C语言数据在内存中的存储超详解
文章目录
- 1. 整数在内存中的存储
- 2. 大小端字节序和字节序判断
- 2. 1 什么是大小端?
- 2. 2 为什么会有大小端?
- 2. 3 练习
- 3. 浮点数在内存中的存储
- 3. 1 一个代码
- 3. 2 浮点数的存储
- 3. 2. 1 浮点数存的过程
- 3. 2. 2 浮点数取的过程
- 3. 3 题目解析
1. 整数在内存中的存储
在操作符的博客中,我们就了解过了下面的内容:
- 整数的二进制表示方法有三种,即原码、反码和补码,有符号的整数,三种表示方法均有符号位和数值位两部分,符号位都是用0表示“正”,用1表 示“负”,最高位的一位是被当做符号位,剩余的都是数值位。
- 正整数的原、反、补码都相同。
负整数的三种表示方法各不相同。 - 原码:直接将数值按照正负数的形式翻译成二进制得到的就是原码
反码:将原码的符号位不变,其他位依次按位取反就可以得到反码
补码:反码+1就得到补码。
实际上对于整形来说:数据存放在内存中的是补码。
为什么呢?
在计算机系统中,数值一律用补码来表示和存储。
原因在于,使用补码,可以将符号位和数值域统一处理。
同时,加法和减法也可以统一处理(CPU只有加法器)此外,补码与原码相互转换,其运算过程是
相同的,不需要额外的硬件电路。
关于 其运算过程是相同的 这一点:正整数不必赘述,负数的补码是原码取反+1,如果要从补码得到原码的操作应该是-1再取反,但实际上由于是二进制,取反+1也能得到原码,因此说补码和反码的转换是相同的。
2. 大小端字节序和字节序判断
在了解了数据整数在内存中的存储之后,我们通过调试来看一个细节:
来看这个代码:
#include<stdio.h>
int main()
{int a = 0x11223344;return 0;
}
这里给int 变量a赋值了八进制的 11223344,那它在内存中是这么存储的吗?我们来看一看:

调试的时候,我们可以看到在a中的 0x11223344 这个数字是按照字节为单位,倒着存储的。这是为什么呢?
2. 1 什么是大小端?
其实超过一个字节的数据在内存中存储的时候,就有存储顺序的问题,按照不同的存储顺序,我们分为大端字节序存储和小端字节序存储,下面是具体的概念:
大端(存储)模式:
是指数据的低位字节内容保存在内存的高地址处,而数据的高位字节内容,保存在内存的低地址处。
小端(存储)模式:
是指数据的低位字节内容保存在内存的低地址处,而数据的高位字节内容,保存在内存的高地址处。
也就是说:倒着存储的,就是小端字节序。
2. 2 为什么会有大小端?
为什么会有大小端模式之分呢?
这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8bit 位,但是在C语言中除了8bit的 char 之外,还有16bit的 short 型,32bit的 long 型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。
例如:-个 16bit 的 short型x,在内存中的地址为 0x0010 ,x的值为 0x1122 ,那么0x11 为高字节,0x22 为低字节。对于大端模式,就将 0x11 放在低地址即 0x0010 中,0x22 放在高地址即 0x0011 中。小端模式则刚好相反。我们常用的 X86 结构是小端模式,而KEIL C51 则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
2. 3 练习
练习一
请简述大端字节序和小端字节序的概念,设计个小程序来判断当前机器的字节序。(10分)-百度笔试题
怎么来判断当前机器的字节序呢?既然是程序,那当然不能通过调试来看。
我们可以想一想 int 类型和 char 类型来判断:
#include<stdio.h>int check()
{int a = 1;return *(char*)&a;
}int main()
{if (check())printf("小端");elseprintf("大端");return 0;
}
下面我们来分析一下这个 check 程序的原理:
如果说机器是小端存储的,那么它在内存中就是:
01 00 00 00
而 &a 得到的是 a 的这4个字节的第一个字节的地址,也就是 01 这个字节,将其强制类型转换为 char* 再解引用,得到的就是 1。
如果是小段字节序,得到的就是0。
那么除了用这样的办法以外,我们还可以使用联合体这一自定义结构:
#include<stdio.h>int check()
{union c{int a;char b;}tmp;tmp.a = 1;return tmp.b;
}int main()
{if (check())printf("小端");elseprintf("大端");return 0;
}
这里简要介绍一下联合体,它和结构体一样都是C语言提供的自定义类型,创建与使用都十分地相似,不同之处在于:联合体中的每一个变量都是存储在同一个地址中的。也就是说,上面这个联合体的 a 变量有4个字节,而另一个 变量 b 就是 a 的第一个字节,那么新的 check 函数和上面的 check 函数的原理和结果都是相同的。
练习二
#include <stdio.h>
int main()
{char a = -1;signed char b = -1;unsigned char c = -1;printf("a=%d,b=%d,c=%d", a, b, c);return 0;
}
输出结果为?
首先,我们先要知道 char 类型是有符号还是无符号的?事实上这取决于编译器,但大多数的编译器,包括VS2022 ,char == signed char。
我们继续分析:
-1的补码很容易算,是
11111111111111111111111111111111
那么在将其赋值给不同的 char 类型变量时,会把内存中的第一个字节的内容,也就是
11111111
赋值过去,所以a,b,c三个变量存储的都是这个。
当 a 在打印时,使用了%d占位符要发生整形提升,而且a是有符号的类型,发生整形提升时,高位补原来的最高位,也就是1:
11111111111111111111111111111111
再进行打印,就是-1。
b与a同理。
我们再来看c,c是无符号类型,发生整形提升时,高位补0,得到的就是:
00000000000000000000000011111111
再进行打印,就是255。
所以这个代码的运行结果是:

练习三
//代码一
#include <stdio.h>
int main()
{char a = -128;printf("%u\n", a);return 0;
}
//代码二
#include <stdio.h>
int main()
{char a = 128;printf("%u\n", a);return 0;
}
这两段代码的输出结果分别是什么?
代码一:
-128的反码是
11111111111111111111111110000000
那么放入a的就是
10000000
%u是unsigned int ,所以要发生整形提升。a是有符号的,高位补1,就是
11111111111111111111111110000000
那么代码一的结果就是将这个数以无符号的形式打印出来。
也就是:

代码二:
128的反码和原码相同,也就是:
00000000000000000000000010000000
那么放入 a 的就是
10000000
再进行整形提升,就是:
11111111111111111111111110000000
把这个数按照 %u 的格式打印出来就是结果了:

练习四
#include <stdio.h>
int main()
{char a[1000];int i;for (i = 0; i < 1000; i++){a[i] = -1 - i;}printf("%d", strlen(a));return 0;
}
提示:'\0'的ASCII码值为0。
要计算出哪一个位置会得到0,我们先要算出如果a[i]是 0 ,等号右边应该是什么样的数:
a[i]是char变量,取的是-1-i在内存中的的最后一个字节的内容,很显然 -1-i 恒为负数,那么最后一个字节的内容如果是:00000000,那么在原码中,最后一个字节的内容应该是:00000000,最大的满足这个的原码是:10000000000000000000000100000000,也就是-256,那么此时的i就是255,所以a的长度应该是255.

练习五:
//代码一
#include <stdio.h>
unsigned char i = 0;
int main()
{for (i = 0; i <= 255; i++){printf("hello world\n");}return 0;
}
//代码二
#include <stdio.h>
int main()
{unsigned int i;for (i = 9; i >= 0; i--){printf("%u\n", i);}return 0;
}
代码一
i<=255是恒成立的,为什么?
unsigned char 类型的最大值是255,如果此时再+1,就会变成多少呢?
我们通过一个代码来测试:
#include<stdio.h>
int main()
{unsigned char a = 255;a++;printf("%d", a);return 0;
}

