【实战】机器学习Kaggle比赛—House Prices - Advanced Regression Techniques
House Prices - Advanced Regression Techniques
- 一、准备工作
- (1)查看项目概述
- (2)下载数据集
- (3)导入部分必要的库
- (4)参数设置(图形显示大小+屏蔽警告)
- (5)导入数据集
- 二、特征分析
- (1)分析数据特征
- (2)分析时间序列特征
- 三、数据预处理
- (一)合并数据
- (二)对于数字特征
- (1)减小时间特征值的大小
- (2) 正态化 SalePrice
- (3)连续值归一化(有些数太大了,严重影响拟合情况)
- (4)无效值用该列平均值填充
- (三)对于类别特征
- 四、建立模型
- (一)数据准备
- (二)定义均方根误差函数(评分指标)
- (三)建立 Ridge 回归模型
- (1)模型最佳的 alpha 值的选取
- (2)训练模型+预测结果
- (3)输出结果
- (四)建立 Lasso 回归模型
- (五)建立XGBoost 回归模型
- (六)基于前三种回归模型建立 集成学习 模型
- (1)Ridge 为主 Lasso 为辅
- (2)Lasso 为主 Ridge 为辅
- (3)Lasso 为主 Ridge、XGboost 为辅
- (4)XGboost 为主 Ridge、Lasso 为辅
- (4)单 XGboost + 手动调参
- (5)尝试混合模型(自行设置比列)
一、准备工作
(1)查看项目概述
网址:https://www.kaggle.com/competitions/house-prices-advanced-regression-techniques/overview

简单来说,就是我们需要根据一些房子的信息数据(所有房子的79个特征表现,部分房子的真实房价),来预测其他的房子的价格。
(2)下载数据集

一直往下翻


(3)导入部分必要的库
import pandas as pd
import numpy as np
import matplotlibimport matplotlib.pyplot as plt
from scipy.stats import skew
(4)参数设置(图形显示大小+屏蔽警告)
- %matplotlib inline 是一个 Jupyter Notebook 中的魔术命令(magic command),用于设置 Matplotlib 图形直接在 Notebook 单元格中显示,而不是在一个单独的窗口中显示
- matplotlib.rcParams[‘figure.figsize’] = (12.0, 6.0) 设置 Matplotlib 绘图时的默认图形尺寸。具体来说,rcParams 是 Matplotlib 的运行时配置参数,figure.figsize 是其中一个参数,用于指定图形的宽度和高度。
%matplotlib inline
matplotlib.rcParams['figure.figsize'] = (12.0, 6.0)import warnings
warnings.filterwarnings("ignore")
(5)导入数据集
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
二、特征分析
(1)分析数据特征



(2)分析时间序列特征
year_feats = [col for col in all_data.columns if "Yr" in col or 'Year' in col]
year_feats

- 然后检查一下这些特征与销售价格是否有关系
根据 YrSold 列对 all_data 中此列数据框进行分组,并计算每个分组中 SalePrice 列的中位数,然后绘制这些中位数随时间变化的折线图
combined_df = pd.concat([train,test],axis=0)combined_df.groupby('YrSold')['SalePrice'].median().plot()
plt.xlabel('Year Sold')
plt.ylabel('House Price')
plt.title('House price vs YearSold')

- 绘制其他三个特征与销售价格的散点对应图
for feature in year_feats:if feature != 'YrSold':hs = combined_df.copy()plt.scatter(hs[feature],hs['SalePrice'])plt.xlabel(feature)plt.ylabel('SalePrice')plt.show()



