Scikit-Learn中的分层特征工程:构建更精准的数据洞察
Scikit-Learn中的分层特征工程:构建更精准的数据洞察
在机器学习中,特征工程是提升模型性能的核心技术之一。Scikit-Learn(简称sklearn),作为Python中广受欢迎的机器学习库,提供了多种方法来进行特征工程,包括分层抽样、特征选择、特征提取等。本文将详细探讨sklearn中可用于实现分层特征工程的方法,并提供实际的代码示例。
一、分层特征工程的重要性
分层特征工程是指在特征选择或特征构造过程中,保持数据集中各个类别的比例一致,这对于提高模型的泛化能力和避免偏差至关重要。
二、使用分层抽样进行特征选择
在特征选择阶段,可以使用分层抽样来确保所选特征在各个类别中具有代表性。
示例代码:
from sklearn.feature_selection import StratifiedShuffleSplit# 假设X是特征集,y是目标变量
sss = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in sss.split(X, y):X_train, X_test = X[train_index], X[test_index]y_train, y_test = y[train_index], y[test_index]
三、基于模型的特征选择
sklearn中的一些模型和选择器可以根据数据的分层结构来选择特征。
3.1 使用SelectFromModel
SelectFromModel是一个包装器,可以根据模型的特征重要性来进行特征选择。
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifiermodel = RandomForestClassifier()
selector = SelectFromModel(model, prefit=False)
selector.fit(X_train, y_train)X_new = selector.transform(X_train) # 选择特征
3.2 使用RFE和RFECV
递归特征消除(RFE)和它的交叉验证版本RFECV可以用来选择特征。
from sklearn.feature_selection import RFE, RFECVmodel = RandomForestClassifier()
rfe = RFE(model, n_features_to_select=10)
rfe.fit(X_train, y_train)rfecv = RFECV(model, step=1, cv=5)
rfecv.fit(X_train, y_train)
四、特征提取
特征提取是从原始数据中生成新特征的过程,这些新特征可以是通过对原始特征的转换或组合得到的。
4.1 主成分分析(PCA)
PCA是一种常用的线性降维技术,可以用来提取数据的主成分特征。
from sklearn.decomposition import PCApca = PCA(n_components=0.95) # 保留95%的方差
X_pca = pca.fit_transform(X_train)
4.2 线性判别分析(LDA)
LDA是一种考虑类别信息的降维技术,它试图找到一个线性组合的特征空间,以最大化类间距离和最小化类内距离。
from sklearn.discriminant_analysis import LinearDiscriminantAnalysislda = LinearDiscriminantAnalysis(n_components=2)
X_lda = lda.fit_transform(X_train, y_train)
五、特征转换
特征转换是改变特征尺度或分布的过程,以提高模型的性能。
5.1 标准化
标准化将特征转换为均值为0,标准差为1的标准正态分布。
from sklearn.preprocessing import StandardScalerscaler = StandardScaler()
X_scaled = scaler.fit_transform(X_train)
5.2 归一化
归一化将特征缩放到指定的范围内,通常是0到1。
min_max_scaler = MinMaxScaler()
X_min_max = min_max_scaler.fit_transform(X_train)
六、结语:分层特征工程的最佳实践
分层特征工程是确保模型训练和评估阶段数据一致性的有效手段。通过本文的介绍,你已经了解了sklearn中实现分层特征工程的多种方法。这些方法包括使用分层抽样进行特征选择、基于模型的特征选择、特征提取和特征转换。
在实际应用中,我们需要根据数据集的特点和模型的需求来选择合适的特征工程方法。通过精心设计的特征工程流程,我们可以提高模型的准确性和泛化能力,构建更加健壮和可靠的机器学习系统。随着机器学习技术的不断发展,我们将继续探索更多有效的方法来进行分层特征工程。
相关文章:

Scikit-Learn中的分层特征工程:构建更精准的数据洞察
Scikit-Learn中的分层特征工程:构建更精准的数据洞察 在机器学习中,特征工程是提升模型性能的核心技术之一。Scikit-Learn(简称sklearn),作为Python中广受欢迎的机器学习库,提供了多种方法来进行特征工程&…...

