Python爬虫知识体系-----Selenium
| 数据科学、数据分析、人工智能必备知识汇总-----Python爬虫-----持续更新:https://blog.csdn.net/grd_java/article/details/140574349 |
|---|
文章目录
- 一、安装和基本使用
- 二、元素定位
- 三、访问元素信息
- 四、自动化交互
- 五、PhantomJS
- 六、Chrome headless
一、安装和基本使用
| 什么是Selenium |
|---|
- 一个用于Web应用程序测试的工具
- 测试直接运行在浏览器中,就像真正的用户在操作一样
- 支持通过各种driver驱动真实浏览器完成测试(例如FirfoxDriver,IternetExplorerDriver,OperaDriver,ChromeDriver)
- 支持无界面浏览器操作
| 特长 |
|---|
模拟浏览器功能,自动执行网页中js代码,实现动态加载
| 安装谷歌驱动 |
|---|
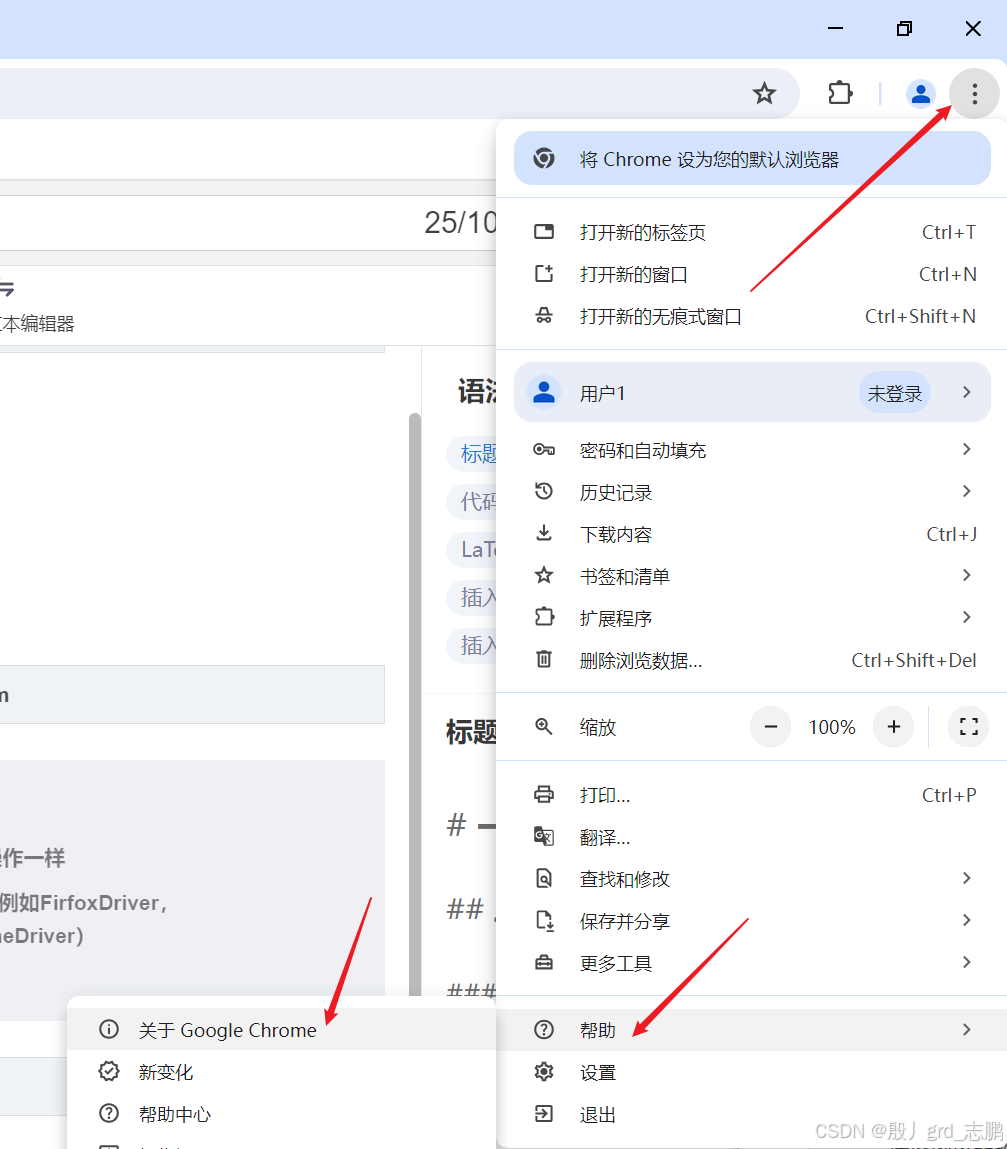
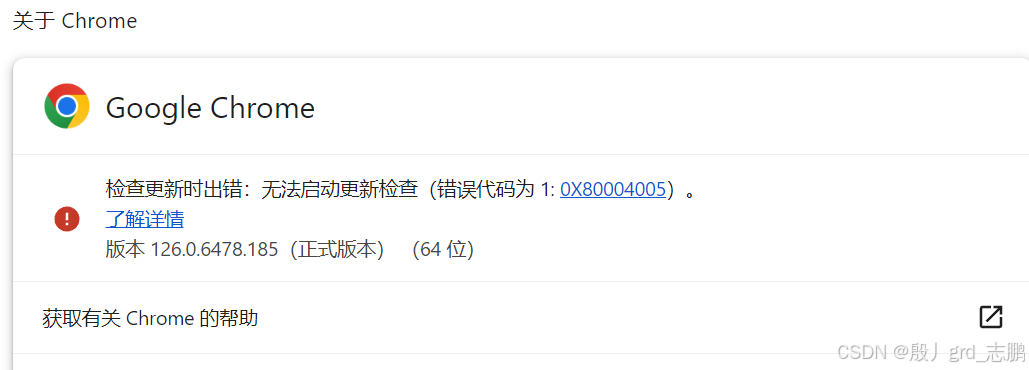
- 查看谷歌浏览器版本,只需要点击谷歌浏览器右上角的菜单按钮,然后选择帮助---->关于即可查看
- 操作谷歌浏览器的驱动下载地址(给出两个,第一个没有再去第二个):
- http://chromedriver.storage.googleapis.com/index.html
- https://googlechromelabs.github.io/chrome-for-testing/
- 选择对应版本和操作系统进行下载,上图中我的版本是126,但是这里只有127,所以可以选择额外下载127版本的chrome浏览器

