大模型算法面试题(十八)
本系列收纳各种大模型面试题及答案。

1、P-tuning v2 思路、优缺点是什么
P-tuning v2是清华大学自然语言处理实验室(THUDM)等研究机构提出的一种新的预训练模型优化方法,主要关注如何通过动态构建任务相关的提示序列来引导预训练模型进行更有效的微调。以下是关于P-tuning v2的思路、优点和缺点的详细分析:
思路
P-tuning v2的思路主要体现在以下几个方面:
-
深度提示调优:与P-tuning v1等早期方法相比,P-tuning v2采用了深度提示调优的方法。它不仅仅在输入嵌入层添加连续的提示,而是将提示添加到模型的每一层中,作为前缀tokens。这种方法使得模型在训练过程中能够更深入地利用预训练知识,并且提高了可调优参数的数量,从而增强了模型的性能。
-
动态模板学习:P-tuning v2引入了动态模板学习的机制。在训练过程中,模型会根据训练样本动态地生成提示结构,并通过搜索算法或基于参数的方式实现。这种机制使得模型能够自适应地调整提示结构,以适应不同任务和数据的需求。
-
参数高效性:P-tuning v2在保持高性能的同时,显著降低了计算资源的需求。它只需要微调模型中的一小部分参数(通常是0.1%到3%),就能够达到与全面微调相当的性能。
优点
-
高效性:P-tuning v2在降低微调步数的同时保持了高精度,显著减少了计算资源的消耗。这使得它在处理大规模数据集或实时在线服务时具有显著优势。
-
通用性强:P-tuning v2可以广泛应用于多种自然语言处理任务,包括但不限于文本分类、情感分析、问答系统、语义理解等。其动态模板学习的机制使得模型能够自适应地调整以适应不同任务和数据的需求。
-
参数高效:通过深度提示调优和动态模板学习,P-tuning v2能够在保持高性能的同时显著减少需要微调的参数数量。这降低了模型的复杂性和过拟合的风险。
-
易于部署:P-tuning v2提供了清晰的API接口和详尽的文档,便于开发者将其集成到自己的项目中。这降低了技术门槛,使得更多的研究人员和开发者能够利用这一技术来优化他们的模型。
缺点
尽管P-tuning v2具有许多优点,但它也存在一些潜在的缺点:
-
模型复杂度增加:虽然P-tuning v2减少了需要微调的参数数量,但它在每一层都添加了提示作为前缀tokens,这增加了模型的复杂度。这可能导致在某些情况下模型的训练时间增加。
-
超参数调整:P-tuning v2的性能受到多个超参数的影响,如提示长度、分类头的设计等。这些超参数的调整需要一定的经验和试错过程,可能会增加模型优化的难度。
-
对特定任务的依赖性:虽然P-tuning v2在多种自然语言处理任务上表现出了良好的性能,但它在某些特定任务上的表现可能仍然受到数据集和任务特性的影响。这可能需要研究者针对特定任务进行进一步的优化和调整。
综上所述,P-tuning v2是一种高效、通用且参数高效的预训练模型优化方法。它通过深度提示调优和动态模板学习的机制,显著提高了模型的性能和计算效率。然而,它也存在一些潜在的缺点和挑战,需要研究者在使用过程中注意和解决。
2、指示微调(Prompt-tuning)与 Prefix-tuning 区别 是什么
指示微调(Prompt-tuning)与Prefix-tuning是两种不同的参数微调技术,它们都旨在通过有限参数调整来引导大型预训练模型执行不同任务,但具体操作位置和方式有所不同。以下是两者之间的主要区别:
1. 操作位置与方式
- Prompt-tuning:
- 主要关注于输入序列的修改。
- 通过在模型输入之前添加一个可学习的“提示”(prompt),这个提示通常是一个或一系列向量,它们代表了特定任务的上下文信息。
