强化学习时序差分算法之Q-learning算法——以悬崖漫步环境为例
0.简介
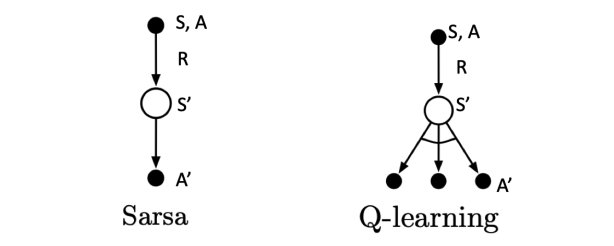
基于时序差分算法的强化学习算法除了Sarsa算法以外还有一种著名算法为Q-learning算法,为离线策略算法,与在线策略算法Sarsa算法相比,其时序差分更新方式变为
Q(St,At)←Q(St,At)+α[Rt+1+γmaxaQ(St+1,a)−Q(St,At)]
对于 Sarsa 来说:
- 1)在状态 s' 时,就知道了要采取那个动作 a',并且真的采取了这个动作
- 2)当前动作 a 和下一个动作 a' 都是 根据 ϵ𝜖 -贪婪策略选取的,因此称为on-policy学习
对于 Q-Learning:
- 1)在状态s'时,只是计算了 在 s' 时要采取哪个 a' 可以得到更大的 Q 值,并没有真的采取这个动作 a'。
- 2)动作 a 的选取是根据当前 Q 网络以及 ϵ𝜖-贪婪策略,即每一步都会根据当前的状况选择一个动作A,目标Q值的计算是根据 Q 值最大的动作 a' 计算得来,因此为 off-policy 学习。
1.导入相关库
import matplotlib.pyplot as plt
import numpy as np
from tqdm import tqdm2.悬崖漫步环境实现环节
class cliffwalking():def __init__(self,colnum,rownum,stepr,cliffr,initx,inity):self.colnum=colnumself.rownum=rownumself.stepr=steprself.cliffr=cliffrself.initx=initxself.inity=inityself.disaster=list(range((self.rownum-1)*self.colnum+1,self.rownum*self.colnum-1))self.end=[self.rownum*self.colnum-1]self.x=self.initxself.y=self.initydef step(self,action):change=[[0,-1],[0,1],[-1,0],[1,0]]#change[0]上;change[1]下;change[2]左;change[3]右;坐标系原点(0,0)在左上角self.x=min(self.colnum-1,max(0,self.x+change[action][0]))self.y=min(self.rownum-1,max(0,self.y+change[action][1]))nextstate=self.y*self.colnum+self.xreward=self.steprdone=Falseif nextstate in self.disaster:reward=self.cliffrdone=Trueif nextstate in self.end:done=Truereturn nextstate,reward,donedef reset(self):self.x=self.initxself.y=self.inityreturn self.y*self.colnum+self.x3.Q-learning算法实现
class Qlearning():""" Qlearning算法 """def __init__(self,colnum,rownum,alpha,gamma,epsilon,actionnum=4):self.colnum=colnumself.rownum=rownumself.alpha=alpha#学习率self.gamma=gamma#折扣因子self.epsilon=epsilonself.actionnum=actionnum#动作个数self.qtable=np.zeros([self.colnum*self.rownum,self.actionnum])def takeaction(self,state):if np.random.random()<self.epsilon:action=np.random.randint(0,self.actionnum)else:action=np.argmax(self.qtable[state])return actiondef bestaction(self,state):qmax=np.max(self.qtable[state])a=np.where(self.qtable[state]==qmax)return adef update(self,s0,a0,r,s1):tderror=r+self.gamma*np.max(self.qtable[s1])-self.qtable[s0][a0]self.qtable[s0][a0]+=self.alpha*tderror4.打印目标策略函数
def printtheagent(agent,env,actionmeaning):for i in range(env.rownum):for j in range(env.colnum):if (i*env.colnum+j) in env.disaster:print('****',end=' ')elif (i*env.colnum+j) in env.end:print('EEEE',end=' ')else:a=agent.bestaction(i*env.colnum+j)b=[0 for _ in range(len(actionmeaning))]for m in range(len(actionmeaning)):b[m]=1 if m in a else 0 pistr=''for k in range(len(actionmeaning)):pistr+=actionmeaning[k] if b[k]>0 else 'o'print('%s'%pistr,end=' ')print()5.相关参数设置
ncol=12#悬崖漫步环境中的网格环境列数
nrow=4#悬崖漫步环境中的网格环境行数
step_reward=-1#每步的即时奖励
cliff_reward=-100#悬崖的即时奖励
init_x=0#智能体在环境中初始位置的横坐标
init_y=nrow-1#智能体在环境中初始位置的纵坐标
alpha=0.1#价值估计更新的步长
epsilon=0.1#epsilon-贪婪算法的探索因子
gamma=0.9#折扣衰减因子
num_episodes=500#智能体在环境中运行的序列总数
tqdm_num=10#进度条的数量
printreturnnum=10#打印回报的数量
actionmeaning=['↑','↓','←','→']#上下左右表示符
6.程序主体部分实现
np.random.seed(5)
returnlist=[]
env=cliffwalking(colnum=ncol,rownum=nrow,stepr=step_reward,cliffr=cliff_reward,initx=init_x,inity=init_y)
agent=Qlearning(colnum=ncol,rownum=nrow,alpha=alpha,gamma=gamma,epsilon=epsilon,actionnum=4)
for i in range(tqdm_num):with tqdm(total=int(num_episodes/tqdm_num)) as pbar:for episode in range(int(num_episodes/tqdm_num)):episodereturn=0state=env.reset()done=Falsewhile not done:action=agent.takeaction(state)nextstate,reward,done=env.step(action)episodereturn+=rewardagent.update(state,action,reward,nextstate)state=nextstatereturnlist.append(episodereturn)if (episode+1)%printreturnnum==0:pbar.set_postfix({'episode':'%d'%(num_episodes/tqdm_num*i+episode+1),'return':'%.3f'%(np.mean(returnlist[-printreturnnum:]))})pbar.update(1)
episodelist=list(range(len(returnlist)))
plt.plot(episodelist,returnlist)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('Qlearning on{}'.format('Cliff Walking'))
plt.show()
print('Qlearning算法最终收敛得到的策略为:')
printtheagent(agent=agent,env=env,actionmeaning=actionmeaning)7.结果展示