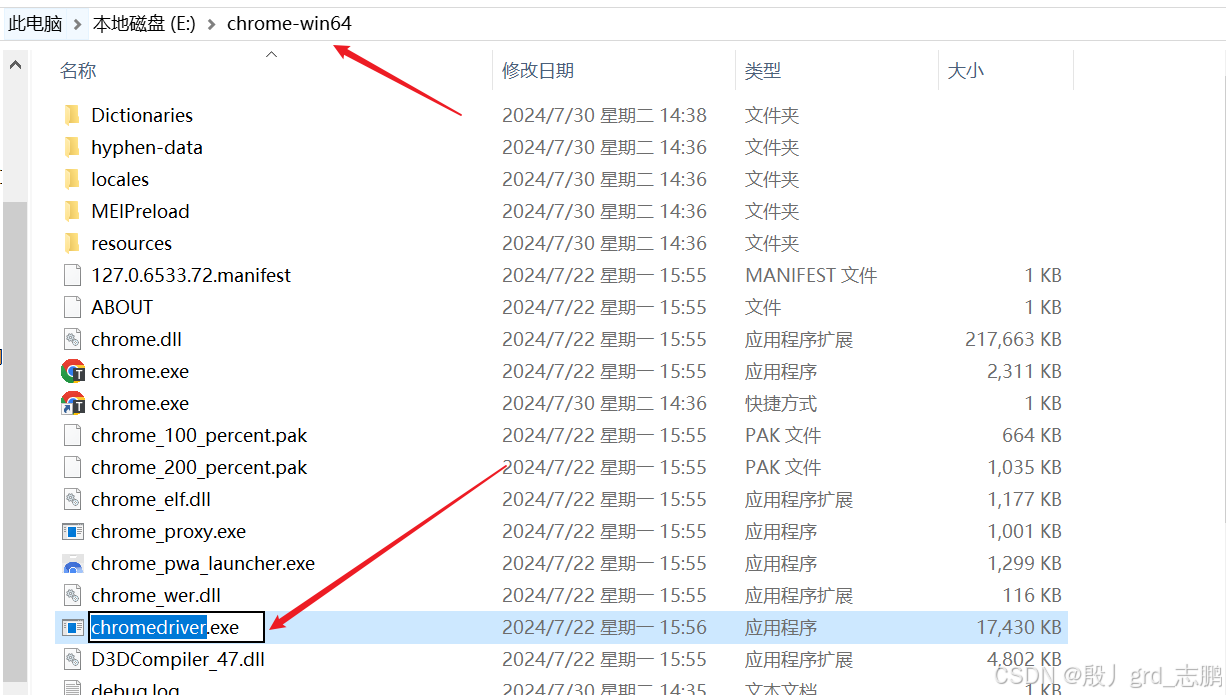
- 将下载好的压缩包解压,将驱动.exe文件拖入chrome浏览器文件夹下
| python安装selenium |
|---|
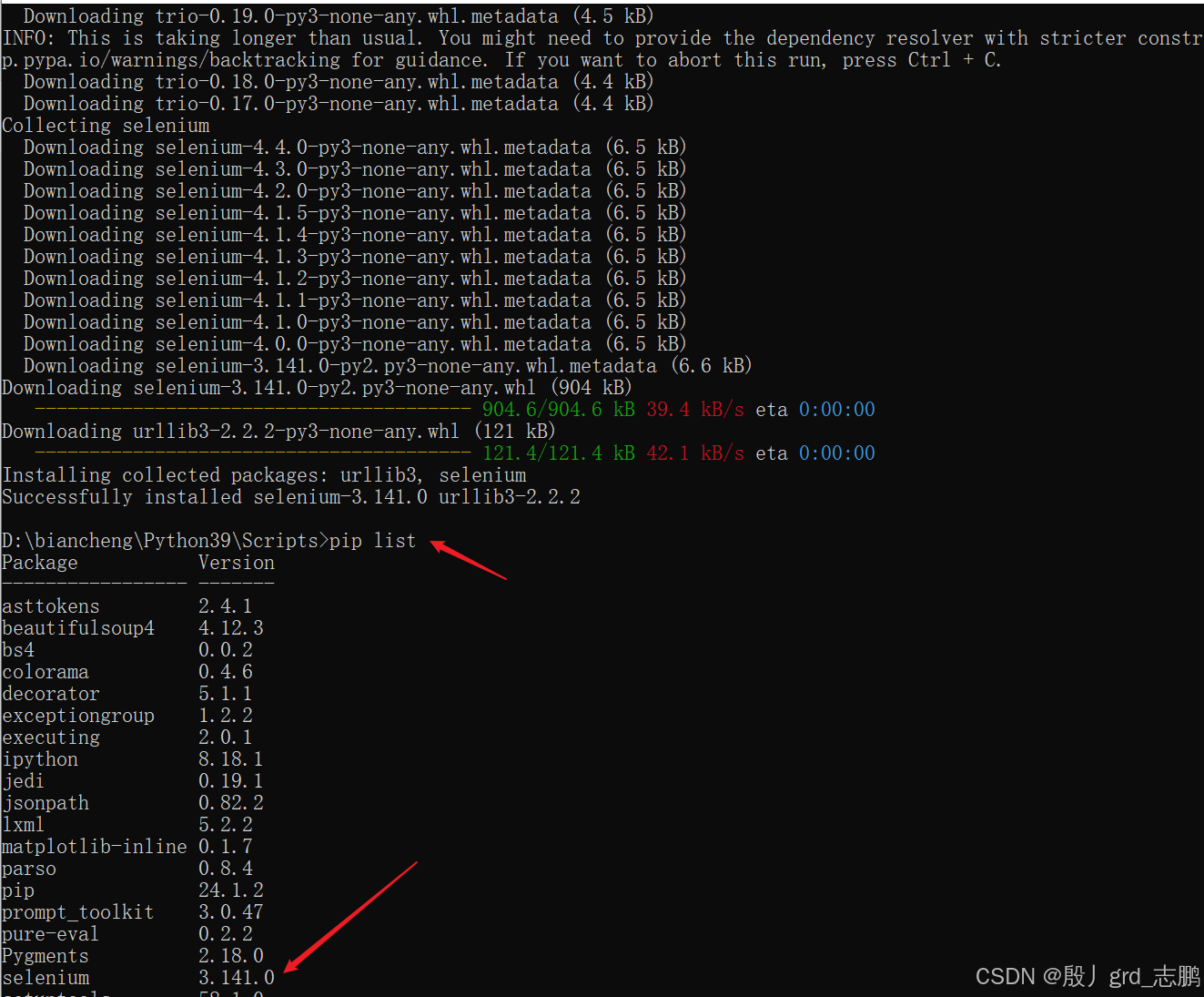
使用命令pip install selenium进行安装即可
| 简单案例,解决常见报错 |
|---|
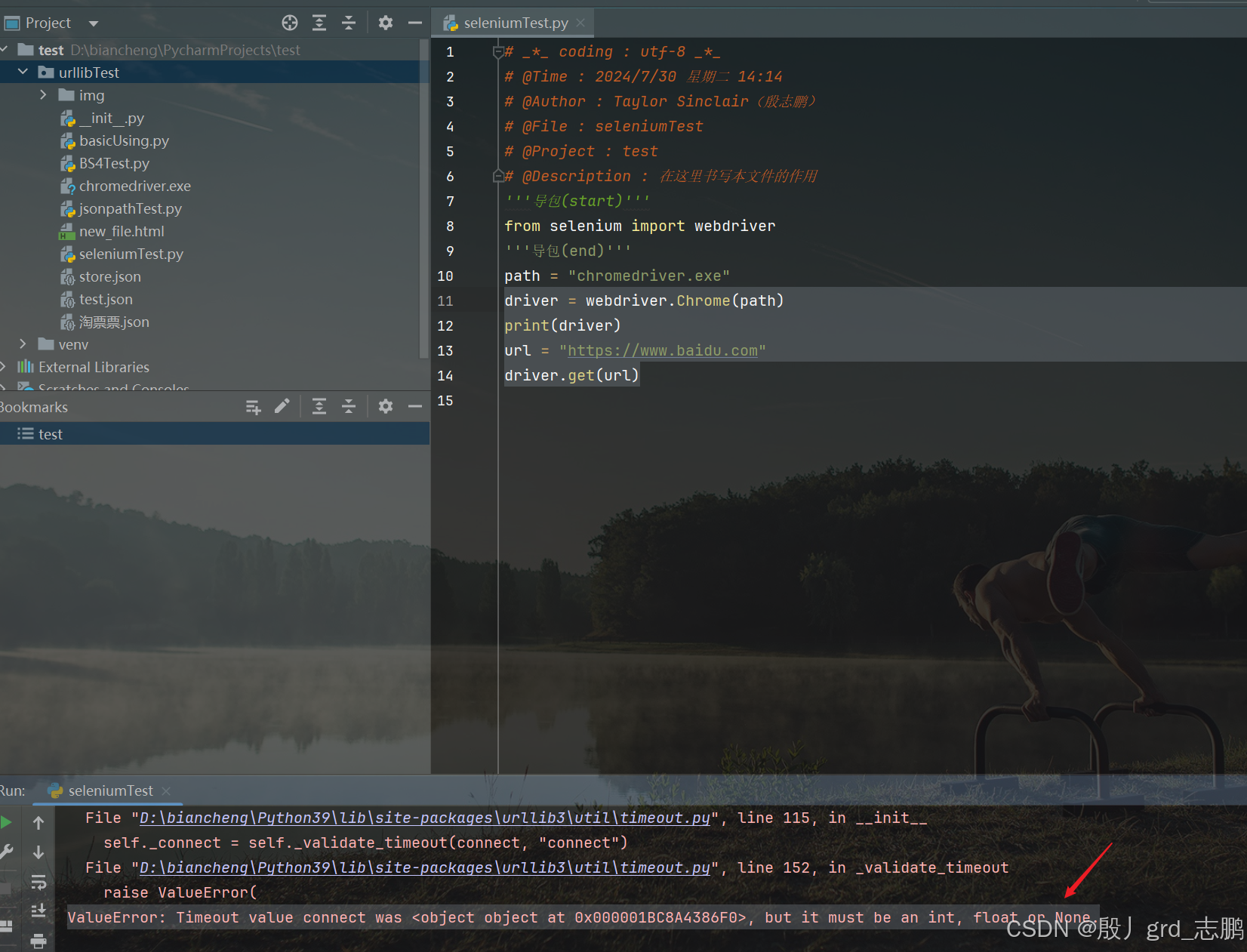
- 正常使用selenium访问百度首页,一般会报错ValueError: Timeout value connect was <object object at 0x000001BC8A4386F0>, but it must be an int, float or None.
- 这是因为和urllib3的版本不兼容导致
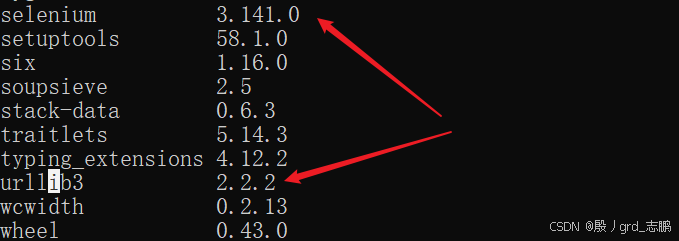
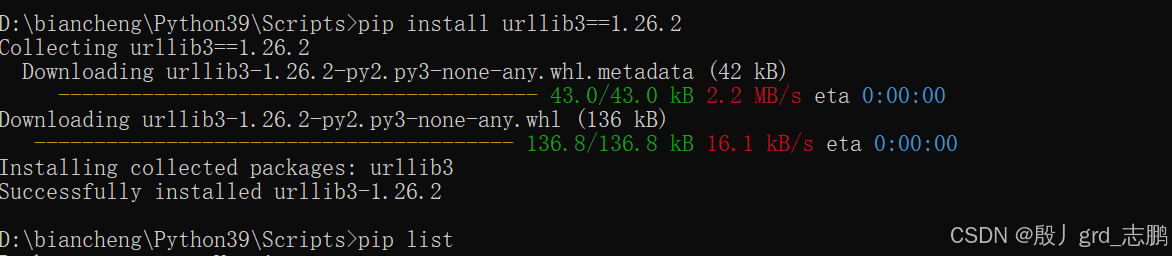
- 所以将urllib3降低到1.26.2版本,首先使用命令pip uninstall urllib3卸载,然后安装指定版本(pip install urllib3==1.26.2)
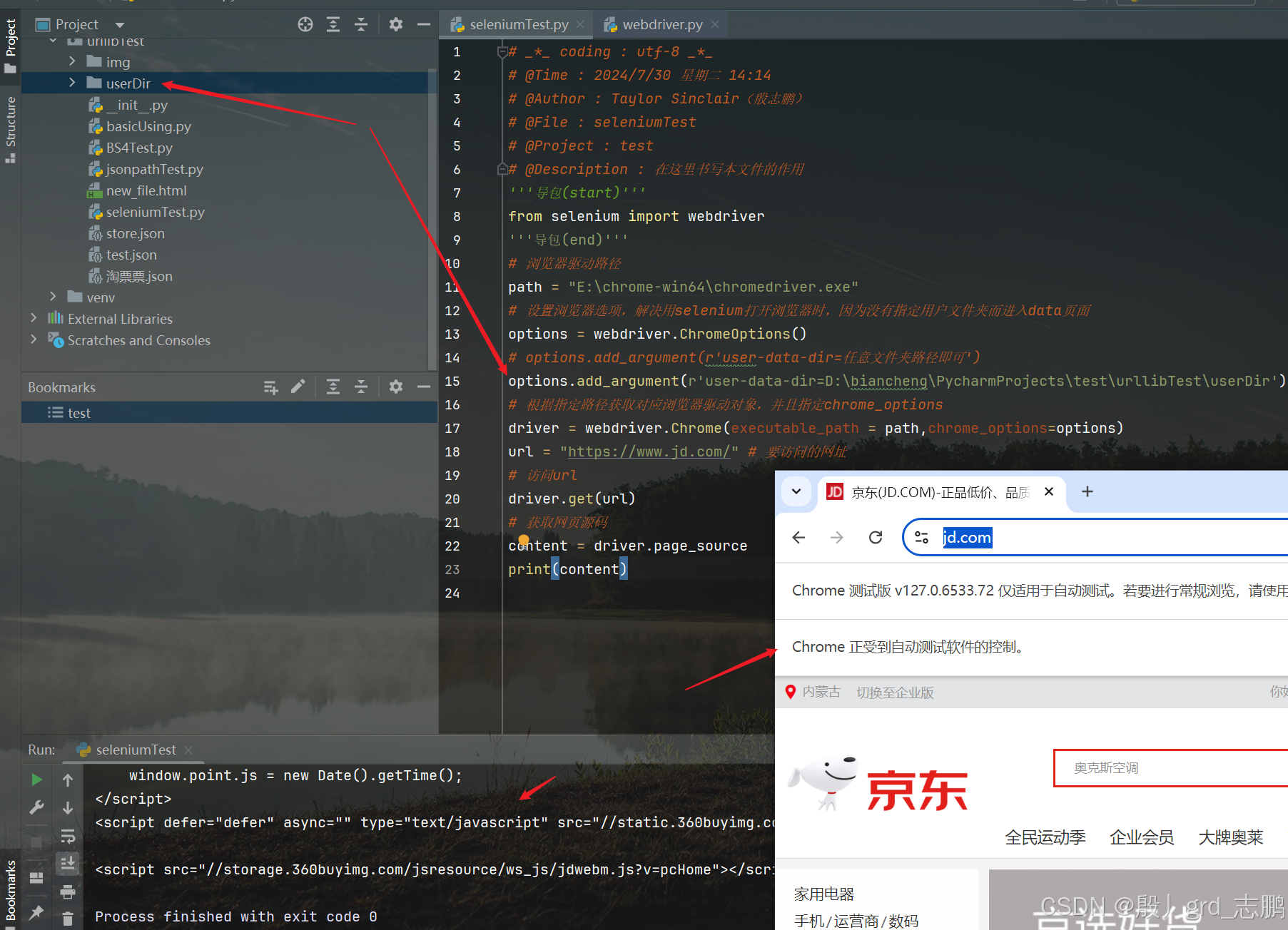
| 访问京东首页,让京东知道我们是真实的浏览器在访问,从而将所有数据交给我们,而不是隐藏部分数据 |
|---|
注意我们要指定一个谷歌浏览器的用户文件夹(随便一个即可),就可以正常访问了。但是访问后,浏览器会显示Chrome正受到自动测试软件的控制,这是接下来我们要解决的问题
'''导包(start)'''
from selenium import webdriver
'''导包(end)'''
# 浏览器驱动路径
path = "E:\chrome-win64\chromedriver.exe"
# 设置浏览器选项,解决用selenium打开浏览器时,因为没有指定用户文件夹而进入data页面
options = webdriver.ChromeOptions()
# options.add_argument(r'user-data-dir=任意文件夹路径即可')
options.add_argument(r'user-data-dir=D:\biancheng\PycharmProjects\test\urllibTest\userDir')
# 根据指定路径获取对应浏览器驱动对象,并且指定chrome_options
driver = webdriver.Chrome(executable_path = path,chrome_options=options)
url = "https://www.jd.com/" # 要访问的网址
# 访问url
driver.get(url)
# 获取网页源码
content = driver.page_source
print(content)
二、元素定位
元素定位:自动化要做的就是模拟鼠标和键盘操作来操作这些元素,点击、输入操作等等。首先要找到这些元素,WebDriver提供了很多定位元素的方法。
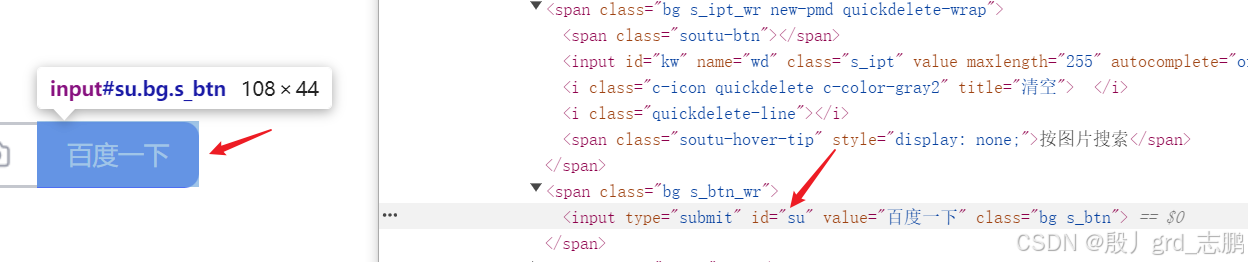
| 根据id定位百度一下按钮 |
|---|
- 可以发现按钮的id为su
- 我们直接通过driver.find_element_by_id()来进行查找
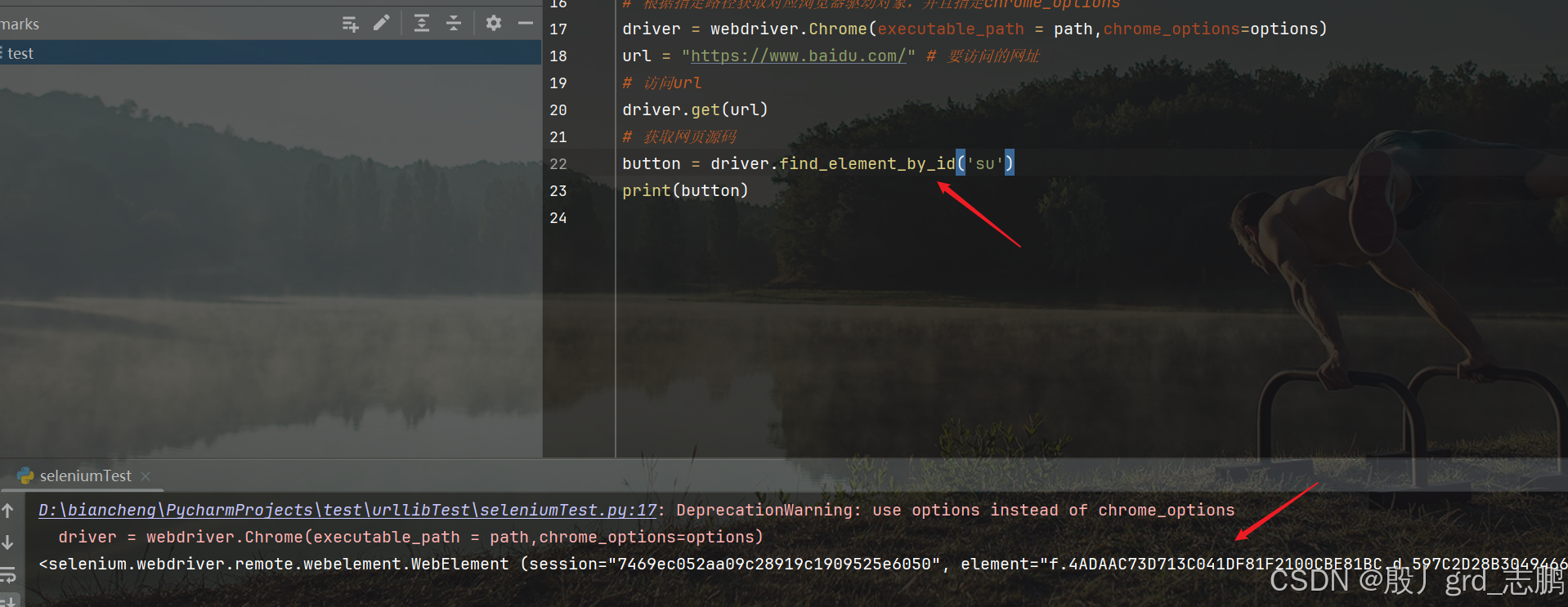
'''导包(start)'''
from selenium import webdriver
'''导包(end)'''
# 浏览器驱动路径
path = "C:\\Users\\Administrator\\AppData\\Local\\Google\\Chrome\\Bin\\chromedriver.exe"
# 设置浏览器选项,解决用selenium打开浏览器时,因为没有指定用户文件夹而进入data页面
options = webdriver.ChromeOptions()
# options.add_argument(r'user-data-dir=任意文件夹路径即可')
options.add_argument(r'user-data-dir=D:\biancheng\PycharmProjects\test\urllibTest\userDir')
# 根据指定路径获取对应浏览器驱动对象,并且指定chrome_options
driver = webdriver.Chrome(executable_path = path,chrome_options=options)
url = "https://www.baidu.com/" # 要访问的网址
# 访问url
driver.get(url)
# 获取网页源码
input = driver.find_element_by_id('su')
print(input)
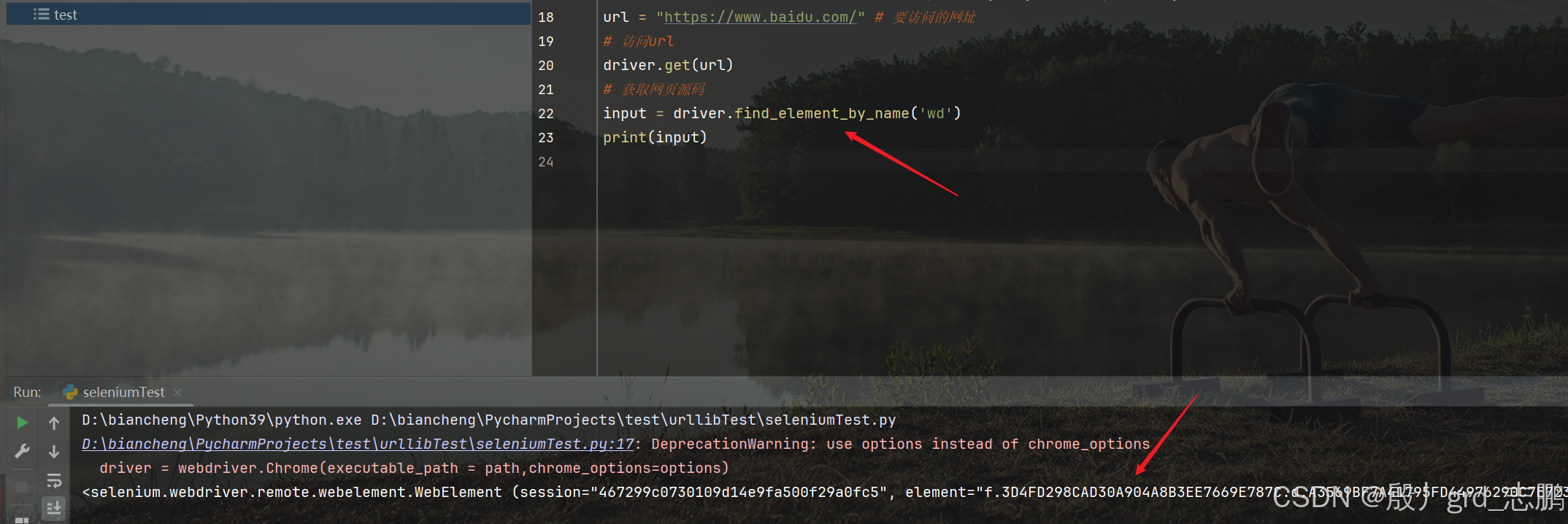
| 根据name属性定位input输入框 |
|---|
- 可以发现搜索框的name属性值为wd
- 我们直接通过driver.find_element_by_id()来进行查找