可以看到随着时间的增加,价格是逐增加的
三、数据预处理
(一)合并数据
all_data = pd.concat([train.loc[:, 'MSSubClass':'SaleCondition'],test.loc[:, 'MSSubClass':'SaleCondition']])
(二)对于数字特征
(1)减小时间特征值的大小
- 用售卖时间减去 build/remodadd/garageBuild 的时间
在某些情况下,直接使用年份数据可能不如使用年龄数据有效,年龄数据可以减少年份数据中的噪声,并可能提高模型的性能
for feature in ['YearBuilt','YearRemodAdd','GarageYrBlt']:all_data[feature]=all_data['YrSold']-all_data[feature]
(2) 正态化 SalePrice
- skew() 是一个统计函数,用于计算数据集的偏度(skewness)。偏度是描述数据分布形态的一个统计量,它衡量数据分布的不对称程度。对偏斜程度大于0.75的做log1p处理,减少数据的偏度,使其更接近正态分布
prices = pd.DataFrame({"price":train["SalePrice"],"log(price + 1)":np.log1p(train["SalePrice"])})
train["SalePrice"] = np.log1p(train["SalePrice"])numeric_feats = all_data.dtypes[all_data.dtypes != 'object'].indexskewed_feats = train[numeric_feats].apply(lambda x: skew(x.dropna()))
skewed_feats = skewed_feats[skewed_feats > 0.75]
skewed_feats = skewed_feats.index
all_data[skewed_feats] = np.log1p(all_data[skewed_feats])
(3)连续值归一化(有些数太大了,严重影响拟合情况)
all_data[numeric_feats] = all_data[numeric_feats].apply(lambda x: (x - x.mean())/(x.std()))
(4)无效值用该列平均值填充
all_data = all_data.fillna(all_data.mean())
(三)对于类别特征
- 扩充成特征列(用0、1表示),以达到值全部都是数的效果,这样计算机才能读懂
将 all_data 数据框中的分类变量进行独热编码,并将结果重新赋值给 all_data。经过 get_dummies 处理后,all_features 数据框中的每个分类变量都会被转换为多个二进制列,每个列对应一个分类变量的一个唯一值。
如果 dummy_na=True,还会为每个包含 NaN 的分类变量创建一个额外的列来表示 NaN 值。
all_data = pd.get_dummies(all_data)
四、建立模型
(一)数据准备
(1)分别拿到训练和测试特征,训练标签
因之前合并了数据进行特征处理,这里把数据集拆分还原为训练集和测试集,还要将训练标签拆分出来
- .shape( ) 返回一个包含数据框形状的元组 (rows, columns),这里.shape[0]通过索引 [0] 访问元组的第一个元素,即数据框的行数,作用就是计算并存储 train 数据框的行数,即训练数据集的样本数量
- train.SalePrice 从名为 train 的 DataFrame 中提取 SalePrice 这一列,并将其赋值给变量 y
X_train = all_data[:train.shape[0]]
X_test = all_data[train.shape[0]:]
y = train.SalePrice
(2)导入训练模型所需的库
- Ridge 和 RidgeCV:
Ridge 是 Ridge 回归模型,一种线性回归的正则化版本,通过添加 L2 正则化项(即平方和惩罚项)来防止过拟合。
RidgeCV 是 Ridge 回归的交叉验证版本,用于自动选择最佳的正则化参数(alpha)。- ElasticNet:
ElasticNet 是一种结合了 L1 和 L2 正则化的线性回归模型。它同时使用 L1 正则化(Lasso)和 L2 正则化(Ridge)来平衡特征选择和模型复杂度。- LassoCV 和 LassoLarsCV:
LassoCV 是 Lasso 回归的交叉验证版本,Lasso 回归通过添加 L1 正则化项(即绝对值和惩罚项)来进行特征选择和防止过拟合。
LassoLarsCV 是使用最小角回归(Least Angle Regression, LARS)算法的 Lasso 回归的交叉验证版本,适用于高维数据集。
from sklearn.linear_model import Ridge, RidgeCV, ElasticNet, LassoCV, LassoLarsCV
from sklearn.model_selection import cross_val_score
(二)定义均方根误差函数(评分指标)
- 通过交叉验证(cross-validation)来评估模型的性能
- cross_val_score 是一个函数,用于执行交叉验证并返回每个折叠的评分
- scoring=‘neg_mean_squared_error’ 指定评分指标为负的均方误差(Negative Mean Squared Error)。由于 cross_val_score 返回的是负的均方误差,我们需要取负号来得到正的均方误差。
- cv=5 指定使用 5 折交叉验证。
def rmse_cv(model):rmse = np.sqrt(-cross_val_score(model, X_train, y, scoring='neg_mean_squared_error', cv=5))return rmse
(三)建立 Ridge 回归模型
(1)模型最佳的 alpha 值的选取
- 通过交叉验证评估不同 alpha 值对 Ridge 回归模型性能的影响,并绘制结果图表,以便选择最佳的 alpha 值
- model_ridge = Ridge() 创建了一个 Ridge 回归模型的实例,但并没有指定 alpha 值。alpha 值是 Ridge 回归中的正则化参数,用于控制模型的复杂度。
- 还定义了一个包含不同 alpha 值的列表。这些 alpha 值将用于评估 Ridge 回归模型的性能。
- 接着定义了一个列表推导式,对于 alphas 列表中的每个 alpha 值,创建一个 Ridge 模型实例,并指定该 alpha 值。调用 rmse_cv 函数计算该模型的 RMSE,rmse_cv 函数通过交叉验证返回每个折叠的 RMSE 值。对每个 alpha 值的 RMSE 值取平均,得到该 alpha 值对应的平均 RMSE。
model_ridge = Ridge()alphas = [0.05, 0.1, 0.3, 1, 3, 5, 10, 15, 30, 50, 75]
cv_ridge = [rmse_cv(Ridge(alpha = alpha)).mean() for alpha in alphas]
cv_ridge = pd.Series(cv_ridge, index = alphas)
cv_ridge.plot(title = "Validation")
plt.xlabel("Alpha")
plt.ylabel("RMSE")

