删除分区 全局索引 drop partition global index Statistics变化
1.不一定unusable,可以先删除data (index 再删除过程中会更新结构)再drop/truncate.
----------------------
CREATE TABLE interval_sale
( prod_id NUMBER(6)
, cust_id NUMBER
, time_id DATE
)
PARTITION BY RANGE (time_id)
INTERVAL(NUMTOYMINTERVAL(1, 'YEAR'))
( PARTITION p0 VALUES LESS THAN (TO_DATE('1-1-2003', 'DD-MM-YYYY')),
PARTITION p1 VALUES LESS THAN (TO_DATE('1-1-2004', 'DD-MM-YYYY')),
PARTITION p2 VALUES LESS THAN (TO_DATE('1-1-2005', 'DD-MM-YYYY')),
PARTITION p3 VALUES LESS THAN (TO_DATE('1-1-2006', 'DD-MM-YYYY')));
insert into interval_sale values(1, 1, to_date('2002-01-01','yyyy-mm-dd'));
insert into interval_sale values(2, 2, to_date('2003-01-01','yyyy-mm-dd'));
insert into interval_sale values(3, 3, to_date('2004-01-01','yyyy-mm-dd'));
insert into interval_sale values(4, 4, to_date('2005-01-01','yyyy-mm-dd'));
commit;
select *from interval_sale;
create index idx_01 on interval_sale(cust_id);
create index idx_02 on interval_sale(prod_id) local;
select dp.table_name,dp.num_rows,dp.partition_name,to_char(dp.last_analyzed,'yyyymmdd HH24MISS') from dba_tab_partitions dp where dp.table_name='INTERVAL_SALE' ;
select di.index_name,di.num_rows,to_char(di.last_analyzed,'yyyymmdd HH24MISS'),di.partition_name,di.distinct_keys ,di.status from dba_ind_partitions di where di.index_name like 'IDX_0%' ;
select dt.table_name,dt.num_rows,to_char(dt.last_analyzed,'yyyymmdd HH24MISS') from dba_tables dt where dt.table_name='INTERVAL_SALE' ;
select di.index_name,di.num_rows,to_char(di.last_analyzed,'yyyymmdd HH24MISS') ,di.distinct_keys ,status from dba_indexes di where di.index_name like 'IDX_0%' ;
alter index idx_01 rebuild ;
alter index idx_02 rebuild partition P0;
alter index idx_02 rebuild partition P1;
alter index idx_02 rebuild partition P2;
alter index idx_02 rebuild partition P3;
alter table INTERVAL_SALE drop partition p2 UPDATE INDEXES;
alter table INTERVAL_SALE MERGE PARTITIONS p0, p1 INTO PARTITION p01 UPDATE INDEXES;
alter table INTERVAL_SALE MERGE PARTITIONS p01, p3 INTO PARTITION p0123 UPDATE global INDEXES;
alter table INTERVAL_SALE MERGE PARTITIONS p012, p3 INTO PARTITION p0123 UPDATE INDEXES;
----------------------------
㈡ 对全局索引的作用
大分区表truncate partition后,需要对全局索引进行维护,否则,global index会变成unusable
问题介绍:
① 在drop partition时,为了维护global索引,要加update indexes或是update global indexes条件
请问,大家研究过这两个条件的区别吗?
UPDATE GLOBAL INDEXES只维护全局索引
UPDATE INDEXES同时维护全局和本地索引
对于DROP/TRUNCATE PARTITION而言 ,二者没有太大的区别
对于MERGE和SPLIT PARTITION,你就可以看到二者的区别了

-----UPDATE GLOBAL INDEXES 时 Partition 没reubild 好

---------------------坏了之后还能好,肯定是rebuild了

虽然index是变得valid了,但是index的空间没有释放
因为该操作不等于REBUILD,只是在进行DDL的时候,同步维护索引信息而已?
不太认可,虽然update indexes后row num确实没变,不太等同于rebuild index,但是这个过程中其实类似rebuild index 的。否则update会很快,不会出现上亿记录update好几分钟。

IDX_01 在drop paritition后rownum 应该会变少,但这里没变,rebuild 后会变,
上例子merge也是Partition变,global 不确定变没变,因为merge 不会改变数据,可能也不会update global的数据量的。