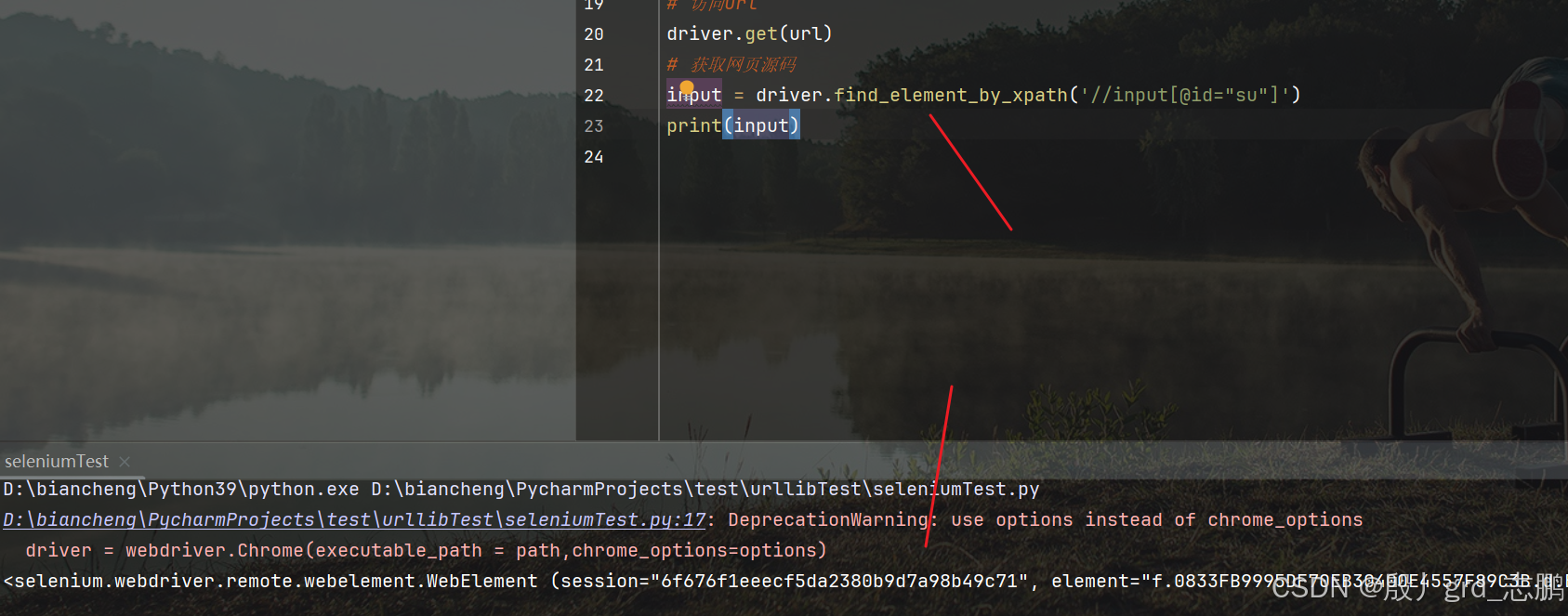
| 根据xpath路径找到百度一下按钮 |
|---|
- 先确定其xpath路径
- 通过driver.find_element_by_xpath(‘//input[@id=“su”]’)进行定位

