RisingWave 1.10 发布!新增用户自定义聚合函数
我们非常高兴地宣布:RisingWave 1.10 版本正式发布!新版本为大家带来了许多重要更新,例如:新增用户自定义聚合函数 (UDAF)、支持从游标获取多个更新、支持可溢出哈希 Join、增强 CDC 连接器、新增 Sink 连接器等。一起来了解本次更新的主要亮点吧!
1. 新增 UDAF
现在,您可以用 Python 和 JavaScript 创建嵌入式用户自定义聚合函数(User-defined Aggregate Function)。这些函数在 RisingWave 中定义,并使用嵌入式解释器执行。定义后,您可以像使用任何内置 SQL 聚合函数一样使用它们。创建 UDAF 需要使用 CREATE AGGREGATE 命令,其一般语法如下:
CREATE AGGREGATE function_name ( argument_type [, ...] )RETURNS return_typeLANGUAGE language_nameAS $$ function_body $$;
其中,函数体 (function_body) 内是一系列返回聚合值的函数,可以用 Python 或 JavaScript 定义。对于 UDAF,您必须定义 create_state 函数,它会创建一个新状态 (State),用于维护聚合函数的持续计算,促成高效的计算结果。您还必须定义 accumulate 函数,它更新并返回当前状态值。此函数将状态和来自聚合函数定义的输入参数作为参数。
此外,您可以选择定义 finish 函数,该函数返回聚合函数的结果,定义时必须将状态作为输入参数。如果您未定义此函数,则函数将返回当前状态。您还可以选择 retract 函数,它会撤回当前状态的值,然后返回该值。
UDAF 赋予了 RisingWave 更复杂的计算能力,让您在处理数据时更灵活更自主。
更多细节,请查看:
- CREATE AGGREGATE
- Embedded Python UDFs
- Use UDFs in JavaScript
2. 从游标获取多个更新
在 v1.9 中,我们为订阅引入了子脚本和游标,允许您检索对表或物化视图所做的更新。以前,您只能使用 FETCH 命令逐行从游标中检索更新。现在,您可以指定从游标中检索多少行。以下 SQL 查询从游标 cur1 中检索四个最新的更新。
FETCH 4 FROM cur1;
此功能更方便您查看表和物化视图的最近更改。此外,结果表的列名已更新为与源表或物化视图的列名匹配,此前的格式为 table_name.col_name。
更多细节,请查看:
- Fetch from cursor
3. 支持可溢出哈希 Join
为提高 RisingWave 在 Join 两个大表时的性能,我们现在支持可溢出哈希 Join。目前,RisingWave 正在使用的是哈希 Join,哈希表在内存中构建,它们能够很好地并行化和扩展,但需要大量内存去构建,当表很大时,可能会导致内存不足问题。可溢出哈希 Join 解决了这个问题,在 Join 查询期间内存使用量高时,RisingWave 可以利用磁盘空间。
4. 对 CDC Source 连接器的增强
本次版本中,我们继续改进了现有 CDC Source 连接器,为您提供更流畅的流处理体验。此版本包含两个新功能:自动映射 Schema 和元数据列。但请注意,这些新功能并不适用于所有 CDC 连接器,因此请继续阅读以了解更多详情。
4.1 自动映射 Schema
在创建 MySQL 或 PostgreSQL CDC 表时,RisingWave 现在会自动将上游表的 Schema 映射到 RisingWave 表。创建表时可以使用 * 以从源表中导入所有列,而无需单独定义列。但是,如果在表创建过程中指定了其他列,则不能使用 *。
让我们用一个简单例子说明这个过程。首先,我们用以下 SQL 查询连接到 MySQL 数据库。在从 MySQL 或 PostgreSQL 导入 CDC 数据时,您必须先创建一个 Source,用于连接到数据库,然后再从各个表中导入数据。
CREATE SOURCE mysql_source WITH (connector = 'mysql-cdc',hostname = '127.0.0.1',port = '3306',username = 'root',password = 'password',database.name = 'mydb',server.id = 5888
);
接下来,我们创建一个表,从 MySQL 数据库中上游表 tbl1 中导入所有列。mysql_tbl 的列将对应 tbl1 的列。
CREATE TABLE mysql_tbl (*)
FROM mysql_source TABLE 'mydb.tbl1';
此功能使在 RisingWave 中创建 CDC 表更加高效。
4.2 包含元数据列
在创建 MongoDB、MySQL 或 PostgreSQL CDC 表时,可以使用 INCLUDE 子句附加元数据列。如果需要将元数据列添加到已有的 CDC 表中,则需要在 RisingWave 中重新创建该表。
