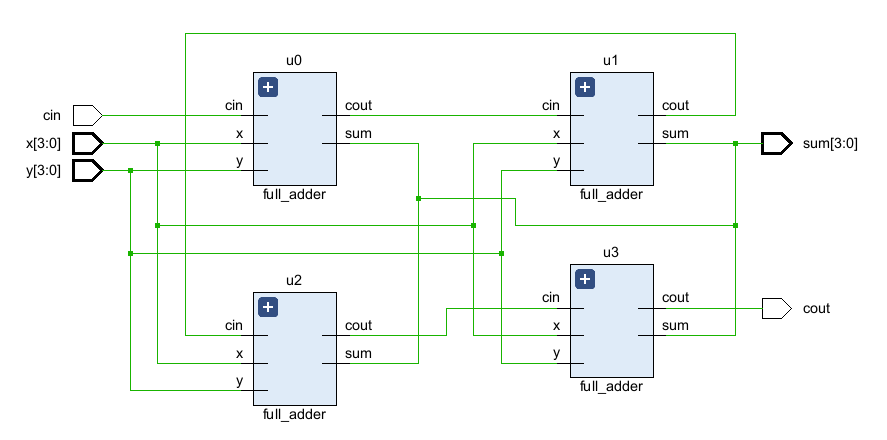
endmodule 这里记得把全加器的代码也要添加进工程。生成的示意图如下(虽然这个排布不能很好地看出来层次结构,但确实没错):
然后写个TB测试一下这个加法器电路,因为4个bits即16×16=256种情况,加上低位进位的两种情况,也才256×2=512种情况,所以可以用穷举法来测试:
`timescale 1ns/1ns //时间刻度:单位1ns,精度1ns
module tb_rca();
//定义变量
reg [3:0] x; //加数1
reg [3:0] y; //加数2
reg cin; //来自低位的进位
wire [3:0] sum; //和
wire cout; //向高位进位
reg [3:0] sum_real; //和的真实值,作为对比
reg cout_real; //向高位进位的真实值,作为对比
wire sum_flag; //sum正确标志信号
wire cout_flag; //cout正确标志信号
assign sum_flag = sum == sum_real; //和的结果正确时拉高该信号
assign cout_flag = cout == cout_real; //进位结果正确时拉高该信号
integer z,i,j; //循环变量
//设置初始化条件
initial begin//初始化x =1'b0; y =1'b0; cin =1'b0; //穷举所有情况for(z=0;z<=1;z=z+1)begincin = z;for(i=0;i<16;i=i+1)beginx = i;for(j=0;j<16;j=j+1)beginy = j;if((i+j+z)>15)begin //如果加法的结果产生了进位sum_real = (i+j+z) - 16; //减掉进位值cout_real = 1; //向高位的进位为1endelse begin //如果加法的结果没有产生了进位sum_real = i+j+z; //结果就是加法本身cout_real = 0; //向高位的进位为0end#5; end endend#10 $stop(); //结束仿真
end
//例化被测试模块