CSOL遭遇DDOS攻击如何解决
CSOL遭遇DDOS攻击如何解决?在错综复杂的数字网络丛林中,《Counter-Strike Online》(简称CSOL)犹如一座坚固的堡垒,屹立在游戏世界的中心,吸引着无数玩家的目光与热情。这座堡垒并非无懈可击,DDo…...
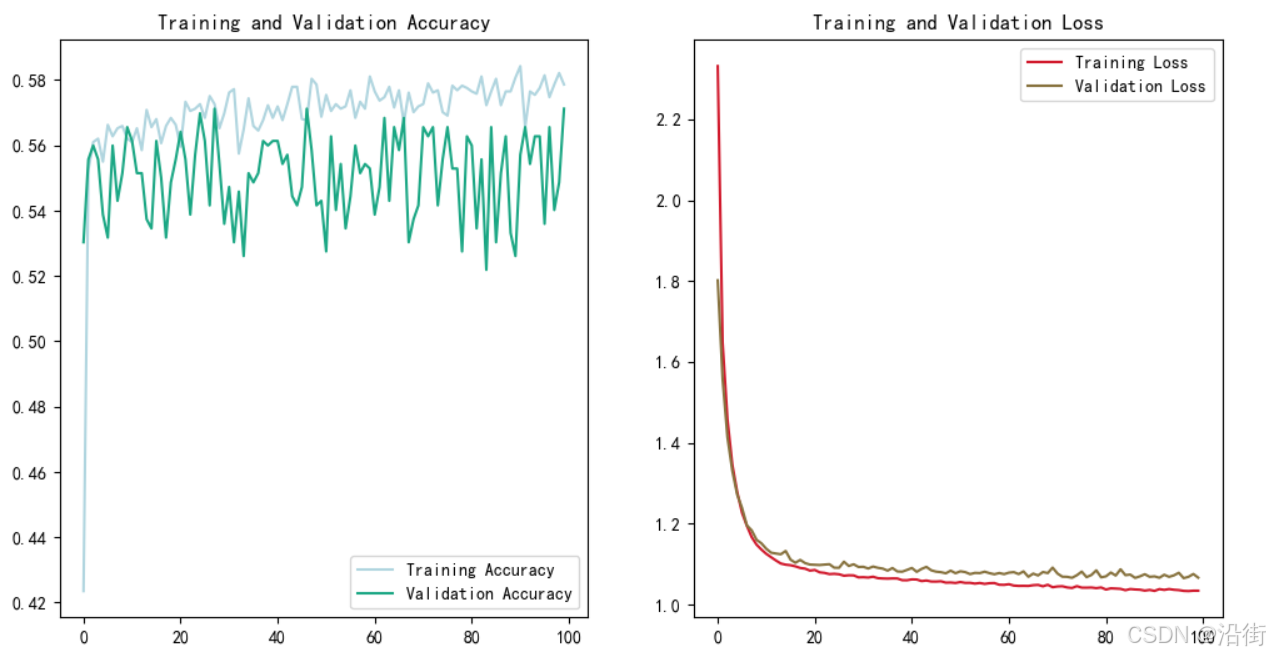
基于python的BP神经网络红酒品质分类预测模型
1 导入必要的库 import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder from tensorflow.keras.models import Sequential from tenso…...

Kylin与Spark:大数据技术集成的深度解析
引言 在大数据时代,企业面临着海量数据的处理和分析需求。Kylin 和 Spark 作为两个重要的大数据技术,各自在数据处理领域有着独特的优势。Kylin 是一个开源的分布式分析引擎,专为大规模数据集的 OLAP(在线分析处理)查…...

⌈ 传知代码 ⌋ 利用scrapy框架练习爬虫
💛前情提要💛 本文是传知代码平台中的相关前沿知识与技术的分享~ 接下来我们即将进入一个全新的空间,对技术有一个全新的视角~ 本文所涉及所有资源均在传知代码平台可获取 以下的内容一定会让你对AI 赋能时代有一个颠覆性的认识哦&#x…...
)
深入了解 Python 面向对象编程(最终篇)
大家好!今天我们将继续探讨 Python 中的类及其在面向对象编程(OOP)中的应用。面向对象编程是一种编程范式,它使用“对象”来模拟现实世界的事务,使代码更加结构化和易于维护。在上一篇文章中,我们详细了解了…...

手把手教你实现基于丹摩智算的YoloV8自定义数据集的训练、测试。
摘要 DAMODEL(丹摩智算)是专为AI打造的智算云,致力于提供丰富的算力资源与基础设施助力AI应用的开发、训练、部署。 官网链接:https://damodel.com/register?source6B008AA9 平台的优势 💡 超友好! …...