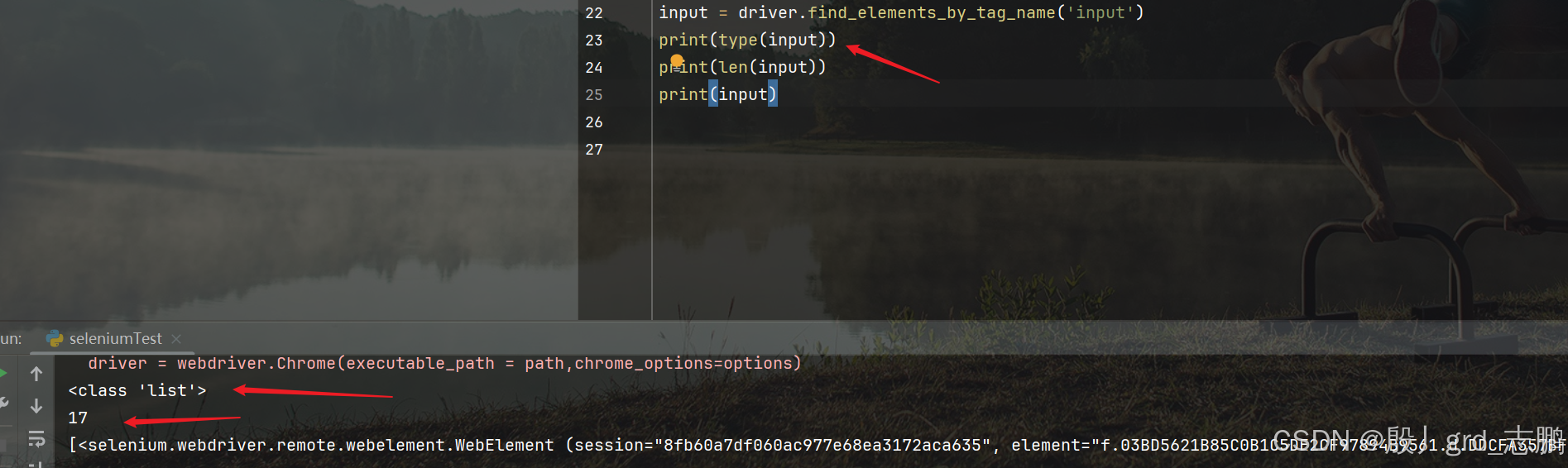
| 根据标签名定位所有input |
|---|
通过driver.find_elements_by_tag_name(‘input’),将所有input控件保存到list列表返回
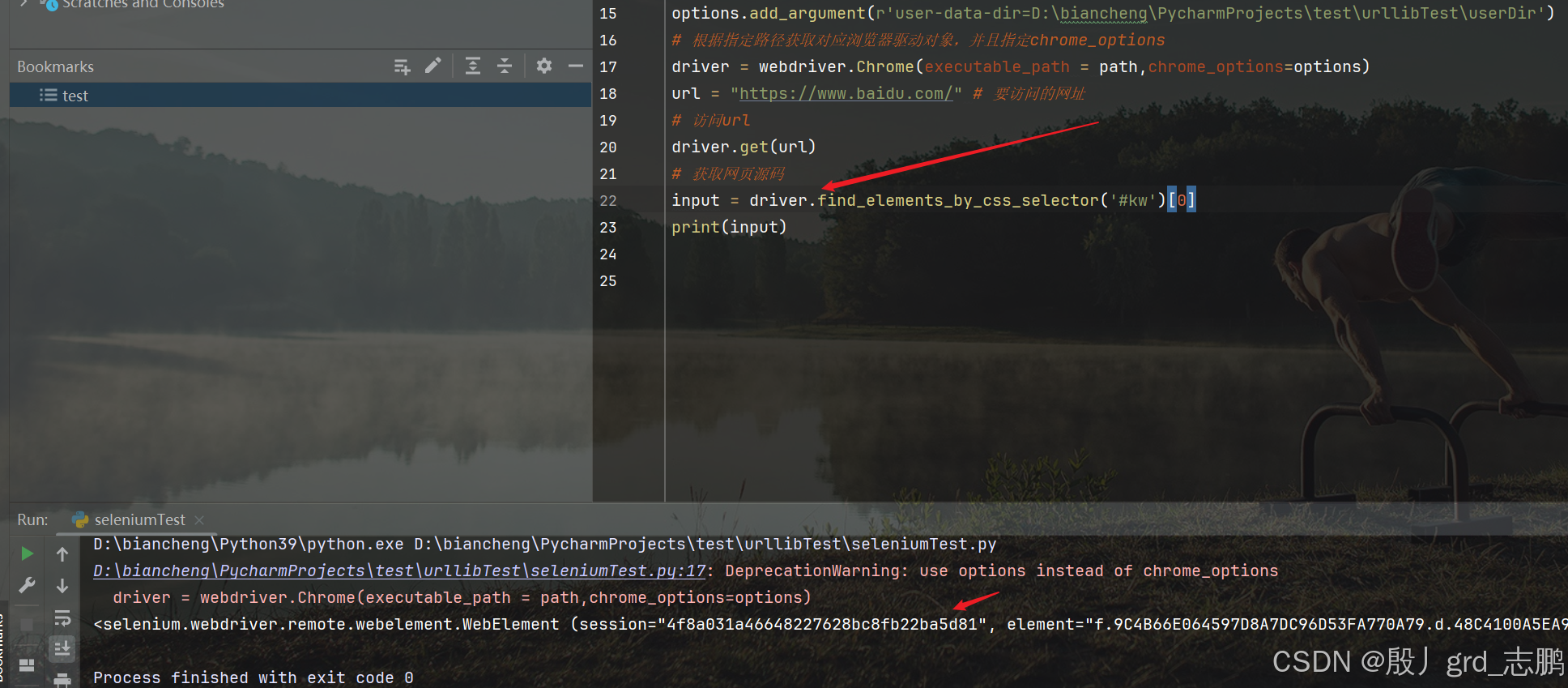
| 通过css选择器语法定位id为kw的元素 |
|---|
- 百度搜索框id为kw
- 通过driver.find_elements_by_css_selector(‘#kw’)[0]获取