rca u_rca(.x (x),.y (y), .sum (sum),.cin (cin),.cout (cout)
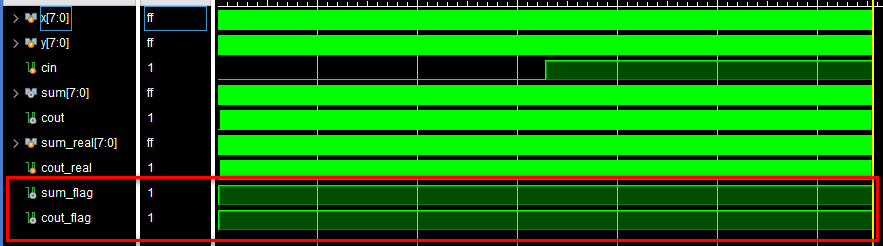
);endmoduleTB中分别用3个嵌套的循环将所有情况穷举出来,即cin=0~1、x=0~15和y=0~15的所有情况。加法运算的预期结果也是很容易就可以找出来的,就是在TB中直接写加法就行。接着构建了两个标志向量sum_flag和cout_flag作为电路输出与预期正确结果的对比值,当二者一致时即拉高这两个信号。这样我们只要观察这两个信号,即可知道电路输出是否正确。仿真结果如下:
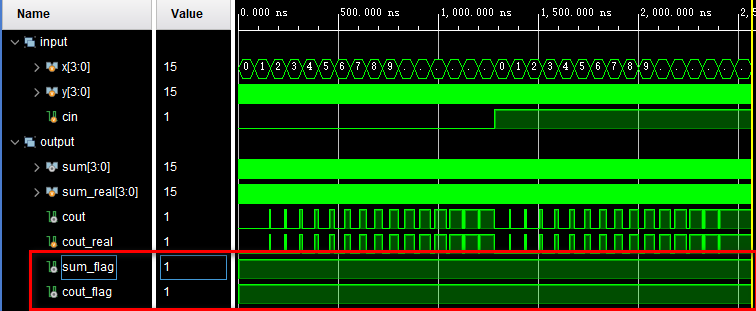
可以看到,sum_flag和cout_flag都是一直拉高的,说明电路输出正确。
3、RCA加法器的缺陷
因为RCA的结构是从低到高依次级联的,所以它的进位链特别长,比如加法 1111 + 0000 + 1(最后的1表示来自低位的进位即cin),它的进位从最低位开始,需要经过4级全加器才能传递到最高级,如下:
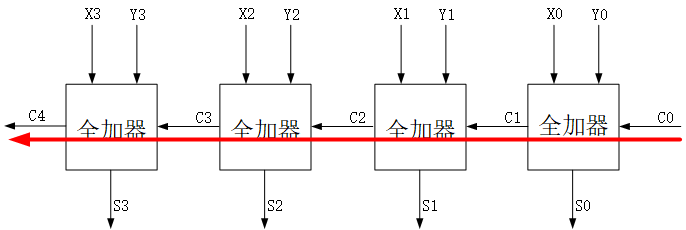
这条进位cin传递的路径也是拖垮整个电路速度的关键路径(Critical Path),它的长度(延迟)为 4*全加器 的延迟。可以预见,随着加法器位宽的增加,这条路径也会越来越长,所以RCA不适合位宽很大的加法,因为它的延迟实在是太高了。
以RCA的基础组成部分全加器FA为例,它的结构是这样的:
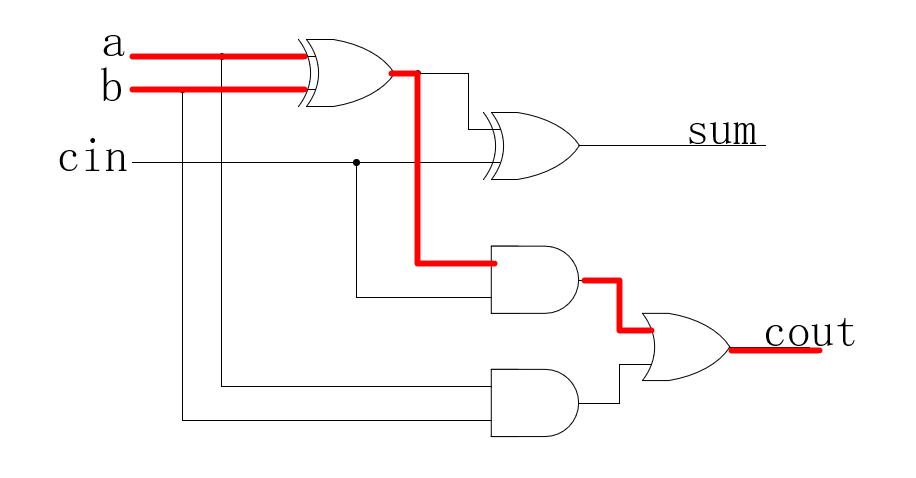
图中的红色路径就是关键路径,即延迟最高的路径,它由 1个异或门延迟 + 1个与门延迟 + 1个或门延迟 + 布线延迟 组成,若忽略布线延迟(和门电路延迟比起来,布线延迟相对较小),并将3种门电路的延迟都近似看做同一个数值的话,则单个全加器的延迟是 3个门电路延迟。
这么说,从直观上感觉多个全加器构成的行波进位加法器的关键路径延迟应该是 3×全加器数量(即加法位宽),比如两个4bits数相加,其关键路径延迟应该是 4×3=12个门电路延迟,但实际上不是,我们看下具体结构:

除了在第一个全加器有3个门电路的延迟外,后面经过的全加器都只有两个门电路的延迟,所以总共的延迟是 3 + 3*2 = 9个,由此可以推广到Nbits数,其延迟为 3 + 2×(N - 1) = 2N + 1 个门电路。
在RCA的基础上,工程师们又设计了很多种其他的加法器结构,它们的延迟较之RCA加法器有了显著的降低,其中比较有名的一种加法器是 超前进位加法器(Lookahead Carry Adder),我们将在下一篇文章介绍它。
4、RCA加法器的参数化设计
在上面的内容种,对RCA的举例是两个4bits数相加实现的形式,为了满足不同位宽的加法,这里也给出参数化设计形式的Verilog代码:
//使用多个全加器级联构建RCA加法器
module rca
#(parameter integer WIDTH = 4
)
(input [WIDTH-1:0] x, //加数1input [WIDTH-1:0] y, //加数2input cin, //来自低位的进位output [WIDTH-1:0] sum, //和output cout //向高位的进位
);
wire [WIDTH:0] c_wire; //用来连线传递的进位变量
assign c_wire[0] = cin; //最低位是输入的进位
assign cout = c_wire[WIDTH]; //最高位是输出的进位
//用generate来例化多个模块
genvar i;
generatefor(i=0;i<WIDTH;i=i+1)begin:full_adderfull_adder u_full_adder(.x (x[i] ),.y (y[i] ),.sum (sum[i] ),.cin (c_wire[i] ),.cout (c_wire[i+1]));end
endgenerate
endmodule 配套的TB也改成参数化形式:
`timescale 1ns/1ns //时间刻度:单位1ns,精度1ns
module tb_rca();
parameter integer WIDTH = 'd4;
//定义变量
reg [WIDTH-1:0] x; //加数1
reg [WIDTH-1:0] y; //加数2
reg cin; //来自低位的进位
wire [WIDTH-1:0] sum; //和
wire cout; //向高位进位
reg [WIDTH-1:0] sum_real; //和的真实值,作为对比
reg cout_real; //向高位进位的真实值,作为对比
wire sum_flag; //sum正确标志信号
wire cout_flag; //cout正确标志信号
assign sum_flag = sum == sum_real; //和的结果正确时拉高该信号
assign cout_flag = cout == cout_real; //进位结果正确时拉高该信号
integer z,i,j; //循环变量
//设置初始化条件
initial begin//初始化x = 0; y = 0; cin = 0; //穷举所有情况for(z=0;z<=1;z=z+1)begincin = z;for(i=0;i<(2**WIDTH);i=i+1)beginx = i;for(j=0;j<(2**WIDTH);j=j+1)beginy = j;if((i+j+z)>(2**WIDTH-1))begin //如果加法的结果产生了进位sum_real = (i+j+z) - (2**WIDTH); //减掉进位值cout_real = 1; //向高位的进位为1end else begin //如果加法的结果没有产生了进位sum_real = i+j+z; //结果就是加法本身cout_real = 0; //向高位的进位为0end#5; end endend#10 $stop(); //结束仿真
