1_初识pytorch
之前完全没有了解过深度学习和pytorch,但现在因为某些原因不得不学了。不得不感叹,深度学习是真的火啊。纯小白,有错的欢迎指正~
参考视频:PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】_哔哩哔哩_bilibili
不得不夸一句,这个老师讲的很仔细了,并且他排查错误和查找函数使用方法的方式让我受益匪浅。
顺带提一嘴,因为项目原因,我没有使用老师用的pycharm,用的是vscode。
教学视频中所使用的数据集可以去翻找评论区,里面就有。
下载过程我就不重复了,其实我也重下了好几次,一度崩溃了,一不小心c盘就爆了o(╥﹏╥)o。
---------------------------------------------------------------------------------------------------------------------------------
目录
加载数据初认识
Dataset
Dataloader
Tensorboard的使用
Transform的使用
常见的Transform.py文件中所使用的类
ToPILImage类
Normalize类
Resize类
Compose类
RandomCrop类
总结
torchvision中的数据集使用
---------------------------------------------------------------------------------------------------------------------------------
加载数据初认识
pytorch中带有加载处理数据的工具,以下就是其中两个很常用到的工具。
Dataset
作用:提供一种方式获取数据及label、告诉我们总共有多少数据。
也就是说,我们可以通过重写这个类,来构造我们自己的数据集,方便后面进行深度学习的训练操作。
引入方式如下:
#注意大小写,这里导入的是Dataset类,不是dataset文件
from torch.utils.data import Dataset跟着up主学习了一种新的掌握新工具的方式,使用python中自带的help函数可以快速查看用法。比如这个dataset。
在vscode中直接输入:
help(Dataset)运行之后会在终端出现如下内容:
class Dataset(typing.Generic)| Dataset(*args, **kwds)|| An abstract class representing a :class:`Dataset`.|
'''
以下这段提到,所有继承Dataset的子类都需要重写__getitem__方法,可有选择的重写__len__方法
'''| All datasets that represent a map from keys to data samples should subclass| it. All subclasses should overwrite :meth:`__getitem__`, supporting fetching a| data sample for a given key. Subclasses could also optionally overwrite| :meth:`__len__`, which is expected to return the size of the dataset by many| :class:`~torch.utils.data.Sampler` implementations and the default options| of :class:`~torch.utils.data.DataLoader`.|| .. note::| :class:`~torch.utils.data.DataLoader` by default constructs a index| sampler that yields integral indices. To make it work with a map-style| dataset with non-integral indices/keys, a custom sampler must be provided.|| Method resolution order:| Dataset| typing.Generic| builtins.object|| Methods defined here:|| __add__(self, other: 'Dataset[T_co]') -> 'ConcatDataset[T_co]'|| __getitem__(self, index) -> +T_co
-- More --那么接下来,我们就来写一个类继承Dataset类:
from torch.utils.data import Dataset
from PIL import image
import os
class MyData(Dataset):#自定义构造方法,这里我们希望获取图片路径,把图片读入def __init__(self,root_dir,label_dir):self.root_dir=root_dirself.label_dir=label_dirself.path=os.path.join(root_dir,label_dir)self.img_path=os.listdir(self.path)#重写__getitem__方法,这个方法的重写可以帮助我们调取数据集中的某一个数据def __getitem__(self, index):img_name=self.img_path[index]img_item_path=os.path.join(self.root_dir,self.label_dir,img_name)img=image.open(img_item_path)label=self.label_dirreturn img,label#返回数据集长度(数据的个数)def __len__(self):return len(self.img_path)root_dir="d:\\Desktop\\hymenoptera_data\\train"
ants_label_dir="ants"
#实例化对象,传入构造参数后,这个对象就已经导入了我们想要的数据集
ants_dataset=MyData(root_dir,ants_label_dir)
#使用索引的方式,这里的[index]与上面__getitem__函数中的index相对应,可以单独调出其中某一张图片(数据)
img,label=ants_dataset[0]Dataloader
作用:为后面的网络提供不同的数据形式
提示:这个可以放到这一篇结尾看。有用到后面的知识!
DataLoader 在内部使用 Dataset 对象来加载数据。它接收一个 Dataset 对象作为参数,并从该对象中按需加载数据。因此,Dataset 提供了数据的抽象表示和访问接口,而 DataLoader 则封装了批处理和数据加载的逻辑。
个人理解为,dataset之前有讲,其实是我们自定义一个类继承它,就可以实现完整的数据集的导入(它会告诉程序数据集在什么地方);而在训练模型过程中,我们使用dataloader来抽取其中的某一些数据。
这里照搬官方文档的定义,当然大家可以选择自己去官网看:
网址:torch.utils.data — PyTorch 2.4 documentation
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=None, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None, generator=None, *, prefetch_factor=None, persistent_workers=False, pin_memory_device='')介绍一下这个类的常用参数,部分会以视频上老师说的打牌例子来介绍,假如说dataset就是一摞牌,那么dataloader就是我们抽到手里的牌:
- dataset:我们的数据集
- batch_size:指定每一次取数据集中的多少个数据,默认1(一次抽取多少张牌)
- shuffle:指定数据集在每次抽取时是否重新排列,默认False(每次抽牌前是否洗牌)
- num_workers:采用单进程还是多进程,默认为0
- drop_last:当除不尽时,是否舍弃)(比如一共有100张牌,要求每次取三张,那么到最后有1张多余,这个参数用于设置是否把最后一张舍弃掉)
上视频截图:

当设置batch_size为4时,dataloader会从dataset中抽取四个数据出来,并将他们的img打包为imgs,把target打包为targets。
import torchvision
from torch.utils.data import DataLoader
tensor_trans=torchvision.transforms.ToTensor()
#注意这里传入的是一个列表
trans_compose=torchvision.transforms.Compose([tensor_trans])
#准备一个测试数据集
test_set=torchvision.datasets.CIFAR10(root="./dataset",train=False,download=True,transform=trans_compose)
test_loader=DataLoader(dataset=test_set,batch_size=4,shuffle=True,num_workers=0,drop_last=False)#测试集中的第一张图片及target
img,target=test_set[0]
print(img.shape)
print(target)for data in test_loader:imgs,targets=dataprint(imgs.shape)print(targets)打印结果的部分截图:

imgs打印:torch,Size([4,3,32,32]):4代表4张图片;3代表3通道;32,32代表32*32大小的图片
下面的tensor代表targets
我们也可以使用tensorboard查看一下结果:
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
tensor_trans=torchvision.transforms.ToTensor()
#注意这里传入的是一个列表
trans_compose=torchvision.transforms.Compose([tensor_trans])
#准备一个测试数据集
test_set=torchvision.datasets.CIFAR10(root="./dataset",train=False,download=True,transform=trans_compose)
test_loader=DataLoader(dataset=test_set,batch_size=4,shuffle=True,num_workers=0,drop_last=False)#测试集中的第一张图片及target
# img,target=test_set[0]
# print(img.shape)
# print(target)writer=SummaryWriter("Logs")
step=0
for data in test_loader:imgs,targets=data# print(imgs.shape)# print(targets)writer.add_images("test_data",imgs,step)step=step+1writer.close()这里忘改batch_size了,老师视频上把这个改成了64,所以我这里仍是4张图片一组,可以看到结果是这样的:

Tensorboard的使用
TensorBoard 是 TensorFlow 的一个可视化工具,用于展示 TensorFlow 训练过程中的各种数据和指标。它提供了一个直观的界面,帮助开发者更好地理解、调试和优化他们的机器学习模型。
主要功能包括:
-
可视化模型图:
- TensorBoard 可以展示 TensorFlow 模型的计算图,这对于理解模型的结构和流程非常有帮助。你可以在 TensorBoard 中清晰地看到各个层之间的连接和数据流动。
-
训练指标:
- 在训练过程中,TensorBoard 可以实时地展示训练和验证集的损失值、准确率、学习率等指标的变化情况。这些指标可以帮助开发者监控模型的训练进度和性能表现。
-
直方图和分布图:
- TensorBoard 可以展示各个变量的直方图和分布图。这些图表能够帮助你了解权重、偏置和梯度等变量的分布情况,有助于调试和优化模型的训练过程。
-
嵌入式数据可视化:
- 如果你的模型包含嵌入层(Embedding),TensorBoard 可以将嵌入向量在高维空间中进行可视化,帮助你理解和分析这些向量的含义和关系。
-
计算图的操作和时间线:
- TensorBoard 还提供了一个操作面板,显示图中的操作(ops)和其用法。此外,时间线功能可以帮助你查看 TensorFlow 操作在时间上的分布和性能瓶颈。
使用 TensorBoard 需要将相关数据写入到 TensorFlow 的事件文件中,然后通过命令行启动 TensorBoard 服务,可以在浏览器中查看可视化界面。
但现在,tensorboard不仅可以在tensorflow中使用,也可以单独使用,它将会对我们理解模型的训练过程十分有帮助,因此来简单学习它的使用方法。
在py文件中导入tensorboard:
from torch.utils.tensorboard import SummaryWriter按住ctrl鼠标单击SummaryWriter可以查看这个类的使用方法,其中提供了一个使用例子:
"""
Examples::from torch.utils.tensorboard import SummaryWriter# create a summary writer with automatically generated folder name.writer = SummaryWriter()# folder location: runs/May04_22-14-54_s-MacBook-Pro.local/# create a summary writer using the specified folder name.writer = SummaryWriter("my_experiment")# folder location: my_experiment# create a summary writer with comment appended.writer = SummaryWriter(comment="LR_0.1_BATCH_16")# folder location: runs/May04_22-14-54_s-MacBook-Pro.localLR_0.1_BATCH_16/"""接下来,我们介绍两个常用的方法:
from torch.utils.tensorboard import SummaryWriter
#实例化对象
writer=SummaryWriter("Logs")
'''
将要介绍的方法:
writer.add_scalar()
writer.add_image()
'''
writer.close()先来看add_scalar(),还是查看官方文档中给的:
"""Add scalar data to summary.Args:tag (str): Data identifierscalar_value (float or string/blobname): Value to saveglobal_step (int): Global step value to recordwalltime (float): Optional override default walltime (time.time())with seconds after epoch of eventnew_style (boolean): Whether to use new style (tensor field) or oldstyle (simple_value field). New style could lead to faster data loading.
-----------------------------------------------------------------------------------以上这段话在介绍这个方法所包含的形参,tag其实就是图表的标题,global_step是横轴,
scalar_value是纵轴。其他参数相对不重要
-----------------------------------------------------------------------------------Examples::from torch.utils.tensorboard import SummaryWriterwriter = SummaryWriter()x = range(100)for i in x:writer.add_scalar('y=2x', i * 2, i)writer.close()Expected result:.. image:: _static/img/tensorboard/add_scalar.png:scale: 50 %"""如图所示:

就拿上述代码给的例子来实践一下:
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
x = range(100)
for i in x:writer.add_scalar('y=2x', i * 2, i)
writer.close()运行代码,可以看到右边文件夹中多了一个子文件夹(Logs):

接下来在终端找到Logs文件夹下,然后输入:
tensorboard --logdir=D:\vscodeProjects\Logs↑ 记得是使用绝对地址,相对地址会出错的。如图:

打开链接就可以看到:

Transform的使用
在 PyTorch 的 torchvision 库中,transform(转换)指的是一系列的图像预处理操作,用于在数据加载过程中对图像进行变换和处理。这些变换可以应用于数据集的图像,以便于在训练过程中增强数据、标准化数据或使数据更适合于模型训练。
导入:
from torchvision import transforms通过transform.py文件中的ToTensor类,可以实现图像转换为张量的操作,方便后续数据的训练。
from torchvision import transforms
from PIL import Image
#导入图片
img_path="D:\\Desktop\\hymenoptera_data\\train\\ants\\0013035.jpg"
img=Image.open(img_path)#转换张量
tensor_trans=transforms.ToTensor()
tensor_img=tensor_trans(img)视频讲解截图:

这里有一个小的注意事项,ToTensor类接受两种类型的数据:PIL的image类型和numpy的ndarray,因此:
img_path="D:\\Desktop\\hymenoptera_data\\train\\ants\\0013035.jpg"'''可以使用Image读取图像'''
img=Image.open(img_path)'''也可以使用opencv读取图像,这个读入的类型就是ndarray'''
cv_img=cv2.imread(img_path)常见的Transform.py文件中所使用的类
以上的讲解把图像的输入和输出给讲解了。总结一下,输入其实就是两种方式:一个是image格式,一个是ndarray格式,而输出则是使用Transform.py文件中的ToTendor类将上述两种格式转换成tensor(张量)输出,方便后续的操作。
ToPILImage类
作用:把tensor类型或ndarray类型转换回image类型
"""Convert a tensor or an ndarray to PIL Image - this does not scale values.This transform does not support torchscript.Converts a torch.*Tensor of shape C x H x W or a numpy ndarray of shapeH x W x C to a PIL Image while preserving the value range.Args:mode (`PIL.Image mode`_): color space and pixel depth of input data (optional).If ``mode`` is ``None`` (default) there are some assumptions made about the input data:- If the input has 4 channels, the ``mode`` is assumed to be ``RGBA``.- If the input has 3 channels, the ``mode`` is assumed to be ``RGB``.- If the input has 2 channels, the ``mode`` is assumed to be ``LA``.- If the input has 1 channel, the ``mode`` is determined by the data type (i.e ``int``, ``float``,``short``)... _PIL.Image mode: https://pillow.readthedocs.io/en/latest/handbook/concepts.html#concept-modes"""Normalize类
transforms.Normalize 是 torchvision 中的一个转换函数,用于对张量进行标准化处理。它的作用主要是将输入张量的每个通道进行标准化,使得每个通道的均值和标准差符合指定的数值,从而使数据分布更加标准化和稳定。
具体来说,transforms.Normalize 的作用包括:
-
数据标准化:
- 对每个通道进行标准化处理,使得数据在经过标准化后,每个通道的均值为给定的 mean,标准差为给定的 std。
- 这种标准化确保了数据分布的稳定性和一致性,有助于提升模型训练的效果和稳定性。
-
影响模型收敛速度:
- 标准化后的数据分布更加接近标准正态分布或者某个预期的分布,有助于优化算法(如梯度下降)更快地收敛到最优解。
-
防止数据范围过大:
- 在深度学习中,如果输入数据的范围过大,可能会导致激活函数输出非常大的值,从而使得梯度消失或爆炸。标准化可以帮助限制数据的范围,避免这些问题的发生。
"""Normalize a tensor image with mean and standard deviation.This transform does not support PIL Image.Given mean: ``(mean[1],...,mean[n])`` and std: ``(std[1],..,std[n])`` for ``n``channels, this transform will normalize each channel of the input``torch.*Tensor`` i.e.,``output[channel] = (input[channel] - mean[channel]) / std[channel]``.. note::This transform acts out of place, i.e., it does not mutate the input tensor.Args:mean (sequence): Sequence of means for each channel.std (sequence): Sequence of standard deviations for each channel.inplace(bool,optional): Bool to make this operation in-place."""示例:
from torchvision import transforms
from PIL import Imageimg_path = "D:\\Desktop\\hymenoptera_data\\train\\ants\\0013035.jpg"
img = Image.open(img_path)# 将 PIL 图片转换为 PyTorch 的张量
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)# 输出张量中第一个通道、第一个像素的像素值
print(tensor_img[0][0][0])# 定义标准化转换,均值和标准差都为 0.5
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])# 对张量化后的图像进行标准化
img_norm = trans_norm(tensor_img)# 输出标准化后张量中第一个通道、第一个像素的像素值
print(img_norm[0][0][0])
Resize类
transform.Resize 类是 torchvision 中的一个转换类,用于调整图像的尺寸大小。其主要作用是将输入的 PIL 图像或者张量(Tensor)调整为指定的尺寸。