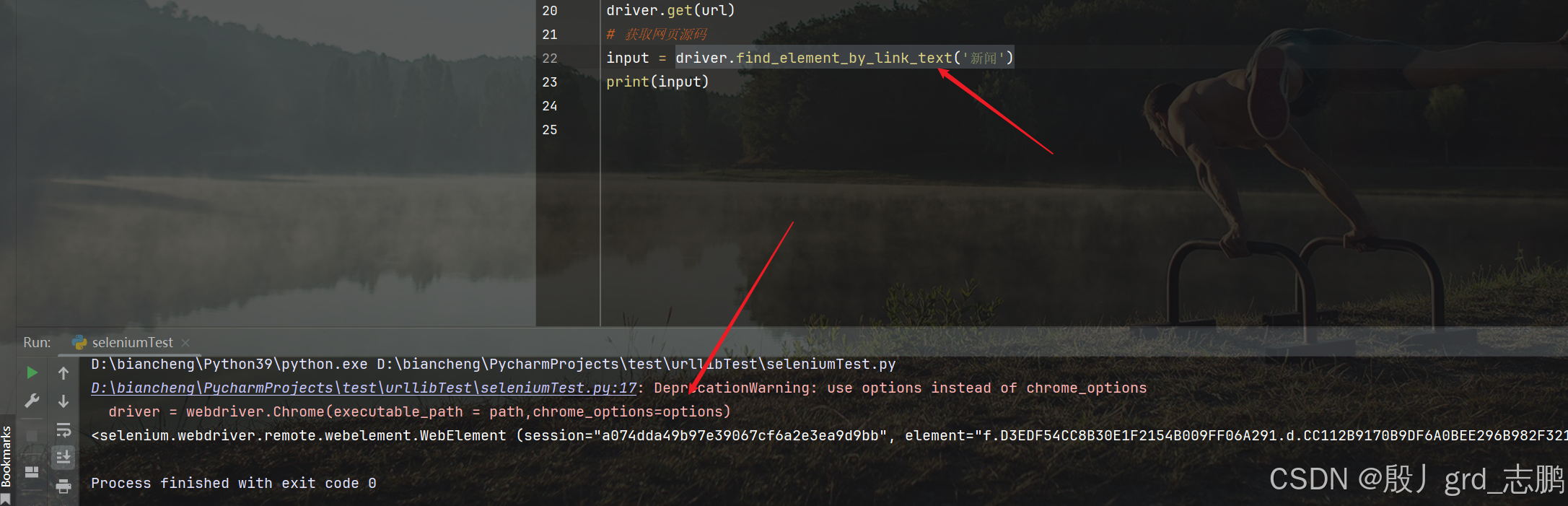
| 通过超链接定位 |
|---|
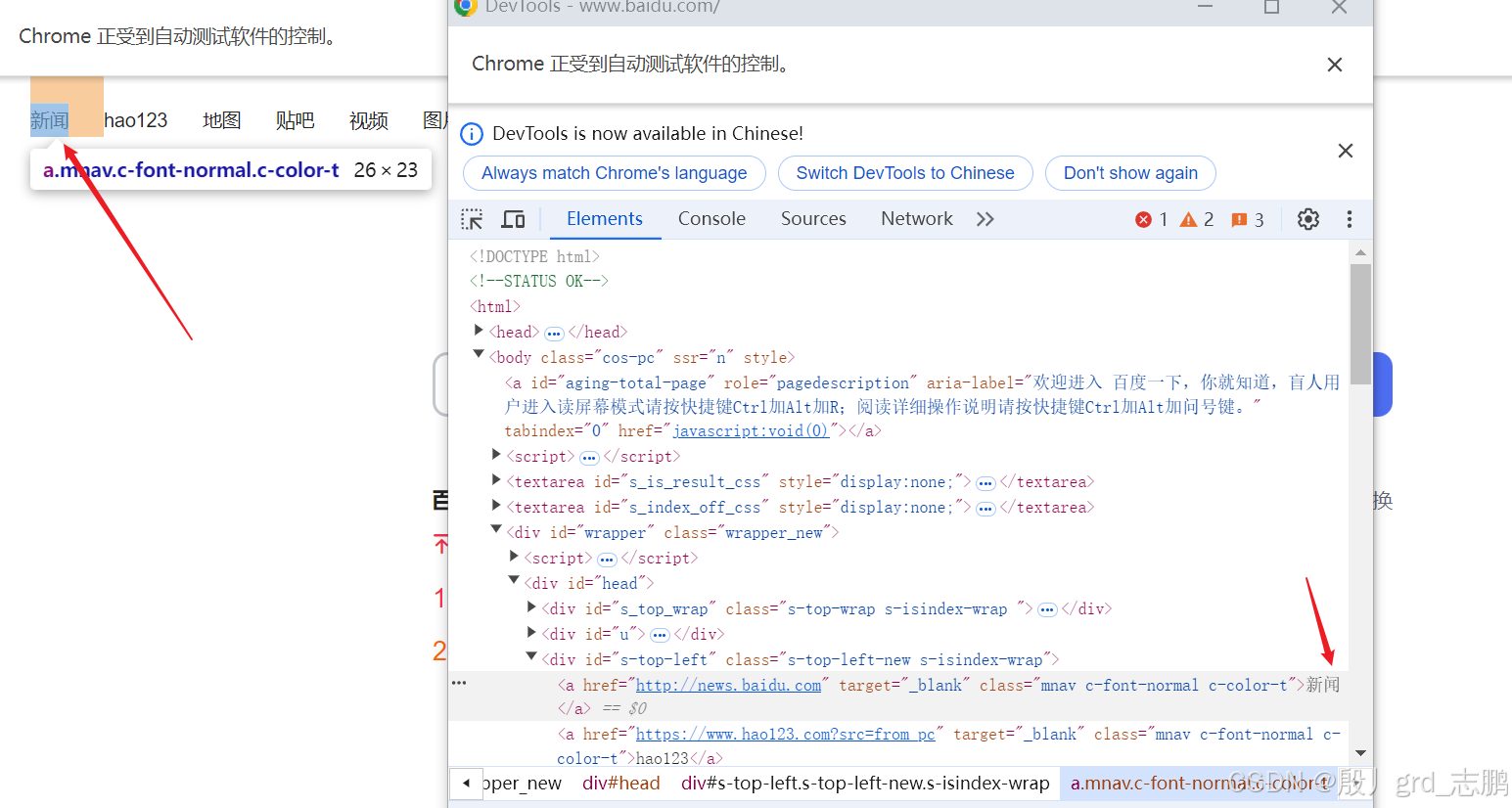
- 定位百度首页左上角第一个超链接"新闻"
- 通过driver.find_element_by_link_text(‘新闻’)获取即可

三、访问元素信息
上面讲解了如何找到元素,现在来介绍如何获取这些元素的信息
| 获取元素属性 |
|---|
- 获取新闻超链接的class属性
- 通过目标元素对象.get_attribute(“class”)获取即可