end
//例化被测试模块
rca #(.WIDTH (WIDTH)
)
u_rca(.x (x),.y (y), .sum (sum),.cin (cin),.cout (cout)
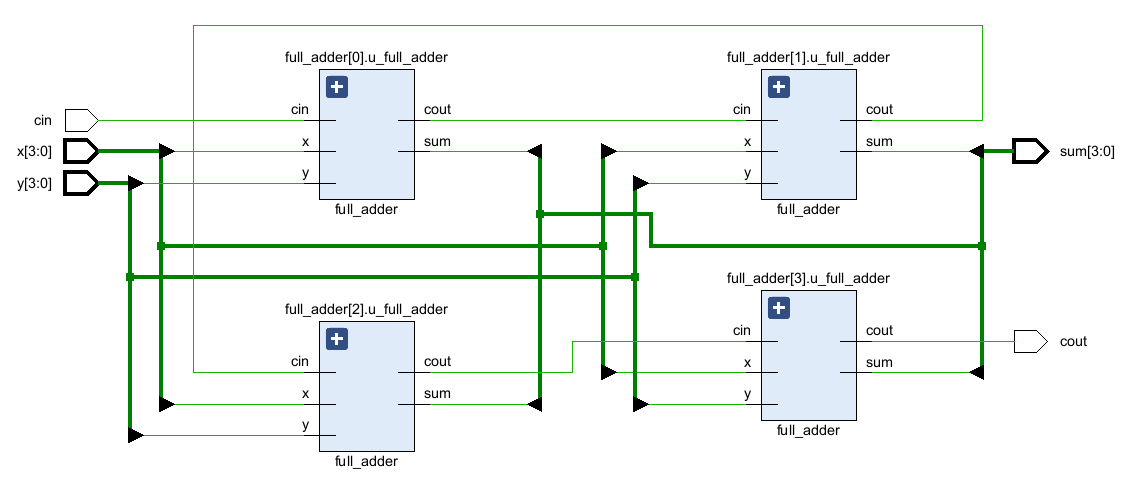
);endmodule(1)把位宽width改成4
生成的4bits加法的RCA示意图:
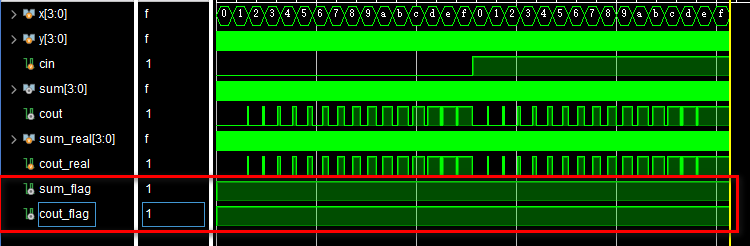
仿真结果证明电路设计无误:
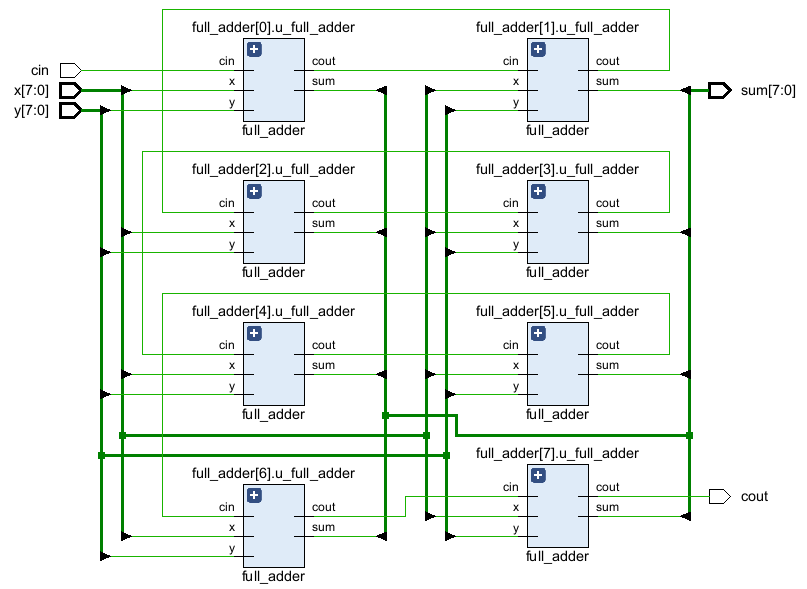
(2)把位宽width改成8
生成的8bits加法的RCA示意图:
仿真结果证明电路设计无误:
5、RCA加法器的时序性能
为了探究RCA加法器的时序性能,需要再原有代码的基础上,做一些小小的改变:在输入和输出分别添加上寄存器。如下:
//使用多个全加器级联构建RCA加法器
module rca
#(parameter integer WIDTH = 32
)
(input clk,input [WIDTH-1:0] x, //加数1input [WIDTH-1:0] y, //加数2input cin, //来自低位的进位output [WIDTH-1:0] sum, //和output cout //向高位的进位
);
reg cin_r,cout_r;
reg [WIDTH-1:0] x_r,y_r,sum_r;
wire [WIDTH:0] c_wire; //用来连线传递的进位变量
wire [WIDTH-1:0] sum_w; //用来连线传递和
//输入寄存
always@(posedge clk)beginx_r <= x;y_r <= y;cin_r <= cin;
end
assign c_wire[0] = cin_r; //最低位是输入的进位
//输出寄存
always@(posedge clk)beginsum_r <= sum_w;cout_r <= c_wire[WIDTH]; //最高位是输出的进位
end
assign sum = sum_r;
assign cout = cout_r;
//用generate来例化多个模块
genvar i;
generatefor(i=0;i<WIDTH;i=i+1)begin:full_adderfull_adder u_full_adder(.x (x_r[i] ),.y (y_r[i] ),.sum (sum_w[i] ),.cin (c_wire[i] ),.cout (c_wire[i+1]));end
endgenerate
endmodule 分别例化4位加法,8位加法,16位加法和32位加法,记录它们的逻辑级数logic levels、最差建立时间裕量WNS和电路面积,并算出最大运行频率Fmax。如下:
| 4位 | 8位 | 16位 | 32位 | |
|---|---|---|---|---|
| WNS(ns) | 8.777 | 8.155 | 6.917 | 4.429 |
| Fmax(Mhz) | 818 | 542 | 324 | 180 |
| logic levels(级) | 2 | 4 | 8 | 16 |
| 电路面积(不考虑FF) | 4 LUT | 8 LUT | 16 LUT | 32 LUT |
从上表可以看到:
-
随着加法器位宽的增加,逻辑级数也越来越大,这是导致时序性能变差的直接原因
-
