基于python的BP神经网络红酒品质分类预测模型
1 导入必要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.callbacks import EarlyStopping
from sklearn.metrics import classification_report, confusion_matrix
# 忽略Matplotlib的警告(可选)
import warnings
warnings.filterwarnings("ignore")
# 设置中文显示和负号正常显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False2 数据加载与预处理
# 读取数据
df = pd.read_csv('train.csv') # 处理缺失值(这里假设我们删除含有缺失值的行)
df.dropna(inplace=True) # 处理重复值(这里选择删除重复的行)
df.drop_duplicates(inplace=True) # 将'wine types'列的文本转换为数值
df['wine types'] = df['wine types'].map({'red': 1, 'white': 2})
# 假设'quality'是我们要预测的标签
X = df.drop('quality', axis=1)
y = df['quality']3 数据探索
# 选择绘制特征数据的折线图
X_columns_to_plot = X.columnsdf_plot = df[X_columns_to_plot] df_plot.plot(subplots=True, figsize=(15, 15))
plt.tight_layout()
plt.show()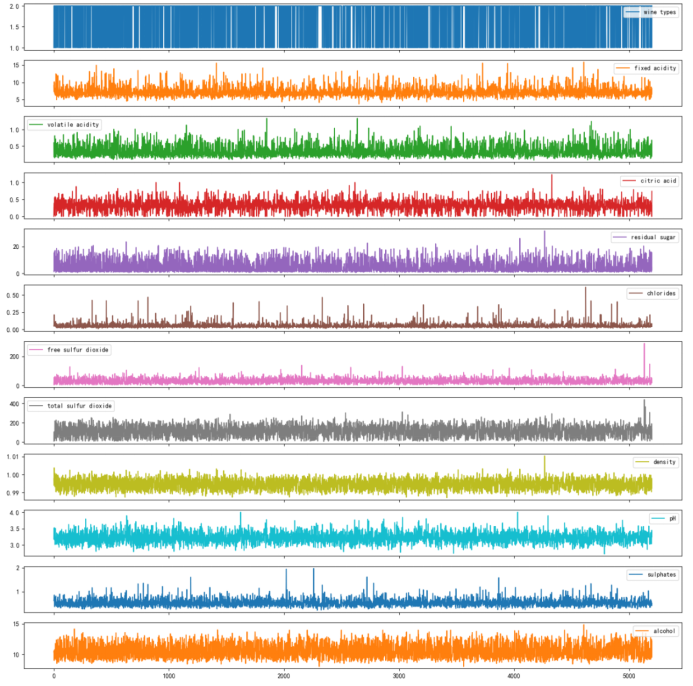
图 3-1
4 BP神经网络模型构建
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler # 分离特征和标签
X = df.drop('quality', axis=1)
y = df['quality'] # 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 特征缩放
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test) # 构建模型
model = Sequential([ Dense(64, activation='relu', input_shape=(X_train_scaled.shape[1],)), Dense(32, activation='relu'), Dense(10, activation='softmax') # 假设有10个类别,根据实际情况调整
]) # 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) # 训练模型
history = model.fit(X_train_scaled, y_train, epochs=100, validation_split=0.2, verbose=1)
图 4-1
5 训练评估可视化
# 绘制训练和验证的准确率与损失
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], color='#B0D5DF',label='Training Accuracy')
plt.plot(history.history['val_accuracy'], color='#1BA784',label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend() plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], color='#D11A2D',label='Training Loss')