Iteration 0: 100%|████████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 428.50it/s, episode=50, return=-114.000]
Iteration 1: 100%|████████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 895.23it/s, episode=100, return=-72.500]
Iteration 2: 100%|███████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 1222.78it/s, episode=150, return=-66.100]
Iteration 3: 100%|███████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 1519.26it/s, episode=200, return=-40.000]
Iteration 4: 100%|███████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 1533.70it/s, episode=250, return=-26.600]
Iteration 5: 100%|███████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 1925.46it/s, episode=300, return=-38.000]
Iteration 6: 100%|███████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 2387.50it/s, episode=350, return=-47.000]
Iteration 7: 100%|███████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 2949.12it/s, episode=400, return=-25.500]
Iteration 8: 100%|███████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 3133.12it/s, episode=450, return=-34.000]
Iteration 9: 100%|███████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 3133.44it/s, episode=500, return=-60.400]
Qlearning算法最终收敛得到的策略为:
↑ooo o↓oo ooo→ o↓oo ooo→ ooo→ ooo→ ooo→ o↓oo ooo→ o↓oo o↓oo
o↓oo ooo→ ooo→ ooo→ ooo→ ooo→ o↓oo ooo→ o↓oo ooo→ ooo→ o↓oo
ooo→ ooo→ ooo→ ooo→ ooo→ ooo→ ooo→ ooo→ ooo→ ooo→ ooo→ o↓oo
↑ooo **** **** **** **** **** **** **** **** **** **** EEEE
8.总结
打印出的回报是行为策略在环境中交互得到的,而不是Q-learning算法在学习的目标策略的真实回报,目标策略打印出来如上所示,发现其更偏向于走在悬崖边上,这与Sarsa算法得到的比较保守的策略相比更优。
比较Sarsa算法与Q-learnig算法在训练中的回报曲线图,可以发现在一个序列中Sarsa算法获得期望回报高于Q-learning算法,原因是训练过程中智能体采取基于当前Q(s,a)函数的-贪婪策略来平衡探索与利用,Q-learning算法由于沿着悬崖边走,会以一定的概率探索“掉入悬崖”这一动作,而Sarsa相对保守的路线使得智能体几乎不可能掉入悬崖。
相关文章:
强化学习时序差分算法之Q-learning算法——以悬崖漫步环境为例
0.简介 基于时序差分算法的强化学习算法除了Sarsa算法以外还有一种著名算法为Q-learning算法,为离线策略算法,与在线策略算法Sarsa算法相比,其时序差分更新方式变为 Q(St,At)←Q(St,At)α[Rt1γmaxaQ(St1,a)−Q(St,At)] 对于 Sarsa 来说&am…...

