随机森林的算法
1、随机森林算法简介
随机森林算法(Random Forests)是LeoBreiman于2001年提出的,它是一种通过重采样办法从原始训练样本集中有放回地重复随机抽取若干个样本生成多个决策树,样本的最终预测值由这些决策树的结果投票决定的一种有监督集成学习模型。
其核心思想是通过随机的样本抽样和特征抽样生成众多决策树,形成一片“森林”,以多数的表决结果作为预测值。
随机森林作为一种bagging集成学习,在决策树算法中有着重要的地位。
2、随机森林算法基本原理
2.1 样本的选择
随机森林的样本采样选择可以看作是行采样。随机森林每棵在构建过程中,这棵树的样本从总样本中随机抽样生成。完成抽样后将样本放回,以便下一棵树的抽样。假设总样本有N个,随机森林每棵树的随机抽样样本数为n,一般可取n为N的平方根。
2.2 特征的选择
随机森林的特征采样可以看作是列采样。每棵树都是从总体M个特征中随机选择m特征进行树的生成。列采样有两种形式,一种是全局列采样,即同一棵树的生成过程中均采用同一批特征;另一种是局部列采样,即每一次节点分裂的时候都单独随机挑选m个特征进行分裂。
2.3 分裂准则
在树的生成过程中,采用的分裂准则。在随机森林算法中,可以有多种分裂准则。在随机森林的分类算法中,比较常见的有信息增益、基尼不纯度;在随机森林的回归算法中,比较常见的有均方误差。
3、随机森林算法步骤
3.1 输入输出
(1)输入:给定训练样本;参数设置:森林里树的数量、分裂的准则、分裂终止条件等。
(2)输出:样本的分类或回归值。
3.2 算法步骤
(1)从训练样本N个中随机有放回地选择n个;
(2)从特征中随机不放回地选择k个特征;
(3)根据指定的分裂准则进行分裂,生成一棵决策树;叶子节点的输出值:当为分类问题时,叶子的取值为分类最多的值;当为回归问题时,叶子节点的取值为该节点所有样本的平均值;
(4)当森林中树的数量小于指定值时,继续步骤(1)到(3),最终成生指定数量的决策树;
(5)预测时,样本在每棵决策树下会有一个对应叶子的值。当为分类问题时,最终取值为所有树下该叶子值的数量最多的值(分类);当为回归问题时,最终取值为所有树下叶子值的平均值。
4、随机森林算法实例
这里以用scikit-learn自带的数据集进行演示。
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score#加载数据集
X, y = make_classification(n_samples=1000, n_features=4,n_informative=2, n_redundant=0,random_state=0, shuffle=False)
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)#模型训练
clf = RandomForestClassifier(max_depth=2, random_state=0)
clf.fit(X_train,y_train)# 预测测试集
y_pred = clf.predict(X_test)# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print("Model accuracy: %.2f"%accuracy)Model accuracy: 0.94
5、随机森林算法总结
(1)随机森林算法具有很高的准确性和鲁棒性。随机森林算法由众多决策树共同投票决策,其结果具有较好的准确性和鲁棒性。
(2)随机森林算法可以很好地防止过拟合。随机森林每棵树的训练都是在小部分样本及特征上训练而成,可以很好地防止过拟合。
(3)随机森林算法可以并行构建决策树,提高运算效率。
(4)随机森林算法可以很好地处理高维度数据。
(5)随机森林算法在小样本上的表现可能会不佳。
相关文章:

随机森林的算法
1、随机森林算法简介 随机森林算法(Random Forests)是LeoBreiman于2001年提出的,它是一种通过重采样办法从原始训练样本集中有放回地重复随机抽取若干个样本生成多个决策树,样本的最终预测值由这些决策树的结果投票决定的一种有监督集成学习模型。 其核…...

3.1、数据结构-线性表
数据结构 数据结构线性结构线性表顺序存储和链式存储区别单链表的插入和删除练习题 栈和队列练习题 串(了解) 数据结构 数据结构该章节非常重要,上午每年都会考10-12分选择题下午一个大题 什么叫数据结构?我们首先来理解一下什…...

记一次对HTB:Carpediem的渗透测试
信息收集 端口扫描 通过nmap对靶机端口进行探测,发现存在22和80端口。 访问web页面。发现是一个静态页面,没有可利用的部分。 目录扫描 子域枚举 通过对域名进行fuzz子域名,发现存在portal一级域名。 将它加入/etc/hosts,访问之…...