'''导包(start)'''
from selenium import webdriver
'''导包(end)'''
# 浏览器驱动路径
path = "C:\\Users\\Administrator\\AppData\\Local\\Google\\Chrome\\Bin\\chromedriver.exe"
# 设置浏览器选项,解决用selenium打开浏览器时,因为没有指定用户文件夹而进入data页面
options = webdriver.ChromeOptions()
# options.add_argument(r'user-data-dir=任意文件夹路径即可')
options.add_argument(r'user-data-dir=D:\biancheng\PycharmProjects\test\urllibTest\userDir')
# 根据指定路径获取对应浏览器驱动对象,并且指定chrome_options
driver = webdriver.Chrome(executable_path = path,chrome_options=options)
url = "https://www.baidu.com/" # 要访问的网址
# 访问url
driver.get(url)
# 获取网页源码
input = driver.find_element_by_link_text('新闻')
print(input.get_attribute("class"))
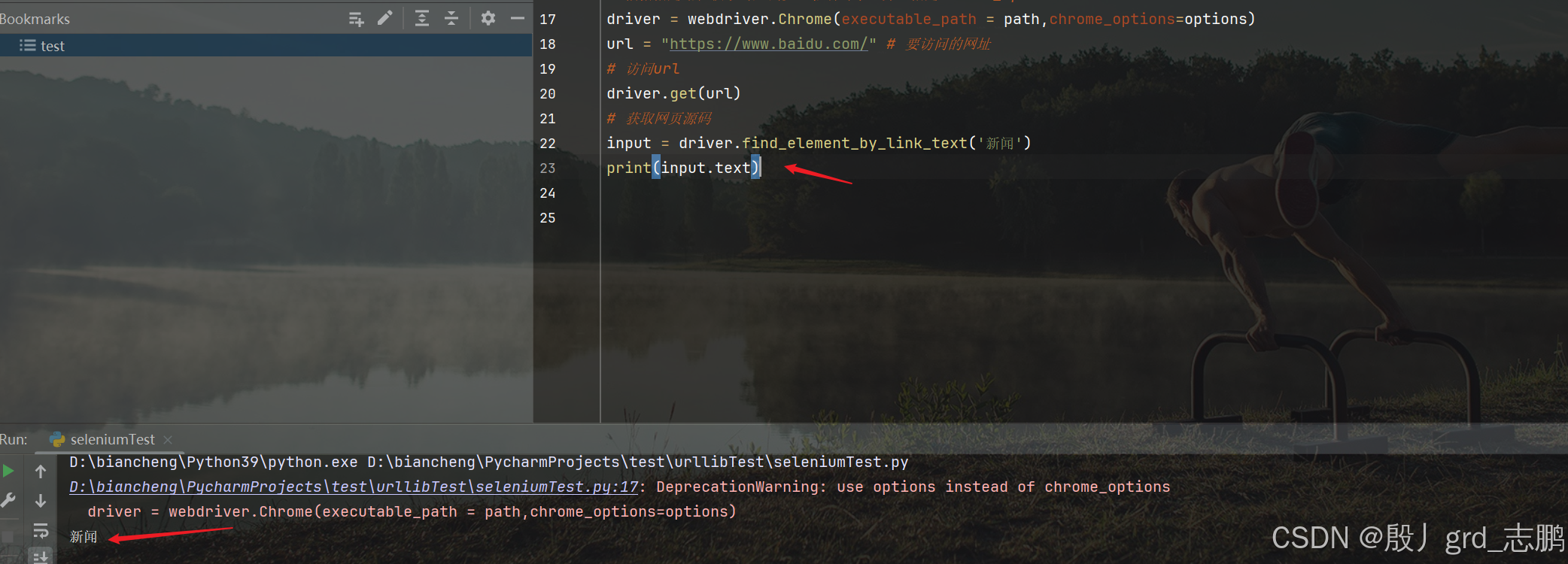
| 获取元素文本内容 |
|---|
- 获取新闻超链接的标签内容
- 通过目标元素对象.text来获取
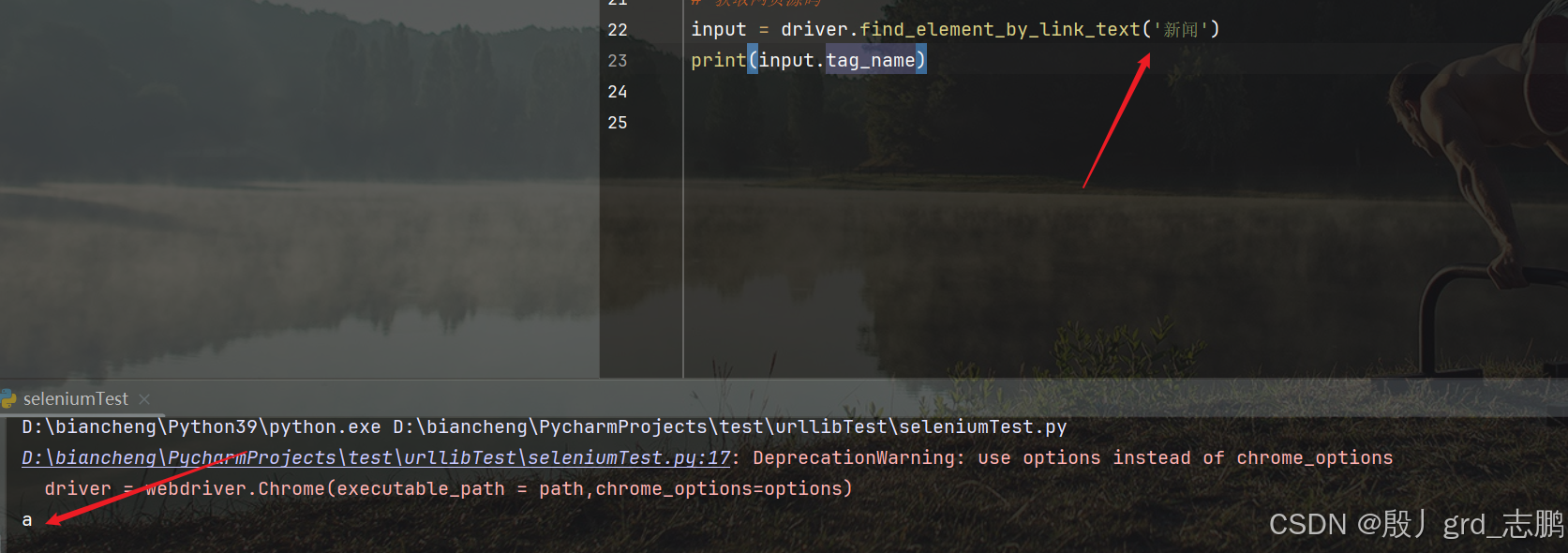
| 获取标签名 |
|---|
通过目标元素对象.tag_name来获取
四、自动化交互
找到元素后,不能只是获取内容,还要进行自动化交互,例如点击按钮等操作
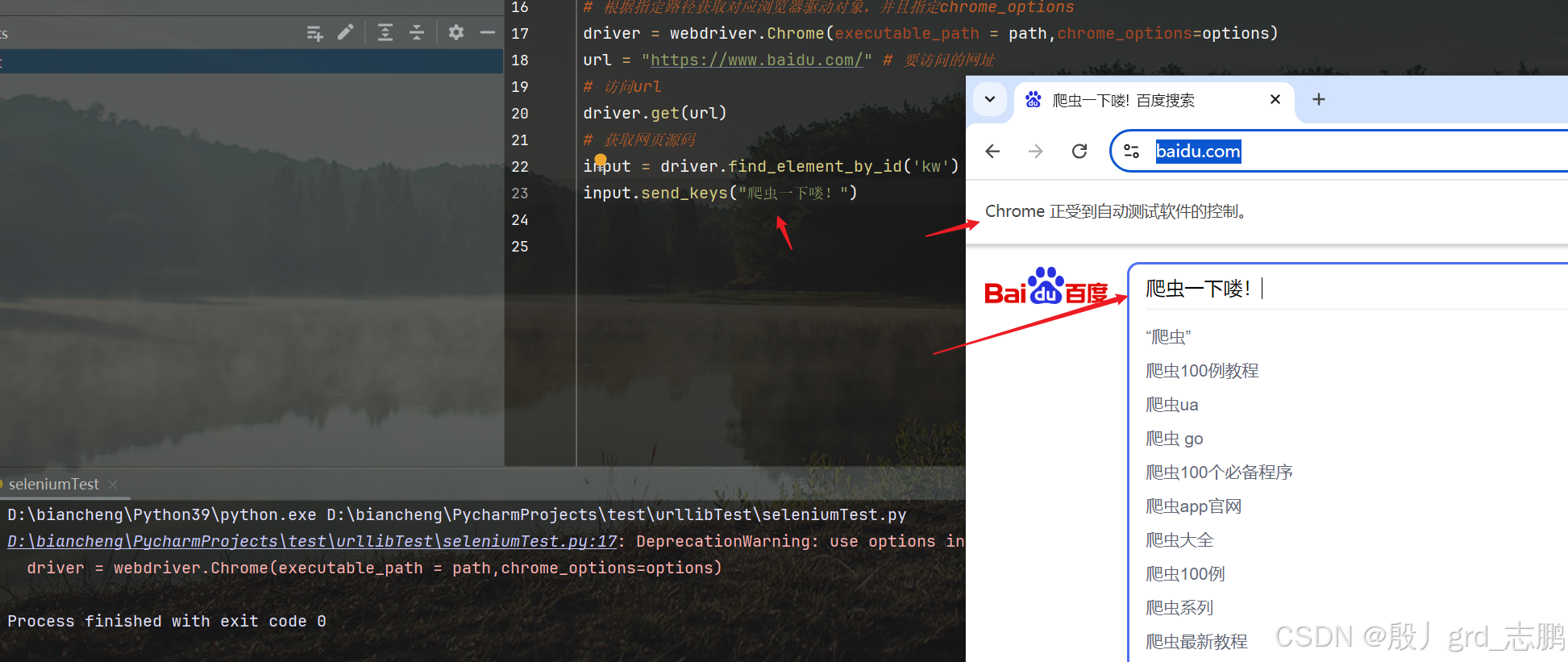
| 在百度一下搜索框输入文字 |
|---|
通过目标元素.send_keys(“爬虫一下喽!”),将"爬虫一下喽!"输入到搜索框
'''导包(start)'''
from selenium import webdriver
'''导包(end)'''
# 浏览器驱动路径
path = "C:\\Users\\Administrator\\AppData\\Local\\Google\\Chrome\\Bin\\chromedriver.exe"
# 设置浏览器选项,解决用selenium打开浏览器时,因为没有指定用户文件夹而进入data页面
options = webdriver.ChromeOptions()
# options.add_argument(r'user-data-dir=任意文件夹路径即可')
options.add_argument(r'user-data-dir=D:\biancheng\PycharmProjects\test\urllibTest\userDir')
# 根据指定路径获取对应浏览器驱动对象,并且指定chrome_options
driver = webdriver.Chrome(executable_path = path,chrome_options=options)
url = "https://www.baidu.com/" # 要访问的网址
# 访问url
driver.get(url)
# 获取网页源码
input = driver.find_element_by_id('kw')
input.send_keys("爬虫一下喽!")
| 点击百度一下按钮 |
|---|