- 提示可以是文本形式,即直接插入到输入序列中的词汇项(tokens),也可以是对嵌入层权重的更新,这些权重用于生成每个任务特有的前缀部分。
- 通过优化这些提示向量,模型可以在不改变主体模型参数的情况下,根据不同的任务调整其输出。
- Prefix-tuning:
- 更具体地将可学习的“前缀”向量应用于模型的自回归部分(如Transformer的解码器部分),而非输入序列的开头。
- 前缀向量被附加到自回归过程中的隐藏状态,并随着每次自回归步骤传播,影响整个解码过程。
- 这种方法允许模型动态地调整其生成行为,同时保持主体模型参数不变,但它不是以插入额外的词汇项形式进行,而是改变了模型内部计算的初始状态。
2. 灵活性与通用性
- Prompt-tuning:
- 由于其直接在输入序列中添加提示,因此可以根据不同的任务灵活地定义和调整提示内容,具有较高的灵活性。
- 这种灵活性使得Prompt-tuning能够更好地适应各种自然语言处理任务。
- Prefix-tuning:
- 更多地关注于模型内部状态的调整,而非直接修改输入序列。
- 在某些情况下,可能不如Prompt-tuning那样灵活,但在保持模型主体参数不变的情况下,能够有效地调整模型的生成行为。
3. 应用场景
- 两者都可以应用于多种自然语言处理任务,如情感分析、问答系统、文本分类等。
- Prompt-tuning由于其灵活性,可能更适合于那些需要频繁更改输入提示或任务定义的场景。
- Prefix-tuning则可能更适用于那些需要微调模型内部状态以优化生成性能的场景。
综上所述,Prompt-tuning和Prefix-tuning在操作位置、方式、灵活性与通用性方面存在差异。选择哪种方法取决于具体任务的需求、模型的特点以及调优的目标。
3、微调方法批处理大小模式GPU显存速度
微调方法中的批处理大小、GPU显存使用以及速度之间的关系是深度学习训练过程中的重要考虑因素。以下是对这些方面的详细分析:
1. 批处理大小(Batch Size)
批处理大小是指在训练过程中,模型同时处理的数据样本数量。它直接影响到模型的训练速度和稳定性。
- 对GPU显存的影响:批处理大小越大,每次迭代所需的显存就越多,因为需要同时存储更多的数据样本及其对应的梯度信息。当批处理大小增加到一定程度时,可能会超出GPU的显存限制,导致训练无法进行。
- 对速度的影响:在一定范围内,增大批处理大小可以提高GPU的利用率,从而加快训练速度。然而,当批处理大小过大时,由于显存限制和梯度计算量的增加,可能会导致训练速度下降。
2. GPU显存使用
GPU显存是训练深度学习模型时的重要资源,它用于存储模型参数、中间计算结果和梯度信息等。
- 优化显存使用的方法:
- 梯度积累(Gradient Accumulation):在显存有限的情况下,可以通过减小批处理大小并增加梯度积累的步数来模拟较大的批处理效果。这种方法可以在不增加显存消耗的情况下,提高模型的训练稳定性。
- 混合精度训练:将部分或全部FP32(32位浮点)参数转换为FP16(16位浮点)或更低精度的格式,以减少显存使用并可能提高训练速度。
- 模型量化:将模型参数从高精度转换为低精度格式,如INT8量化,可以显著减少显存使用和模型大小,但可能会牺牲一定的精度。
3. 速度
训练速度受到多种因素的影响,包括硬件性能(如GPU型号和显存大小)、软件优化(如代码实现和库的使用)、数据加载速度以及批处理大小等。
- 提高训练速度的方法:
- 使用高性能硬件:选择具有更多计算单元和更大显存的GPU可以显著提高训练速度。
- 优化数据加载:使用高效的数据加载和预处理技术可以减少CPU到GPU之间的数据传输时间。
