MySQL查询语句
1. 一般查询
select * from table;
创建表:并插入数据,为下面的查询做例
create table info (
id int primary key,
name varchar(10),
score decimal(5,2),
address varchar(20),
hobbid int(5));insert into info values(1,'liuyi',80,'beijing',2);
insert into info values(2,'wangwu',90,'shengzheng',2);
insert into info values(3,'lisi',60,'shanghai',4);
insert into info values(4,'tianqi',99,'hangzhou',5);
insert into info values(5,'jiaoshou',98,'laowo',3);
insert into info values(6,'hanmeimei',10,'nanjing',3);
insert into info values(7,'lilei',11,'nanjing',5);
2. 排序语法:关键字排序
升序和降序
默认的排序方式就是升序
ASC :升序;DESC :降序;配合order by 语法
按照name列降序排列:
select * from info order by name desc;
#order by :指定要排序的列
#desc :指定排序的方式为降序
按照hobbid列降序,id列升序排列(先排hobbid,再排id)
select * from info order by hobbid desc,id;
#id不指定排序方式,就默认是升序排序
注意:以多个列作为排序关键字,只有当第一个参数有相同的值,第二个字段才有意义。因为多个列排序,会先对第一个字段进行排序,当第一个字段存在重复时,对重复的字段,会根据第二个字段再进行排序
3. where条件的筛选功能(比较符)
3.1 区间判断:可与and or 搭配使用
查询分数大于70且小于等于90的行:
select * from info where score > 70 and score <= 90;
查询分数大于80或小于70的行
select * from info where score < 70 or score > 80;
3.2 嵌套多条件
条件中再嵌套条件,用()
select * from info where score < 60 or (score > 75 and score < 90)
4. 分组查询
SQL查询的结果进行分组,使用 group by 语句 配合聚合函数一起来实现。
4.1 常用聚合函数的类型
- count :统计个数
- sum :求和
- avg :求平均数
- max :最大值
- min :最小值
4.2 聚合函数用法示例
选择列用于聚合函数,如果使用group by,则还需要至少一个列用于分组
select count(name),hobbid from info
group by hobbid;
解释:**针对 info 表中的数据,按照 hobbid 列中的每个唯一值,统计出该值对应的记录数量,并将结果按照 hobbid 的值进行分组展示。**直白点说就是统计每个hobbid对应的记录数量,并显示出来。
在聚合函数分组语句中,所有的非聚合函数列,都可以在group by 语句中。
select count(name),hobbid,name from info
group by hobbid,name;
也可以联合where,having等语句进行筛选
select count(name),hobbid from info
where score >= 60 group by hobbid;
在group中使用having语句
select count(name),hobbid,score from info
group by hobbid,score
having score > 80;
having是在group by中用于筛选的语句,写在group by之后
例:以hobbid这一列作为分组,计算成绩score的平均值,筛选出平均成绩大于等于60分的分组
select avg(score),hobbid from info
group by hobbid
having avg(score) >= 60;
例:统计姓名,以兴趣和分数作为分组,统计出成绩大于80的分组,然后对统计姓名的列按照降序排列
select count(name),hobbid,score from info
group by hobbid,score
having score > 80
order by count(name) desc;
5. limit
limit 1,3 为例:
1是位置偏移量(可选参数),偏移1表示从第二行开始;
如果不设定位置偏移量,默认为0,从第一行开始。3是从起始行开始连续选取三行。
例:选取以id排序的最后三行:
select * from info order by id desc limit 3;
6. as :表和列的别名
实际工作中,表的名字和列的名字可能会很长,书写起来不太方便,需要多次声明表和列时,完整展示太麻烦,可以设置别名,可以使书写简化,方便阅读。
设置别名使用 as
设置列名的别名
select name as 姓名,score as 成绩 from info;
也可以省略as:
select name 姓名,score 成绩 from info;
设置表名的别名:
select i.name as 姓名,i.score as 成绩 from info as i;
select i.name 姓名,i.score 成绩 from info i;
复制表
create table test as select * from info;
注意:这种方式只能复制表的数据类型和数据,但是复制不了结构(各种KEY,约束等)
7. 通配符
like :模糊查询
% :表示0个,1个或多个字符
_ :表示单个字符
#查询地址以s开头
select * from info where address like 's%';
#查询地址包含s
select * from info where address like '%s%';
#查询地址以s开头,长度至少为2
select * from info where address like 's_%';
#查询地址以s开头,第三个字母是a
select * from info where address like 's_a%';
8. 子查询
子查询也叫内查询,嵌套查询。
是在select语句当中又嵌套了一个select。嵌套的select才是子查询,先执行子查询的语句,外部的select再根据自条件的结果进行过滤查找。
子查询可以使多个表,也可以是同一张表。
关联语句: in ; not in ,格式 select (select)
select name,score from info
where id in
( select id from info where score >= 80);