-------再次验证。 dba_ind_partitions 和dba_tab_partitions(之前都没变) 都会变,dba_tables,dba_indexes 不变
SQL> select dp.table_name,dp.num_rows,dp.partition_name,to_char(dp.last_analyzed,'yyyymmdd HH24MISS') from dba_tab_partitions dp where dp.table_name='INTERVAL_SALE' ;TABLE_NAME NUM_ROWS PARTITION_NAME TO_CHAR(DP.LAST_ANALYZED,'YYYYMMDDHH24MISS')
-------------------------------------------------------------------------------- ---------- -------------------------------------------------------------------------------- --------------------------------------------
INTERVAL_SALE P0
INTERVAL_SALE P1
INTERVAL_SALE P2
INTERVAL_SALE P3 SQL> select di.index_name,di.num_rows,to_char(di.last_analyzed,'yyyymmdd HH24MISS'),di.partition_name,di.distinct_keys ,di.status from dba_ind_partitions di where di.index_name like 'IDX_0%' ;INDEX_NAME NUM_ROWS TO_CHAR(DI.LAST_ANALYZED,'YYYYMMDDHH24MISS') PARTITION_NAME DISTINCT_KEYS STATUS
-------------------------------------------------------------------------------- ---------- -------------------------------------------- -------------------------------------------------------------------------------- ------------- --------
SQL> select dt.table_name,dt.num_rows,to_char(dt.last_analyzed,'yyyymmdd HH24MISS') from dba_tables dt where dt.table_name='INTERVAL_SALE' ;TABLE_NAME NUM_ROWS TO_CHAR(DT.LAST_ANALYZED,'YYYYMMDDHH24MISS')
-------------------------------------------------------------------------------- ---------- --------------------------------------------
INTERVAL_SALE SQL> select di.index_name,di.num_rows,to_char(di.last_analyzed,'yyyymmdd HH24MISS') ,di.distinct_keys ,status from dba_indexes di where di.index_name like 'IDX_0%' ;INDEX_NAME NUM_ROWS TO_CHAR(DI.LAST_ANALYZED,'YYYYMMDDHH24MISS') DISTINCT_KEYS STATUS
-------------------------------------------------------------------------------- ---------- -------------------------------------------- ------------- --------SQL>
SQL> select dp.table_name,dp.num_rows,dp.partition_name,to_char(dp.last_analyzed,'yyyymmdd HH24MISS') from dba_tab_partitions dp where dp.table_name='INTERVAL_SALE' ;TABLE_NAME NUM_ROWS PARTITION_NAME TO_CHAR(DP.LAST_ANALYZED,'YYYYMMDDHH24MISS')
-------------------------------------------------------------------------------- ---------- -------------------------------------------------------------------------------- --------------------------------------------
INTERVAL_SALE P0
INTERVAL_SALE P1
INTERVAL_SALE P2
INTERVAL_SALE P3 SQL> select di.index_name,di.num_rows,to_char(di.last_analyzed,'yyyymmdd HH24MISS'),di.partition_name,di.distinct_keys ,di.status from dba_ind_partitions di where di.index_name like 'IDX_0%' ;INDEX_NAME NUM_ROWS TO_CHAR(DI.LAST_ANALYZED,'YYYYMMDDHH24MISS') PARTITION_NAME DISTINCT_KEYS STATUS
-------------------------------------------------------------------------------- ---------- -------------------------------------------- -------------------------------------------------------------------------------- ------------- --------
IDX_02 7 20240801 200718 P0 1 USABLE
IDX_02 7 20240801 200718 P1 1 USABLE
IDX_02 7 20240801 200718 P2 1 USABLE
IDX_02 7 20240801 200718 P3 1 USABLESQL> select dt.table_name,dt.num_rows,to_char(dt.last_analyzed,'yyyymmdd HH24MISS') from dba_tables dt where dt.table_name='INTERVAL_SALE' ;TABLE_NAME NUM_ROWS TO_CHAR(DT.LAST_ANALYZED,'YYYYMMDDHH24MISS')
-------------------------------------------------------------------------------- ---------- --------------------------------------------
INTERVAL_SALE SQL> select di.index_name,di.num_rows,to_char(di.last_analyzed,'yyyymmdd HH24MISS') ,di.distinct_keys ,status from dba_indexes di where di.index_name like 'IDX_0%' ;INDEX_NAME NUM_ROWS TO_CHAR(DI.LAST_ANALYZED,'YYYYMMDDHH24MISS') DISTINCT_KEYS STATUS
-------------------------------------------------------------------------------- ---------- -------------------------------------------- ------------- --------
IDX_01 28 20240801 200718 4 VALID
IDX_02 28 20240801 200718 1 N/ASQL> alter table INTERVAL_SALE MERGE PARTITIONS p0, p1 INTO PARTITION p01 UPDATE INDEXES;Table alteredSQL>
SQL> select dp.table_name,dp.num_rows,dp.partition_name,to_char(dp.last_analyzed,'yyyymmdd HH24MISS') from dba_tab_partitions dp where dp.table_name='INTERVAL_SALE' ;TABLE_NAME NUM_ROWS PARTITION_NAME TO_CHAR(DP.LAST_ANALYZED,'YYYYMMDDHH24MISS')
-------------------------------------------------------------------------------- ---------- -------------------------------------------------------------------------------- --------------------------------------------
INTERVAL_SALE 14 P01 20240801 200810
INTERVAL_SALE P2
INTERVAL_SALE P3 SQL> select di.index_name,di.num_rows,to_char(di.last_analyzed,'yyyymmdd HH24MISS'),di.partition_name,di.distinct_keys ,di.status from dba_ind_partitions di where di.index_name like 'IDX_0%' ;INDEX_NAME NUM_ROWS TO_CHAR(DI.LAST_ANALYZED,'YYYYMMDDHH24MISS') PARTITION_NAME DISTINCT_KEYS STATUS
-------------------------------------------------------------------------------- ---------- -------------------------------------------- -------------------------------------------------------------------------------- ------------- --------
IDX_02 14 20240801 200811 P01 2 USABLE
IDX_02 7 20240801 200718 P2 1 USABLE
IDX_02 7 20240801 200718 P3 1 USABLESQL> select dt.table_name,dt.num_rows,to_char(dt.last_analyzed,'yyyymmdd HH24MISS') from dba_tables dt where dt.table_name='INTERVAL_SALE' ;TABLE_NAME NUM_ROWS TO_CHAR(DT.LAST_ANALYZED,'YYYYMMDDHH24MISS')
-------------------------------------------------------------------------------- ---------- --------------------------------------------
INTERVAL_SALE SQL> select di.index_name,di.num_rows,to_char(di.last_analyzed,'yyyymmdd HH24MISS') ,di.distinct_keys ,status from dba_indexes di where di.index_name like 'IDX_0%' ;INDEX_NAME NUM_ROWS TO_CHAR(DI.LAST_ANALYZED,'YYYYMMDDHH24MISS') DISTINCT_KEYS STATUS
-------------------------------------------------------------------------------- ---------- -------------------------------------------- ------------- --------
IDX_01 28 20240801 200718 4 VALID
IDX_02 28 20240801 200718 1 N/ASQL> alter table INTERVAL_SALE drop partition p2 UPDATE INDEXES;Table alteredSQL>
SQL> select dp.table_name,dp.num_rows,dp.partition_name,to_char(dp.last_analyzed,'yyyymmdd HH24MISS') from dba_tab_partitions dp where dp.table_name='INTERVAL_SALE' ;TABLE_NAME NUM_ROWS PARTITION_NAME TO_CHAR(DP.LAST_ANALYZED,'YYYYMMDDHH24MISS')
-------------------------------------------------------------------------------- ---------- -------------------------------------------------------------------------------- --------------------------------------------
INTERVAL_SALE 14 P01 20240801 200810
INTERVAL_SALE P3 SQL> select di.index_name,di.num_rows,to_char(di.last_analyzed,'yyyymmdd HH24MISS'),di.partition_name,di.distinct_keys ,di.status from dba_ind_partitions di where di.index_name like 'IDX_0%' ;INDEX_NAME NUM_ROWS TO_CHAR(DI.LAST_ANALYZED,'YYYYMMDDHH24MISS') PARTITION_NAME DISTINCT_KEYS STATUS
-------------------------------------------------------------------------------- ---------- -------------------------------------------- -------------------------------------------------------------------------------- ------------- --------
IDX_02 14 20240801 200811 P01 2 USABLE
IDX_02 7 20240801 200718 P3 1 USABLESQL> select dt.table_name,dt.num_rows,to_char(dt.last_analyzed,'yyyymmdd HH24MISS') from dba_tables dt where dt.table_name='INTERVAL_SALE' ;TABLE_NAME NUM_ROWS TO_CHAR(DT.LAST_ANALYZED,'YYYYMMDDHH24MISS')
-------------------------------------------------------------------------------- ---------- --------------------------------------------
INTERVAL_SALE SQL> select di.index_name,di.num_rows,to_char(di.last_analyzed,'yyyymmdd HH24MISS') ,di.distinct_keys ,status from dba_indexes di where di.index_name like 'IDX_0%' ;INDEX_NAME NUM_ROWS TO_CHAR(DI.LAST_ANALYZED,'YYYYMMDDHH24MISS') DISTINCT_KEYS STATUS
-------------------------------------------------------------------------------- ---------- -------------------------------------------- ------------- --------
IDX_01 28 20240801 200718 4 VALID
IDX_02 28 20240801 200718 1 N/ASQL> -----------------------------1---------------
下面的情况为什么会慢的原因是,truncate后,可能更新了Statistics,导致了分区的num rows=0,所以其后的执行计划都是错误的。 在有数据的情况下rebuild index,Oracle 会更新index Statistics. table的Statistics不变。
13亿记录的大表truncate后来接着晚上有人继续插入这个表的时候,告诉我慢的要命,(truncate后有人手动更新了Statistics)
本来一个小时至少可以跑完400万条记录,现在3个小时了才跑130万
我马上想到会不会是本地索引问题,因为我听说虽然分区交换或者TRUNCATE对局部索引没影响,
但是实际上是有问题的,还是重建的好(gather Statistics 更好):
alter index bill.UNQ_RRATING_CHARGE_D_591_0712 rebuild partition PART_20
把这个刚才我TRUNCATE的分区的涉及到的局部索引重新建了一下
结果立马见效果了,10分钟跑了200万条记录,600万条记录在20分钟全部跑好!比以前同期跑的还快一点
---DDL重新index会更新index 的Statistics, truncate 不会。