- 代码和库优化:使用经过优化的深度学习框架和库,以及编写高效的代码,可以减少计算冗余和提高计算效率。
- 调整超参数:如学习率、优化器类型等超参数的调整也可能对训练速度产生影响。
综上所述,微调方法中的批处理大小、GPU显存使用和速度之间存在复杂的关系。在实际应用中,需要根据具体的硬件条件、任务需求和模型特性来选择合适的批处理大小和优化策略,以达到最佳的训练效果。
4、能不能总结一下各种参数高效微调方法
参数高效微调(PEFT, Parameter Efficient Fine-Tuning)方法旨在通过调整模型中的少量参数来优化模型在特定任务上的性能,同时保持大部分预训练模型的参数不变。这种方法在处理大规模预训练模型时尤为重要,因为它可以显著降低计算资源的需求并加速训练过程。以下是几种主要的参数高效微调方法的总结:
1. 增加式方法(Additive Methods)
a. 适配器(Adapters)
- 原理:在预训练模型的每个Transformer层中插入可训练的适配器模块,这些模块通常包含两个前馈子层,用于将特征维度投影到较小的空间,应用非线性函数后再投影回原始维度。
- 特点:通过限制新添加的参数数量(如设置较小的维度m),适配器方法能够在保持模型性能的同时减少训练参数。
- 应用:如Adapter Tuning,在多个NLP任务上表现出色,且能够生成性能强劲的紧凑模型。
b. 软提示(Soft Prompts)
- 原理:在模型输入层或中间层加入可训练的虚拟标记(Virtual Tokens)或前缀(Prefixes),这些标记会参与到模型的计算过程中,并通过梯度下降法进行更新。
- 特点:软提示方法避免了硬提示(Hard Prompts)的局限性,如难以优化和受输入长度限制。
- 应用:如Prefix Tuning、P-Tuning、P-Tuning v2等,这些方法在多个NLP任务上取得了与全量微调相近甚至更好的性能。
2. 选择性方法(Selective Methods)
原理:选择性方法从预训练模型中选择一部分参数进行微调,而保持其他参数不变。这种方法通常基于某种策略来选择要更新的参数,如层的深度、层类型或个别参数的重要性。
应用:如BitFit,该方法仅修改模型的偏置项(Bias)或其中的子集,并在多个任务上取得了与全量微调相近的性能。
3. 重新参数化方法(Reparameterization Methods)
a. 低秩分解(Low-Rank Decomposition)
- 原理:基于模型权重矩阵在特定微调后具有较低的本征秩的假设,将预训练模型的权重矩阵分解成两个较小的矩阵。
- 特点:通过训练这两个较小的矩阵来间接更新原始权重矩阵,从而显著减少需要训练的参数数量。
- 应用:如LoRA(Low-Rank Adaptation),该方法在多个NLP任务上取得了与全量微调相近甚至更好的性能,且训练过程可以在单个GPU上完成。
b. AdaLoRA
- 原理:AdaLoRA是LoRA的升级版,它让模型学习SVD分解的近似,并在损失函数中增加惩罚项以防止矩阵偏离正交性太远,从而实现稳定训练。
- 特点:AdaLoRA能够自适应地调整不同模块的秩,进一步节省计算量,并在多个任务上表现出色。
4. 混合微调(Hybrid Fine-Tuning)
原理:混合微调方法结合了上述多种PEFT方法的优点,通过设计特定的组合策略来优化模型性能。
应用:如结合Adapter和Soft Prompts的方法,或结合LoRA和其他PEFT方法的策略,这些方法在特定任务上可能取得更好的性能。
总结