plt.plot(history.history['val_loss'], color='#87723E', label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()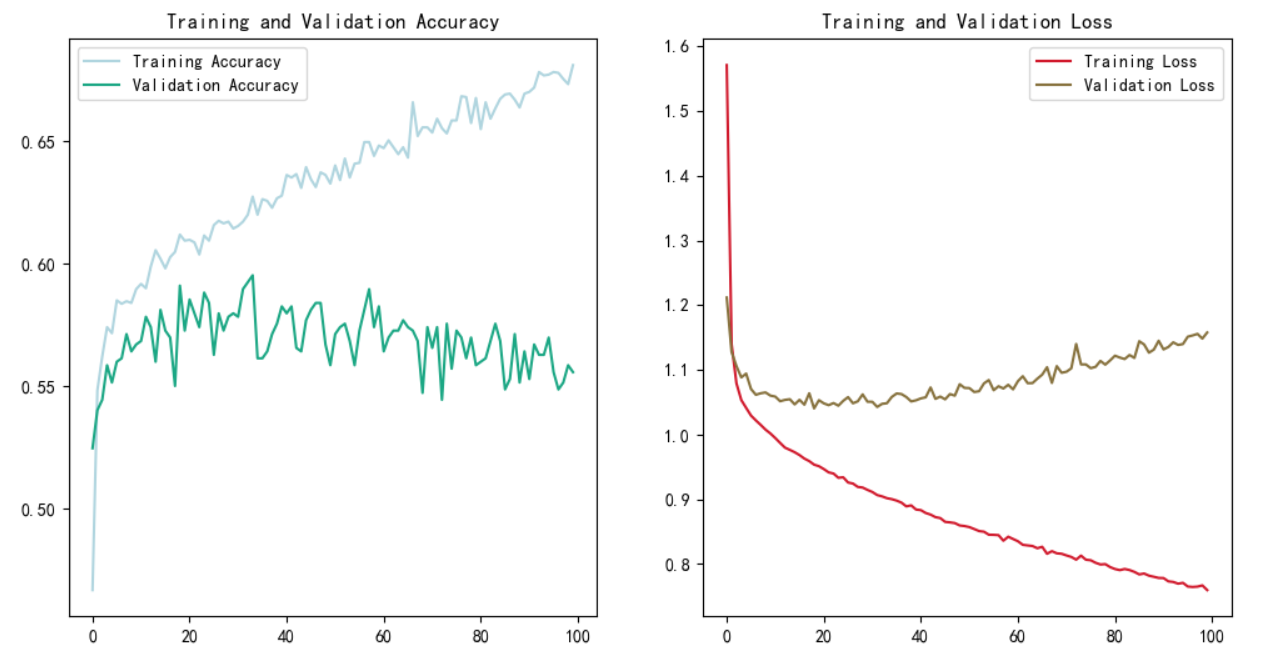
图 5-1 过拟合
成功过拟合了,其实早有预料,我手里的数据集都挺顽固的,训练效果都不好。
6 正则化
这里采用L2正则化
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.regularizers import l2
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler # 分离特征和标签
X = df.drop('quality', axis=1)
y = df['quality'] # 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 特征缩放
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test) # 构建模型,添加L2正则化
model = Sequential([ Dense(64, activation='relu', input_shape=(X_train_scaled.shape[1],), kernel_regularizer=l2(0.01)), # 对第一个Dense层的权重添加L2正则化 Dense(64, activation='relu', kernel_regularizer=l2(0.01)), # 对第二个Dense层的权重也添加L2正则化 Dense(10, activation='softmax') # 输出层,假设是多分类问题
]) # 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) # 训练模型
history = model.fit(X_train_scaled, y_train, epochs=100, validation_split=0.2, verbose=1)
# 绘制训练和验证的准确率与损失
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], color='#B0D5DF',label='Training Accuracy')
plt.plot(history.history['val_accuracy'], color='#1BA784',label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend() plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], color='#D11A2D',label='Training Loss')
plt.plot(history.history['val_loss'], color='#87723E', label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()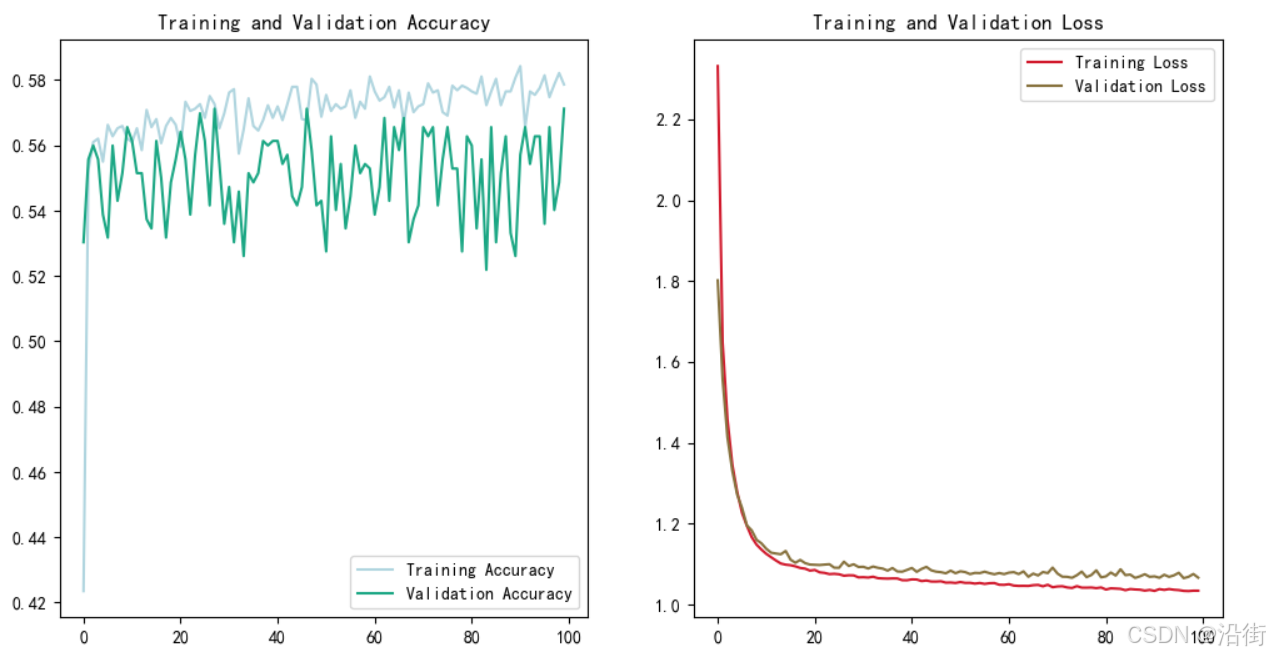
图 6-1
这就不错了。
相关文章:
基于python的BP神经网络红酒品质分类预测模型
1 导入必要的库 import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder from tensorflow.keras.models import Sequential from tenso…...

