一文学会CUDA编程:深入了解CUDA编程与架构(一)
前言:
CUDA(Compute Unified Device Architecture,统一计算设备架构)是由NVIDIA公司开发的一种并行计算平台和编程模型。CUDA于2006年发布,旨在通过图形处理器(GPU)解决复杂的计算问题。在早期,GPU主要用于图像处理和游戏渲染,但随着技术的发展,其并行计算能力被广泛应用于科学计算、工程仿真、深度学习等领域。
CUDA的工作原理
CUDA的核心思想是将计算任务分配给GPU上的大量线程,这些线程可以并行地执行任务,从而实现高性能计算。CUDA将GPU划分为多个独立的计算单元,称为“流处理器”(Streaming Processor),这些流处理器可以独立地执行指令,互相加不干扰。
硬件层面
1、CUDA核心 (CUDA Core)
CUDA核心是执行线程计算的基本硬件单元。每个CUDA核心可以执行一个线程的计算任务。
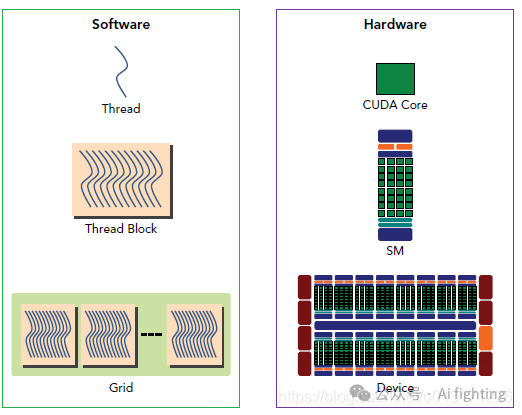
2、SM (Streaming Multiprocessor)
流多处理器 (SM) 是由多个CUDA核心组成的集成单元。每个SM负责管理和执行一个或多个线程块。SM内部有共享内存和缓存,用于加速数据访问和计算。
3、设备 (Device)
设备指的是整个GPU硬件。一个设备包含多个SM,能够处理大量并行计算任务。设备通过高带宽的内存和数据传输机制与主机(如CPU)进行数据交换。
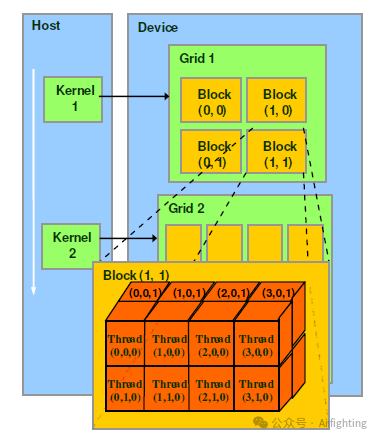
软件层面
1、线程 (Thread)
在CUDA编程中,线程是执行基本计算任务的最小单位。每个线程执行相同的程序代码,但可以处理不同的数据。

2、线程块 (Thread Block)
线程块是由多个线程组成的集合。线程块中的线程可以共享数据,并且可以通过同步机制来协调彼此的工作。线程块的大小在程序执行时是固定的。
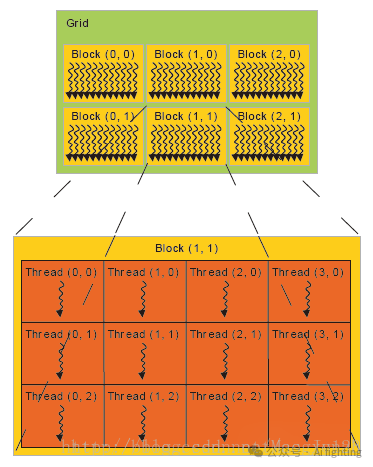
3、网格 (Grid)
网格是由多个线程块组成的更大集合。网格中的所有线程块并行执行任务,网格的大小也在程序执行时固定。