参数高效微调方法通过不同的策略来调整预训练模型中的少量参数,从而在保持模型性能的同时显著降低计算资源的需求。这些方法各有千秋,适用于不同的应用场景和任务需求。在选择具体的PEFT方法时,需要根据任务特性、模型规模和计算资源等因素进行综合考虑。
5、如何解决三个阶段的训练(SFT->RM->PPO)过程较长,更新迭代较慢问题?
针对三个阶段的训练(SFT->RM->PPO)过程较长、更新迭代较慢的问题,可以从多个方面进行优化和改进。以下是一些具体的解决策略:
1. 数据和计算优化
优化训练数据集:
- 提高数据质量:确保训练数据集的准确性和多样性,减少噪声和不相关数据。
- 数据增强:通过合成、变换、拼接等手段丰富数据多样性,模拟真实场景中的变体,提升模型抗干扰能力。
利用更高效的计算资源:
- 分布式训练:采用分布式训练方法,将训练任务分配到多个计算节点上并行处理,加速训练过程。
- 使用高性能硬件:如GPU、TPU等,提升计算速度。
2. 模型架构改进
简化模型架构:
- 减少模型参数:通过简化模型结构或使用更高效的网络结构,减少模型参数数量,降低计算复杂度。
- 知识蒸馏:通过模型蒸馏技术,将大型复杂模型的知识转移到更小、更高效的模型中,以加快训练速度和降低资源消耗。
探索新型模型结构:
- 稀疏化:采用稀疏化技术减少模型中的非零参数数量,提高计算效率。
- 自适应结构:设计能够根据任务需求自适应调整结构的模型,以更好地适应不同场景。
3. 算法优化
优化优化算法:
- 改进PPO算法:探索使用改进的PPO算法或其他强化学习算法,以加快收敛速度和提高训练稳定性。
- 超参数调整:通过自动化的超参数搜索和调整,找到最优的训练参数组合,以缩短训练时间并提高模型性能。
引入其他优化技术:
- 动量优化:使用动量项来加速梯度下降过程,减少训练时间。
- 早停策略:在验证集上监测模型性能,一旦性能不再提升则提前停止训练,避免过拟合和浪费资源。
4. 奖励函数设计
优化奖励函数:
- 设计更准确的奖励函数:使奖励函数能够更准确地反映模型输出的质量,从而更有效地指导模型学习。
- 引入人类反馈:利用人类标注的数据集来训练奖励模型,使其能够更好地捕捉人类偏好和期望。
减少奖励模型依赖:
- RRHF方法:使用RRHF(RankResponse from Human Feedback)等方法,通过排名损失来使回复与人类偏好对齐,减少对强化学习阶段的依赖。
5. 微调策略调整
调整SFT策略:
- 部分参数微调:采用部分参数微调策略(如LoRA、P-tuning v2等),仅更新模型中的部分参数以加速训练过程。
- 冻结预训练权重:在微调过程中冻结部分或全部预训练模型的权重,以减少需要训练的参数数量。
优化RM和PPO阶段:
- 减少RM阶段数据量:通过优化数据集选择策略减少RM阶段所需的数据量。
- 并行化PPO训练:采用并行化训练方法加速PPO阶段的训练过程。
综上所述,通过数据和计算优化、模型架构改进、算法优化、奖励函数设计以及微调策略调整等多方面的努力,可以有效解决三个阶段的训练过程较长、更新迭代较慢的问题。
相关文章:
大模型算法面试题(十八)
本系列收纳各种大模型面试题及答案。 1、P-tuning v2 思路、优缺点是什么 P-tuning v2是清华大学自然语言处理实验室(THUDM)等研究机构提出的一种新的预训练模型优化方法,主要关注如何通过动态构建任务相关的提示序列来引导预训练模型进行更…...
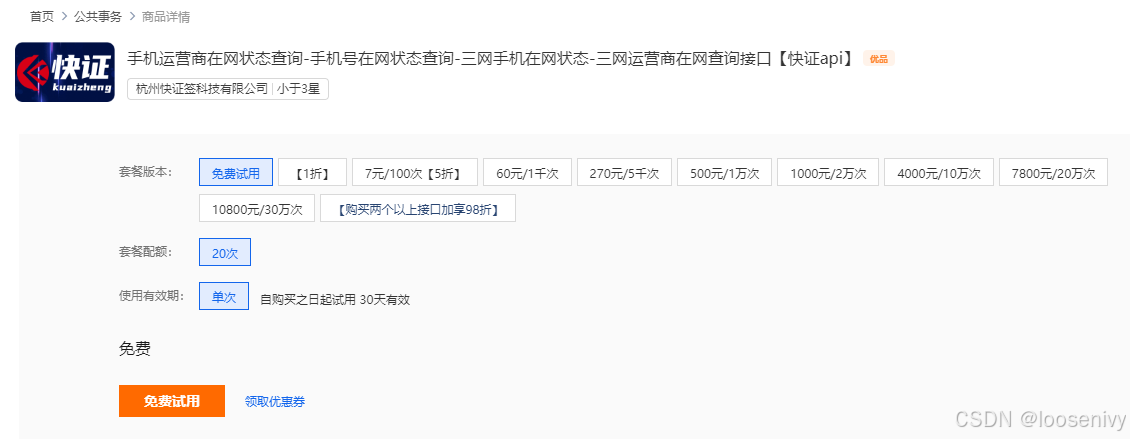
手机在网状态接口如何对接?(二)
一、什么是手机在网状态? 传入手机号码,查询该手机号的在网状态,返回内容有正常使用、停机、在网但不可用、不在网(销号/未启用/异常)、预销户等多种状态。 二、手机在网状态使用场景? 1.用户验证与联系…...