"""Resize the input image to the given size.If the image is torch Tensor, it is expectedto have [..., H, W] shape, where ... means an arbitrary number of leading dimensionsArgs:size (sequence or int): Desired output size. If size is a sequence like(h, w), output size will be matched to this. If size is an int,smaller edge of the image will be matched to this number.i.e, if height > width, then image will be rescaled to(size * height / width, size)."""
from torchvision import transforms
from PIL import Image
import cv2
#导入图片
img_path="D:\\Desktop\\hymenoptera_data\\train\\ants\\0013035.jpg"
img=Image.open(img_path)#转换张量
tensor_trans=transforms.ToTensor()
tensor_img=tensor_trans(img)trans_resize=transforms.Resize((512,512))
img_resize=trans_resize(img)
print(img_resize)'''
运行输出:
<PIL.Image.Image image mode=RGB size=512x512 at 0x272ACCEE7C0>'''Compose类
可以注意到,上述使用resize变换前后都是image类型,为了方便操作,transform提供了一个类专门用来自定义流水线工程。我们可以把任意多个transform组合起来封装成一个compose对象,然后就可以简化我们的步骤了。
作用:把多个transform操作结合在一起。
"""Composes several transforms together. This transform does not support torchscript.Please, see the note below.Args:transforms (list of ``Transform`` objects): list of transforms to compose.Example:>>> transforms.Compose([>>> transforms.CenterCrop(10),>>> transforms.PILToTensor(),>>> transforms.ConvertImageDtype(torch.float),>>> ]).. note::In order to script the transformations, please use ``torch.nn.Sequential`` as below.>>> transforms = torch.nn.Sequential(>>> transforms.CenterCrop(10),>>> transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),>>> )>>> scripted_transforms = torch.jit.script(transforms)Make sure to use only scriptable transformations, i.e. that work with ``torch.Tensor``, does not require`lambda` functions or ``PIL.Image``."""from torchvision import transforms
from PIL import Image
import cv2
#导入图片
img_path="D:\\Desktop\\hymenoptera_data\\train\\ants\\0013035.jpg"
img=Image.open(img_path)#将resize和totensor操作流水线化
trans_resize=transforms.Resize((512,512))
tensor_trans=transforms.ToTensor()
#注意这里传入的是一个列表
trans_compose=transforms.Compose([trans_resize,tensor_trans])
#对图像只需要调用compose对象即可进行resize和totensor操作
img_resize_2=trans_compose(img)RandomCrop类
主要作用是从输入的图像或张量中随机裁剪出指定大小的区域。
from torchvision import transforms
from PIL import Image
import cv2
#导入图片
img_path="D:\\Desktop\\hymenoptera_data\\train\\ants\\0013035.jpg"
img=Image.open(img_path)
transforms.RandomCrop
tensor_trans=transforms.ToTensor()
trans_random=transforms.RandomCrop(512)
#注意这里传入的是一个列表
trans_compose_1=transforms.Compose([trans_random,tensor_trans])
#对图像只需要调用compose对象即可进行resize和totensor操作
img_compose_1=trans_compose_1(img)
print(img_compose_1)总结
1、关注每个工具的输入输出类型。
2、多看官方文档。
3、关注方法所需要的参数。
torchvision中的数据集使用
官方文档网址:
https://pytorch.org/docs/stable/index.html
import torchvision
train_set=torchvision.datasets.CIFAR10(root="./dataset",train=True,download=True)
test_set=torchvision.datasets.CIFAR10(root="./dataset",train=False,download=True)
print(test_set[0])这里提一嘴,用相对路径下载后,我以为它会在当前py文件所在的文件夹的上级文件夹下新建dataset文件夹,但没想到它跑到了我之前建立的那个Logs文件夹下:

原因在于我的命令行仍停留在Logs文件夹里,记得执行cd..命令返回:
![]()
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor()
])
train_set=torchvision.datasets.CIFAR10(root="./dataset",train=True,download=True,transform=dataset_transform)
test_set=torchvision.datasets.CIFAR10(root="./dataset",train=False,download=True,transform=dataset_transform)writer=SummaryWriter('p1')
for i in range(10):img,tarfet=test_set[i]writer.add_image("test_set",img,i)writer.close()
命令行运行:

结果成功:

相关文章:
1_初识pytorch
之前完全没有了解过深度学习和pytorch,但现在因为某些原因不得不学了。不得不感叹,深度学习是真的火啊。纯小白,有错的欢迎指正~ 参考视频:PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆…...
的使用)
c++typeid()的使用
用处: typeid()函数主要用来获取对应类型或者变量的类型信息,其返回一个std::type_info的对象,这个对象中存放了对应类型的具体信息。 所以typeid()函数就是获取一个type_info的类型,然后可以通过此类型来获取到相应的类型信息。 type_info的…...

【面向就业的Linux基础】从入门到熟练,探索Linux的秘密(十四)-租云服务器及配环境、docker基本命令
主要介绍了租云服务器和docker配置、基本命令!!! 文章目录 前言 一、云平台 二、租云服务器及安装docker 1.阿里云 2.安装docker 三、docker命令 将当前用户添加到docker用户组 镜像(images) 容器(container) 四、实战…...

实现一个全栈模糊搜索匹配的功能
提供一个全栈实现的方案,包括 Vue 3 前端、Express 后端和 MySQL 数据库的分类模糊搜索功能。让我们逐步来看: 1. 数据库设计 (MySQL) 首先,我们需要一个存储分类的表: CREATE TABLE categories (id INT AUTO_INCREMENT PRIMAR…...

智慧景区导览系统小程序开发
智慧景区导览系统小程序的开发是一个综合性的过程,旨在通过先进的技术手段提升游客的游览体验。以下是开发智慧景区导览系统小程序的主要步骤和关键点: 一、需求分析 市场调研:了解旅游市场的最新趋势和游客的实际需求,包括游客…...

HIVE调优方式及原因
3.HIVE 调优: 需要调优的几个方面: 1.HIVE语句执行不了 2.HIVE查询语句,在集群中执行时,数据无法落地 HIVE执行时,一开始语句检查没有问题,生成了多个JOB, …...

deploy local llm ragflow
CPU > 4 cores RAM > 16 GB Disk > 50 GB Docker > 24.0.0 & Docker Compose > v2.26.1 下载docker: 官方下载方式:https://docs.docker.com/desktop/install/ubuntu/ 其中 DEB package需要手动下载并传输到服务器 国内下载方式&…...

测桃花运(算姻缘)的网站系统源码
简介: 站长安装本源码后只要有人在线测算,就可以获得收入哦。是目前市面上最火的变现利器。 本版本无后台,无数据。本版本为开发的逗号联盟接口版本。直接对接逗号联盟,修改ID就可以直接运营收费赚钱。 安装环境:PH…...

电商平台优惠券
优惠券业务逻辑 优惠券的发放: 来源:优惠券可以由平台统一发放,也可以由商家自行发放。平台优惠券的优惠由平台承担,而店铺优惠券则由商家承担。类型:优惠券可以分为满减优惠券、无门槛优惠券等,根据使用限…...

内衣洗衣机多维度测评对比,了解觉飞、希亦、鲸立哪款内衣洗衣机更好
想要代替手洗内衣物,那么一台内衣专用的小型洗衣机就必不可少啦,不仅能够为我们节约更多的时间以及精力,还能大大提高内衣物的卫生,面对于市面上各种各样的小型内衣洗衣机,相信很多小伙伴都无从下手! 为一…...