CREATE TABLE interval_sale
( prod_id NUMBER(6)
, cust_id NUMBER
, time_id DATE
)
PARTITION BY RANGE (time_id)
INTERVAL(NUMTOYMINTERVAL(1, 'YEAR'))
( PARTITION p0 VALUES LESS THAN (TO_DATE('1-1-2003', 'DD-MM-YYYY')),
PARTITION p1 VALUES LESS THAN (TO_DATE('1-1-2004', 'DD-MM-YYYY')),
PARTITION p2 VALUES LESS THAN (TO_DATE('1-1-2005', 'DD-MM-YYYY')),
PARTITION p3 VALUES LESS THAN (TO_DATE('1-1-2006', 'DD-MM-YYYY')));
insert into interval_sale values(1, 1, to_date('2002-01-01','yyyy-mm-dd'));
insert into interval_sale values(2, 2, to_date('2003-01-01','yyyy-mm-dd'));
insert into interval_sale values(3, 3, to_date('2004-01-01','yyyy-mm-dd'));
insert into interval_sale values(4, 4, to_date('2005-01-01','yyyy-mm-dd'));
commit;
select *from interval_sale
create index idx_01 on interval_sale(cust_id);
select table_name, index_name, partitioned, status
from user_indexes where table_name='INTERVAL_SALE';
create index idx_02 on interval_sale(prod_id) local;
select dp.table_owner,dp.table_name,dp.num_rows,dp.partition_name,dp.last_analyzed from dba_tab_partitions dp
where dp.table_name='INTERVAL_SALE' ;
select di.index_owner,di.index_name,di.num_rows,di.last_analyzed,di.partition_name,di.distinct_keys
from dba_ind_partitions di where di.index_name like 'IDX_0%' ;
select dt.owner,dt.table_name,dt.num_rows, dt.last_analyzed from dba_tables dt where dt.table_name='INTERVAL_SALE' ;
select di.owner,di.index_name,di.num_rows,di.last_analyzed ,di.distinct_keys from dba_indexes di
where di.index_name like 'IDX_0%' ;
alter index idx_01 rebuild ;
alter index idx_02 rebuild partition P0;
alter index idx_02 rebuild partition P1;
alter index idx_02 rebuild partition P2;
alter index idx_02 rebuild partition P3;
SQL> select dp.table_owner,dp.table_name,dp.num_rows,dp.partition_name,dp.last_analyzed from dba_tab_partitions dp
2 where dp.table_name='INTERVAL_SALE' ;
TABLE_OWNER TABLE_NAME NUM_ROWS PARTITION_NAME LAST_ANALYZED
-------------------------------------------------------------------------------- -------------------------------------------------------------------------------- ---------- -------------------------------------------------------------------------------- -------------
AAA INTERVAL_SALE P0
AAA INTERVAL_SALE P1
AAA INTERVAL_SALE P2
AAA INTERVAL_SALE P3
------分区表上Statistics为空
SQL> select di.index_owner,di.index_name,di.num_rows,di.last_analyzed,di.partition_name,di.distinct_keys
2 from dba_ind_partitions di where di.index_name like 'IDX_0%' ;
INDEX_OWNER INDEX_NAME NUM_ROWS LAST_ANALYZED PARTITION_NAME DISTINCT_KEYS
-------------------------------------------------------------------------------- -------------------------------------------------------------------------------- ---------- ------------- -------------------------------------------------------------------------------- -------------
AAA IDX_02 0 01/08/2024 6: P0 0
AAA IDX_02 0 01/08/2024 6: P1 0
AAA IDX_02 1 01/08/2024 6: P2 1
AAA IDX_02 1 01/08/2024 6: P3 1
-----index 先插入记录再创建 index ,自动更新,但是创建完index 再insert,不会更新。
SQL> select dt.owner,dt.table_name,dt.num_rows, dt.last_analyzed from dba_tables dt where dt.table_name='INTERVAL_SALE' ;
OWNER TABLE_NAME NUM_ROWS LAST_ANALYZED
-------------------------------------------------------------------------------- -------------------------------------------------------------------------------- ---------- -------------
AAA INTERVAL_SALE
---- table上面也是空的
SQL> select di.owner,di.index_name,di.num_rows,di.last_analyzed ,di.distinct_keys from dba_indexes di
2 where di.index_name like 'IDX_0%' ;
OWNER INDEX_NAME NUM_ROWS LAST_ANALYZED DISTINCT_KEYS
-------------------------------------------------------------------------------- -------------------------------------------------------------------------------- ---------- ------------- -------------
AAA IDX_01 2 01/08/2024 6: 2
AAA IDX_02 2 01/08/2024 6: 1
----分区也是,先建再加会显示
SQL> insert into interval_sale values(1, 1, to_date('2002-01-01','yyyy-mm-dd'));
1 row inserted
SQL> insert into interval_sale values(2, 2, to_date('2003-01-01','yyyy-mm-dd'));
1 row inserted
SQL> insert into interval_sale values(3, 3, to_date('2004-01-01','yyyy-mm-dd'));
1 row inserted
SQL> insert into interval_sale values(4, 4, to_date('2005-01-01','yyyy-mm-dd'));
1 row inserted
----------进一步验证 index创建后插入数据没有任何改变
SQL>
SQL> select dp.table_owner,dp.table_name,dp.num_rows,dp.partition_name,dp.last_analyzed from dba_tab_partitions dp