示例
实现两个向量相加 arr_c[] = arr_a[] +arr_b[]
#include <cuda.h>
#include <cuda_runtime_api.h>#include <cmath>
#include <iostream>#define CUDA_CHECK(call) \{ \const cudaError_t error = call; \if (error != cudaSuccess) { \fprintf(stderr, "Error: %s:%d, ", __FILE__, __LINE__); \fprintf(stderr, "code: %d, reason: %s\n", error, \cudaGetErrorString(error)); \exit(1); \} \}__global__ void addKernel(float *pA, float *pB, float *pC, int size)
{int index = blockIdx.x * blockDim.x + threadIdx.x; // 计算当前数组中的索引if (index >= size)return;pC[index] = pA[index] + pB[index];
}int main()
{float a[16] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15};float b[16] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15};int arr_len = 16;float *dev_a, *dev_b, *dev_c;CUDA_CHECK(cudaMalloc(&dev_a, sizeof(float) * arr_len));CUDA_CHECK(cudaMalloc(&dev_b, sizeof(float) * arr_len));CUDA_CHECK(cudaMalloc(&dev_c, sizeof(float) * arr_len));CUDA_CHECK(cudaMemcpy(dev_a, a, sizeof(float) * arr_len, cudaMemcpyHostToDevice));CUDA_CHECK(cudaMemcpy(dev_b, b, sizeof(float) * arr_len, cudaMemcpyHostToDevice));int *count;CUDA_CHECK(cudaMalloc(&count, sizeof(int)));CUDA_CHECK(cudaMemset(count, 0, sizeof(int)));addKernel<<<arr_len + 512 - 1, 512>>>(dev_a, dev_b, dev_c, arr_len);float *output = (float *)malloc(arr_len * sizeof(float));CUDA_CHECK(cudaMemcpy(output, dev_c, sizeof(float) * arr_len, cudaMemcpyDeviceToHost));std::cout << " output add" << std::endl;for (int i = 0; i < arr_len; i++) {std::cout << " " << output[i];}std::cout << std::endl;return 0;
}代码理解
addKernel<<<arr_len + 512 - 1, 512>>>函数类型如下
addKernel<<<dim3 grid, dim3 block>>>前面的表达等价于
addKernel<<<(dim3 grid(arr_len + 512 - 1), 1, 1), dim3 block(512, 1, 1)>>>grid 与block 理解
假设只使用16个元素, arr_len =16
1、使用调整block的参数:
1.1只有x:
dim3 grid(1, 1, 1), block(arr_len, 1, 1); // 一个block里面有16个线程 // 设置参数
此时遍历的代码如下:
__global__ void addKernel(float *pA, float *pB, float *pC, int size){// block是一维的int index = threadIdx.x; // 计算当前数组中的索引if (index >= size)return;pC[index] = pA[index] + pB[index];}
1.2 含有x, y
dim3 grid(1, 1, 1), block(8, 2, 1); //每个block x方向有8个线程,总共2组。 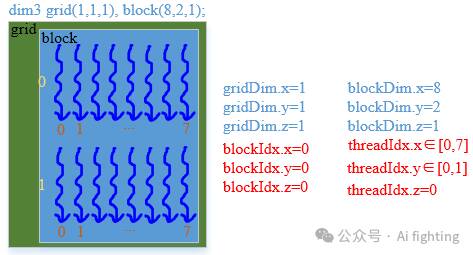
__global__ void addKernel(float *pA, float *pB, float *pC, int size){ // block是二维的int index = threadIdx.x + blockDim.x* threadIdx.y; // 计算当前数组中的索引if (index >= size)return;pC[index] = pA[index] + pB[index];}
2、更改grid 参数
2.1 只更改x方向的参数
dim3 grid(16, 1, 1), block(1, 1, 1); //还有16个block, 每个block就一个线程 // 设置参数
__global__ void addKernel(float *pA, float *pB, float *pC, int size){ // grid.x是一维的int index = blockIdx.x; // 计算当前数组中的索引if (index >= size)return;pC[index] = pA[index] + pB[index];}
3、grid, block参数都改
3.1 grid block各改一个
dim3 grid(4, 1, 1), block(4, 1, 1) // 代码还有4个x方向block, 每个block x方向有4个线程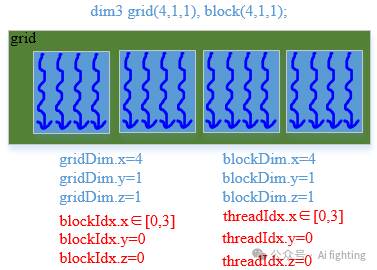
__global__ void addKernel(float *pA, float *pB, float *pC, int size){ // grid.x是一维的int index = blockIdx.x*gridDim.x + threadIdx.x; // 计算当前数组中的索引if (index >= size)return;pC[index] = pA[index] + pB[index];}
3.2 grid block更改两个
dim3 grid(2, 2, 1), block(2, 2, 1) // 代码还有2个X方向block,Y方向上有两组, 每个block x方向有2个线程, y方向上有两组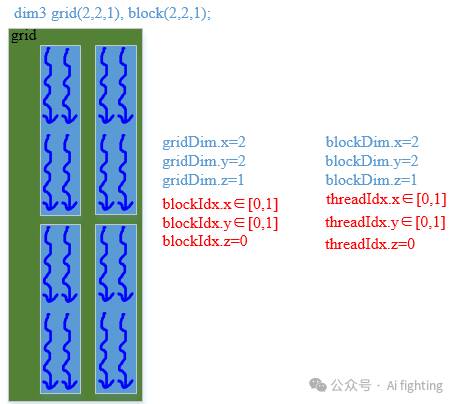
__global__ void addKernel(float *pA, float *pB, float *pC, int size){ // 在第几个块中 * 块的大小 + 块中的x, y维度(几行几列)int index = (blockIdx.y * gridDim.x + blockIdx.x) * (blockDim.x * blockDim.y) + threadIdx.y * blockDim.y + threadIdx.x;if (index >= size)return;pC[index] = pA[index] + pB[index];}
总结
CUDA作为一种强大的并行计算平台和编程模型,极大地推动了高性能计算、深度学习等领域的快速发展。通过掌握CUDA,开发者可以充分利用GPU的并行计算能力,显著提升程序的运行效率和性能。无论是科学研究还是商业应用,CUDA都提供了广阔的可能性和机遇。
关注我的公众号auto_driver_ai(Ai fighting), 第一时间获取更新内容。
相关文章:
一文学会CUDA编程:深入了解CUDA编程与架构(一)
前言: CUDA(Compute Unified Device Architecture,统一计算设备架构)是由NVIDIA公司开发的一种并行计算平台和编程模型。CUDA于2006年发布,旨在通过图形处理器(GPU)解决复杂的计算问题。在早期…...