input = driver.find_element_by_id('kw')
input.send_keys("爬虫一下喽!")
baiduButton = driver.find_element_by_id('su')
baiduButton.click()
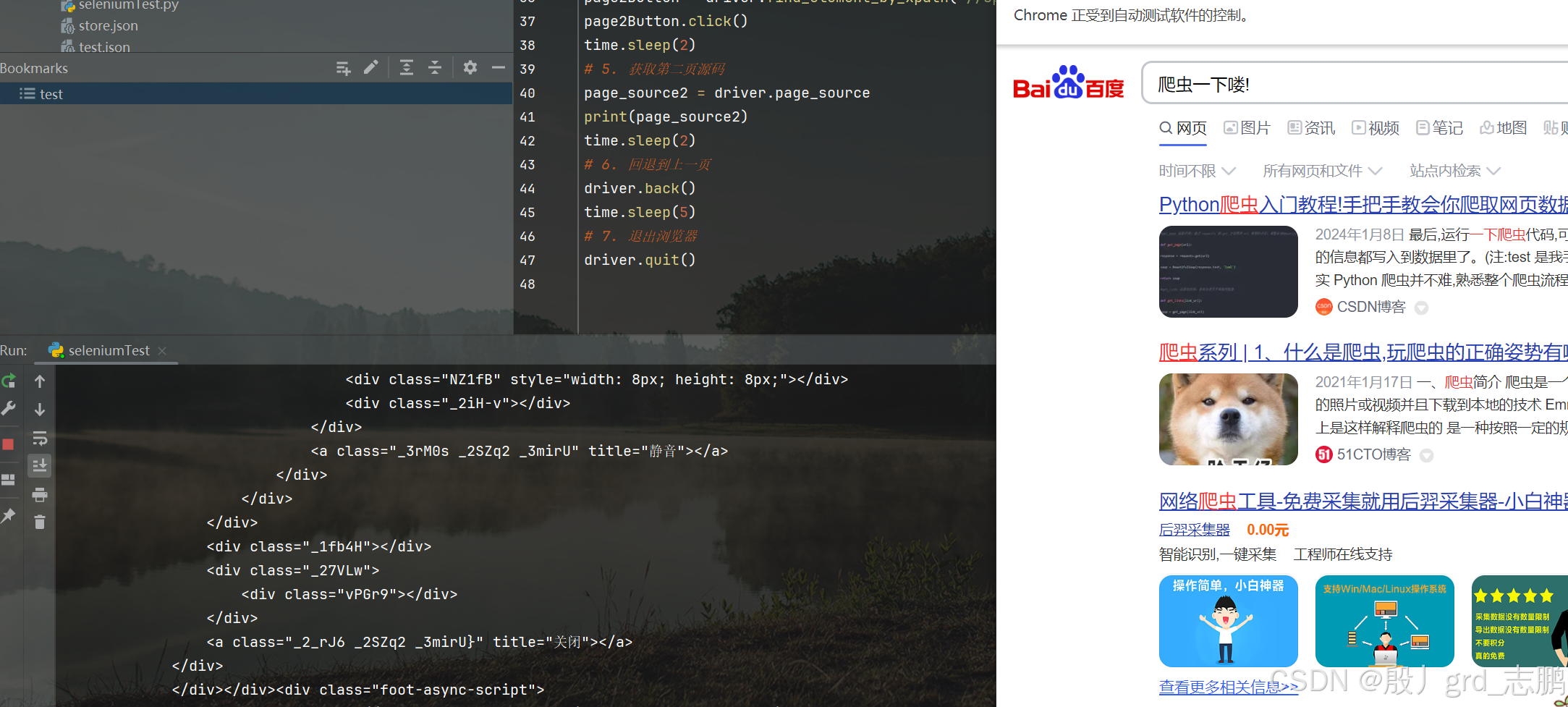
| 在上面的基础上,实现向下滑动到页面底部,点击第二页按钮,获取第二页源码,回退到上一级,然后在前进一级(回退的逆操作),然后关闭浏览器 |
|---|
- 获取第二页按钮的xpath语句为://span[@class = “page-item_M4MDr pc” and text()=2]
- 代码实现

'''导包(start)'''
from selenium import webdriver
import time
'''导包(end)'''
# 浏览器驱动路径
path = "C:\\Users\\Administrator\\AppData\\Local\\Google\\Chrome\\Bin\\chromedriver.exe"
# 设置浏览器选项,解决用selenium打开浏览器时,因为没有指定用户文件夹而进入data页面
options = webdriver.ChromeOptions()
# options.add_argument(r'user-data-dir=任意文件夹路径即可')
options.add_argument(r'user-data-dir=D:\biancheng\PycharmProjects\test\urllibTest\userDir')
# 根据指定路径获取对应浏览器驱动对象,并且指定chrome_options
driver = webdriver.Chrome(executable_path = path,chrome_options=options)
url = "https://www.baidu.com/" # 要访问的网址
# 访问url
driver.get(url)
# 互动操作
# 1. 获取搜索框,并输入爬虫一下喽!
input = driver.find_element_by_id('kw')
input.send_keys("爬虫一下喽!")
time.sleep(2)
# 2. 获取百度一下按钮,并单击
baiduButton = driver.find_element_by_id('su')
baiduButton.click()
time.sleep(2)
# 3. 执行js代码,定位到距离网页上端100000的位置,也就是类似于向下滑100000个像素
js = "document.documentElement.scrollTop=100000"
driver.execute_script(js)
time.sleep(2)
# 4. 点击第二页按钮
page2Button = driver.find_element_by_xpath("//span[@class = 'page-item_M4MDr pc' and text()=2]")
page2Button.click()
time.sleep(2)
# 5. 获取第二页源码
page_source2 = driver.page_source
print(page_source2)
time.sleep(2)
# 6. 回退到上一页
driver.back()
time.sleep(2)
# 7. 前进一级
driver.forward()
time.sleep(2)
# 8. 退出浏览器
driver.quit()
五、PhantomJS
- 一个无界面浏览器,前面直接用selenium打开的浏览器,和我们人为打开是一样的,这样的操作对于程序来说有些太慢了
- 支持页面元素查找,js执行等等
- 由于不进行css和GUI渲染,运行效率要比真实浏览器快很多
但是因为这个团队已经散伙,所以这个已经不再更新了,老项目你依然会见到它,这里提一下就是让大家不要日后见到两眼懵
而现如今,Chrome headless用的更多一点
六、Chrome headless
Chrome-headless模式是Google在Chrome浏览器59版所新增的一种模式,可以让你在不打卡UI界面的情况下使用Chrome浏览器,运行效果与Chrome完美的保持了一致性
代码层面,除了需要一些固定代码创建Chrome headless对象以外,其余操作代码与上面直接用selenium打开浏览器是一样的。下面的代码是用Chrome headless模式打开百度首页,并且截屏
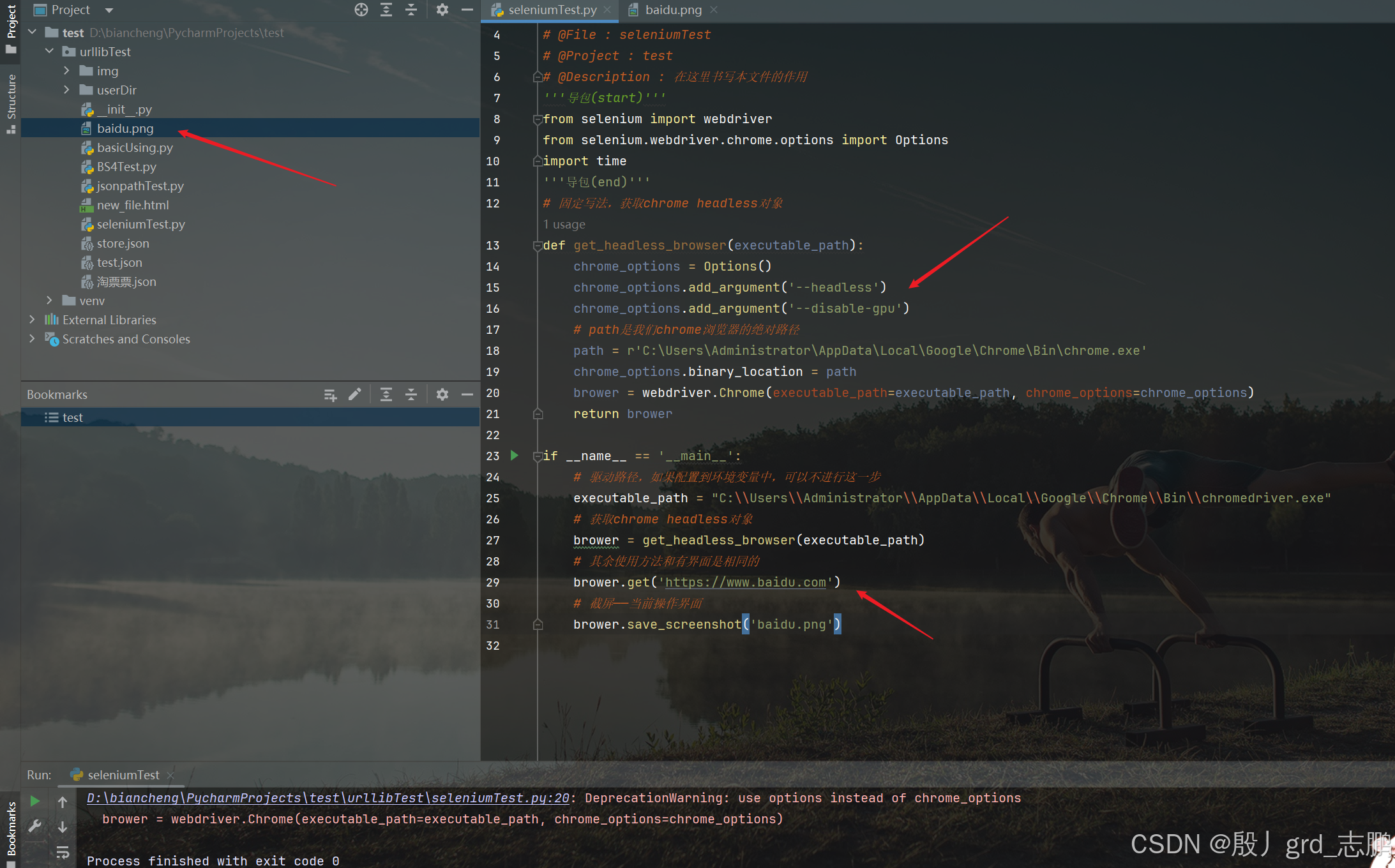
'''导包(start)'''
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
'''导包(end)'''
# 固定写法,获取chrome headless对象
def get_headless_browser(executable_path):chrome_options = Options()chrome_options.add_argument('--headless')chrome_options.add_argument('--disable-gpu')# path是我们chrome浏览器的绝对路径path = r'C:\Users\Administrator\AppData\Local\Google\Chrome\Bin\chrome.exe'chrome_options.binary_location = pathbrower = webdriver.Chrome(executable_path=executable_path, chrome_options=chrome_options)return browerif __name__ == '__main__':# 驱动路径,如果配置到环境变量中,可以不进行这一步executable_path = "C:\\Users\\Administrator\\AppData\\Local\\Google\\Chrome\\Bin\\chromedriver.exe"# 获取chrome headless对象brower = get_headless_browser(executable_path)# 其余使用方法和有界面是相同的brower.get('https://www.baidu.com')# 截屏——当前操作界面brower.save_screenshot('baidu.png')
相关文章:
Python爬虫知识体系-----Selenium
数据科学、数据分析、人工智能必备知识汇总-----Python爬虫-----持续更新:https://blog.csdn.net/grd_java/article/details/140574349 文章目录 一、安装和基本使用二、元素定位三、访问元素信息四、自动化交互五、PhantomJS六、Chrome headless 一、安装和基本使用…...

springboot+webSocket对接chatgpt
webSocket对接参考 话不多说直接上代码 WebSocket package com.student.config;import com.alibaba.fastjson2.JSONArray; import com.alibaba.fastjson2.JSONObject; import lombok.extern.slf4j.Slf4j; import org.springframework.http.MediaType; import org.springfram…...

