Python3网络爬虫开发实战(4)数据的存储
文章目录
- 一、文本文件存储
- 1. os 文件 mode
- 2. TXT
- 3. JSON
- 4. CSV
- 二、数据库存储
- 1. SQLAlchemy
- 2. MongoDB
- 3. Redis
- 1) 键操作
- 2) 字符串操作
- 3) 列表操作
- 4) 集合操作
- 5) 有序集合操作
- 6) 散列操作
- 4. Elasticsearch
- 1) 检索数据:利用 elasticsearch-analysis-ik 进行分词
- 2) dsl 语句:[Search DSL — Elasticsearch DSL 8.14.0 documentation (elasticsearch-dsl.readthedocs.io)](https://elasticsearch-dsl.readthedocs.io/en/latest/search_dsl.html)
- 5. RabbitMQ
- 1) 声明队列
- 2) 生产内容
- 3) 消费内容
一、文本文件存储
1. os 文件 mode
python open() 函数用于打开一个文件,创建一个 file 对象,相关的方法才可以调用它进行读写。
open(name[, mode[, buffering]])
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
2. TXT
with open('movies.txt', 'w', encoding='utf-8') as f:f.writelines(['名称', '类别', '时间'])with open('movies.txt', 'w', encoding='utf-8') as f:f.write('名称')f.write('类别')f.write('时间')
3. JSON
json 数据要使用双引号包围起来,而不能使用单引号;
import json# 读取数据
with open('data.json', encoding='utf-8') as f:json_data = json.loads(f.read())json_data = json.load(open('data.json', encoding='utf-8'))# 导出数据
with open('data.json', mode='w', encoding='utf-8') as f:f.write(json.dumps(json_data, indent=2, ensure_ascii=False))json.dump(json_data, open('data.json', mode='w', encoding='utf-8'), indent=2, ensure_ascii=False)
4. CSV
import csv# 存储数据
with open('data.csv', 'w') as csvfile:writer = csv.writer(csvfile, delimiter=',')writer.writerow(['1', '2', '3'])writer.writerow(['1', '2', '3'])writer.writerow(['1', '2', '3'])with open('data.csv', 'w') as csvfile:writer = csv.DictWriter(csvfile, delimiter=',', fieldnames = ['id1', 'id2', 'id3'])writer.writeheader()writer.writerow({'id1': 1, 'id2': 2, 'id3': 3})writer.writerow({'id1': 1, 'id2': 2, 'id3': 3})writer.writerow({'id1': 1, 'id2': 2, 'id3': 3})# 读取数据
with open('data.csv', 'r') as csvfile:reader = csv.DictReader(csvfile)for row in reader:print(row)# 如果 w 模式中没有使用 newline='' 则会出现空行,不推荐使用,推荐使用 csv.DictReader
with open('data.csv', 'r') as csvfile:reader = csv.reader(csvfile)for row in reader:print(row)
二、数据库存储
1. SQLAlchemy
安装 SQLAlchemy 库:
pip install SQLAlchemy
SQLAlchemy 库相较于 pymysql 库来说,sqlalchemy还包括ORM,可以负责数据转换和类型处理;sqlalchemy ORM 使用 Python 类来表示数据库表,这使得查询和数据处理变得无比容易。此外,sqlalchemy 还支持高级查询和 SQL 语句生成,可以在处理复杂查询时更加便捷。
官网:SQLAlchemy Documentation — SQLAlchemy 2.0 Documentation
| drivername | Database |
|---|---|
| mysql | MySQL |
| mysql+mysqldb | MySQL |
| mysql+pymysql | MySQL |
| oracle | Oracle |
| oracle+cx_oracle | Oracle |
| mssql+pyodbc | Microsoft SQL Server |
| mssql+pymssql | Microsoft SQL Server |
| sqlite | SQLite |
| postgresql | PostgreSQL |
| postgresql+psycopg2 | PostgreSQL |
| postgresql+pg8000 | PostgreSQL |
from sqlalchemy import URL, create_engine, texturl_object = URL.create(drivername="postgresql+pg8000",username="dbuser",password="kx@jj5/g", # plain (unescaped) texthost="pghost10",database="appdb",
)engine = create_engine(url_object, echo=False)with engine.connect() as conn:result = conn.execute(text("select 'hello world'"))print(result.all())# 加上 conn.commit() 表示提交 否则就是 rollback# conn.commit()
在这里涉及到 SQL 语句部分:史上最全SQL基础知识总结(理论+举例)-CSDN博客
2. MongoDB
首先安装 MongoDB,然后安装 PyMongo 库:MongoDB 的安装 | 静觅 (cuiqingcai.com);(异步库 motor)
pip install pymongo
MongoDB 是一个基于分布式文件存储的开源数据库系统,其内容的存储形式类似于 Json 对象;在 MongoDB 中,每条数据都有一个 _id 属性作为唯一标识,如果没有显示指明该属性,那么 MongoDB 会自动产生一个 ObjectID 类型的 _id 属性,insert 方法会在执行后返回 _id 值;MongoDB 教程 | 菜鸟教程 (runoob.com)
import pymongo# 连接 MongoDB
client = pymongo.MongoClient(host="localhost", port=27017)
client = pymongo.MongoClient('mongodb://localhost:27107/')# 指定名为 test 的数据库
db = client.test
db = client['test']# 指定名为 students 的集合
collection = db.students
collection = db['students']# 插入数据,insert 方法会在执行后返回 ObjectID 类型的 _id 值;
student_1 = {'name':'张三', 'age': 14}
student_2 = {'name':'张三', 'age': 14}collection.insert_one(student_1)
collection.insert_one(student_2)
collection.insert_many([student_1, student_2])# 查询数据,返回的数据是 字典型 数据
collection.find_one({'name': '张三'})
collection.find({'age': { $eq: 25}}) # 返回 cursor 类型数据,相当于一个生成器 from bson.objectid import ObjectID
collection.find_one({'_id': ObjectID('88888888')})# 更新
condition = {'name': 'Kevin'}
student = collection.find_one(condition)
student['age'] = 26
collection.update(condition, student) # 可以不用 $set
## {'ok': 1, ...}## $set 只会更新 student 字典内存在的字段,如果原先还有其他字段,则既不会更新,也不会删除;
collection.update_one(condition, {'$set': student})
collection.update_many(condition, {'$set': student}) # 删除
collection.delete_one({'name': '张三'})
collection.delete_many({'name': '张三'})
## {'ok': 1, ...}# 计数
collection.find().count()# 排序 ASCENDING 和 DESCENDING
collection.find().sort('name', pymongo.ASCENDING) # 偏移位置
collection.skip(2)# 限制结果个数
collection.limit(2)
条件操作符:
| 操作符 | 描述 | 示例 |
|---|---|---|
$eq | 等于 | { age: { $eq: 25 } } |
$ne | 不等于 | { age: { $ne: 25 } } |
$gt | 大于 | { age: { $gt: 25 } } |