可以看到,此时a又变成了 unsigned char 的最小值0。
那么上面的循环就是一个死循环,会不停地打印hello world。

代码二
unsigned int 的取值范围最小为0,再-1会变成什么呢?
我们还是通过一个代码来分析:
#include<stdio.h>
int main()
{unsigned int a = 0;a--;printf("%u", a);//注意使用 %u 占位符return 0;
}

可以看到,a变成了 unsigned int 的最大值,所以上面的循环也是一个死循环,会不停地打印 i 的值。

练习六
#include <stdio.h>
//X86环境 小端字节序
int main()
{int a[4] = { 1, 2, 3, 4 };int* ptr1 = (int*)(&a + 1);int* ptr2 = (int*)((int)a + 1);printf("%x,%x", ptr1[-1], *ptr2);return 0;
}
关于ptr1,在指针系列中我已经讲解过,这里只做简要说明,不明白可以看我的指针系列文章,&a+1跳过整个数组,再强制类型转换为int*,ptr1[-1]就是取ptr1 的上一个数字,也就是 4,按照16进制打印,还是4.
我们重点来看 ptr2,首先将 a强制类型转换为int,这里a是指数组的首元素的地址,假设是0x00115511,再+1得到0x00115512,再强制类型转换为int*,也就是相对原来的位置,向后走了一个字节,那么此时ptr2是多少?
我们画图来分析:

那么此时的ptr2就是0x02000000。
3. 浮点数在内存中的存储
浮点数表示的范围:float.h中定义
常见的浮点数:3.14159、1E10等,浮点数家族包括: float、double、long double 类型。
3. 1 一个代码
#include <stdio.h>
int main()
{int n = 9;float* pFloat = (float*)&n;printf("n的值为:%d\n", n);printf("*pFloat的值为:%f\n", *pFloat);*pFloat = 9.0;printf("num的值为:%d\n", n);printf("*pFloat的值为:%f\n", *pFloat);return 0;
}
输出结果为:

上面的代码中, num 和 *pFloat 在内存中明明是同一个数,为什么浮点数和整数的解读结果会差别
这么大?
3. 2 浮点数的存储
要理解这个结果,一定要搞懂浮点数在计算机内部的表示方法。
根据国际标准IEEE(电气和电子工程协会)754,任意一个二进制浮点数V可以表示成下面的形式:
V = (−1) S * M ∗ 2E
其中:
(−1) S 表示符号位,当S=0,V为正数;当S=1,V为负数
M 表示有效数字,M是大于等于1,小于2的
2E 表示指数位
举例来说:
十进制的5.0,写成二进制是 101.0 ,相当于 1.01x2^2。
那么,按照上面V的格式,可以得出S=0,M=1.01,E=2。
十进制的 -5.0,写成二进制是-101.0,相当于-1.01x22。那么,S=1,M=1.01,E=2。
IEEE 754规定:
对于32位的浮点数,最高的1位存储符号位S,接着的8位存储指数E,剩下的23位存储有效数字M
对于64位的浮点数,最高的1位存储符号位S,接着的11位存储指数E,剩下的52位存储有效数字M
float:

double:

3. 2. 1 浮点数存的过程
IEEE754 对有效数字M和指数E,还有一些特别规定。
前面说过,1 ≤ M < 2 ,也就是说,M可以写成1.xxxxxx 的形式,其中 xxxxxx 表示小数部分。
IEEE 754 规定,在计算机内部保存M时,默认这个数的第一位总是1,因此可以被舍去,只保存后面的xxxxxx部分。比如保存1.01的时候,只保存01,等到读取的时候,再把第一位的1加上去。这样做的目的,是节省1位有效数字。以32位浮点数为例,留给M只有23位,将第一位的1舍去以后,等于可以保存24位有效数字。
至于指数E,情况就比较复杂
首先,E为一个无符号整数(unsigned int)
这意味着,如果E为8位,它的取借范围为0 ~ 255;如果E为11位,它的取值范围为0 ~ 2047。
但是,我们知道,科学计数法中的E是可以出现负数的,所以IEEE754规定,存入内存时E的真实值必须再加上一个中间数,对于8位的E,这个中间数是127;对于11位的E,这个中间数是1023。比如,2^10的E是10,所以保存成32位浮点数时,必须保存成10+127=137,即10001001。
3. 2. 2 浮点数取的过程
指数E从内存中取出还可以再分成三种情况:
E不全为0或不全为1
这时,浮点数就采用下面的规则表示,即指数E的计算值减去127(或1023),得到真实值,再将有效
数字M前加上第一位的1。
比如:0.5 的二进制形式为0.1,由于规定正数部分必须为1,即将小数点右移1位,则为1.0*2^(-1),其阶码为-1+127(中间值)=126,表示为01111110,而尾数1.0去掉整数部分为0,补齐0到23位00000000000000000000000,则其二进制表示形式为:
0 01111110 00000000000000000000000
E全为0
这时,浮点数的指数E等于1-127(或者1-1023)即为真实值,有效数字M不再加上第一位的1,而是还
原为0.xxxxxx的小数。这样做是为了表示±0,以及接近于0的很小的数字。
E全为1
这时,如果有效数字M全为0,表示±无穷大(正负取决于符号位s)
3. 3 题目解析
先看第1环节,为什么 9 还原成浮点数,就成了 0.000000 ?
9 以整型的形式存储在内存中,得到如下二进制序列:
0000 0000 0000 0000 0000 0000 0000 1001
首先,将 9的二进制序列按照浮点数的形式拆分,得到第一位符号位s=0,后面8位的指数
E=00000000,最后23位的有效数字M=000 0000 0000 0000 00001001。
由于指数E全为0,所以符合E为全0的情况。因此,浮点数V就写成:
V=(-1)^0 x 0.00000000000000000001001x2^(-126)=1.001x2^(-146)
显然,V是一个很小的接近于0的正数,所以用十进制小数表示就是0.000000。
再看第2环节,浮点数9.0,为什么整数打印是1091567616
首先,浮点数9.0等于二进制的1001.0,即换算成科学计数法是:1.001x2^3
所以:9.0 = (-1)0*(1.001)*23
那么,第一位的符号位S=0,有效数字M等于001后面再加20个0,凑满23位,指数E等于3+127=130,
即10000010
所以,写成二进制形式,应该是S+E+M,即
0 10000010 001 0000 0000 0000 0000 0000
这个32位的二进制数,被当做整数来解析的时候,就是整数在内存中的补码,原码正是
1091567616。
谢谢你的阅读,喜欢的话来个点赞收藏评论关注吧!
相关文章:
C语言数据在内存中的存储超详解
文章目录 1. 整数在内存中的存储2. 大小端字节序和字节序判断2. 1 什么是大小端?2. 2 为什么会有大小端?2. 3 练习 3. 浮点数在内存中的存储3. 1 一个代码3. 2 浮点数的存储3. 2. 1 浮点数存的过程3. 2. 2 浮点数取的过程3. 3 题目解析 1. 整数在内存中的…...

【大模型】【NL2SQL】基本原理
三个输入: prompt 用户输入 数据库表格等信息 sql 语句...
DRM vop驱动程序分析)
RK3568平台(显示篇)DRM vop驱动程序分析
一.设备树配置 vopb: vopff900000 {compatible "rockchip,rk3399-vop-big";reg <0x0 0xff900000 0x0 0x2000>, <0x0 0xff902000 0x0 0x1000>;interrupts <GIC_SPI 118 IRQ_TYPE_LEVEL_HIGH 0>;assigned-clocks <&cru ACLK_VOP0>, &…...

vue3 动态加载组件
//模版调用 <component :is"geticon(item.icon)" />//引入 import { ref, onMounted, markRaw, defineAsyncComponent } from vue;//异步添加icon图标组建 function geticon(params) {const modules import.meta.glob(../components/icons/*.vue);const link …...

Latex on overleaf入门语法
Latex on overleaf入门语法 前言基本结构序言 简单的格式化命令添加注释:%加粗、斜体、下划线有序列表、无序列表 添加图片图片的标题、标签和引用 添加表格一个简单的表格为表格添加边框标题、标签、引用 数学表达式基本的数学命令 基本格式摘要段落、新行章节、分…...