Jquery判断图片加载失败,显示默认图片
//加载图片 出现404状态时触发 $(img).error(function () { //将加载不到的图片的src属性时,修改成默认图片,注意:默认图片必须保证存在,否则会一直调用此函数,造成死循环。$(this).attr("src", "Imag…...

App 自动化测试调研
App 自动化测试调研 App 自动化测试的价值 App 自动化测试在软件开发过程中扮演着重要的角色,具有以下几个方面的价值: 1.提高测试效率和覆盖率:自动化测试可以执行大量的测试用例,覆盖各种功能和场景,相比手动测试…...
Java 后端已经过时的技术,也是我逝去的青春
最近这段时间收到了一些读者的私信,问我某个技术要不要学,还有一些的同学竟然对 Java 图形化很感兴趣,还想找这方面的工作。 我接触 Java 已近 10多年了,见证了许多 Java 技术变迁,包括: JavaEE 框架&…...

释放自动化测试潜能:性能优化策略与实战技巧!
引言 在当今追求软件快速迭代的环境下,自动化测试的性能瓶颈正成为制约开发流程加速的主要障碍。本文将深入探讨如何通过策略和实践,优化自动化测试的性能,实现测试执行速度的质的飞跃。 自动化性能瓶颈的识别与突破 首先,识别并…...