$gte | 大于等于 | { age: { $gte: 25 } } |
$lt | 小于 | { age: { $lt: 25 } } |
$lte | 小于等于 | { age: { $lte: 25 } } |
$in | 在指定的数组中 | { age: { $in: [25, 30, 35] } } |
$nin | 不在指定的数组中 | { age: { $nin: [25, 30, 35] } } |
$and | 逻辑与,符合所有条件 | { $and: [ { age: { $gt: 25 } }, { city: "New York" } ] } |
$or | 逻辑或,符合任意条件 | { $or: [ { age: { $lt: 25 } }, { city: "New York" } ] } |
$not | 取反,不符合条件 | { age: { $not: { $gt: 25 } } } |
$nor | 逻辑与非,均不符合条件 | { $nor: [ { age: { $gt: 25 } }, { city: "New York" } ] } |
$exists | 字段是否存在 | { age: { $exists: true } } |
$type | 字段的 BSON 类型 | { age: { $type: "int" } } |
$all | 数组包含所有指定的元素 | { tags: { $all: ["red", "blue"] } } |
$elemMatch | 数组中的元素匹配指定条件 | { results: { $elemMatch: { score: { $gt: 80, $lt: 85 } } } } |
$size | 数组的长度等于指定值 | { tags: { $size: 3 } } |
$regex | 匹配正则表达式 | { name: { $regex: /^A/ } } |
$text | 进行文本搜索 | { $text: { $search: "coffee" } } |
$where | 使用 JavaScript 表达式进行条件过滤 | { $where: "this.age > 25" } |
| 功能操作符: |
![[Pasted image 20240725150419.png]]
3. Redis
首先可以按照下面链接安装 Redis,安装好 Redis 数据库后,还需要安装好 redis-py 库,即用来操作 Redis 的 Python 包
- Redis 库的安装 | 静觅 (cuiqingcai.com)
- Redis 安装 | 菜鸟教程 (runoob.com)
- Python redis 使用介绍 | 菜鸟教程 (runoob.com)
pip install redis
Redis 是一个基于内存的,高效的键值型非关系型数据库,存取效率极高,而且支持多种数据结构,使用起来也非常简单;鉴于 Redis 的便捷性和高效性,在维护代理池,账号池,ADSL拨号代理池,Scrapy-Redis 分布式架构有着重要应用
from redis import StrictRedis, ConnectionPool# 连接 Redis
pool = ConnectionPool(host='localhost', port=6379, db=0, password='foobared')
redis = StrictRedis(connection_pool=pool)redis = StrictRedis(host='localhost', port=6379, db=0, password='foobared')
1) 键操作
| 方 法 | 作 用 | 参数说明 | 示 例 | 示例说明 | 示例结果 |
|---|---|---|---|---|---|
| exists(name) | 判断一个键是否存在 | name:键名 | redis.exists(‘name’) | 是否存在 name 这个键 | True |
| delete(name) | 删除一个键 | name:键名 | redis.delete(‘name’) | 删除 name 这个键 | 1 |
| type(name) | 判断键类型 | name:键名 | redis.type(‘name’) | 判断 name 这个键类型 | b’string’ |
| keys(pattern) | 获取所有符合规则的键 | pattern:匹配规则 | redis.keys(‘n*’) | 获取所有以 n 开头的键 | [b’name’] |
| randomkey() | 获取随机的一个键 | randomkey() | 获取随机的一个键 | b’name’ | |
| rename(src, dst) | 重命名键 | src:原键名;dst:新键名 | redis.rename(‘name’, ‘nickname’) | 将 name 重命名为 nickname | True |
| dbsize() | 获取当前数据库中键的数目 | dbsize() | 获取当前数据库中键的数目 | 100 | |
| expire(name, time) | 设定键的过期时间,单位为秒 | name:键名;time:秒数 | redis.expire(‘name’, 2) | 将 name 键的过期时间设置为 2 秒 | True |
| ttl(name) | 获取键的过期时间,单位为秒,1 表示永久不过期 | name:键名 | redis.ttl(‘name’) | 获取 name 这个键的过期时间 | 1 |
| move(name, db) | 将键移动到其他数据库 | name:键名;db:数据库代号 | move(‘name’, 2) | 将 name 移动到 2 号数据库 | True |
| flushdb() | 删除当前选择数据库中的所有键 | flushdb() | 删除当前选择数据库中的所有键 | True | |
| flushall() | 删除所有数据库中的所有键 | flushall() | 删除所有数据库中的所有键 | True |
2) 字符串操作
| 方 法 | 作 用 | 参数说明 | 示 例 | 示例说明 | 示例结果 |
|---|---|---|---|---|---|
| set(name, value) | 给数据库中键名为 name 的 string 赋予值 value | n ame:键名;value:值 | redis.set(‘name’, ‘Bob’) | 给 name 这个键的 value 赋值为 Bob | True |
| get(name) | 返回数据库中键名为 name 的 string 的 value | name:键名 | redis.get(‘name’) | 返回 name 这个键的 value | b’Bob’ |
| getset(name, value) | 给数据库中键名为 name 的 string 赋予值 value 并返回上次的 value | name:键名;value:新值 | redis.getset(‘name’, ‘Mike’) | 赋值 name 为 Mike 并得到上次的 value | b’Bob’ |
| mget(keys, *args) | 返回多个键对应的 value 组成的列表 | keys:键名序列 | redis.mget([‘name’, ‘nickname’]) | 返回 name 和 nickname 的 value | [b’Mike’, b’Miker’] |
| setnx(name, value) | 如果不存在这个键值对,则更新 value,否则不变 | name:键名 | redis.setnx(‘newname’, ‘James’) | 如果 newname 这个键不存在,则设置值为 James | 第一次运行结果是 True,第二次运行结果是 False |
| setex(name, time, value) | 设置可以对应的值为 string 类型的 value,并指定此键值对应的有效期 | n ame:键名;time:有效期;value:值 | redis.setex(‘name’, 1, ‘James’) | 将 name 这个键的值设为 James,有效期为 1 秒 | True |
| setrange(name, offset, value) | 设置指定键的 value 值的子字符串 | name:键名;offset:偏移量;value:值 | redis.set(‘name’, ‘Hello’) redis.setrange (‘name’, 6, ‘World’) | 设置 name 为 Hello 字符串,并在 index 为 6 的位置补 World | 11,修改后的字符串长度 |
| mset(mapping) | 批量赋值 | mapping:字典或关键字参数 | redis.mset({‘name1’: ‘Durant’, ‘name2’: ‘James’}) | 将 name1 设为 Durant,name2 设为 James | True |
| msetnx(mapping) | 键均不存在时才批量赋值 | mapping:字典或关键字参数 | redis.msetnx({‘name3’: ‘Smith’, ‘name4’: ‘Curry’}) | 在 name3 和 name4 均不存在的情况下才设置二者值 | True |
| incr(name, amount=1) | 键名为 name 的 value 增值操作,默认为 1,键不存在则被创建并设为 amount | name:键名;amount:增长的值 | redis.incr(‘age’, 1) | age 对应的值增 1,若不存在,则会创建并设置为 1 | 1,即修改后的值 |
| decr(name, amount=1) | 键名为 name 的 value 减值操作,默认为 1,键不存在则被创建并将 value 设置为 - amount | name:键名;amount:减少的值 | redis.decr(‘age’, 1) | age 对应的值减 1,若不存在,则会创建并设置为1 | 1,即修改后的值 |
| append(key, value) | 键名为 key 的 string 的值附加 value | key:键名 | redis.append(‘nickname’, ‘OK’) | 向键名为 nickname 的值后追加 OK | 13,即修改后的字符串长度 |
| substr(name, start, end=-1) | 返回键名为 name 的 string 的子字符串 | name:键名;start:起始索引;end:终止索引,默认为1,表示截取到末尾 | redis.substr(‘name’, 1, 4) | 返回键名为 name 的值的字符串,截取索引为 1~4 的字符 | b’ello’ |