解释:先执行子查询里,筛选出score>=80的id,再回到外层查询,根据查到的id,列出对应id的name,score
select name,score from info
where id not in
(select id from info where score >= 80);
解释:执行顺序和上面一样,区别在于回到外层查询时,对查到的id取反,即除了查到id,列出其他的id对应的name,score
例:联合其他表进行查询
select name,score from info where id not in
(select id from test where score >= 80);
也可以和update连用
查询test表中name为tianqi的id,将info表中对应id的score改为80
update info set score = 80 where id in
(select id from test where name = 'tianqi');
注意:使用update,子查询不能再查自己的表,会报错
子查询当中多表查询和别名
例:info表和test表,查询两张表id相同的部分。然后根据id相同的部分,查询info表的对应id的所在行
select * from info as a
where a.id in
(select b.id from test as b);
解释:a.id in (select b.id from test as b);
例:info表和test表,查询两张表id相同的部分。然后根据id相同的部分,查询info表的对应id中score大于80的所在行
select * from info as a
where a.score > 80 and a.id in
(select b.id from test as b);
例:info表和test表,查询两张表id相同的部分。然后根据id相同的部分,查询info表的平均成绩
select avg(a.score) from info as a
where a.id in
(select b.id from test as b);
9. exists
exists判断子查询的结果是否为空。不为空返回true;为空返回false
select count(*) from info where exists
(select id from test where score > 80);
解释:看起来好像是统计score大于80的数量,实际是先执行子查询,查询结果存在,则exists返回值为true,执行外层查询,统计info的总行数
例:查询分数,如果分数小于50,则统计info的字段数
select count(*) from info where exists
(select id from info where score < 50);
10. mysql的视图(view)
视图是一个虚拟表,表的数据基于查询的结果生成。
视图可以简化复杂的查询,隐藏查询的细节,访问数据更安全。
视图表是多表数据的一个集合表。
视图和表之间的区别
- 存储方式:表是实际的数据行,视图不存储数据行,仅仅是查询结果的虚拟表。
- 数据更新:更新表可以直接更新数据表的数据(较老的版本可能不支持)。
- 占用空间:表实际占用空间,视图表不占用空间,只是一个动态结果的展示。
- 视图表的数据可以是一张表的部分查询数据,也可以是多个表的一部分查询数据。
查询当前数据库当中的视图表:
show full tables in basename where table_type like 'VIEW';
创建视图表:实例:
create view test03 as select * from info where score >= 80;
#创建视图表test03,展示info表中score>=80的行
#此时执行下行
select * from test02;
#相当于执行下行
select * from info where score >= 80;
注意:MySQL5.5版本之前,视图表是只读的,不能修改;MySQL5.5版本开始,视图表可以修改,且修改视图表和修改源表是双向的,即修改视图表也能更新源表。
删除视图表:
drop view tablename;
创建一张视图表,视图表中包含 id,name,address ,从info 和test当中的name值相同的部分创建
create view v_info as
select a.id,a.name,a.address from info as a
where a.name in
(select b.name from test as b); select * from v_info;
可以发现,视图表其实就相当于为查询语句创建了一个别名,为查询做了简化。
平时使用中表的权限是不一样的,因为库的权限是有控制的。而查询视图表的权限相对低。所以使用视图表既可以保证原表的数据安全,也简化了查询的过程。
11. 连接查询
两张表或者多个表的记录结合起来,基于这些表共同的字段,进行数据的拼接。
首先,要确定一个主表作为结果集,然后将其他表的行有选择性的选定到主表的结果上(即做一个拼接)。
11.1 连接的类型
内连接:两张表或者多张表之间符合条件的数据记录的集合。
INNER JOIN,INNER一般可以省略
创建两张表:
create table test1 (
a_id int(11) default null,
a_name varchar(32) default null);create table test2 (
b_id int(11) default null,
b_level int(11) default null);insert into test1 values (1,'aaaa');
insert into test1 values (2,'bbbb');
insert into test1 values (3,'cccc');
insert into test1 values (4,'dddd');insert into test2 values (2,20);
insert into test2 values (3,30);
insert into test2 values (5,50);
insert into test2 values (6,60);
把两张表按照a_id,a_name,b_level拼接起来,并以on 后接筛选条件
select a.a_id,a.a_name,b.b_level from
test1 as a INNER JOIN test2 as b
on a.a_id = b.b_id;
外连接:取两个表或多个表之间的交集。
outer join,outer一般可以省略
左连接:左外连接,left join ,left outer join
左连接以左表为基础,接收左表的所有行,以左表的记录和右表的记录进行匹配。匹配左表的所有,以及右表中符合条件的行。不符合的显示null。
select * from test1 as a left join test2 as b
on a.a_id = b.b_id;
注意:写在left join 左边的就是左表。