对于 MongoDB、MySQL 和 PostgreSQL CDC 表,您可以使用 INCLUDE 子句导入上游提交时间戳。对于历史数据,默认填充数据为 1970-01-01 00:00:00+00:00。
- 对于 MongoDB,您可以使用
INCLUDE子句导入collection_name。 - 对于 MySQL 和 PostgreSQL,您可以导入
database_name、schema_name和table_name。
INCLUDE 子句的语法如下:
INCLUDE metadata_col [AS col_name];
metadata_col 可以是上述提到的任何元数据列。在表 Schema 定义之后,此子句可以在创建表时使用。
以下是一个示例,从 MySQL 表中导入元数据列 timestamp 和 database_name。
CREATE TABLE tbl_meta (id int,name varchar,age intPRIMARY KEY (id)
) INCLUDE TIMESTAMP AS commit_ts
INCLUDE DATABASE_NAME AS db_name
FROM mysql_source TABLE 'mydb.tbl2';
更多细节,请查看:
- Ingest data from MySQL CDC
- Ingest data from PostgreSQL CDC
- Ingest data from MongoDB CDC
5. 增强现有 Sink 连接器
5.1 默认 Sink 解耦
对于 ClickHouse、Google Pub/Sub、Kafka、Kinesis、MQTT、NATS 和 Pulsar Sink 连接器,Sink 解耦将默认启用。之前,此功能只在 Sink 是 append-only 时才会启用,现在则不再有此限制。Sink 解耦会在 RisingWave 和下游系统之间插入一个缓冲队列,以确保 RisingWave 不受下游系统性能问题的影响。
如果您想禁用 Sink 解耦,请使用会话变量 sink_decouple。
SET sink_decouple = false;
5.2 检查点解耦选项
对于 Delta Lake 和 StarRocks Sink 连接器,您可以使用 commit_checkpoint_interval 参数,将下游系统的 commit 与 RisingWave 的 commit 解耦。这意味着,RisingWave 将在达到指定的检查点间隔时提交数据,而不是在每个屏障处提交数据。
例如,如果 commit_checkpoint_interval 设置为 5,RisingWave 将间隔 5 个检查点提交一次数据。这可以减少生成的目标表版本,提升查询性能。
在创建 Delta Lake 或 StarRocks Sink 连接器时,commit_checkpoint_interval 参数应在 WITH 选项中指定。
CREATE SINK s1_sink FROM s1_source
WITH (connector = 'deltalake',type = 'append-only',location = 's3a://my-delta-lake-bucket/path/to/table',s3.endpoint = '<https://s3.ap-southeast-1.amazonaws.com>',s3.access.key = '${ACCESS_KEY}',s3.secret.key = '${SECRET_KEY}',commit_checkpoint_interval = 5
)
更多细节,请查看:
- Sink decoupling
- Sink data from RisingWave to Delta Lake
- Sink data from RisingWave to StarRocks
6. 新增 Sink 连接器
RisingWave 一直在持续添加下游系统连接器,扩展其生态系统。我们现在支持将数据 Sink 到 DynamoDB 和 Microsoft SQL Server。如果您对特定连接器感兴趣,请参阅我们的集成页面。您可以投票以表示对特定连接器感兴趣,或在其可用时收到通知。
6.1 Amazon DynamoDB
Amazon DynamoDB 是一个 NoSQL 数据库,旨在处理高容量的结构化和半结构化数据。它提供一致的高性能和易扩展性。要将数据从 RisingWave Sink 到 DynamoDB 表,需使用 CREATE SINK 命令。Sink 到 DynamoDB 表时,您的 RisingWave 源表必须有一个由两列组成的复合主键。它们需要对应 DynamoDB 目标表中定义的分区键和排序键。
例如,如果您想 Sink 到名为 books_dynamo 的 DynamoDB 表,该表具有分区键 isbn 和排序键 edition,则 RisingWave 表 Schema 应定义如下:
CREATE TABLE IF NOT EXISTS books_rw (isbn varchar,edition int,title varchar,author varchar,primary key (isbn, edition)
);
然后再创建 Sink 连接器,将数据从 books_rw Sink 到 books_dynamo。
CREATE SINK dynamo_sink
FROM movies
WITH (connector = 'dynamodb',table = 'books_dynamo',primary_key = 'isbn, edition',endpoint = '<http://localhost:8000>',region = 'region,access_key = 'access_key',secret_key = 'secret_key'
);
6.2 Microsoft SQL Server
Microsoft SQL Server 是一个强大的关系数据库管理系统,支持广泛的数据事务处理、商业智能等功能。它使用 T-SQL,并包括 SQL Server 集成服务、报告服务和分析服务等工具。RisingWave 支持将数据 Sink 到自托管的 SQL Server 和 Azure SQL。
以下是一个示例,我们创建了 Sink 连接器 sqlserver_sink,将数据从物化视图 mv1 Sink 到 SQL Server 表 sqlserver_tbl。因为这是一个 Upsert Sink ,我们定义了主键 pk1 和 pk2。
CREATE SINK sqlserver_sinkFROM mv1WITH (connector = 'sqlserver',type = 'upsert',sqlserver.host = 'sqlserver-server',sqlserver.port = 1433,sqlserver.user = 'user',sqlserver.password = 'password',sqlserver.database = 'mydb',sqlserver.table = 'sqlserver_tbl',primary_key = 'pk1, pk2',
);
6.3 OpenSearch
OpenSearch 是一个开源的搜索和分析引擎,旨在实时搜索、分析和可视化大量数据。它源自 ElasticSearch,适用于日志和事件数据分析、企业搜索、监控观测等各种应用。
要将数据从 RisingWave Sink 到 OpenSearch,您可以使用 CREATE SINK 命令。
CREATE SINK opensearch_sink
FROM table1
WITH (connector = 'opensearch',index = 'id1',primary_key = 'types_id',url = '<http://opensearch:8080>',username = 'user',password = 'password'
);
更多细节,请查看:
- Sink data from RisingWave to OpenSearch
7. 保留内存算法变更
现在,用于计算默认保留内存 (Reserved Memory) 的算法已更改。保留内存用于为 RisingWave 提供调整内存使用量的缓冲时间,以应对输入数据的额外涌入。之前,我们将计算节点总内存的 20% 用作保留内存。现在,保留内存的计算方式为:前 16GB 内存的 30% + 剩余内存的 20%。通过这种计算方法,保留内存可以根据您的设置进行扩展,更好地平衡系统性能和内存利用率。
如果此方法不适合您,您可以使用启动选项 --reserve-memory-bytes 或环境变量 RW_RESERVED_MEMORY_BYTES 指定保留内存,但需要注意,保留内存必须至少为 512MB。
更多细节,请查看:
- Sink data from RisingWave to Amazon DynamoDB
- Sink data from RisingWave to SQL Server
- Sink data from RisingWave to OpenSearch
8. 总结
以上只是 RisingWave 1.10 版本新增的部分功能,如果您想了解本次更新的完整列表,请查看更详细的发布说明。
9. 关于 RisingWave
RisingWave 是一款开源的分布式流处理数据库,旨在帮助用户降低实时应用的开发成本。RisingWave 采用存算分离架构,提供 Postgres-style 使用体验,具备比 Flink 高出 10 倍的性能以及更低的成本。
👨🔬加入 RW 社区,欢迎关注公众号:RisingWave 中文开源社区
🧑💻想要了解和探索 RisingWave,欢迎浏览我们的官网:risingwave.com/
🔧快速上手 RisingWave,欢迎体验入门教程:github.com/risingwave
💻深入理解使用 RisingWave,欢迎阅读用户文档:zh-cn.risingwave.com/docs
相关文章:

RisingWave 1.10 发布!新增用户自定义聚合函数
我们非常高兴地宣布:RisingWave 1.10 版本正式发布!新版本为大家带来了许多重要更新,例如:新增用户自定义聚合函数 (UDAF)、支持从游标获取多个更新、支持可溢出哈希 Join、增强 CDC 连接器、新增 Sink 连接器等。一起来了解本次更…...

Modbus通讯协议
Modbus通讯协议 Modbus协议是一种用于电子控制器之间的通信协议,它允许不同类型的设备之间进行通信,以便进行数据交换和控制。Modbus协议最初为可编程逻辑控制器(PLC)通信开发,现已广泛应用于工业自动化领…...

fal.ai发布超分辨率模型——AuraSR V2
今天,我们发布了单步 GAN 升频器的第二个版本: AuraSR。 我们在上个月发布了 AuraSR v1,社区的反响让我们深受鼓舞,因此我们立即开始了新版本的训练。 AuraSR 基于 Adobe Gigagan 论文,以 lucidrain 的实现为起点。Gi…...

SYD88xx代码复位不成功和解决办法
原来的复位代码如下: void ota_manage(void){#ifdef _OTA_if(ota_state){switch(ota_state){case 1 : #if defined(_DEBUG_) || defined(_SYD_RTT_DEBUG_)dbg_printf("start FwErase\r\n");#endifCmdFwErase();#if defined(_DEBUG_) || defined(_SYD_RTT_DEBUG_)db…...

加油,为Vue3提供一个可媲美Angular的ioc容器
为什么要为Vue3提供ioc容器 Vue3因其出色的响应式系统,以及便利的功能特性,完全胜任大型业务系统的开发。但是,我们不仅要能做到,而且要做得更好。大型业务系统的关键就是解耦合,从而减缓shi山代码的生长。而ioc容器是…...
)
RS485 CAN SPI IIC UART RS232这些通信协议传输距离、传输速度对比给出比较顺序-笔记(面试必备)
各类通信协议(RS485、CAN、SPI、I2C、UART、RS232)的传输距离和传输速度各有不同,适用于不同的应用场景。以下是这些通信协议的传输距离和传输速度的对比及排序: 传输距离比较(从长到短) RS485 最大传输距…...

高频JMeter软件测试面试题
近期,有很多粉丝在催更关于Jmeter的面试题,索性抽空整理了一波,以下是一些高频JMeter面试题,拿走不谢~ 一、JMeter的工作原理 JMeter就像一群将请求发送到目标服务器的用户一样,它收集来自目标服务器的响应以及其他统计…...
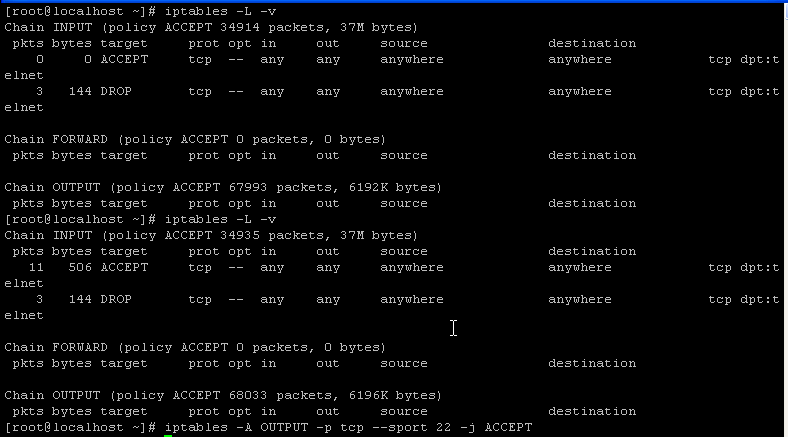
iptables netfilter
iptables -L --line...

如何使用Python自动发送邮件?
Python 提供了强大的内置库 smtplib 和 email,让我们能够轻松地发送各种类型的电子邮件。本指南将带你逐步了解如何使用 Python 发送邮件,从简单文本邮件到包含 HTML 内容、附件和内嵌图片的复杂邮件。 1. 准备工作: 1.1 安装必要的库 确保…...

C#中读写INI配置文件
在作应用系统开发时,管理配置是必不可少的。例如数据库服务器的配置、安装和更新配置等等。由于Xml的兴起,现在的配置文件大都是以xml文档来存储。比如Visual Studio.Net自身的配置文件Mashine.config,Asp.Net的配置文件Web.Config࿰…...

深入解析Spring中的@RequestMapping注解
RequestMapping是Spring框架中的一个核心注解,用于映射Web请求到处理器类的方法上。本文将详细介绍RequestMapping注解的用途、支持的属性以及如何在Spring MVC和Spring WebFlux中应用它。 1. 引言 在Spring框架中,RequestMapping是一个用于简化请求映…...

Python:lambda函数
lambda函数解释 Lambda函数,也被称为匿名函数,是Python等编程语言中用于创建简单、一次性使用的函数对象的一种快捷方式。在Python中,lambda函数使用lambda关键字定义,其后紧跟一个或多个参数(用逗号分隔)…...

MySQL查询语句
1. 一般查询 select * from table; 创建表:并插入数据,为下面的查询做例 create table info ( id int primary key, name varchar(10), score decimal(5,2), address varchar(20), hobbid int(5));insert into info values(1,liuyi,80,bei…...

远程连接服务
1.SSH协议握手流程 TCP三次握手后当前主机与远程服务器之间协商用哪种协议版本,ssh有两个(ssh1/ssh2)一般用ssh2,协商完后进入到密钥交换的阶段,客户端会生成一个公钥和一个私钥,公钥用来上锁,私…...