如何理解代码的跨平台?
跨平台性: 跨平台性意味着,在多个平台都兼容运行 那么是怎么做到跨平台? 一般来说,window的操作系统和Linux的操作系统肯定是不一样的 那么提供的系统调用接口和诸多细节也是不一样的 但是,我们的c语言和c语言…...

dp:221. 最大正方形
221. 最大正方形 看到这个题目真能立马想到dp吗?貌似很难,即使知道是一个dp题也很难想到解法。 直观来看,使用bfs以一个点为中点进行遍历,需要的时间复杂度为 O ( n 2 m 2 ) O(n^2m^2) O(n2m2) 但是可以很容易发现,…...

花10分钟写个漂亮的后端API接口模板!
你好,我是田哥 在这微服务架构盛行的黄金时段,加上越来越多的前后端分离,导致后端API接口规范变得越来越重要了。 比如:统一返回参数形式、统一返回码、统一异常处理、集成swagger等。 目的主要是规范后端项目代码,以及…...
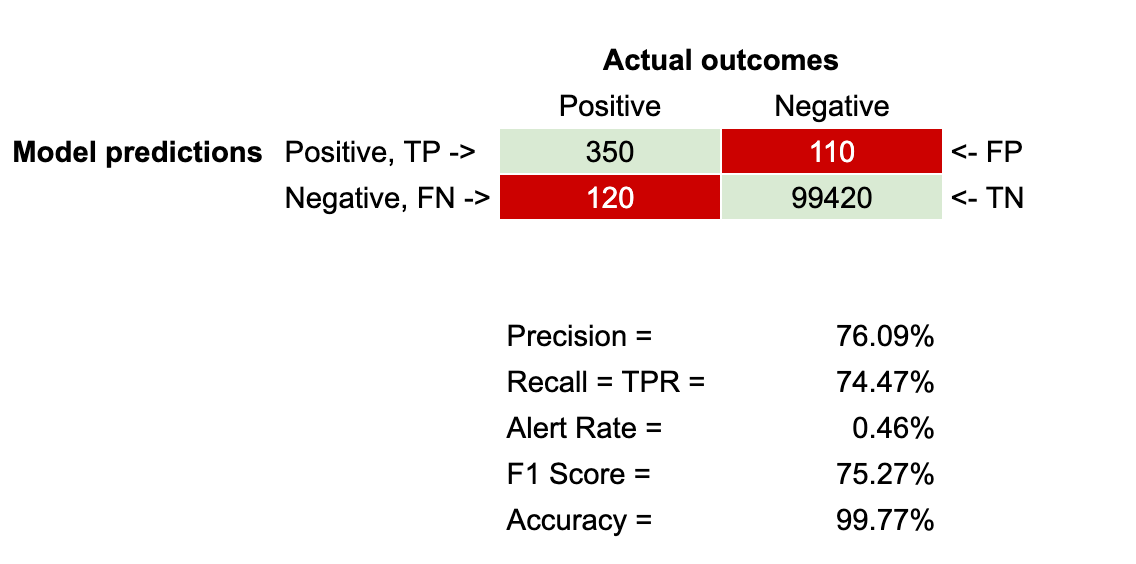
评估分类机器学习模型的指标
欢迎来到雲闪世界。一旦我们训练了一个监督机器学习模型来解决分类问题,如果这就是我们工作的结束,我们会很高兴,我们可以直接向他们输入新数据。我们希望它能正确地对所有内容进行分类。然而,实际上,模型做出的预测并…...

农机自动化:现代农业的未来趋势
随着人口的增长和农业生产的需求不断增加,提高农业生产效率成为现代农业的重要目标。农机自动化作为一种新兴技术,可以大幅度提升农机的使用效率和生产能力。农机自动化是指利用先进的传感技术、数据处理和人工智能技术,使农机能够自动完成农…...