右连接:右外连接,right join , right outer join
基本就是跟左连接反过来。右连接以右表为基础,接收右表的所有行,以左表的记录和右表的记录进行匹配。匹配右表的所有,以及左表中符合条件的行。不符合的显示null。
select * from test1 as a right join test2 as b
on a.a_id = b.b_id;
注意:写在right join 右边的就是右表。
12. 练习
需求:两张表
第一张表:记录学生的学号,所属专业,课程,姓名 成绩 性别
第二张表:记录学生的学号,手机 家庭地址,兴趣爱好,性别
编写一个查询来查找具有最高分数的学生。
找出至少有两门课程成绩及格的学生。
查找每个系的学生人数。
计算每个系的学生平均分数。
获取至少同时选修了一门与 ‘xxx’ 相同课程的学生。
找出具有重复名字的学生。
查找在所有课程中都取得了及格分数的学生。
找出每门课程的平均分数,并按照平均分数降序排列。
查找学生选课数量超过平均选课数量的学生信息。
左连接查询 查学号
右连接查询 查学号
内连接查询 查学号
第一张表:记录学生的学号,所属专业,课程,姓名 成绩 性别
第二张表:记录学生的学号,手机 家庭地址,兴趣爱好,性别
create table info1 (id int(4),major varchar(10),lesson varchar(10),name varchar(10),score decimal(5,2) default null,sex char(2)
);
create table info2 (id int(4),phone int(11),address varcha(30),hobby varchar(10) default null,sex char(2)
); insert into info1 values
(1,'电气工程','高数','张三',90,'男'),
(1,'电气工程','英语','张三',55,'男'),
(1,'电气工程','计算机','张三',80,'男'),
(2,'通信工程','高数','李四',60,'男'),
(2,'通信工程','英语','李四',55,'男'),
(2,'通信工程','计算机','李四',50,'男'),
(3,'制药工程','高数','韩梅梅',70,'女'),
(3,'制药工程','英语','韩梅梅',90,'女'),
(3,'制药工程','计算机','韩梅梅',80,'女');
(4,'通信工程','高数','李雷',80,'男'),
(4,'通信工程','英语','李雷',80,'男'),
(4,'通信工程','计算机','李雷',90,'男'),insert into info1 values
(5,'计算机','计算机','张三',88,'男'),
(6,'传媒','英语','李四',88,'女');insert into info2 values
(1,'18369961111','南京','爬山','男'),
(2,'18369962222','北京','遛弯','男'),
(3,'18369963333','天津','说相声','女'),
(4,'18369964444','东京','下海','男');
编写一个查询来查找具有最高分数的学生。
找出至少有两门课程成绩及格的学生。
查找每个系的学生人数。
计算每个系的学生平均分数。
获取至少同时选修了一门与 ‘xxx’ 相同课程的学生。
找出具有重复名字的学生。
查找在所有课程中都取得了及格分数的学生。
找出每门课程的平均分数,并按照平均分数降序排列。
查找学生选课数量超过平均选课数量的学生信息。
左连接查询 查学号
右连接查询 查学号
内连接查询 查学号
- 查找具有最高分数的学生:
select * from info1
where score = (select max(score) from info1);
- 找出至少有两门课程成绩及格的学生:
select count(score),id,name from info1
where score >= 60
group by id,name having count(score) >= 2;
- 查找每个系的学生人数:
select major,COUNT(DISTINCT id) as stu_num from info1
group by major;
- 计算每个系的学生平均分数
select major,lesson,FORMAT(AVG(score),2) as avg_score from info1
group by major,lesson;
- 获取至少选修了有一门课程与 ‘id=5的张三’ 的课程相同的学生
select distinct id,name from info1 where id<>5 and lesson in
(select lesson from info1 where id = 5);#或者用表info1自连接的方式
select distinct i1.id,i1.name from info1 i1
join info1 i2 on i1.lesson = i2.lesson and i2.id = 5
where i1.id <> 5;
- 找出具有重复名字的学生
select distinct id,name from info1 where name in
(select name from info1
group by name having COUNT(DISTINCT id) > 1)
ORDER BY name;
- 查找在所有课程中都取得了及格分数的学生
select distinct id,name from info1 where id not in
(select id from info1 where score < 60);
- 找出每门课程的平均分数,并按照平均分数降序排列
select lesson,FORMAT(AVG(score),2) as avg_score from info1
group by lesson
order by avg_score desc;
- 查找学生选课数量超过平均选课数量的学生信息
select id,name,num_lesson from
(select id,name,count(*) as num_lesson from info1
group by id,name) as stu_lesson
where num_lesson >
(select avg(cnt) as avg_lesson from
(select count(*) as cnt from info1
group by id,name) as avg_count);
- 左连接查询 查学号
select * from info1 as i1 left join info2 as i2
on i1.id = i2.id;
- 右连接查询 查学号
select * from info1 as i1 right join info2 as i2
on i1.id = i2.id;
- 内连接查询 查学号
select * from info1 as i1 inner join info2 as i2
on i1.id = i2.id;
相关文章:

MySQL查询语句
1. 一般查询 select * from table; 创建表:并插入数据,为下面的查询做例 create table info ( id int primary key, name varchar(10), score decimal(5,2), address varchar(20), hobbid int(5));insert into info values(1,liuyi,80,bei…...

远程连接服务
1.SSH协议握手流程 TCP三次握手后当前主机与远程服务器之间协商用哪种协议版本,ssh有两个(ssh1/ssh2)一般用ssh2,协商完后进入到密钥交换的阶段,客户端会生成一个公钥和一个私钥,公钥用来上锁,私…...

系统架构设计师——软件开发方法分类
分类 软件开发方法是指软件开发过程所遵循的办法和步骤,从不同的角度可以对软件开发方法进行不同的分类。 按照开发风范 软件开发过程中,开发方法的选择对项目的成功至关重要。这些方法可按照特定的开发风范分为自顶向下和自底向上两种主要策略&#…...

《看漫画学Python》全彩PDF教程,495页深度解析,零基础也能轻松上手!
前言 说起编程语言,Python 也许不是使用最广的,但一定是现在被谈论最多的。随着近年大数据、人工智能的兴起,Python 越来越多的出现在人们的视野中。 在各家公司里,Python 还常被用来做快速原型开发,以便更快验证产品…...
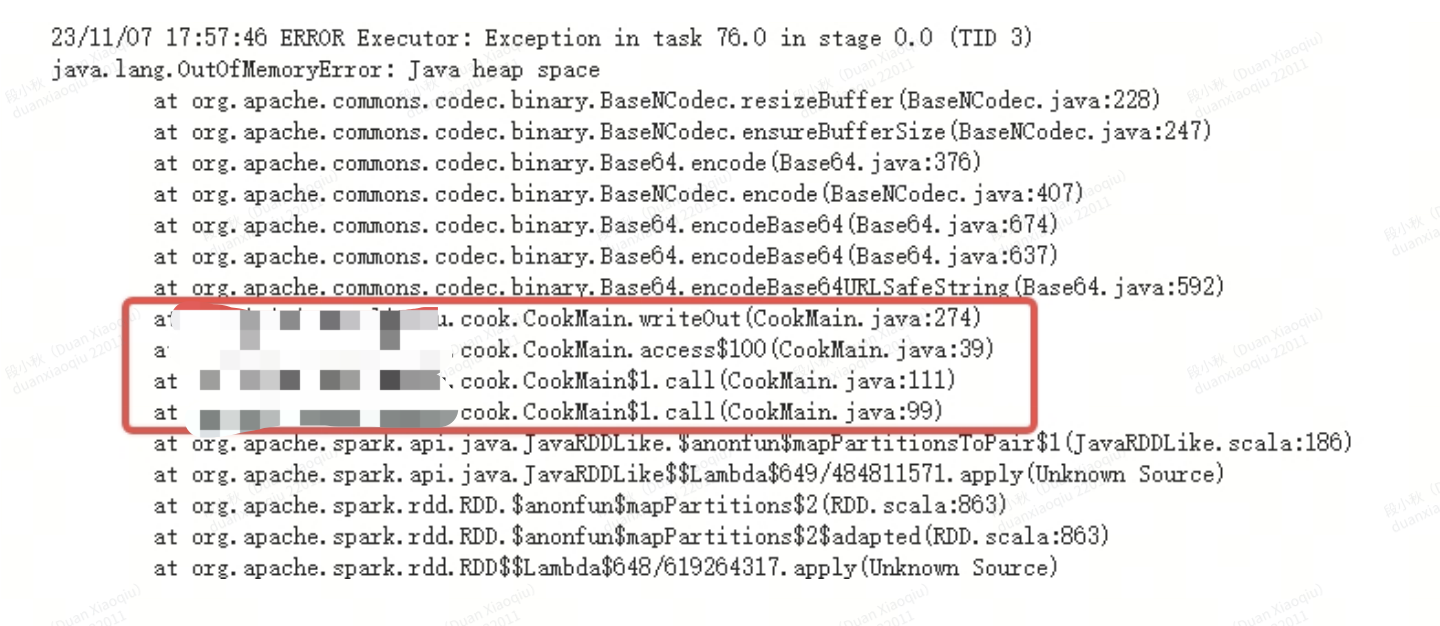
用户画像系列——Spark任务调优实践
在画像标签的加工和写入hbase中,我们采用了spark来快速进行处理和写入。但是在实际线上运行的过程中,仍然遇到了不少问题,下面来总结下遇到的一些问题 1.数据倾斜问题 其实spark 数据倾斜思路和hive、mapreduce 数据倾斜思路处理类似&…...

前端面试宝典【HTML篇】【4】
欢迎来到《前端面试宝典》,这里是你通往互联网大厂的专属通道,专为渴望在前端领域大放异彩的你量身定制。通过本专栏的学习,无论是一线大厂还是初创企业的面试,都能自信满满地展现你的实力。 核心特色: 独家实战案例:每一期专栏都将深入剖析真实的前端面试案例,从基础知…...