【ROS2】 默认的DDS通信中间件替换为Eclipse Cyclone_DDS (DDS配置方法)
ROS2替换中间件为Cyclone_DDS 1.一些介绍:)2.不同DDS的RMW实现3.默认的FastDDS替换为Cyclone DDSi.安装依赖ii.编译 cyclone-dds 4.配置网络 1.一些介绍:) 上一篇我们探讨了ros1和ros2编写launch的区别 【ROS2】launch启动文件编…...

迈向数智金融:机器学习金融科技新纪元的新风采
个人名片: 🐼作者简介:一名大三在校生,喜欢AI编程🎋 🐻❄️个人主页🥇:落798. 🐼个人WeChat:hmmwx53 🕊️系列专栏:🖼️…...

Nginx+PHP+CI框架实现,访问静态文件带权限验证
1、访问来源验证配置nginx #文件访问来源校验 如路径:https://ys.test.com/test/api/uploads/test.png #不是该允许域名的将返回403页面 location /test/api/uploads/ {valid_referers ys.test.com ys.test2.com;if ($invalid_referer) {return 403;} }2、拦截访问…...

javascript 第二天
正则表达式 a/正则表达式内容/ a.test(“需要检测的内容”) 焦点事件 onfocus 获得焦点 onblur 失去焦点 他们都是事件,和onclick一样 onchange 内容改变 失去焦点时生效,多了内容检测,如果内容不变不触发,内容改变才触发 onk…...

unity2D游戏开发17战斗精灵
导入 将PlayerFight32x32.png拖Player文件夹进去 设置属性 创建动画剪辑 选中前四帧,右键Create|Animation,将动画命名为player-ire-east 其他几个动画也创建好后,将其拖到Animations|Animations文件夹 选中PlayerController,再点击Animator 创建新的Blend Tree Graph,并重…...

kafka架构+原理+源码
1.安装jdk17 sudo yum -y update sudo wget https://download.oracle.com/java/17/latest/jdk-17_linux-x64_bin.rpm sudo yum -y install ./jdk-17_linux-x64_bin.rpm sudo java -version 2.安装kafka How to easily install kafka without zookeeper | Aditya’s Blog 1.…...

实力共鉴!微风企斩获2024年浙江省专精特新中小企业
日前,微风企斩获2024年浙江省专精特新中小企业荣誉,这是继获得“国家高新技术企业”“浙江省科技中小企业”“杭州市雏鹰计划企业”等权威性认证后,微风企荣获的又一重磅殊荣。 “专精特新中小企业”是国家对具有“专业化、精细化、特色化、新…...

C#:枚举及位标志周边知识详解(小白入门)
文章目录 枚举为什么要有枚举?枚举的性质设置默认类型和显式设置成员的值 位标志(重要)位标记是什么及作用位标志周边知识HasFlag判断是否有该功能枚举前面加Flags的好处 关于枚举的更多知识using static简化代码获取枚举成员的字面量 枚举 为什么要有枚举? 为了增加代码的…...

这本vue3编译原理开源电子书,初中级前端竟然都能看懂
前言 众所周知vue提供了很多黑魔法,比如单文件组件(SFC)、指令、宏函数、css scoped等。这些都是vue提供的开箱即用的功能,大家平时用这些黑魔法的时候有没有疑惑过一些疑问呢。 我们每天写的vue代码一般都是写在*.vue文件中,但是浏览器却只…...
,需要安装python3.8,torch,ptwt,pywt等)
小白如何安装WNO(小波神经算子),需要安装python3.8,torch,ptwt,pywt等
下载项目 WNO在github上面的项目地址如下: https://github.com/csccm-iitd/WNO/tree/main 下载下来后,里面的数据集需要用matlab代码生成,也可以到里面提到的google云盘里面下载数据集 安装环境 然后需要安装环境 注意python版本一定要…...
--xunznux)
Java HashMap 源码解读笔记(一)--xunznux
文章目录 HashMap介绍实现说明:源码解读静态常量和内部节点类 Node静态工具方法属性字段 Fields未完待续。。。 HashMap 本文主要是用于记录我在阅读Java1.8的 HashMap 源码所做的笔记。对于源码中的注释会进行翻译下来,并且会对其中部分源码进行注释。 这一篇文章…...

“等保测评下的数据加密与隐私保护“
在当今数字化时代,数据已成为企业最宝贵的资产之一。然而,数据泄露、隐私侵犯等事件频发,不仅给企业带来经济损失,更严重损害了公众信任。等保测评,作为国家信息安全等级保护制度的重要组成部分,对数据加密…...

Oat++ 后端实现跨域
这里记录在官方的例子中,加入跨域。Oat Example-CRUD 在官方的例子中,加入跨域。 Oat Example-CRUD 修改AppComponent.hpp文件中的代码,如下: #include "AppComponent.hpp"#include "controller/UserController…...

Three basic starting points to do AI
Computers have been based on memory/storage for so many years. Don’t try to come up with something else. For so many years, AI has been based on fixed precise rules or fuzzy matching rules. Don’t think about coming up with the third one by yourself. Vi…...

等保测评练习卷22
等级保护初级测评师试题22 姓名: 成绩: 一、判断题(10110分) 1. 在应用系统测试中,如果审计是一个独立的功能,那么应用系统应对审计进程进行保…...

Linux用户-普通用户
作者介绍:简历上没有一个精通的运维工程师。希望大家多多关注我,我尽量把自己会的都分享给大家,下面的思维导图也是预计更新的内容和当前进度(不定时更新)。 Linux是一个多用户多任务操作系统,这意味着它可以同时支持多个用户登录并使用系统。…...

世界顶级思想家颜廷利:生命的升华,人类与动物的进化之道
世界顶级思想家颜廷利:生命的升华,人类与动物的进化之道 动物在于进化, 人类载于净化…(升命学说) 当代世界最著名的哲学家颜廷利教授指出,在探索生命奥秘的广阔旅程中,我们不禁惊叹于大自然…...

团队心脏:项目比赛中激发团队潜力的策略与技巧
团队心脏:项目比赛中激发团队潜力的策略与技巧 前言项目负责人的角色定位执行力的重要性提升个人执行力的策略团队协作的关键持续学习与创新应对挑战的态度总结与反思结语 前言 在项目管理的世界里,每一次比赛都是一场没有硝烟的战争。作为项目负责人&am…...

微信机器人WeixinBot完整指南:从零构建自动化微信应用
微信机器人WeixinBot完整指南:从零构建自动化微信应用 【免费下载链接】WeixinBot 网页版微信API,包含终端版微信及微信机器人 项目地址: https://gitcode.com/gh_mirrors/we/WeixinBot 微信机器人WeixinBot是一个功能强大的网页版微信API框架&am…...

突破大语言模型平滑诅咒:Emergence Codex语义架构与OpenClaw实战指南
1. 项目概述:什么是 Emergence Codex 与 OpenClaw Skill如果你和我一样,在深度使用大语言模型(LLM)构建智能体或进行复杂推理任务时,常常感到一种无力感——无论你怎么精心设计提示词(Prompt)&a…...

Kohya Trainer 图像生成实战:利用训练好的模型进行高质量创作
Kohya Trainer 图像生成实战:利用训练好的模型进行高质量创作 【免费下载链接】kohya-trainer Adapted from https://note.com/kohya_ss/n/nbf7ce8d80f29 for easier cloning 项目地址: https://gitcode.com/gh_mirrors/ko/kohya-trainer Kohya Trainer 是一…...

BepInEx IL2CPP启动失败终极解决指南:从异常诊断到游戏正常运行
BepInEx IL2CPP启动失败终极解决指南:从异常诊断到游戏正常运行 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx BepInEx作为Unity游戏插件框架,为玩家和开发…...

从 Classic ABAP 走到 ABAP Cloud,开发习惯、架构边界与 Clean Core 的重新建立
今天还在做 SAP S/4HANA 项目的人,大多已经感受到一个很现实的变化,真正难迁移的,从来不只是几段旧代码,也不只是把 SE80 里的对象搬到一个新工具里,而是整个开发思路要重新校准。以前很多团队习惯把 ABAP 当成一个紧贴业务系统内核的实现层,屏幕逻辑、数据库访问、增强点…...

基于MCP协议的智能文档处理工具simdoc-mcp:从RAG原理到Claude集成实战
1. 项目概述:从“文档理解”到“智能交互”的范式跃迁最近在折腾一个挺有意思的开源项目,叫simdoc-mcp。乍一看这个名字,可能有点摸不着头脑,svd-ai-lab是背后的团队,simdoc是核心,mcp是关键协议。简单来说…...

5分钟解决Windows热键冲突:Hotkey Detective完全指南
5分钟解决Windows热键冲突:Hotkey Detective完全指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否曾经…...

HolmesGPT 值不值得跟?把 AI SRE 的七强格局摊开看
CNCF Sandbox 在 2025-10 收了一个项目叫 HolmesGPT,定位是"开源 SRE Agent"。看着像下一个值得跟的风口——但同样进了 Sandbox 的 k8sgpt 已经 7,746 星,比它早一年;新来的 kagent 背靠 Solo.io,2,716 星只用了一年就…...

Armv9架构中STINDEX_EL1与SVCR寄存器详解
1. Arm架构中的STINDEX_EL1寄存器解析在Armv9架构中,STINDEX_EL1(Saved TIndex Register for EL1)是一个关键的系统寄存器,主要用于在异常进入时保存EL1的TIndex值。这个寄存器仅在实现了FEAT_S1POE2和FEAT_AA64特性时存在&#x…...

Go语言服务网格egress:外部服务访问
Go语言服务网格egress:外部服务访问 1. Egress代理 package egressimport ("net/http""net/url" )type EgressProxy struct {dialer *net.Dialertransport *http.Transport }func NewEgressProxy() *EgressProxy {return &EgressProxy{d…...