25考研操作系统复习·1.1/1.2/1.3 操作系统的基本概念/发展历程/运行环境
目录 操作系统的基本概念 概念(定义) 功能和目标 资源的管理者 向上层提供服务 给普通用户的 给软件/程序员的 对硬件机器的拓展 操作系统的特征 操作系统的发展历程 操作系统的运行环境 操作系统的运行机制 中断和异常 中断的作用 中断的…...

如何培养学生的创新意识和实践能力
培养学生的创新意识和实践能力是一个复杂而系统的过程,涉及多个方面的努力和措施。以下是一些具体的做法: 一、培养学生的创新意识 提供创新环境: 为学生创造一个开放、自由、支持创新的学习环境,让他们能够自由地表达自己的想法…...
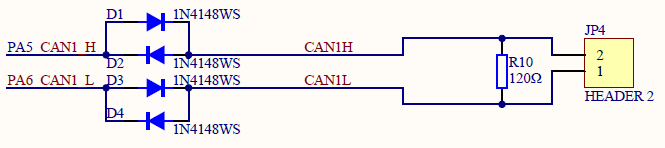
四、GD32 MCU 常见外设介绍(15)CAN 模块介绍
CAN是控制器局域网络(Controller Area Network)的简称,它是由研发和生产汽车电子产品著称的德国BOSCH公司开发的,并最终成为国际标准(ISO11519),是国际上应用最广泛的现场总线之一。 CAN总线协议已经成为汽车计算机控…...

AIGC大模型产品经理高频面试大揭秘‼️
近期有十几个学生在面试大模型产品经理(薪资还可以,详情见下图),根据他们面试(包括1-4面)中出现高频大于3次的问题汇总如下,一共32道题目(有答案)。 29.讲讲T5和Bart的区…...

【嵌入式笔记】【C语言】struct union
结构体(Struct)定义: struct 结构体名 {member1; // 成员1,可以是任何基本数据类型或复合类型member2; // 成员2... };//例如: struct Point {float x;float y;...
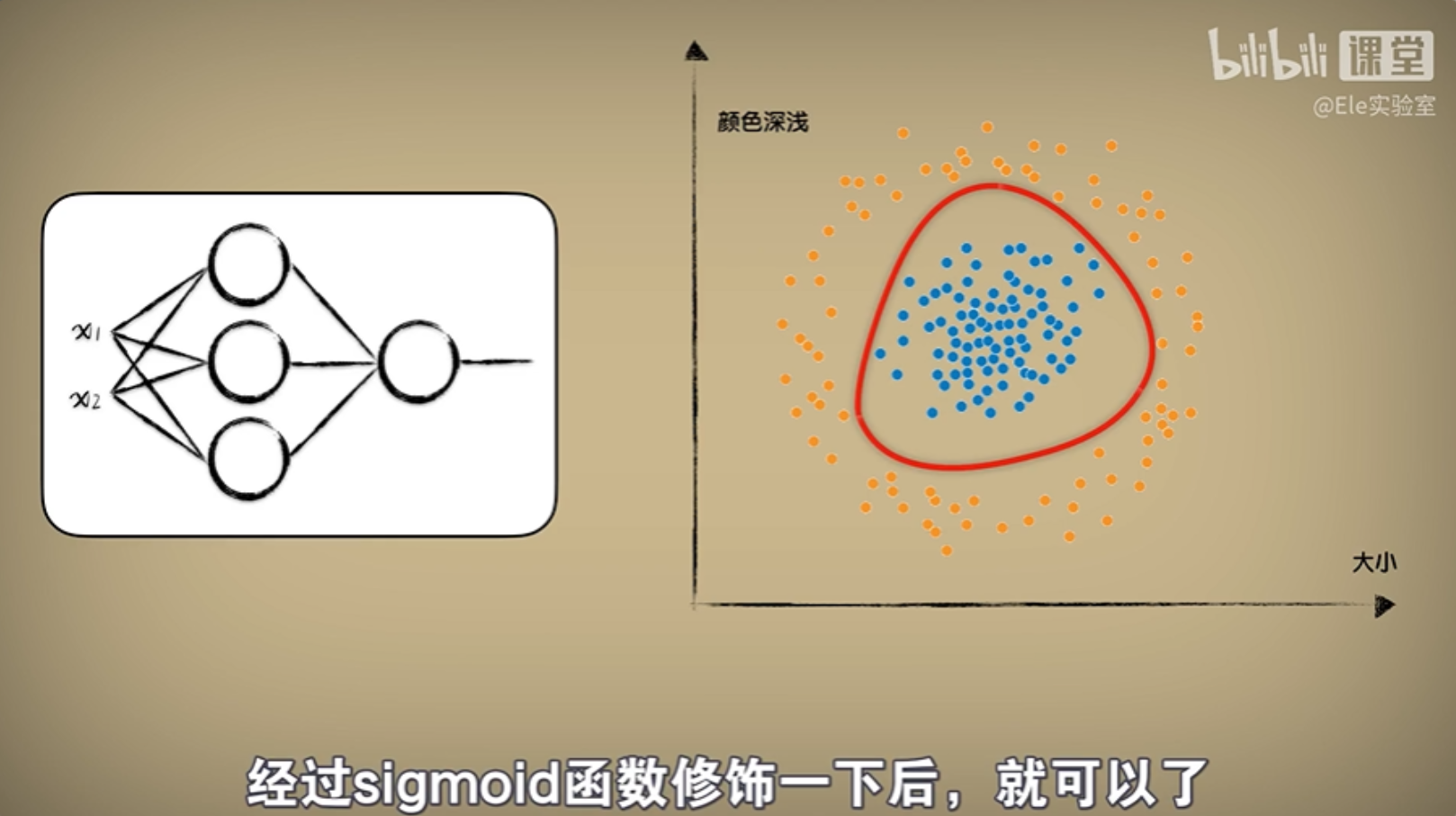
【初学人工智能原理】【9】深度学习:神奇的DeepLearning
前言 本文教程均来自b站【小白也能听懂的人工智能原理】,感兴趣的可自行到b站观看。 代码及工具箱 本专栏的代码和工具函数已经上传到GitHub:1571859588/xiaobai_AI: 零基础入门人工智能 (github.com),可以找到对应课程的代码 正文 深度…...