MATH2 数据集:AI辅助生成高挑战性的数学题目
随着大型语言模型(LLMs)在理解和生成复杂数学内容方面的能力显著提高,通过利用所有公开数据以及相当一部分私有数据,已经取得了进展。然而,高质量、多样化和具有挑战性的数学问题来源正在逐渐枯竭。即使是寻找新的评估…...

加密货币“蓄势待发”!美国松口降息!九月开始连续降息8次?2025年利率目标3.25-3.5%?
今晨,美国联准会(Fed)结束FOMC会议,一如市场预期第八度冻涨利率在5.25%-5.5%。不过主席鲍威尔(Jerome Powell)在会后的记者会访出鸽派讯号,暗示9月降息脚步将近。这一消息令金融市场顿时沸腾,美股全面大涨&…...

Vue.js 3.x 必修课|005|代码规范与 ESLint 入门
欢迎关注公众号:CodeFit 创作不易,如果你觉得这篇文章对您有帮助,请不要忘了 点赞、分享 和 关注,为我的 持续创作 提供 动力! 1. 代码规范的重要性 在现代软件开发中,代码规范扮演着至关重要的角色。 特别是在团队协作的环境中,统一的代码风格可以大大提高工作效率和…...

【Linux】动态库|静态库|创建使用|动态库加载过程
目录 编辑 前言 静态库 为什么要使用库(形成原理 ) 生成一个静态库 静态库的使用 动态库 生成一个动态库 动态库的使用 解决方法 动态库加载过程 编辑 前言 库(Library)是一种方式,可以将代码打包成可重用的格式(站…...

WebSocket 协议与 HTTP 协议、定时轮询技术、长轮询技术
目录 1 为什么需要 WebSocket?2 WebSocket2.1 采用 TCP 全双工2.2 建立 WebSocket 连接2.3 WebSocket 帧 3 WebSocket 解决的问题3.1 HTTP 存在的问题3.2 Ajax 轮询存在的问题3.3 长轮询存在的问题3.4 WebSocket 的改进 参考资料: 为什么有 h…...

二叉树节点问题
问题:设一棵二叉树中有3个叶子结点,有8个度为1的结点,则该二叉树中总的结点数为( 13)个 设某种二叉树有如下特点:每个结点要么是叶子结点,要么有2棵子树。假如一棵这样的二叉树中有m(m>0&…...

公司里的IT是什么?
公司里的IT是什么? 文章目录 公司里的IT是什么?1、公司里的IT2、IT技术3、IT行业4、IT行业常见证书 如果对你有帮助,就点赞收藏把!(。・ω・。)ノ♡ 前段时间,在公…...
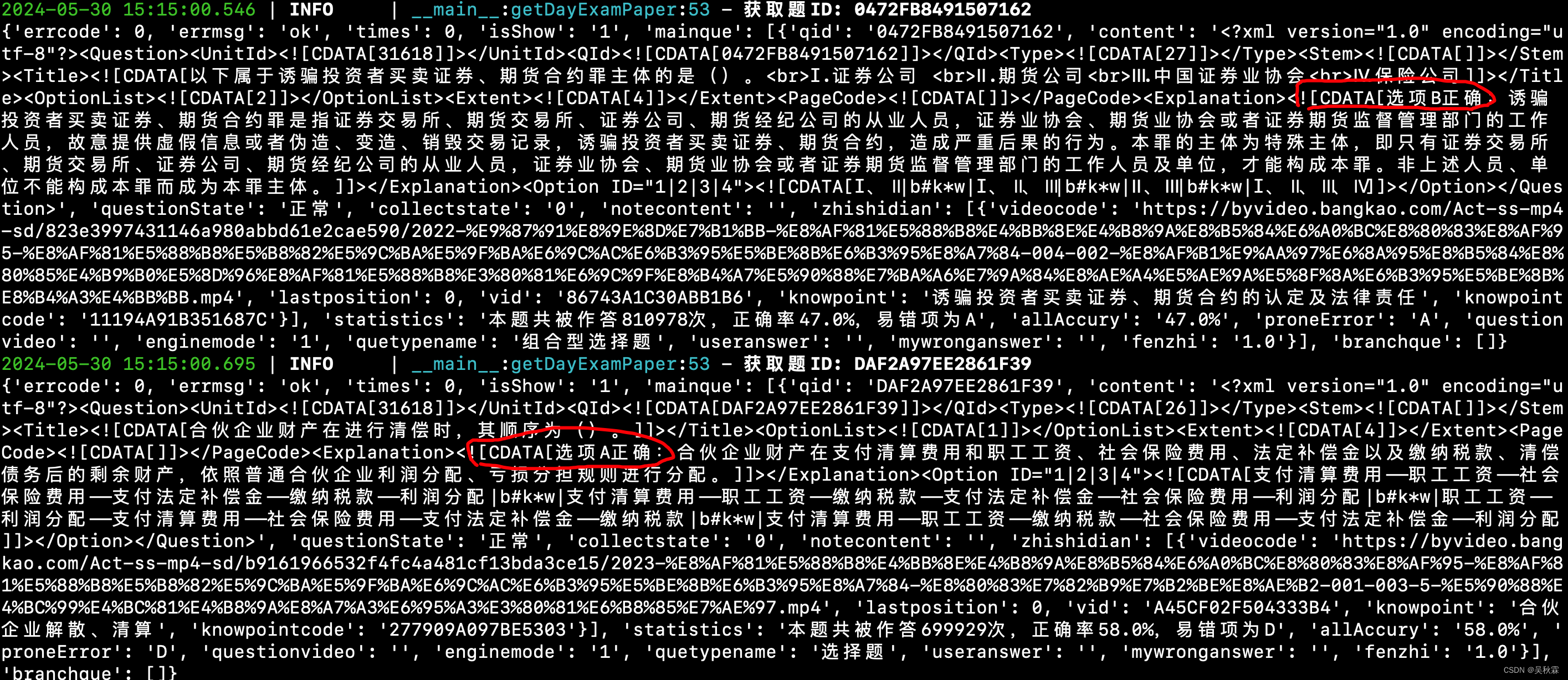
【小程序爬虫入门实战】使用Python爬取易题库
文章目录 1. 写在前面2. 抓包分析 【🏠作者主页】:吴秋霖 【💼作者介绍】:擅长爬虫与JS加密逆向分析!Python领域优质创作者、CSDN博客专家、阿里云博客专家、华为云享专家。一路走来长期坚守并致力于Python与爬虫领域研…...