【UbuntuDebian安装MySQL】在线安装MySQL8
云计算:腾讯云轻量服务器 系统:Ubuntu-v22 1.更新系统软件包列表 打开终端并运行以下命令来确保你的系统软件包列表是最新的: sudo apt update2.安装 MySQL 存储库 MySQL 提供了官方的 APT 存储库,可以确保你安装的是最新版本…...
PDF翻译神器:这四款可以实现一键搞定,留学党必备!
外文的阅读还是需要一定的语言功底,现在大家也对外文越来越重视起来了,但是借助一些翻译工具进行翻译可以很大程度地提升工作的效率,就算是遇到批量的文件处理也可以一键翻译出来,所以今天借此文章整理了四款好用的pdf翻译工具&am…...

精心准备的高水平的博客【点评语】,来抄啊!
大家好,我是一名_全栈_测试开发工程师,已经开源一套【自动化测试框架】和【测试管理平台】,欢迎大家关注我,和我一起【分享测试知识,交流测试技术,趣聊行业热点】。 第 1 条 这篇博客文章如同灯塔般照亮了技…...

gitlab汉化
承接上文安装好gitlab 首先查看好gitlab的版本(ps:要启动gitlab) cat /opt/gitlab/embedded/service/gitlab-rails/VERSION我的版本是10.0.0 然后安装git yum install -y git然后克隆一下汉化的仓库 git clone https://gitlab.com/xhang/g…...

SSH访问控制:精确管理你的服务器门户
“ 在数字世界中,服务器的安全性是任何网络管理员的首要任务。特别是对于远程登录协议如SSH,确保只有授权用户可以访问是至关重要的。 今天,记录两种有效的方法来控制用户对特定服务器的访问:通过sshd_config实现黑/白名单机制和利…...

Java中的SSL/TLS安全通信实现
Java中的SSL/TLS安全通信实现 大家好,我是微赚淘客系统3.0的小编,是个冬天不穿秋裤,天冷也要风度的程序猿!今天,我们将探讨如何在Java中实现SSL/TLS安全通信。 一、什么是SSL/TLS SSL(Secure Sockets La…...