| getrange(key, start, end) | 获取键的 value 值从 start 到 end 的子字符串 | key:键名;start:起始索引;end:终止索引 | redis.getrange(‘name’, 1, 4) | 返回键名为 name 的值的字符串,截取索引为 1~4 的字符 | b’ello’ |
3) 列表操作
| 方 法 | 作 用 | 参数说明 | 示 例 | 示例说明 | 示例结果 |
|---|---|---|---|---|---|
| rpush(name, *values) | 在键名为 name 的列表末尾添加值为 value 的元素,可以传多个 | name:键名;values:值 | redis.rpush(‘list’, 1, 2, 3) | 向键名为 list 的列表尾添加 1、2、3 | 3,列表大小 |
| lpush(name, *values) | 在键名为 name 的列表头添加值为 value 的元素,可以传多个 | name:键名;values:值 | redis.lpush(‘list’, 0) | 向键名为 list 的列表头部添加 0 | 4,列表大小 |
| llen(name) | 返回键名为 name 的列表的长度 | name:键名 | redis.llen(‘list’) | 返回键名为 list 的列表的长度 | 4 |
| lrange(name, start, end) | 返回键名为 name 的列表中 start 至 end 之间的元素 | name:键名;start:起始索引;end:终止索引 | redis.lrange(‘list’, 1, 3) | 返回起始索引为 1 终止索引为 3 的索引范围对应的列表 | [b’3’, b’2’, b’1’] |
| ltrim(name, start, end) | 截取键名为 name 的列表,保留索引为 start 到 end 的内容 | name:键名;start:起始索引;end:终止索引 | ltrim(‘list’, 1, 3) | 保留键名为 list 的索引为 1 到 3 的元素 | True |
| lindex(name, index) | 返回键名为 name 的列表中 index 位置的元素 | name:键名;index:索引 | redis.lindex(‘list’, 1) | 返回键名为 list 的列表索引为 1 的元素 | b’2’ |
| lset(name, index, value) | 给键名为 name 的列表中 index 位置的元素赋值,越界则报错 | name:键名;index:索引位置;value:值 | redis.lset(‘list’, 1, 5) | 将键名为 list 的列表中索引为 1 的位置赋值为 5 | True |
| lrem(name, count, value) | 删除 count 个键的列表中值为 value 的元素 | name:键名;count:删除个数;value:值 | redis.lrem(‘list’, 2, 3) | 将键名为 list 的列表删除两个 3 | 1,即删除的个数 |
| lpop(name) | 返回并删除键名为 name 的列表中的首元素 | name:键名 | redis.lpop(‘list’) | 返回并删除名为 list 的列表中的第一个元素 | b’5’ |
| rpop(name) | 返回并删除键名为 name 的列表中的尾元素 | name:键名 | redis.rpop(‘list’) | 返回并删除名为 list 的列表中的最后一个元素 | b’2’ |
| blpop(keys, timeout=0) | 返回并删除名称在 keys 中的 list 中的首个元素,如果列表为空,则会一直阻塞等待 | keys:键名序列;timeout:超时等待时间,0 为一直等待 | redis.blpop(‘list’) | 返回并删除键名为 list 的列表中的第一个元素 | [b’5’] |
| brpop(keys, timeout=0) | 返回并删除键名为 name 的列表中的尾元素,如果 list 为空,则会一直阻塞等待 | keys:键名序列;timeout:超时等待时间,0 为一直等待 | redis.brpop(‘list’) | 返回并删除名为 list 的列表中的最后一个元素 | [b’2’] |
| rpoplpush(src, dst) | 返回并删除名称为 src 的列表的尾元素,并将该元素添加到名称为 dst 的列表头部 | src:源列表的键;dst:目标列表的 key | redis.rpoplpush(‘list’, ‘list2’) | 将键名为 list 的列表尾元素删除并将其添加到键名为 list2 的列表头部,然后返回 | b’2’ |
4) 集合操作
| 方 法 | 作 用 | 参数说明 | 示 例 | 示例说明 | 示例结果 |
|---|---|---|---|---|---|
| sadd(name, *values) | 向键名为 name 的集合中添加元素 | name:键名;values:值,可为多个 | redis.sadd(‘tags’, ‘Book’, ‘Tea’, ‘Coffee’) | 向键名为 tags 的集合中添加 Book、Tea 和 Coffee 这 3 个内容 | 3,即插入的数据个数 |
| srem(name, *values) | 从键名为 name 的集合中删除元素 | name:键名;values:值,可为多个 | redis.srem(‘tags’, ‘Book’) | 从键名为 tags 的集合中删除 Book | 1,即删除的数据个数 |
| spop(name) | 随机返回并删除键名为 name 的集合中的一个元素 | name:键名 | redis.spop(‘tags’) | 从键名为 tags 的集合中随机删除并返回该元素 | b’Tea’ |
| smove(src, dst, value) | 从 src 对应的集合中移除元素并将其添加到 dst 对应的集合中 | src:源集合;dst:目标集合;value:元素值 | redis.smove(‘tags’, ‘tags2’, ‘Coffee’) | 从键名为 tags 的集合中删除元素 Coffee 并将其添加到键为 tags2 的集合 | True |
| scard(name) | 返回键名为 name 的集合的元素个数 | name:键名 | redis.scard(‘tags’) | 获取键名为 tags 的集合中的元素个数 | 3 |
| sismember(name, value) | 测试 member 是否是键名为 name 的集合的元素 | name:键值 | redis.sismember(‘tags’, ‘Book’) | 判断 Book 是否是键名为 tags 的集合元素 | True |
| sinter(keys, *args) | 返回所有给定键的集合的交集 | keys:键名序列 | redis.sinter([‘tags’, ‘tags2’]) | 返回键名为 tags 的集合和键名为 tags2 的集合的交集 | {b’Coffee’} |
| sinterstore(dest, keys, *args) | 求交集并将交集保存到 dest 的集合 | dest:结果集合;keys:键名序列 | redis.sinterstore (‘inttag’, [‘tags’, ‘tags2’]) | 求键名为 tags 的集合和键名为 tags2 的集合的交集并将其保存为 inttag | 1 |
| sunion(keys, *args) | 返回所有给定键的集合的并集 | keys:键名序列 | redis.sunion([‘tags’, ‘tags2’]) | 返回键名为 tags 的集合和键名为 tags2 的集合的并集 | {b’Coffee’, b’Book’, b’Pen’} |
| sunionstore(dest, keys, *args) | 求并集并将并集保存到 dest 的集合 | dest:结果集合;keys:键名序列 | redis.sunionstore (‘inttag’, [‘tags’, ‘tags2’]) | 求键名为 tags 的集合和键名为 tags2 的集合的并集并将其保存为 inttag | 3 |
| sdiff(keys, *args) | 返回所有给定键的集合的差集 | keys:键名序列 | redis.sdiff([‘tags’, ‘tags2’]) | 返回键名为 tags 的集合和键名为 tags2 的集合的差集 | {b’Book’, b’Pen’} |
| sdiffstore(dest, keys, *args) | 求差集并将差集保存到 dest 集合 | dest:结果集合;keys:键名序列 | redis.sdiffstore (‘inttag’, [‘tags’, ‘tags2’]) | 求键名为 tags 的集合和键名为 tags2 的集合的差集并将其保存为 inttag | 3 |
| smembers(name) | 返回键名为 name 的集合的所有元素 | name:键名 | redis.smembers(‘tags’) | 返回键名为 tags 的集合的所有元素 | {b’Pen’, b’Book’, b’Coffee’} |
| srandmember(name) | 随机返回键名为 name 的集合中的一个元素,但不删除元素 | name:键值 | redis.srandmember(‘tags’) | 随机返回键名为 tags 的集合中的一个元素 | Srandmember (name) |
5) 有序集合操作
| 方 法 | 作 用 | 参数说明 | 示 例 | 示例说明 | 示例结果 |
|---|---|---|---|---|---|
| zadd(name, *args, **kwargs) | 向键名为 name 的 zset 中添加元素 member,score 用于排序。如果该元素存在,则更新其顺序 | name:键名;args:可变参数 | redis.zadd(‘grade’, 100, ‘Bob’, 98, ‘Mike’) | 向键名为 grade 的 zset 中添加 Bob(其 score 为 100),并添加 Mike(其 score 为 98) | 2,即添加的元素个数 |
| zrem(name, *values) | 删除键名为 name 的 zset 中的元素 | name:键名;values:元素 | redis.zrem(‘grade’, ‘Mike’) | 从键名为 grade 的 zset 中删除 Mike | 1,即删除的元素个数 |