力扣-3232. 判断是否可以赢得数字游戏
给你一个 正整数 数组 nums。 Alice 和 Bob 正在玩游戏。在游戏中,Alice 可以从 nums 中选择所有个位数 或 所有两位数,剩余的数字归 Bob 所有。如果 Alice 所选数字之和 严格大于 Bob 的数字之和,则 Alice 获胜。 如果 Alice 能赢得这场游…...

Table SQL connectors以及FileSystem、JDBC connector
目录 Flink支持的连接器 如何使用连接器 FileSystem SQL Connector 文件格式 分区文件 Source 目录监控 元数据 Streaming Sink 滚动策略 文件合并 JDBC SQL Connector 依赖 如何创建JDBC表 连接器配置 案例 pom依赖 代码 测试 Flink的Table API和SQL…...
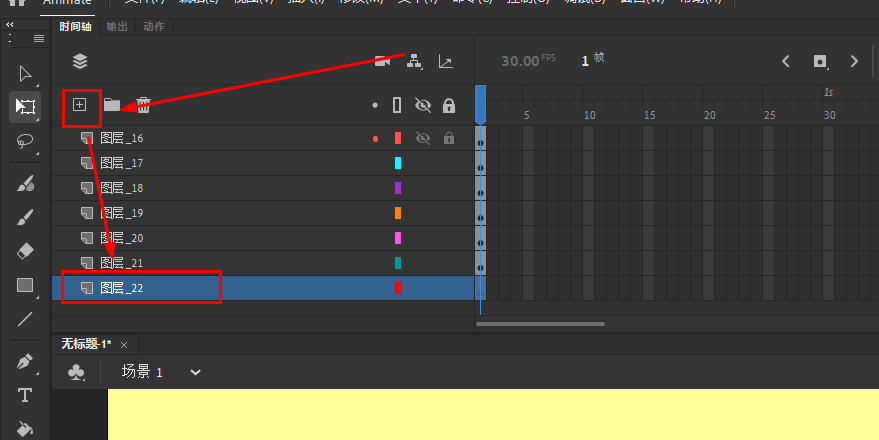
Animate软件基础:“分散到图层”创建的新图层
FlashASer:AdobeAnimate2021软件零基础入门教程https://zhuanlan.zhihu.com/p/633230084 FlashASer:实用的各种Adobe Animate软件教程https://zhuanlan.zhihu.com/p/675680471 FlashASer:Animate教程及作品源文件https://zhuanlan.zhihu.co…...

ffmpeg命令-Windows下常用最全
查询命令 参数 说明 -version 显示版本。 -formats 显示可用的格式(包括设备)。 -demuxers 显示可用的demuxers。 -muxers 显示可用的muxers。 -devices 显示可用的设备。 -codecs 显示libavcodec已知的所有编解码器。 -decoders 显示可用…...

反序列化漏洞靶机实战-serial
一.安装靶机 下载地址为https://download.vulnhub.com/serial/serial.zip,安装好后开启靶机,这里并不需要我们去登录,直接扫描虚拟机nat模式下c网段的ip,看看哪个的80端口开放,然后直接去访问 二.查找cookie 访问靶…...
医疗器械产品没有互联网连接,就不适用于网络安全要求吗?
医疗器械产品是否不适用于网络安全要求,需要考虑产品是否具有网络连接功能以进行电子数据交换或远程控制,以及是否采用储存媒介进行电子数据交换。详细解析如下: 一、医疗器械的网络安全要求不仅限于互联网连接 数据交换接口:医疗…...