可以看到 alpha=10 时效果最好,我们就取 alpha=10
(2)训练模型+预测结果
- fit 方法会根据输入数据调整模型的参数,使其能够对数据进行预测。训练后的模型存储在 ridge_model_after_fit 变量中。
- predict 方法返回预测结果。由于在训练过程中对目标变量 y 进行了对数变换(np.log1p),这里使用 np.expm1 对预测结果进行逆变换,将其转换回原始的房价范围。np.expm1 是 np.exp(x) - 1 的简写,用于计算 exp(x) - 1。
chosen_alpha = 10
model_ridge = Ridge(alpha = chosen_alpha)ridge_model_after_fit = model_ridge.fit(X_train, y)ridge_preds = np.expm1(model_ridge.predict(X_test))
(3)输出结果
solution = pd.DataFrame({"id":test.Id, "SalePrice":ridge_preds})
solution.to_csv("ridge_sol_alpha10.csv", index=False)
(四)建立 Lasso 回归模型
步骤与前面类似,这里不再阐述
model_lasso = LassoCV(alphas = [20, 10, 1, 0.1, 0.01, 0.001, 0.0005]).fit(X_train, y)lasso_preds = np.expm1(model_lasso.predict(X_test))solution = pd.DataFrame({"id":test.Id, "SalePrice":lasso_preds})
solution.to_csv("lasso_sol.csv", index=False)
(五)建立XGBoost 回归模型
- DMatrix 是 XGBoost 中用于存储数据的一种数据结构,它优化了内存使用和计算效率。
- objective 指定了模型的目标函数为回归问题中的平方误差。colsample_bylevel 指定类每层的列采样比例
- 用交叉验证来训练 XGBoost 模型。xgb.cv 函数会在指定的 num_boost_round 轮迭代中训练模型,并在 early_stopping_rounds 轮内没有提升时提前停止训练
- xgb.XGBRegressor 是 XGBoost 库中的一个类,用于创建一个梯度提升回归模型。n_estimators=360 指定了模型的迭代次数,即构建的树的数量。在这个例子中,模型将构建 360 棵树。max_depth=2 指定了每棵树的最大深度。树的深度控制了模型的复杂度,较小的深度可以防止过拟合。在这个例子中,每棵树的最大深度为 2。learning_rate=0.1 指定了学习率,也称为收缩因子(shrinkage factor)。学习率控制了每棵树对最终预测结果的贡献程度。较小的学习率可以防止过拟合,但可能需要更多的树来达到较好的性能。在这个例子中,学习率为 0.1。
- model_xgb = xgb.XGBRegressor(n_estimators=360, max_depth=2, learning_rate=0.1) 和 model_xgb.fit(X_train, y) 用于创建和训练模型,而 model = xgb.cv(params, dtrain, num_boost_round=500, early_stopping_rounds=100) 用于通过交叉验证评估模型性能并选择最佳的迭代次数。这三行代码共同构成了一个完整的模型训练和评估流程。
import xgboost as xgbdtrain = xgb.DMatrix(X_train, label=y)
dtest = xgb.DMatrix(X_test)params = {"objective":"reg:squarederror","max_depth": 4,"colsample_bylevel": 0.5,"learning_rate": 0.1,"random_state": 20}
model = xgb.cv(params, dtrain, num_boost_round=500, early_stopping_rounds=100)model_xgb = xgb.XGBRegressor(n_estimators=360, max_depth=2, learning_rate=0.1)
model_xgb.fit(X_train, y)xgb_preds = np.expm1(model_xgb.predict(X_test))solution = pd.DataFrame({"id":test.Id, "SalePrice":xgb_preds})
solution.to_csv("xgb_sol.csv", index=False)
(六)基于前三种回归模型建立 集成学习 模型
(1)Ridge 为主 Lasso 为辅
- 创建了一个堆叠回归模型 model_stacked,它使用 model_ridge 和 model_lasso 作为基础回归模型,并使用 model_ridge 作为元回归模型。
- use_features_in_secondary=True 元回归模型将训练阶段得到的特征信息应用到预测阶段。这种堆叠方法可以提高模型的性能,因为它结合了多个模型的优势。
from mlxtend.regressor import StackingCVRegressor
model_stacked = StackingCVRegressor(regressors=(model_ridge, model_lasso),meta_regressor=model_ridge,use_features_in_secondary=True)
rmse = rmse_cv(model_stacked)
print("model_stacked: {:.4f} ({:.4f})".format(rmse.mean(), rmse.std()))
rmse = rmse_cv(model_ridge)
print("model_ridge: {:.4f} ({:.4f})".format(rmse.mean(), rmse.std()))
rmse = rmse_cv(model_lasso)
print("model_lasso: {:.4f} ({:.4f})".format(rmse.mean(), rmse.std()))
rmse = rmse_cv(model_xgb)
print("model_xgb: {:.4f} ({:.4f})".format(rmse.mean(), rmse.std()))