| zincrby(name, value, amount=1) | 如果在键名为 name 的 zset 中已经存在元素 value,则将该元素的 score 增加 amount;否则向该集合中添加该元素,其 score 的值为 amount | name:键名;value:元素;amount:增长的 score 值 | redis.zincrby(‘grade’, ‘Bob’, -2) | 键名为 grade 的 zset 中 Bob 的 score 减 2 | 98.0,即修改后的值 |
| zrank(name, value) | 返回键名为 name 的 zset 中元素的排名,按 score 从小到大排序,即名次 | name:键名;value:元素值 | redis.zrank(‘grade’, ‘Amy’) | 得到键名为 grade 的 zset 中 Amy 的排名 | 1 |
| zrevrank(name, value) | 返回键为 name 的 zset 中元素的倒数排名(按 score 从大到小排序),即名次 | name:键名;value:元素值 | redis.zrevrank (‘grade’, ‘Amy’) | 得到键名为 grade 的 zset 中 Amy 的倒数排名 | 2 |
| zrevrange(name, start, end, withscores= False) | 返回键名为 name 的 zset(按 score 从大到小排序)中 index 从 start 到 end 的所有元素 | name:键值;start:开始索引;end:结束索引;withscores:是否带 score | redis.zrevrange (‘grade’, 0, 3) | 返回键名为 grade 的 zset 中前四名元素 | [b’Bob’, b’Mike’, b’Amy’, b’James’] |
| zrangebyscore (name, min, max, start=None, num=None, withscores=False) | 返回键名为 name 的 zset 中 score 在给定区间的元素 | name:键名;min:最低 score;max:最高 score;start:起始索引;num:个数;withscores:是否带 score | redis.zrangebyscore (‘grade’, 80, 95) | 返回键名为 grade 的 zset 中 score 在 80 和 95 之间的元素 | [b’Bob’, b’Mike’, b’Amy’, b’James’] |
| zcount(name, min, max) | 返回键名为 name 的 zset 中 score 在给定区间的数量 | name:键名;min:最低 score;max:最高 score | redis.zcount(‘grade’, 80, 95) | 返回键名为 grade 的 zset 中 score 在 80 到 95 的元素个数 | 2 |
| zcard(name) | 返回键名为 name 的 zset 的元素个数 | name:键名 | redis.zcard(‘grade’) | 获取键名为 grade 的 zset 中元素的个数 | 3 |
| zremrangebyrank (name, min, max) | 删除键名为 name 的 zset 中排名在给定区间的元素 | name:键名;min:最低位次;max:最高位次 | redis.zremrangebyrank (‘grade’, 0, 0) | 删除键名为 grade 的 zset 中排名第一的元素 | 1,即删除的元素个数 |
| zremrangebyscore (name, min, max) | 删除键名为 name 的 zset 中 score 在给定区间的元素 | name:键名;min:最低 score;max:最高 score | redis.zremrangebyscore (‘grade’, 80, 90) | 删除 score 在 80 到 90 之间的元素 | 1,即删除的元素个数 |
6) 散列操作
| 方 法 | 作 用 | 参数说明 | 示 例 | 示例说明 | 示例结果 |
|---|---|---|---|---|---|
| hset(name, key, value) | 向键名为 name 的散列表中添加映射 | name:键名;key:映射键名;value:映射键值 | hset(‘price’, ‘cake’, 5) | 向键名为 price 的散列表中添加映射关系,cake 的值为 5 | 1,即添加的映射个数 |
| hsetnx(name, key, value) | 如果映射键名不存在,则向键名为 name 的散列表中添加映射 | name:键名;key:映射键名;value:映射键值 | hsetnx(‘price’, ‘book’, 6) | 向键名为 price 的散列表中添加映射关系,book 的值为 6 | 1,即添加的映射个数 |
| hget(name, key) | 返回键名为 name 的散列表中 key 对应的值 | name:键名;key:映射键名 | redis.hget(‘price’, ‘cake’) | 获取键名为 price 的散列表中键名为 cake 的值 | 5 |
| hmget(name, keys, *args) | 返回键名为 name 的散列表中各个键对应的值 | name:键名;keys:键名序列 | redis.hmget(‘price’, [‘apple’, ‘orange’]) | 获取键名为 price 的散列表中 apple 和 orange 的值 | [b’3’, b’7’] |
| hmset(name, mapping) | 向键名为 name 的散列表中批量添加映射 | name:键名;mapping:映射字典 | redis.hmset(‘price’, {‘banana’: 2, ‘pear’: 6}) | 向键名为 price 的散列表中批量添加映射 | True |
| hincrby(name, key, amount=1) | 将键名为 name 的散列表中映射的值增加 amount | name:键名;key:映射键名;amount:增长量 | redis.hincrby(‘price’, ‘apple’, 3) | key 为 price 的散列表中 apple 的值增加 3 | 6,修改后的值 |
| hexists(name, key) | 键名为 name 的散列表中是否存在键名为键的映射 | name:键名;key:映射键名 | redis.hexists(‘price’, ‘banana’) | 键名为 price 的散列表中 banana 的值是否存在 | True |
| hdel(name, *keys) | 在键名为 name 的散列表中,删除键名为键的映射 | name:键名;keys:键名序列 | redis.hdel(‘price’, ‘banana’) | 从键名为 price 的散列表中删除键名为 banana 的映射 | True |
| hlen(name) | 从键名为 name 的散列表中获取映射个数 | name:键名 | redis.hlen(‘price’) | 从键名为 price 的散列表中获取映射个数 | 6 |
| hkeys(name) | 从键名为 name 的散列表中获取所有映射键名 | name:键名 | redis.hkeys(‘price’) | 从键名为 price 的散列表中获取所有映射键名 | [b’cake’, b’book’, b’banana’, b’pear’] |
| hvals(name) | 从键名为 name 的散列表中获取所有映射键值 | name:键名 | redis.hvals(‘price’) | 从键名为 price 的散列表中获取所有映射键值 | [b’5’, b’6’, b’2’, b’6’] |
| hgetall(name) | 从键名为 name 的散列表中获取所有映射键值对 | name:键名 | redis.hgetall(‘price’) | 从键名为 price 的散列表中获取所有映射键值对 | {b’cake’: b’5’, b’book’: b’6’, b’orange’: b’7’, b’pear’: b’6’} |
4. Elasticsearch
首先要安装 Elasticsearch,安装完毕后,我们需要安装 Elasticsearch 库专门用来对接 Elasticsearch
- Elasticsearch 的安装 | 静觅 (cuiqingcai.com)
- Elasticsearch 教程 - 菜鸟教程 (cainiaojc.com)
pip install elasticsearch
Elasticsearch 是一个分布式的实时文档存储库,每个字段都可以被索引与搜索,能胜任上百个服务节点的拓展,并支持 PB 级别的结构化或者非结构化数据
from elasticsearch import Elasticsearch# 连接 Elasticsearch 默认连接本地9200端口
es = Elasticsearch(hosts:"localhost",port:9200,verify_certs=True # 是否验证证书
)# 创建索引
es.indices.create(index='news', ignore=400) # ignore 为 400 忽略索引存在错误
## {'acknowledged':True, ...} acknowledged 表示创建成功# 删除索引
es.indices.delete(index='news')
## {'acknowledged':True, ...} acknowledged 表示创建成功# 插入数据 es.index() 可以不提供 id,会自动生成
es.index(index='test', id='1', body={"id": "1", "name": "小明"}) # 提倡使用下面的方法
es.index(index='test', id='2', doc={"name": "方天", "age": "23"})# 插入数据 es.create() 必须提供 id,当索引中已存在具有相同 ID 的文档时,返回 409 响应。
es.create(index='test', id='3', doc={"name": "方天", "age": "23"})# 更新数据 必须提供 id
es.update(index='test', id='3', doc={"name": "方天", "age": "23"})# 查询数据
es.get(index='test',id='1')
1) 检索数据:利用 elasticsearch-analysis-ik 进行分词