可视掏耳勺安全吗?独家揭示六大风险弊病!
很多人习惯在洗漱完顺手拿一根棉签掏耳朵,但是棉签的表面直径大且粗糙,不易将耳朵深处的耳垢挖出,耳垢堆积在耳道深处长时间不清理会导致堵塞耳道,引起耳鸣甚至感染。而可视掏耳勺作为一种新型的挖耳工具,它的安全性也…...

JavaScript 变量声明var、let、const
在 JavaScript 中,var、let和const是用于声明变量的关键字。 let和const是JavaScript里相对较新的变量声明方式。 let用法类似于var,但是所声明的变量,只在let命令所在的代码块内有效。 const声明一个只读的常量。一旦声明,常量的…...

ipvlan: operation not supported 导致的POD不断重启
情况描述 接到反馈有一台虚拟机HA迁移了,需要检查一下上面业务是否正常,由于是K8S node节点,正常情况下重启会自动恢复的,不过抱着严谨的态度,上去看了一眼。 问题:发现docker运行正常,但是业…...
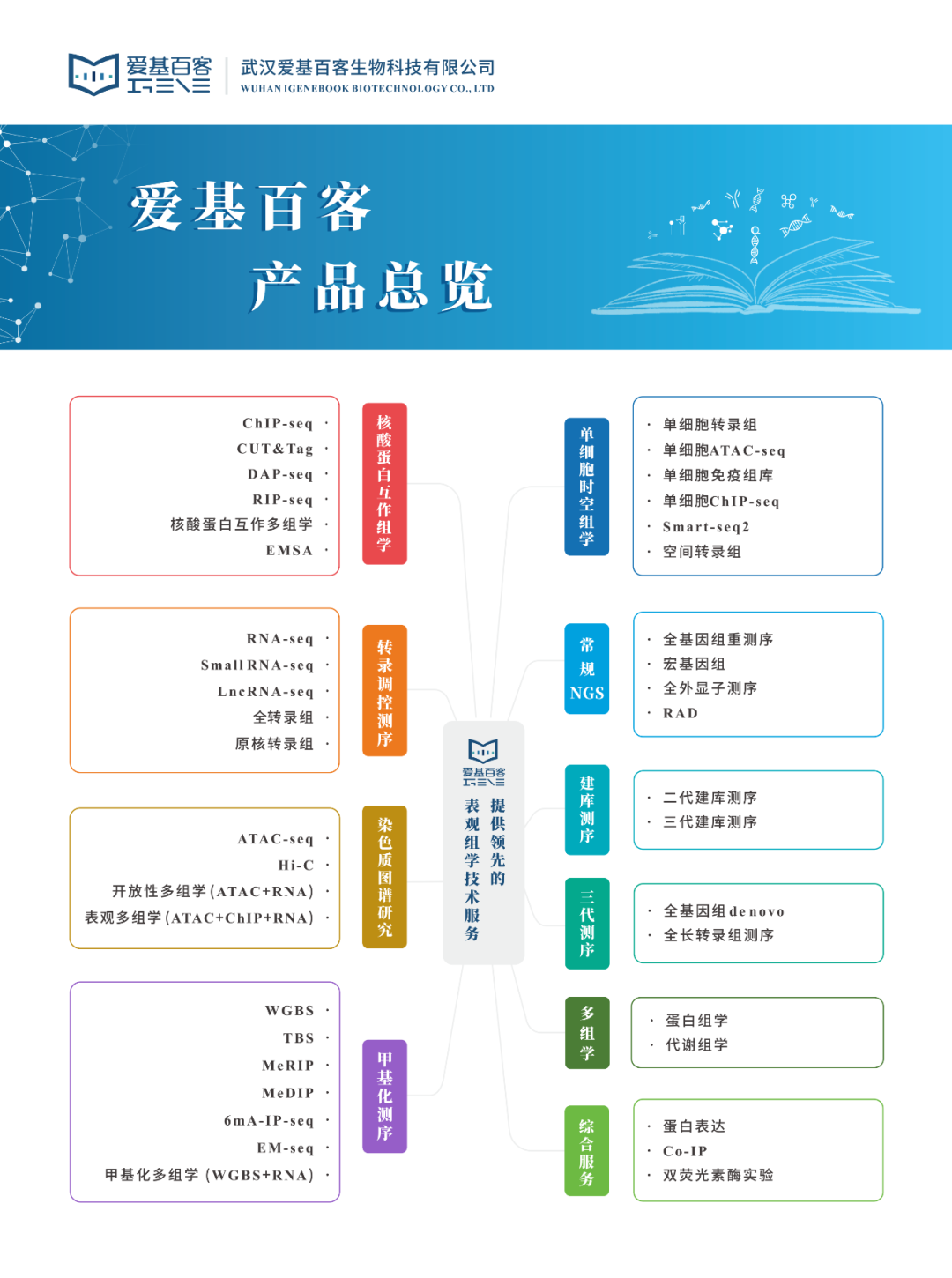
组蛋白乳酸化和RNA甲基化如何联动?请大数据把这个思路推给科研人
在细胞生物学中,基因表达调控是决定细胞功能与命运的核心过程之一。组蛋白作为修饰性蛋白,在调控基因转录中起着至关重要的作用。近年来,科学家们发现,组蛋白的多种化学修饰(如甲基化、乙酰化、磷酸化等)影…...