分数不是很理想,以 Lasso 为主试一下
(2)Lasso 为主 Ridge 为辅
model_stacked = StackingCVRegressor(regressors=(model_ridge, model_lasso),meta_regressor=model_lasso,use_features_in_secondary=True)
rmse = rmse_cv(model_stacked)
print("model_stacked: {:.4f} ({:.4f})".format(rmse.mean(), rmse.std()))
rmse = rmse_cv(model_ridge)
print("model_ridge: {:.4f} ({:.4f})".format(rmse.mean(), rmse.std()))
rmse = rmse_cv(model_lasso)
print("model_lasso: {:.4f} ({:.4f})".format(rmse.mean(), rmse.std()))
rmse = rmse_cv(model_xgb)
print("model_xgb: {:.4f} ({:.4f})".format(rmse.mean(), rmse.std()))

好了点,再加上 XGboost 试一下
(3)Lasso 为主 Ridge、XGboost 为辅
model_stacked = StackingCVRegressor(regressors=(model_ridge, model_lasso, model_xgb),meta_regressor=model_lasso,use_features_in_secondary=True)
rmse = rmse_cv(model_stacked)
print("model_stacked: {:.4f} ({:.4f})".format(rmse.mean(), rmse.std()))
rmse = rmse_cv(model_ridge)
print("model_ridge: {:.4f} ({:.4f})".format(rmse.mean(), rmse.std()))
rmse = rmse_cv(model_lasso)
print("model_lasso: {:.4f} ({:.4f})".format(rmse.mean(), rmse.std()))
rmse = rmse_cv(model_xgb)
print("model_xgb: {:.4f} ({:.4f})".format(rmse.mean(), rmse.std()))

得分看起来挺好的,其他组合都可以试一下,但从单个模型的效果上来看,只有下面这种组合有预测提升的可能
(4)XGboost 为主 Ridge、Lasso 为辅
model_stacked = StackingCVRegressor(regressors=(model_ridge, model_lasso, model_xgb),meta_regressor=model_xgb,use_features_in_secondary=True)
rmse = rmse_cv(model_stacked)
print("model_stacked: {:.4f} ({:.4f})".format(rmse.mean(), rmse.std()))
rmse = rmse_cv(model_ridge)
print("model_ridge: {:.4f} ({:.4f})".format(rmse.mean(), rmse.std()))
rmse = rmse_cv(model_lasso)
print("model_lasso: {:.4f} ({:.4f})".format(rmse.mean(), rmse.std()))
rmse = rmse_cv(model_xgb)
print("model_xgb: {:.4f} ({:.4f})".format(rmse.mean(), rmse.std()))

(4)单 XGboost + 手动调参
xgb_params = dict(max_depth=3,learning_rate=0.05,n_estimators=1000,min_child_weight=1,colsample_bytree=0.3,subsample=0.4,reg_alpha=0.5,reg_lambda=0.1,num_parallel_tree=1
)
model_xgb = xgb.XGBRegressor(**xgb_params)rmse = rmse_cv(model_xgb)
print("model_xgb: {:.4f} ({:.4f})".format(rmse.mean(), rmse.std()))

得分不错
(5)尝试混合模型(自行设置比列)
from skimage.metrics import mean_squared_errormodel_stacked.fit(X_train, y)ridge_preds_train = model_ridge.predict(X_train)
lasso_preds_train = model_lasso.predict(X_train)
xgb_preds_train = model_xgb.predict(X_train)
stacked_preds_train = model_stacked.predict(X_train)train_blended_predictions = (0.80 * xgb_preds_train) + \(0.2 * stacked_preds_train)
print(np.sqrt(mean_squared_error(y, train_blended_predictions)))ridge_preds_test = model_ridge.predict(X_test)
lasso_preds_test = model_lasso.predict(X_test)
xgb_preds_test = model_xgb.predict(X_test)
stacked_preds_test = model_stacked.predict(X_test)blended_predictions = (0.20 * ridge_preds_test) + \(0.70 * xgb_preds_test) + \(0.10 * stacked_preds_test)
blended_predictions = np.floor(np.expm1(blended_predictions))solution = pd.DataFrame({"id":test.Id, "SalePrice":blended_predictions})
solution.to_csv("blended_predictions.csv", index=False)