使用Echarts来实现数据可视化
目录 一.什么是ECharts? 二.如何使用Springboot来从后端给Echarts返回响应的数据? eg:折线图: ①Controller层: ②service层: 一.什么是ECharts? ECharts是一款基于JavaScript的数据可视化图标库,提供直观&…...

一文搞懂GIT
文章目录 1. GiT概述1.1 GIT概述1.2 GIT安装 2. GIT组成3. GIT基本命令3.1 基本命令3.2 分支操作3.3 远程操作3.4 标签操作3.5 其他命令 1. GiT概述 1.1 GIT概述 Git 是一个分布式版本控制系统,被广泛应用于软件开发中。 Git 具有众多优点,比如&#…...
案例)
jQuery入门(四)案例
jQuery 操作入门案例 一、复选框案例 功能: 列表的全选,反选,全不选功能实现。 实现步骤和分析: - 全选 1. 为全选按钮绑定单击事件。 2. 获取所有的商品项复选框元素,为其添加 checked 属性,属性值为 true。 -…...

揭秘MITM攻击:原理、手法与防范措施
中间人攻击发生时,攻击者会在通讯两端之间插入自己,成为通信链路的一部分。攻击者可以拦截、查看、修改甚至重新定向受害者之间的通信数据,而不被双方察觉。这种攻击常见于未加密的Wi-Fi网络、不安全的HTTP连接或者通过社会工程学手段诱导受害…...

【YOLOv8】一文全解+亮点介绍+训练教程+独家魔改优化技巧
前言 Hello,大家好,我是cv君,最近开始在空闲之余,经常更新文章啦!除目标检测、分类、分隔、姿态估计等任务外,还会涵盖图像增强领域,如超分辨率、画质增强、降噪、夜视增强、去雾去雨、ISP、海…...
)
创建mvp ubo(uniform buffer object)
创建过程: 创建一个uniform buffer查找buffer memory requirements分配、绑定buffer memorymap buffer memory拷贝mvp data to buffer memoryunmap buffer memory 示例代码: glm::mat4 projection glm::perspective(glm::radians(45.0f), 1.0f, 0.1f…...

1.GPIO
理论说明 输入 上拉输入:拉高电平 下拉输入:拉低电平 浮空输入:不拉高也不拉低电平 输出 开漏输出:不能输出高电平(P-MOS不可用,则只能低电平) 推挽输出:可输出高低电平 输出速率…...
C++必修:STL之vector的了解与使用
✨✨ 欢迎大家来到贝蒂大讲堂✨✨ 🎈🎈养成好习惯,先赞后看哦~🎈🎈 所属专栏:C学习 贝蒂的主页:Betty’s blog 1. C/C中的数组 1.1. C语言中的数组 在 C 语言中,数组是一组相同类型…...