系统架构设计师——软件开发方法分类
分类 软件开发方法是指软件开发过程所遵循的办法和步骤,从不同的角度可以对软件开发方法进行不同的分类。 按照开发风范 软件开发过程中,开发方法的选择对项目的成功至关重要。这些方法可按照特定的开发风范分为自顶向下和自底向上两种主要策略&#…...

《看漫画学Python》全彩PDF教程,495页深度解析,零基础也能轻松上手!
前言 说起编程语言,Python 也许不是使用最广的,但一定是现在被谈论最多的。随着近年大数据、人工智能的兴起,Python 越来越多的出现在人们的视野中。 在各家公司里,Python 还常被用来做快速原型开发,以便更快验证产品…...
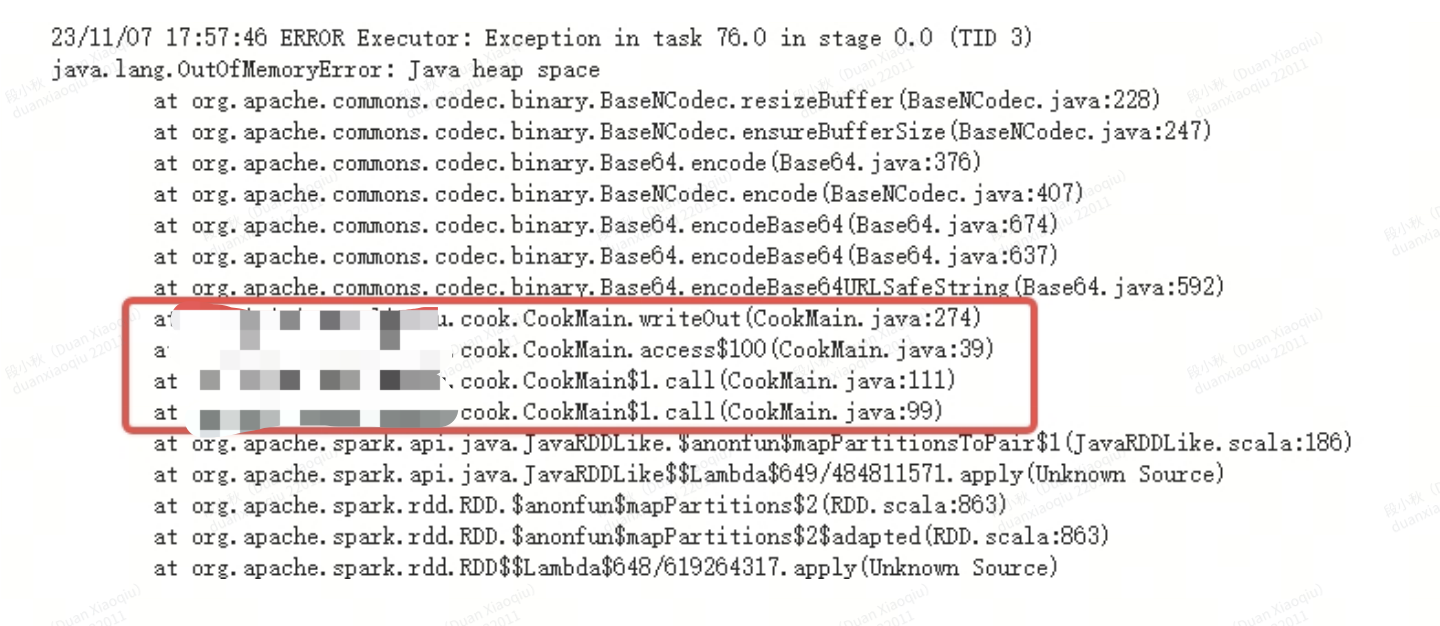
用户画像系列——Spark任务调优实践
在画像标签的加工和写入hbase中,我们采用了spark来快速进行处理和写入。但是在实际线上运行的过程中,仍然遇到了不少问题,下面来总结下遇到的一些问题 1.数据倾斜问题 其实spark 数据倾斜思路和hive、mapreduce 数据倾斜思路处理类似&…...

前端面试宝典【HTML篇】【4】
欢迎来到《前端面试宝典》,这里是你通往互联网大厂的专属通道,专为渴望在前端领域大放异彩的你量身定制。通过本专栏的学习,无论是一线大厂还是初创企业的面试,都能自信满满地展现你的实力。 核心特色: 独家实战案例:每一期专栏都将深入剖析真实的前端面试案例,从基础知…...