相关文章:
【实战】机器学习Kaggle比赛—House Prices - Advanced Regression Techniques
House Prices - Advanced Regression Techniques 一、准备工作(1)查看项目概述(2)下载数据集(3)导入部分必要的库(4)参数设置(图形显示大小屏蔽警告)…...

【前端面试题】前端工程化、Webpack、Vite、Git项目管理相关问题
目录 关于前端工程化关于Webpack关于Vite关于Git项目管理综合性问题 关于前端工程化 1. 前端工程化的定义和好处 问题:什么是前端工程化?它的主要好处是什么?答案:前端工程化是指在前端开发中应用系统化、自动化和标准化的方法&…...

【号外】「省点时间」新功能暖心上线!
好消息,好消息,重大好消息! 应广大用户朋友的要求,经过一个多月的鏖战,「省点时间」的VIP功能终于上线啦! 新版本在原有基础上,新增VIP功能,用户拥有了更多选择,赶快来…...

Python面试题:如何使用WebSocket实现实时Web应用
使用 WebSocket 实现实时 Web 应用可以使你的应用程序具备实时双向通信的能力。以下是一个完整的指南,展示如何使用 Django Channels 和 WebSocket 实现一个简单的实时 Web 应用。 环境准备 安装 Django Channels: pip install channels创建 Django 项目: django-a…...
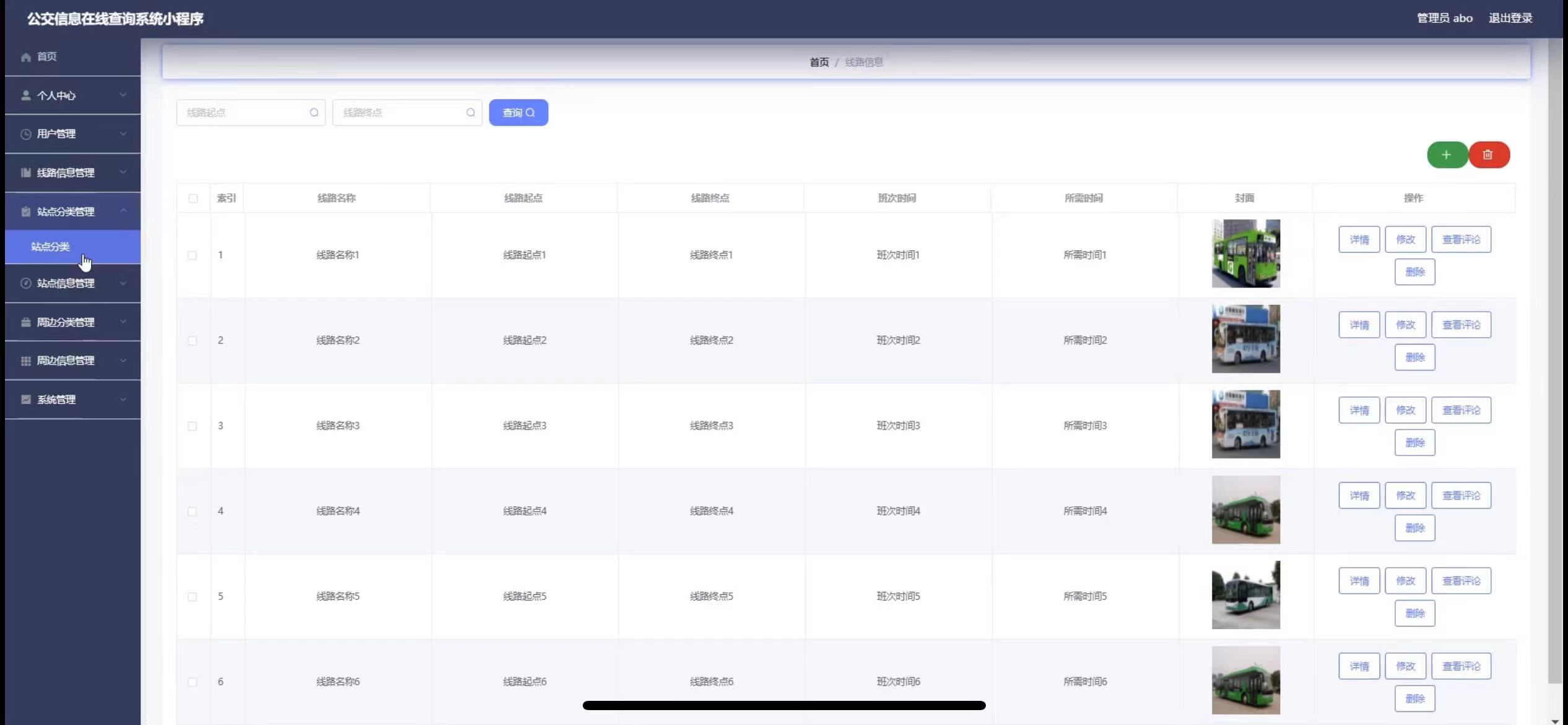
公交信息在线查询小程序的设计
管理员账户功能包括:系统首页,个人中心,用户管理,线路信息管理,站点分类管理,站点信息管理,周边分类管理周边信息管理,系统管理 微信端账号功能包括:系统首页࿰…...