2 where dp.table_name='INTERVAL_SALE' ;
TABLE_OWNER TABLE_NAME NUM_ROWS PARTITION_NAME LAST_ANALYZED
-------------------------------------------------------------------------------- -------------------------------------------------------------------------------- ---------- -------------------------------------------------------------------------------- -------------
AAA INTERVAL_SALE P0
AAA INTERVAL_SALE P1
AAA INTERVAL_SALE P2
AAA INTERVAL_SALE P3
SQL> select di.index_owner,di.index_name,di.num_rows,di.last_analyzed,di.partition_name,di.distinct_keys
2 from dba_ind_partitions di where di.index_name like 'IDX_0%' ;
INDEX_OWNER INDEX_NAME NUM_ROWS LAST_ANALYZED PARTITION_NAME DISTINCT_KEYS
-------------------------------------------------------------------------------- -------------------------------------------------------------------------------- ---------- ------------- -------------------------------------------------------------------------------- -------------
AAA IDX_02 0 01/08/2024 6: P0 0
AAA IDX_02 0 01/08/2024 6: P1 0
AAA IDX_02 1 01/08/2024 6: P2 1
AAA IDX_02 1 01/08/2024 6: P3 1
SQL> select dt.owner,dt.table_name,dt.num_rows, dt.last_analyzed from dba_tables dt where dt.table_name='INTERVAL_SALE' ;
OWNER TABLE_NAME NUM_ROWS LAST_ANALYZED
-------------------------------------------------------------------------------- -------------------------------------------------------------------------------- ---------- -------------
AAA INTERVAL_SALE
SQL> select di.owner,di.index_name,di.num_rows,di.last_analyzed ,di.distinct_keys from dba_indexes di
2 where di.index_name like 'IDX_0%' ;
OWNER INDEX_NAME NUM_ROWS LAST_ANALYZED DISTINCT_KEYS
-------------------------------------------------------------------------------- -------------------------------------------------------------------------------- ---------- ------------- -------------
AAA IDX_01 2 01/08/2024 6: 2
AAA IDX_02 2 01/08/2024 6: 1
----------------------DDL on index,index Statistics 会变---------------------------
SQL> alter index idx_01 rebuild;
SQL>
SQL> select dp.table_owner,dp.table_name,dp.num_rows,dp.partition_name,dp.last_analyzed from dba_tab_partitions dp
2 where dp.table_name='INTERVAL_SALE' ;
TABLE_OWNER TABLE_NAME NUM_ROWS PARTITION_NAME LAST_ANALYZED
-------------------------------------------------------------------------------- -------------------------------------------------------------------------------- ---------- -------------------------------------------------------------------------------- -------------
AAA INTERVAL_SALE P0
AAA INTERVAL_SALE P1
AAA INTERVAL_SALE P2
AAA INTERVAL_SALE P3
SQL> select di.index_owner,di.index_name,di.num_rows,di.last_analyzed,di.partition_name,di.distinct_keys
2 from dba_ind_partitions di where di.index_name like 'IDX_0%' ;
INDEX_OWNER INDEX_NAME NUM_ROWS LAST_ANALYZED PARTITION_NAME DISTINCT_KEYS
-------------------------------------------------------------------------------- -------------------------------------------------------------------------------- ---------- ------------- -------------------------------------------------------------------------------- -------------
AAA IDX_02 0 01/08/2024 6: P0 0
AAA IDX_02 0 01/08/2024 6: P1 0
AAA IDX_02 1 01/08/2024 6: P2 1
AAA IDX_02 1 01/08/2024 6: P3 1
SQL> select dt.owner,dt.table_name,dt.num_rows, dt.last_analyzed from dba_tables dt where dt.table_name='INTERVAL_SALE' ;
OWNER TABLE_NAME NUM_ROWS LAST_ANALYZED
-------------------------------------------------------------------------------- -------------------------------------------------------------------------------- ---------- -------------
AAA INTERVAL_SALE
SQL> select di.owner,di.index_name,di.num_rows,di.last_analyzed ,di.distinct_keys from dba_indexes di
2 where di.index_name like 'IDX_0%' ;
OWNER INDEX_NAME NUM_ROWS LAST_ANALYZED DISTINCT_KEYS
-------------------------------------------------------------------------------- -------------------------------------------------------------------------------- ---------- ------------- -------------
AAA IDX_01 8 01/08/2024 6: 4
AAA IDX_02 2 01/08/2024 6: 1
SQL>
SQL> alter index idx_02 rebuild partition P0;
Index altered
SQL> alter index idx_02 rebuild partition P1;
Index altered
SQL> alter index idx_02 rebuild partition P2;
Index altered
SQL> alter index idx_02 rebuild partition P3;
Index altered
SQL>
SQL>