Kylin与Spark:大数据技术集成的深度解析
引言 在大数据时代,企业面临着海量数据的处理和分析需求。Kylin 和 Spark 作为两个重要的大数据技术,各自在数据处理领域有着独特的优势。Kylin 是一个开源的分布式分析引擎,专为大规模数据集的 OLAP(在线分析处理)查…...

⌈ 传知代码 ⌋ 利用scrapy框架练习爬虫
💛前情提要💛 本文是传知代码平台中的相关前沿知识与技术的分享~ 接下来我们即将进入一个全新的空间,对技术有一个全新的视角~ 本文所涉及所有资源均在传知代码平台可获取 以下的内容一定会让你对AI 赋能时代有一个颠覆性的认识哦&#x…...
)
深入了解 Python 面向对象编程(最终篇)
大家好!今天我们将继续探讨 Python 中的类及其在面向对象编程(OOP)中的应用。面向对象编程是一种编程范式,它使用“对象”来模拟现实世界的事务,使代码更加结构化和易于维护。在上一篇文章中,我们详细了解了…...

手把手教你实现基于丹摩智算的YoloV8自定义数据集的训练、测试。
摘要 DAMODEL(丹摩智算)是专为AI打造的智算云,致力于提供丰富的算力资源与基础设施助力AI应用的开发、训练、部署。 官网链接:https://damodel.com/register?source6B008AA9 平台的优势 💡 超友好! …...

SSH相关
前言 这篇是K8S及Rancher部署的前置知识。因为项目部署测试需要,向公司申请了一个虚拟机做服务器用。此前从未接触过服务器相关的东西,甚至命令也没怎么接触过(接触最多的还是git命令,但我日常用sourceTree)。本篇SSH…...
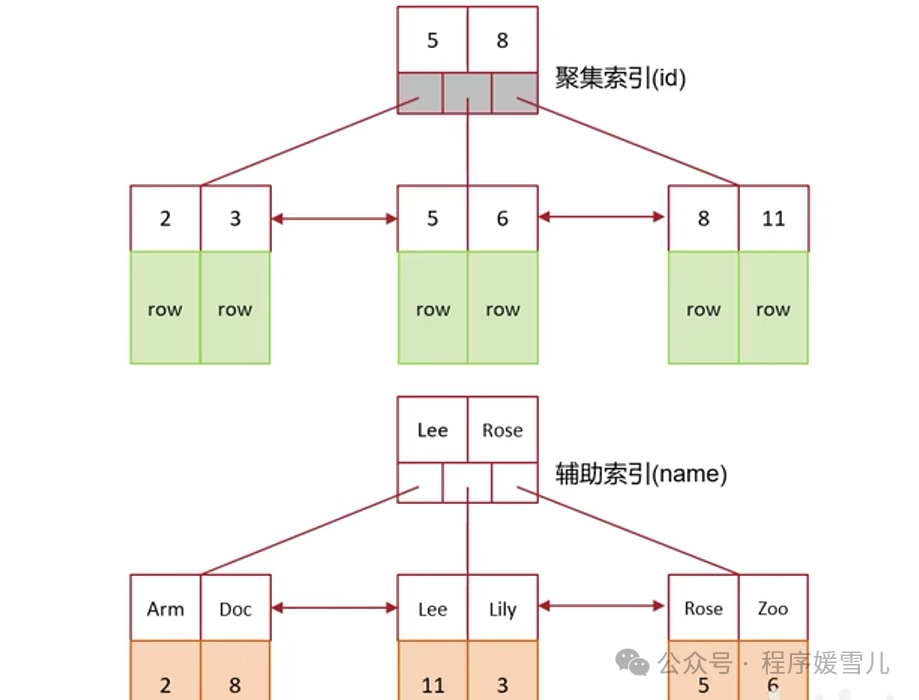
mysql超大分页问题处理~
大家好,我是程序媛雪儿,今天咱们聊mysql超大分页问题处理。 超大分页问题是什么? 数据量很大的时候,在查询中,越靠后,分页查询效率越低 例如 select * from tb_sku limit 0,10; select * from tb_sku lim…...