Airtest实施手机精准截图
Airtest实施手机精准截图 一、接口查找 首先我们需要知道我们应该怎么实现用脚本去进行局部截图,我们可以通过翻阅Airtest的API文档发现,Airtest提供了 crop_image(img, rect) 方法可以帮助我们实现局部截图,在我们往期的推文里也介绍过该接…...

前端面试宝典【设计模式】【2】
欢迎来到《前端面试宝典》,这里是你通往互联网大厂的专属通道,专为渴望在前端领域大放异彩的你量身定制。通过本专栏的学习,无论是一线大厂还是初创企业的面试,都能自信满满地展现你的实力。 核心特色: 独家实战案例:每一期专栏都将深入剖析真实的前端面试案例,从基础知…...

技术汇总笔记7:条件分支相关内容
嵌套Switch语句的使用和改进 嵌套的switch语句虽然在语法上是允许的,但可能会使代码难以阅读和维护。例如: switch (_get_urgency_ob_type(sData.structure_name)) {case URGENCY_OB_PRESSUREINFO:{switch(_get_urgency_ob_sub_type( sData.attribute_…...

一文让你学会python:面向对象
面向对象编程(OOP) 一.类与实例 1.类: 是对现实世界描述的一种类型,是抽象的,是实例的模板,类名采用大驼峰,定义方式为 class 类名: pass 。 2.实例: 根据类创建的具体对象&…...

mac电脑安装 docker镜像 btpanel/baota
PS:docker链接:https://hub.docker.com/r/btpanel/baota 1、将docker下载到本地,然后运行端口映射 docker run -d --restart unless-stopped --name baota -p 8888:8888 -p 22:22 -p 443:443 -p 80:80 -p 888:888 -v ~/website_data:/www/w…...

Python写UI自动化--playwright(pytest.ini配置)
在 pytest.ini 文件中配置 playwright 的选项可以更好地控制测试执行的过程。 在终端输入pytest --help,可以找到playwright的配置参数 目录 1. --browser{chromium,firefox,webkit} 2. --headed 3. --browser-channelBROWSER_CHANNEL 4. --slowmoSLOWMO 5. …...

java实现序列化操作
Java序列化是一种将对象转换为字节流的过程,以便在网络上传输或将对象持久化到磁盘中。在Java中,实现序列化的关键是实现Serializable接口。当一个类实现了Serializable接口时,它可以被Java序列化机制序列化成字节流,然后再反序列…...

视频帧的概念
一个视频帧是视频中的单一静态图像。视频帧的概念与电影胶片中的单一帧类似,视频帧序列的快速播放形成了连续运动的视觉效果。以下是视频帧的详细解释: 视频帧的定义: 视频帧:视频中的单一静态图像。视频是由一系列连续的帧按一定…...

卫星导航系统的应用领域与发展前景
当人们提到卫星导航系统,往往会联想到车载导航仪或手机上的地图应用。然而,卫星导航系统的应用远不止于此,它在许多领域都发挥着重要作用。下面将介绍几个卫星导航系统的应用领域及其发展前景。首先是海洋航行安全领域。在过去,海…...

FPGA开发——数码管的使用(二)
一、概述 在上一篇文章中我们针对单个数码管的静态显示和动态显示进行了一个设计和实现,这篇文章中我们针对多个数码管同时显示进行一个设计。这里和上一篇文章唯一不同的是就是数码管位选进行了一个改变,原来是单个数码管的显示,所以位选就直…...