Elasticsearch 具有一个强大的信息检索功能,对于中文来说,我们需要安装一个中文分词插件,如 elasticsearch-analysis-ik,这里我们可以使用 Elasticsearch 的命令行工具 elasticsearch-plugin 来安装这个插件:infinilabs/analysis-ik: 🚌 The IK Analysis plugin integrates Lucene IK analyzer into Elasticsearch and OpenSearch, support customized dictionary. (github.com)
elasticsearch-plugin install https://get.infini.cloud/elasticsearch/analysis-ik/8.4.1
安装完毕后,重新启动 Elasticsearch,会自动加载安装好的插件,然后我们定义一个 mapping,指定搜索分词器 search_analyzer 为 ik_smart (书上是 ik_max_word )
from elasticsearch import Elasticsearch# 连接 Elasticsearch 默认连接本地9200端口
es = Elasticsearch(hosts:"localhost",port:9200,verify_certs=True # 是否验证证书
)# 指定搜索分词器 search_analyzer 为 ik_smart (书上是 ik_max_word )
mapping = {"properties": {"content": {"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_smart"}}
}
es.indices.put_mapping(index='news', body=mapping)
然后我们可以使用 search 函数搭配 query 进行解锁;
# 基础查询 -> 查询 test 索引前 10 条数据
es.search(index='test')# 过滤字段查询 -> 只显示test索引的age字段信息
es.search(index='test',filter_path=['hits.hits._source.age'])# 切片查询 -> 查询test索引中,从序号为1的位置查询两条数据
es.search(index='test', from_=1, size=2)# 模糊查询(分词)-> 查询test索引中,age字段为20的数据
es.search(index='test', query={'match':{'age':20}})# 模糊查询(不分词)-> 查询test索引中,name字段为杨晨的数据
es.search(index='test', query={'match_phrase':{'name':'杨晨'}})# 精准单值查询 -> 查询test索引中,age为20的数据
es.search(index='test', query={'term':{'age':20}})# 精准单值查询 -> 查询test索引中,name为杨晨的数据,查询中文,要在字段后面加上.keyword
es.search(index='test', query={'term':{'name.keyword':'杨晨'}})# 精准多值查询 -> 查询test索引中,name为杨晨或小明的数据
es.search(index='test', query={'terms':{'name.keyword':['杨晨','小明']}})# 多字段查询 -> 查询test索引中,name和about都为小美的数据
es.search(index='test',query={'multi_match':{'query':'小美',"fields":['name','about']}})# 前缀查询 -> 查询test索引中,name字段前缀为小的数据
es.search(index='test',query={'prefix':{'name.keyword':'小'}})# 通配符查询 -> 查询test索引中,name字段为杨*的数据
es.search(index='test',query={'wildcard':{'name.keyword':'杨?'}})# 正则查询 -> 查询test索引中,name字段为杨*的数据
es.search(index='test',query={'regexp':{'name.keyword':'杨.'}})# 多条件查询 -> 查询test索引中,name字段为小美,id字段为1的数据
es.search(index='test',query={'bool':{'must':{'term':{'name':'小美'},'term':{'id':'1'}}}})# 存在字段查询 -> 查询test索引中,包含age字段的数据
es.search(index='test',query={'exists':{'field':'age'}})# 范围查询 -> 查询test索引中,age字段大于20小于等于23的数据
es.search(index='test',query={'range':{'age':{'gt':20,'lte':23}}})# Json字段查询 -> 查询test索引中,jsonfield1字段下json数据jsonfield2字段的数据包含'json'的数据
es.search(index='test',query={'nested':{'path':'jsonfield1','query':{'term':{'jsonfield1.jsonfield2':'json'}}}})# 排序 -> 查询test索引中的数据,按照age字段降序
es.search(index='test', sort={'age.keyword':{'order':'desc'}})
2) dsl 语句:Search DSL — Elasticsearch DSL 8.14.0 documentation (elasticsearch-dsl.readthedocs.io)
5. RabbitMQ
首先需要安装 RabbitMQ,安装完毕后,还有需要安装一个操作 RabbitMQ 的库,pika
- RabbitMQ 的安装 | 静觅 (cuiqingcai.com)
- Installing on Windows | RabbitMQ
- Introduction to Pika — pika 1.3.2 documentation
pip install pika
在爬取过程中,我们可能需要一些进程间的通信机制,例如:
- 一个进程负责构造爬取请求,另一个进程负责执行爬取请求;
- 某个数据爬取进程执行完毕,通知另外一个负责数据处理的进程开始处理数据;
- 某个进程新建了一个爬取任务,通知另外一个负责数据爬取的进程开始爬取数据;
在这里我们可以使用 RabbitMQ 作为消息队列的中间件来存储和转化信息,有了消息队列中间件后,以上各机制中的两个进程就可以独立执行,他们之间的通信则由消息队列实现;
- 声明队列:通过指定一些参数,创建消息队列;
- 生产内容:根据队列的连接信息连接队列,往队列中放入消息;
- 消费内容:根据队列的连接信息连接队列,从队列中取出消息;
1) 声明队列
无论是生产队列还是消费队列,都需要创建 channel 才可以操作队列,其中生产队列需要声明队列
import pikaQUEUE_NAME = 'scrape'
parameters = pika.ConnectionParameters(host='losthost')
connection = pika.BlockingConnection(parameters)channel = connection.channel()# 生产队列需要声明
channel.queue_declare(queue=QUEUE_NAME)
2) 生产内容
在声明队列的时候,添加 durable 参数可以持久化
import pika
import requests
import pickleMAX_PRIORITY = 100
TOTAL = 100
QUEUE_NAME = 'scrape'connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue=QUEUE_NAME, durable=True)for i in range(1, TOTAL + 1):url = f'https://ssr1.scrape.center/detail/{i}'request = requests.Request('GET', url)print('re', request)channel.basic_publish(exchange='',routing_key=QUEUE_NAME,properties=pika.BasicProperties(delivery_mode=2,),body=pickle.dumps(request))print(f'Put request of {url}')
3) 消费内容
import pika
import pickle
import requestsMAX_PRIORITY = 100
QUEUE_NAME = 'scrape3'connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()session = requests.Session()def scrape(request):try:response = session.send(request.prepare())print(f'success scraped {response.url}')except requests.RequestException:print(f'error occurred when scraping {request.url}')while True:method_frame, header, body = channel.basic_get(queue=QUEUE_NAME, auto_ack=True)if body:print(f'Get {body}')request = pickle.loads(body)print(request)scrape(request)
更具体的介绍在 Introduction to Pika — pika 1.3.2 documentation 和 Python3WebSpider/RabbitMQTest: RabbitMQ Test (github.com)
相关文章:
数据的存储)
Python3网络爬虫开发实战(4)数据的存储
文章目录 一、文本文件存储1. os 文件 mode2. TXT3. JSON4. CSV 二、数据库存储1. SQLAlchemy2. MongoDB3. Redis1) 键操作2) 字符串操作3) 列表操作4) 集合操作5) 有序集合操作6) 散列操作 4. Elasticsearch1) 检索数据:利用 elasticsearch-analysis-ik 进行分词2)…...