SSH相关
前言 这篇是K8S及Rancher部署的前置知识。因为项目部署测试需要,向公司申请了一个虚拟机做服务器用。此前从未接触过服务器相关的东西,甚至命令也没怎么接触过(接触最多的还是git命令,但我日常用sourceTree)。本篇SSH…...
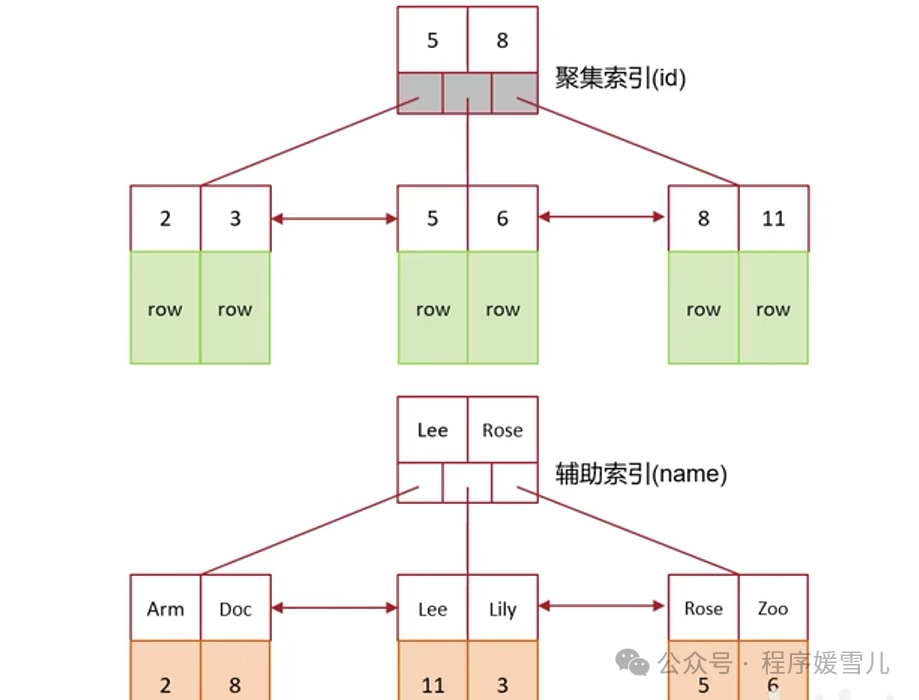
mysql超大分页问题处理~
大家好,我是程序媛雪儿,今天咱们聊mysql超大分页问题处理。 超大分页问题是什么? 数据量很大的时候,在查询中,越靠后,分页查询效率越低 例如 select * from tb_sku limit 0,10; select * from tb_sku lim…...

Gitlab以及分支管理
一、概述 Git 是一个分布式版本控制系统,用于跟踪文件的变化,尤其是源代码的变化。它由 Linus Torvalds 于 2005 年开发,旨在帮助管理大型软件项目的开发过程。 二、Git 的功能特性 Git 是关注于文件数据整体的变化,直接会将文件…...

探索Axure在数据可视化原型设计中的无限可能
在当今数字化浪潮中,产品设计不仅关乎美观与功能的平衡,更在于如何高效、直观地传达复杂的数据信息。Axure RP,作为原型设计领域的佼佼者,其在数据可视化原型设计中的应用,正逐步揭开产品设计的新篇章。本文将从多个维…...

Redis 内存淘汰策略
Redis 作为一个内存数据库,必须在内存使用达到配置的上限时采取策略来处理新数据的写入需求。Redis 提供了多种内存淘汰策略(Eviction Policies),以决定在内存达到上限时应该移除哪些数据。...

逆天!吴恩达+OpenAI合作出了大模型课程!重磅推出《LLM CookBook》中文版
吴恩达老师与OpenAI合作推出的大模型系列教程,从开发者在大型模型时代的必备技能出发,深入浅出地介绍了如何基于大模型API和LangChain架构快速开发出结合大模型强大能力的应用。 这些教程非常适合开发者学习,以便开始基于LLM实际构建应用程序…...

uint16_t、uint32_t类型数据高低字节互换
1. 使用位运算和逻辑运算符实现 #include<stdio.h> #include<stdint.h> int main() {void test_3() {uint16_t version = 0x1234;printf("%#x\n",(uint8_t)version);printf("%#x\n", version>>8);/*** 在C语言中,uint16和uint8是无符号…...

Java实现数据库图片上传(包含从数据库拿图片传递前端渲染)-图文详解
目录 1、前言: 2、数据库搭建 : 建表语句: 3、后端实现,将图片存储进数据库: 思想: 找到图片位置(如下图操作) 图片转为Fileinputstream流的工具类(可直接copy&#…...

开放式耳机原理是什么?通过不入耳的方式,享受健康听音体验
在开放式耳机的领域又细分了骨传导和气传导两种类型的耳机, 气传导开放式耳机原理 气传导是传统的声音传递方式,它依赖于空气作为声音传播的介质。 声源输入:与普通开放式耳机相同,音频设备通过耳机线将电信号传递到耳机。 驱动…...