【MySQL】索引 【上】 {没有索引的查询/磁盘/mysql与磁盘IO/初识索引}
文章目录 1.没有索引存在的问题2. 认识磁盘MySQL与存储MySQL与磁盘交互基本单位建立共识图解IO认识索引 在关系数据库中,索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合和相应的指向表中物…...
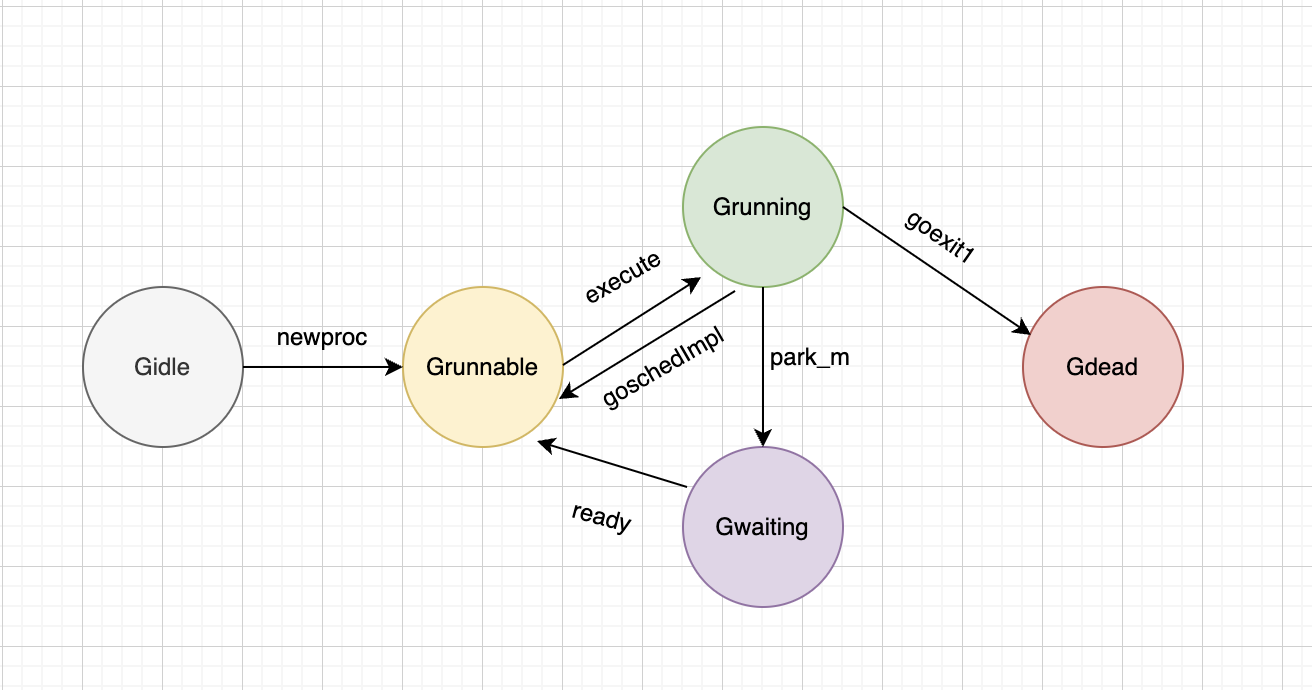
GO goroutine状态流转
Gidle -> Grunnable newproc获取新的goroutine,并放置到P运行队列中 这也是go关键字之后实际编译调用的方法 func newproc(fn *funcval) {// 获取当前正在运行中的goroutinegp : getg()// 获取调用者的程序计数器地址,用于调试和跟踪pc : getcallerp…...
)
DLMS/COSEM中的信息安全:DLMS/COSEM安全概念(上)
DLMS/COSEM中的信息安全描述并规定: ——DLMS/COSEM安全概念; ——选择加密算法; ——安全密钥; ——使用加密算法进行实体认证、xDLMS APDU保护和COSEM数据保护。 1.综述 DLMS/COSEM服务器的资源(COSEM对象属性和方法)可以由在应用连接内的DLMS/COSEM客户机访问。 在AA…...

C语言第九天笔记
数组的概念 什 么是数组 数组是 相同类型, 有序数据的集合。 数 组的特征 数组中的数据被称为数组的 元素,是同构的 数组中的元素存放在内存空间里 (char player_name[6]:申请在内存中开辟6块连续的基于char类 型的变量空间) 衍生概念&…...
智慧环卫可视化:科技赋能城市清洁管理
图扑智慧环卫可视化通过实时监控、数据分析和智能调度,提高环卫作业效率,优化资源配置,提升城市清洁水平,实现城市管理的精细化和现代化。...

【力扣】SQL题库练习5
高级查询和连接 1341.电影评分 表:Movies ------------------------ | Column Name | Type | ------------------------ | movie_id | int | | title | varchar | ------------------------ movie_id 是这个表的主键(具有唯一值的列)。 ti…...

永结无间Ⅸ--你不需要LLM Agent
人们将目光锁定在下一个闪亮的事物上。FOMO 是人性的一部分。这也适用于企业。就像数据科学成为每个企业分析功能的热潮一样,Agentic Architecture 是大多数 AI 雷达上的热门目标。 但您是否考虑过您是否真的需要它? 实际情况是,您不需要 A…...