《C++基础入门与实战进阶》专栏介绍
🚀 前言 本文是《C基础入门与实战进阶》专栏的说明贴(点击链接,跳转到专栏主页,欢迎订阅,持续更新…)。 专栏介绍:以多年的开发实战为基础,总结并讲解一些的C/C基础与项目实战进阶内…...
- 数据清洗)
每天一个数据分析题(四百五十)- 数据清洗
数据在真正被使用前需进行必要的清洗,使脏数据变为可用数据。下列不属于“脏数据”的是() A. 重复数据 B. 错误数据 C. 交叉数据 D. 缺失数据 数据分析认证考试介绍:点击进入 题目来源于CDA模拟题库 点击此处获取答案 数据…...

昇思25天学习打卡营第XX天|Pix2Pix实现图像转换
Pix2Pix是一种基于条件生成对抗网络(cGAN)的图像转换模型,由Isola等人在2017年提出。它能够实现多种图像到图像的转换任务,如从草图到彩色图像、从白天到夜晚的场景变换等。与传统专用机器学习方法不同,Pix2Pix提供了一…...

数据结构经典测试题5
1. int main() { char arr[2][4]; strcpy (arr[0],"you"); strcpy (arr[1],"me"); arr[0][3]&; printf("%s \n",arr); return 0; }上述代码输出结果是什么呢? A: you&me B: you C: me D: err 答案为A 因为arr是一个2行4列…...