有趣的PHP小游戏——猜数字
猜数字 这个游戏会随机生成一个1到100之间的数字,然后你需要猜测这个数字是什么。每次你输入一个数字后,程序会告诉你这个数字是“高了”还是“低了”,直到你猜对为止! 使用指南: 代码如下,保存到一个php中:如 index.php。代码部署到PHP服务器,比如 phpstudy。运行网…...

logstash 全接触
简述什么是Logstash ? Logstash是一个开源的集中式事件和日志管理器。它是 ELK(ElasticSearch、Logstash、Kibana)堆栈的一部分。在本教程中,我们将了解 Logstash 的基础知识、其功能以及它具有的各种组件。 Logstash 是一种基于…...
Windows本地构建镜像推送远程仓库
下载 Docker Desktop https://smartidedl.blob.core.chinacloudapi.cn/docker/20210926/Docker-win.exe 使用本地docker构建镜像和推送至远程仓库(harbor) 1、开启docker的2375端口 2、配置远程仓库push镜像可以通过http harbor.soujer.com:5000ps&am…...

计算机毕业设计LSTM+Tensorflow股票分析预测 基金分析预测 股票爬虫 大数据毕业设计 深度学习 机器学习 数据可视化 人工智能
|-- 项目 |-- db.sqlite3 数据库相关 重要 想看数据,可以用navicat打开 |-- requirements.txt 项目依赖库,可以理解为部分技术栈之类的 |-- data 原始数据文件 |-- data 每个股票的模型保存位置 |-- app 主要代码文件夹 | |-- mod…...
)
别再让日志拖慢你的服务器!深入对比C++同步与异步日志的性能差异(附TinyWebServer实测)
C服务器日志性能优化实战:同步与异步方案深度对比 当你的Web服务器开始承载真实流量时,那些看似无害的日志语句可能正在悄悄吞噬着系统性能。我曾在一个电商促销日亲眼目睹,由于同步日志的阻塞导致服务器响应时间从50ms飙升到800ms࿰…...

3步搞定歌词管理难题:LDDC歌词下载工具的完整实战指南
3步搞定歌词管理难题:LDDC歌词下载工具的完整实战指南 【免费下载链接】LDDC 简单易用的精准歌词(逐字歌词/卡拉OK歌词)下载匹配工具|A simple and user-friendly tool for downloading and matching precise lyrics (word-by-word lyrics/Karaoke lyrics) 项目地…...

OptScale 安全最佳实践:10个关键步骤保护你的云成本数据和配置
OptScale 安全最佳实践:10个关键步骤保护你的云成本数据和配置 【免费下载链接】optscale FinOps and cloud cost optimization tool. Supports AWS, Azure, GCP, Alibaba Cloud and Kubernetes. 项目地址: https://gitcode.com/gh_mirrors/op/optscale OptS…...

智慧树自动刷课插件终极指南:三步实现高效网课自动化学习
智慧树自动刷课插件终极指南:三步实现高效网课自动化学习 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台冗长的网课视频而烦恼吗…...

一键部署开源 AI 项目教程:OpenClaw 下载安装启动卸载全流程
AIStarter 是什么?一文彻底讲清楚很多朋友第一次看到 AIStarter 和 PanelAI 都比较懵:这到底是个什么工具?简单来说,AIStarter 是一款专为本地 AI 部署打造的一键安装管理平台,它能帮助开发者快速下载、安装、启动各种…...

java springboot-vue社区资源共享系统 社区活动报名系统
目录同行可拿货,招校园代理 ,本人源头供货商项目概述技术栈核心功能模块系统架构设计部署方案扩展性设计项目技术支持源码获取详细视频演示 :同行可合作点击我获取源码->->进我个人主页-->获取博主联系方式同行可拿货,招校园代理 ,本人源头供货商 项目概述…...

好用的山西GEO服务商
你可能已经感受到:当客户在AI大模型里问“山西哪家GEO优化公司靠谱?”、“中小企业如何用AI引流”时,你的企业信息根本搜不到。流量入口变了,传统SEO正在失效。如果能选对一家GEO服务商,就能在这个新战场里抢占先机。我…...

fastapi · FastAPI framework, high performance, easy to learn, fast to code, ready for production
fastapi FastAPI framework, high performance, easy to learn, fast to code, ready for production 本文整理自 GitHub,经重新整理编辑。 FastAPI framework, high performance, easy to learn, fast to code, ready for production Documentation: https://fas…...

日薪2700的护网HW面试,以及HW全面熟悉必看流程
前言 参与hvv的事情还是要想办法规避掉很多坑的。网络安全这个行业现阶段还是主要政策驱动,后面应该是客户意识,现在用户教育成本明显比以前低太多。 1.关于HVV的一个简单流程 首先我带大家从甲方和厂商的角度来分解一下整个护网流程的核心逻辑 第一阶段…...

SchemaCrawler:终极数据库模式发现与理解工具完全指南
SchemaCrawler:终极数据库模式发现与理解工具完全指南 【免费下载链接】SchemaCrawler Free database schema discovery and comprehension tool 项目地址: https://gitcode.com/gh_mirrors/sc/SchemaCrawler 在当今数据驱动的时代,数据库模式发现…...