[RoarCTF 2019]Easy Calc1
打开题目 查看源码,看到 看到源代码有 calc.php,构造url打开 看到php审计代码, 由于页面中无法上传num,则输入 num,在num前加入一个空格可以让num变得可以上传,而且在进行代码解析时,php会把前…...
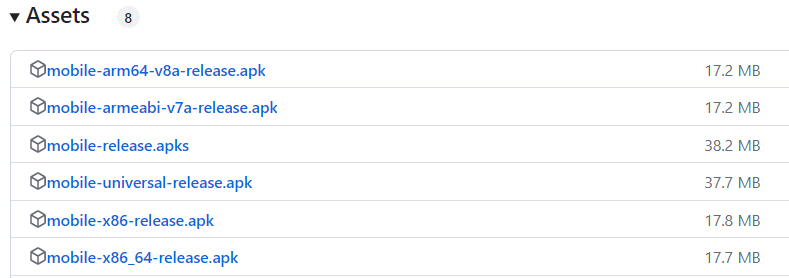
安卓APK安装包arm64-v8a、armeabi-v7a、x86、x86_64有何区别?如何选择?
在GitHub网站下载Android 安装包,Actions资源下的APK文件通常有以下版本供选择: 例如上图是某Android客户端的安装包文件,有以下几个版本可以选择: mobile-release.apk(通用版本,体积最大)mobi…...

【AI大模型】通义千问:开启语言模型新篇章与Function Call技术的应用探索
文章目录 前言一、大语言模型1.大模型介绍2.大模型的发展历程3.大模型的分类a.按内容分类b.按应用分类 二、通义千问1.通义千问模型介绍a.通义千问模型介绍b.应用场景c.模型概览 2.对话a.对话的两种方式通义千问API的使用 b.单轮对话Vue页面代码:Django接口代码 c.多…...