数据结构和算法入门
1.了解数据结构和算法 1.1 二分查找 二分查找(Binary Search)是一种在有序数组中查找特定元素的搜索算法。它的基本思想是将数组分成两半,然后比较目标值与中间元素的大小关系,从而确定应该在左半部分还是右半部分继续查找。这个…...
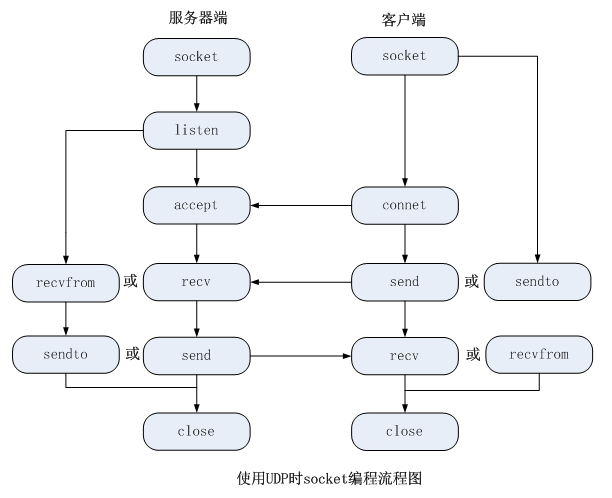
基于OpenCV C++的网络实时视频流传输——Windows下使用TCP/IP编程原理
1.TCP/IP编程 1.1 概念 IP 是英文 Internet Protocol (网络之间互连的协议)的缩写,也就是为计算机网络相互连接进行通信而设计的协议。任一系统,只要遵守 IP协议就可以与因特网互连互通。 所谓IP地址就是给每个遵循tcp/ip协议连…...
CAN_FD 总线协议详解6- PL(物理层)规定3)
(BS ISO 11898-1:2015)CAN_FD 总线协议详解6- PL(物理层)规定3
目录 6.4 AUI 规范 6.4.1 一般规定 6.4.2 PCS 到 PMA 消息 6.4.2.1 输出消息 6.4.2.2 Bus_off 消息 6.4.2.3 Bus_off 释放消息 6.4.2.4 FD_Transmit 消息 6.4.2.5 FD_Receive 消息 6.4.3 PMA 到 PCS 消息 6.4.3.1 输入消息 如果有不懂的问题可在评论区点赞后留言&…...

docker环境下php安装扩展步骤 以mysqli为例
docker环境下php安装扩展步骤 以mysqli为例 1.0 前言2.0 php 扩展安装原理3.0 docker 环境下 php 扩展安装3.1 docker php 容器扩展安装路径及原理3.2 docker php 扩展脚本安装过程 同步发布在个人笔记[docker环境下php安装扩展步骤 以mysqli为例]( https://blog.lichenrobo.co…...

医院综合绩效核算系统,绩效核算系统源码,采用springboot+avue+MySQL技术开发,可适应医院多种绩效核算方式。
一、系统概述 作为医院用综合绩效核算系统,系统需要和his系统进行对接,按照设定周期,从his系统获取医院科室和医生、护士、其他人员工作量,对没有录入信息化系统的工作量,绩效考核系统设有手工录入功能(可…...
ROOM数据快速入门
ROOM数据库快速入门 文章目录 ROOM数据库快速入门第一章 准备工作第01节 引入库第02节 布局文件第03节 activity类第04节 效果图 第二章 数据类第01节 实体类(表)第02节 数据访问类(DAO)第03节 数据Service层第04节 RoomDataBase …...

刷新,前面接口的返回值没有到,第二个接口已经请求完了,导致第二个接口返回数据错误
刷新,前面接口的返回值没有到,(前端)第二个接口已经请求完了(入参没有拿前面那个接口返回的数据),导致第二个接口返回数据错误...

pdcj设计
为了实现这些功能需求,我们需要设计多个数据库表来存储相关的数据,并编写相应的Java代码来处理业务逻辑。下面是各个功能需求对应的MySQL表结构以及部分Java代码示例。 商品设置管理 商品分类管理 商品分类表 (product_categories)CREATE TABLE produ…...

【数据结构】哈希表的模拟实现
文章目录 1. 哈希的概念2. 哈希表与哈希函数2.1 哈希冲突2.2 哈希函数2.3 哈希冲突的解决2.3.1 闭散列(线性探测)2.3.2 闭散列的实现2.3.3 开散列(哈希桶)2.3.4 开散列的实现 2.4 开散列与闭散列比较 1. 哈希的概念 在我们之前所接触到的所有的数据结构…...