React Native初次使用遇到的问题
Write By Monkeyfly 以下内容均为原创,如需转载请注明出处。 前提:距离上次写博文已经过去了5年之久,诸多原因导致的,写一篇优质博文确实费时费力,中间有其他更感兴趣的事要做(打游戏、旅游、逛街、看电影…...

2024西安铁一中集训DAY28 ---- 模拟赛(简单dp + 堆,模拟 + 点分治 + 神秘dp)
文章目录 前言时间安排及成绩题解A. 江桥不会做的签到题(简单dp)B. 江桥树上逃(堆,模拟)C. 括号平衡路径(点分治)D. 回到起始顺序(dp,组合数学) 前言 T2好难…...

【论文阅读笔记 + 思考 + 总结】MoMask: Generative Masked Modeling of 3D Human Motions
创新点: VQ-VAE 👉 Residual VQ-VAE,对每个 motion sequence 输出一组 base motion tokens 和 v 组 residual motion tokensbidirectional 的 Masked transformer 用来生成 base motion tokensResidual Transformer 对 residual motion toke…...

Mojo控制语句详解
Mojo 包含几个传统的控制流结构,用于有条件和重复执行代码块。 The if statement Mojo 支持条件代码执行语句。有了它,当给定的布尔表达式计算结果为 时,if您可以有条件地执行缩进的代码块 。True temp_celsius = 25 if temp_celsius > 20:print("It is warm.&quo…...

web安全基础学习
http基础 HTTP(HyperText Transfer Protocol,超文本传输协议)是一种用于分布式、协作式和超媒体信息系统的应用层协议。本文将介绍如何使用HTTP协议,以及在Linux操作系统中如何使用curl工具发起HTTP请求。 一、HTTP特性 无状态…...

天气预报的爬虫内容打印并存储用户操作
系统名称: 基于网络爬虫技术的天气数据查询系统文档作者:清馨创作时间:2024-7-29最新修改时间:2024-7-29最新版本号: 1.0 1.背景描述 该系统将基于目前比较流行的网络爬虫技术,对网站上(NowAPI…...
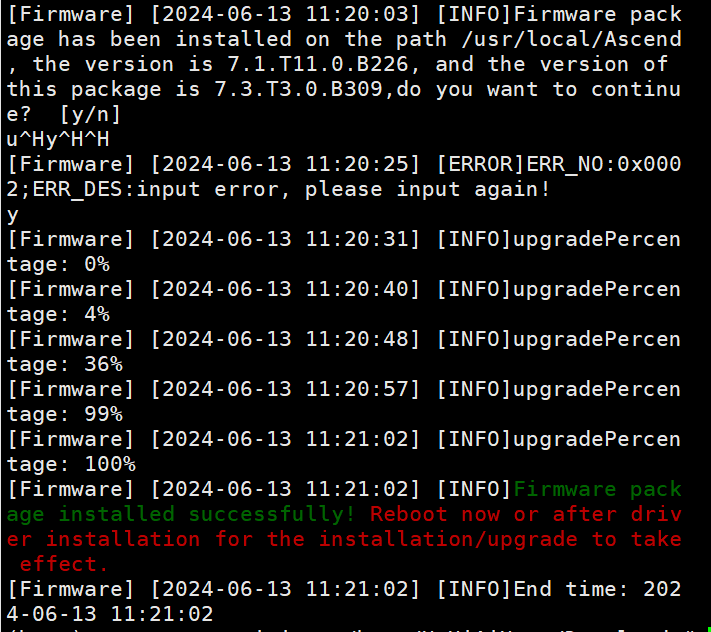
OrangePi AI Pro 固件升级 —— 让主频从 1.0 GHz 到 1.6 GHz 的巨大升级
前言 OrangePi AI Pro 最近发布了Ascend310B-firmware 固件包,据说升级之后可以将 CPU 主频从 1.0 GHz 提升至 1.6 GHz,据群主大大说,算力也从原本的 8T 提升到了 12T,这波开发板的成长让我非常的 Amazing 啊!下面就来…...

学习大数据DAY27 Linux最终阶段测试
满分:100 得分:72 目录 一选择题(每题 3 分,共计 30 分) 二、编程题(共 70…...