案例 —— 怪物出水
一,Ocean Setup 设置海洋Surface Grid(使用Large Ocean工具架) 调节默认Grid的大小尺寸及细分(使用非常小尺寸来测试);调整频谱输入点的多少,频谱Grid Size,波浪方向,速度…...

vue中使用print.js实现页面打印并增加水印
1.安装print.js npm install print-js --save2.在main.js文件中引入并注册(我使用的是print.js的源码文件,并且做了一修改) //引入 import Print from ./utils/print//注册 Vue.use(Print); //注册3.在页面中使用 <template> <div class&quo…...

计算机基础(Windows 10+Office 2016)教程 —— 第5章 文档编辑软件Word 2016(下)
文档编辑软件Word 2016 5.4 Word 2016的表格应用5.4.1 创建表格5.4.2 编辑表格5.4.3 设置表格 5.5 Word 2016的图文混排5.5.1 文本框操作5.5.2 图片操作5.5.3 形状操作5.5.4 艺术字操作 5.6 Word 2016的页面格式设置5.6.1 设置纸张大小、页面方向和页边距5.6.2 设置页眉、页脚和…...

简单洗牌算法
🎉欢迎大家收看,请多多支持🌹 🥰关注小哇,和我一起成长🚀个人主页🚀 ⭐目前主更 专栏Java ⭐数据结构 ⭐已更专栏有C语言、计算机网络⭐ 在学习了ArrayList之后,我们可以通过写一个洗…...

JVM: 堆上的数据存储
文章目录 一、对象在堆中的内存布局1、对象在堆中的内存布局 - 标记字段2、JOL打印内存布局 二、元数据指针 一、对象在堆中的内存布局 对象在堆中的内存布局,指的是对象在堆中存放时的各个组成部分,主要分为以下几个部分: 1、对象在堆中的…...

AI产品经理的职责与能力:将AI技术转化为实际价值
一、AI产品经理的职责 发现和解决问题:AI产品经理需要具备敏锐的洞察力,能够发现用户需求和痛点,并提出相应的解决方案。传递价值给用户:AI产品经理需要确保产品能够满足用户的需求,提供价值,并提升用户体…...

【独家原创RIME-CNN-LSSVM】基于霜冰优化算法优化卷积神经网络(CNN)结合最小二乘向量机(LSSVM)的数据回归预测
【独家原创RIME-CNN-LSSVM】基于霜冰优化算法优化卷积神经网络(CNN)结合最小二乘向量机(LSSVM)的数据回归预测 目录 【独家原创RIME-CNN-LSSVM】基于霜冰优化算法优化卷积神经网络(CNN)结合最小二乘向量机(LSSVM)的数据回归预测效果一览基本介绍程序设计参考资料 效果一览 基本…...