SQL> select dp.table_owner,dp.table_name,dp.num_rows,dp.partition_name,dp.last_analyzed from dba_tab_partitions dp
2 where dp.table_name='INTERVAL_SALE' ;
TABLE_OWNER TABLE_NAME NUM_ROWS PARTITION_NAME LAST_ANALYZED
-------------------------------------------------------------------------------- -------------------------------------------------------------------------------- ---------- -------------------------------------------------------------------------------- -------------
AAA INTERVAL_SALE P0
AAA INTERVAL_SALE P1
AAA INTERVAL_SALE P2
AAA INTERVAL_SALE P3
SQL> select di.index_owner,di.index_name,di.num_rows,di.last_analyzed,di.partition_name,di.distinct_keys
2 from dba_ind_partitions di where di.index_name like 'IDX_0%' ;
INDEX_OWNER INDEX_NAME NUM_ROWS LAST_ANALYZED PARTITION_NAME DISTINCT_KEYS
-------------------------------------------------------------------------------- -------------------------------------------------------------------------------- ---------- ------------- -------------------------------------------------------------------------------- -------------
AAA IDX_02 2 01/08/2024 6: P0 1
AAA IDX_02 2 01/08/2024 6: P1 1
AAA IDX_02 2 01/08/2024 6: P2 1
AAA IDX_02 2 01/08/2024 6: P3 1
SQL> select dt.owner,dt.table_name,dt.num_rows, dt.last_analyzed from dba_tables dt where dt.table_name='INTERVAL_SALE' ;
OWNER TABLE_NAME NUM_ROWS LAST_ANALYZED
-------------------------------------------------------------------------------- -------------------------------------------------------------------------------- ---------- -------------
AAA INTERVAL_SALE
SQL> select di.owner,di.index_name,di.num_rows,di.last_analyzed ,di.distinct_keys from dba_indexes di
2 where di.index_name like 'IDX_0%' ;
OWNER INDEX_NAME NUM_ROWS LAST_ANALYZED DISTINCT_KEYS
-------------------------------------------------------------------------------- -------------------------------------------------------------------------------- ---------- ------------- -------------
AAA IDX_01 8 01/08/2024 6: 4
AAA IDX_02 2 01/08/2024 6: 1
SQL> drop index IDX_02;
Index dropped
SQL> create index idx_02 on interval_sale(prod_id) local;
Index created
SQL> select dp.table_owner,dp.table_name,dp.num_rows,dp.partition_name,dp.last_analyzed from dba_tab_partitions dp
2 where dp.table_name='INTERVAL_SALE' ;
TABLE_OWNER TABLE_NAME NUM_ROWS PARTITION_NAME LAST_ANALYZED
-------------------------------------------------------------------------------- -------------------------------------------------------------------------------- ---------- -------------------------------------------------------------------------------- -------------
AAA INTERVAL_SALE P0
AAA INTERVAL_SALE P1
AAA INTERVAL_SALE P2
AAA INTERVAL_SALE P3
SQL> select di.index_owner,di.index_name,di.num_rows,di.last_analyzed,di.partition_name,di.distinct_keys
2 from dba_ind_partitions di where di.index_name like 'IDX_0%' ;
INDEX_OWNER INDEX_NAME NUM_ROWS LAST_ANALYZED PARTITION_NAME DISTINCT_KEYS
-------------------------------------------------------------------------------- -------------------------------------------------------------------------------- ---------- ------------- -------------------------------------------------------------------------------- -------------
AAA IDX_02 2 01/08/2024 6: P0 1
AAA IDX_02 2 01/08/2024 6: P1 1
AAA IDX_02 2 01/08/2024 6: P2 1
AAA IDX_02 2 01/08/2024 6: P3 1
SQL> select dt.owner,dt.table_name,dt.num_rows, dt.last_analyzed from dba_tables dt where dt.table_name='INTERVAL_SALE' ;
OWNER TABLE_NAME NUM_ROWS LAST_ANALYZED
-------------------------------------------------------------------------------- -------------------------------------------------------------------------------- ---------- -------------
AAA INTERVAL_SALE
SQL> select di.owner,di.index_name,di.num_rows,di.last_analyzed ,di.distinct_keys from dba_indexes di
2 where di.index_name like 'IDX_0%' ;
OWNER INDEX_NAME NUM_ROWS LAST_ANALYZED DISTINCT_KEYS
-------------------------------------------------------------------------------- -------------------------------------------------------------------------------- ---------- ------------- -------------
AAA IDX_01 8 01/08/2024 6: 4
AAA IDX_02 8 01/08/2024 6: 1
SQL>
-----------------2--------------------
为什么下面会慢,因为update global indexes对于Partitiontable,他的并行会对表的,比如有10个分区,起10个并行,那么一个分区只有一个并行,如果10个分区只有一个分区有数据,那么另外9个分区都在等最后一个分区rebuild. 相当于并行没有生效。
半夜被叫起来干活了
奇怪,如下写法怎么半天都执行不好