Gitlab以及分支管理
一、概述 Git 是一个分布式版本控制系统,用于跟踪文件的变化,尤其是源代码的变化。它由 Linus Torvalds 于 2005 年开发,旨在帮助管理大型软件项目的开发过程。 二、Git 的功能特性 Git 是关注于文件数据整体的变化,直接会将文件…...

探索Axure在数据可视化原型设计中的无限可能
在当今数字化浪潮中,产品设计不仅关乎美观与功能的平衡,更在于如何高效、直观地传达复杂的数据信息。Axure RP,作为原型设计领域的佼佼者,其在数据可视化原型设计中的应用,正逐步揭开产品设计的新篇章。本文将从多个维…...

Redis 内存淘汰策略
Redis 作为一个内存数据库,必须在内存使用达到配置的上限时采取策略来处理新数据的写入需求。Redis 提供了多种内存淘汰策略(Eviction Policies),以决定在内存达到上限时应该移除哪些数据。...

逆天!吴恩达+OpenAI合作出了大模型课程!重磅推出《LLM CookBook》中文版
吴恩达老师与OpenAI合作推出的大模型系列教程,从开发者在大型模型时代的必备技能出发,深入浅出地介绍了如何基于大模型API和LangChain架构快速开发出结合大模型强大能力的应用。 这些教程非常适合开发者学习,以便开始基于LLM实际构建应用程序…...

uint16_t、uint32_t类型数据高低字节互换
1. 使用位运算和逻辑运算符实现 #include<stdio.h> #include<stdint.h> int main() {void test_3() {uint16_t version = 0x1234;printf("%#x\n",(uint8_t)version);printf("%#x\n", version>>8);/*** 在C语言中,uint16和uint8是无符号…...

Java实现数据库图片上传(包含从数据库拿图片传递前端渲染)-图文详解
目录 1、前言: 2、数据库搭建 : 建表语句: 3、后端实现,将图片存储进数据库: 思想: 找到图片位置(如下图操作) 图片转为Fileinputstream流的工具类(可直接copy&#…...

开放式耳机原理是什么?通过不入耳的方式,享受健康听音体验
在开放式耳机的领域又细分了骨传导和气传导两种类型的耳机, 气传导开放式耳机原理 气传导是传统的声音传递方式,它依赖于空气作为声音传播的介质。 声源输入:与普通开放式耳机相同,音频设备通过耳机线将电信号传递到耳机。 驱动…...

有趣的PHP小游戏——猜数字
猜数字 这个游戏会随机生成一个1到100之间的数字,然后你需要猜测这个数字是什么。每次你输入一个数字后,程序会告诉你这个数字是“高了”还是“低了”,直到你猜对为止! 使用指南: 代码如下,保存到一个php中:如 index.php。代码部署到PHP服务器,比如 phpstudy。运行网…...

logstash 全接触
简述什么是Logstash ? Logstash是一个开源的集中式事件和日志管理器。它是 ELK(ElasticSearch、Logstash、Kibana)堆栈的一部分。在本教程中,我们将了解 Logstash 的基础知识、其功能以及它具有的各种组件。 Logstash 是一种基于…...
Windows本地构建镜像推送远程仓库
下载 Docker Desktop https://smartidedl.blob.core.chinacloudapi.cn/docker/20210926/Docker-win.exe 使用本地docker构建镜像和推送至远程仓库(harbor) 1、开启docker的2375端口 2、配置远程仓库push镜像可以通过http harbor.soujer.com:5000ps&am…...