如何对B站的热门视频进行分析
1. 视频内容分析 主题和类型:确定视频的主题和类型(如游戏、教育、生活、科技等),分析其是否符合当前流行趋势或特定兴趣群体。内容创意:评估视频内容的创意性和原创性,是否具有吸引力和独特性。内容质量&…...

MobaXterm tmux 配置妥当
一、事出有因 缘由:接上篇文章,用Docker搭建pwn环境后,用之前学过的多窗口tmux进行调试程序,但是鼠标滚动的效果不按预期上下翻屏。全网搜索很难找到有效解决办法,最后还是找到了一篇英文文章,解决了&…...

Steam成就管理终极指南:三步掌握高效成就解锁技巧
Steam成就管理终极指南:三步掌握高效成就解锁技巧 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager Steam Achievement Manager(SAM&…...

如何免费获取全球50+图书馆古籍资源:BookGet数字古籍下载完整指南
如何免费获取全球50图书馆古籍资源:BookGet数字古籍下载完整指南 【免费下载链接】bookget bookget 数字古籍图书下载工具。 项目地址: https://gitcode.com/gh_mirrors/bo/bookget 还在为寻找古籍文献而烦恼吗?想要从哈佛、国会图书馆等全球知名…...

Cadence 17.4 保姆级教程:从DRC检查到Gerber输出的完整避坑指南
Cadence 17.4 终极避坑指南:从DRC检查到Gerber输出的全流程实战 第一次使用Cadence Allegro 17.4导出Gerber文件时,那种如履薄冰的感觉至今记忆犹新。记得去年为TMC2300电机驱动模块导出生产文件时,因为一个简单的单位设置错误,导…...

双强联袂,数智共舞 | 中聚信 × 金蝶启联巅峰对话,共探财税未来新航道
3 月 26 日,由金蝶软件(中国)有限公司、贵州启联科技有限公司联合主办,中聚信财税技术研究中心协办的「AI 时代 先进管理用金蝶」主题峰会,在贵阳国际生态会议中心圆满落幕。这场聚焦制造企业数字化转型与 AI 赋能管理…...

Gemini实时字幕在Google Meet中延迟超800ms?揭秘谷歌内部SRE监控数据与3步毫秒级调优法
更多请点击: https://intelliparadigm.com 第一章:Gemini实时字幕在Google Meet中延迟超800ms?揭秘谷歌内部SRE监控数据与3步毫秒级调优法 谷歌内部SRE团队近期公开的一组匿名化监控数据显示:在高并发(>500人&…...
全量上线及直连 API 体验指南)
AI 绘图新进展:GPTimage2 系列(含 4K 超清版)全量上线及直连 API 体验指南
随着 AIGC(人工智能生成内容)技术的快速迭代,近期备受关注的 GPTimage2 系列模型已全量上线。作为 AI 绘图领域的新晋生力军,GPTimage2 在图像生成质量、细节刻画上展现出了极强的竞争力。特别值得一提的是,本次不仅上…...

Git 入门教程:从命令行到 IDE 集成
文章目录Git 入门教程:从命令行到 IDE 集成一、环境准备与初始配置1.1 安装 Git1.2 配置用户身份2.2 查看仓库状态2.3 添加文件到暂存区2.4 提交文件到本地仓库2.5 查看历史版本2.6 版本回退2.7 删除文件三、Git 分支操作(多人协作核心)3.1 分…...

BGA虚焊别头疼!从焊膏印刷到回流焊曲线,一份保姆级的SMT工艺避坑指南
BGA虚焊别头疼!从焊膏印刷到回流焊曲线,一份保姆级的SMT工艺避坑指南 在SMT产线上,BGA虚焊问题就像个幽灵,时不时冒出来折腾工程师。上周产线刚报修一批主板,X光下那些不规则焊点像极了抽象派画作——可惜客户要的是工…...

基于SpringBoot的B2C生鲜电商平台毕设源码
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot与Vue框架的B2C生鲜电商平台以解决当前生鲜电商领域存在的核心问题包括供应链管理效率低下导致的商品损耗率居高不下用户端体…...

如何彻底解决Windows风扇控制难题:Fan Control完整指南
如何彻底解决Windows风扇控制难题:Fan Control完整指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/f…...