技术汇总记录笔记5:在 C++ 中,如何使用正则表达式来验证一个字符串是否只包含数字?
在C中,你可以使用 <regex> 头文件中定义的正则表达式功能来验证一个字符串是否只包含数字。以下是一个基本的示例,展示如何使用正则表达式来检查一个字符串是否完全是数字: #include <iostream> #include <string> #inclu…...
ai模特换装软件哪个好用?不知道怎么穿搭就用这几个
最近#紫色跑道的city穿搭#风靡全网,大家纷纷晒出自己的紫色风情。 可一想到衣橱里堆积如山的衣服和钱包的“瘦身计划”,是不是有点小纠结? 别怕,科技来救场!那就是“一键换装在线工具”,让你无需剁手&…...

HCL实验2:VLAN
目的:让PC_3和PC_5处于vlan1, PC_4和PC_6处于vlan2 SW1的配置命令: vlan 2 port GigabitEthernet 1/0/2 quit int g1/0/3 port link-type trunk port trunk permit vlan all quit SW2的配置命令: vlan 2 port GigabitEthernet 1/0/2 quit int g1/0/3 p…...

输出总分题目
题目描述 依次输入三位同学的语文、数学和英语成绩,依次输出他们的总分。 输入输出格式 输入 三行,每行三个整数,用空格隔开,分别表示这三个同学的语文、数学和英语成绩。 输出 一行三个整数,用空格隔开…...
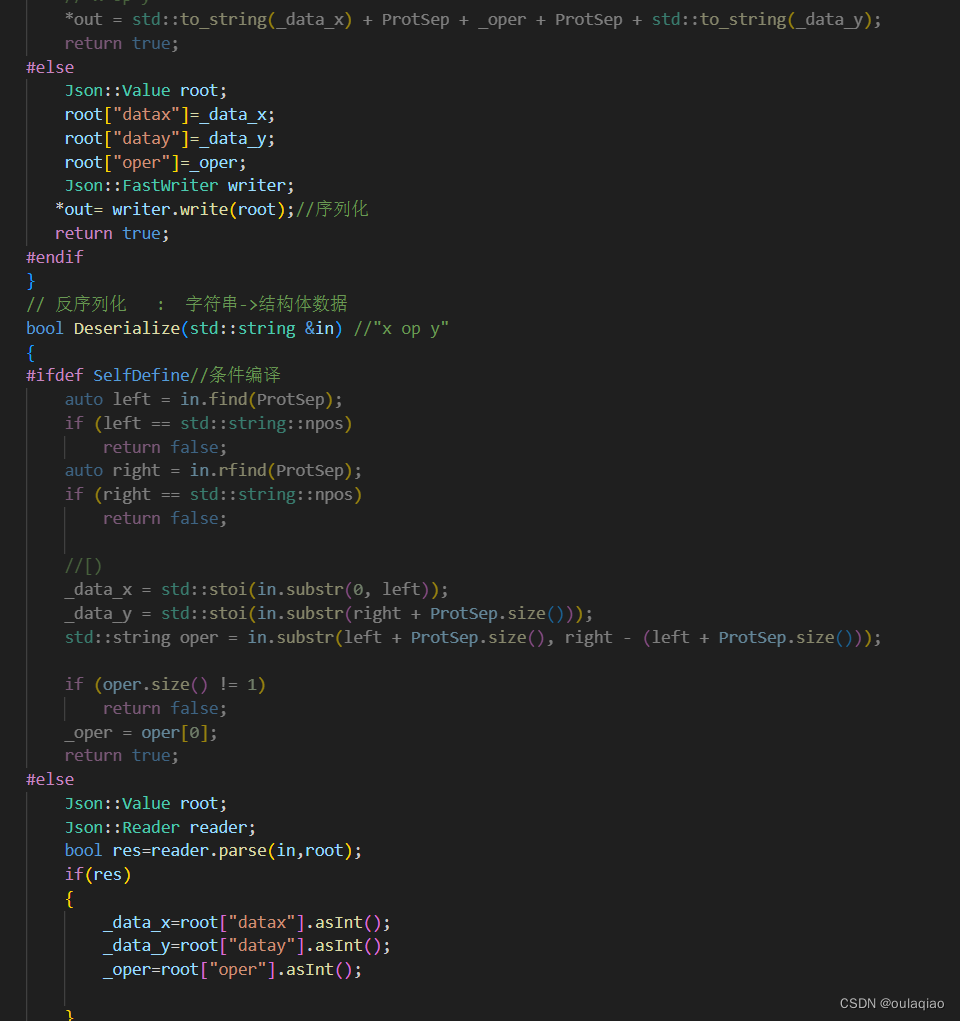
自定义协议(应用层协议)——网络版计算机基于TCP传输协议
应用层:自定义网络协议:序列化和反序列化,如果是TCP传输的:还要关心区分报文边界(在序列化设计的时候设计好)——粘包问题 ——两个问题:粘包、序列化反序列化 1、首先想要使用TCP协议传输的网…...