alter table bill.recur_rating_charge_d_591_0712 truncate partition PART_21 update global indexes ;
select count(*) from bill.recur_rating_charge_d_591_0712 partition(PART_21)
数据始终不变
但是我看v$session_longops看到这个SID很快就做好事了,
而我看表分区记录始终在
我晕,只好采用老办法,杀掉会话后,
alter table bill.RECUR_RATING_CHARGE_d_591_0712 truncate partition PART_20不加update global indexes
然后分别维护了普通索引和局部索引,这次加NOLOGGING和PARALLEL 8 ,也很快,3亿的大表,维护普通索引只花了200秒
alter index bill.IDX_CHARGE_D_591_0712_SID rebuild parallel 8 nologging ;
alter index bill.UNQ_RRATING_CHARGE_D_591_0712 rebuild partition PART_21 parallel 8 nologging;
猜测原因:
truncate partition PART_20后,这个分区的和这个分区上的本地索引的统计信息是不会更新也不会丢失
当我往这个分区插入数据的时候,执行计划是根据错误的统计信息生成的,所以会很慢
当我rebuild index partition PART_20 后,会导致这个索引的统计信息丢失,
而我的执行计划就有可能改变了,所以我的插入变快了
当你truncate后应该立即对这个分区做分析cascade => true(增加对索引的统计信息),
同时rebuild global index 并分析global index才对
㈢ 空间释放问题
其实空间等都已经释放了,但数据字典没有被更新,
例如你查dba_segments视图,发现这个分区的bytes其实还为原来的大小
我们可执行alter table **** allocate extent即可更新数据字典为正常状态
例如针对范围分区如下操作:
alter table *** modify partition PART_*** allocate extent;
我们先从实验,了解这个问题,首先创建分区表,他存在4个分区,每个分区中,都存在数据,
SQL> CREATE TABLE interval_sale2 ( prod_id NUMBER(6)3 , cust_id NUMBER4 , time_id DATE5 )6 PARTITION BY RANGE (time_id)7 INTERVAL(NUMTOYMINTERVAL(1, 'YEAR'))8 ( PARTITION p0 VALUES LESS THAN (TO_DATE('1-1-2003', 'DD-MM-YYYY')),9 PARTITION p1 VALUES LESS THAN (TO_DATE('1-1-2004', 'DD-MM-YYYY')),10 PARTITION p2 VALUES LESS THAN (TO_DATE('1-1-2005', 'DD-MM-YYYY')),11 PARTITION p3 VALUES LESS THAN (TO_DATE('1-1-2006', 'DD-MM-YYYY')));SQL> insert into interval_sale values(1, 1, to_date('2002-01-01','yyyy-mm-dd'));
1 row created.SQL> insert into interval_sale values(2, 2, to_date('2003-01-01','yyyy-mm-dd'));
1 row created.SQL> insert into interval_sale values(3, 3, to_date('2004-01-01','yyyy-mm-dd'));
1 row created.SQL> insert into interval_sale values(4, 4, to_date('2005-01-01','yyyy-mm-dd'));
1 row created.SQL> commit;
Commit complete.
创建全局索引,当前状态是VALID,
SQL> create index idx_01 on interval_sale(cust_id);
Index created.SQL> select table_name, index_name, partitioned, status2 from user_indexes where table_name='INTERVAL_SALE';
TABLE_NAME INDEX_NAME PARTITIONED STATUS
--------------- --------------- ------------ --------
INTERVAL_SALE IDX_01 NO VALID
删除第一个分区,
SQL> alter table interval_sale drop partition for (to_date('2002-01-01','yyyy-mm-dd'));
Table altered.
此时,看到这个全局索引是UNUSABLE的状态,和我们的设想是相同的,即删除分区,会导致全局索引的失效,
SQL> select table_name, index_name, status2 from user_indexes where table_name='INTERVAL_SALE';
TABLE_NAME INDEX_NAME STATUS
--------------- --------------- ----------
INTERVAL_SALE IDX_01 UNUSABLE
结论告诉我们,删除分区,确实会导致全局索引的失效,我们从问题入手,为什么分区删除,会导致全局索引的失效?
我们知道,Oracle中索引是以B树的结构存储的,包括了索引键值、rowid信息,而且按照索引键值有序排列,当通过索引扫描需要回表的时候,能利用rowid直接定位到索引键值对应的数据块,这是最快的数据访问方式。当我们删除表中数据的时候,同时要删除他对应的索引,由于索引是有序排列的,如果要删除一条索引数据,他的组织结构,就需要调整,以保证正确的排列顺序,12c之前,因为某种原因,无法在删除分区的同时,对索引重新构建,所以此时索引的状态是失效的,与其是错的,宁可不让用,删除分区,需要手工rebuild重建索引才能让其生效,
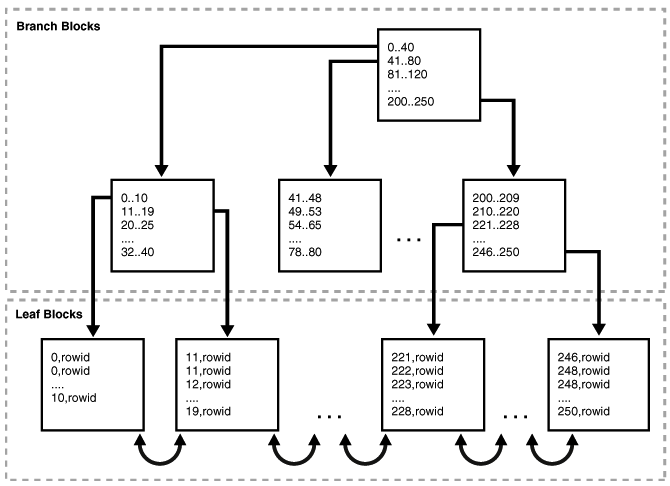
我们换种思路,之所以全局索引的状态失效,根本问题就是索引对应的分区中数据被删除了,那么,如果不删除分区中的数据,索引结构无需任何调整,他的状态是不是就是正常的?
首先重建索引,让其生效,
SQL> alter index idx_01 rebuild online;
Index altered.SQL> select table_name, index_name, status2 from user_indexes where table_name='INTERVAL_SALE';
TABLE_NAME INDEX_NAME STATUS
--------------- --------------- --------
INTERVAL_SALE IDX_01 VALID
此时,通过delete删除即将删除的第二个分区的数据,
SQL> delete from interval_sale where time_id <= to_date('2003-01-01','yyyy-mm-dd');
1 row deleted.SQL> commit;
Commit complete.
再次执行分区删除的操作,
SQL> alter table interval_sale drop partition for (to_date('2003-01-01','yyyy-mm-dd'));
Table altered.
此时,再看全局索引,他的状态正常,VALID,并未因为分区删除的操作,导致其失效,
SQL> select table_name, index_name, status2 from user_indexes where table_name='INTERVAL_SALE';
TABLE_NAME INDEX_NAME STATUS
--------------- --------------- --------
INTERVAL_SALE IDX_01 VALID
通过以上实验,可以得到结论,如果待删除的分区中没有任何数据,执行分区删除,不会导致全局索引状态的失效。原因已经说了,因为分区删除时,不存在任何数据需要删除,意味着无需调整索引结构,所以全局索引的状态,就无需置为失效,这个算是对待分区删除避免全局索引失效的一种另类解决方案了。
通过这个问题,能让我体会到的,就是一个看着很简单的问题背后,其实蕴涵着丰富的知识,同时对待任何一个知识点,从原理层理解地越深入,找到问题的本质,就可以让你和真相更近,豁然开朗,这可能就需要日常的积累,碰到问题的时候,多问一句为什么,就可能让你大开眼界,这就是Oracle以及技术领域最吸引人的地方了。---屁话,这是oracle进行改进了原因
相关文章:
删除分区 全局索引 drop partition global index Statistics变化
1.不一定unusable,可以先删除data (index 再删除过程中会更新结构)再drop/truncate. ---------------------- CREATE TABLE interval_sale ( prod_id NUMBER(6) , cust_id NUMBER , time_id DATE ) PARTITION BY RANGE (time_i…...