详细教程 MySQL 数据库 下载 安装 连接 环境配置 全面
数据库就是储存和管理数据的仓库,对数据进行增删改查操作,其本质是一个软件。 首先数据有两种,一种是关系型数据库,另一种是非关系型数据库。 关系型数据库是以表的形式来存储数据,表和表之间可以有很多复杂的关系&a…...
)
告别手动刷新!用PowerShell脚本实现Windows下校园网自动重连(含任务计划设置)
告别手动刷新!用PowerShell脚本实现Windows下校园网自动重连(含任务计划设置) 每次开机都要手动登录校园网?网络突然断开还得重新输入账号密码?这些繁琐操作已经成为过去式。本文将手把手教你用PowerShell打造全自动校…...
)
保姆级教程:在Windows 10/11上从源码编译Groops(含Qt环境变量避坑指南)
从零构建Groops编译环境:Windows系统下的完整避坑指南 当你在GNSS数据处理领域深耕时,一款强大的开源工具能让你事半功倍。Groops作为重力场恢复和精密定轨的瑞士军刀,其功能强大但编译过程却可能让新手望而却步。本文将带你一步步穿越编译迷…...

如何为iOS 14.0-16.6.1设备安装TrollStore:TrollInstallerX完整指南
如何为iOS 14.0-16.6.1设备安装TrollStore:TrollInstallerX完整指南 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX 如果你正在寻找一种可靠且简单的方法在i…...
)
别再只会用IP核了!手把手教你用Verilog从零实现一个16阶FIR滤波器(附完整代码)
从零构建16阶FIR滤波器:Verilog实战指南与工程思维解析 在FPGA开发领域,FIR(有限脉冲响应)滤波器是数字信号处理的基础模块,但大多数工程师习惯直接调用厂商提供的IP核,这就像只会开自动挡汽车的司机——虽…...

跨境社媒账号做不稳 很多时候不是内容不够好而是气质不够稳定
很多团队做跨境社媒时,最容易把注意力集中在“内容创意”上。 选题够不够新,切口够不够巧,视频开头能不能抓住人,标题会不会让人点开,这些当然都重要。但真正做久了之后会发现,一个账号能不能长期跑起来&am…...

如何快速解密QMC音频文件:qmc-decoder完整使用指南
如何快速解密QMC音频文件:qmc-decoder完整使用指南 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 你是否遇到过从音乐平台下载的歌曲无法在其他播放器播放的情…...

别再只调包了!用PyTorch从零手搓一个Unet,搞懂语义分割的每个细节
从零构建Unet:深入解析语义分割的代码实现与设计哲学 在计算机视觉领域,语义分割一直是极具挑战性的任务之一。不同于简单的图像分类,语义分割需要模型对图像中的每一个像素进行分类,这要求模型既要理解全局上下文信息,…...

S7-1200 PLC 五大核心实验精讲:从振荡电路到浮点数运算的仿真实战
1. 从零开始搭建S7-1200仿真环境 第一次接触西门子S7-1200 PLC时,我被它强大的功能和复杂的软件界面吓到了。后来发现只要掌握几个关键步骤,仿真环境搭建其实比想象中简单得多。这里分享我的踩坑经验,帮你省去80%的摸索时间。 首先需要安装…...

MetaGPT多智能体协作框架:从原理到实战的AI自动化软件开发指南
1. 项目概述:当AI学会“开会”,一个智能体协作框架的诞生 如果你关注AI领域,最近可能被一个叫“MetaGPT”的项目刷屏了。它不是一个单一的模型,而是一个雄心勃勃的框架,其核心目标直指一个激动人心的未来:…...

可解释AI评估指南:从原型纯度到TCAV分数的量化度量体系
1. 项目概述:为什么我们需要量化评估可解释AI?在人工智能,尤其是深度学习模型日益渗透到医疗诊断、自动驾驶、金融风控等关键领域的今天,一个核心的信任危机始终悬而未决:我们如何相信一个“黑箱”模型做出的决策&…...