5步搞定Jimeng LoRA测试台:Streamlit界面,LoRA版本智能排序
5步搞定Jimeng LoRA测试台:Streamlit界面,LoRA版本智能排序 1. 项目概述:轻量级LoRA测试系统 Jimeng LoRA测试台是一款专为模型开发者设计的轻量化文本生成图像系统。它基于Z-Image-Turbo文生图底座,实现了动态多版本LoRA热切换…...

SeamlessM4T v2:跨语言实时对话的终极解决方案与技术实践
SeamlessM4T v2:跨语言实时对话的终极解决方案与技术实践 【免费下载链接】seamless-m4t-v2-large 项目地址: https://ai.gitcode.com/hf_mirrors/ai-gitcode/seamless-m4t-v2-large 在全球化协作日益频繁的今天,跨语言沟通已成为技术团队、跨国…...

如何实现零配置专业级视频播放体验?mpv_PlayKit配置方案深度解析
如何实现零配置专业级视频播放体验?mpv_PlayKit配置方案深度解析 【免费下载链接】mpv_PlayKit 🔄 mpv player 播放器折腾记录 Windows conf | 中文注释配置 汉化文档 快速帮助入门 | mpv-lazy 懒人包 Win11 x64 config | 着色器 shader 滤镜 filter 整合…...

星露谷跨地域联机实战:基于FRP的低成本内网穿透方案
1. 为什么需要FRP内网穿透玩星露谷 星露谷物语作为一款支持多人联机的农场模拟游戏,和朋友一起种田钓鱼挖矿的乐趣远胜单人游玩。但官方服务器对国内玩家并不友好,经常出现高延迟甚至连接失败的情况。更头疼的是,当你想和异地好友联机时&…...

CodeSys自定义HTML5控件:从零构建到工程部署的实战指南
1. 为什么需要自定义HTML5控件? 在工业自动化领域,CodeSys作为主流的PLC编程环境,其WebVisu功能允许工程师创建可视化界面。但默认控件库往往无法满足特定需求,比如: 需要展示实时数据曲线图而非简单数值要求特殊交互…...

GPU集群网络优化实战:万兆以太网 vs InfiniBand,哪种更适合你的AI训练任务?
GPU集群网络优化实战:万兆以太网 vs InfiniBand,哪种更适合你的AI训练任务? 在构建高性能GPU集群时,网络架构的选择往往成为决定整体性能的关键因素。想象一下,当你的AI模型需要处理海量参数更新时,网络带宽…...

告别系统臃肿:Win11Debloat三步配置流程让Windows运行效率提升51%
告别系统臃肿:Win11Debloat三步配置流程让Windows运行效率提升51% 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declu…...

解放双手!用Python自动化Adobe Premiere Pro视频编辑的终极指南 [特殊字符]
解放双手!用Python自动化Adobe Premiere Pro视频编辑的终极指南 🎬 【免费下载链接】pymiere Python for Premiere pro 项目地址: https://gitcode.com/gh_mirrors/py/pymiere 还在为重复的视频编辑任务而烦恼吗?PyMiere项目让你用Pyt…...

别再死记硬背了!用‘打电话’、‘寄快递’、‘发长信’来秒懂网络交换三兄弟
别再死记硬背了!用‘打电话’、‘寄快递’、‘发长信’来秒懂网络交换三兄弟 刚接触计算机网络时,那些晦涩的专业术语总让人望而生畏。记得我第一次看到"电路交换"、"分组交换"这些概念时,满脑子都是问号——直到有一天&…...

深度学习框架YOLOV8模型如何训练水下生物检测数据集 构建基于YOLOv8➕pyqt5的水下生物检测系统 海胆‘, ‘海参‘, ‘扇贝‘, ‘海星‘, ‘水草
享基于YOLOv8➕pyqt5的水下生物检测系统内含7600张水下生物数据集 包括[‘海胆’, ‘海参’, ‘扇贝’, ‘海星’, ‘水草’],5类也可自行替换模型,使用该界面做其他检测 这是一个非常经典的计算机视觉应用项目,结合了深度学习的目标检测&…...