面试经典算法150题系列-数组/字符串操作之多数元素
序言:今天是第五题啦,前面四题的解法还清楚吗?可以到面试算法题系列150题专栏 进行复习呀。 温故而知新,可以为师矣!加油,未来的技术大牛们。 多数元素 给定一个大小为 n 的数组 nums ,返回其…...

Navicat Premium试用期重置终极指南:三步恢复完整14天试用
Navicat Premium试用期重置终极指南:三步恢复完整14天试用 【免费下载链接】navicat-premium-reset-trial Reset macOS Navicat Premium 15/16/17 app remaining trial days 项目地址: https://gitcode.com/gh_mirrors/na/navicat-premium-reset-trial 你是否…...

终极AI音乐创作工具:5分钟生成专业级歌曲翻唱
终极AI音乐创作工具:5分钟生成专业级歌曲翻唱 【免费下载链接】AICoverGen A WebUI to create song covers with any RVC v2 trained AI voice from YouTube videos or audio files. 项目地址: https://gitcode.com/gh_mirrors/ai/AICoverGen 你是否曾经梦想…...

BurpBounty配置文件完全解析:从API密钥到SQL注入检测
BurpBounty配置文件完全解析:从API密钥到SQL注入检测 【免费下载链接】BurpBounty Burp Bounty (Scan Check Builder in BApp Store) is a extension of Burp Suite that allows you, in a quick and simple way, to improve the active and passive scanner by mea…...

三步破解安全研发合规难题:Gitee软件工厂助力GJB5000B与等保三级高标准落地
TL;DR 国家安全领域软件研发需同时满足GJB5000B、等保2.0三级等强制合规要求与智能化装备带来的软件复杂度挑战。传统研发模式在协作、安全、交付三方面日益乏力。Gitee软件工厂通过“统一底座、细粒度权限、标准化流程”三大核心能力,内置SM2/SM4国密加密、IP白名单…...

【AI】多阶段执行:分阶段完成大型任务
多阶段执行:分阶段完成大型任务📝 本章学习目标:本章介绍流程编排,让AI Agent执行更加规范可控。通过本章学习,你将全面掌握"多阶段执行:分阶段完成大型任务"这一核心主题。一、引言:…...

群晖NAS远程SSH配置全解:从权限控制到独立模式实战
1. 为什么群晖的SSH不是“开个开关”就完事——从权限失控风险说起群晖NAS作为家用与小型办公场景中最普及的存储设备,很多人买来装好硬盘、配好共享文件夹,就觉得万事大吉。直到某天想批量处理照片缩略图、想用rsync做异地备份、想部署一个轻量级服务&a…...

SQL出现filesort 一定慢吗
前言:filesort 出现在当无法使用索引排序时,MySQL 必须自己计算排序顺序,这个过程称为 filesort。EXPLAIN 的 Extra 字段会出现 Using filesort。常见触发场景:排序列不在索引中,或顺序/方向与索引不一致ORDER BY 包含…...
)
别再只算差异了!用Cytoscape给Hub Gene分析加个‘可视化Buff’(附脑网络实战图)
别再只算差异了!用Cytoscape给Hub Gene分析加个‘可视化Buff’(附脑网络实战图) 在生物信息学分析中,差异基因筛选往往是研究的第一步,但如何从海量差异基因中找出真正具有生物学意义的"关键调控者"…...

交易所技术三重门:吞吐量、安全性与合规性的不可能三角破解之道
引言:交易所战争进入3.0时代 当Coinbase市值突破千亿美元,当Binance单日交易量超越纳斯达克,当Uniswap用AMM机制改写交易规则——数字货币交易所已从边缘实验进化为金融基础设施的核心。在这场价值万亿美元的军备竞赛中,技术架构的…...

原来赛事专用匹克球工厂还有这么多门道?你了解吗?
引言在匹克球运动蓬勃发展的当下,赛事专用匹克球的品质至关重要。而赛事专用匹克球工厂背后,其实隐藏着诸多门道。泉州凯瑞麟体育用品有限公司作为行业内的佼佼者,在这方面有着独特的技术与经验。核心材料与技术创新赛事专用匹克球对核心材料…...