111推流111
推流推流...

刷题——数组中只出现一次的两个数字
数组中只出现一次的两个数字_牛客题霸_牛客网 描述 一个整型数组里除了两个数字只出现一次,其他的数字都出现了两次。请写程序找出这两个只出现一次的数字。 数据范围:数组长度 2≤n≤10002≤n≤1000,数组中每个数的大小 0<val≤100000…...

《剖析程序员面试“八股文”:助力、阻力还是噱头?》
#“八股文”在实际工作中是助力、阻力还是空谈? 作为现在各类大中小企业面试程序员时的必问内容,“八股文”似乎是很重要的存在。但“八股文”是否能在实际工作中发挥它“敲门砖”应有的作用呢?有IT人士不禁发出疑问:程序员面试考…...

Redis过期key的删除策略
在 Redis 中,设置了过期时间的键在过期时间到达后,并不会立即从内存中删除。如果不是,那过期后到底什么时候被删除呢? 下面对这三种删除策略进行具体分析。 立即删除: 立即删除能够保证内存数据的及时性和空间的有效…...

软件管理
设备挂载在目录下才可以读 挂载类似于将u盘插在电脑上 mount /dev/sr0 /opt/openeuler/ vim /etc/rc.d/rc.local #开机自运行脚本,将挂载命令写入脚本,并给这个脚本执行权限 chmod x /etc/rc.d/rc.local [rootlocalhost ~]# cd /etc/yum.repos.d/ […...

【2024】Datawhale AI夏令营 Task3笔记——Baseline2部分代码解读及初步上分思路
【2024】Datawhale AI夏令营 Task3笔记——Baseline2部分代码解读及初步上分思路 本文对可完成赛事“逻辑推理赛道:复杂推理能力评估”初赛的Baseline2部分关键代码进行详细解读,介绍Baseline2涉及的关键技术和初步上分思路。 Baseline2代码由Datawhal…...

软件测试——测试分类(超超超齐全版)
为什么要对软件测试进行分类 软件测试是软件⽣命周期中的⼀个重要环节,具有较⾼的复杂性,对于软件测试,可以从不同的⻆度加以分类,使开发者在软件开发过程中的不同层次、不同阶段对测试⼯作进⾏更好的执⾏和管理测试的分类⽅法。…...
深入解析 Go 语言 GMP 模型:并发编程的核心机制
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家:点击跳转到网站,对人工智能感兴趣的小伙伴可以点进去看看。 前言 本章是Go并发编程的起始篇章,在未来几篇文章中我们会…...