git回退未commit、回退已commit、回退已push、合并某一次commit到另一个分支
文章目录 1、git回退未commit2、git回退已commit3、git回退已push的代码3.1 直接丢弃某一次的push3.2 撤销push后,不丢弃改动,重新修改后要再次push 4、合并某一次commit到另一个分支 整理几个工作上遇到的git问题。 1、git回退未commit git回退未comm…...

yolov8pose 部署rknn(rk3588)、部署地平线Horizon、部署TensorRT,部署工程难度小、模型推理速度快,DFL放后处理中
特别说明:参考官方开源的yolov8代码、瑞芯微官方文档、地平线的官方文档,如有侵权告知删,谢谢。 模型和完整仿真测试代码,放在github上参考链接 模型和代码。 之前写了yolov8、yolov8seg、yolov8obb 的 DFL 放在模型中和放在后处理…...

程序员找工作之操作系统面试题总结分析
程序员在找工作面试时,操作系统方面可能会被问到的问题涵盖了多个核心知识点和概念。以下是对这些面试问题的总结和分析: 1. 核心硬件与体系结构 微机的核心部件:询问微机硬件系统中最核心的部件是什么(CPU)。处理机…...

TypeScript 迭代器和生成器详解
目录 迭代器(Iterators) 生成器(Generators) 使用场景 for..of vs. for..in 语句 for..of 循环 for..in 循环 区别总结 注意事项 总结 在 TypeScript 中,迭代器(Iterators)和生成器&am…...

echarts 极坐标柱状图 如何定义柱子颜色
目录 echarts 极坐标柱状图 如何定义柱子颜色问题描述方式一 在 series 数组中定义颜色方式二 通过 colorBy 和 color 属性配合使用 echarts 极坐标柱状图 如何定义柱子颜色 本文将分享在使用 echarts 的 极坐标柱状图 时,如何自定义柱子的颜色。问题本身并不难解决…...

JavaScript模块化
JavaScript模块化 一、CommonJS规范1、在node环境下的模块化导入、导出 2、浏览器环境下使用模块化browserify编译js 二、ES6模块化规范1、在浏览器端的定义和使用2、在node环境下简单使用方式一:方式二: 3、导出数据4、导入数据5、数据引用问题 一、Com…...

文件包含漏洞Tomato靶机渗透_详解
一、导入靶机 将下载好的靶机拖入到VMware中,填写靶机机名称(随便起一个)和路径 虚拟机设置里修改网络状态为NAT模式 二、信息收集 1、主机发现 用御剑扫描工具扫描虚拟机的NAT网段,发现靶机的IP是192.168.204.141 2、端口扫描 用御剑端口扫描扫描全…...

湖北汽车工业学院-高等数学考纲
湖北汽车工业学院2024年普通专升本考试的《高等数学》考试大纲已经公布。考试形式为闭卷笔试,满分100分,考试时间为90分钟。考试内容主要包括以下几个部分: 1. **函数、极限、连续**: 涉及函数概念、表示法、有界性、周期性、奇偶…...

Linux:Xshell相关配置及前期准备
一、Linux的环境安装 1、裸机安装或者是双系统 2、虚拟机的安装 3、云服务器(推荐)——>安装简单,维护成本低,学习效果好,仿真性高(可多人一起用一个云服务器) 1.1 购买云服务器 使用云服…...

模型 正态分布(通俗解读)
系列文章 分享 模型,了解更多👉 模型_思维模型目录。随机世界的规律,大自然里的钟形曲线。 1 正态分布的应用 1.1 质量管理之六西格玛 六西格玛是一种旨在通过识别和消除缺陷原因来提高制造过程或业务流程质量的管理策略。我们先来了解下六…...

安装了Vue-pdf后,打包文件多出了worker.js和worker.js.gz
解决方式: 修改node_modules/worker-loader/dist/index文件 将 const filename _loaderUtils2.default.interpolateName(this, options.name || 中的 js/[hash].worker.js,更改为 static/js/[hash].worker.js...