2959. 关闭分部的可行集合数目
2959. 关闭分部的可行集合数目 题目链接:2959. 关闭分部的可行集合数目 代码如下: //参考链接:https://leetcode.cn/problems/number-of-possible-sets-of-closing-branches/solutions/2844227/guan-bi-fen-bu-de-ke-xing-ji-he-shu-mu-b-85ov class S…...
第十九天培训笔记
上午 1 、构建 vue 发行版本 [rootserver eleme_web]# nohup npm run serve& // 运行 vue 项目 [rootserver eleme_web]# mkdir /eleme [rootserver eleme_web]# cp -r /root/eleme_web/dist/* /eleme/ // 将项目整体 移动到 /eleme 目录下 [rootserver eleme_web]# …...

初学者编程指南:方法与资源推荐
一、引言 编程已成为当代大学生的必备技能,但面对众多编程语言和学习资源,新生们常常感到迷茫。如何选择适合自己的编程语言?如何制定有效的学习计划?如何避免常见的学习陷阱?编程不仅是技术领域的一项基本技能&#…...

【SpringBoot】数据验证之URL参数校验
URL参数校验 Validated public class UserController{ RequestMapping("/query"); public String query(Length(min2,max10,message"姓名长度错误,姓名长度2-10!") RequestParam(name"name",requiredtrue)String name…...

目标检测 | yolov2/yolo9000 原理和介绍
前言:目标检测 | yolov1 原理和介绍 简介 论文链接:https://arxiv.org/abs/1612.08242 时间:2016年 作者:Joseph Redmon 作者首先在YOLOv1的基础上提出了改进的YOLOv2,然后提出了一种检测与分类联合训练方法&#…...
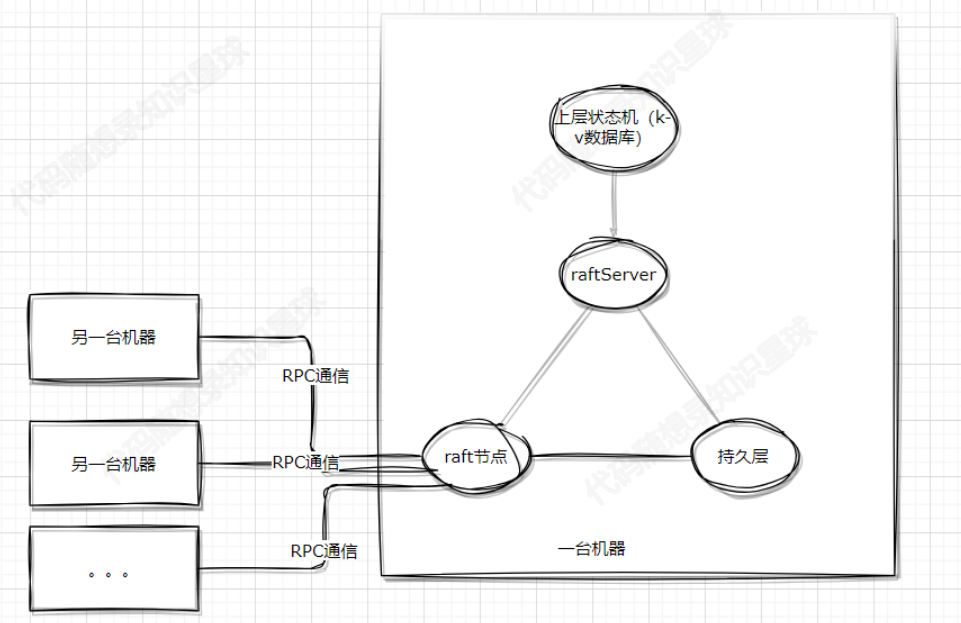
基于Raft算法的分布式KV数据库:一、开篇
项目描述:本项目是基于Raft算法的分布式KV数据库,保证了分布式系统的数据一致性和分区容错性,在少于半数节点发生故障时仍可对外提供服务。使用个人实现的分布式通信框架mpRPC和跳表数据库skipList提供RPC服务和KV存储服务。 github地址&…...

react-日期选择器封装
文件 import { useMemo, useState, useEffect } from "react" import dayjs, { Dayjs } from "dayjs" import "dayjs/locale/zh-cn" import "./App.css" dayjs.locale("zh-cn")function SimpleCalendar() {// 当前时间对象…...