时序性能从818M相关性地降低到180M,需要说明的是这里的最大频率Fmax只能作为一个参考,因为我整个工程只添加了这么一个加法器,而且Fmax一般还和FGPA的器件强挂钩,一般的器件肯定是跑不到800M的,这里我们主要是观察这个频率降低的趋势
-
电路面积上是几位加法就用几个LUT(因为1个全加器用1个LUT),而且都是直接级联的
作为参考,我们不使用任何加法器,就直接用加法运算符 + 来实现加法,电路就让综合工具vivado来自动生成,代码如下:
//直接写加法,看Vivado综合的结果
module rca
#(parameter integer WIDTH = 32
)
(input clk,input [WIDTH-1:0] x, //加数1input [WIDTH-1:0] y, //加数2input cin, //来自低位的进位output [WIDTH-1:0] sum, //和output cout //向高位的进位
);
reg cin_r,cout_r;
reg [WIDTH-1:0] x_r,y_r,sum_r;
wire [WIDTH-1:0] sum_w;
wire cout_w;
//输入寄存
always@(posedge clk)beginx_r <= x;y_r <= y;cin_r <= cin;
end
assign {cout_w,sum_w} = x_r + y_r + cin_r; //直接写加法
//输出寄存
always@(posedge clk)beginsum_r <= sum_w;cout_r <= cout_w;
end
//端口连接
assign sum = sum_r;
assign cout = cout_r;
endmodule看看时序性能如何:
| 4位 | 8位 | 16位 | 32位 | |
|---|---|---|---|---|
| WNS(ns) | 8.777 | 8.755 | 8.657 | 8.461 |
| Fmax(Mhz) | 818 | 803 | 745 | 650 |
| logic levels(级) | 2 | 3 | 5 | 9 |
| 电路面积(不考虑FF) | 4 LUT | 8 LUT + 3 CARRY4 | 16 LUT + 5 CARRY4 | 32 LUT + 9 CARRY4 |
从上表可以看到:
-
vivado综合出来的加法电路在时序性能上明显比RCA电路要强
-
逻辑级数的增加并没有RCA电路那么明显,哪怕是32位的加法也只有9级逻辑层级。这也是它频率能跑很高的直接原因
-
4位加法使用的电路面积和RCA是一样的,因为位宽较小,综合工具直接用LUT而不是CARRY4来生成电路,二者在小位宽时的时序性能差不多
-
之所以大位宽加法的时序性能仍然比较好是因为综合工具使用CARRY4来实现加法,这种结构的加法电路有很快的进位速度,而且可以合并很多个进位链上的LUT从而减少逻辑级数
-
CARRY4的使用尽管可以提高时序性能,但是也会增大一部分电路面积。当然了,拿这点面积来换性能的提升,还是十分划算的
如果你不了解CARRY4,可以看看这篇文章:从底层结构开始学习FPGA(7)----进位链CARRY4
或者看看这个专栏:从底层结构开始学习FPGA
6、总结
行波进位加法器RCA结构简单,进位链长,时序性能差,在实际应用尤其是FPGA设计中基本不会使用。对于FPGA设计来说,如今的综合工具已经非常智能了,一般的加法还是不要自己设计加法器了,直接让综合工具生成或者用IP就行。
相关文章:
基于FPGA的数字信号处理(19)--行波进位加法器
1、10进制加法是如何实现的? 10进制加法是大家在小学就学过的内容,不过在这里我还是帮大家回忆一下。考虑2个2位数的10进制加法,例如:15 28 43,它的运算过程如下: 个位两数相加,结果为5 8 1…...