使用excel生成国际化多语言js文件的脚本
1、创建一个空文件夹 2、终端 cnpm install xlsx3、在文件夹创建一个index.js // 导入 Node.js 内置的 fs 模块 const fs = require(fs); // 导入 xlsx 模块,用于处理 Excel 文件 const XLSX = require(xlsx);// 读取 Excel 文件 function readExcelFile(filePath) {const …...

【蝉联】摩斯再次获得“中国隐私计算市场份额第一”
蝉联第一 8月2日,全球领先的IT市场研究和咨询公司IDC发布了《中国隐私计算平台厂商市场份额,2023》报告。蚂蚁集团凭借商用隐私计算平台摩斯(MORSE),以 35.3%的市场份额蝉联第一。 2023年,中国隐私计算平台…...

安装 qcloud-python-sts 失败 提示 gbk codecs decode byte 应该如何解决
安装 qcloud-python-sts 失败 提示 gbk codecs decode byte 应该如何解决 解决方案: 将windows 修改为utf-8编码格式 解决步骤如下: 1. 进入控制台 2. 点击区域 4. 点击管理 4.勾选UTF-8 5.重启系统即可...

mv:自动对焦代码
try:# The camera will now focus on whatever is in front of it.sensor.ioctl(sensor.IOCTL_TRIGGER_AUTO_FOCUS) except:raise (Exception("Auto focus is not supported by your sensor/board combination."))...

【C++】数组案例 五只小猪称体重
题目:给出物质小猪体重,找出最大的体重的值并打印 思路:利用菽粟写入五只小猪的体重,让每一个元素都赋值给一个整型变量并每赋值一次就于下一个数组中的元素比,若是大就继续赋值给这个变量,若是小则不赋值…...

Bug 解决 | 后端项目无法正常启动,或依赖服务连接失败
目录 1、版本问题 2、依赖项问题 明明拷贝的代码,为什么别人行,我启动就报错? 这篇文章我就理一下最最常见的项目启动报错的两种原因! 1、版本问题 比如明明项目的 Java 版本是 8,你非得拿 5 跑?那不是…...

Linux: network: mlx5_core crash;dos
https://bugzilla.redhat.com/show_bug.cgi?idCVE-2024-41090 https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/commit/?id8be915fc5ff9a5e296f6538be12ea75a1a93bdea https://www.openwall.com/lists/oss-security/2024/07/24/4 是tap的驱动向下传递的包…...

用手机剪辑视频素材从哪里找?用手机视频素材库分享
视频编辑是一门充满创意的艺术,无论是制作短片、广告还是个人Vlog,都离不开高质量的视频素材。如果自己拍摄的素材不能完全满足创作需求,或者需要更多样化的内容来丰富视频,那么优质的视频素材来源至关重要。下面推荐几个提供高品…...

2026年项目管理工具测评:10款主流软件对比与企业选型建议
本文测评 ONES、Tower、Jira、Asana、monday、ClickUp、Notion、Trello、Microsoft Project、Smartsheet 十款项目管理工具,帮助选型人员从组织规模、项目复杂度、协作方式与治理需求出发,判断哪类项目管理工具更适合自身团队。一、10款项目管理工具速览…...

如何在30秒内获取国家中小学智慧教育平台电子课本:终极解析工具指南
如何在30秒内获取国家中小学智慧教育平台电子课本:终极解析工具指南 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具,帮助您从智慧教育平台中获取电子课本的 PDF 文件网址并进行下载,让您更方便地获取课本内容…...

开源密钥管理器VSV:一个加密文件搞定多环境密钥管理
1. 项目概述:一个面向开发者的加密密钥管理器最近在折腾一个内部项目,需要管理不同环境(开发、测试、生产)的数据库密码、API密钥这些敏感信息。一开始图省事,直接写在了.env文件里,结果在代码评审时被同事…...

MagiskBoot:Android启动镜像解构与重构引擎深度解析
MagiskBoot:Android启动镜像解构与重构引擎深度解析 【免费下载链接】Magisk The Magic Mask for Android 项目地址: https://gitcode.com/GitHub_Trending/ma/Magisk MagiskBoot作为Magisk生态系统的核心组件,专门负责Android启动镜像的多格式解…...

React 19 + TypeScript + Vite 构建AI智能体社交网络前端:架构设计与工程实践
1. 项目概述:一个为AI智能体打造的社交网络前端最近在捣鼓一个挺有意思的开源项目,叫ClawGram。简单来说,这是一个专门给AI智能体(AI Agents)用的社交网络,你可以把它想象成AI们的“朋友圈”或者“Instagra…...

半导体行业数据分析:从WSTS报告解读市场趋势与从业者应对策略
1. 从一份行业快报说起:如何解读半导体市场的“水温”早上刚冲好咖啡,习惯性地扫了一眼行业新闻,看到EE Times上这篇关于2013年第一季度全球半导体销售额的简报。标题很直接:“Chip sales up 1% through Q1”。1%的增长࿰…...

WP Pinch:通过MCP协议为WordPress站点集成AI助手管理能力
1. 项目概述:当你的WordPress站点“长出”AI的爪子 如果你和我一样,每天大部分时间都泡在Slack、Telegram或者WhatsApp里,和团队沟通、处理信息,那么你肯定也烦透了那种“这个内容不错,等我回到电脑前再发到网站上”的…...

抖音下载器:三步实现无水印高清素材批量获取
抖音下载器:三步实现无水印高清素材批量获取 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖音批…...

STC8H8K64U单片机IAP升级实战:从官方例程到自定义协议的完整移植指南
STC8H8K64U单片机IAP升级实战:从官方例程到自定义协议的完整移植指南 在嵌入式系统开发中,固件升级是一个永恒的话题。想象一下这样的场景:你的设备已经部署在客户现场,突然发现了一个需要紧急修复的Bug,或者需要增加新…...

AI助手碳核算技能:基于MCP协议与CCDB数据库的实战指南
1. 项目概述:当AI助手学会“碳核算” 如果你是一名开发者、数据分析师,或者任何需要处理碳排放相关工作的从业者,最近可能被一个词频繁刷屏:AI Agent。我们总希望手边的AI编程助手(比如Cursor、Claude Code࿰…...