这家头部智能家居品牌是如何让全渠道电商闭环运营落地?
在电商渠道愈发多元的当下,让很多企业陷入 “数据多却用不好” 的困境。这不是个别现象,而是绝大多数全渠道电商企业正在经历的“成长烦恼”。今天,我们用一个真实案例,带您看看如何用一套系统,彻底告别这些噩梦。这家…...

慕尼黑电子展:洞察汽车电子、工业物联网与功率半导体技术趋势
1. 从慕尼黑看全球电子产业:一场技术与商业的“双向奔赴”又到了双数年的十一月,全球电子工程师和产业领袖的目光,不约而同地再次聚焦于德国慕尼黑。没错,Electronica——这个被誉为全球电子元器件行业“晴雨表”的顶级盛会&#…...

淘宝商品详情 API 实现标题 / SKU / 主图批量采集
item_get_pro-获得淘宝商品详情高级版请求示例-- 请求示例 url 默认请求参数已经URL编码处理 curl -i "https://api-服务器.cn/taobao/item_get_pro/?key<您自己的apiKey>&secret<您自己的apiSecret>&num_iid678121631641"响应示例"num_ii…...

收藏!小白程序员必备:2026年AI大模型就业新机遇与学习路线指南
根据世界经济论坛报告,到2030年科技、数据、AI等领域将创造1.7亿工作机会,同时淘汰9200万个岗位。AI市场规模预计到2034年达36804.7亿美元,年复合增长率19.20%。中国AI人才需求将远超供应。文章介绍了AI运营/AIGC内容创作者、算法工程师、大模…...

泰拉瑞亚整合包下载灾厄大杂烩整合包2026最新版下载
1. 游戏基础介绍 《泰拉瑞亚》是一款经典的二维像素风格沙盒冒险游戏。游戏拥有极高的自由度,玩家可以自由探索地图、收集资源、建造房屋、打造装备、挑战BOSS。凭借自由开放的玩法、丰富的道具体系和独特的冒险氛围,这款游戏长久以来备受玩家喜爱。原版…...
让你的直播码率稳如老狗)
告别I帧卡顿!用H.264帧内刷新(Intra Refresh)让你的直播码率稳如老狗
告别I帧卡顿!用H.264帧内刷新(Intra Refresh)让你的直播码率稳如老狗 直播技术发展到今天,画面流畅度已经成为用户体验的核心指标之一。但许多开发者在实际推流中常遇到一个棘手问题:明明网络带宽充足,却在…...

如何解决QQ音乐下载的歌曲在其他设备上无法播放的问题
如何解决QQ音乐下载的歌曲在其他设备上无法播放的问题 【免费下载链接】qmcflac2mp3 直接将qmcflac文件转换成mp3文件,突破QQ音乐的格式限制 项目地址: https://gitcode.com/gh_mirrors/qm/qmcflac2mp3 你是否曾经在QQ音乐下载了喜欢的歌曲,却发现…...

AI代理技术如何赋能新生儿护理:从数据记录到个性化模式学习
1. 项目概述:当AI成为新手父母的“第二大脑”孩子出生的头三个月,被无数过来人称为“生存模式”。这不是夸张。在那些昼夜颠倒、睡眠被切割成碎片、大脑因极度疲惫而停摆的日子里,新手父母面对的不仅仅是新生儿的啼哭,更是一场信息…...

BG3ModManager:博德之门3模组管理终极指南,告别模组冲突烦恼![特殊字符]
BG3ModManager:博德之门3模组管理终极指南,告别模组冲突烦恼!🚀 【免费下载链接】BG3ModManager A mod manager for Baldurs Gate 3. This is the only official source! 项目地址: https://gitcode.com/gh_mirrors/bg/BG3ModMa…...

终极魔兽争霸3优化指南:5分钟让你的经典游戏焕发新生
终极魔兽争霸3优化指南:5分钟让你的经典游戏焕发新生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还在为《魔兽争霸3》的老旧限制…...