计算机毕业设计LSTM+Tensorflow股票分析预测 基金分析预测 股票爬虫 大数据毕业设计 深度学习 机器学习 数据可视化 人工智能
|-- 项目 |-- db.sqlite3 数据库相关 重要 想看数据,可以用navicat打开 |-- requirements.txt 项目依赖库,可以理解为部分技术栈之类的 |-- data 原始数据文件 |-- data 每个股票的模型保存位置 |-- app 主要代码文件夹 | |-- mod…...
最新版上帝粒子The God Particle(winmac),Cradle Complete Bundle 2024绝对可用
一。Cradle插件套装Cradle Complete Bundle 2024 Cradle 是一家音乐技术公司,致力于为个人提供所需的工具,使他们成为最好的音乐人。自发布我们的第一款插件 The Prince 以来,我们一直致力于不懈地打造可靠、有益且易于使用的产品,…...

数 据 库
数据库是什么? 如何按照和移植数据库? 如何在命令行使用SQL语句操作数据库? 如何在C / C程序中操作数据库? 1. 数据库是什么? 数据库...

UxPlay应用场景:从家庭娱乐到企业演示的全面解决方案
UxPlay应用场景:从家庭娱乐到企业演示的全面解决方案 【免费下载链接】UxPlay AirPlay Unix mirroring server 项目地址: https://gitcode.com/gh_mirrors/uxp/UxPlay UxPlay是一款功能强大的AirPlay Unix镜像服务器,它让Linux、macOS和Unix系统能…...

CANN/pypto量化矩阵乘法
pypto.scaled_mm 【免费下载链接】pypto PyPTO(发音: pai p-t-o):Parallel Tensor/Tile Operation编程范式。 项目地址: https://gitcode.com/cann/pypto 产品支持情况 产品是否支持Ascend 950PR/Ascend 950DT√ 功能说明 实现mat_…...

纤维增强复合材料多轴3D打印的神经网络协同优化
1. 纤维增强复合材料与多轴3D打印技术概述纤维增强复合材料(Fiber-Reinforced Composites)因其独特的力学性能组合——高强度、高刚度和低密度,已成为现代工程设计中不可或缺的材料选择。这类材料由高强度纤维(如碳纤维、玻璃纤维…...

MoE稀疏激活原理与工程实践:解密大模型2%参数调用真相
1. 项目概述:参数规模与稀疏激活的真相拆解“GPT-4 Has 1.8 Trillion Parameters. It Uses 2% of Them Per Token.”——这句话过去两年在技术社区反复刷屏,常被当作“AI算力爆炸”的标志性论断。但作为从2016年就开始跑LSTM、2018年手写Transformer Enc…...

深度解析:光引擎、光模块、光器件之间的关系和区别?
随着AI大模型加速迭代,算力集群正从“千卡”向“万卡”“十万卡”规模迈进,光通信作为连接算力的“血管”,其内部层级关系变得愈发关键。然而,光器件、光模块、光引擎这三者并非同一概念,而是产业链中层层递进的“铁三…...

瑞萨RZ系列核心板选型指南:从A55到RISC-V的嵌入式开发实战
1. 项目概述:当国产方案商遇上日系芯片巨头在嵌入式开发这个圈子里混久了,你会发现一个有趣的现象:很多项目在启动时,面临的第一个灵魂拷问往往不是“功能怎么实现”,而是“平台怎么选”。是追求极致的性能,…...

HBase 分布式集群部署实战:从解压到启动的完整指南
HBase 分布式集群部署实战:从解压到启动的完整指南 文章目录HBase 分布式集群部署实战:从解压到启动的完整指南步骤一:解压安装文件步骤二:配置环境变量步骤三:修改配置文件(master节点)步骤四&…...
)
14. 声明文件(Declaration Files)
14. 声明文件(Declaration Files) 1. 概述 声明文件(.d.ts 文件)用于描述 JavaScript 库的类型信息,让 TypeScript 能够理解和使用纯 JavaScript 编写的代码。声明文件只包含类型定义,不包含实现代码。 ┌─…...
)
Postgresql基础实践教程(二)
十三、查询会员的预订开始时间 题目 如何列出名为"David Farrell"的会员的所有预订开始时间? 预期结果 starttime 2012-09-18 09:00:00 2012-09-18 17:30:00 2012-09-18 13:30:00 2012-09-18 20:00:00 2012-09-19 09:30:00 2012-09-19 15:00:00 2012-09-19 12:00:…...

PHP Intelephense项目结构解析:多工作区、虚拟工作区与远程开发
PHP Intelephense项目结构解析:多工作区、虚拟工作区与远程开发 【免费下载链接】vscode-intelephense PHP intellisense for Visual Studio Code 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-intelephense PHP Intelephense是一款为Visual Studio …...