【C++题解】1022. 百钱百鸡问题
欢迎关注本专栏《C从零基础到信奥赛入门级(CSP-J)》 问题:1022. 百钱百鸡问题 类型:嵌套穷举 题目描述: 用 100 元钱买 100 只鸡,公鸡,母鸡,小鸡都要有。 公鸡 5 元 1 只&#x…...

3分钟掌握Krita AI抠图:点一下就能完成的智能选区革命
3分钟掌握Krita AI抠图:点一下就能完成的智能选区革命 【免费下载链接】krita-vision-tools Krita plugin which adds selection tools to mask objects with a single click, or by drawing a bounding box. 项目地址: https://gitcode.com/gh_mirrors/kr/krita-…...

日本电子产业转型启示:从技术过剩到商业模式创新
1. 日本电子产业的十字路口:一场箱根闭门会背后的行业剧痛2013年的春天,当全球电子产业的聚光灯都打在硅谷和深圳时,日本箱根的一家温泉旅馆里,正进行着一场鲜为人知却意义深远的对话。索尼、瑞萨、NEC、日立、松下、富士通、Mega…...

喜马拉雅VIP音频下载指南:xmly-downloader-qt5完整解决方案
喜马拉雅VIP音频下载指南:xmly-downloader-qt5完整解决方案 【免费下载链接】xmly-downloader-qt5 喜马拉雅FM专辑下载器. 支持VIP与付费专辑. 使用GoQt5编写(Not Qt Binding). 项目地址: https://gitcode.com/gh_mirrors/xm/xmly-downloader-qt5 你是否曾为…...

Simplefolio构建优化终极指南:Tree Shaking与代码分割实战
Simplefolio构建优化终极指南:Tree Shaking与代码分割实战 【免费下载链接】simplefolio ⚡️ A minimal portfolio template for Developers 项目地址: https://gitcode.com/gh_mirrors/si/simplefolio Simplefolio是一个为开发者设计的极简个人作品集模板&…...

Tailark部署指南:从开发到生产环境的完整流程
Tailark部署指南:从开发到生产环境的完整流程 【免费下载链接】cnblocks Shadcn marketing blocks 项目地址: https://gitcode.com/gh_mirrors/cn/cnblocks Tailark是一个专为现代营销网站打造的响应式组件库,基于shadcn/ui、Tailwind CSS和Next.…...

高效自动化安装:Windows平台ADB与Fastboot驱动完整配置指南
高效自动化安装:Windows平台ADB与Fastboot驱动完整配置指南 【免费下载链接】Latest-adb-fastboot-installer-for-windows A Simple Android Driver installer tool for windows (Always installs the latest version) 项目地址: https://gitcode.com/gh_mirrors/…...

BrowserClaw:容器化浏览器自动化平台部署与爬虫实战指南
1. 项目概述:一个浏览器自动化与数据抓取的瑞士军刀最近在折腾一些数据采集和自动化测试的活儿,发现一个挺有意思的开源项目,叫BrowserClaw。这名字起得挺形象,“浏览器之爪”,一听就知道是跟浏览器自动化、网页抓取相…...

工程师幽默:从EE Times标题竞赛看技术文化表达与沟通艺术
1. 从“Wizard of Woz”看工程师文化的幽默表达看到“Wizard of Woz”这个标题,很多老电子工程师或硅谷历史爱好者大概会心一笑。这显然是在玩一个经典的双关梗——“Wizard of Oz”(绿野仙踪)和“Woz”(史蒂夫沃兹尼亚克…...

ML:SARSA 的基本原理与实现
在强化学习中,智能体(Agent)并不是一次性从已有标签中学习答案,而是在环境(Environment)中不断尝试动作、观察结果、获得奖励,并根据经验逐步调整行为策略。在 Q 学习中,智能体可以通…...

如何在Blender中实现工程级精确建模:CAD_Sketcher完全指南 [特殊字符]
如何在Blender中实现工程级精确建模:CAD_Sketcher完全指南 🚀 【免费下载链接】CAD_Sketcher Constraint-based geometry sketcher for blender 项目地址: https://gitcode.com/gh_mirrors/ca/CAD_Sketcher 你是否曾经在Blender中尝试创建精确的机…...