树莓派下,centos7操作系统, TensorFlow java版实现植物分类功能
在树莓派上运行CentOS 7,并使用TensorFlow Java版本实现植物分类功能可以通过以下步骤实现。以下是详细的指导: 一、安装和设置环境 1. 更新系统并安装基本工具 确保你的CentOS 7系统是最新的,并安装必要的工具: sudo yum update -y sudo yum install -y wget unzip gi…...

开源一个react路由缓存库
Github仓库 背景 产品希望可以像浏览器那样每打开一个路由,会多一个tab,用户可以切换tab访问之前加载过的页面,且不会重新加载。真就产品一句话…… Github上有轮子了吗 Github上开箱即用的轮子是基于react-router-dom V5实现的ÿ…...

go-kratos 学习笔记(7) 服务发现服务间通信grpc调用
服务发现 Registry 接口分为两个,Registrar 为实例注册和反注册,Discovery 为服务实例列表获取 创建一个 Discoverer 服务间的通信使用的grpc,放到data层,实现的是从uses服务调用orders服务 app/users/internal/data.go 加入 New…...

SPSS个人版是什么软件
SPSS是一款数据统计、分析软件,它由IBM公司出品,这款软件平台提供了文本分析、大量的机器学习算法、数据分析模型、高级统计分析功能等,软件易学且功能非常强大,可以使用SPSS制作图表,例如柱状、饼状、折线等图表&…...

Minos 多主机分布式 docker-compose 集群部署
参考 docker-compose搭建多主机分布式minio - 会bk的鱼 - 博客园 (cnblogs.com) 【运维】docker-compose安装minio集群-CSDN博客 Minio 是个基于 Golang 编写的开源对象存储套件,虽然轻量,却拥有着不错的性能 中文地址:MinIO | 用于AI的S3 …...

Unity + Hybridclr + Addressable + 微信小程序 热更新报错
报错时机: Generate All 怎么All 死活就是报错 生成微信小程序,并启动后 报错内容: MissingMethodException:AoT generic method notinstantiated in aot.assembly:Unity.ResourceManager:dll, 原因: Hybridclr 开发文档 解…...