【UbuntuDebian安装MySQL】在线安装MySQL8
云计算:腾讯云轻量服务器 系统:Ubuntu-v22 1.更新系统软件包列表 打开终端并运行以下命令来确保你的系统软件包列表是最新的: sudo apt update2.安装 MySQL 存储库 MySQL 提供了官方的 APT 存储库,可以确保你安装的是最新版本…...
PDF翻译神器:这四款可以实现一键搞定,留学党必备!
外文的阅读还是需要一定的语言功底,现在大家也对外文越来越重视起来了,但是借助一些翻译工具进行翻译可以很大程度地提升工作的效率,就算是遇到批量的文件处理也可以一键翻译出来,所以今天借此文章整理了四款好用的pdf翻译工具&am…...
)
Claude长文档推理能力跃迁全记录(2024–2026技术演进图谱)
更多请点击: https://intelliparadigm.com 第一章:Claude 2026长文档推理能力的定义与边界 Claude 2026 的长文档推理能力指其在单次上下文窗口内(最大支持 2,000,000 tokens)对跨章节、多模态混合结构化文本(含嵌入表…...

Modbus RTU 与 Modbus TCP 深入指南-附录:快速参考表
十五、附录:快速参考表 15.1 Modbus RTU 帧示例速查 操作请求帧(十六进制)响应帧示例读线圈(1个)01 01 00 00 00 01 CRC01 01 01 01 CRC读离散输入01 02 00 00 00 01 CRC01 02 01 00 CRC读保持寄存器(1个…...

利用GPU指纹技术进行位置验证
大家读完觉得有帮助记得关注和点赞!!!摘要对GPU芯片进行强有力的监管,对于防范先进AI模型被未经授权开发和滥用至关重要。目前的芯片位置监控方法,依赖于存储在芯片内部的加密密钥所支持的“基于ping的协议”。然而&am…...

多语言AI Agent的构建:跨语言理解与任务执行
多语言AI Agent的构建:跨语言理解与任务执行 本文面向有一定大模型应用开发基础的工程师,从原理、架构、实战三个维度完整讲解可落地的多语言AI Agent构建方案,全文约11000字,代码可直接运行。 引言 痛点引入 你是否遇到过这些场景? 运营跨境电商平台时,每个语言站点要…...

Mac Mouse Fix终极指南:如何让普通鼠标在Mac上获得超越触控板的体验
Mac Mouse Fix终极指南:如何让普通鼠标在Mac上获得超越触控板的体验 【免费下载链接】mac-mouse-fix Mac Mouse Fix - Make Your $10 Mouse Better Than an Apple Trackpad! 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix 还在为Mac上第三…...

APK安装器完整指南:在Windows上轻松安装安卓应用的终极方案
APK安装器完整指南:在Windows上轻松安装安卓应用的终极方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否想在Windows电脑上直接运行手机应用&…...

SIGTRAN协议:电信网络IP化的关键技术解析
1. SIGTRAN:下一代电信网络的信令传输基石2003年全球电信业寒冬中,一个技术决策正在悄然改变行业格局。当运营商们紧缩资本开支时,AT&T、Verizon等巨头却不约而同地加大了对IP网络的投入。这背后隐藏着一个关键技术转折——传统TDM网络向…...

如何快速解决Funannotate数据库安装失败:终极完整指南
如何快速解决Funannotate数据库安装失败:终极完整指南 【免费下载链接】funannotate Eukaryotic Genome Annotation Pipeline 项目地址: https://gitcode.com/gh_mirrors/fu/funannotate Funannotate作为一款强大的真核生物基因组注释流程工具,其…...

InferenceX:大模型高效推理引擎核心原理与生产部署实战
1. 项目概述:从模型训练到高效推理的最后一公里如果你在AI领域,特别是大模型应用开发上投入过精力,那么对“InferenceX”这个名字可能不会感到陌生。它不是一个全新的训练框架,也不是一个模型仓库,而是精准地瞄准了当前…...

Tempera风格在Midjourney中为何始终不达标?:资深提示工程专家拆解v6.1/v6.2渲染底层逻辑
更多请点击: https://intelliparadigm.com 第一章:Tempera风格在Midjourney中的定义性困境 Tempera(蛋彩画)作为一种古老绘画媒介,其细腻笔触、哑光质感与矿物颜料特有的微颗粒反光,在Midjourney等文本到图…...