ctr管理containerd基本命令
1. 创建命名空间 创建名为custom的命令空间 ctr ns create custom2. 导入镜像 把镜像导入到刚刚创建的空间 ctr -n custom images improt restfulapi.tar3. 创建容器 创建一个test_api的容器 ctr -n custom run --null-io --net-host -d --mount typebind,src/etc,dst/ho…...
)
rust 初探 -- 路径(path)
rust 初探 – 路径Path 路径(Path) 目的:为了在 Rust 的模块中找到某个条目,需要使用 路径两种形式: 绝对路径:从 crate root 开始,使用 crate 名或字面值 crate相对路径:从当前模…...
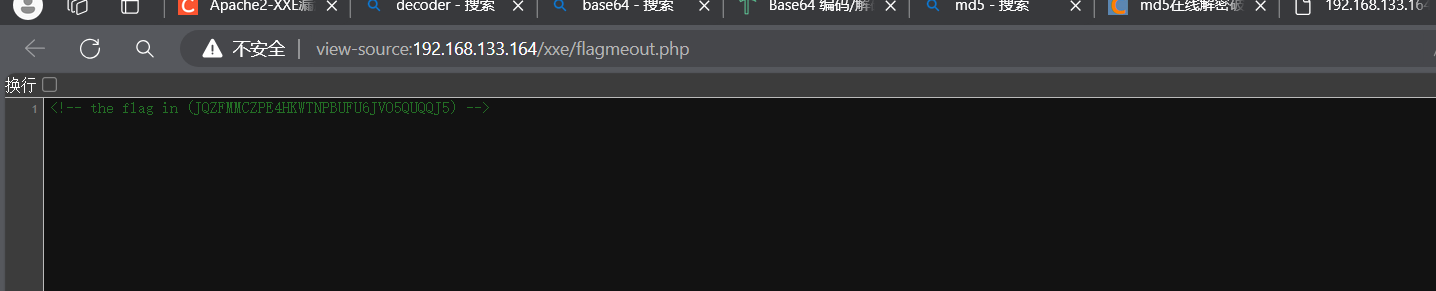
XXE -靶机
XXE靶机 一.扫描端口 进入xxe靶机 1.1然后进入到kali里 使用namp 扫描一下靶机开放端口等信息 1.2扫描他的目录 二 利用获取的信息 进入到 robots.txt 按他给出的信息 去访问xss 是一个登陆界面 admin.php 也是一个登陆界面 我们访问xss登陆界面 随便输 打开burpsuite抓包 发…...

vue2 搭配 html2canvas 截图并设置截图时样式(不影响页面) 以及 base64转file文件上传 或者下载截图 小记
下载 npm install html2canvas --save引入 import html2canvas from "html2canvas"; //使用 html2canvasForChars() { // 使用that来存储当前Vue组件的上下文,以便在回调函数中使用 let that this; // 获取DOM中id为"charts"的元素&…...
请大家监督:我要开启Python之路,首要任务最简单的搭建环境
任务说明: 如上图所示,Python稳稳第一,为何?因为Python可以做很多事情,比如:Web开发,网络爬虫,软件开发、数据分析、游戏开发,金融分析,人工智能与机器学习&a…...

http协议深度解析——网络时代的安全与效率(1)
作者简介:一名云计算网络运维人员、每天分享网络与运维的技术与干货。 公众号:网络豆云计算学堂 座右铭:低头赶路,敬事如仪 个人主页: 网络豆的主页 目录 写在前面: 本章目的: …...

类和对象【下】
一、类的默认成员函数 默认成员函数从名字就告诉我们何为默认成员函数,即:用户没有实现,编译器默认自动实现的函数。 这时你不禁一喜,还有这好事,编译器给我打工,那么,我们今天都来了解一下都有…...

Gemma-3-12b-it实战教程:对接企业微信/钉钉机器人实现图文消息自动解析
Gemma-3-12b-it实战教程:对接企业微信/钉钉机器人实现图文消息自动解析 1. 引言:当多模态AI遇上企业协作 想象一下这个场景:你的同事在企业微信群里发了一张复杂的业务流程图,问“这个流程的第三步有什么风险?”或者…...

Qwen3-TTS-VoiceDesign实战案例:用‘撒娇稚嫩萝莉声’描述生成高拟真TTS音频
Qwen3-TTS-VoiceDesign实战案例:用‘撒娇稚嫩萝莉声’描述生成高拟真TTS音频 1. 项目概述与核心价值 Qwen3-TTS-VoiceDesign是一个让人惊艳的语音合成模型,它最大的特点就是能用简单的文字描述,生成你想要的任何声音风格。想象一下…...

vLLM-v0.17.1实操手册:Prometheus监控指标接入与告警配置
vLLM-v0.17.1实操手册:Prometheus监控指标接入与告警配置 1. vLLM框架简介 vLLM是一个专为大型语言模型(LLM)设计的高性能推理和服务库,由加州大学伯克利分校的天空计算实验室(Sky Computing Lab)开发,现已发展为社区驱动的开源项目。这个框…...

从AHB到AXI:手把手带你用Verilog仿真看Outstanding如何提升SoC数据吞吐
从AHB到AXI:深入解析Outstanding机制如何优化SoC数据吞吐效率 在复杂的SoC设计中,总线架构的选择直接影响系统性能。传统AHB总线虽然结构简单,但在高并发场景下容易成为瓶颈。AXI协议通过引入Outstanding、Out-of-order等机制,显著…...

OpCore-Simplify:实现OpenCore EFI自动化生成的黑苹果配置解决方案
OpCore-Simplify:实现OpenCore EFI自动化生成的黑苹果配置解决方案 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 副标题:告别…...

Qwen3.5-4B-Claude-Opus快速上手:Web页面直接调用推理蒸馏模型
Qwen3.5-4B-Claude-Opus快速上手:Web页面直接调用推理蒸馏模型 1. 模型概述 Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF 是一个基于 Qwen3.5-4B 的推理蒸馏模型,重点强化了结构化分析、分步骤回答、代码与逻辑类问题的处理能力。该版本以 G…...

SIM800L新手避坑指南:从电源不稳到中文短信发送,我的踩坑实录
SIM800L实战避坑手册:从电源设计到中文短信的完整解决方案 第一次拿到SIM800L模块时,我天真地以为这不过是个"高级版蓝牙模块"。直到电源指示灯开始疯狂闪烁、串口不断吐出乱码、中文短信变成问号时,我才意识到自己掉进了技术深坑。…...
)
DeepSeek LintCode 3866.有效子数组的数量 public int validSubarrays(int[] nums)
这是关于LintCode 3866 “有效子数组的数量”的问题。这是一个典型的单调栈应用问题,需要计算数组中所有满足特定条件的子数组数量。 问题理解 有效子数组的定义: 对于数组 nums 中的某个子数组 nums[i..j](i ≤ j),如…...

Image-to-Video镜像使用技巧:提示词怎么写?参数怎么调?
Image-to-Video镜像使用技巧:提示词怎么写?参数怎么调? 1. 快速上手Image-to-Video镜像 Image-to-Video图像转视频生成器是一款基于I2VGen-XL模型的实用工具,能够将静态图片转化为动态视频。这个由科哥二次开发的镜像已经预装了…...

动态规划详解:从入门到精通,这四个案例让你彻底掌握DP思想
面试必考、算法进阶的核心,一篇文章帮你打通任督二脉在算法学习的过程中,动态规划(Dynamic Programming,简称DP)绝对是让很多人头疼的一个难点。很多初学者看到DP问题就发怵,其实只要掌握了核心思想&#x…...