PHP中如何处理字符串
在PHP中,处理字符串是一项非常常见的任务,PHP提供了大量的内置函数来方便地处理字符串。以下是一些常用的字符串处理函数: strlen() - 返回字符串的长度。 php复制代码 $text "Hello, World!"; echo strlen($text); // 输出&…...

windows内存泄漏检查汇总
VLD(Visual Leak Detector) 下载 官方下载地址2.5 另一分支2.7 安装 点击运行安装...

yolo格式数据集之空中及地面拍摄道路病害检测7种数据集已划分好|可以直接使用|yolov5|v6|v7|v8|v9|v10通用
yolo格式数据集之空中及地面拍摄道路病害检测7种数据集已划分好|可以直接使用|yolov5|v6|v7|v8|v9|v10通用 本数据为空中及地面拍摄道路病害检测检测数据集,数据集数量如下: 总共有:33585张 训练集:6798张 验证集:3284张 测试集&a…...
[Meachines] [Easy] Mirai Raspberry树莓派默认用户登录+USB挂载文件读取
信息收集 IP AddressOpening Ports10.10.10.48TCP:22,53,80,1276,32400,32469 $ nmap -p- 10.10.10.48 --min-rate 1000 -sC -sV PORT STATE SERVICE VERSION 22/tcp open ssh OpenSSH 6.7p1 Debian 5deb8u3 (protocol 2.0) | ssh-hostkey: | 1024 aa:ef:5c:…...

从零开始安装Jupyter Notebook和Jupyter Lab图文教程
前言 随着人工智能热浪(机器学习、深度学习、卷积神经网络、强化学习、AGC以及大语言模型LLM, 真的是一浪又一浪)的兴起,小伙伴们Python学习的热情达到了空前的高度。当我20年前接触Python的时候,做梦也没有想到Python会发展得怎么…...

数据库魔法:SQL Server中自定义分区函数的奥秘
数据库魔法:SQL Server中自定义分区函数的奥秘 在SQL Server中,分区表是管理大型表和提高查询性能的强大工具。分区函数和分区方案允许你根据特定的规则将数据分散到不同的文件组中。本文将深入探讨如何在SQL Server中实现数据库的自定义分区函数&#…...

网页禁止移除水印
一般的话水印分为明水印和暗水印两种 明水印的话就是在视频canvas上面蒙上一个div(如我上篇文章) ,暗水印的话就是把文字通过技术嵌入到图像里。 具体实现的话可以使用MutationObserver API 来监视 DOM 的变化,特别是针对目标节…...
Node Red 与axios简易测试环境的搭建
为了学习在vue3中如何使用axios,我借Sider Fusion的帮助搭建了基于node的简易测试环境。 Axios 是一个基于 Promise 的 HTTP 客户端,通常用于浏览器环境,但它也可以在 Node.js 环境中使用。因此,可以在 Ubuntu 的 Bash 环境下通过…...
—— 接口测试流程)
测试面试宝典(四十三)—— 接口测试流程
回答一: 接口测试一般遵循以下流程: 需求分析 仔细研究接口的需求文档,包括接口的功能、输入输出参数、业务逻辑、性能要求等。与开发人员、产品经理等沟通,确保对需求的理解准确无误。 测试计划制定 确定测试的目标、范围和策略。…...

arkhamintelligence 请求头加密 X-Payload 完整逆向分析+自动化解决方案
大家好!我是爱摸鱼的小鸿,关注我,收看每期的编程干货。 逆向是爬虫工程师进阶必备技能,当我们遇到一个问题时可能会有多种解决途径,而如何做出最高效的抉择又需要经验的积累。本期文章将以实战的方式,带你详细地逆向分析 arkhamintelligence 请求头加密字段 X-Payload 的…...

Vue Router哈希模式和历史模式
Vue官方文档 哈希模式(hash mode) 特点 URL 格式:使用 # 符号分隔路径,哈希值之后的部分由客户端解析。 https://example.com/#/about无需服务器配置:哈希值部分不会被发送到服务器,因此不需要额外的服…...