操作文件-Path
Java操作文件-Path Paths 参数说明 first:必选参数,表示路径的第一个组件。more:可选参数,表示路径的其他组件,可以传入多个。 创建路径对象 // 创建一个表示当前工作目录的Path对象 Path currentPath Paths.get…...

RAC(Teamcenter )开发,Bom行解包和打包的方法
1、打包 UnpackAllAction allAction new UnpackAllAction((AbstractBOMLineViewerApplication) currentApplication, "packAllAction"); new Thread(allAction).start();2、解包 UnpackCommand command new UnpackCommand(bomLine); command.executeModal();3、注…...

log4j2漏洞练习
log4j2 是Apache的一个java日志框架,我们借助它进行日志相关操作管理,然而在2021年末log4j2爆出了远程代码执行漏洞,属于严重等级的漏洞。apache log4j通过定义每一条日志信息的级别能够更加细致地控制日志生成地过程,受影响的版本…...

OpenEuler安装部署教程
目录 OpenEuler安装部署教程 MobaXterm一款全能的远程工具 yum安装软件 vim编辑器(了解) 防火墙 常用命令 网络工具netstat & telnet 进程管理工具top ps 磁盘free、fdisk 用户、组(了解) 权限(了解&am…...
Canto - hackmyvm
简介 靶机名称:Canto 难度:简单 靶场地址:https://hackmyvm.eu/machines/machine.php?vmCanto 本地环境 虚拟机:vitual box 靶场IP(Canto):192.168.130.53 windows_IP:192.1…...
【数据结构进阶】手撕红黑树
🔥个人主页: Forcible Bug Maker 🔥专栏: C || 数据结构 目录 🌈前言🔥红黑树的概念🔥手撕红黑树红黑树结点的定义红黑树主体需要实现的成员函数红黑树的插入findEmpty和Size拷贝构造析构函数和…...

【C++从小白到大牛】类和对象
目录 一、面向过程和面向对象初步认识 二、类的引入 三、类的定义 类的成员函数两种定义方式: 1. 声明和定义全部放在类体中 2. 类声明放在.h文件中,成员函数定义放在.cpp文件中 成员变量命名规则的建议: 四、类的访问限定符 【访问限…...

Kafka 为什么这么快的七大秘诀,涨知识了
我们都知道 Kafka 是基于磁盘进行存储的,但 Kafka 官方又称其具有高性能、高吞吐、低延时的特点,其吞吐量动辄几十上百万。 在座的靓仔和靓女们是不是有点困惑了,一般认为在磁盘上读写数据是会降低性能的,因为寻址会比较消耗时间。…...

OpenManus-RL:基于强化学习优化大语言模型智能体决策的完整框架
1. 项目概述与核心价值如果你正在关注大语言模型智能体领域,尤其是如何让模型从“会聊天”进化到“会做事”,那么OpenManus-RL这个项目绝对值得你投入时间研究。它不是一个简单的工具库,而是一个由UIUC-Ulab和MetaGPT团队联合发起的、以直播形…...