鸿蒙开发—黑马云音乐之Music页面
目录 1.外层容器效果 2.信息区-发光效果 3.信息区-内容布局 4.播放列表布局 5.播放列表动态化 6.模拟器运行并配置权限 效果: 1.外层容器效果 Entry Component export struct MuiscPage {build() {Column() {// 信息区域Column() {}.width(100%)// .backgroun…...

IsaacLab | 如何在Manipulation任务中添加新的目标(target)
如是我闻: 终于让我给摸索出来了,在这里描述一下问题场景。 假使说我们有一个机械臂操作的任务,这样婶的 Isaac Lab | Push 我们想做多目标的任务,这时候需要向环境中添加第二个目标,像这样 Isaac Lab | Add target 那…...

【Python从入门到进阶】61、Pandas中DataFrame对象的操作(二)
接上篇《60、Pandas中DataFrame对象的操作(一)》 上一篇我们讲解了DataFrame对象的简介、基本操作及数据清洗相关的内容。本篇我们来继续讲解DataFrame对象的统计分析、可视化以及数据导出与保存相关内容。 一、DataFrame的统计分析 在数据分析和处理中…...

Linux(虚拟机)的介绍
Linux介绍 常见的操作系统 Windows:微软公司开发的一款桌面操作系统(闭源系统)。版本有dos,win98,win NT,win XP , win7, win vista. win8, win10,win11。服务器操作系统:winserve…...

CSS(九)——CSS 轮廓(outline)
CSS 轮廓(outline) 轮廓(outline)是绘制于元素周围的一条线,位于边框边缘的外围,可起到突出元素的作用。 轮廓(outline)属性指定元素轮廓的样式、颜色和宽度。 让我们用一个图来看…...

Unity Timeline:构建复杂动画序列的利器
Unity的Timeline是一个强大的动画工具,它允许开发者创建复杂的动画序列,将动画、音频和事件整合到一个统一的时间轴上。Timeline的可视化编辑界面使得动画制作变得更加直观和灵活。本文将介绍Unity Timeline的基本概念、功能以及如何使用它来实现动画。 …...

C# 与C++ cli
cli CLI(Command Line Interface)是一种通过命令行界面与计算机系统进行交互的方式。它提供了一种以文本形式输入命令和接收系统输出的方法,用于执行各种操作和管理计算机系统。以下是CLI的详细解释: 一、定义与基本概念 定义&…...

Linux文件编程--打开及创建
...

Vue3点击按钮实现跳转页面并携带参数
前提:有完整的路由规则 1.源页面 <template><div><h1>源页面</h1><!--通过js代码跳转--><template #default"scope"><button click"toTargetView(scope.row)">点击跳转携带参数</button><…...

探索Linux-1-虚拟机远程登陆XShell6远程传输文件Xftp6
Linux是什么? Linux是一个开源的操作系统内核,由林纳斯托瓦兹(Linus Torvalds)于1991年首次发布。它基于Unix操作系统,但提供了更多的自由和灵活性。Linux内核是操作系统的核心部分,负责管理系统资源、处理…...

SpringBoot中使用监听器
1.定义一个事件 /*** 定义事件* author hrui* date 2024/7/25 12:46*/ public class CustomEvent extends ApplicationEvent {private String message;public CustomEvent(Object source, String message) {super(source);this.message message;}public String getMessage() …...

mybatise全接触-面试宝典-知识大全
1 . 简述什么是Mybatis和原理 ? Mybatis工作原理: (1)Mybatis是一个半ORM(对象关系映射)框架,它内部封装了JDBC,加载驱动、创建连接、创建statement等繁杂的过程,开发者…...

Catalyst优化器:让你的Spark SQL查询提速10倍
目录 1 逻辑优化阶段 2.1 逻辑计划解析 2.2 逻辑计划优化 2.2.1 Catalys的优化过程 2.2.2 Cache Manager优化 2 物理优化阶段 2.1 优化 Spark Plan 2.1.1 Catalyst 的 Join 策略 2.1.2 如何决定选择哪一种 Join 策略 2.2 Physical Plan 2.2.1 EnsureRequirements 规则 3 相关文…...

django基于在线音乐分享的社交网站全vue
目录功能模块划分技术架构设计核心功能实现性能优化方案测试策略部署方案项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作功能模块划分 用户模块 注册/登录(邮箱/手机号验证)个人资料管理(头像…...