BiliBili-UWP:Windows 10/11 上最流畅的第三方B站客户端完全指南
BiliBili-UWP:Windows 10/11 上最流畅的第三方B站客户端完全指南 【免费下载链接】BiliBili-UWP BiliBili的UWP客户端,当然,是第三方的了 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBili-UWP 还在为网页版B站卡顿和操作不便而…...

免费开源!3分钟让Mac鼠标滚动告别卡顿的终极平滑方案
免费开源!3分钟让Mac鼠标滚动告别卡顿的终极平滑方案 【免费下载链接】Mos 一个用于在 macOS 上平滑你的鼠标滚动效果或单独设置滚动方向的小工具, 让你的滚轮爽如触控板 | A lightweight tool used to smooth scrolling and set scroll direction independently fo…...

10分钟学会Appium:移动端自动化测试的终极指南
10分钟学会Appium:移动端自动化测试的终极指南 【免费下载链接】til :memo: Today I Learned 项目地址: https://gitcode.com/gh_mirrors/ti/til Appium是一款功能强大的开源移动端自动化测试工具,支持iOS和Android平台,让开发者和测试…...

性价比高可代理的油烟分离油烟机的厂家
最近跟10多个开厨电店的老板喝茶,一半人唉声叹气:去年赚的钱全压库存里了,3个做了十几年的老老板说,再找不到好产品,今年打算把店转了。为啥好好的店做成这样?说白了就是选品选错了,风口变了&am…...

EMAC寄存器配置与网络性能优化实战
1. EMAC寄存器概述与核心功能以太网媒体访问控制器(EMAC)是现代嵌入式系统中实现网络通信的核心硬件模块,其寄存器配置直接决定了数据传输的可靠性、实时性和效率。作为硬件与协议栈之间的桥梁,EMAC通过精心设计的寄存器组实现了对…...
实战:利用Excel的Solver工具进行投资组合优化)
规划求解(Solver)实战:利用Excel的Solver工具进行投资组合优化
投资界有句老话:"别把鸡蛋放在一个篮子里。"但很少有人告诉你后半句:“每个篮子放多少鸡蛋,才是大学问。“Solver就是投资组合的"营养师”,帮你配出最佳"营养比例”。就像投资界的红绿灯,约束条件告诉你什么可以做,什么不可以碰。 一、什么是规划求解…...

矩阵本地化获客技术落地:同城流量精准匹配与合规运营方案
前言同城本地化流量是短视频生态中转化率最高、精准度最强的流量赛道,广泛适配本地生活服务、实体门店、同城咨询、区域服务商等各类业态。相比于泛全域流量,同城用户具备明确的地域消费属性、就近服务需求,成交意向更强烈,获客落…...
)
Sora 2 + After Effects 24.4终极联动教程:含LUT自动映射、运动追踪反哺、动态遮罩同步(附独家.jsx插件)
更多请点击: https://intelliparadigm.com 第一章:Sora 2与After Effects 24.4深度整合概览 Adobe After Effects 24.4 正式引入对 OpenAI Sora 2 模型输出格式的原生支持,标志着生成式视频工作流首次在专业后期平台中实现端到端闭环。该整…...

告别网络盲区:用RTL8811CU让旧笔记本变身Linux双频WiFi网卡/AP二合一网关
旧硬件新生:用RTL8811CU打造Linux双频无线网关实战指南 每次升级笔记本后,那些陪伴我们多年的旧设备往往被束之高阁。作为一名网络技术爱好者,我发现这些"退役"笔记本其实蕴藏着巨大的再利用价值——特别是当它们遇到RTL8811CU这样…...

SAR ADC性能优化:电压基准设计与THD改善方案
1. 电压基准对SAR ADC性能的影响机制在精密数据采集系统设计中,工程师们常常花费大量精力选择高性能的模数转换器(ADC)和优化输入驱动电路,却容易忽视一个关键因素——电压基准的质量及其驱动能力。对于逐次逼近型(SAR)ADC而言,基准电压的稳定…...