模型运行记录
1753...

量子信号处理技术及其在离子阱系统中的应用
1. 量子信号处理技术概述量子信号处理(Quantum Signal Processing, QSP)是近年来量子计算领域涌现的一项基础性技术,它通过精心设计的量子比特旋转序列,实现对量子数据的系统性多项式变换。这项技术的核心价值在于,它为…...

荔枝派Zero V3s新手避坑指南:从源码编译到SPI Flash烧录u-boot的完整流程
荔枝派Zero V3s开发实战:从源码编译到SPI Flash烧录的避坑手册 第一次拿到荔枝派Zero V3s开发板时,那种既兴奋又忐忑的心情至今记忆犹新。作为全志V3s芯片的经典开发平台,它凭借64MB DDR2内存、内置WiFi和丰富的外设接口,成为嵌入…...

从原理图到Vivado:手把手教你搞定XC7Z020-CLG400的EMIO引脚分配与约束
从原理图到Vivado:手把手教你搞定XC7Z020-CLG400的EMIO引脚分配与约束 在ZYNQ7000系列开发中,EMIO引脚的正确分配与约束是实现PS与PL协同工作的关键环节。许多工程师在初次接触ZYNQ架构时,往往会被MIO、EMIO和AXI_GPIO的关系所困扰ÿ…...

基于官方API的WhatsApp AI助手集成:规避封号风险与实战部署指南
1. 项目概述:为你的AI助手开通一个安全的WhatsApp专线 如果你正在使用OpenClaw构建自己的AI助手,并且希望它能通过WhatsApp与用户自然交流,那么你很可能已经研究过各种方案了。市面上常见的方案,比如基于 whatsapp-web.js 或 …...
:风险计算、工具应用)
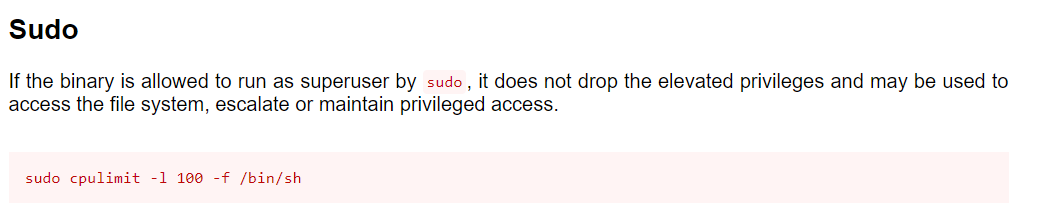
信息安全工程师-网络安全风险评估(下篇):风险计算、工具应用
一、引言风险评估是软考信息安全工程师考试中风险管理模块的核心考点,分值占比约 8%-12%,涵盖客观题、案例分析题两类题型。从技术定位来看,风险评估是连接安全需求与安全建设的核心枢纽,其输出结果直接作为安全策略制定、安全措施…...
)
从“能用”到“愿用”:Lovable Serverless平台的6大心理学设计法则(基于87家头部企业DevOps调研数据)
更多请点击: https://intelliparadigm.com 第一章:从“能用”到“愿用”:Lovable Serverless平台的认知跃迁 Serverless 并非仅关于函数执行与自动扩缩——真正的分水岭在于开发者是否**主动选择、持续信任并乐于传播**该平台。当运维负担归…...
)
Hi3559AV100 MPP开发:从IMX334到HDMI输入,VI参数配置避坑指南(含/proc/umap解析)
Hi3559AV100 MPP开发实战:非标准HDMI输入与VI参数配置深度解析 当我们需要在Hi3559AV100平台上接入HDMI视频源时,传统的MIPI摄像头配置方案往往无法直接适用。本文将从一个真实项目案例出发,详细讲解如何将原本为IMX334 MIPI摄像头设计的VI参…...

Meta发布最大视觉模型:DSG架构如何重构视觉理解范式
1. 项目概述:这不是一次普通更新,而是一次视觉理解边界的重写“Meta Just Updated the Largest Computer Vision Model in History”——这个标题乍看像科技媒体的快讯标题,但如果你在CV领域摸爬滚打过几年,第一反应不是点开链接&…...