Eigen矩阵打印踩坑记:从乱码到优雅输出的3个关键技巧与一个隐藏Bug
Eigen矩阵打印踩坑记:从乱码到优雅输出的3个关键技巧与一个隐藏Bug 第一次在ROS项目里调试Eigen矩阵时,我盯着终端里歪歪扭扭的数字对齐和突然冒出的科学计数法,花了整整两小时才意识到这不是算法问题,而是输出格式在作祟。Eigen作…...
及其特性对比)
实战指南:利用Python可视化常见激活函数(Sigmoid、Tanh、ReLU、PReLU)及其特性对比
1. 为什么需要可视化激活函数? 在深度学习的世界里,激活函数就像是神经网络的"开关",决定了神经元是否应该被激活。但很多初学者在学习时,往往只是死记硬背公式,却不知道这些函数长什么样、在什么情况下会有…...

从零到一:超外差收音机DIY全流程解析与调试心法
1. 超外差收音机原理精要 第一次接触超外差收音机时,我被这个拗口的专业名词吓到了。但拆解开来理解其实很简单——"超"指的是本振频率超过信号频率,"外差"则是混频产生差频的过程。这种设计巧妙地把不同电台信号都转换成固定的465k…...

Arduino Nano与SSD1306实战:从静态位图到动态动画的完整实现
1. Arduino Nano与SSD1306 OLED屏入门指南 如果你手头正好有一块Arduino Nano开发板和SSD1306驱动的OLED屏幕,想要实现从静态图片显示到动态动画的效果,那这篇文章就是为你准备的。我最近在做一个智能家居项目时,正好用到了这个组合ÿ…...
)
Windows系统管理员必备:LastActivityView详细使用指南(含数据导出技巧)
Windows系统管理员必备:LastActivityView深度实战手册 作为Windows系统管理员,我们常常需要追踪用户活动、排查异常行为或进行合规审计。市面上虽然有不少商业监控工具,但NirSoft出品的LastActivityView以其轻量高效、数据全面且完全免费的特…...

3分钟掌握医学文献关键信息:本草模型如何从肝癌研究中提取核心知识
3分钟掌握医学文献关键信息:本草模型如何从肝癌研究中提取核心知识 【免费下载链接】Huatuo-Llama-Med-Chinese Repo for BenTsao [original name: HuaTuo (华驼)], Instruction-tuning Large Language Models with Chinese Medical Knowledge. 本草(原名…...

【stm32_2.1】【快速入门】自举模式、Flash闪存、LED点灯——对二极管PN结解析
目录 当前MCU概述 固化程序到单片机 自举模式 自举配置 Flash闪存 二极管的原理 当前MCU概述 MCU名称stm32F407ZET6处理器主频168MHz 闪存容量 512KB静态随机访问存储器SRAM192KBMCU引脚数量144pin 固化程序到单片机 写好的程序要固化到单片机,就必须学习怎…...
)
【2026年阿里巴巴春招- 3月28日-算法岗-第二题- 隐式素数计算】(题目+思路+JavaC++Python解析+在线测试)
题目内容 我们称一个正整数为隐式素数,如果它不同的正因子的个数是一个素数。给定一个闭区间$ [l,r]$,请计算该区间内隐式素数的个数 输入描述 每个测试文件均包含多组测试数据。第一行输入一个整数$ T (1 ≤ T ≤ 10^4)$,代表数据组数,每组测试数据描述如下: 在一行上…...
)
运维工程师必看:如何用因果AI+DeepSeek实现3分钟精准故障定位(实战案例)
运维工程师必看:如何用因果AIDeepSeek实现3分钟精准故障定位(实战案例) 在当今复杂的云原生和微服务架构环境中,运维工程师面临的挑战前所未有。系统组件间的依赖关系错综复杂,一个微小的故障可能引发连锁反应…...